
细粒度视觉分类:深度成对特征对比交互算法
2023-11-16 00:51郭鑫平
计算机与生活 2023年11期
汪 敏,赵 鹏,郭鑫平,闵 帆
1.西南石油大学 电气信息学院,成都 610500
2.西南石油大学 计算机科学学院,成都 610500
3.西南石油大学 人工智能研究所,成都 610500
卷积神经网络(convolutional neural network,CNN)在视觉识别领域取得了巨大的成功[1-2]。细粒度视觉分类(fine-grained visual categorization,FGVC)旨在识别各种特定类别的子类别,如不同种类的鸟、狗、飞机以及汽车等[3]。由姿势、视角、光照、遮挡和背景干扰引起的高类内和低类间视觉差异使细粒度图像分类成为一项极具挑战性的任务[4]。将普通图像识别领域性能优越的经典CNN模型直接应用于细粒度图像识别会导致模型性能的显著下降[5]。图1举例给出了普通图像识别与细粒度识别的区别。图1(a)展示了普通图像识别问题。通常的图像识别,是为了区分不同的大类,类别之间存在显著差异。因此经典CNN模型能够取得优异性能。图1(b)展示了细粒度图像识别。其中赫尔曼海鸥、灰背鸥、银鸥以及加州海鸥均属于鸟类这一大类。然而,它们分属于不同的子类别,类别之间具有极其相似的外部特征。这给CNN模型识别带来了巨大挑战。

图1 普通图像识别与细粒度图像识别的区别Fig.1 Difference between ordinary image recognition and fine-grained image recognition
深度FGVC 方法主要分为强监督方法和弱监督方法。强监督方法采用额外的人工标注信息,如目标边界框和特殊部位关键点,来获取目标物体的空间位置和细微差异。Zhang等人[6]通过使用特殊部位标注信息对小语义信息进行建模,并在分类子网络中引入新的部件语义信息,完成多个语义部分的定位和整个对象的识别。Krause 等人[7]设计了基于共同分割和对齐的细粒度识别网络,虽然不需要使用部分注释,但依据目标对象标注框所训练的模型具有更好的识别效果。Wang等人[8]构建了一个基于补丁关系的网络结构,通过三元组建模具有区分性的语义信息,并自动挖掘具有区别的三元组信息进行分类。
虽然借助差异性的部件标注信息,通过精细设计挖掘差异信息的网络结构,可以实现更高精度的分类性能,但人工标注成本昂贵,不符合现实研究以及工业应用的需求。因此仅使用类别标签的弱监督方法成为近年来研究的新趋势。Lin等人[9]设计了一种双线性的CNN模型,通过两个子网络相互协作,完成图像的差异性特征提取和区域定位,最后将两种特征经过外积的形式联合用于细粒度分类。Ji等人[10]提出了一种注意力神经网络的树结构模型,通过树结构对细粒度特征由粗到细进行差异性建模,以实现更优性能的分类。Zhang 等人[11]构建了一个多尺度三支网络,将原始图像经过定位和拆分,生成更细微更具判别力的补丁,有效提升了经典网络的识别性能,但相应的模型结构也更复杂。此外,Chen等人[12]提出了基于图像拼接方法对补丁间关系进行建模的破坏构建学习(destruction and construction learning,DCL)。Yang 等人[13]提出了基于自我监督机制的导航学习网络(navigator-teacher-scrutinizer neural network,NTS-Net)等。这些方法均显著提升了经典CNN 模型在细粒度识别领域的性能,但伴随而至的是网络模型更复杂,所需的训练成本更高。
鉴于以上分析,由于细粒度图像类间信息差异小而类内信息差异大,现有一些方法仅使用单输入单输出的模式无法挖掘更具差异的信息部位以及更具代表性的公共特征,进而影响模型的分类性能。因此,提出了一种深度成对特征对比交互算法(deep pairwise feature contrast interactive fine-grained classification,PCI)。
首先,PCI 构建了正对和负对输入,基于典型CNN模型提取深度成对细粒度特征。成对细粒度深度特征之间包含共同、差异特征。
其次,建立深度成对特征交互机制。通过成对特征的全局信息学习、深度对比、深度自适应交互提取特征对之间的共同、差异特征,实现正对共同特征、负对差异特征的自适应交互学习。
最后,建立成对特征对比学习机制,用对比损失约束正对、负对特征之间的相似性,增大正对之间的相似性并减小负对之间的相似性。以此解决细粒度图像类内方差大、类间方差小的难题。
本文的主要贡献包括以下三方面:
(1)设计双输入双输出的网络结构,建立了对比机制、特征自适应学习策略,依据成对图像对比推理,显著提升模型细粒度识别能力。
(2)构建正负对学习策略,设计成对细粒度对比损失函数,以对比学习的方式解决细粒度图像类内方差大而类间方差小的问题。
(3)在具有挑战性的细粒度数据集CUB-200-2011、Stanford Dogs、Stanford Cars 和FGVC-Aircraft上与近年来20 种顶会论文算法对比,对比结果表明了所提方法的先进性与有效性。
1 相关工作
1.1 细粒度图像分类
FGVC旨在实现更精细化的子类之间的区分,是一项极具挑战性的研究课题。在其发展过程中,根据有无使用更加精细的标注(边界框或特殊关键点等)将FGVC方法分为强监督方法和弱监督方法。强监督方法使用额外的人工标注信息使CNN模型关注类别之间更加细致的差异,从而提升模型的识别能力。经典的强监督学习方法包括基于部分区域的卷积神经网络(part-based region-based convolutional neural network,Part-based R-CNN)[14]、全卷积注意力定位网络(fully convolutional attention localization network,FCAN)[15]、姿势归一化卷积神经网络(pose normalized deep convolutional nets,PN-CNN)[16]、部分堆叠卷积神经网络(part-stacked convolutional neural network,Part-Stacked CNN)[17]等。其中,Part-based R-CNN[14]采取的方式为构造一个全局特征检测器和一个局部特征检测器,通过对局部特征检测器施加更加精细的标注以强制使CNN 关注类别之间细微的差异特征。FCAN[15]则提出了一种强化学习框架,可优化适应不同细粒度域的局部判别区域。PN-CNN[16]提出了更接近于人类专家系统的神经架构,首先利用网络估计出目标的边界信息,依据边界对局部语义信息进行整合分类。Part-stacked CNN[17]构建了部分堆叠的CNN架构,建模与对象部分的细微差异,明确解释了细粒度识别过程。然而,精细标注导致的昂贵标签代价阻碍了强监督方法的适用性。
弱监督方法仅依靠类别标签进行分类,这是近年来的主要趋势。Gao 等人[18]通过自通道交互(selfchannel interaction,SCI)和对比通道交互(contrastive channel interaction,CCI)两个模块挖掘特征通道间的互补信息和差异信息,其中SCI模块用于挖掘自身通道间特征信息并进行加权,CCI模块用于挖掘差异通道间的信息并进行加权判断。Chang 等人[19]设计了互通道损失充分挖掘通道特征的多样性和差异性,通过将通道特征划分成属于不同类别的特征组,并施加多样性约束以定位细微差异特征。Zhang等人[20]通过结合专家系统解决细粒度分类问题,通过引入约束使专家产生不同的预测分布,从而迫使模型关注不同的细粒度特征。Xu等人[21]建立空间注意力机制使模型注意更具差异性和信息量的区域。
1.2 对比学习
对比学习的基本思想是将原始数据映射到一个特征空间中,其中正对的相似性最大化,而负对的相似性最小化[22]。其作为一种无监督的手段,被广泛应用于表示学习[23]。其中正对和负对的构建方式也不尽相同。Sharma等人[24]使用聚类的结果作为伪标签来构建正对与负对。更为简单的方法是直接利用数据增强的方法来构建数据对,即正对由同一张图像的两种不同的数据增强方式构成,除此之外都为负对[25]。在三元组损失中通过设置锚点,最小化锚点与正对的距离,同时最大化锚点与负对的距离。对比损失极大优化了特征表示的结果[26]。
最近的对比学习被应用于深度图像聚类任务。Li等人[27]将对比学习引入了无监督聚类任务,通过在特征级向量上施加对比损失增大正对间的相似性同时减小负对间的相似性。Dang等人[28]根据深度特征矩阵行与列不同的性质差异设计了双重对比学习进行深度聚类。通过对行与列施加对比学习,深度模型可以自适应地将正对拉近,而将负对推开。
从人类深度对比细粒度图像的视角出发,本文创新性地设计了双输入双输出网络模型,提出了成对对比约束损失,构建了正负对深度特征构建、深度特征成对交互以及成对特征对比策略。
2 网络框架
2.1 问题定义
将单个图像实例对象表示为,i∈[1,n],p∈Y表示实例所属类别,训练集与测试集具有相同的类别Y={1,2,…,k},n为训练集样本总数。骨干CNN模型用f(∙)表示,f(∙)由L层卷积层和一个全连接层组成,即f(∙)的深度为L。将实例经过f(∙)的卷积层后输出的深度特征用∈RC×H×W表示,C、H、W分别表示深度特征的通道数量、高和宽。f(∙)中第l层输出的深度特征表示为。fl(∙)表示f(∙)第l层卷积层,1 ≤l≤L。将经过f(∙)的输出预测标签用y∈Y表示,将真实标签用y*∈Y表示。
2.2 网络框架概述
PCI网络结构由正负对构建及深度特征提取、深度成对特征对比交互、成对特征对比学习三部分组成。图2展示了网络的总体框架。
正负对构建及深度特征提取由正负对构建、成对深度特征提取两部分组成。正负对构建保证输入包含同类组成的正对和异类组成的负对。这使模型能同时学习同类对之间的共同特征和异类对之间的差异特征。详细的正负对构建以及成对深度特征提取过程见3.1节。
深度成对特征对比交互模拟人类深度对比交互的过程。它由全局信息向量学习、门向量学习、深度成对特征交互三部分组成。全局信息向量融合了成对特征的全局信息。门向量学习对比了成对特征的共同、差异特征。深度成对特征交互利用门向量所学习的对比信息自适应交互正负对深度特征。详细的深度成对特征对比交互过程见3.2节。
成对特征对比学习对深度交互后的特征施加对比约束,从特征映射角度增大正对特征的相似性和减小负对特征的相似性。其能够与深度成对特征对比交互有机结合,增强模型的泛化性能。详细的成对特征对比学习见3.3节。
3 深度成对特征对比交互算法
本章将详细介绍正负对构建以及深度特征提取、深度成对特征对比交互、成对特征对比学习三个模块。
3.1 正负对构建以及深度特征提取
将来自于同类的两张图像定义为正对,将来自于不同类的两张图像定义为负对,即:
其中,p与q分别表示样本属于第p类和第q类,n为训练集样本总数。
将图像对(,)输入深度为L层的CNN 模型f(∙),经过每一层卷积,会生成对应层的深度特征。将第l层卷积层输出的深度特征表示为RC×H×W,即:
其中,fl(∙)表示f(∙)的第l层卷积层,C、H、W分别表示深度特征的通道数量、高和宽。该对特征将用于深度成对特征对比交互,模仿人类深度对比成对图像的过程。
3.2 深度成对特征对比交互
本节将阐述深度成对特征对比交互的过程,其分为三部分,包括全局信息向量学习、门向量学习、深度成对特征交互。
(1)全局信息向量学习:全局信息向量将成对特征的信息融合为一个特征向量,并映射到高维特征空间。
其中,MLP(∙)为一个两层神经网络映射函数(multilayer perceptron,MLP)。目的是将全局信息向量映射到更高维度的向量空间作为全局信息的通道表示。全局信息向量M是从图像对所提取的特征中自适应学习并映射,它融合了两者特征的通道信息。这有效借鉴了人类的行为,在对比判断过程中会同时接受两张图像信息。
(2)差异性门向量生成:差异性门向量为全局信息向量与自信息向量通过对比的方式生成。它包含了成对深度特征对比后的特征信息,具有细粒度特征选择性。
基于获得的全局信息向量M,PCI 继续模仿人类的行为,深度对比两张图像的异同。即PCI将所学得的全局信息向量M分别与代表各自特征的自信息向量进行对比。受注意力交互网络(attentive pairwise interaction network,API-Net)[5]的启发,本文采用通道乘积的方法进行对比,使全局信息向量M分别与自信息向量相乘,再经过一个Sigmoid(Sig)函数以生成各自的差异性门向量g∈RC,即:
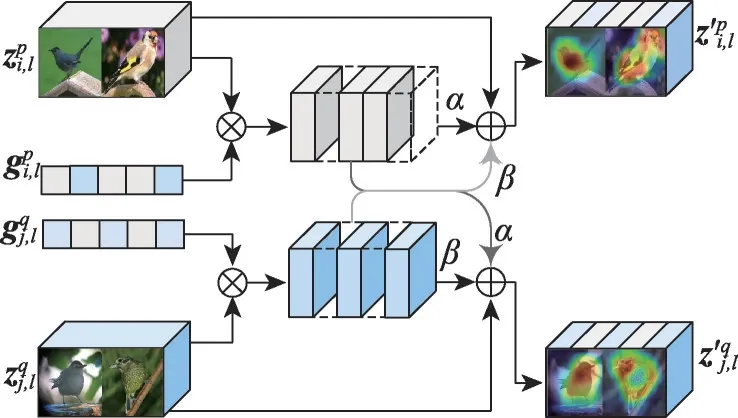
图3 深度特征交互Fig.3 Deep feature interaction
(3)深度特征交互:深度特征交互利用差异性门向量的选择信息,将选择后的对比特征自适应交互,以生成共同或差异特征。深度特征交互过程如图3所示。
首先,门向量为成对深度特征经过对比后自适应产生。它们分别代表了图像对的不同特征信息,将各自的特征通过各自的门向量以选取对比过后的特征,即。
其次,为了将对比选取后的特征信息施加在原特征上进行交互,本文采用了相加求和的方式,这样做可以放大原本的特征信息。但PCI 网络需要同时适应正对与负对两种情况,即在正对的情况下需放大共同特征,在负对情况下需突出差异特征。因此在交互的过程中不能直接相加求和。因此,在交互时引入了两个可训练的参数α和β,并使它们通过Tanh 函数。目的是利用Tanh(T)将两个可训练参数映射到正负数空间。从而模拟正负对完全不同的特征交互方式,使网络在训练过程可以自适应调节这两个参数以同时适应正负对两种情况。成对深层特征交互的过程如式(5)所示:
3.3 成对特征对比学习
考虑深度成对特征交互,模型完成了成对细粒度图像的深度对比。进一步,本文优化损失函数,将对比约束与交叉熵损失有机融合,提升模型分类性能。模型以端到端的方式训练。在正对与负对上施加的对比约束,使正对之间的相似性增大、负对之间的相似性减小。
优化后的总损失函数为:
其中,Lce为分类任务中常用的交叉熵损失函数,λ为可调节超参数,Lcon为对比损失。
sp,q利用余弦相似度衡量了特征对之间的相似性。在网络训练过程中,若成对图像为正对,Lcon会增大正对之间的相似性;若成对图像为负对,Lcon则会减小负对之间的相似性。因此,在分类损失Lce和对比损失Lcon的共同作用下,PCI 会自适应执行深度成对特征对比交互过程,提取差异性的特征或公共特征,从而提高模型的细粒度识别能力。
4 实验结果与分析
4.1 数据集和评价指标
实验数据集:为验证所提出方法PCI 的有效性,在四个最富有挑战性的细粒度数据集上进行了相关实验,即CUB-200-2011[29]、FGVC-Aircraft[30]、Stanford Cars[31]、Stanford Dogs[32]。使用官方的训练和测试划分训练集和测试集,详细的类别信息以及拆分信息统计见表1。
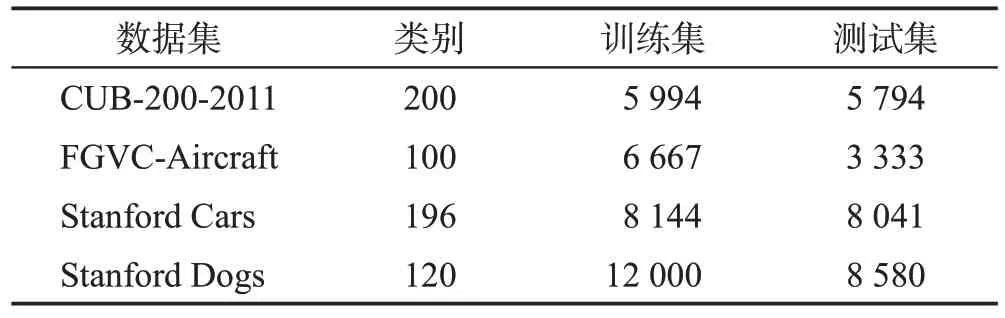
表1 数据集的训练集与测试集信息Table 1 Datasets information of training and testing
实验评价指标:为验证所提出的细粒度分类算法PCI 的性能,采用分类任务中广泛使用的精度(accuracy,Acc)作为评价指标,如式(9)所示:
其中,TP(true positive)表示真实值是Positive,模型认为是Positive 的数量;TN(true negative)表示真实值是Negative,模型认为是Negative 的数量;FP(false positive)表示真实值是Negative,模型认为是Positive 的数量;FN(false negative)表示真实值是Positive,模型认为是Negative的数量。
4.2 训练和测试
(1)训练:采用在ImageNet[33]数据集上预训练的残差网络(residual network,ResNet)[34]作为骨干网络。在训练时,每次从训练集中随机采样N个类别,每个类别采样2 张图像,每批次组成批量即Batch-Size=2N的训练数据,按照3.1 节中所示的正负对配对的方式进行配对训练并计算对比损失和交叉熵损失。使用反事实注意力学习(counterfactual attention learning,CAL)[35]中建议的弱监督数据增强方法,即首先将原始图像缩放为512×512,再使用随机裁剪将图像裁剪为448×448 大小,并使用随机反转以增强数据。采用随机梯度下降(stochastic gradient descent,SGD)优化器。SGD 的初始学习率为0.001,动量为0.9,权重衰减为5E-4。此外,采用余弦下降方法调整学习率,在整个训练过程仅使用类别标签。
(2)测试:表2 和表3 中shuffle=True 和shuffle=False表示同一模型在两种不同配对方式下的测试结果。PCI为双输入双输出的网络结构,在测试集上进行两种配对方式的测试以验证其性能。第一种为随机打乱整个测试数据集,即在加载数据集的时候将shuffle设置为True,此时整个数据集的配对方式完全随机。第二种为不打乱测试数据集,使用测试数据集默认的顺序进行测试,即在加载数据集的时候将shuffle 设置为False,此时配对方式按照数据集默认的顺序配对,不随机打乱整个数据集。为验证实验结果的准确性,在随机配对测试的时候采取计算10次求均值的方式。
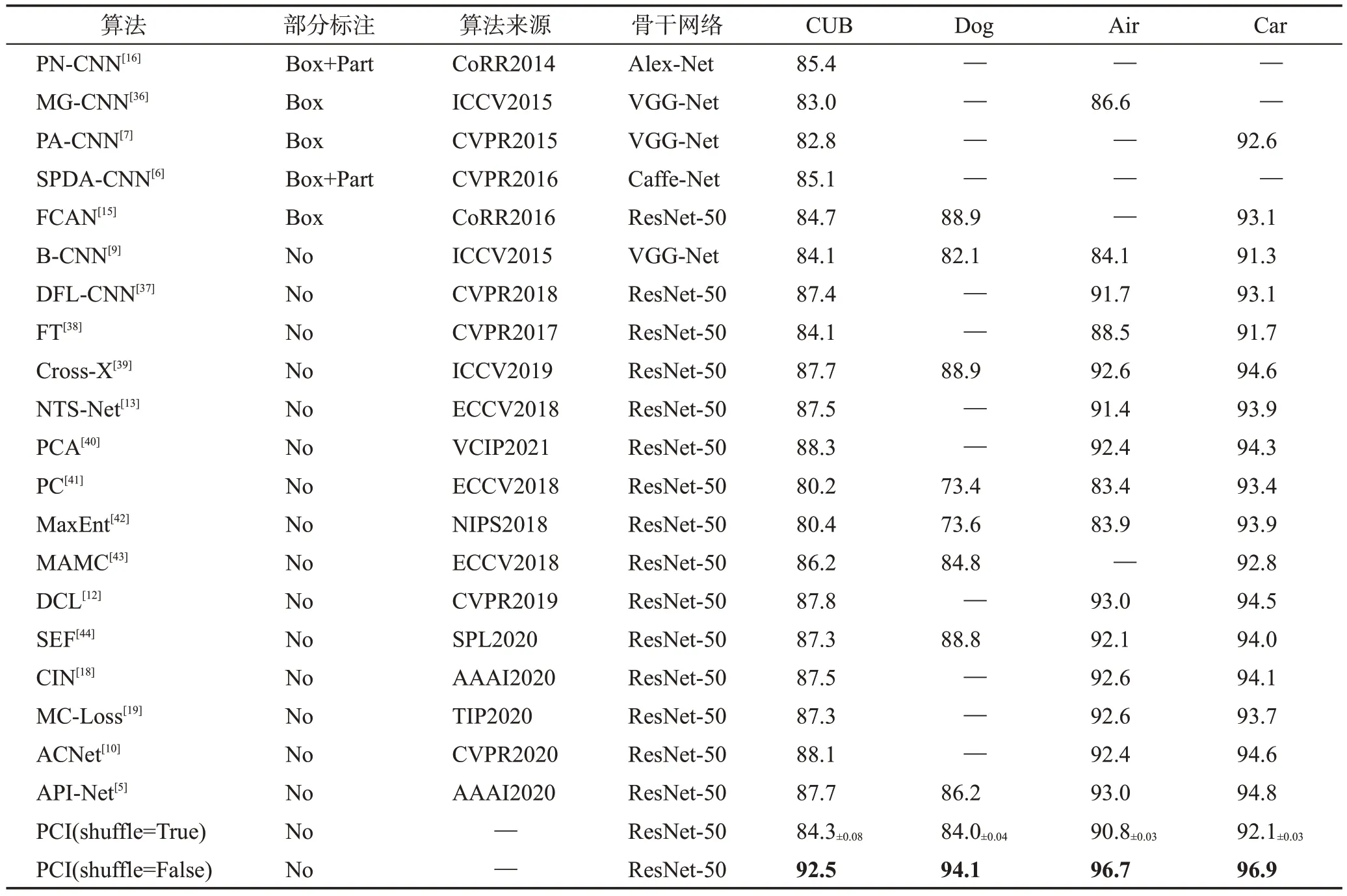
表2 PCI与对比算法在4个数据集上的Top-1分类准确率比较Table 2 Comparison of Top-1 classification accuracy between PCI algorithm and other algorithms on 4 datasets 单位:%
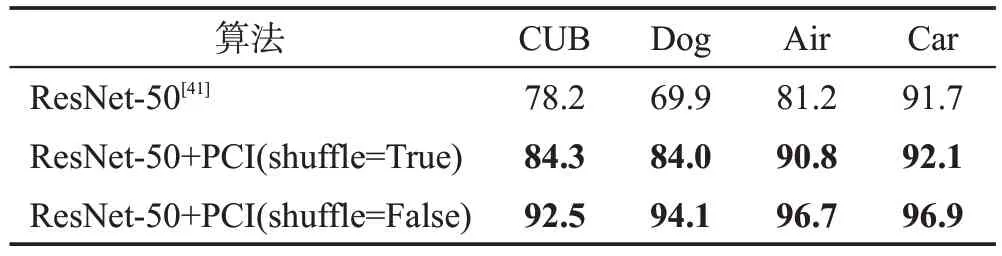
表3 本文算法在4个数据集上的消融实验Table 3 Ablation studies of proposed algorithm on 4 datasets 单位:%
4.3 实验结果及对比分析
(1)对比基线:为验证所提出算法PCI 的有效性和先进性,同时选取了强监督算法和弱监督算法进行对比实验。强监督算法包括SPDA-CNN(semantic part detection and abstraction CNN)[6]、PA-CNN(part annotations CNN)[7]、FCAN(fully convolutional attention localization network)[15]、PN-CNN(pose normalized CNN)[16]、MGCNN(multiple granularity descriptors CNN)[36]等性能优越的算法。弱监督算法包括API-Net(attentive pairwise interaction network)[5]、B-CNN(bilinear CNN)[9]、ACNet(attention convolutional network)[10]、DCL(destruction and construction learning)[12]、NTS-Net(navigatorteacher-scrutinizer neural network)[13]、CIN(channel interaction networks)[18]、MC-Loss(mutual-channel loss)[19]、DFL-CNN(discriminative filter bank CNN)[37]、FT(finetuned)[38]、Cross-X[39]、PCA(progressive co-attention)[40]、PC(pairwise confusion)[41]、Max-Ent(maximumentropy)[42]、MAMC(multi-attention multi-class)[43]和SEF(semantically enhanced feature)[44]等性能优越的算法。
表2展示了所提出的方法PCI在CUB-200-2011、Stanford Dogs、FGVC-Aircraft以及Stanford Cars四个细粒度数据集上的实验结果,其中符号“—”表示当前方法在对应的数据集上未进行实验,表中对比算法结果严格引用自原论文。
从表2 可以看出,shuffle 为True 时,在CUB-200-2011、Stanford Dogs、FGVC-Aircraft 以 及Stanford Cars 数据集上所提出模型PCI 的精度分别为84.3%、84.0%、90.8%、92.1%。在CUB-200-2011 数据集上PCI 的性能超过了强监督算法MG-CNN(↑1.3 个百分点)和PA-CNN(↑1.5个百分点),并超过了弱监督算法PC(↑4.1个百分点)、B-CNN(↑0.2个百分点)、MaxEnt(↑3.9 个百分点)以及FT(↑0.2 个百分点)。在Stanford Dogs 数据集上超过了算法B-CNN(↑1.9个百分点)、PC(↑10.6 个百分点)和MaxEnt(↑10.4个百分点)。在FGVC-Aircraft 数据集上超过了强监督算法MG-CNN(↑4.2 个百分点),弱监督算法BCNN(↑6.7 个百分点)、FT(↑2.3 个百分点)、PC(↑7.4 个百分点)以及MaxEnt(↑6.9 个百分点)。在Stanford Cars 数据集上PCI 测试精度超过了B-CNN(↑0.8个百分点)和FT(↑0.4个百分点)。
从表2 可以看出,shuffle 为False 时,即整个测试集配对按照数据集默认顺序进行。此时,PCI 在CUB-200-2011、Stanford Dogs、FGVC-Aircraft 以及Stanford Cars 数据集上的测试精度分别为92.5%、94.1%、96.7%、96.9%。此时,PCI 在4 个细粒度视觉分类数据集上的测试精度均优于当前最先进的算法。它们分别是在CUB-200-2011 数据集上的PCA(88.3%)、Stanford Dogs数据集上的FCAN(88.9%)和Cross-X(88.9%)、FGVC-Aircraft 数据集上的DCL(93.0%)和API-Net(93.0%)以及Stanford Cars数据集上的API-Net(94.8%)。PCI 此时的精度分别超过了PCA(↑4.2 个百分点)、FCAN(↑5.2 个百分点)和Cross-X(↑5.2 个百分点)、DCL(↑3.7 个百分点)和API-Net(↑3.7个百分点)、API-Net(↑2.1个百分点)。
(2)对不同的强监督细粒度分类算法进行实验分析:所提出PCI算法在两种配对方式的情况下均优于强监督算法PA-CNN[7]以及MG-CNN[36]。例如,在CUB-200-2011 数据集上与PA-CNN[7]相比较,此时PCI的性能在两种情况下分别提高了1.5个百分点和9.7个百分点,具有明显的提升。PA-CNN[7]采用了部分标注框,通过分割和对齐网络设计以促使模型更具竞争力。在FGVC-Aircraft数据集上与MG-CNN[36]相比较,此时PCI 的性能分别提升了4.2 个百分点和10.1 个百分点,具有明显的提升。MG-CNN 采用多分支构建多粒度网络结构,在使用标注框时网络性能更好。与强监督算法比较,PCI的优势在于不使用更精细化的标注而取得更优异的性能,并且不额外增大模型的参数量。PCI在shuffle为True时在Stanford Dogs数据集上的性能弱于FCAN[15],这是因为此时测试集随机进行配对,而不同的对比对象会影响模型的预测性能,从而影响模型提取差异特征的能力。这与人类对比过程一致。如表2所示。
(3)对不同的弱监督细粒度分类算法进行实验分析:所提出方法PCI 在数据集CUB-200-2011、Stanford Dogs、FGVC-Aircraft和Stanford Cars上精度达到最高,分别为92.5%、94.1%、96.7%、96.9%。在CUB-200-2011数据集上与性能最优异的弱监督算法PCA[40]相比,提高了4.2 个百分点。PCA 同样引入了寻找共同特征的机理,并设计注意力擦除模块以促使模型关注更加多样性的特征。在FGVC-Aircraft数据集上与性能最优异的弱监督算法DCL[12]和API-Net[5]相比,提升了3.7个百分点。DCL依据破坏和重建建模图像补丁关系,并引入对抗攻击的思想以学习细粒度特征。API-Net同样从成对图像中学习,但其只对模型最后一层特征做对比约束和交互,这无法在训练过程中有效对比中间层的深度特征,并学习它们之间的关系。另外与多分支网络相比较,如NTSNet[13]虽然不需要使用额外标签,但其在构建具有差异性提取能力的网络时需要多个分支网络进行协同合作,这促使推理模型更大,训练成本增大。而PCI仅需要成对的图像进行深度对比交互学习就可以实现共同特征与差异特征的提取,模型更加简化。如表2所示。
综上分析,实验结果和分析表明所提出的PCI算法能够在细粒度数据集上达到优异的表现性能。所提出的深度成对特征对比交互算法能够显著优化模型的泛化性能,提高模型的细粒度视觉识别能力。
4.4 可视化实验分析
为直观表示PCI 所提取的细粒度图像对之间的细微特征,采用类激活图(Grad-Cam)[45]对特征进行了可视化。可视化对比的基线为ResNet-50[34]和APINet[5]。
从图4 可以看出,ResNet-50、API-Net 以及本文方法PCI 都能定位到目标所在空间位置。但与普通图像识别不同,细粒度图像的目标更加细微,背景更加复杂,同类之间的特征差异更小。这使模型即使定位到目标却不能准确判断目标类别。因此,这时需要模型关注更细微的特征,如同类之间的共同特征,异类之间的差异特征。所提出的算法遵循这一思想,从实验结果和可视化可以看出,本文方法PCI能够更多地关注细粒度图像的共同特征和差异特征。
(1)正对共同特征:正对图像,由于背景与姿势的差异,应使模型关注它们之间的共同特征。图4中第一行和第二行为两对不同的正对图像。从图4 可以看出,API-Net与PCI均比基础ResNet-50关注到更多的共同特征。但API-Net 在背景较为复杂而目标较为精细的情况下不能关注到足够的共同特征。图4(b)第一行中,API-Net 仅关注了鸟的尾部特征,而没有捕捉到鸟的身体特征。图4(b)第二行中,处于飞行和静止中的两张同类鸟的图像,因为姿势和背景的不同使它们的特征具有明显的差异。这时候应该更关注它们之间相同的特征,如红色的嘴、白色的头部等。而API-Net 没有很好地关注到这些共同特征。与之相比,从图4(c)中可以看出,PCI 更多地注意到两幅图像的共同特征,如红色的嘴等。
(2)负对差异特征:对于负对图像,由于类别之间细微的差异,模型应关注它们之间的差异特征。图4 中第三行和第四行为两对不同负对图像。可以看出API-Net 与PCI 都比基础ResNet-50 关注到更多的差异特征。但某些情况下,API-Net没有关注到足够的差异特征,如第三行中鸟的爪子和嘴巴。与之对比,从图4(c)中可以看出,PCI 更多地关注到了差异性特征,爪子和嘴巴等。
4.5 消融实验
(1)PCI 的有效性:表3 详细列出与基础模型ResNet-50[34]相比,引入PCI 算法后,在4 个数据集上都显著提升了基础骨干模型的细粒度识别性能。
shuffle 为True 时,引入PCI 后在CUB-200-2011、Stanford Dogs、FGVC-Aircraft、Stanford Cars 上识别精度分别提升了6.1 个百分点、14.1 个百分点、9.6 个百分点、0.4个百分点。shuffle为False时,引入PCI后在CUB-200-2011、Stanford Dogs、FGVC-Aircraft、Stanford Cars数据集上识别精度分别提升了14.3个百分点、24.2 个百分点、15.5 个百分点、5.2 个百分点。综上分析,消融实验对比结果表明了PCI 的有效性,它显著提升了经典CNN模型在细粒度识别中的性能。
shuffle为False的性能整体上优于为True时的性能,说明图像配对的不同将会影响模型的预测能力,这与人类对比判别一致,不同的对比对象将会产生不同的判断结果。shuffle 为True 时每次的配对都是随机的,此时整个数据集的配对方式主要为负对,模型更多依据提取差异特征进行推理。shuffle为False时每次的配对为默认顺序,此时整个数据集的配对方式主要为正对,模型更多依据提取共同特征进行推理。因此,False时的性能优于True时的性能,说明模型提取共同特征的能力整体上优于提取差异特征的能力。但两种情况下相较于原模型,PCI均带来了性能的提升,因此PCI是有效的。
(2)错误案例分析:在探索配对方式对PCI 性能的影响过程中,对于差异较大的负对,PCI 可以轻易判别正确。然而,对于差异过于细微的类别,PCI 无法有效识别。如图5中13、14类别,人类的肉眼也很难通过对比进行区分。

图5 成对分类错误案例分析Fig.5 Case analysis of pairwise misclassification
图5(a)表明,对于人类肉眼无法辨识的类别,PCI也会发生识别错误。图5(a)这幅图像为负对,但它们之间具有极为相似的外部特征。生物学上它们属于同一种鸟类下面的两个不同分支,它们的真实标签分别为13 和14。但PCI 将第一幅图像预测为14,显然PCI在对比交互的过程中没有区分出这一对图像的细微差异,从而将它们预测为了一类。
图5(b)表明,正对深度对比提取共同特征有利于细粒度图像识别。图5(a)中配对分类错误的图像与它的同类组成正对,从图5(b)中可以发现,PCI 将两幅图像都预测正确,这印证了PCI可以通过深度对比提取更多的共同特征。
图5(c)表明,负对深度对比提取差异特征有利于细粒度图像识别。图5(a)中配对分类错误的图像与另一类与其外观差异较大的图像组成负对。从图5(c)中可以看出,PCI将两幅图像都预测正确。这证明PCI 能够通过对比提取异类之间的差异特征。消融实验的结果验证了PCI深度对比的过程,通过深度对比成对图像的特征从而区分一对细粒度图像。
(3)可解释性推理:PCI 根据人类对比交互过程而设计,因此具有一定的解释能力。在判断一对同类图像,PCI注意到的更多是它们的共同特征。如图4(c)中第二行所示,提取到了共同的鸟嘴和头部等。在判断一对异类图像时,PCI则提取区分于它们的差异特征。如图4(c)中第四行所示,提取到了异类之间具有区分性的鸟嘴和鸟爪等。同样,图5 中,对于同一张图像,在其与差异较小的负对进行同时预测时(图5(a)),此时将其预测为14类,置信度为0.864 9。将其与差距较大的负对进行同时预测时,此时将其预测为13类,置信度为0.922 2(图5(c))。0.864 9的置信度弱于0.922 2,两种不同情况的推理差异说明PCI确实是通过如人类一样进行深度对比来推理的,这反过来解释了模型的判断过程。
5 结束语
受人类会深入对比两张图像的特征进而区分细粒度图像的启发,设计了深度成对特征对比交互算法(PCI),从成对深度特征对比学习的角度解决细粒度图像存在的固有问题,有效提升了细粒度识别精度。
其中,正负对构建模拟了现实中既包含同类对也包含异类对的场景,保证模型输入更合理。深度成对特征对比交互模拟人类深度对比两张细粒度图像的过程,能够有效对比两张图像的共同和差异特征并进行深度的交互。成对特征对比学习对成对图像施加对比约束,和深度成对对比交互过程有机融合,增强模型提取共同特征和差异特征的能力。
未来的研究工作主要包括以下三部分:
(1)进一步优化深度对比交互过程,提高辨别差异更细微特征的能力。
(2)将成对深度对比交互应用于其他图像处理领域,如语义分割和行为识别等。
(3)将深度对比交互过程应用于基于注意力的深度模型,如Transformer。
猜你喜欢
红外技术(2022年11期)2022-11-25
新高考·高一数学(2022年3期)2022-04-28
高技术通讯(2021年1期)2021-03-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电脑与电信(2018年11期)2018-02-16
数学物理学报(2017年5期)2017-11-23
信息安全研究(2016年3期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
