
用XEdu做一个趣味甲骨文学习系统
2023-11-12 11:25陆雅楠上海人工智能实验室
中国信息技术教育 2023年21期
陆雅楠 上海人工智能实验室
谢作如 浙江省温州科技高级中学
近年来,与甲骨文相关的小视频曾一度火爆,但这类视频大多是将甲骨文做成动画或表情包,创意比较单一。因此,笔者决定另辟蹊径,做个凸显互动性的学习小游戏,让学生在网页上以“涂鸦”的形式书写甲骨文,系统则给出评价。这样,不仅能给学生提供更加直观、生动的学习体验,也能使其在感受甲骨文独特魅力的同时,体验AI的图像分类技术的神奇。
●趣味甲骨文学习系统的开发技术分析
从技术角度看,系统的核心是实现甲骨文识别。按照深度学习的一般流程,首先是收集很多甲骨文的图片,形成数据集,然后训练一个图像分类的AI模型。在XEdu工具的图像分类模块的帮助下,训练AI模型用几行代码就能完成,已经不再是难题。相对而言,难度较高的是数据集的制作,因为在互联网上暂时没有找到能够直接使用的甲骨文字符数据,只能自己以手绘的形式来制作这个数据集。考虑到工作量,笔者仅仅选择了“人”和“大”这两个文字。
采集数据需确保数据的质量和多样性,笔者参照深度学习领域著名的手写数字数据集MNIST,进行了手绘甲骨文字符数据集的采集与整理(如图1)。手绘主要使用电脑自带的画图软件进行字符手绘并保存为图片,特意使用了多种类型的、不同粗细的画笔工具绘制。每个类别的图片达到500张后,便开始整理数据集为ImageNet格式,即XEdu的图像分类模型支持的数据集格式,合理划分训练集、验证集和测试集。

图1 数据集和MNIST对照图
对于这个支持“涂鸦”识别的学习系统来说,设计一个交互网页反而难度最高。这涉及Web界面的搭建,需要具备前端开发的能力。可喜的是,已经有团队将常见的Web交互功能封装为一个很好用的Python库,也就是Gradio。借助Gradio只需定义输入和输出接口即可快速构建简单的交互页面,并轻松部署模型,且只需在一行代码中加个参数,即设置“source”为“canvas”,Gradio便可实现“涂鸦”功能,非常方便。
●趣味甲骨文学习系统的实现
在图像分类模型方面,笔者选择了LeNet网络。因为对于白底黑色字符的甲骨文字符数据集来说,LeNet是非常适合的,速度快且效果好。如果不想写代码,那就用XEdu内置的EasyTrain工具。图2是EasyTrain训练的图示,“loss”表示模型在训练集上的损失值,用以衡量模型预测结果与真实值之间的差异。而“accuracy”代表每轮训练结束后,模型在验证集上的预测准确率。

图2 EasyTrain训练界面
趣味甲骨文学习系统的交互设计部分,是借助Gradio来实现的。Gradio的核心是Interface类,参考代码如图3所示,通过关联的处理函数“predict”,以及定义“inputs”输入组件类型、“ouputs”输出组件类型,运行代码便可启动一个直观的、用户友好的模型交互界面(如图4)。

图3 参考代码
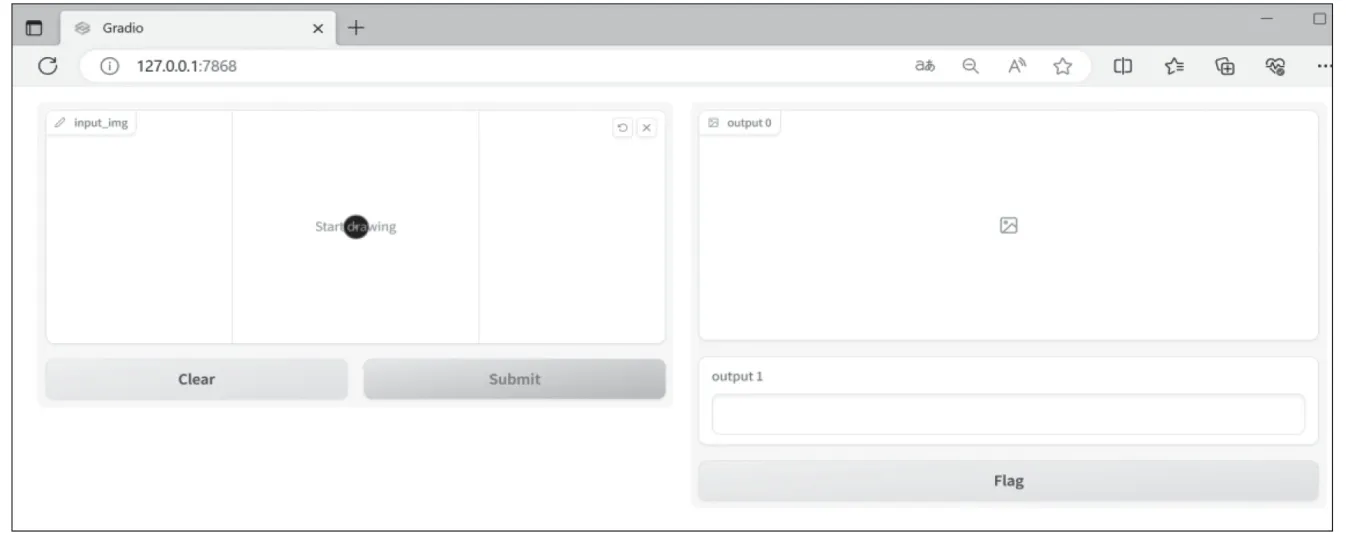
图4 Gradio的运行界面
●系统测试与完善
当完成了简易的学习系统后,笔者开始从学生的学习角度思考如何完善这一系统。例如,加入学习游戏的逻辑设置,先自己输入甲骨文绘制目标文字,再进行绘图,提交后传入AI模型进行判断,不仅要判断类别是否准确,还要根据置信度给出评分。同时,还可以给学习系统的界面加入使用说明、计时积分等功能。经过优化后,这个学习系统能够给出比较有趣的提示,交互更加友好,如下页图5所示。
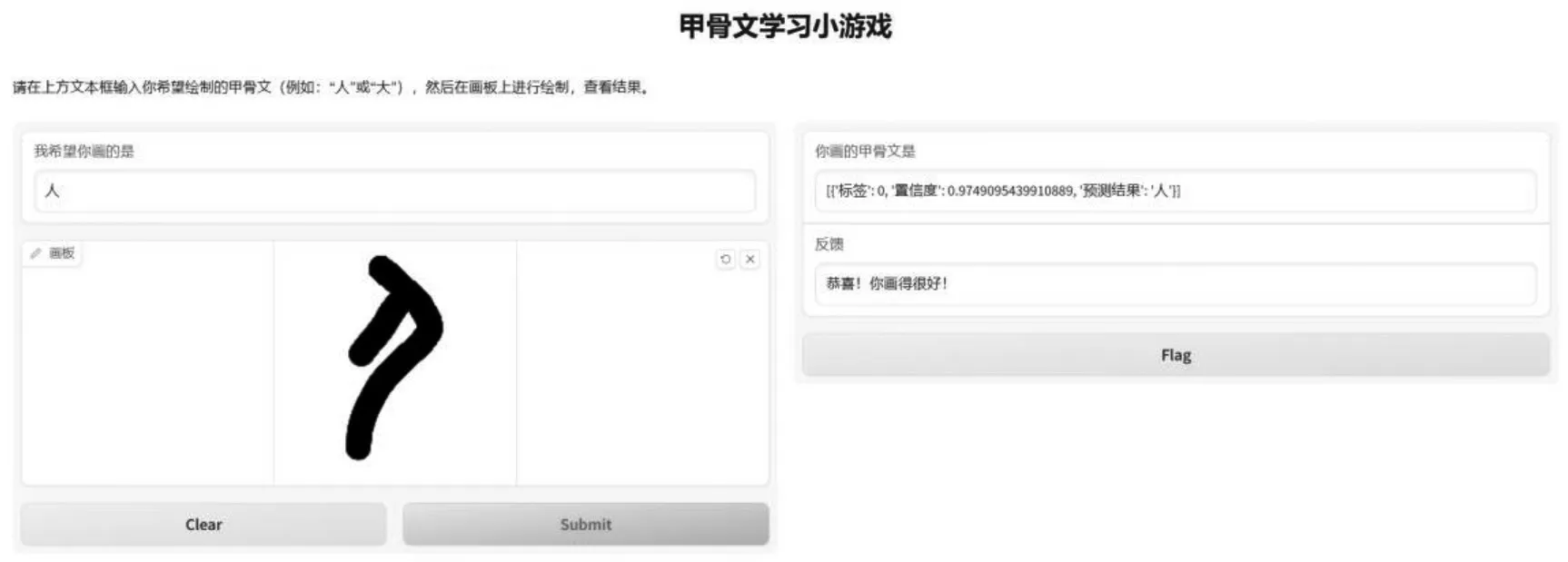
图5 甲骨文学习小游戏运行效果
考虑到部署这一模型的计算机系统可能没有安装XEdu,笔者将模型转换为通用ONNX格式,再借助XEduHub来推理,这样不仅代码更加精简,而且推理速度更快,放在行空板之类的开源硬件上都能运行。
AI模型转换的代码如下页图6所示,转换后部署模型的代码如下页图7所示。完整的项目相关文件可在以下网址找到:https://www.openinnolab.org.cn/pjlab/proje ct?id=64faba48929a840fc49ced33&sc=62f34141bf4f550f3e926e0e#public。

图6 参考代码

图7 参考代码
●从项目设计到课程开发
在成功搭建了这个趣味甲骨文学习系统后,笔者才意识到这一做法为学生提供了一个有趣的学习途径。因为在制作数据集时,找了好多资料,也学到了很多关于中国古代文字的知识,而这一过程完全可以让学生来参与,也就是让学生来制作数据集。学生不仅可以选择自己感兴趣的文字,通过研究和手绘制做出不同的数据集来,还可以通过测试,找出数据集的“瑕疵”,研究更多的甲骨文写法,让数据集更加丰富。
因此,笔者准备以这一项目为基础,开发一个完整的项目式学习课程,引导学生亲身参与从数据收集、模型训练到模型部署的完整过程。项目计划6课时,配合课程设计可将此项目分成大任务和子任务,大任务是完成一个趣味甲骨文学习小游戏,小任务则围绕项目创作的流程进行拆分,其中包括主题选择、创意构思、数据准备、模型训练、游戏开发、测试优化等。
猜你喜欢
阅读(高年级)(2022年9期)2022-10-08
疯狂英语·初中天地(2021年5期)2021-07-21
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
汉字汉语研究(2018年1期)2018-05-26
遵义(2017年24期)2017-12-22
创新作文(小学版)(2016年11期)2016-11-11
神州学人(2016年9期)2016-10-20
