
结合光流算法与注意力机制的U-Net网络跨模态视听语音分离
2023-11-18 08:48兰朝凤蒋朋威郭小霞
电子与信息学报 2023年10期
兰朝凤 蒋朋威 陈 欢 韩 闯* 郭小霞
①(哈尔滨理工大学测控技术与通信工程学院 哈尔滨 150080)
②(中国舰船研究设计中心 武汉 430064)
1 引言
在人机交互中,干净且高质量的声音输入,能有效提高语音识别(Automatic Speech Recognition,ASR)和自然语言理解(Natu ral Language P rocessing,NLP)的准确度。然而现实生活中,由于环境的复杂性,存在噪声和其他说话者的干扰,很难直接得到干净的语音信号。因此,需要采用语音分离技术对复杂场景下的语音信号进行前端处理,语音分离的最终目的是将目标声音与背景噪声(环境噪声、人声等)进行分离。
近年来,国内外学者针对语音分离提出了多种模型方法。基于传统信号处理的角度,人们利用统计学方法解决语音分离。例如W ang等人[1]提出的计算机场景分析(Com putational Auditory Scene Analysis,CASA)、文献[2,3]提出的非负矩阵分解(Non-negative M atrix Factorization,NM F),但CASA,NM F学习能力不足,限制了整体性能进一步提高。随着深度学习的快速发展,以深度神经网络(Deep Neural Network,DNN)为代表的深度模型[4]在语音分离方面取得了显著的进展,如深度聚类(deep clustering)[5]和置换不变训练(Perm utation Invariant T raining,PIT)[6]。然而,这些基于音频流的方法都存在标签置换问题,很难将分离的音频与混合信号中相对应的说话者对应。
在拥挤的餐厅和嘈杂的酒吧,人类的感知系统能有效处理复杂环境。例如人类能只关注自己感兴趣的声音,而忽略外部的干扰声音。这种复杂场景下的语音感知能力不仅依赖人类听觉系统,还得益于视觉系统,共同促进多感官的感知[7,8]。受此启发,基于视听融合的多模态主动说话者检测[9]、视听语音分离[10]、视听同步[11]等研究被相继提出。
Gabbay等人[12]提出基于视频帧的语音分离网络,利用视频帧中面部信息辅助进行语音分离,虽然有效地减少了混合噪声对分离的影响,但是该方法具有局限性,只能在有限的环境下取得较好分离效果,不具有泛化性。A fouras等人[13]在Gabbay等人的基础上,提出用光谱信号代替图像信号作为时间信号的分离方案,并用softmask进行预测。谷歌最早提出基于视频和声音联合表征的多流体卷积神经网络[14],该方法从输入的视频流提取人脸图像,然后从音频流提取音频特征,通过在卷积层进行特征拼接,得到融合后视听特征,将视听特征输入双向长短时记忆网络(B i-d irectiona l Long Short-Term M em ory,BiLSTM),输出二值掩蔽(Ideal Binary M ask,IBM),最后将IBM与混合语谱图相乘得到分离语音。为了提高不同场景下视听语音分离的鲁棒性,Gao等人[15]提出了多任务建模策略。该策略通过学习跨模态的嵌入来建立人脸和声音的匹配,通过人脸和声音的相互关联,有效解决了视听不一致问题。X iong等人[16]在多任务建模基础上,提出了基于跨模态注意的联合特征表示的视听语音分离,将多任务建模策略应用于视听融合,提高了视觉信息利用率。
上述利用视觉信息辅助进行语音分离方法,可以从混合声音中自动分离出对应视觉部分的音频信号,有效地解决标签置换问题。但这些方法提取视觉特征仅包括唇部特征,在小规模数据集上,面对更复杂的场景时容易受到干扰。视听融合采用简单的特征拼接或叠加方法,融合方法单一,未能充分融合视听特征。
为提高视觉特征的鲁棒性和解决视听融合单一性,本文在基于跨模态注意联合特征表示的基础上,分析面部特征外,通过Farneback算法从光流中获得唇部运动特征。为了充分考虑光流运动特征、视觉特征、音频特征之间相互联系,采用了多头注意力机制,结合Farneback算法和U-Net网络,提出了一种新的跨模态融合策略。跨模态融合策略的创新主要在于:利用缩放点积注意力计算音频特征与视觉特征相关性,同时在缩放点积注意力中加入可学习参数,可以自适应调整注意力权重,加快模型的收敛速度;在缩放点积注意力的基础上,采用多头注意力机制,利用不同的子空间计算音频特征与视觉特征相关性,通过对不同子空间的计算结果进行累加,从而获得音频和视觉信息的联合特征表示,以提高语音分离效果。
2 分离模型
2.1 光流算法
光流表征的是图像像素在运动时的瞬时速度矢量,光流法主要是利用图像序列中像素之间的相关性来找到前后帧跟当前帧之间存在的对应关系、计算出相邻帧之间像素的运动信息[17]。光流可以被认为是在一幅图像中亮度模式的表面运动分布,是图像中所有像素点的2维速度场,其中每个像素的2维运动向量可以理解为一个光流,所有的光流构成光流场,如图1所示[18]。

图1 2 维光流矢量表示观测场景中3维速度在成像表面投影
通过光流场中2维光流矢量的疏密程度,将光流法分为稀疏光流与稠密光流[19]。稀疏光流是对指定的某一组像素点进行跟踪,稠密光流是针对图像或指定的某一片区域进行逐点匹配的图像配准方法。相比较稀疏光流,稠密光流可以计算图像所有运动的像素点,进行像素级别的图像配准。所以,本文利用稠密Farneback光流算法分析唇部的运动信息。
Farneback光流算法假设亮度恒定不变、时间连续运动或是“小运动”、光流的变化几乎是光滑的。像素在唇部图像第1帧的光强度为I(x,y,t)(其中x,y代 表像素点当前位置、t代表所在的时间维度),像素点移动了(dx,dy)的距离到下一帧,用了dt时间,根据亮度恒定不变,可得


其中,Ix,I y,I t可由唇部图像数据求得,(u,v)为所求的光流矢量。
2.2 注意力机制
注意力机制可以直接获取到局部和全局的关系,相比较循环神经网络(Recurrent Neural Netw ork,RNN)不会受到序列长度限制,同时参数少、模型复杂度低。
注意力机制是在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。注意力机制的核心公式为
其中,Q,K,V分别表示查询、键、值,dk表 示K的维度大小。Q,K,V计算过程为
其中,X为输入矩阵,A表示权重矩阵,A Q,A K和AV是3个可训练的参数矩阵。输入矩阵X分别与A Q,AK和AV相乘,生成Q,K,V,相当于进行了线性变换。A ttention使用经过矩阵乘法生成的3个可训练参数矩阵,增强了模型的拟合能力。Q,K,V的计算过程如图2所示。

图2 Q,K,V计算过程
为了进一步增强模型拟合性能,T ransformer对A ttention继续扩展,提出了多头注意力。在单头注意力机制中,Q,K,V是输入X与A Q,AK和A V分别相乘得到的,A Q,AK和AV是可训练的参数矩阵。对于同样的输入X,本文定义多组不同的A Q,AK和AV,如AQ0,A0K,AV0和AQ1,AK1,A V1,每组分别计算生成不同的Q,K,V,最后学习到不同的参数,如图3所示。

图3 定义多组A,生成多组Q,K,V
2.3 跨模态融合的光流-视听分离框架
2.3.1网络体系结构
基于Farneback光流算法能较好地提取唇部运动特征,以及注意力机制能充分利用视听特征相关性的优势,本文提出了跨模态融合的光流-视听分离(Flow-AudioV isual Speech Separation,Flow-AVSS)网络。Flow-AVSS采用了常用的混合-分离训练方法,通过稠密光流(Farneback)算法和轻量级网络Shu ffleNet v2分别提取运动特征和唇部特征,然后将运动特征与唇部特征进行仿射变换,经过时间卷积模块得到视觉特征,为充分利用到视觉信息,在进行特征融合时采用多头注意力机制,将视觉特征与音频特征进行跨模态融合,得到融合视听特征,最后融合视听特征经过U-Net分离网络得到分离语音。Flow-AVSS网络如图4所示。
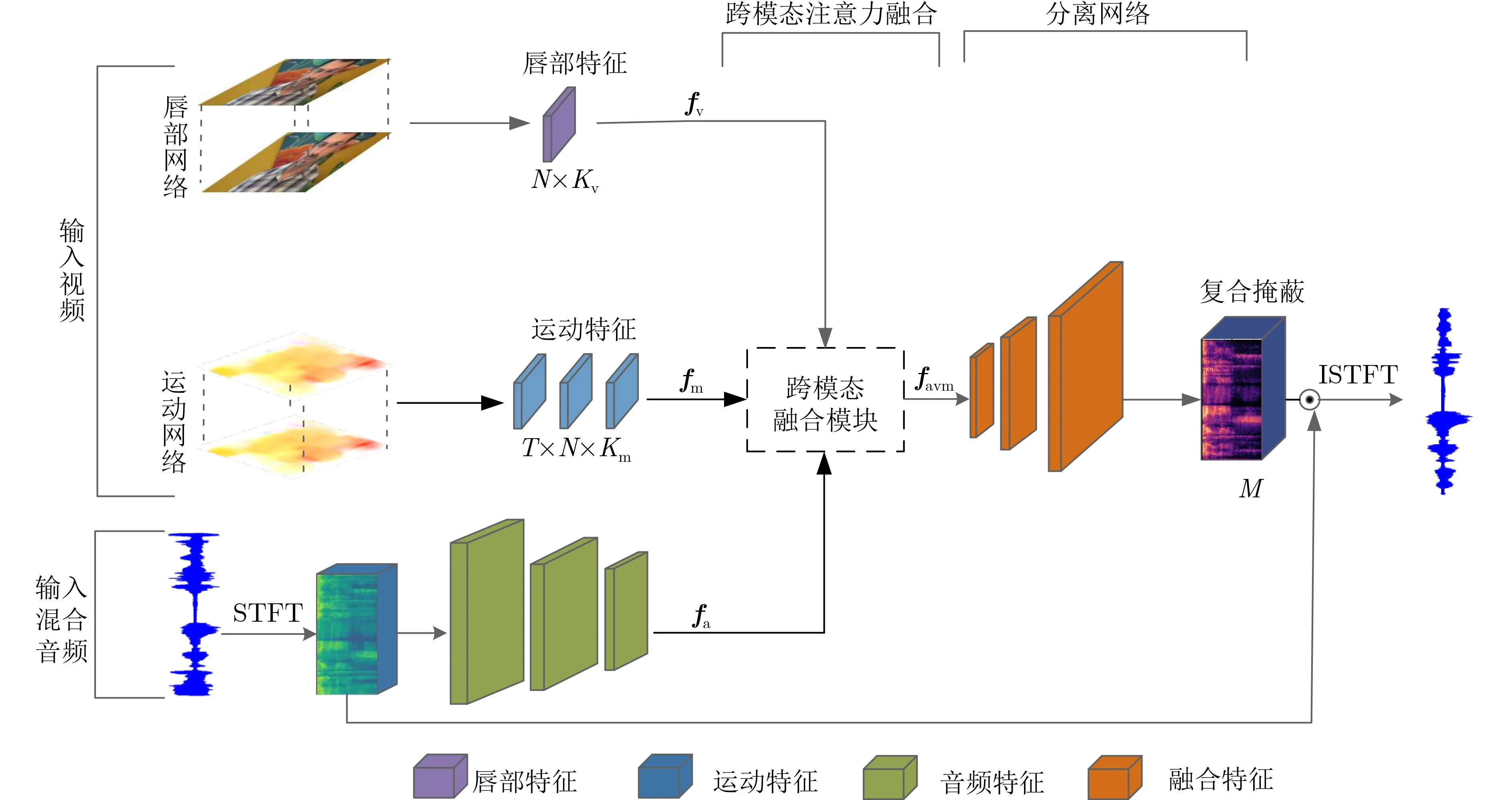
图4 跨模态融合的光流-视听分离框架
图4主要由4部分组成,分别是唇部网络、运动网络、跨模态融合模块和语音分离网络。唇部网络对输入视频帧进行特征提取,该网络由1个3维卷积层和1个ShuffleNet v2网络[20]组成,唇部网络采用N个连续堆叠的灰度图像,生成维度为Kv的唇部特征向量fv,v 表示唇部图像。
为了能稳定地捕捉视觉特征的空间和时间信息,引入了运动网络。受动作识别研究的最新进展的启发,将预训练的膨胀卷积网络(In flated 3D convnet,I3D)模型[21]加入到视听分离框架作为运动网络。前文光流算法讲到,在计算机视觉空间中,光流场是将3维空间的物体运动表现到了2维图像中,缺少了时间维度。运动网络通过将2维卷积网络膨胀到3维,从而获得缺少的时间维度,将先前灰度图像估计的光流,生成维度为Km的运动特征向量fm,m表示运动。然后,将运动特征的时间维度与通道维度相乘,获得与唇部特征相同维度的运动特征。最后,将同维度的运动特征和唇部特征输入到跨模态融合模块。
语音分离网络的结构类似于U-Net网络[22],输出掩码与输入掩码大小相同。该网络由编码器和解码器组成,编码器的输入是混合信号的2维音频特征。输入经过一系列的卷积层和池化层处理后,对复谱图进行压缩降维。将音频特征fa、唇部特征fv和运动特征fm进行跨模态融合得到视听特征favm。其中,a表示音频,avm表示音频、唇部、运动融合。解码器的输入是视听特征favm,输出是预测的复合掩码M,复合掩码M的维度与输入频谱图维度相同。最后,将复合掩码M与混合音频相乘,得到分离后的语谱图,并进行短时傅里叶逆变换(Inverse Short Time Fourier T ransform,ISTFT)得到最终分离的语音信号。
2.3.2跨模态融合模块
为了充分考虑各个模态之间相关性,实现不同模态之间的联合表示,本文提出基于注意力机制的跨模态融合策略,跨模态融合模块的整体结构如图5所示。

图5 跨模态融合模块整体结构
本文利用了运动特征、唇部特征、音频特征去进行多模态融合。其中,由于运动特征是利用光流算法对图像进行特征提取,运动特征和唇部特征都属于视觉特征,是同一种模态,因此在进行特征融合的时候,先利用文献[23]中提出的特征线性调制(Feature-w ise Linear M odulation,FiLM)对唇部特征和运动特征进行特征仿射变换处理,表示为
其中,γ(·)和β(·)是单层的全连接层,输出是缩放向量和偏移向量。
运动特征fm经过线性变换与fv相乘进行仿射变换,并送入时间卷积网络(Tem poral Convolutional Network,TCN)[24]。TCN由1维卷积、批量归一化(Batch Norm alization,BN)和整流线性单元(Rectified Linear Unit,ReLU)组成,通过TCN模块可以捕获唇部特征中的时间关系。最后TCN模块输出视觉特征fvm,如图6所示。

图6 仿射变换和TCN模块
受T ransform er多头注意力[25]启发,跨模态融合模块采用了跨模态注意力融合(C ross-M odal A ttention,CMA)策略。在表示注意力机制的式(6)中,加入可学习参数λ,不仅能自适应地调整注意力权重,还能作为残差连接I(fm),加快模型收敛速度。由式(6)可得缩放点积注意力跨模态融合(Scaled dot-p roduct Cross-M odal A tten tion,SCMA),可表示为
其中,视觉特征fvm经过2维卷积得到Qvm和Kvm,音频特征fa经过2维卷积得到Va,d是Qvm,Kvm和Va的维度,输出为视听融合特征。具体融合过程如图7(a)所示。
为了进一步增强模型拟合性能,充分利用不同模态的相互关系。在SCMA基础上,采用多头注意力跨模态融合(multip le Head Cross-M odal A ttention,HCMA),利用多个子空间让模型去关注不同方面的信息,如图7(b)所示。HCMA是将SCMA过程重复进行3次后,再把输出合并起来,输出视听融合特征。由式(7)、式(8)、式(9)、式(11)可得HCMA计算过程
其中,i表 示多头注意力头数,Wi Q,Wi K和Wi V表示权重训练矩阵,Qvmi,Kvmi,Vai分别表示不同子空间下Qvm,Kvm,Va,h eadi表示缩放点积注意力的融合结果。
3 实验结果与分析
3.1 数据集
AVSpeech数据集中语音长度在3~10 s,在每个片段中,视频中唯一可见的面孔和原声带中唯一可以听到的声音属于一个说话人。该数据集包含了约4 700 h的视频片段,大约有150 000个不同的说话者,跨越了各种各样不同性别的人、语音和面部姿态。
干净的语音剪辑来自AVSpeech数据集,从数据集中不同长度的片段中截取3 s不重叠的语音片段,对于视频剪辑也是来自AVSpeech数据集,同样截取与音频时间相对应的时长为3 s的视频段,本次实验随机选取1 000个干净语音,然后按照每3个语音混合的方法,生成混合的语音数据库,再从此混合语音中选取20 000个可懂度相当的混合语音作为本次实验的数据集,其中90%作为训练集,剩余的10%作为测试集。本文利用的混合语音按如式(19)的方式生成,公式为
其中,A VSi,A VSj和A VSk是来自AVSpeech数据集的不同源视频的干净语音;M ix为生成的混合音频。
3.2 实验配置及分离性能评价
(1)实验配置。本文提出的跨模态融合F low-AVSS网络,是用Pytorch工具包实现。通过Farneback算法计算唇部区域内的光流,唇部数据和音频数据的处理基于文献[15],并对训练数据进行预处理。使用权重衰减为10-2的AdamW作为网络优化器,初始学习速率为10-4,并且每次迭代以8×104将学习速率减半。实验设备采用处理器In tel(R)Core(TM)i7-9700 CPU@3.00 GHz,安装内存32GB,操作系统64位W indows10,GPU型号GEFORCE RTX2080 Ti,实验在GPU模式下运行,1次训练所抓取的数据样本量为8。
(2)分离性能评价。常用于评估语音分离效果的指标有3种:客观语音质量评估(Percep tua l Evaluation of Speech Quality,PESQ)[26]指标,衡量语音的感知能力;短时客观可懂度(Short-T im e Objective Intelligibility,STOI)[27]指标,衡量分离语音的可懂度;源失真比(Signal-to-Distortion Ratio,SDR)[28]指标,衡量语音的分离能力。本文利用上述3种评价指标,对提出的跨模态融合光流-视听语音分离模型进行性能评估。
3.3 结果分析
(1)为了分析跨模态融合的Flow-AVSS网络性能,利用SDR,PESQ及STOI评价语音分离效果,结果如表1所示。表1中,为了简化表达,唇部网络、运动网络分别缩写为Lip,Flow。Lip+Flow+特征拼接表示加入运动特征后,采用特征拼接方法的网络结构,Lip+Flow+SCMA表示加入运动特征后,采用缩放点积注意力跨模态融合的网络结构,Lip+Flow+HCMA表示加入运动特征后,采用多头注意力跨模态融合的网络结构。
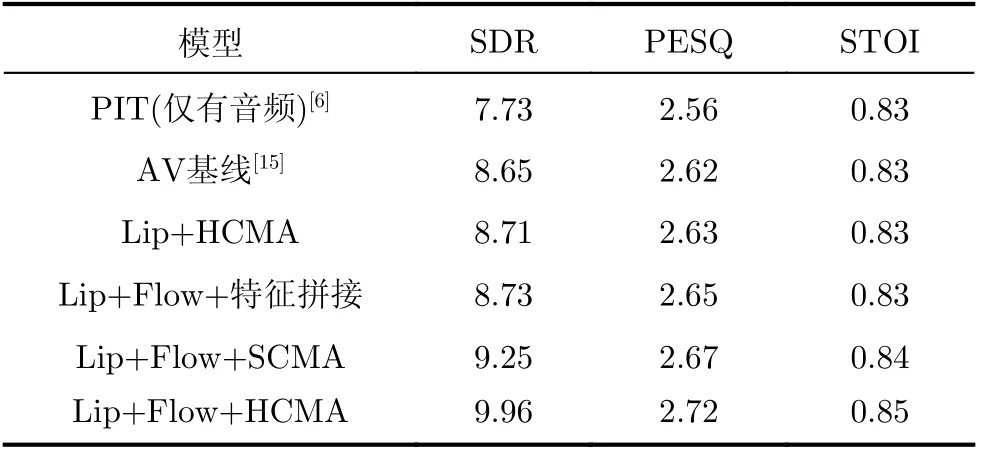
表1 语音分离的性能评估(dB)
由表1可知,Lip+Flow+特征拼接的SDR值为8.73,相比于AV基线未加光流的SDR提升了0.8 dB,说明加入光流后,提高了视觉特征鲁棒性,有效提高视听语音分离性能。Lip+Flow+SCMA,Lip+Flow+HCMA的SDR值分别为9.25 dB,9.96 dB,相比L ip+F low+特征拼接,SDR分别提高了0.52 dB,1.23 dB,说明采用跨模态注意力,相比特征拼接,能更好地利用不同模态之间相互关系,得到更理想的视听特征。Lip+Flow+HCMA的SDR值为9.96 dB,相比Lip+Flow+SCMA,SDR提高了0.71 dB,多头注意力中利用了多个学习Q,K,V的权重矩阵,该权重矩阵是独立地随机初始化,然后将输入的视觉特征映射到不同的子空间,从而获得更多与音频特征关联性强的视觉信息,通过对SCMA单次结果的累加降维,最终获得视觉信息利用率更高的视听特征,获得了更好的分离性能。
(2)由于测试集、服务器配置等不同,评价结果也不同,为了提高对比的准确性。利用本实验室服务器的配置环境,在本文测试集下对文献[29]、文献[14]、文献[15]和文献[16]进行复现,并于Lip+F low+SCM A和Lip+F low+HCMA进行对比,结果如表2所示。
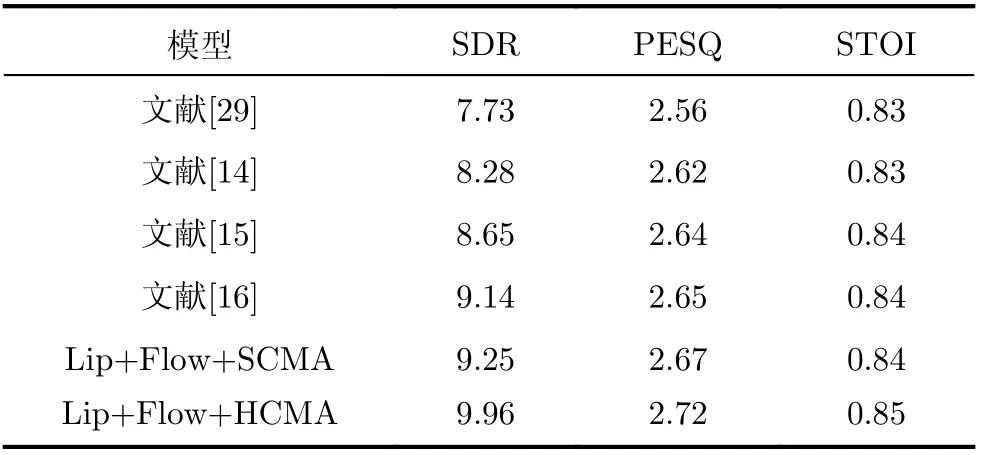
表2 同一数据集、服务器下不同模型分离结果(dB)
由表2可知,采用多头注意力跨模态融合Flow-AVSS,相比较文献[29]纯语音分离、文献[14]视听语音分离、文献[15]和文献[16]跨模态融合视听语音分离,SDR分别提升了2.23 dB,1.68 dB,1.31 dB和0.82 dB。
4 结论
本文针对单通道语音分离,提出一种基于Farneback算法和跨模态注意力融合的视听语音分离模型。采用Farneback稠密光流算法,提取唇部的运动特征,可以有效提高视觉特征的鲁棒性。采用跨模态注意力进行视听特征融合,可以充分利用音频流和视频流之间的相关性。实验结果表明,本文提出的跨模态注意力融合的光流-视听语音分离网络在SDR,PESQ和STOI 3个指标上,都优于纯语音分离和采用特征拼接的视听语音分离网络。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小资CHIC!ELEGANCE(2020年2期)2020-03-10
保健与生活(2020年3期)2020-03-02
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电光与控制(2018年10期)2018-10-13
实用口腔医学杂志(2017年6期)2017-09-19
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
中国铁道科学(2014年6期)2014-06-21
