
基于图像局部滤波去噪增强算法的图像语义分割模型
2023-11-14 08:07钱康亮
机械设计与制造工程 2023年10期
钱康亮
(四川三河职业学院工程技术学院,四川 泸州 646200)
图像分割技术[1-3]作为计算机视觉技术的重要分支,现已广泛应用于遥感测绘、辅助医疗、航空宇航等领域。根据研究的角度不同,图像分割可分为几何特征法和深度学习方法。几何特征法主要基于边缘、颜色、区域等几何特征进行分割[4-5]。然而,该方法受限于几何特征的维度,无法大规模推广至其他场景,模型鲁棒性较低。随着深度学习方法不断发展,因其模型具有适应性强、精度高等优势,正推动图像分割技术高速发展。
目前,大量学者对基于深度学习的图像分割技术进行了研究。文献[6]提出一种基于改进多尺度特征学习策略与注意力机制的服装图像分割方法。文献[7]详细介绍了U-Net的网络结构及常用改进方法,并对未来图像分割领域的发展进行了展望。文献[8]提出一种基于循环残差卷积神经网络的图像分割算法。这些文献在不同领域对图像分割技术进行了研究,并针对性地提出了一些改进技术,实现了对图像的有效分割。然而对存在模糊、纹理特征不均匀等问题的复杂图像进行处理时,部分方法精度较低,存在较大的改进空间。为有效改善上述问题,本文提出基于图像局部滤波去噪增强算法的图像语义分割模型。
1 模型建立
为了进一步提高图像分割的准确性和效率,本文提出一种基于去噪和局部增强的图像语义分割模型。模型的总体结构如图1所示。
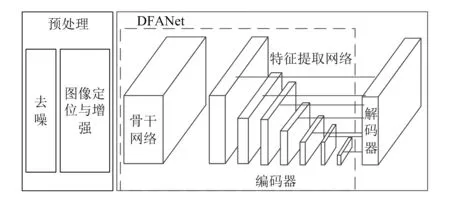
图1 模型的总体结构
首先对图像数据集进行预处理,包括去噪和图像定位与增强。其中,去噪指去除影响分割精度的噪声数据;图像定位与增强指基于非参数定位和增强方法对图像区域进行定位和增强,使图像的形状更清晰、更容易识别。其次,基于提出的DFANet对图像进行语义分割,从而获取目标位置和轮廓特征。
1.1 预处理
1.1.1预处理网络结构
由于待检测图像中目标分布密度不均匀,不同图像之间亮度有差异,并且许多图像中含有很多噪声,因此会导致模型的过拟合。同时,部分图像中存在的伪影和边缘模糊会影响后续的分割精度。为了解决这些问题,本文基于Eformer去除图像中的噪声,增强图像区域的边缘,从而提高后续分割的准确性。Eformer利用Transformer来构建编码器-解码器网络,并使用基于窗口的自我注意机制来减少计算需求和工作量。此外,Eformer将可学习的Sobel-Feldman算子连接到模型的中间层,用于增强边缘并提高去噪性能。Eformer模型结构如图2所示。
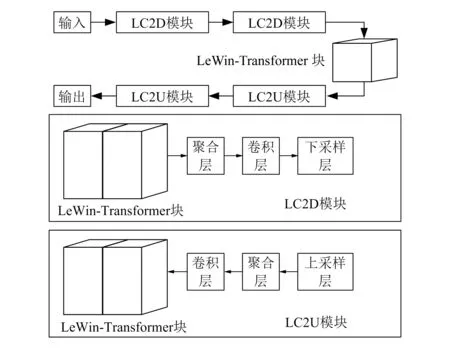
图2 Eformer模型结构
在输入原始图像I后,首先基于Sobel算子生成边缘增强特征图S(I),然后用GeLU激活函数进行激活。在Sobel算子处理后,不仅获得了整个图像的特征图,而且通道的数量发生了变化。在编码阶段的每个LC2D模块中,首先使用LeWin-Transformer块处理特征图;然后与S(I)级联,并使用卷积层处理;最后对特征图和S(I)进行下采样和编码。编码后的特征图将传递给另一个LeWin-Transformer块进行处理。在解码期间,LC2U模块先对特征图进行上采样,然后再将生成的结果与先前生成的边缘特征图S(I)级联后通过卷积块进行特征提取与融合、非线性变换等处理,最后将所有特征图传递到LeWin-Transformer块。解码的最后部分使用单层卷积模块输出映射。经过上述过程,不仅图像中的噪声被去除,而且目标边缘也会被增强。
LeWin-Transformer模块结构如图3所示,包含2个部分:W-MSA模块和局部增强前馈网络(locally enhanced feedforward network,LeFF)模块。首先,通过归一化层对特征图进行归一化,然后将结果传递给W-MSA。其次,在W-MSA模块中将二维特征图分解为不重叠的窗口,然后对每个窗口的平坦特征进行自关注。最后,将所有输出连接起来,并线性映射为最终结果。同时,通过归一化层将特征传递到LeFF模块。在LeFF模块中,通过线性投影层和3×3深度卷积层来管理图像块。
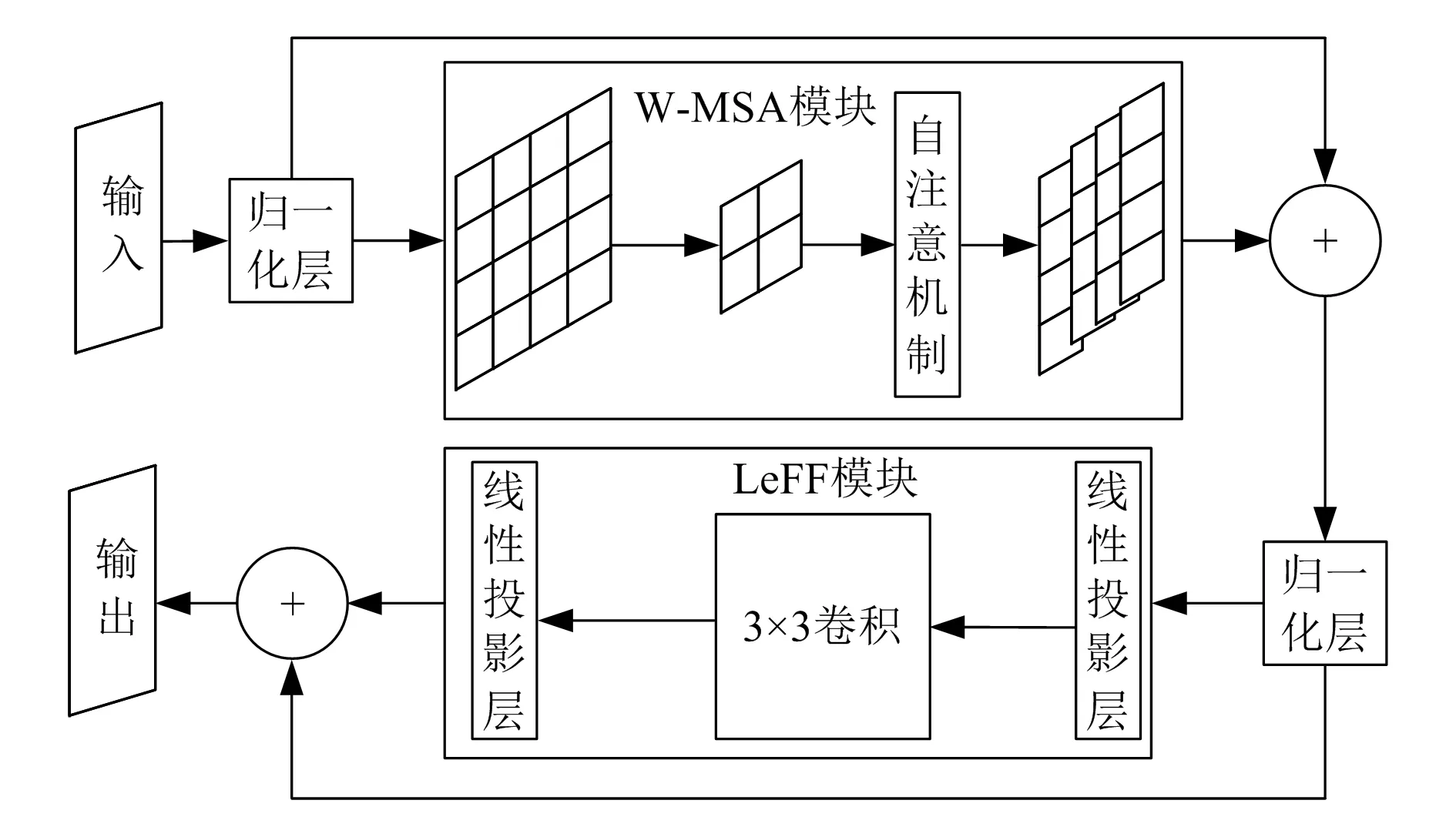
图3 LeWin-Transformer模块结构
LeWin-Transformer计算表达式如下:
Pn=MSA(LN(Qn-1))+Qn-1
(1)
Qn=LeFF(LN(Pn))+Pn
(2)
式中:Pn为W-MSA模块的输出,MSA(·)表示W-MSA模块的作用,LN(·)为层归一化函数,Qn为LeFF模块的输出,LeFF(·)为LeFF函数。
Eformer下采样使用跨步卷积,上采样采用转置卷积,从而重构空间结构。为了避免不均匀的采样过程,卷积核的大小通常应该可以被步长整除,因此选择4×4的卷积核大小进行转置卷积,步长设置为2。
1.1.2损失函数
图像去噪过程中使用了多种损失函数。首先,采用均方误差(mean squared error,MSE)损失函数估计实际输出和低噪声图像之间的像素距离:
(3)
式中:Lmse为均方误差损失,ti为第i个带噪声的图像的特征,ci为第i个低噪声图像的特征,R(·)为残差映射特征,N为图像总数。
MSE损失函数容易导致图像产生伪影,如过度平滑和模糊,这对图像的去噪非常不利,因此本研究在经典MSE中添加了ResNet中使用的多尺度感知(multi-scale perceptual,MSP)损失函数:
(4)
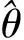
综上所述,去噪网络最终的损失函数定义如下:
Ltotal=λ1Lmse+λ2Lmsp
(5)
式中:Ltotal为去噪网络最终的损失函数,λ1和λ2分别为MSE和MSP损失的权重。MSE和MSP损失的组合不仅可以处理整体结构信息,还可以处理逐像素的相似性,从而获得更准确的处理结果,提高去噪效果,最大限度地减少原始图像中重要信息的丢失。
1.2 图像定位和增强
本节使用非参数图像定位和增强方法来定位和增强目标区域,以便为后续分割提供参考。首先,利用原始图像中强度频率分布直方图来区分背景和目标区域,并去除零强度值。图像强度频率计算如下:
(6)
式中:ηj为图像中第j个强度的频率分布值,σ为图像中最大强度值,Ij为图像I中第j个强度,x和y为像素值。
将初始非参数阈值θ定义为强度频率的平均值,则有:
(7)
在原始图像中,可基于强度值分布不均特性区分背景以及目标前景。令待检测图像中背景和前景目标区域的强度最小值为Emin和Fmin,则有:
Emin=min(Iθ)
(8)
Fmin=max(Iθ)
(9)
式中:Iθ为频率大于非参数阈值θ的强度值。通过计算Emin和Fmin,可从原始图像中对背景和前景待检测目标区域进行初步定位。
对于对比分明的目标,可通过初步定位区分背景和前景目标区域。对于难分辨目标,本文基于标准偏差方法确定对比度并进行细定位。背景和目标区域面积的标准偏差计算公式如下:
(10)
式中:Sj为图像对比度,θj为图像中强度的平均值,K为像素数。在原始图像中进行初始定位后,可基于对比度最终进行精确定位,即根据对比度确定背景和前景目标区域。
为了提升目标区域的视觉特征,本文还对局部目标区域进行了增强处理,从而使得目标区域更加突出。增强过程计算如下:
(11)
(12)
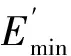
接下来,通过将局部增强图像添加到原始图像中,可以获得定位和全局增强图像:
ZR=If+Zi
(13)
(14)
式中:ZR为全局增强图像,If为原始图像,Zi为局部增强后的图像,IE(x,y)为原始图像中前景区域增强值。
1.3 图像分割网络
当实现原始图像定位和增强后,基于提出的深度聚合分割网络(deep aggregation segmentation network,DASNet)实现图像分割。DASNet结构如图4所示。
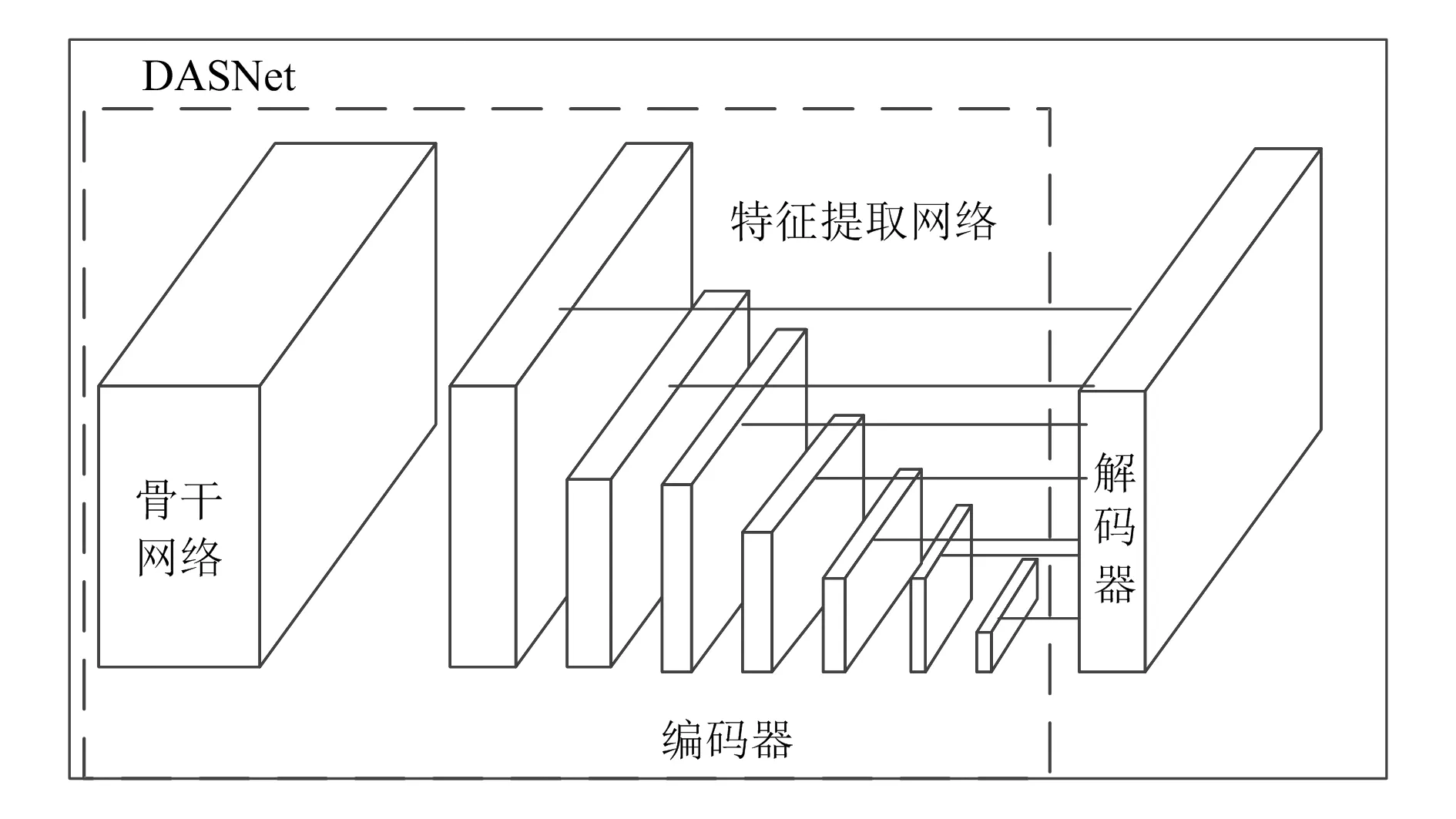
图4 DASNet结构
DASNet可理解为一种编码器-解码器结构。编码器由骨干网和特征信息提取网络组成,从而有效提取高级和低级特征。同时,DASNet实现了跨级别的特征聚合,可从上一层骨干网络和下一层骨干网络的输入对高级特征图进行上采样,且对具有相同维度的层进行分组,从而更加快速学习更高维度特征的细节信息。解码器由卷积和双线性上采样算子组成,这些算子将每个阶段的输出组合起来以生成分割结果。
2 实验与分析
2.1 数据集
本文基于DRIVE数据集验证所提基于去噪和局部增强的图像语义分割模型性能。DRIVE数据集由40幅彩色视网膜图像组成,其中20幅用于训练,其余20幅用于测试。每个原始图像的大小为565像素×584像素。STARE数据集包含20个彩色图像,每个图像的大小为700像素×605像素。DRIVE数据集部分数据展示效果如图5所示。
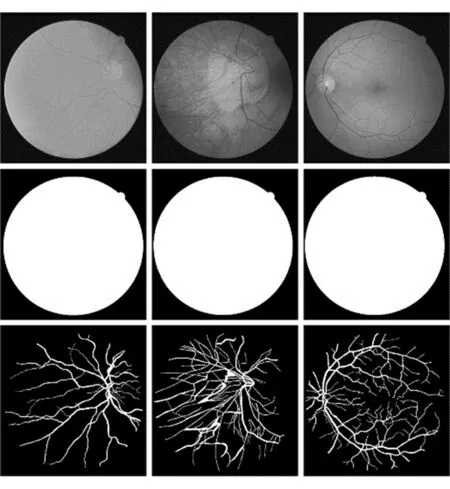
图5 部分数据展示效果
2.2 数据集
令训练时批处理量为32,迭代最大步长为18 000。图6所示为使用U-Net、ResU-net、R2U-Net及本文所提模型(简称本文模型)在DRIVE数据集训练准确率及损失变化曲线。可以看出,本文方法训练性能提升明显。分析原因:本文模型使用非参数定位和增强方法可以有效解决原始图像复杂的结构、形状和位置所带来的干扰,从而使得目标区域形状更加清晰,便于提高后续分割准确率。
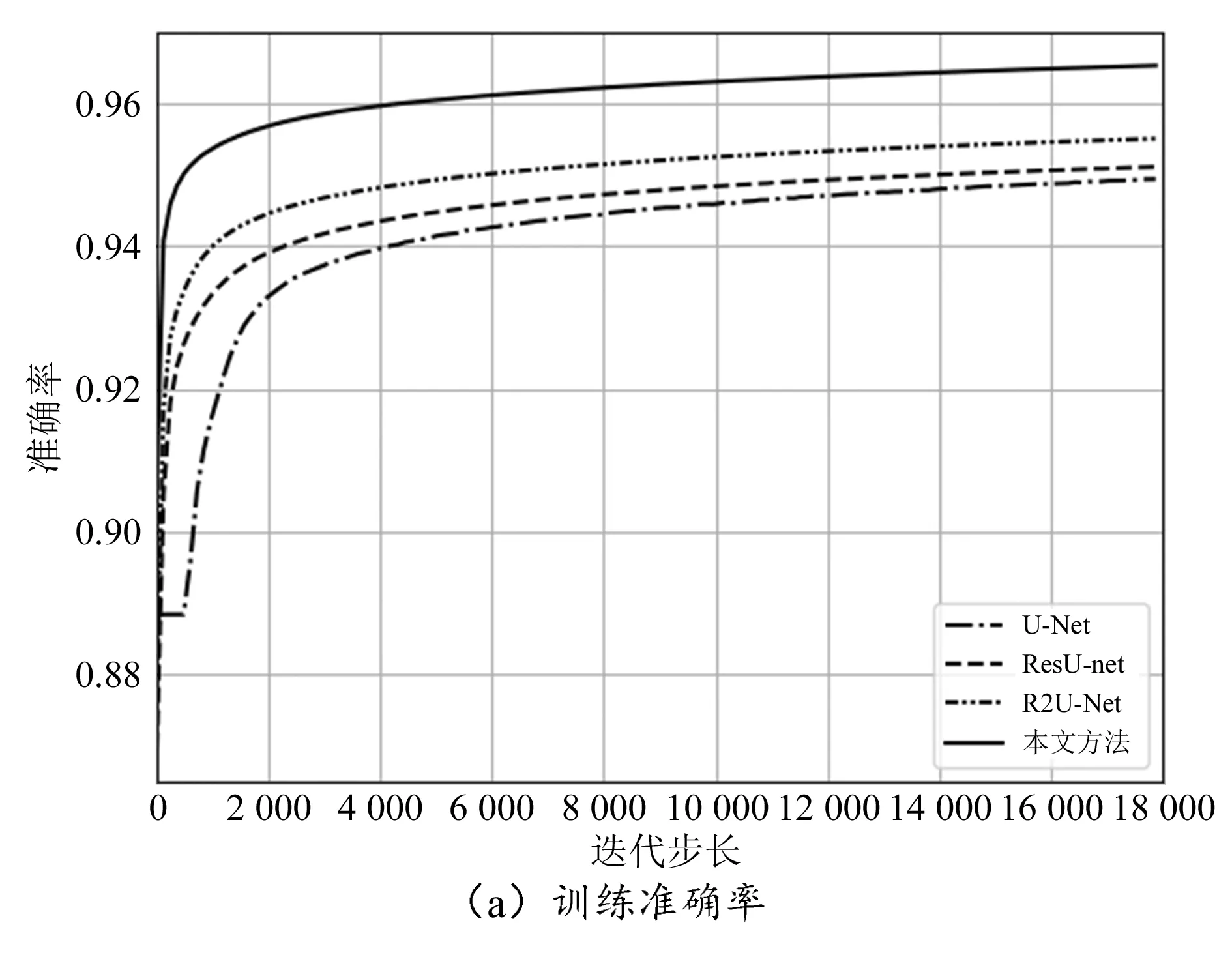
图6 DRIVE数据集下训练曲线
图7所示为分割模型测试效果,其中第一行为输入,中间为标签,最后一行为模型的实测分割结果。
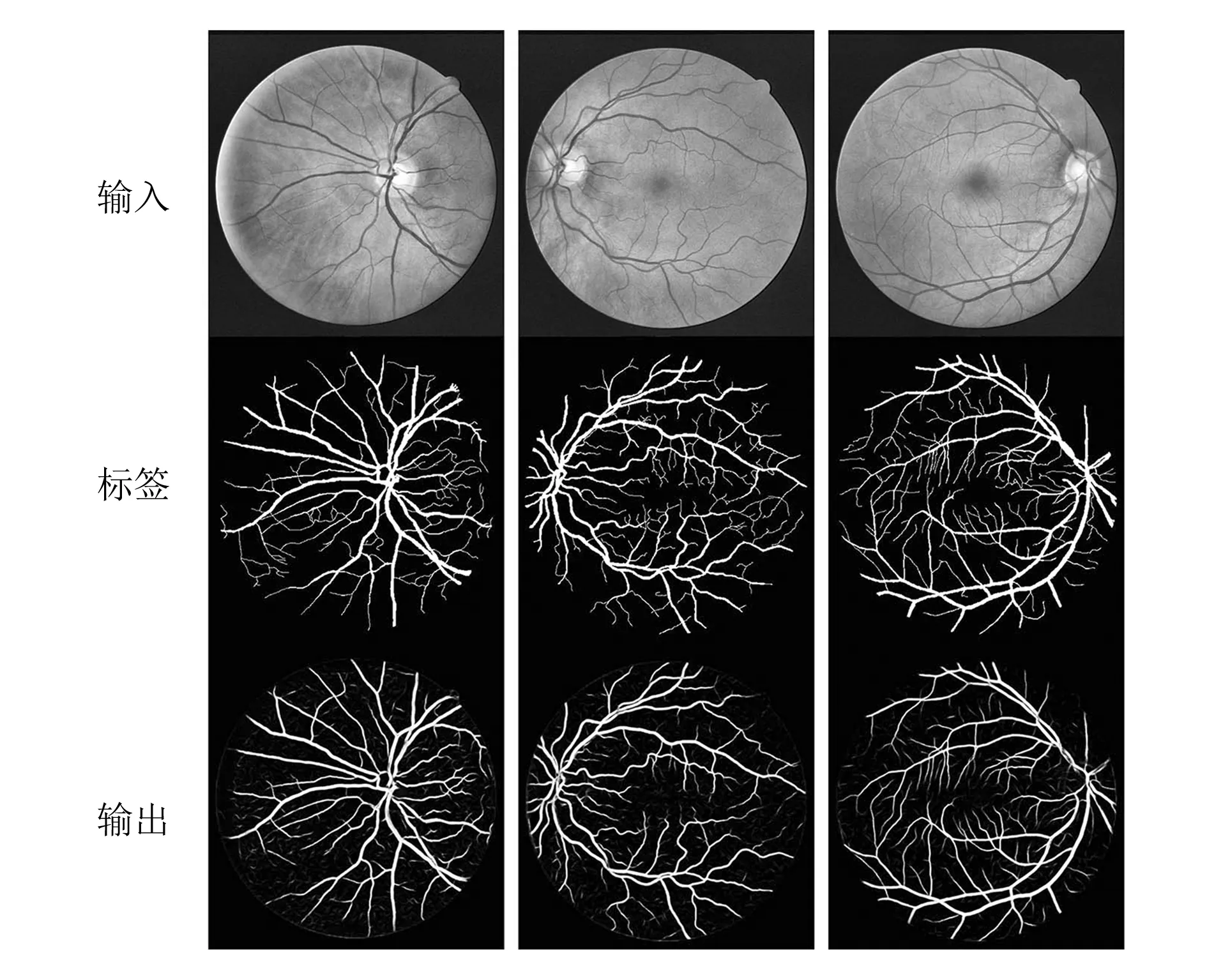
图7 模型测试效果
不同模型综合性能定量分析结果见表1。对比指标分别选取敏感度(SE)、特异性(SP)、准确率(AC)、AUC曲线下的面积(ROC)。由表可知,U-Net性能最低,其次为ResU-net和R2U-Net,本文模型的AC和AUC性能更优,分别为96.60%和97.85%。
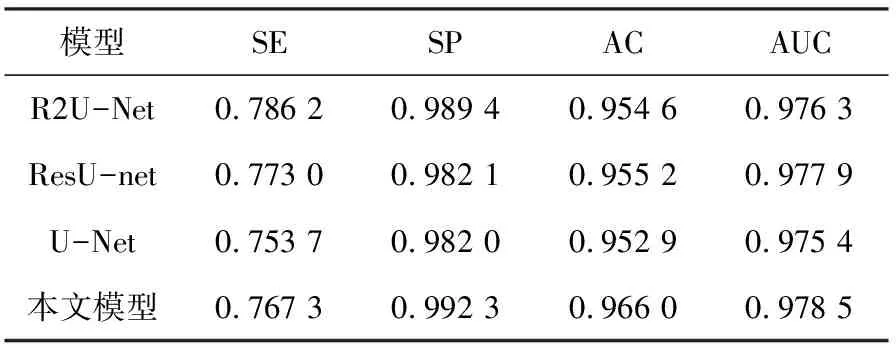
表1 不同模型综合性能定量分析结果
综合以上分析可知,本文模型可综合考虑非参数定位和图像增强因素,从而高质量确定图像中的分割目标。仿真结果符合实际情况,验证了所提模型的有效性和实用性。
3 结束语
本文对智能图像处理中的图像分割进行了研究与分析,建立了一种基于图像局部滤波去噪增强算法的图像语义分割模型。该模型将端对端的图像分割任务分为两个过程:预处理和语义分割,从而实现高质量的目标位置和轮廓特征提取。本文所提基于图像局部滤波去噪增强算法的图像语义分割模型可为图像分割领域发展提供借鉴。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
CHIP新电脑(2016年3期)2016-03-10
大连民族大学学报(2015年2期)2015-02-27
