
基于改进GANomaly网络的旋开盖缺陷检测方法
2023-11-07 09:15舒军王祥李灵雷建军何俊成杨莉
中南民族大学学报(自然科学版) 2023年6期
舒军,王祥,李灵,雷建军,何俊成,杨莉
(1 湖北工业大学 电气与电子工程学院,武汉 430068;2 湖北第二师范学院 计算机学院,武汉 430205)
旋开盖受加工工艺的影响会出现刮痕,尺寸变换、脏污等缺陷,导致密封性下降、食品变质,检测缺陷瓶盖能保证消费者享用安全、健康的食品.对于瓶盖的缺陷检测通常采用基于传统图像处理的方法.2018年,文欣雨等[1]针对瓶盖黑点缺陷提出了一种基于Canny 算子和SVM 的瓶盖缺陷检测技术.2019 年,岳昊等[2]针对医用瓶盖的脏污和圆度,采用了阈值分割、求平均灰度、边缘检测等方法来检测.杨健等[3]采用高斯差分滤波对细微划痕进行增强,采用二维Otsu 阈值分割和形态学处理进行划痕的提取.2020年,任小丹等[4]基于瓶盖颜色与传送带颜色不同的特点,采用二值化、滤波、锐化等图像处理方法检测瓶盖是否合格.随着卷积神经网络的发展,基于深度学习的图像处理技术有着较强的特征提取能力.2021 年,HORPUTRA 等[5]在饮料包装过程中将传统图像处理方法和YOLO v3 网络相结合,检测瓶盖是否存在倾斜、松动和缺失这3 种情况,具有高速度和高精度.上述瓶盖缺陷检测方法可总结为2个步骤:图像预处理和检测缺陷.图像预处理的目的是提取瓶盖,例如使用阈值分割、边缘检测、特征提取等,用于去除背景的干扰;检测缺陷是使用相关算法检测瓶盖是否存在缺陷,例如SVM分类器把有缺陷的瓶盖检测出来.基于以上分析,本文将语义分割作为预处理方法,异常检测作为缺陷检测方法,来完成旋开盖缺陷检测.
PSPNet[6]、UperNet[7]、DeepLabV3+[8]、OCRNet[9]等经典语义分割方法,可对图像的每一个像素产生一个预测.PSPNet 核心模块是金字塔池化模块(Pyramid Pooling Module),它能够聚合不同区域的上下文信息,提高获取全局信息的能力.UperNet 是针对统一感知解析的语义分割网络,该网络是基于PSPNet 的改进,有足够多的特征融合,同时去掉了PSPNet 的辅助损失,在训练时间上缩减了很多.DeepLabV3+以DeepLabv3 做编码器架构,解码器采用一个简单却有效的模块,改进了Xception,并将深度分离卷积应用在模型中,进一步提升了模型在语义分割任务上的性能.OCR-Net 通过像素与区域的关系来增强像素的表示,获取的上下文更有针对性.上述方法在PASCALVOC[10]、ADE20K[11]、cityScape[12]等公开数据集上表现良好,但这些数据集须在光照充足的白天采集,对于低照度图像语义分割方法的研究很少.在低光环境中采集的图像,由于照明方式、光源特点、周围环境的复杂性,使拍摄环境或光线亮度值低,拍摄的图像亮度值低、亮度和对比度下降,并伴随着大量的随机噪声.在低照度环境采集的旋开盖图形存在颜色信息消失和噪声,导致语义分割模型训练的特征数量少,出现误分割、分割边界不准确的问题.
异常检测(Anomaly Detection,AD)是对给定数据集中的异常标签进行识别.随着深度学习和计算机视觉的发展,异常检测逐渐向图像处理领域发展.基于深度学习的图像异常检测方法解决了模板匹配、图像分解、构建分类面等传统方法检测速度慢、通用性差、不适应多变目标的问题[13].基于深度学习的图像异常检测分为监督学习、半监督学习和无监督学习这三类.当异常数据处在明显且有限的定义下,例如行人跌倒[14]、安检[15]和交通事故检测[16]中,卷积神经网络可在正常图像数据集和异常图像数据集下学习,并有效区分异常情况.杨子固等[15]对安检时打火机、刀具、电池、剪刀这4 类危险物品的检测,在Faster R-CNN 上增加了PCM 来学习正常样本和异常样本的差异.当异常数据处在繁琐且无法统计的情况下,因异常情况存在多样性,无法使用监督学习方法学习所有异常数据的特征,半监督学习方法可解决上述问题.AnoGAN[17]、Efficient-GANAnomaly[18]、GANomaly[19]等利用正常数据集训练,使自编码器在测试阶段能重构正常情况下的图像.在测试阶段,对存在异常的图像进行编码和重构,与正常图像产生的差异被作为判别图像是否存在异常的指标.当异常数据处在无法标注或很少有异常情况下,需使用无监督学习方式来进行异常检测.LAI 等[20]提出了一种无监督异常检测网络,有新颖的鲁棒空间恢复层(RSR 层).此图层从给定数据的潜在表示中提取底层子空间,并删除远离此子空间的异常值,根据原始和映射位置之间的距离来区分正常值和异常值.P-KDGA[21]将知识蒸馏与GAN 相结合,通过设计蒸馏损失来连接两个标准GAN,将知识转移到学生完成对图像的异常检测.因旋开盖的缺陷存在多样性且无法统计,故采用基于半监督学习的异常检测解决旋开盖缺陷样本不足的问题.目前基于半监督学习的图像异常检测方法大多使用图像重构的方法,重构正常样本和异常样本,比较重构后的差异,即可检测出缺陷.但GANomaly 采用编解码结构,存在重构细节不精细的问题,导致无法区分细节特征相似的样本.
针对语义分割和GANomaly网络存在的问题,本文提出了一种结合低照度图像增强[22]、OCR-Net 语义分割[9]和GANomaly 异常检测[19]的新旋开盖缺陷检测方法.该方法采用基于最大熵的Retinex 模型[22]来增强低照度图像的亮度和对比度,在此基础上使用OCR-Net 语义分割方法分割瓶盖,并基于十字交叉注意力[23]和最小二乘损失函数[24]改善GANomaly异常检测网络的图像重建能力,最后使用无缺陷的瓶盖训练改进后的网络,检测出有缺陷的图像.
1 旋开盖缺陷检测的整体框架
新方法具体流程如图1 所示,包含预处理和缺陷检测两部分.由于所采集图像存在两个问题:(1)部分图像存在亮度低和对比度低影响缺陷检测;(2)瓶盖图像中的传送带存在脏污情况,在传统算法中容易被误检为瓶盖缺陷.针对上述问题,对低照度旋开盖图像使用基于最大熵的Retinex 模型对低照度图像增强,改善图像的亮度和对比度,选用OCR-Net 语义分割从背景中提取出瓶盖.对于正常光照图像选用OCR-Net 语义分割方法.经过上述预处理后,采用改进后的GANomaly 异常检测网络检测缺陷瓶盖.该网络学习正常样本的特征,并根据图像重建的分数来判断瓶盖是否存在缺陷.

图1 旋开盖缺陷检测的整体框架Fig.1 Overall framework of screw-on cap defect detection
2 图像预处理
2.1 低照度图像增强
图像质量的好坏与拍摄环境有极大的关联.在光照充足的白天所采集的图像,有合适的对比度和亮度,能体现拍摄物体的细节;在光照不足的夜晚或者黑暗环境中所采集的图像,亮度和对比度低,严重时还会出现噪声、分辨率低的问题,导致图像不能体现目标物体的细节.一般来说,在低光环境下光量不足,图像的获得需把相机的曝光时间设置得比白天长,但这会使捕获的图像产生光学模糊和噪声.在低照度环境下获取的彩色图像,直接限制了对图像的处理.
旋开盖的颜色上存在多样性,有白色、金色、蓝色、红色等.在调试相机与光源的参数时,发现对于颜色偏暗的旋开盖,图像亮度会出现过暗的情况,不能显示瓶盖盖沿的细节部分.在相同曝光时间、同一光源和相机下,对于暗色瓶盖,采集的注胶面图像不能体现瓶盖盖沿的颜色,绿色瓶盖与黑色、蓝色瓶盖盖沿颜色相似,不能区分出是何种颜色;对于金色、白色这些亮色瓶盖,工业相机能很好地拍摄出目标物体的颜色信息(见图2).

图2 旋开盖图像Fig.2 Image of the screw-on cap
分析图2 可知:当目标物体颜色与背景颜色对比度很高时,目标物体的信息比较充分;当目标物体颜色与背景颜色对比度低时,目标物体的细节信息有所欠缺.例如所采集的瓶盖图像为绿色瓶盖,而传送带的颜色也是绿色,导致图像整体偏暗,无法显示瓶盖盖沿的颜色.为使相机清晰地拍摄暗色瓶盖,试着调试相机的曝光时间.当曝光时间调低时,加剧了暗色瓶盖的问题,使亮色瓶盖图像同暗色瓶盖一样,不能体现瓶盖盖沿颜色;当曝光时间调高时,无法适应缺陷检测系统速度,无法满足生产条件.背景颜色影响着图像的细节部分,可更换背景颜色,即根据待测瓶盖的颜色更换不同颜色的传送带,例如检测黑色瓶盖时,将传送带更换为白色传送带,但在实际情况中,更换传送带颜色,不仅增加了设备成本,而且增加了人工更换传送带的成本,更重要的是使检测效率下降,增加了检测时间.
为解决上述问题,使用低照度图像增强.低照度图像增强方法从传统方法发展到了基于深度学习的方法.为选取最好的低照度图像增强方法,将所采集的低照度瓶盖图像应用到GLADNet[25]、TBEFN[26]、RUAS[27]和基于最大熵的Retinex 模型[19]中,图2(a)瓶盖注胶面和图2(b)瓶盖印刷面的增强效果如图3所示.

图3 瓶盖图像增强效果的对比Fig.3 Comparison of image enhancement effects of bottle caps
图3 中在GLADNet 增强方法中,由于GLADNet考虑全局信息,瓶盖反面的白色影响增强效果,导致瓶盖正面和瓶盖反面的增强效果不一样;TBEFN增强方法相较于RUAS 和基于最大熵的Retinex 模型,在瓶盖反面图像中的盖沿部分出现了阴影;RUAS 增强方法受白色的影响,瓶盖反面出现了过增强效果,瓶盖内部全部变为白色;基于最大熵的Retinex模型在增强效果上优于GLADNet、TBEFN 和RUAS.故采用基于最大熵的Retinex 模型来增强低照度瓶盖图像.
2.2 语义分割
语义分割可将标签分配给图像中的每个像素,解决背景环境干扰这一问题,为后续的缺陷检测奠定良好的基础.为提取瓶盖完成缺陷检测,根据所采集的图像照度情况,分为低照度图像数据集和正常光照图像数据集,并研究了PSPNet、UPerNet、DeepLabV3+和OCR-Net 在正常光照瓶盖和低照度瓶盖中的分割性能,其性能如表1所示.

表1 旋开盖的分割Tab.1 Segmentation of the screw-on cap
表1 中mIOU 表示预测结果与原始图像中真值的重合度.当正常光照瓶盖采用OCR-Net 语义分割方法时,mIOU 的值高于其他方法,故选用OCR-Net来对正常光照瓶盖进行分割.低照度图像直接语义分割,其mIOU 值与正常光照图像相比,低照度瓶盖因受传送带颜色的影响,图像的颜色细节不像正常光照的瓶盖一样细腻,其mIOU 值有所下降.低照度瓶盖在PSPNet、UPerNet、DeepLabV3+和OCR-Net 中的分割结果如图4 所示,它们对瓶盖盖沿分割不准确.
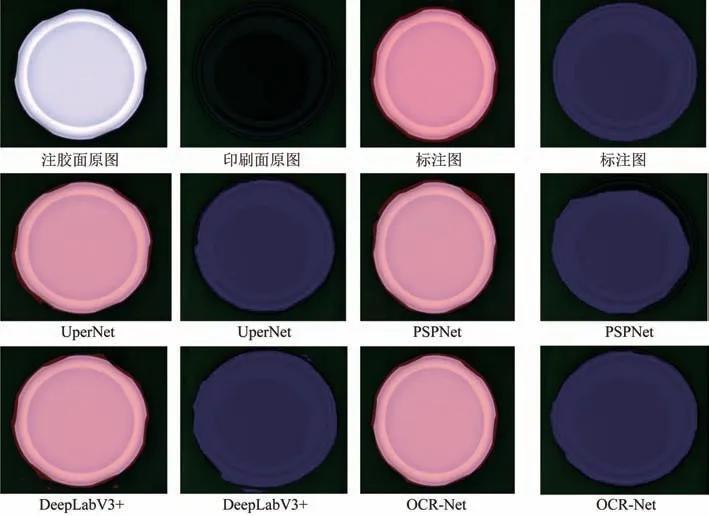
图4 低照度旋开盖直接语义分割Fig.4 Direct semantic segmentation of low-illumination screw-on caps
为解决上述问题,在低照度旋开盖图像中,依据2.1节分析先采用基于最大熵的Retinex模型增强图像,再使用OCR-Net来分割.训练结果相比于直接分割,mIOU 为95.7%,提高了3.4%.分割预测结果如图5 所示,训练好的OCR-Net 准确分割出了无缺陷瓶盖和带有缺陷的瓶盖,从背景中将瓶盖分割出来,直接将背景变黑,从而解决了传送带脏污情况影响异常检测效果的问题.

图5 瓶盖分割预测结果Fig.5 Prediction result of bottle cap segmentation
3 基于GANomaly 网络的旋开盖图像缺陷检测
为解决缺陷样本不足的问题,将缺陷情况作为异常来处理,采用基于GANomaly 异常检测网络来实现对瓶盖的缺陷检测.
3.1 GANomaly网络结构
随着深度学习的发展,用于数据挖掘领域的异常检测引入到了图像处理邻域.常用的目标检测算法需要大量带有精确标注的图像,标注包括图像类别、位置、像素点的类别.异常检测十分适用于旋开盖的缺陷检测:一是收集正常瓶盖的难度要比收集带有缺陷瓶盖低;二是只训练正常样本,不用标注缺陷瓶盖.鉴于以上优点,本文将异常检测用于旋开盖缺陷检测中.
基于深度学习的异常检测方法,无需依靠人工设计的特征,算法通用性高.AKCAY 等[19]提出了GANomaly 网络,它是一种基于图像重构的异常检测方法,将比较图像分布转换成了比较图像编码下的潜在空间,采用半监督学习方式,捕获了图像和潜在向量空间内的分布.GANomaly只学习正常态样本的特征分布,然后在包含正常和缺陷样本的数据集上测试和评估,找出样本之间的特征差异.基于GANomaly 网络学习正常瓶盖图像的分布模式,在检测阶段通过分析重构前后的差异来实现旋开盖的缺陷检测.GANomaly网络结构如图6所示.

图6 GANomaly网络结构Fig.6 GANomaly network structure
该网络由3部分构成:自编码器、重构编码器和判别器,采用半监督生成式对抗训练方式,自编码器和重构器相当于生成器.自编码器用于重建输入的正常图像,x表示输入图像,z表示图像经编码器得到的特征表示,x1表示z经解码器重构的图像.在重构编码器部分,对重构图像x1编码得到特征表示z1.判别器根据原始图像x来判断重构图像x1的真假.网络的每个部分对应一个损失函数:重建损失Lrec、重构损失Lenc和判别器损失Ladv,如公式(1)-公式(3)所示.采用的训练方式和常规GAN 一样,先优化判别器,再优化自编码器和重构编码器.推断采用重构损失Lenc,当网络训练好以后,选取Lenc的最大值作为阈值来推断.若一张图像的Lenc小于阈值,则为正常图像,若一张图像的Lenc大于阈值,则为缺陷图像.
GANomaly 网络采用编解码和重构编码的结构来对正常图像进行学习,使模型学习到更高层的信息,但忽略了图像细节部分.若缺陷瓶盖的外观和正常瓶盖的外观差异比较小,模型很难判断.此外该网络在训练过程中会出现梯度消失的问题.针对以上问题,在网络中引入了十字交叉注意力模块学习正常样本的细节,重建精细的上下文特征.通过改进损失函数解决训练过程梯度消失的问题.
3.2 基于十字交叉注意力的GANomaly网络
为区分差异比较小的样本,引入了上下文信息这一概念,即形状、纹理和像素识别等细节信息.为捕获有用的上下文信息,使模型更加注意图像的细节,在GANomaly 中的引入了十字交叉注意力(Criss-Cross Attention)模块[23],如图7 所示.十字交叉注意力是一个位置像素注意力模块,更加关注特征图上的像素点之间的相关性,即获取像素交叉路径上的邻近像素的上下文信息.

图7 基于十字交叉注意力的GANomalyFig.7 GANomaly based on Criss-Cross Attention
十字交叉注意力如图8 所示.输入是编码器GE(x)输出的特征图H,分别通过2 个1×1 卷积降维,生成特征图Q和特征图K,再通过关联操作获得注意力图.另外特征图H再通过一个1×1卷积得到与注意力图尺寸一样的特征图V,然后将横纵方向上每个位置的特征与注意力图横纵方向上的特征进行点乘,再相加得到残差聚合特征,最后加上原特征得到更强表征能力的特征H1.

图8 十字交叉注意力Fig.8 Criss-Cross Attention
关联操作如公式(5)所示,di,u表示特征Qu与特征组Ωi,u相关程度,即注意力图,Qu表示特征图Q在像素u位置的一个向量,Ωi,u表示从特征图K中按照十字交叉方式进行提取的一组向量,采用向量乘积计算相关性.聚合操作如公式(6)所示,Φi,u表示横纵方向上每个位置的特征,Hu表示原特征.通过上述操作,十字交叉注意力捕获了更有用的上下文信息,使GANomaly网络更加关注图像细节:
3.3 损失函数的改进
原始GANomaly 网络模型在自编码器与判别器交替训练时,使用了交叉熵损失函数.当判别网络确定重建图像为“真”时,重建损失函数直接等于“0”,因此,网络将不再继续优化这些被判断为真实的生成图像.虽然这些重建的图像还远未达到真实图像的决策边界,但网络输出的重建图像质量较低,引起早期梯度消失.为使重建的图像尽可能适合真实图像的分布,使用最小二乘损失[24]代替交叉熵损失进行对抗训练,使判别网络不仅要区分自编码器生成的真假图像,还要优化重建样本的异常值的分布,以保持接近真实样本.根据最小二乘损失构造如下:
式中:D(x)为判别器,G(x)为自编码器.则更改后的损失函数为:
式中:wadv、wrec和wenc是权重参数,用于调整每个损失,分配不同损失在整体训练中的贡献.更改损失后,其训练步骤为:第一步优化判别器,保持自编码器的权重不变,根据式(7)计算判别器损失,并不断更新判别器的权重;第二步冻结判别器权重,优化自编码器,总损失如式(9)所示.在预测时,对于测试样本y,由原图像特征GE(y) 与重建图像特征E(G(y))之间的差异,获得重建分数为S(y),其定义如(10)所示:
测试集D会产生一组重建分数S=Si:S(yi),yi∈D,方便评估网络的检测性能,将重建分数归一化到[0,1]之间,如(11)所示.
当网络根据正常样本训练好后,可得到正常样本数据集的重构损失Lenc,选取重构损失的最大值作为判断异常的阈值.在测试时,由式(11)获得图像的重建分数.若重建分数小于阈值,则图像为正常;若重建分数大于阈值,则图像为异常.
4 实验
实验主要分为3个部分:旋开盖缺陷检测实验、消融实验和泛化实验,经过低照度图像增强、语义分割和异常检测这3个步骤完成对旋开盖的缺陷检测,然后对改进后的GANomaly进行泛化验.
4.1 旋开盖缺陷检测实验
实验中所使用的旋开盖图像数据集来源于工厂流水线上,在同一设备下和相同设置下采集了旋开盖的印刷面和注胶面图像.瓶盖印刷面图像共有12185张,瓶盖注胶面图像共有7199张,图像尺寸为1920×1200.根据第2.1 节分析,瓶盖颜色与传送带颜色的对比度影响着图像的明暗,为满足瓶盖缺陷的多样性,分别采集了金色、绿杂色、绿色、蓝色、白色瓶盖图像,其数据集的分布如表2所示.

表2 瓶盖数据集的分布Tab.2 Distribution of the bottle cap dataset
在实验中,因图像包含了传送带金属边缘的少部分,为减少其影响改变图像尺寸为600×538.实验环境为Nvidia Quadro P5000 GPU 和Intel(R)Xeon(R)CPU E5-2673 v3 @ 2.40 GHz,操作系统为64 位的Ubuntu 18.04.基于最大熵的Retinex 模型对低照度图像进行增强,利用低照度图像的直方图均衡化的最大通道来约束增强效果,实现了仅利用低照度图像就可以完成增强的任务.采用自监督的学习方法,训练好的权重,直接对所有的低照度瓶盖图像进行增强,输出了增强后的图像.在OCR-Net分割增强后的图像和正常光照图像时,使用Labelme 标注软件对瓶盖人工标注,分为3 类目标:背景、瓶盖正面和瓶盖反面.将瓶盖标注好的数据集整理成VOC数据集格式,其标注数量、训练集和评估集的分布情况如表3 所示,其中增强图像表示低照度瓶盖图像基于最大熵的Retinex模型做了图像增强.依据表3分别训练好OCR-Net,并对剩下的图像预测.

表3 OCR-Net的训练Tab.3 Training of OCR-Net
改进后的GANomaly 网络只学习正常样本的特征,故在已分割的瓶盖数据集上,挑选出了2000 张无缺陷图像,其中包括1000 张瓶盖印刷面图像,1000张瓶盖注胶面图像.将2000张正常瓶盖图像输入到改进后的GANomaly网络进行异常检测的训练.训练网络时,为防止显存爆满的问题,将600×538的图像缩放到128×128,设置训练批次为100,学习率为0.0002.根据总损失函数L,设置wadv=1,wrec=40,wenc=0.8,以上权重在实验结果中获得了最佳效果.训练过程损失L的表现如图9 所示,训练自编码器和重构器时,损失L达到了0.9.

图9 改进后网络训练情况(损失L)Fig.9 Improved network training(loss L)
当改进的GANomaly 网络训练好后,将待测样本进行预测.本实验中,待测样本数量为857 张,正常样本数量为427 张,缺陷样本数量为430 张.图10为预测阶段正常样本和缺陷样本的直方图.

图10 网络改进后的预测结果Fig.10 Prediction results after network improvement
由图10可知:网络改进后检测缺陷瓶盖的正确率达到了98%.故低照度图像增强解决了缺陷检测受拍摄光照的影响,语义分割解决了缺陷检测受背景因素影响的问题,为瓶盖的异常检测奠定了良好的基础;使用改进后的GANomaly 网络检测瓶盖的缺陷,训练正常样本就可检测多种缺陷.在异常检测训练阶段,自编码器、重构编码器和判别器这3部分的损失函数达到了最好状态.
4.2 消融实验
为进一步探究改进后的GANomaly网络,在瓶盖数据集上进行了消融实验.先在GANomaly 上添加十字交叉注意力模块,并使用原损失函数,如公式(4)所示.再在添加十字交叉注意力模块的基础上,更改损失函数,如公式(9)所示,分别证明十字交叉注意力模块及最小二乘损失函数对网络的影响.
将原网络与加入十字交叉注意力后的热力图进行了对比.由于原网络采用编解码结构,对于瓶盖的细节特征容易忽略.如图11 所示,加入十字交叉注意力后,体现了瓶盖盖沿的细节和缺陷瓶盖的缺陷特点.加入十字交叉注意力后,仍使用原损失函数,Ladv的表现如图12(a)所示,在训练到29次时,判别器已到达了最好的状态,随着训练时间的增加,损失几乎接近零.当训练结束时,正常图像的重建效果如图13(c)所示,相比于原GANomaly,加入十字交叉注意力后,改善了图像重建上的细节,如注胶面的盖沿颜色、印刷面颜色等细节.虽然判别器达到最好状态,但重建的图像尚未达到真实图像的决策边界,网络输出的重建图像还需进一步提升,如瓶盖盖沿轮廓,印刷花纹等细节.

图11 热力图Fig.11 Heat map

图12 损失函数Fig.12 Loss function

图13 重建效果对比Fig.13 Comparison of reconstruction results
根据以上分析,将交叉熵损失函数更改为最小二乘损失函数,Ladv-G损失函数的训练表现如图12(b)所示,损失最终达到了0.011.原损失函数Ladv在训练29 次,其值几乎等于零,出现梯度消失的问题.为使训练稳定,将Ladv更改为Ladv-G,进一步提升图像的重建效果,如图13(d)所示.
为进一步探究改进后的GANomaly网络,在瓶盖数据集上,对比了改进前后的ROC曲线和AUC值.缺陷检测使用了异常检测方法,GANomaly网络相当于一个二分类器,故采用ROC曲线和AUC值来评价模型的好坏.其中ROC曲线代表模型以多大的置信度将样本分类为正样本,在瓶盖数据集中出现类别不平衡的现象下,即负样本比正样本多,ROC曲线能够保持不变.而AUC 是ROC 曲线下的面积,当AUC 的值越大,缺陷检测效果越好.对比结果如图14所示.在改进前,受交叉熵损失函数和编解码结构的影响,在重建图像过程中,遗漏了瓶盖的细节信息,尤其是反面瓶盖盖沿部分,也影响着ROC 曲线.当在原GANomaly网络中加入了十字交叉注意力模块,同时将交叉熵损失函数替换为最小二乘损失函数.图14中改进后的ROC曲线更加凸,说明改进后的模型更好,同时AUC值提升了0.12.

图14 改进前后的ROC曲线Fig.14 ROC curves before and after improvement
4.3 泛化实验
为验证改进的GANomaly网络的优点,采用了如表4所示MVTec AD[28]数据集中的10类对象.

表4 MVTec AD数据集Tab.4 MVTec AD dataset
MVTec AD是一个对工业检测方法进行基准测试的数据集,广泛用于异常检测,每个对象包括一组无缺陷的训练图像和一组具有各种缺陷的测试图像以及无缺陷的图像.
将提出的方法与Auto-Encoders[29]、GANomaly 和skip-GANomaly[30]在MVTec AD数据集上进行了对比.上述异常检测网络和改进的GANomaly 训练方式一样,仅利用正常样本的特征构建异常检测的模型,有着不同的自编码器结构.MVTec AD数据集在上述网络的AtUC值如表5所示.

表5 MVTec AD数据集AUC值的比较Tab.5 Comparison on the AUC value of the MVTec AD dataset
改进后的GANomaly相比于其他3种网络在AUC值上有所提升,加入了十字交叉注意力,使网络更关注图像的细节信息,同时最小二乘损失函数,解决了重构损失函数等于“0”的问题.故改进的GANomaly网络能在各类数据集中应用,具有一定的应用价值,同时在AUC值上优于其他3种网络.
5 结语
基于现有瓶盖缺陷检测方法,提出了一种结合低照度图像增强、语义分割和异常检测的旋开盖缺陷检测方法.针对低照度旋开盖在语义分割中分割不准确的问题,使用基于最大熵的Retinex模型来改善低照度图像的亮度和对比度,通过实验选取了分割效果好的语义分割方法OCR-Net,对旋开盖的注胶面和印刷面进行了有效的分割.结果证明采用低照度图像增强后,分割效果明显提升.针对GANomaly网络存在图像重效果差的问题,基于十字交叉注意力和最小二乘损失函数进行了改进,解决原网络忽略瓶盖盖沿细节问题,提高了AUC值,在MVTec AD数据集上优于Auto-Encoders、GANomaly和skip-GANomaly.
猜你喜欢
幼儿100(2022年23期)2022-12-27
学苑创造·A版(2022年5期)2022-05-19
光源与照明(2019年4期)2019-05-20
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2018年9期)2018-06-26
快乐语文(2017年27期)2017-11-15
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
中学科技(2014年11期)2014-12-25
电测与仪表(2014年13期)2014-04-04
