
基于XGBoost机器学习模型的信用评分卡与基于逻辑回归模型的对比
2023-11-07 09:15张利斌吴宗文
中南民族大学学报(自然科学版) 2023年6期
张利斌,吴宗文
(中南民族大学 经济学院,武汉 430074)
在金融风控领域,如何根据贷款客户的基本信息和行为数据等,利用一定的分类模型,将贷款客户区分为违约客户和非违约客户,从而减少贷款机构的信用风险,是金融贷款机构孜孜不倦的追求.当前有两种主流分类模型——统计学模型和机器学习模型.逻辑回归模型是最常用的统计学模型,其优点主要体现在:第一,理论基础成熟,适合二分类问题[1];第二,可解释性较强,易于理解[2];第三,模型训练时间短[3].缺点主要体现在:第一,容易产生过拟合,泛化能力弱[4];第二,特征空间很大时,分类性能不好[5].近年来,XGBoost 机器学习模型在分类问题中表现优秀,受到越来越多风控人员的青睐,其优点主要体现在:第一,计算复杂度低,运行速度快,准确度高[6];第二,可处理数据量大[7].缺点主要体现在:第一,建模过程不透明,模型较难解释[8];第二,理论基础不够成熟,布置上线较困难[9].
在分类模型的评价方面,当前学者主要使用AUC、KS、F1 和Accuracy 值等来评价逻辑回归模型和XGBoost 机器学习模型的效果,并指出XGBoost机器学习模型比逻辑回归模型在AUC、KS、F1 和Accuracy 值上表现更加优秀,但是并未解释更加优秀的原因.本文拟从维度信息的损失程度、缺失值的处理方式以及模型的算法原理三方面来解释其中的原因.
1 模型对比
1.1 逻辑回归模型
逻辑回归模型[10]是线性回归模型的改进,是一种“广义的线性回归模型”,该模型是分类问题中最常用的统计学模型.逻辑回归模型的一般形式见式(1)所示,如下:
其中,β0~βn为模型的估计参数,x1~xn为模型的变量.
在金融风控领域,以贷款客户的违约与否作为逻辑回归模型的因变量,一般称为“非违约客户”和“违约客户”,用0 或1 来表示,即f(x) <0.5 为0;f(x) >0.5为1.
1.2 XGBoost机器学习模型
XGBoost 机器学习模型[11]比传统的GBDT(Gradient Boosting Decision Tree,以下简称GBDT)更加进步的原因在于:传统的GBDT 只利用了一阶的导数信息,而XGBoost 机器学习模型对损失函数进行了二阶的泰勒展开,求得模型最优解的效率更高.具体如下:
将XGBoost机器学习模型进行t次迭代之后,此时的目标函数为:
将目标函数进行泰勒二阶展开可得:
1.3 模型优缺点
逻辑回归模型和XGBoost 机器学习模型的优缺点如表1 所示.相较于XGBoost 机器学习模型,逻辑回归模型更加方便实现,并且可解释强;XGBoost 机器学习模型在处理大数据时精度更高,并且可以有效防止过拟合.

表1 逻辑回归模型和XGBoost机器学习模型的优缺点Tab.1 Advantages and disadvantages of logistic regression model and XGboost machine learning model
2 实证分析
本文的实证分析思路如下:首先,分别运用逻辑回归模型和XGBoost 机器学习模型来构建信用评分卡,并运用AUC、KS、F1和Accuracy这四个指标评估模型的效果.其次,从维度信息的损失程度、缺失值的处理方式以及模型的算法原理三个方面对比两个模型,分析XGBoost 机器学习模型比逻辑回归模型更加优秀的原因.
2.1 逻辑回归模型
2.1.1 数据介绍
实验数据来自于kaggle 官网(https://www.kaggle.com/c/home-credit-default-risk/overview)的 住房贷款违约风险预测的竞赛数据.本文的实验数据集包括20000 个训练数据和5000 个测试数据,其中实验数据集共有121列,包括个人基本信息、所在地区情况、借贷信息状况以及公司相关状况等.本文为更好地解释实证部分,将实验数据集的英文变量翻译为中文变量,如表2所示.
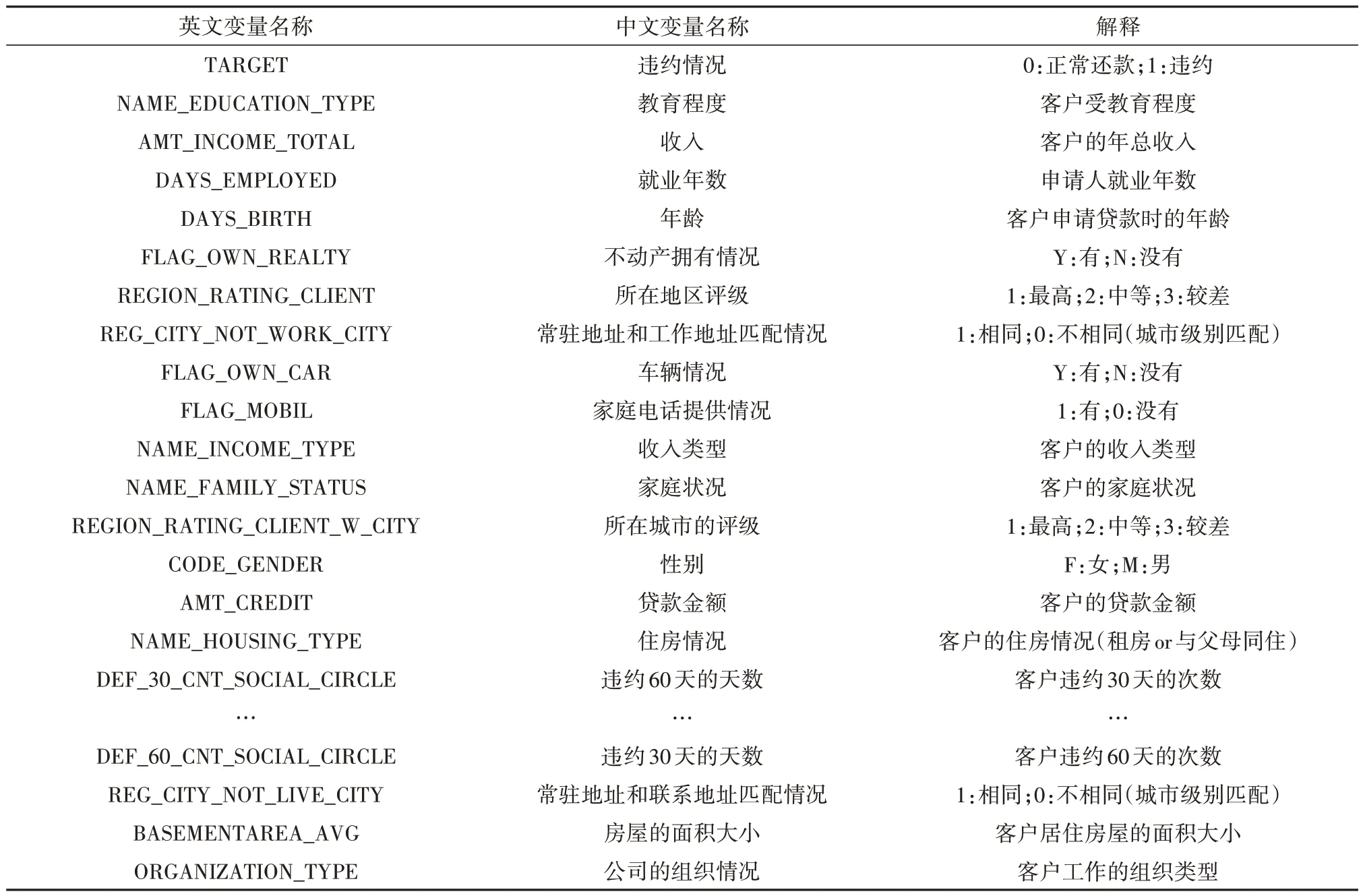
表2 变量解释表Tab.2 Variable interpretation
2.1.2 数据预处理
(1)无效值处理
原始数据表中的SK_ID_CURR 变量在实际建模中的用处不大,且包含用户的隐私信息,故需直接删除.
(2)缺失值处理
根据jupyter 分析软件可得,121 个变量中共有65 个有缺失值.其中,共有57 个变量的缺失比例大于10%,将其直接删除,对剩余的缺失变量做相应的填充处理,具体处理方式如表3所示.
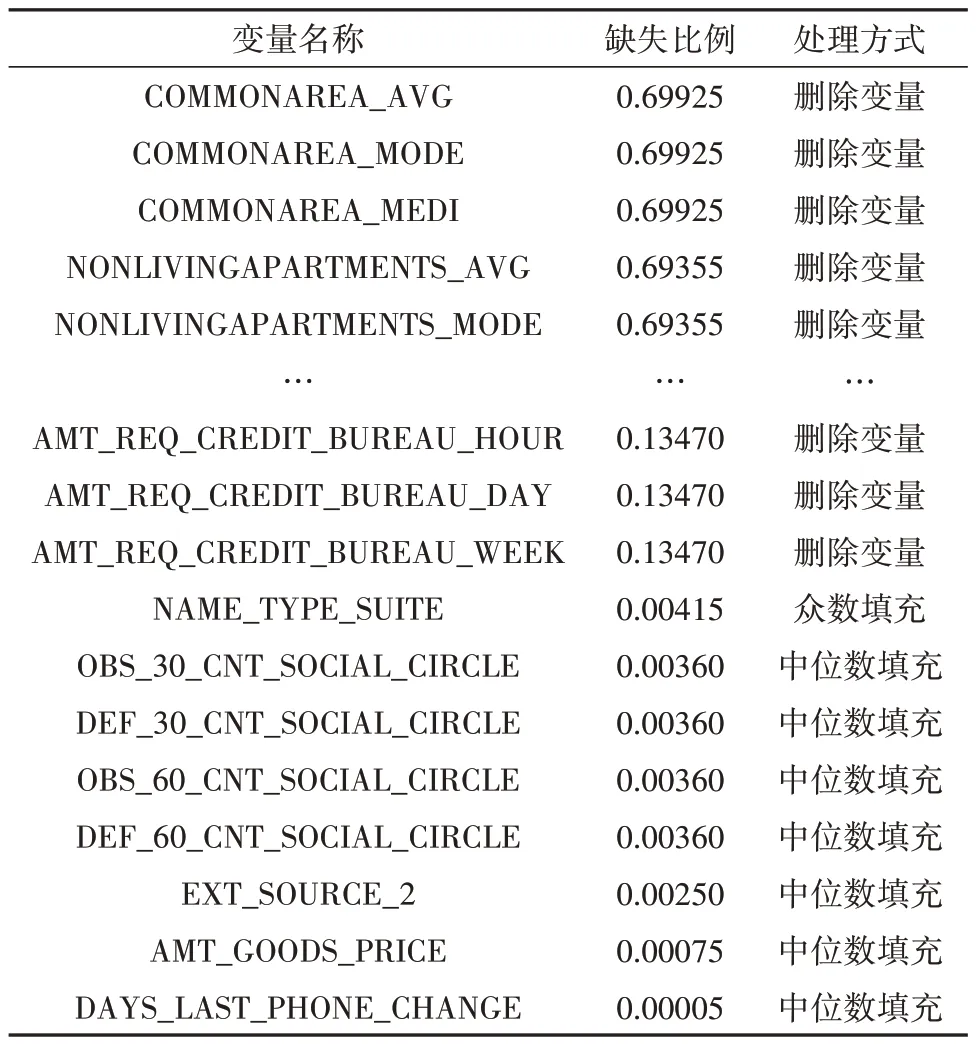
表3 缺失变量处理表Tab.3 Missing variable processing table
2.1.3 入模变量筛选
对逻辑回归模型来说,入模变量的选择至关重要.本文选择WOE 分箱、IV 值筛选法以及相关性检测相结合的方法筛选入模变量,具体思路如下:首先,根据变量的阈值以及业务趋势进行WOE 分箱;其次,根据WOE分箱计算变量的IV值,筛选IV值大于0.3 的变量(IV 值大于0.3 有较高的预测能力);最后,对IV 值大于0.3变量进行相关性检测,剔除相关性大于0.5中IV值较小的那个变量.
一般来说,建立逻辑回归模型只需选择10~12个变量[12].本文选择IV 值排名靠前且通过相关性检测的11个变量作为入模变量,具体如表4所示.

表4 入模变量表Table.4 Molding variables
2.1.4 逻辑回归模型的建立
根据SPSS 软件,确定x1~x11各变量的估计参数,从而建立逻辑回归模型,具体表达式如(4)式所示:
其中xi(i=1…11)为11 个入模变量;f(x)为预测结果.
2.1.5 信用评分卡的建立
根据传统的信用评分机制,可以制作信用评分卡,标准的信用评分卡如表5所示.

表5 标准评分卡Table.5 Standard score card
表中,A、B 为假设的基础分值,本文设为500 和50,θ0~θn为x1~xn的估计参数,ω11~ωnkn为x1~xn各分量的WOE值.
根据评分转换原理,计算出11个入模变量的各分量得分值,具体结果如表6所示.

表6 基于逻辑回归模型的信用评分卡Tab.6 Credit scoring card based on logistic regression model
利用表6 的信用评分卡对5000 个测试集样本进行评分转换,得测试集样本的最终得分情况见表7.
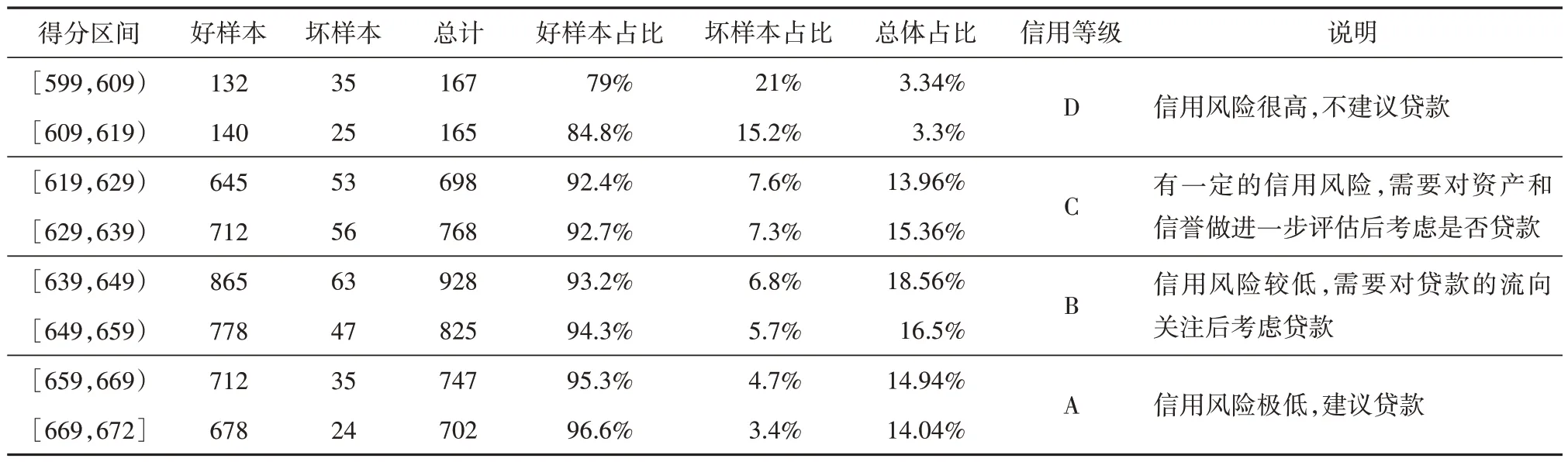
表7 测试集样本得分情况统计Tab.7 Statistics of sample scores of test set
从表7 的得分情况可以看出,随着用户得分的上升,高分段的坏样本占比呈现出不断下降的趋势,这也说明了信用评分卡可以较好地识别信用风险.
2.1.6 模型的效果评价
对于分类模型而言,可以从分类能力和预测的准确程度来评价模型的效果.一般来说,使用AUC和KS 来评估模型的分类能力以及F1 和Accuracy 来评估模型的预测准确程度[13].通过对训练集和测试集的样本测试,得到相关的评价指标如表8所示.

表8 模型结果评估Tab.8 Evaluation of model results
从表8 可以看出该模型在测试集上拥有0.7294的AUC 和0.5378 的KS,这表示模型具有较好的分类能力.同时该模型在测试集上拥有0.8218的F1和0.8325 的Accuracy,这表示模型具有较高的预测准确程度.
2.2 XGBoost机器学习模型
2.2.1 朴素的XGBoost机器学习模型
首先,用训练数据来建立默认参数下的XGBoost 机器学习模型;其次,对所构建的XGBoost机器学习模型进行效果评价.具体结果如表9所示.
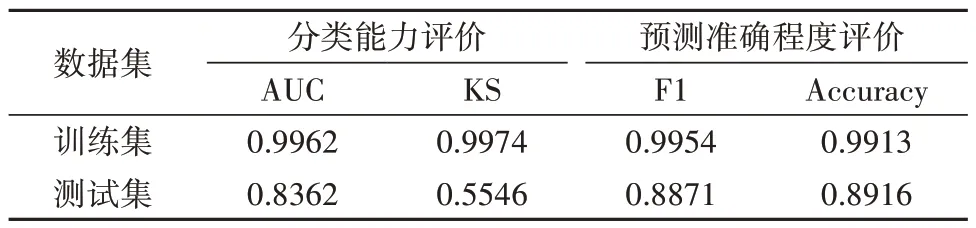
表9 朴素的XGBoost机器学习模型结果Tab.9 Results of simple XGBoost machine learning model
由表9 可知,在没有超参数约束的情况下,XGBoost 机器学习模型在训练集上完全拟合,而在测试集上的表现相对一般,这表明该模型的泛化能力较弱.造成这种现象的原因是XGBoost 机器学习模型是基于决策树的集成模型,如果不限制其增长,它可以学习到适应所有训练样本的规则.但是如何提高该模型在测试集上的表现,才是我们真正所关心的,因此需要对模型进行调参优化.
2.2.2 调优的XGBoost机器学习模型
XGBoost 的超参数可以归为三个核心部分:通用参数,Booster 参数和任务参数[14].本文在通用参数、Booster 参数以及学习目标参数这三类参数的具体选择如表10所示.

表10 XGBoost的调参参数Tab.10 Adjusted parameters of XGBoost
本文使用网格搜索交叉验证得到的最优超参数为:eta 为0.02,min_child_weight 为2,gamma=0.2,max_depth 为5,num_boost_round 为110.使用该参数组合的XGBoost机器学习模型对训练数据和测试数据进行效果评价,具体结果如表11所示.

表11 调优的XGBoost机器学习模型结果Tab.11 Results of optimized XGboost machine learning model
从表11 可以看出,该模型在测试集上拥有0.8746的AUC和0.6318的KS,这表示模型具有很好的分类能力.同时该模型在测试集上拥有0.9487 的F1 和0.9318 的Accuracy,这表示模型具有很高的预测准确程度.
将该模型与朴素的XGBoost 机器学习模型在测试集上的表现进行对比,得到的结果如表12所示.

表12 朴素的XGBoost与调优的XGBoost机器学习模型对比结果Tab.12 Comparison results of simple XGboost and optimized XGboost machine learning models
从表12 可知,调优的XGBoost 机器学习模型相比于朴素的XGBoost 机器学习模型,AUC、KS、F1 和Accuracy 都有所提升,这说明调优后的XGBoost 机器学习模型更加优秀.
2.2.3 信用评分卡的构建
为了更加具体地观察调优的XGBoost 机器学习模型输出结果,本文考虑引入传统的信用评分机制,进而将机器学习模型输出的概率值转换为常见的信用评分值.通过对测试集样本的信用评分统计,具体的信用评分卡如表13所示.
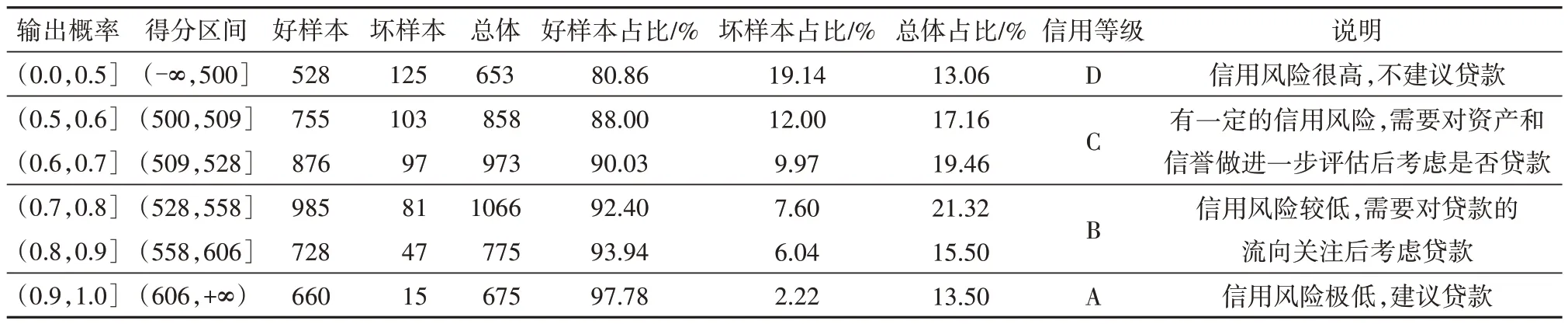
表13 基于XGBoost机器学习模型的信用评分卡Tab.13 Credit scoring card based on XGBoost machine learning model
从表13 可以看出,XGBoost 机器学习模型输出的概率值可以通过信用评分机制转换为信用评分值.随着得分的提高,好样本的占比逐渐提升,坏样本的占比逐渐降低,这说明所建立的信用评分卡能够较好地识别信用风险.
2.3 模型对比分析
根据上文的实验结果,将逻辑回归模型和调优的XGBoost 机器学习模型在测试集上的AUC、KS、F1和Accuracy进行比较,如表14所示.

表14 逻辑回归模型与调优的XGBoost机器学习模型对比结果Tab.14 Comparison results between logistic regression model and optimized XGboost machine learning model
从表14 可以看出,XGBoost 机器学习模型在测试集上的AUC、KS、F1 和Accuracy 均高于逻辑回归模型.通过对两种建模方式的比较,XGBoost 机器学习模型更加优秀的原因主要有以下三点:
(1)维度信息损失程度更低
在建立逻辑回归模型,运用WOE 分箱、IV 值筛选法以及相关性检测相结合的方法从121个原始变量中挑选出11个变量来建立逻辑回归模型,该方法损失了较多的维度信息,仅列出Ⅳ最高的11个变量.然而,在建立XGBoost 机器学习模型时,将121 个变量经过数据处理后全部输入到模型中,几乎没有原始数据的信息损失.单从数据维度来看,XGBoost 机器学习模型纳入更多的维度信息是机器学习模型相对于逻辑回归模型更加优秀的原因之一.
(2)缺失值的处理方式更加科学
在建立逻辑回归模型时,一般删除缺失比例超过10%的缺失值,同时用众数填充类别型缺失变量和中位数填充连续型缺失变量,该方法有一定的人工干预,处理缺失值方式不够严谨.然而,XGBoost机器学习模型采用内置算法处理数据的缺失值,该方法处理缺失值更加科学.单从缺失值的处理方式来看,XGBoost 机器学习模型科学地处理缺失值是该模型相对于逻辑回归模型更加优秀的原因之一.
(3)模型的算法原理考虑了正则化项
在建立逻辑回归模型时,没有考虑正则化项,导致该模型复杂度较高,有过拟合的风险,评估效果一般.然而,在建立XGBoost 机器学习模型时,考虑了正则化项,降低了过拟合风险,评估效果得到了有效提升.单从模型的算法原理来看,XGBoost 机器学习模型考虑了正则化项是该模型相对于逻辑回归模型更加优秀的原因之一.
3 结论与思考
本文比较了逻辑回归模型和XGBoost 机器学习模型在信用评分卡构建中的具体表现,通过对比两个模型的AUC、KS、F1 和Accuracy 值,得出了以下结论:
(1)逻辑回归模型在测试集上的分类效果以及预测准确程度不如XGBoost 机器学习模型.逻辑回归模型的AUC、KS、F1 和Accuracy 均低于XGBoost机器学习模型,这表明XGBoost 机器学习模型在分类效果以及预测准确程度上均表现更优.
(2)逻辑回归模型建模过程较XGBoost 机器学习模型更易于理解.在建立逻辑回归模型时,通过特征筛选从121 个变量中筛选出11 个变量建立逻辑回归模型,该方法建模过程透明,易于理解.然而,XGBoost 机器学习模型以编程和调整参数的形式来建立模型,具有一定的不透明性,不易于理解.
(3)维度信息损失程度更低、缺失值的处理方式更加科学以及模型的算法原理更加科学(考虑了正则化项)是XGBoost 机器学习模型相较于逻辑回归模型在分类效果以及预测准确程度上更加优秀的原因.
如何融合逻辑回归模型和XGBoost 机器学习模型,使其两者在风控领域可以优势互补,在提高模型效果的同时又增强解释能力?是值得我们下一步深入研究的问题.
猜你喜欢
法律方法(2022年2期)2022-10-20
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电影(2018年8期)2018-09-21
数学物理学报(2017年5期)2017-11-23
37°女人(2017年11期)2017-11-14
