
一种高精度并行主偏度分析算法及其在遥感图像中的应用
2023-11-18 08:49王大虎
电子与信息学报 2023年10期
王大虎 刘 畅* 王 健 姚 锴 张 振
①(中国科学院空天信息创新研究院 北京 100190)
②(中国科学院大学电子电气与通信工程学院 北京 100094)
③(陆军航空兵学院 北京 101123)
1 引言
随着遥感技术的发展,人们可以获得越来越多的高维大规模遥感图像数据。在过去的几十年中,许多学者使用遥感图像数据在光谱融合[1]、目标分类[2]、目标检测[3]、图像去噪[4]、图像压缩[5]等研究领域做了大量研究。高维大规模数据所蕴含的巨大的信息为后续遥感图像处理带来巨大挑战,过高的数据维度不利于后续的存储、传输以及运算,而特征提取成为解决这一问题的关键技术。
近几年研究人员提出了多种用于特征提取的算法,典型方法包括主成分分析方法(Principal Component Analysis, PCA)[6]、奇异值分解(Singu lar Value Decom position, SVD) 和独立成分分析方法(Independen t Com ponen t Analysis, ICA)[7]。PCA是基于数据的2阶相关统计特征找到一组正交向量集,这个向量集从最小二乘意义上对原始信号进行表示。SVD则是在最大能量的意义上选择较大的变量对原矩阵进行分解,以此来提取数据矩阵的主要特征。上述方法主要针对数据的2阶统计特征,并假设数据满足高斯分布。然而,许多真实数据集的分布通常不满足高斯分布。在这种情况下,基于高阶统计量的ICA方法近年来受到了越来越多的关注。ICA是对数据进行高阶统计分析以寻求非高斯量最大化来分离各个独立的信号源。FastICA是ICA的一种改进算法,它可以选择偏度、负熵、峭度等指标作为非高斯度量[8]。虽然FastICA算法能达到3次收敛速度,优于其他大多数常用的ICA算法[9],但是其每次迭代都需要涉及所有的像素来寻找最优的投影方向,这导致其在处理高维数据时耗时大。
为了解决这一问题,Geng等人[10]提出了一种主偏度分析方法(Principal Skew ness Analysis,PSA),该方法的求解可以转化为计算数据3阶统计张量特征对,因此PSA可以看作PCA的3阶泛化。当选择偏度作为非高斯指标时,可等效为FastICA。在此基础上,文献[11,12]进一步提出了动量PSA(Momentum Principal Skewness Analysis, MPSA)和主峰度分析方法(Principal Kurtosis Analysis,PKA)。超对称张量并不具有天然的正交性[13,14],然而PSA和MPSA算法在求解过程中均采用了正交补策略,因此它们得到的解(特征对)是相互正交的。这导致除了第1个特征对外,得到的其他特征对都偏离了协偏度张量的实际特征对。针对这个问题,Geng等人[15]又提出了一种新的非正交的PSA(Nonorthogonal Principal Skew ness Analysis,NPSA)算法。NPSA算法通过引入克罗内克积提出了一种新的搜索策略,该策略可以在更大的空间内搜索解,因此可以获得比PSA算法更精确的解,但是NPSA算法得到的仍然是近似解。
针对上述局限,本文提出了一种新的高精度并行主偏度分析(Parallel Principle of Skewness Analysis, PPSA)算法,PPSA算法把协偏度张量切片的特征向量作为初始值进行迭代求解。与现有PSA算法施加约束再依次求解各特征对不同,PPSA算法不再施加约束,而是将各个特征对的初始值并行地、一次性地全部算出,有效地避免了施加约束带来的误差。相比以前只能得到近似解,PPSA算法可以准确得到实际解。
2 PSA算法


3 PPSA算法
3.1 现有PSA算法局限
现有的 PSA 算法主要采用了串行方式依次求解各个特征对,为了避免收敛到同一特征对而施加约束,但是这也将导致除了第1个特征对外,其他特征对都偏离了实际特征对[15]。并且现有PSA算法初始化均采用随机生成初始值,这意味着给定不同的初始化,可能收敛到不同的解(特征对)[18]。在这里举一个简单的例子来更直观地说明这两种现象。考虑一个2阶超对称张量,其两个切片分别为

这个简单的例子直观地说明了现有的PSA算法并不能准确地得到协偏度张量的实际特征对,还证明了现有的PSA算法随机生成初始值,导致每次运行都会收敛到不同的特征对。并且上述问题会随着张量维数的增加表现得更加明显,在3阶2维超对称张量求解中,可能会收敛到两个不同的特征对,在3阶维超对称张量求解中,因为初始值的不同可能收敛到个不同的特征对。因此如何设计出计算求解精确、稳定的方法至关重要。
3.2 PPSA算法
针对上述问题,本文在PSA算法基础上进行改进,提出一种高精度并行PSA算法。PPSA算法不再施加约束,而是将各个特征对的初始值并行地全部算出,有效地避免了施加约束和串行计算带来的误差。
求解协偏度张量的实际特征对可以理解为求解张量的局部极大值解[18],只要保证初始值落在协偏度张量各个收敛区域,然后再使用不动点迭代法进行求解,就能保证精确地求解到所有极大值解。因此求解协偏度张量的特征对问题可转化为初始值选取的问题。常见的初始化方法有随机初始化,基于正交约束的随机初始化。随机初始化的方法虽然可以精确求解,但是它们受初始值影响很大,并且是不可重复的。因此设计出一种初始值可重复,可以稳定的精确的求解出协偏度张量的特征对的方法是很重要的。

图1 不同初始值,PSA,MPSA算法求解结果

图2 不同初始值,NPSA算法求解结果
PPSA算法充分考虑数据结构,选用协偏度张量的全部切片的特征向量作为迭代的初始值。首先,此方法是可重复的。其次,此方法是并行的。最后,对比随机初始化方法,此方法可以获得稳定精确的解的原因是我们相信它将提供在最优解附近的初始猜测。
假设S ∈R[3,n],如果λ是协偏度张量S的一个特征值,设u是S关于λ的单位特征向量,即u=[a1,a2,...,a n]T且uTu=1。求 解S×1u×3u=λu,其等价求解
由式(7)可知,求解协偏度张量的局部极值解等价多个主成分分析联合求极大极小值。把协偏度张量的切片的特征向量作为迭代初始值可以理解为从单个主成分的极值点去逼近联合主成分的极值点。因此对比随机选取初始值,此初始化方法生成的初始值距离实际特征对更近。为了验证这一结论,本文在4.1节做了蒙特卡罗仿真实验。
为方便起见,总结PPSA算法如算法1所示。
需要注意的是,PPSA算法中步骤7中的循环终止条件包含最小允许误差ε和最大循环次数K。本文ε设置为0.0001,K设置为1000。U是最终的非正交主偏度变换矩阵。

算法1 PPSA算法
同样对上述3.1节的例子进行计算,用PPSA算法重复上述操作,求解得到的结果为=[0.8812,-0.4727]T,=[0.3756,0.9268]T。

图3 PPSA算法求解结果
4实验与复杂度分析
本文将PPSA算法应用于盲图像分离、SAR图像去噪以及高光谱特征提取,并与几种经典方法开展了对比试验。所有的算法都是在1台CPU AMD Ryzen 7 5800H,16 GB RAM,@3.20 GHz的笔记本电脑上完成的,所有程序在MATLAB R2021a上编程和实现。
4.1 蒙特卡罗仿真实验
为了检验本文所提出的初始化算法的效果,本文采用蒙特卡罗方法进行验证。实验采用有n个极大值特征对的3阶n维超对称张量进行求解,n分别取2~9。采用3种不同的初始化方法进行迭代求解,进行10万次蒙特卡罗仿真后,对比求解正确的结果,其结果如表1所示。
从实验结果上看,基于协偏度张量的单个切片的特征向量作为初始值的方法好于基于正交约束的随机初始化方法以及随机初始值的初始化方法。但是随着协偏度阶数的增加,此初始化得到全部解的概率会有所下降。为了改善这种情况,可以适当增加初始值的数量,选用全部切片的特征向量作为迭代初始值重复上述实验,其结果如表2所示。
从实验结果上看,随着初值点数的增加,各种初始化方法得到所有特征对的概率都有明显提升。尤其是基于全部切片的特征向量作为初始值的方法,其在所有的实验中准确率均达到了99.9%。因此,对比随机初始化方法,选用协偏度张量的全部切片的特征向量作为迭代的初始值距离实际特征对更近。
4.2 盲图像分离实验
本文首先将PPSA算法应用于盲图像分离(B lind Im age Separation,BIS)问题上,BIS的目的是估计混合矩阵,记为B(或其逆矩阵,即分解矩阵,记为U)。本文将PPSA算法与Fast ICA[8],PSA[10],MPSA[11],NPSA[15]和MSDP[18]等算法进行比较,评价各算法的分离性能。在本实验中,本文选取n幅大小为256像素×256像素的灰度图像作为源图像,其中n分别取值2~6。由于已知真实的源图像,因此可以将其与各算法获得的结果进行比较。由于篇幅的限制,本文没有显示所有实验结果,只选择n=3的情况进行展示,结果如图4所示。为了确保结论的可靠性,本文还进行了其他两种组合实验,在每种组合中本文随机选择3种不同的源图像进行实验。
从实验结果来看,上述6种算法均可以从混合图像中分离出源图像,为了定量评估上述6种算法的性能,本文使用5个评估指标对上述6种算法获得的分离结果进行评价。5个评价指标分别为符号间干扰(InterSymbol-Interference,ISI)[15]、总均方误差(Total M ean Square Error,TMSE)[15]、相关系数指数(Correlation Coefficient,记为ρ)[15]、峰值信噪比(Peak Signal to Noise Ratio,PSNR)[15]和运行时间(Time,T)。值得注意的是除PPSA算法与MSDP算法外,其余4种算法获得的结果均具有随机性[18],因此本文取10次运行的平均值作为最终结果。
表3详细地列出了3种不同组合下6种算法的符号间干扰、总均方误差、相关系数、峰值信噪比和运行时间。对于ISI和TM SE指标,指数值越小,代表该方法的性能越好;ρ和PSNR越大,代表该方法的性能更好。通过对表3进行分析可以得到如下结论:
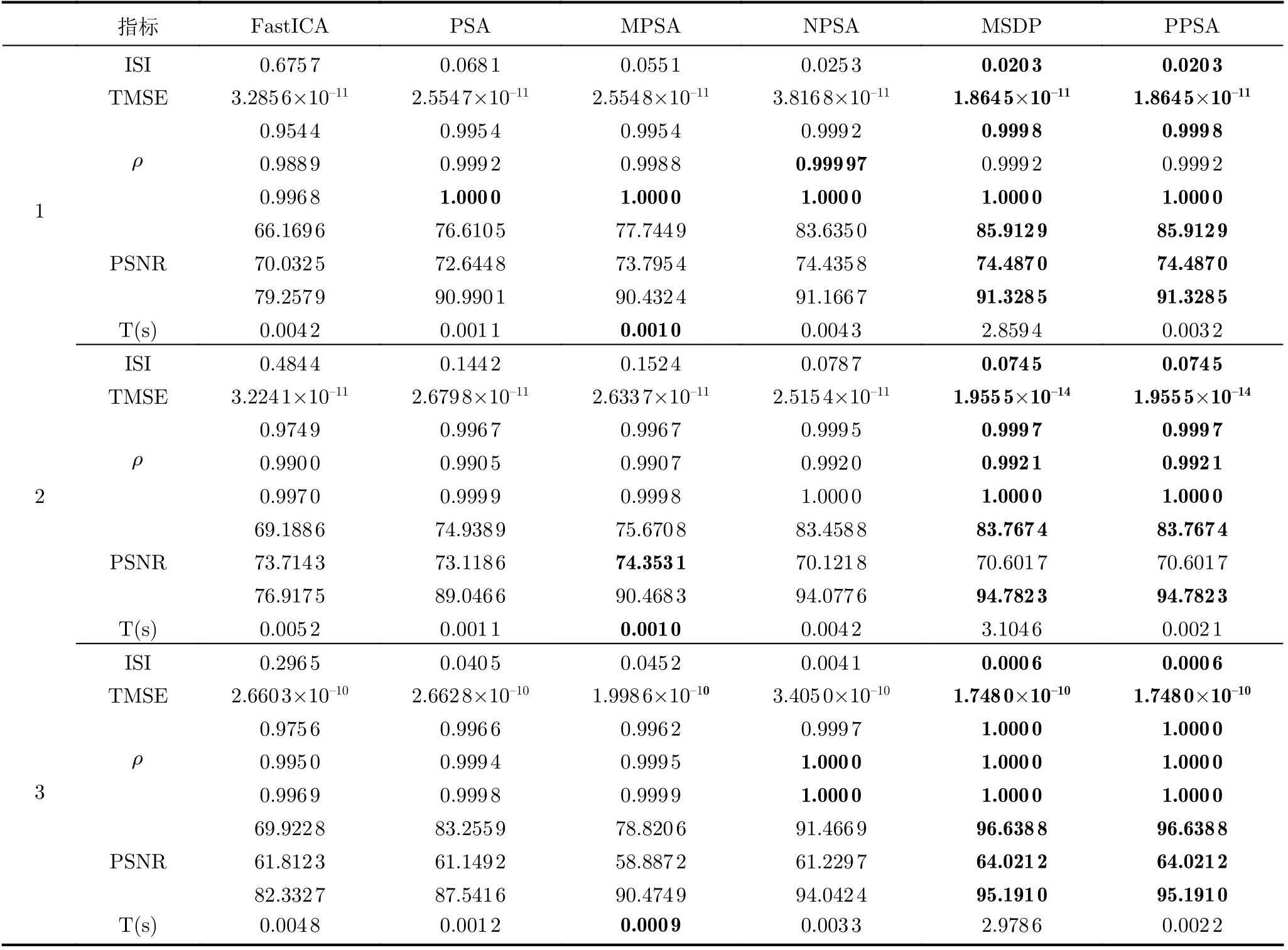
表3 FastICA,PSA, MPSA,NPSA,MSDP和PPSA算法评估结果
(1)MSDP算法可以准确得到张量的特征对[18],通过观察MSDP算法与PPSA算法的评价指标,可以发现PPSA算法与MSDP算法获得的结果一致,这说明PPSA算法也可以准确得到张量的实际特征对,验证了本文所提方法的有效性。同时,PPSA算法的运行时间远小于MSDP算法的运行时间,这说明PPSA算法在精确求解的同时还可以做到快速求解。
(2)PPSA算法获得的ISI与TMSE指标始终小于其余4种方法的,ISI与TMSE指标越小,图像分离效果越好,这说明PPSA算法在BIS应用中可以获得更好的整体效果。
(3)PPSA算法获得的相关系数与峰值信噪比也在这6种算法中处于较高水平,相关系数值和峰值信噪比越大,分离图像质量越好,这说明PPSA算法性能稳定。
最后,结合上述5个指标的比较结果,说明PPSA算法在BIS应用中具有更准确和更鲁棒的性能。
4.3 SAR图像去噪实验
本文将PPSA算法用于SAR图像去噪问题上,实验使用的是高分三号拍摄的一幅美国旧金山图像,图像大小为448像素×364像素,极化方式为HV极化。对源图像施加噪声来模拟低信噪比图像,通常认为SAR图像的斑点噪声服从伽马分布或者高斯分布,因此分别在源图上施加均值为0,方差为100的高斯噪声(记为Egs=0,=100)和均值为2,方差为80的伽马噪声(记为Egm=2,=80)来仿真低信噪比的混合图像。将原始图像按逐行的方式转化为相应的3个1维信号,产生随机混合矩阵rand(3,3)。1维信号与随机混合矩阵混合后得到混合图像,再使用FastICA,PSA,NPSA,PPSA、均值滤波和中值滤波等算法对混合图像进行去噪处理,结果如图5所示。
因为FastICA,PSA和NPSA的处理结果受随机初值影响,所以本文选择它们10次实验的最佳的处理结果进行对比以及展示。同样,本文也选择出均值滤波以及中值滤波最佳的结果进行对比展示,均值滤波与中值滤波均选择5×5大小的滤波器。
通过观察图5,发现 PSA算法、NPSA算法、PPSA算法的去噪效果优于FastICA算法、中值滤波和均值滤波。为了客观评价分离滤波结果,本文分别计算图像去噪后的峰值信噪比(PSNR)[15]和平均绝对误差(MAE)。对像素为M×N的图像,其MAE定义为
式中,h(x,y)和g(x,y)分别表示原始图像与待评价图像的第 个像素的灰度值。为了保证结论的可靠性,本文还选择不同参数的伽马噪声与高斯噪声进行了2次实验,计算结果如表4所示。

表4 不同算法的平均峰值信噪比和平均绝对误差(计算10次运行的平均结果)
MAE越小,算法性能越好。由表4可看出,对于相同强度的高斯噪声和伽马噪声,均值滤波法和中值滤波法的去噪效果相对较差,而FastICA方法相对较好,PSA方法在所有组合中均获得了不错的效果,尤其是PPSA方法,能显著地去除噪声,提高复原图像的质量。结合上述两个指标的比较结果,说明PPSA算法在SAR图像去噪处理中具有更强的去噪能力。
4.4 高光谱特征提取实验
本节使用高光谱数据集Cuprite来评价PPSA算法的性能。该数据集是由机载可见红外成像光谱仪于1997年6月在内华达州铜矿矿区获得的。将数据嵌入到可视化图像环境软件中,图像包含50个波段,每个波段有350像素×400像素,伪彩色图像如图6所示。

图6 高光谱Cup rite数据彩色图像

图7 4种算法运行时间对比图
本文直接选择数据集Cup rite全部的50个波段进行特征提取。当选用全部50个波段进行特征提取时,MSDP和FastICA算法的时间消耗是巨大的[18],因此本文使用PSA,MPSA,NPSA和PPSA算法进行特征提取。与4.2节的情况不同,在实际数据处理中,通常不知道独立分量的数量,所以PSA,MPSA和NPSA算法的独立分量的数量总是手动设置为频带的数量。因此用上述3种算法进行求解,它们最终全都获得50个独立分量。相比之下,PPSA算法是参数自适应的,它不需要事先设置独立分量的数量,它可以自动确定独立分量的数目,用PPSA算法进行求解,最终获得了6个独立分量。由于不知道真实数据的参考独立分量,因此4.2节仿真实验部分使用的评价指标不可用。因为篇幅的限制,本文不一一显示PSA,MPSA和NPSA这3种算法获得的结果。本文仅显示PPSA算法获得的结果,如图8所示。

图8 PPSA算法对高光谱图像Cup rite的偏度比较
其余3种算法虽然均获得了50个独立分量,但是所提取到50个特征对中大多是没有信息的冗余结果,并且提取到的特征对除了第1个外其余都为近似解。把PSA,MPSA和NPSA这3种算法得到的50个独立分量分别作为初始值进行固定点迭代求解,最终全都收敛为6个独立分量,这6个独立分量与PPSA算法得到的结果完全相同,说明PPSA算法在对高维数据进行特征提取时具有更好的自适应性和准确性。
此外,本文还对上述4种算法的运行速度进行比较。PPSA算法可以并行地求解各特征对,因此PPSA算法可以使用Parfor并行加速计算。本文将使用Parfor并行加速计算的PPSA算法命名为FastPPSA。
图7绘制了不同数量波段下4种算法的运行时间曲线,根据Cuprite数据各波段的偏度值,从小到大排列依次选取n个 波段进行特征提取,n的范围为2~50。
通过观察图7可以看出在处理相同数量的数据样本时(样本数大于20时),MPSA算法运行时间小于FastPPSA算法运行时间小于PSA算法运行时间小于NPSA算法运行时间小于PPSA算法运行时间。同时,还可以看出在处理高阶数据时FastPPSA算法运行时间远小于PPSA算法运行时间。然而在处理低阶数据时FastPPSA运行时间要略大于PPSA算法的运行时间。这是因为当计算机处理的数据量较小时,Parfor并行加速在初始化过程中需要消耗大量的时间,这部分时间在总的运行时间里占了很大的一部分。因此,当所要处理图像规模较小时,利用Parfor并行运算的加速效果并不明显。然而,随着张量维数的逐渐增大,耗费在并行计算额外开销上的时间占算法执行总时间的比例越来越小,所以并行加速效果明显。FastPPSA采用Parfor并行计算导致其在处理高维数据时运算速度很快,处理50个样本数据,其运行速度为3.1028 s,NPSA运行速度为17.2797 s,PPSA算法运行时间为28.1447 s。
结合上述实验结果与分析可知,本文所提出的PPSA算法不仅能够准确地对高光谱数据进行特征提取,而且还可以做到快速提取。这说明PPSA算法在高光谱数据特征提取上具有更好的准确性、自适应性和鲁棒性。
4.5 复杂度分析
本节从理论上比较PSA算法和PPSA算法的计算复杂度。由于这两种方法基本流程都一样,只是在求解张量特征对时主循环的次数不同,因此只需考虑主循环求解的计算复杂性。对于L×M大小的数据,PSA算法只需要循环L次,假设每次循环需要迭代K次,其中K是平均迭代次数,则PSA算法需要进行K L次操作。同样对于L×M大小的数据,PPSA算法则需要循环L2次,同样也假设每次循环需要迭代K次,因此PPSA算法最终需要K L2次操作。虽然本文PPSA算法的计算复杂度略高于PSA算法,但PPSA算法相对于PSA算法的主要优势在于PPSA算法是并行的,所以它可以采用并行计算来提升算法运行速度。由前面的高光谱运行速度对比实验可知,在处理高维数据时,采用并行加速计算后的PPSA算法运行速度更快。
5 结束语
本文针对现有PSA算法不能准确得到实际解这一问题,在原有的PSA算法的基础上进行改进,提出了一种高精度并行PSA算法。与现有PSA算法串行求解特征对不同,本文所提算法不再施加任何约束,而是选择张量全部切片的特征向量作为初始值进行自由迭代求解,有效地避免了施加约束带来的误差。通过将PPSA算法与现有PSA算法进行实验对比,验证了PPSA算法在盲图像分离,SAR图像去噪以及高光谱数据特征提取上具有更好的准确性和鲁棒性。PSA,NPSA以及PPSA都关注数据集的3阶偏度。对于其他数据集,偏度可能并不总是最佳选择。在这种情况下,可以选用其他指标,如4阶峰度或其他高阶统计量替代。
猜你喜欢
数学物理学报(2021年1期)2021-03-29
五邑大学学报(自然科学版)(2020年4期)2020-12-09
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
电子制作(2018年19期)2018-11-14
数学小灵通·3-4年级(2017年9期)2017-10-13
自动化学报(2017年11期)2017-04-04
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
噪声与振动控制(2015年4期)2015-01-01
河南科技(2014年23期)2014-02-27
