
电子鼻结合GC-MS鉴别不同部位的三七粉
2023-11-07 04:15李丽霞林宇浩李珊珊张付杰
食品科学 2023年20期
李丽霞,张 浩,林宇浩,史 磊,李珊珊,张付杰,*,王 俊
(1.昆明理工大学现代农业工程学院,云南 昆明 650500;2.浙江大学生物系统工程与食品科学学院,浙江 杭州 310058)
三七(Panax notoginseng(Burk.) F.H.Chen),又名文州三七,为五加科(Araliaceae)人参属(Panax)植物,是临床常用传统中药[1]。三七商品有主根、剪口、侧根、须根的划分,不同部位的药用成分构成有较大差异,临床功效也不尽相同[2]。现代药理学研究表明,三七总皂苷(Panax notoginsengsaponins,PNS)是三七药效的主要物质基础[3]。根据GB/T 19086—2008《文山三七地理标志产品》,三七不同部位总皂苷含量从高到低依次为剪口、主根、侧根、须根。三七的主要商业价值在于剪口和主根,三七粉是三七的主要消费和商品形式[4]。剪口、主根、侧根和须根等形态相对简单,很容易通过外观鉴别,但在粉末状态下,它们的颜色相同,通过肉眼很难对其进行鉴别[5]。所以,市场上一些不良商家会利用三七侧根、须根粉假冒主根和剪口粉获取暴利,这严重扰乱市场秩序,影响了三七的品质与药效。因此,鉴别不同部位的三七粉有利于保证三七的药效,以及促进该产业的规范化发展。
目前,对于三七粉的检测研究,主要采用高效液相色谱法和近红外光谱法。其中,高效液相色谱法虽然精度很高,但是操作复杂,且投入很高,无法达到快速、无损检测的要求[6]。近红外光谱技术分析样品具有方便、快速和成本较低等优点,但其单色光的谱带较宽,波长分辨率差,且对温湿度敏感,抗干扰能力差,导致检测精度不高[7]。已有研究表明,三七挥发性成分众多,且三七不同部位挥发物有差异[8-10]。因此,可以通过三七粉挥发物的检测对不同部位三七粉进行鉴别。基于嗅觉仿生技术的电子鼻操作简单,且成本相对低廉,是一种分析、检测复杂气味和大多数挥发性成分的仪器,具有快速、无损等优点[11-12],是实现中药挥发物检测的较佳方法。
迄今为止,电子鼻在农业食品[13-15]、药材检测[16-17]、医疗健康[18-19]、环境监控[20-21]等方面已经取得较多应用和研究成果。目前,已经有一些学者通过电子鼻检测不同头数三七主根粉挥发物鉴别三七主根的质量等级或者伪品[11,22],也有学者通过检测三七主根粉和支根粉的挥发物判别三七主根、支根的产地[23]。然而,利用电子鼻鉴别不同部位三七粉的报道很少。电子鼻可以快速准确地检测出不同的挥发物类型,通常对一些产品的整体信息提供综合评估,气相色谱-质谱(gas chromatography-mass spectrometry,GC-MS)主要用于挥发性物质的定性和半定量[24],国内外已有许多采用电子鼻结合GC-MS联用技术研究五加科中药材挥发性成分的研究[25-28]。因此,本研究采用电子鼻技术结合GC-MS对三七整根粉、剪口粉、主根粉、侧根粉和须根粉5 种三七粉挥发性成分进行分析,从而鉴别这5 种三七粉。
电子鼻数据分析主要包括特征提取和模式识别[29],不同的特征提取方法会影响分类效果,合适的特征提取方法应该在很大程度上反映电子鼻传感器的变化[30]。模式识别方法众多,但仍然需要大量的工作选择合适的算法表征电子鼻传感器信号。本研究的重点是探究电子鼻结合GC-MS在鉴别不同部位三七粉中的潜在应用。本研究探究利用金属氧化物半导体传感器PEN3电子鼻和GC-MS联用技术鉴别5 种三七粉的可行性,寻找合适的基于电子鼻数据的三七粉特征选择方法和分类模型,旨在应用于5 种不同三七粉的鉴别分析。
1 材料与方法
1.1 材料与试剂
三七样品于2017年12月份采自云南文山州。将三七样品进行清洗,清洗后自然干燥,然后将干燥后的三七样品分为整根、剪口、主根、侧根和须根。最后将样品用小型粉碎机进行粉碎,粉碎的样品过60 目筛后装进密封袋封口,保存于4 ℃冰箱备用。
乙酸辛酯(色谱纯)、二氯甲烷(分析纯)国药集团化学试剂有限公司。
1.2 仪器与设备
7890A-5975C GC-MS仪 美国安捷伦公司;德国Airsense公司生产的PEN3型电子鼻系统,该电子鼻的气体传感器阵列由10 个金属氧化物半导体传感器组成,不同传感器对不同类型的挥发物灵敏性不同,具体见表1。

表1 PEN3电子鼻传感器阵列性能特点Table 1 Response characteristics of PEN3 electronic nose sensor arrays
1.3 方法
1.3.1 电子鼻检测
制作5 种不同部位的三七粉样本,分别为整根粉、剪口粉、主根粉、侧根粉和须根粉,每组24 个样本,每个样本为5 g。将各三七粉末样品分别置于500 mL的烧杯中,立即用保鲜膜密封,在25 ℃室温静置60 min,通过顶空进样的方式进行采样。采样完成后,将氮气泵入电子鼻,对传感器进行清洗使其恢复到初始状态。电子鼻的检测参数为样品测定间隔时间1 s,清洗传感器时间180 s,速率600 mL/min,样品检测时间120 s,速率400 mL/min。
1.3.2 GC-MS测定
采用顶空固相微萃取对样品进行萃取,GC-MS进行分离、鉴定和定量挥发性化合物。称取0.5 g样品于15 mL顶空瓶中,并加入10 μL 2×10-4μL/mL的乙酸辛酯(溶质)二氯甲烷(溶剂)溶液作为内标物,用封口膜封口,涡旋振荡30 s,放入80 ℃水浴锅中平衡30 min,萃取头(DVB/CAR/PDMS-50/35 μm)吸附30 min,解吸10 min,每组处理设置3 个重复样品。
GC条件:进样口温度为250 ℃,不分流,采用HP-5MS色谱柱(30 m×0.25 mm,0.25 μm),载气为氦气,流速2 mL/min。升温程序:初始温度50 ℃保持2 min,以8 ℃/min的速率升温至140 ℃,保持0.1 min,然后以4 ℃/min的速率升温至240 ℃,最后以8 ℃/min的速率升温至280 ℃,保持3 min。
MS条件:离子化方式为电子电离,电子能量为70 eV,四极杆温度为150 ℃,离子源温度为230 ℃,接口温度为280 ℃,质量范围为30~50 u。
1.4 数据处理
1.4.1 电子鼻数据分析
1.4.11 特征提取
检测模型的精度受气敏信号特征参量选择的影响。通过对前人研究分析[31-33],选择积分值(integralvalue,INV)、平均微分值(average differential value,ADV)、相对稳态平均值(relative steady-state averagevalue,RSAV)、最值(extreme value,EV)、二项式曲线拟合系数值(binomial curve fitting coefficient value,BFV)(a,b,c)作为三七粉电子鼻信号的特征,5 种特征分述如下:
1)INV:是传感器响应信号曲线与X轴组成区域的面积,反映了该传感器对被测对象挥发性成分的总体响应结果,本研究取0~120 s时间区间INV为特征值。其计算公式如下:
式中:i为传感器的序号;f(xi)为第i根传感器的响应曲线函数。
2)ADV:反映了传感器响应曲线变化的快慢程度,直接体现了气敏传感器对气体响应的主流特征信息,取检测时间为0~120 s,计算公式如下:
式中:i为传感器的序号;yj为第j秒时第i根电子鼻传感器的响应值。
3)RSAV:气敏传感器响应曲线存在1 个相对稳态区间,可用此区间的平均值表征稳态特征,本研究选取区间为101~120 s,计算公式如下:
式中:i为传感器的序号;f(xi)为第i根传感器的响应曲线函数。
4)EV:为每条电子鼻响应曲线的最大值和最小值。
5)BFV:曲线拟合方法采用解析表达式逼近离散数据,拟合参数作为特征进行计算。多项式函数(polynomial function,PF)是常用的具有鲁棒性的曲线拟合模型。本研究用二次多项式用拟合第i根传感器的响应曲线,拟合参数的系数用来作为特征值[34],计算公式如下:
式中:i为传感器序号;a、b、c分别为拟合系数。
本研究用以上8 个特征表征单个传感器信号,10 个传感器共80 个特征数据,本实验共有5 种三七粉,每种三七粉有24 个样本,故特征提取后的数据为120×80的特征矩阵。
1.4.12 特征选择
竞争性自适应重加权算法[35](competitive adaptive reweighted sampling,CARS)是一种快速有效的特征选择方法。采用偏最小二乘回归(partial least squares regression,PLSR)系数的绝对值作为每个变量重要性的评价指标,通过自适应重加权采样和指数衰减函数技术进行变量选择,选出具有最小交互验证均方根误差(root mean square error of cross validation,RMSECV)的变量子集作为最优变量集合。
空间变量迭代收缩算法[36](variable iterative space shrinkage approach,VISSA)基于模型集群分析的思想,通过引入加权二进制采样方法(weighted binary matrix sampling,WBMS),提取原始数据集中的子集,建立基于变量子集的PLSR模型,在每轮采样中以RMSECV作为指标对子模型进行排序以获得最优模型,提取出最优模型及新的子训练数据集,重复上述过程,直到所有的变量权重恒定为1或者0,最终得出最优模型,选择出最优的特征变量组合。
迭代保留信息变量算法[37](iteratively retains informative variables,IRIV)是一种通过随机组和考虑变量之间可能的交互作用策略,在对特征变量进行筛选时,IRIV将所有特征变量分为强信息变量、弱信息变量、无信息变量和干扰变量,并在每一次迭代中只保留强信息变量和弱信息变量,直到不出现无信息和干扰变量后才停止迭代。
1.4.13 分类模型
支持向量机[38](support vector machine,SVM)是一种监督式学习的方法,与常用算法相比,SVM通常能够获得较好分类性能。SVM在有限的样本下可以实现准确的状态识别,广泛地应用于统计分类以及回归分析。
最小二乘支持向量机[39-40](least squares support vector machine,LSSVM)是由SVM变化而来。SVM主要是根据监督学习的方法对两种不同类型的样本点进行分类,SVM决策边界等同于最大的边距超平面,它的经验风险值是采用铰链损失函数计算得出,并利用正则化方法进行优化。LSSVM打破了使用铰链损失函数对经验风险值进行求解,而是将SVM中的不等式约束条件转换为简便的等式约束条件,这一改变将使得Lagrange乘子的求解过程变得方便,并将二次规划求解转变为求解线性方程组,使得整个算法的计算过程更加简便。
极限学习机[41](extreme learning machine,ELM)是一种针对单隐含层前馈神经网络(single-hidden layer feedforward neural network,SLFN)的算法。与传统的SLFN训练算法不同,极限学习机随机选取输入层权重和隐藏层偏置,输出层权重通过最小化由训练误差项和输出层权重范数的正则项构成的损失函数,依据Moore-Penrose(MP)广义逆矩阵理论计算解析求出。ELM相比传统的神经网络可在保证学习精度的情况下具有更快的学习速度。
1.4.14 智能优化算法
灰狼优化算法[42](grey wolf optimization,GWO)是受到了灰狼捕食猎物活动的启发而开发的一种优化搜索方法,于2014年被Mirjalili等提出,主要步骤如下:根据优化的问题,设计fitness函数,设置可行域;初始化狼群的个数N,每头狼的位置Xi(i=1,2,...,N),并指定α、β、δ狼的位置,以及它们对应的适应度fα、fβ、fδ=inf;依次更新每头狼的位置Xα、Xβ、Xδ,对于第i头狼,计算其与α、β、δ狼的距离,并产生向三头狼移动的趋势项,不断重复这一步骤直至α狼群的位置稳定。
1.4.2 挥发物分析
挥发物成分定性和定量方法:挥发物各组分的定性主要通过核对计算机质谱库(NIST11.0),以及比较相关参考文献。挥发物各组分的定量采用峰面积归一法测算[43],根据已知质量浓度乙酸辛酯的峰面积计算出三七粉样品中各挥发物质的含量,公式如下:
式中:MX为目标化合物的含量/(μg/kg);AX和Ai分别为目标化合物的峰面积和内标化合物的峰面积;Ci为内标化合物的质量浓度/(μg/mL);10为加入标品体积(μL);0.5为加入样品质量(g);分子上1000代表1 kg,分母1000代表1000 μL。
2 结果与分析
2.1 不同部位三七粉挥发物变化
经G C-M S 联用技术检测发现,5 种不同部位三七粉挥发物共有31 种,包括萜烯类17 种,占比43.51%~56.21%;芳香族化合物2 种,占比13.75%~25.77%;烷烃类8 种,占比1.06%~3.51%;烯烃、酸类和醇类4 种,占比26.86%~39.23%。采用Duncan法进行多重比较,主要的代表性挥发物见表2。
由表2可知,5 种不同部位三七粉的挥发物在成分和含量上均存在差异(P<0.05)。5 种三七粉检测到的挥发物总量相互之间差异显著(P<0.05)(参照总量平均值)。侧根粉未检测出中苯乙酮和γ-依兰油烯成分,主根中未检测出α-杜松烯成分,其余成分在5 种三七粉中均有分布。5 种三七粉相互之间均存在显著差异(P<0.05)的挥发物成分是桉油烯醇和香橙烯,无显著差异(P>0.05)的成分是辛酸。其余萜烯类、芳香族化合物和烷烃成分均存在不同程度的差异(P<0.05)。因此,可以通过电子鼻利用以上化合物含量差异鉴别5 种三七粉。
2.2 不同部位三七粉挥发物变化
从图1可以看出,电子鼻每个传感器对5 种三七粉均有响应,且响应值的变化均不相同。其中传感器S2、S6、S8和S9的响应值变化显著高于其他传感器。传感器S2具有广谱响应性,挥发物含量越大,其响应值变化越大,萜烯类物质在挥发物中含量占比最高,其对S2响应值的变化贡献率最高。5 种三七粉的萜烯类物质在成分和含量上均存在显著差异(P<0.05),总含量大小依次为整根粉、剪口粉、主根粉、侧根粉、须根粉,与S2的响应值变化规律一致。传感器S6对烷烃化合物灵敏,其响应值的变化从大到小依次为主根粉、剪口粉、整根粉、须根粉、侧根粉,GC-MS联用仪分析的结果(表2)显示,5 种三七粉烷烃含量高低与S6的响应值变化规律相同。传感器S8和S9对芳香族化合物灵敏,响应值的变化从大到小依次为整根粉、剪口粉、侧根粉、须根粉、主根粉,GC-MS联用仪分析结果显示5 种三七粉的芳香族化合物在成分和含量上均存在差异(P<0.05),且5 种三七粉芳香族化合物在含量上的差异与电子鼻S8、S9的响应值变化差异相同。由以上各样品的电子鼻传感器的响应曲线差异分析可以表明,电子鼻在不同部位三七粉的鉴别上具有可行性。

图1 不同部位三七粉的电子鼻传感器响应曲线Fig.1 Response curves of electronic nose sensors for five P. notoginseng powders
2.3 特征数据分析
特征变量之间存在高冲突数据会影响特征融合数据的可靠性,继而会影响分类模型建模结果,而Pearson相关系数在度量数据之间的冲突程度上表现良好[44]。以整根粉10 根传感器响应值的INV特征数据和整根粉单个传感器S2响应值的8 个特征数据为例分析特征数据之间的冗余程度。图2是这两种不同维度数据各自的Pearson相关矩阵,其中相关系数的绝对值越接近1,说明二者之间的相关性越大;相关系数的大小在图中用椭圆形球的宽窄和颜色表示,正负用椭圆形球的左偏和右偏表示。由图2A可知,除S7、S9传感器外,其余8 个传感器之间都存在大量冗余信息;由图2B可知,除了最大值特征T4和BFVb特征T7外,其余6 个特征数据之间存在大量冗余信息。所以,需要对特征数据进行特征降维提高分类模型的精度。

图2 整根粉两种不同维度特征数据的Pearson相关系数矩阵图Fig.2 Pearson correlation coefficient matrix of two different dimensional feature data of the whole root powder
2.4 特征数据选择
为了降低特征变量之间数据高冲突风险,剔除特征之间的冗余信息,挖掘具有重要价值的特征参数,本研究采用CARS、VISSA和IRIV对80 个三七粉特征变量进行优选,以提高模型的泛化能力和识别准确率,增强模型的鲁棒性。
2.4.1 基于CARS的三七粉特征选择
在CARS的特征选择过程中,设置蒙特卡罗采样次数为50,采用5折交叉验证的方法建立PLSR模型,以RMSECV最小值确定选择的最优特征组合。三七粉的特征选择过程如图3所示。从图3a可以看出,随着采样次数的不断增加,选择的特征数量逐渐减少,且减少趋势逐渐变缓,体现了CARS在特征选择过程中的“粗选”和“精选”的过程。从图3b可以看出,随着采样次数的增加,RMSECV的值呈现先下降后上升的趋势,在下降的过程中,表明无用信息或者干扰信息正在被剔除,而在上升的过程中,表明有用信息正在被剔除。图3c为特征选择过程中各特征变量回归系数的趋势变化,蓝色星号竖线表示最佳采样位置,此时RMSECV值最低,选择的特征变量组合最优。最终通过CARS筛选出了15 个特征变量。

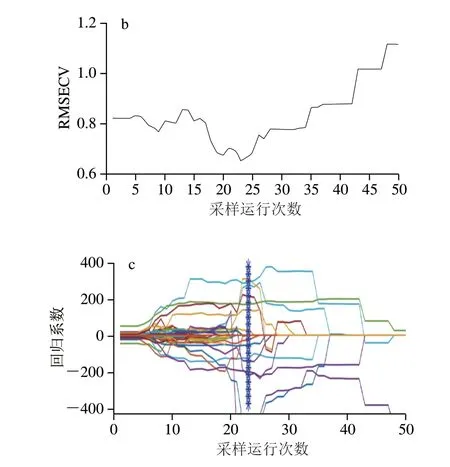
图3 三七粉的CARS特征选择过程Fig.3 CARS feature selection process for P. notoginseng powder
2.4.2 基于VISSA的三七粉特征选择
在VISSA的特征选择过程中,设置每轮WBMS生成的变量个数为5000,子模型的数据集占比为0.05,特征变量的初始权重为0.5,采用5折交叉验证的方法建立PLS模型,根据RMSECV最小值确定最终特征个数。由图4可知,随着选择的特征变量数量的增加,RMSECV的值呈先快速下降再趋于稳定后又上升的趋势。当特征变量个数小于16时,RMSECV较大,表明这些特征变量无法准确表征三七粉特征,当特征变量个数大于28时,RMSECV增加,表明此时的特征变量组合中存在冗余或干扰信息,不利于建模。最终在RMSECV值最小(图4箭头)处选择28 个特征变量。
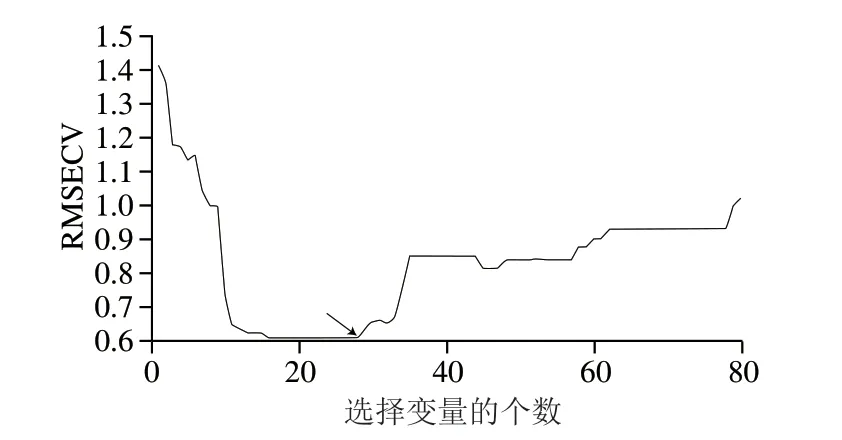
图4 三七粉的VISSA特征选择过程Fig.4 VISSA feature selection process for P. notoginseng powder
2.4.3 基于IRIV的三七粉特征选择
在IRIV特征选择的过程中,采用5折交叉验证的方法建立PLS模型,然后以RMSECV作为评价指标选择特征变量。在每次迭代中,IRIV均会剔除一些无用和干扰的特征变量,保留有用的特征。图5为IRIV选择特征变量数量的过程,经过10 次迭代后,特征变量个数稳定在16 个,再经过反向消除无关变量和干扰变量后,最终保留了14 个特征。
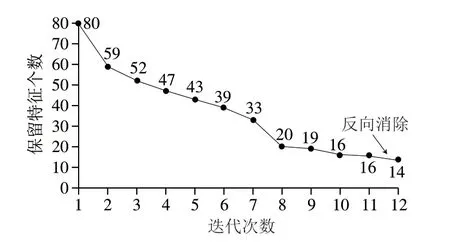
图5 三七粉的IRIV特征选择过程Fig.5 IRIV feature selection process for P. notoginseng powder
2.4.4 3 种算法特征选择结果分析
采用CARS、VISSA和IRIV对特征进行选择后分别得到15、28、14 个特征变量。3 种算法选择后的特征变量分布如图6所示,其中横坐标表示10 根电子鼻传感器响应值的特征变量编号,1~8、101~108分别代表电子鼻传感器S1~S10响应值的INV、ADV、RSAV、最大值、最小值、BFVa、b、c,8 个特征,纵坐标表示特征选择算法的类别。CARS选择的15 个特征中,8 个是BFV特征,占比最大;6 个是EV特征,关于S2、S6、S8、S9四根传感器的特征有5 个,占比为1/3。VISSA选择的特征最多,共28 个,其中16 个是BFV特征,占比最大;剩下的主要是相对平均稳态值和最大值,关于S2、S6、S8、S9四根传感器的特征有14 个,占比为1/2。IRIV选择的特征最少,共14 个,其中9 个是BFV特征,占比最大;而关于S2、S6、S8、S9四根传感器的特征也是9 个,占比大于1/2。综上,3 种特征选择算法选择的特征中占比最大的都是传感器响应曲线的BFV(a,b,c),说明其最能够表征电子鼻信号;其中VISSA、IRIV选择的关于S2、S6、S8、S9四根传感器的特征比例占到了1/2及以上,说明在5 种三七粉的10 根电子鼻响应信号中,这4 根传感器的差异最大,与2.2节的分析一致。

图6 3 种特征选择算法优选后的三七粉特征变量分布Fig.6 Feature variable distribution of P. notoginseng powder optimized by three feature selection algorithms
2.5 三七粉分类模型建立与优化
采用KS(Kennard-Stone)算法对数据进行划分训练集和测试集,将每类三七粉的24 个样本中的16 个作为训练集,其余8 个作为测试集,该方法的优点是能保证训练集中的样本按照空间距离分布均匀,能够增加模型的泛化能力[45]。分别建立基于特征提取数据和3 种特征选择数据的SVM、ELM和LSSVM的三七粉电子鼻信号识别模型,并进行对比,探究3 种分类模型对三七粉的识别效果,以及特征选择算法对降低模型复杂度和提高模型精度的实际效果。其中,SVM和LSSVM的核函数选用径向基核函数,参数c、g、gam和sig2均设为默认值,ELM的最佳隐含层神经元个数设置为100,激活函数选择线性整流函数(ReLU)。同时本研究使用测试集的准确率进行模型评价。各建模方法建模结果如表3所示。

表3 不同建模方法的三七粉识别准确率Table 3 Identification accuracy of P. notoginseng powder by different modeling methods
由表3可知,基于原始数据和CARS、VISSA、IRIV 3 种特征选择算法数据的3 种分类模型的测试集平均准确率分别为72.5%、80%、84.17%和88.33%。基于3 种特征选择数据模型的平均分类精度都高于原始数据,其中IRIV数据的平均分类精度最高,比原始数据提高了15.83%,这验证了特征选择的必要性。对比3 种分类算法,基于原始数据和3 种特征选择数据的LSSVM模型都表现出了最好的效果,基于IRIV数据的LSSVM模型的测试集准确率最高,达到了90%。由图6可知,IRIV选择的关于S2、S6、S8、S9四根传感器的特征占比最高,大于1/2,而这4 根传感器检测的是烷烃、芳香族化合物和挥发物总量,由表2可知,5 种三七粉挥发物总量、烷烃和芳香族化合物均差异显著,这解释了IRIV选择的特征个数最少,但效果最好的原因。综上所述,本研究采用分类效果最好的IRIV-LSSVM模型作为5 种三七粉分类模型。
LSSVM算法分类精度的高低主要取决于其惩罚因子gam和核参数sig2,因此,为了进一步提高模型的分类精度,本研究引入智能优化算法GWO对LSSVM中的gam和sig2进行优化。GWO的最大迭代次数设置为50,种群大小设置为20,参数gam和sig2的搜索范围设置为[2-10,210],经过50 次迭代后,优化模型得出最优解,优化建模结果如表4所示。

表4 基于GWO的IRIV-LSSVM建模结果Table 4 Results of IRIV-LSSVM modeling based on GWO
从表3、4可以看出,优化后分类模型的测试集准确率相较于优化前,提高了7.5%,说明最优惩gam和sig2对提高LSSVM分类精度至关重要。
2.6 基于GWO-IRIV-LSSVM模型的混淆矩阵
如图7所示,其中整根粉、剪口粉、主根粉、侧根粉、须根粉的测试集识别准确率分别为100%、100%、100%、87.5%和100%,平均分级准确率为97.5%;其中,有一个侧根粉样本分错成了须根粉,由图1电子鼻响应曲线结果和IRIV选择的特征结果可以推测是此样本的S2、S6、S8、S9四根传感器的响应曲线与须根粉更相似。以上表明,此模型能够正确地鉴别整根粉、剪口粉、主根粉和须根粉,对市场上用侧根粉和须根粉冒充主根粉和剪口粉提供了一种鉴别方法。

图7 IRIV-GWO-LSSVM的测试集混淆矩阵Fig.7 Test set confusion matrix of IRIV-GWO-LSSVM
3 结论
采用电子鼻和GC-MS对5 种不同部位的三七粉样品进行分析、鉴别。从5 种样品中鉴定出了31 种成分,对其中15 种主要成分进行分析,主要成分在种类和含量上都有差异,特别是挥发物总量、烷烃和芳香族化合物差异显著。通过特征提取和模型优化两种方法提高了电子鼻对三七粉的识别准确率,IRIV选择的特征是能够体现烷烃、芳香族化合物和挥发物总量差异的4 根传感器响应值的特征。最优的GWO-IRIV-LSSVM模型可对道地产区文山5 种不同部位三七粉进行有效区分,测试集准确率为97.5%。证实了一些重要化合物的含量在5 种样品中存在显著差异。该方法可对道地产区文山不同部位三七粉客观、高效、准确地鉴别,可用于道地产区优质三七粉混入劣质三七粉的检测。
猜你喜欢
广西植物(2022年5期)2022-06-18
文山学院学报(2022年2期)2022-05-27
课外生活·趣知识(2022年5期)2022-05-14
中医眼耳鼻喉杂志(2019年3期)2019-04-13
百科探秘·航空航天(2016年6期)2016-12-01
河北果树(2016年2期)2016-08-12
西北园艺(果树)(2016年1期)2016-02-19
山西果树(2015年6期)2015-12-11
食品工业科技(2014年15期)2014-03-11
