
基于EEMD-SVM模型的边坡变形预测
2023-11-17 01:36李建新
广东水利水电 2023年10期
李建新,肖 钢,唐 铃
(1.东莞市地理信息与规划编制研究中心,广东 东莞 523000;2.赣州市国土空间调查规划研究中心,江西 赣州 341000)
1 概述
边坡是自然或人工开挖形成的,也是工程建设中最常见的工程形式,而边坡失稳造成的滑坡时有发生,造成严重的经济损失与人员伤亡[1]。实际上,滑坡灾害的发生并不是一蹴而就,而是边坡变形达到一定程度的结果。如果及时建立了基于边坡变形监测数据的高精度预测模型,准确识别边坡变形趋势,一定程度上可以避免灾害的发生。因此,建立高精度的边坡变形预测模型是必要的,具有重要的社会价值和经济价值。
边坡变形过程复杂,不仅受到地质条件的控制,还受到其他因素的影响,包括地下水、降雨量和人工活动等,难以通过传统方法建立高精度的边坡变形预测模型[2]。随着近些年来机器学习的不断发展,BP神经网络、支持向量机(SVM)和极限学习机等方法广泛应用于边坡变形预测[3-8]。SVM是Vapnik基于统计学习理论提出的一种机器学习方法[9],对于非线性、小样本等问题具有较好的预测精度。研究表明SVM模型应用于边坡或滑坡其他领域同样具有较高的精度,具有很好的适应性[10-11]。
边坡变形监测过程中受到多种因素的干扰,导致监测数据中存在噪声,进而影响预测精度。近些年来基于集成经验模态分解(EEMD)的去噪方法逐渐应用在各个领域,结果表明EEMD能够作为一种有效的去噪方法[12-13]。EEMD 方法的最大优点在于其能够以自适应方式提取信号的各个分量和变化趋势。同时,相较于经验模态分解方法,EEMD 方法显著减少了模态混叠现象,并且也克服了小波变换容易造成许多虚假谐波。简而言之,EEMD 方法是一种高效的信号处理方法,能够更加准确地提取出信号中的各种信息。因此通过EEMD方法去除边坡变形数据中的噪声,使得SVM模型能够更精确的识别边坡的变形趋势,提高边坡变形的预测精度。
本文提出一种由EEMD去噪和SVM组合而成的预测模型,以提高边坡变形预测的精度。模型首先通过集成经验模态分解(EEMD)算法将边坡变形时间序列进行分解,基于相关系数的计算去除噪声后重构边坡变形时间序列,然后将重构后的边坡变形时间序列作为SVM模型的输入,从而建立EEMD-SVM模型,既而预测边坡变形值。
2 模型理论
2.1 集成经验模态分解(EEMD)
经验模态分解(EMD)是一种能够将非平稳和非线性时间序列自适应的分解为IMFs分量的方法,而不需像小波分解、傅里叶变换等方法那样需要提供先验知识。但是传统EMD方法存在模态混叠的问题,为了克服这个问题,Wu等[14]在EMD的基础上加入噪声辅助,称为集成经验模态分解(EEMD)。EEMD先将白噪声添加到原始数据信号中,为时频空间提供一个统一的参考框架,再对添加了白噪声的数据进行EMD分解,重复足够数量的实验,最后将多次分解得到的同频率的IMF分量求平均作为最终的IMF分量。由于添加的白噪声零均值的特性,经过整体平均计算后能够消除白噪声对最终IMFs分量的影响。
EEMD算法具体计算步骤如下。
1)假设原始时间序列数据为x(t),将白噪声nj(t)添加到原始时间序列当中:
xj(t)=x(t)+nj(t)j=1,2,…,M
(1)
式中:
xj(t)——第j次实验已经添加白噪声的数据;
M——最大实验次数。
2)在第j次实验中,通过EMD将添加了白噪声的数据xj(t)分解为若干个IMF:
(2)
式中:
ci,j(t)——第j次实验分解出的第i个IMF分量;
rj(t)——第j次实验分解得到的残差分量;
N——每次实验分解得到的IMF数量。
3)重复步骤(1)和(2),直至达到最大实验次数,最终分解结果通过式(3)和(4)作整体平均所得:
(3)
(4)

2.2 支持向量机(SVM)
SVM通过引入核函数将输入数据映射到高维特征空间,从而将非线性问题转化为线性问题,并且通过核函数避免了高维特征空间中的点积运算。SVM的目标函数为:
y=w·φ(x)+b
(5)
式中:
x——SVM的输入,可以是多维数据;
y——SVM的输出;
w——权重向量;
b——偏置常数;
φ(x)——非线性映射函数。
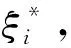
(6)
式中:
ε——训练时回归函数允许误差;
C——惩罚系数,C值越大对训练误差大于ε的样本的惩罚越大。
二次优化问题通常建立拉格朗日方程,对方程求参数偏导,且根据KKT条件偏导数为0,代回原方程可得对偶优化问题,通过SMO算法或者其他二次规划算法可得支持向量回归机预测模型:
(7)
式中:

n——样本个数;
K(xi,x)——核函数,常用核函数为径向基核函数。
采用核函数进行预测时,核参数和惩罚参数对算法的表现起着非常重要的作用,核参数的值太小(0.1~1)或惩罚参数的C值太大会对训练集造成过学习现象,核参数的值太大(100~100 000)或c值太小(0.1~10)则会对训练集造成欠学习现象。本文通过粒子群寻优算法对核参数和惩罚参数进行寻优。
2.3 模型评价指标
本文引用3个统计量来评估模型的预测精度,分别为平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE),定义如下:
(8)
(9)
(10)
式中:

n——测试集样本数目。
3 边坡变形预测模型构建
本文首先通过EEMD算法去除边坡监测数据中的噪声,将去噪之后的变形数据作为SVM模型的输入,建立EEMD-SVM模型。在EEMD去噪过程中,EEMD分解会产生若干分量和残差序列,计算各个分量与原始数据的相关系数,将相关系数较小的分量当作噪声直接去除,重构剩余分量生成无噪声的边坡变形数据。对于EEMD-SVM模型,核函数采用径向基核函数,为了提高模型的训练速度,将去噪后的边坡变形数据归一化到[0,1]区间:
(11)
式中:
xi——去噪后的边坡变形值;
xmax——去噪后的边坡变形最大值;
xmin——去噪后的边坡变形最小值;
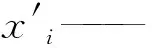
图1给出了构建边坡变形预测模型的流程,详细步骤如下:

图1 EEMD-SVM模型流程示意
1)将边坡变形时间序列划分为训练样本集和测试样本集,对训练样本集进行EEMD分解,得到若干分量和残差序列。根据Wu等[12]的推荐,加入噪声的标准差应为原始数据标准的0.2倍,最大实验次数为100。
2)分别计算各分量和残差序列与边坡变形时间序列的相关系数。
3)将相关系数小于0.2的分量作为噪声直接去除,重构剩余分量得到无噪声边坡变形时间序列。
4)将通过去噪后重构的边坡变形时间序列作为SVM模型的输入,并对SVM模型进行训练,并且预测未来边坡变形值。
5)根据测试样本集的边坡变形实测值,通过式(8)~(10)评价EEMD-SVM模型的预测精度。
4 工程实例
溪洛渡水电站是金沙江下游河段梯级开发规划的第3个梯级,是一座以发电为主,兼有防洪、拦沙和改善下游航运等综合利用效益的特大型水利水电枢纽工程。工程枢纽位于四川省雷波县和云南省永善县接壤的金沙江溪洛渡峡谷。水库正常蓄水位为600 m,死水位为540 m,汛期限制水位为560 m,总库容为126.7亿m3,调节库容为64.6亿m3。水库在蓄水过程及运行过程中,由于库水位的动态变化使库岸边坡地质结构遭受强烈改造,从而可能导致滑坡灾害,带来严重后果。
为了保障水电站的正常运行,建立了溪洛渡水电站水库安全监测系统,系统通过GNSS技术监测了水库长达199 km的库岸边坡。本文以花坪子边坡的TP02-HPZ监测点为例,收集到2018年1月1日至2018年4月30日的边坡变形数据,总共120期数据,前110期为训练样本,后10期为测试样本。
将训练样本通过EEMD算法进行分解,加入的噪声标准差为原始边坡序列的0.2倍,最大实验次数设置为100,图2给出了训练样本的EEMD分解结果。其中,第1行至第5行分别为分解后的分量IMF1~IMF5,反映了从高频到低频不同时间尺度的边坡变形波动特征,并且相对于原始的时间数据序列变化较为平稳,第7行为剩余分量。表1也给出了各分量与原始数据的Pearson相关系数,由表1可知,IMF1、IMF2和 IMF3分量与原始数据相关系数均低于0.2,并且不具有显著性,说明这3个分量的变化趋势与原始数据存在较大差异,可以将其当作噪声直接剔除。而IMF4、IMF5和Residual分量与原始数据都存在显著相关性,其中IMF5和Residual分量相关系数均在0.7以上,说明原始边坡变形趋势主要是由这3个分量组成的。图3给出了剩下的IMF4、IMF5和Residual分量重构得到的去噪后的边坡变形时间序列,可以看出去噪后的边坡变形时间序列更加平滑,能够更加准确的描述边坡的真实变形趋势,为SVM模型准确识别边坡变形趋势奠定了基础。

图2 训练样本EEMD分解结果示意

表1 各分量与原始数据的Pearson相关系数

图3 去噪后的边坡变形时间序列示意
为了证明EEMD-SVM模型的有效性,引入SVM、BP神经网络(BP)和EEMD-BP模型作为对比。其中SVM和BP模型将原始边坡变形时间序列作为输入,而EEMD-SVM和EEMD-BP模型均采用去噪后的边坡变形时间序列作为输入。图4给出了4种模型的预测结果,为了更加直观详细了解每个时刻的预测误差情况,表2给出了4种模型的预测值。由表2可以看出,EEMD-SVM模型预测结果更加接近真实值,相较于其他3种模型,预测误差主要集中在0.2以下。
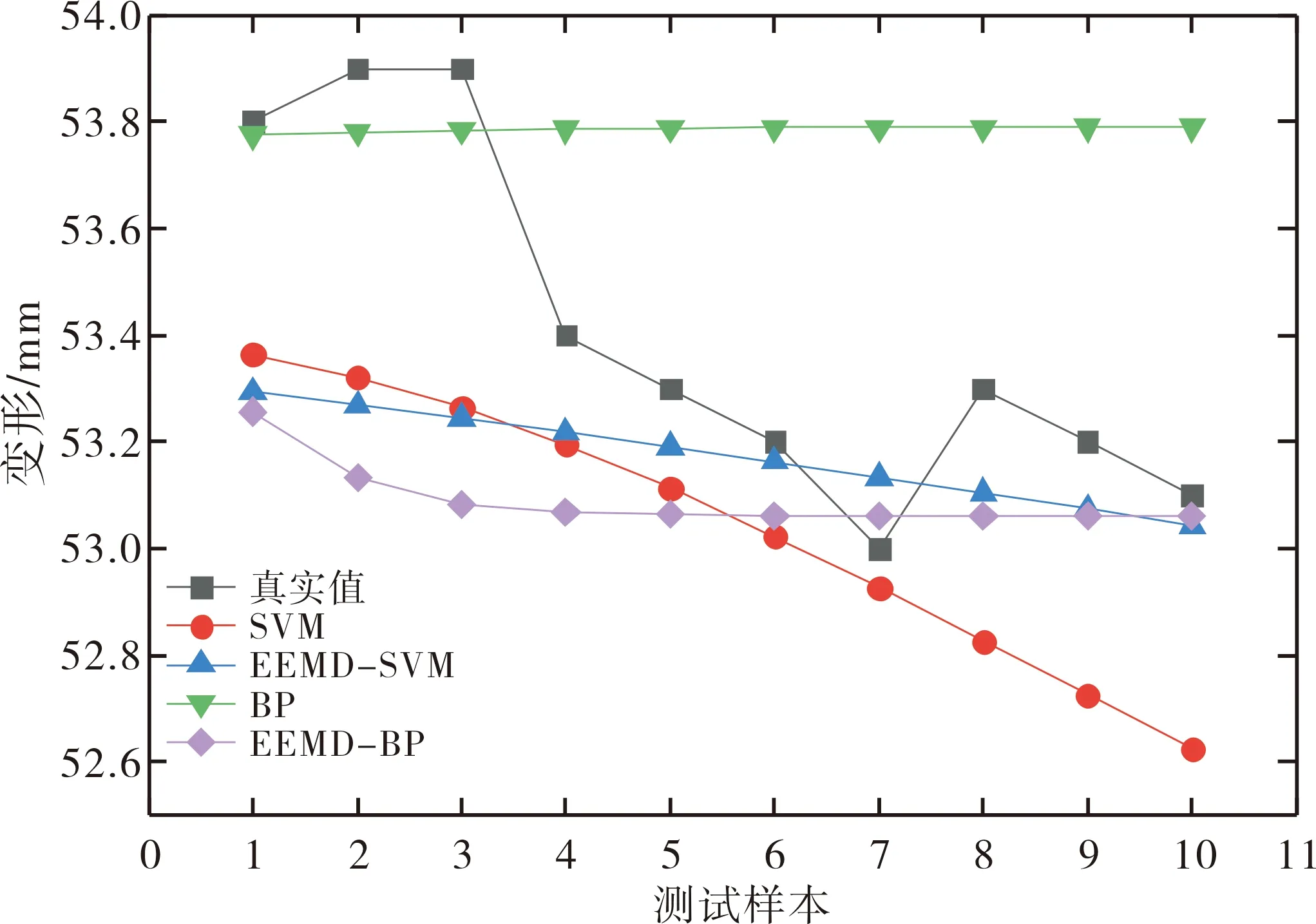
图4 模型预测结果示意

表2 模型预测值
表3给出了4种模型的预测精度。预测精度选用平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE)这3种评价指标对预测精度进行分析。由表3可以看出,SVM和EEMD-SVM模型的预测精度分别优于BP和EEMD-BP模型,说明SVM模型相较于BP模型更适合边坡变形预测。而EEMD-SVM和EEMD-BP模型的预测精度分别优于SVM和BP模型,表明EEMD去噪算法可以消除边坡变形数据的噪声,提取出更准确的边坡变形值。其中EEMD-SVM模型的3个精度评价指标均是最小的,相较于传统SVM模型,MAE、MAPE和RMSE由0.371、0.694和0.414分别降到了0.263、0.491和0.347,MAE降低了29.1%,模型预测精度有着明显提升。

表3 模型预测精度
4 结语
1)边坡的变形预测对于及时掌握边坡的变形趋势是至关重要的,本文通过将支持向量机与集成经验模态分解方法结合,建立了可用于边坡变形预测的EEMD-SVM模型。工程实例表明,EEMD-SVM模型具有较高的预测精度,可以为类似工程提供一种边坡变形预测的参考方法。
2)在边坡变形数据采集过程中,误差是不可避免的,EEMD算法能够将边坡变形时间序列进行分解,消除无关分量,得到的去噪边坡变形时间序列更加平稳,变化趋势更加清晰,能够有效应用于边坡变形预测。
3)传统的神经网络模型在小样本预测时能力有限,而支持向量机模型预测精度更高,模型运行也更简单。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
基层中医药(2021年12期)2021-06-05
物联网技术(2020年12期)2021-01-27
英美文学研究论丛(2018年1期)2018-08-16
汽车零部件(2017年4期)2017-07-12
纺织科学研究(2017年6期)2017-07-03
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
电测与仪表(2014年23期)2014-04-04
计算物理(2014年2期)2014-03-11
