
基于Seq2Seq深度学习模型的焦炉煤气发生量预测方法研究
2023-11-06 13:34:42王文婷刘姝君张耀聪杜小泽
兰州理工大学学报 2023年5期
王文婷, 刘姝君, 张耀聪, 杜小泽, 许 潼
(兰州理工大学 能源与动力工程学院, 甘肃 兰州 730050)
钢铁企业生产过程中在消耗煤和焦炭的同时会产生大量的副产煤气.副产煤气作为重要的二次能源,合理地利用和调度可以降低钢厂的能源消耗和煤气放散,并且减轻对环境的污染.副产煤气主要分为高炉煤气、焦炉煤气和转炉煤气,其中,焦炉煤气的热值和使用价值最高.由于副产煤气易产生波动的特点会引起煤气调度分配不当,从而造成煤气放散对环境产生污染[1],所以副产煤气发生量的准确预测不仅可以降低副产煤气放散率,减少大气污染,还可以为煤气调度安排提供指导,对钢铁企业二次能源充分利用有重要意义[2].
目前,对副产煤气发生量的预测有基于数据驱动的传统机器学习、组合预测和深度学习方法.常用的传统机器学习有最小二乘支持向量机(least square support vector machine, LSSVM)[3]、自回归差分滑动平均(autoregressive integrated moving average model,ARIMA)[4]等,传统机器学习的缺点在于模型精度容易受到时间序列自身规律的影响.组合预测模型是将LSSVM、支持向量机分类(support vector classification,SVC)、Elman 神经网络组合起来对副产煤气进行预测[5],缺点在于模型难以挖掘时间序列之间的非线性关系.深度学习可以获取到不同数据类型潜在的特征,在解决非线性关系序列方面有突出表现[6].将深度学习应用于副产煤气发生量的预测,可以一定程度提高预测的精度,早期有学者利用误差反向传播神经网络(back propagation,BP)模型[7-8]对副产煤气进行预测.李志刚等[9]发现在副产煤气预测中利用长短期记忆神经网络(long short-term memory,LSTM)可以有效提取时间序列的历史信息.Greff等[10]指出在小规模数据任务中门控循环单元(gated recurrent unit, GRU )相比LSTM性能并无降低,并且随着参数的减少运算速度更快.Shahid等[11]将GRU应用到了时间序列预测.由于上述深度学习模型都只能应用于输入和输出定长的时间序列预测,所以将机器翻译[12]中常用的序列到序列(sequence to sequence,Seq2Seq)结构应用于时间序列预测可以处理不定长序列的预测问题.Jin等[13]解决了不定长时间序列的预测问题,并提高了对未来较长时间段的预测精度.目前为止,Seq2Seq结构已被广泛应用于电力系统负荷预测[14-15]、水质预测[16]、交通流量预测[13,17]、空气质量预测[18-19]、温度预测[20-21]、网页流量预测[22-23]、股票预测[24]等时间序列的预测.相比传统机器学习和典型深度学习的预测模型,基于Seq2Seq结构的预测模型在精度和鲁棒性方面都表现优越,然而在副产煤气预测的相关研究中暂无Seq2Seq结构的应用.因此,本文选择Seq2Seq结构进行建模,实现对焦炉煤气发生量的预测.
1 模型构建
1.1 LSTM长短期记忆神经网络

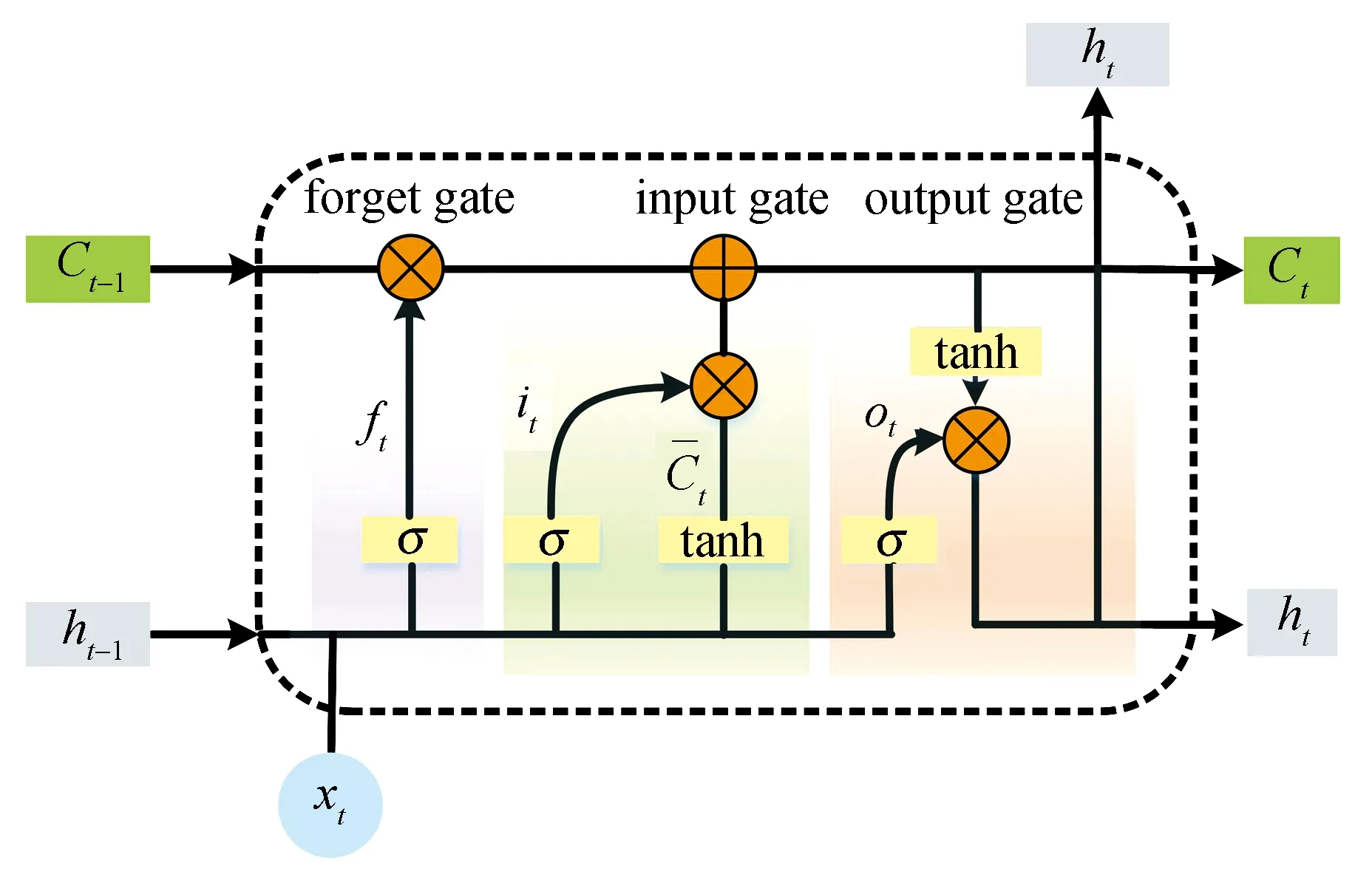
图1 LSTM结构图
1.2 GRU门控循环单元
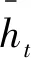
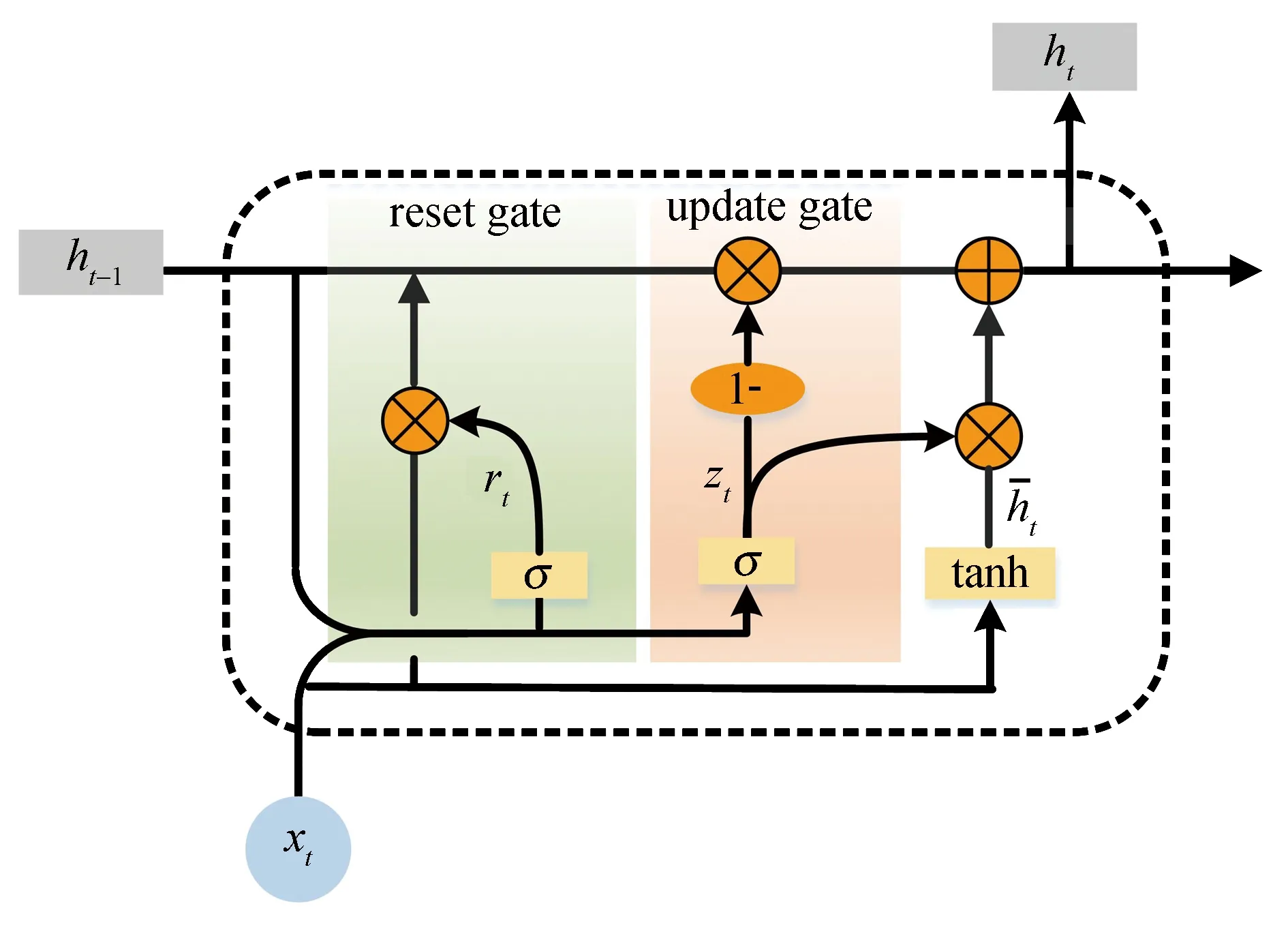
图2 GRU结构图
1.3 LSTM2GRU预测模型
Encoder-Decoder是近年来深度学习中热门模型框架,它不是具体的算法,而是算法框架.可以将其他深度学习算法套用于Encoder-Decoder框架,并且应用在各种领域之中.Encoder-Decoder框架由编码器(encoder)、语义向量(C),解码器(decoder)组成.
Seq2Seq结构是基于Encoder-Decoder框架的,可以把一个序列通过映射转化成另一个序列,其中2个序列的长度不同.Seq2Seq结构可以完成机器翻译(machine translate)、对话生成(dialogue generation)和时间序列预测(time series forcasting)等任务.Sutskever等[29]和Cho等[30]将Seq2Seq结构应用于机器翻译的相关任务中,与循环神经网络相比其最大优势是可实现序列的转化[31].
本文所提LSTM2GRU模型是指基于Seq2Seq结构的深度学习模型,编码器为LSTM,解码器为GRU.设输入序列X=(x1,x2,…,xn),输出序列Y=(y1,y2…,ym),那么Seq2Seq结构的主要原理为Encoder端将X序列转化为固定长度的语义向量C,Decoder端将固定长度的语义向量C转化成Y序列后输出,X序列和Y序列具有不同的长度.因此,Seq2Seq结构有效地结合了Encoder-Decoder框架对输入、输出序列长度没有限制的特点,可建立不同输入、输出序列长度的数据模型.将Encoder-Decoder框架应用于时间序列的预测领域,输入不同长度的时间序列数据,得到不同输出长度的预测数据,经研究证明该模型可以有效地进行时间序列数据的预测[32].其中,解码器每个单元从输入序列的时刻提取特征,聚合信息后通过隐状态传递到序列的下一个单元;编码器产生的最终隐状态代表整个输入序列的编码,目的在于封装所有输入元素信息,帮助解码器得到准确预测;而解码器的单元将解码器所提取特征和最后所获取隐状态经拼接后得到最终预测结果.
图3为本文所构建的LSTM2GRU模型结构图,选用单层LSTM作为编码器,双层GRU作为解码器.设模型输入序列时间步长为n,输出序列时间步长为m,那么编码器端输入、输出序列分别为

图3 LSTM2GRU结构图
编码器每个神经元的隐状态ht依赖于当前神经元的输入数据xt、之前神经元隐状态ht-1和细胞状态ct-1,即
ht=LSTMenc(ht-1,xt,ct-1)
(3)
式中:ht-1、ht分别为t-1、t时刻编码器中LSTM神经元隐状态;xt为t时刻的输入数据;ct-1为t-1时刻LSTM神经元细胞状态.
解码器经过编码器n个时间步长的更新后,输入序列X解码器编码为隐状态hn.由于GRU相对LSTM少了1个门,所以比LSTM少了1个细胞状态,那么解码器的隐藏层和输出分别为
式中:h′t-1和h′t分别为t-1和t时刻解码器中GRU神经元隐状态;yt-1为上一时刻的输出;C为经编码器LSTM最后生成的语义向量.
2 实验验证
2.1 数据来源
本文样本数据均采集于济南某钢铁企业.采集数据包括焦炉煤气发生量、焦炉煤气压力、集气管温度、集气管压力等12种工艺参数,数据样本采集时间间隔为1 min,样本总量为10 800个.
2.2 数据预处理
2.2.1异常数据处理
由于实际生产的数据受到各种外界因素的影响会直接造成采集数据的偏离,所以为减少异常数据对预测模型精度的影响需对数据序列进行异常值处理.本文首先根据箱线图判别出极端异常值,然后进行均值插补处理.此外,突变异常数据在某个或几个数据点出现幅值突增的跳变,表现为较大的数值,因而需要既不影响大部分正常数据又能有效检测出异常值的方法.本文针对突变异常数据采用基于滑动窗口的hampel滤波方法.
以焦炉煤气发生量数据为例,处理前、后的数据对比结果如图4所示.原始序列有许多的极端值和异常值,经数据预处理后,数据中许多极端值和突变值被替换.

图4 原始数据与处理后数据局部对比
2.2.2数据归一化和数据集划分
由于原始样本数据中量纲差异较大,所以导致模型在训练时难以收敛.为防止大数值掩盖小数值的数据特征,需进行归一化处理,使得模型的输入数据规约至[0,1].归一化公式为
(6)
式中:x′为原始数据;X′为归一化处理后的数据;x′max为原始数据中最大值;x′min为原始数据中最小值.
本文数据集被划分成80%训练集和20%测试集.
2.3 特征参数选取
炼焦工艺过程具有十分复杂的物理化学反应,工艺状态参数和炉体本身参数高达几十种,具体哪些参数可以用来预测焦炉煤气发生量还有待研究.因此,在建立模型之前需要对参数进行筛选,通过分析各参数与焦炉煤气发生量之间的相关度,选取相关度较高的影响参数,以此来降低数据量,提高计算效率,保证模型的高效运行.本文使用灰色关联度分析焦炉煤气压力、集气管温度、集气管压力等工艺参数与焦炉煤气发生量的相关性,选取关联度较大的前6个工艺参数,结果如表1所列.

表1 焦炉煤气发生量的影响因素
2.4 模型参数设置
基于Tensorflow深度学习框架建立LSTM2GRU模型和对比深度学习模型.经验证,与单层神经网络相比,堆叠神经网络可以提高模型的学习能力,然而网络参数会随之增加,这对模型的泛化能力和训练时间都有直接影响.考虑到数据总量,本文所提模型中解码器采用单层LSTM结构,隐藏层节点为64;编码器采用双层GRU结构,隐藏层节点为64和32.选用Relu为激活函数,MSE为损失函数,RMSprop为优化器,batch_size为128,学习率为0.001,epoch为100.
2.5 评价指标
钢铁企业焦炉煤气预测属于时间序列预测,即为回归问题.本文采用均方根误差(root mean squard error, RMSE)和平均绝对误差(mean absolute error, MAE)作为评价预测效果的指标,即
式中:yn为真实值;On为模型输出的预测值.
RMSE表示在整个数据样本上衡量yn和On之间的偏差,其量纲与数据集一致;RMSE越小,模型的预测性能越好,精度越高.MAE表示绝对误差的平均值,当yn和On基本一致时,模型最好;MAE越小,模型的性能越好.本文所有误差指标计算均在反归一化基础之上.
2.6 焦炉煤气发生量预测
为研究LSTM2GRU模型的预测性能,在数据集相同时使用4种对比模型对焦炉煤气发生量进行预测,即GRU模型、LSTM模型、编码器和解码器为GRU的Seq2seq结构(GRU2GRU)模型、编码器和解码器为LSTM的Seq2Seq结构(LSTM2LSTM)模型.本文采用单步预测和多步预测2种方式:单步预测又称时点序列,即输入t时刻之前的煤气序列,预测t+1时刻的发生量,因而单步预测对于钢厂瞬时煤气波动的预防有重要作用;多步预测又称时期序列,即输入t时刻之前的煤气序列,预测t+1、t+2、…、t+n时刻的发生量,因而多步预测对于制定调度计划具有深远的指导意义.综上所述,2种预测方式对于实现煤气调度都有重要的意义.
2.6.1单步焦炉煤气发生量预测
以t-15到t的15个时间步长作为输入序列,对焦炉煤气发生量进行单步预测,预测t+1时刻的波动趋势.选取测试集前200个时间点的预测结果进行可视化,4种对比模型和LSTM2GRU模型的预测效果如图5所示.可以看出:1#焦炉在样本150~200时煤气波动较为频繁,35、60、125样本附近有明显的峰谷点;2#焦炉在样本125~175时煤气波动较为频繁,10、75、175样本附近有明显的峰谷点.此外,GRU和LSTM的拟合曲线偏离程度都较为明显,并且较多峰谷处、波动频繁区间的预测点拟合程度并不理想.
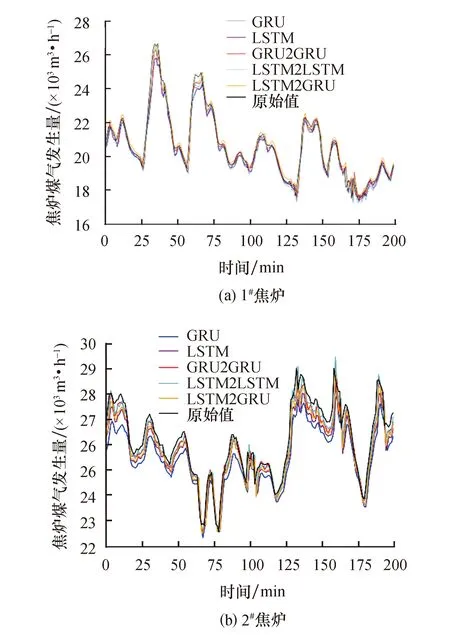
图5 不同模型单步预测拟合图
基于Seq2Seq结构的相关模型在峰谷处、波动频繁区间的拟合程度有很大改善,相比LSTM、GRU等单一时间序列预测模型可以有效提取出数据的动态特征,挖掘数据中蕴含的信息.Seq2Seq结构较传统深度学习模型可获取更多数据本身的潜在规律和数据之间的潜在联系,从而得到精准的预测.LSTM2GRU模型在预测趋势较规律的1#焦炉和走势浮动相对较大的2#焦炉时都有明显的优势,可以较为完整地反映出焦炉煤气的基本趋势.相比对1#焦炉的预测,LSTM2GRU模型对2#焦炉的预测稍显逊色,但总体来看LSTM2GRU模型仍然比其他模型具有更好的预测性能、更明显的优势.
表2为不同模型单步预测误差的对比情况.可以看出,LSTM2GRU模型的RMSE和MAE均小于其他模型的.在1#焦炉数据集上,LSTM2GRU模型的RMSE降低13.514~137.853,MAE降低6.179~102.755;在2#焦炉数据集上,LSTM2GRU模型的RMSE降低78.619~330.251,MAE降低50.803~173.754.因此,本文所提LSTM2GRU模型相比其他模型可以更好地学习变量之间复杂的非线性关系,在单步预测方面具有明显的性能优势.
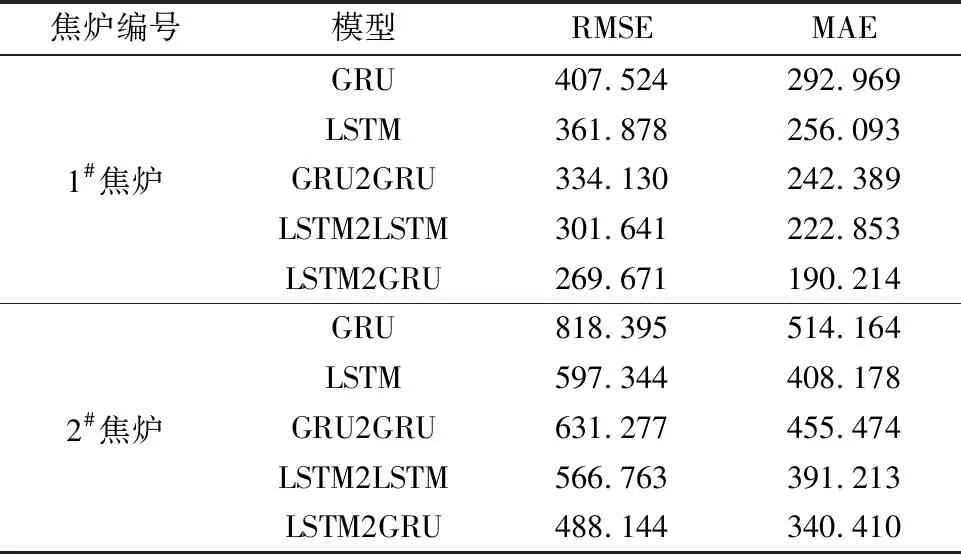
表2 不同模型单步预测误差对比
2.6.2多步焦炉煤气发生量预测
以t-15到t的15个时间步长作为输入序列,对焦炉煤气发生量进行多步预测,分别预测t+1、t+2、t+3、t+4和t+5时刻的波动趋势.选取测试集前200个时间点的预测结果进行可视化,4种对比模型和LSTM2GRU模型的预测结果如图6和图7所示.其中,图6为1#焦炉的拟合曲线,图7为2#焦炉的拟合曲线.可以看出:多步预测会导致误差累积效应的产生,即随着预测步长的增加误差逐渐增大,从而模型预测的质量下降;当超前1步预测时,LSTM2GRU模型预测曲线的拟合程度与其他模型的差异并不明显,但仍精度最高;随着预测步长的增加,LSTM2GRU模型预测曲线与原始曲线的整体变化趋势最为接近,减缓误差累积的效果最为显著.此外,由于煤气序列波动差异和预测时间变长等潜在因素的影响,不同序列的预测效果有所不同,对1#焦炉的整体预测效果会好于2#焦炉,所以模型预测的稳定性还需进一步提高.
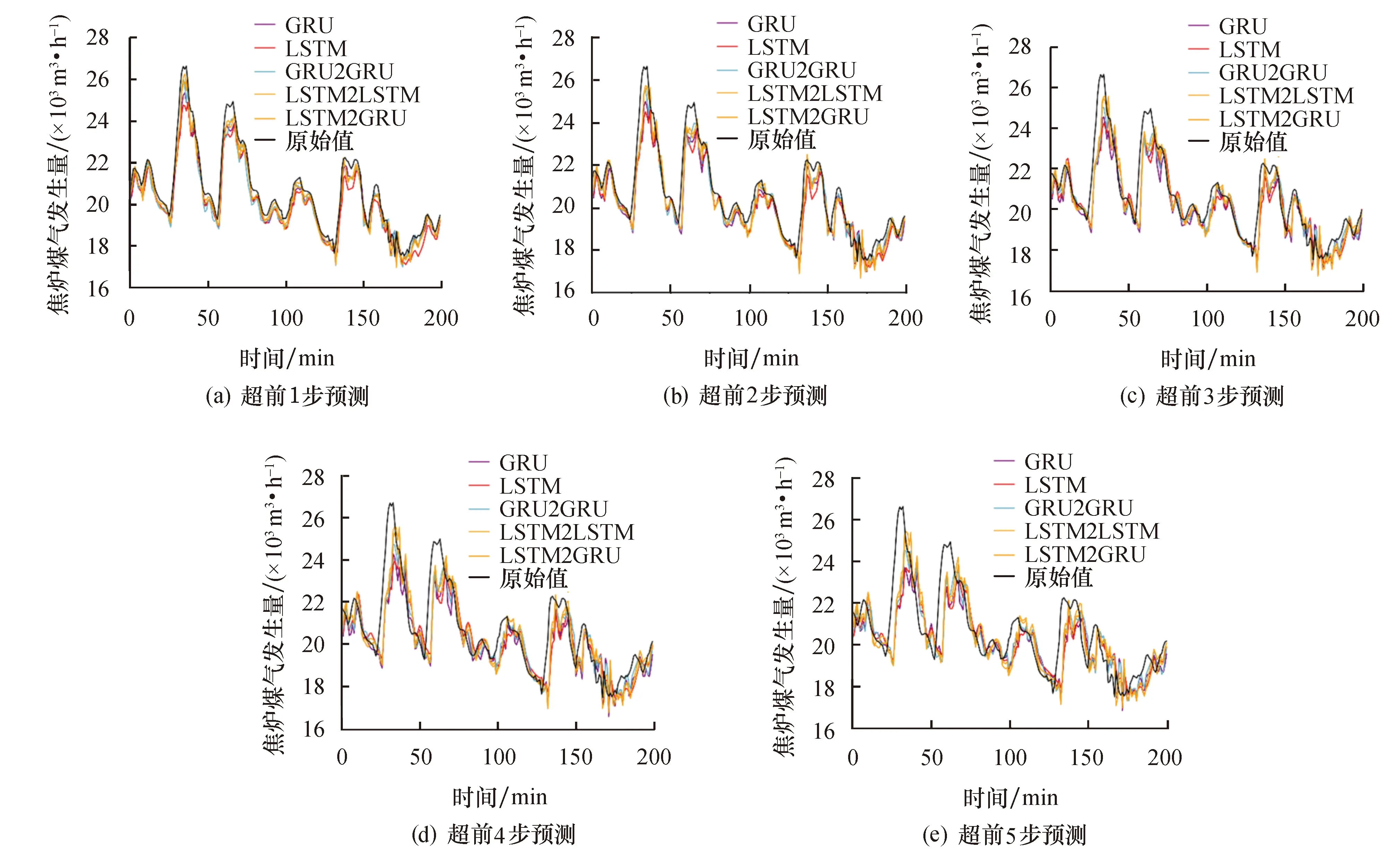
图6 1#焦炉不同模型的多步预测拟合图
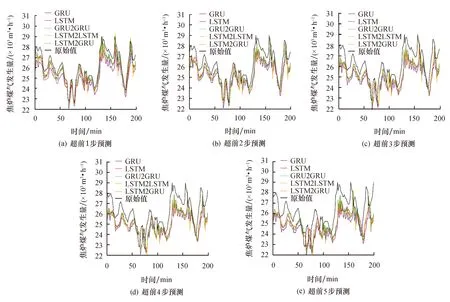
图7 2#焦炉不同模型的多步预测拟合图
表3和表4分别为1#焦炉和2#焦炉在不同模型多步预测时误差的对比情况.可以看出:预测步长对预测结果的精度影响较大,各模型的RMSE、MAE均在逐步增加,前一步预测对后一步产生影响,因而RMSE、MAE均呈现逐步递增的趋势.通过对比发现,基于Seq2Seq结构的模型误差值均小于对应的GRU、LSTM单一模型的误差值.由此说明,Seq2Seq结构可以减缓模型随着时间步长增加而导致误差累积的趋势,从而实现较为精准的焦炉煤气发生量多步预测.同时,LSTM2GRU模型误差指标RMSE、MAE均明显小于其他2种基于Seq2Seq结构的模型,在预测过程中性能的下降趋势相比较为缓慢.

表3 1#焦炉多步预测误差对比

表4 2#焦炉多步预测误差对比
超前预测5个时间步长,根据表3中1#焦炉的误差数值可知:LSTM2GRU模型的RMSE为844.8,MAE为636.724;LSTM2LSTM模型的RMSE为892.936,MAE为674.281;GRU2GRU模型的RMSE为911.419,MAE为684.733.LSTM2GRU模型的RMSE相比LSTM2LSTM模型和GRU2GRU模型分别下降了5.3%和7.3%,MAE分别下降了5.6%和7%.根据表4中2#焦炉误差数值可知:LSTM2GRU模型的RMSE为1 181.580,MAE为747.129;LSTM2LSTM模型的RMSE为1 299.034,MAE为809.536;GRU2GRU模型的RMSE为1 307.922,MAE为810.341.LSTM2GRU模型的RMSE相比LSTM2LSTM模型和GRU2GRU模型分别下降了9%和9.7%,MAE分别下降了7.7%和7.8%.因此,基于Seq2Seq结构的模型可获取更多数据本身的潜在规律和数据之间的潜在联系,可以有效处理不定长序列,LSTM2GRU模型相比其他模型更适合长尺度时间序列的预测.
2.6.3模型预测耗时
由于GRU相比LSTM少1个门函数,参数数量较少,所以理论上GRU的训练时长要短于LSTM的.为研究本文所提模型的预测效率,在相同的收敛次数下,将LSTM2LSTM模型和LSTM2GRU模型的预测耗时进行对比,各模型的预测耗时如表5所示.可以看出:LSTM2GRU模型不管进行单步或多步预测,还是在波动趋势差异较大的序列进行预测,训练时长相比LSTM2LSTM模型均明显缩短.因此,LSTM2GRU模型的预测效率具有明显优势,在实际应用中可为调度工作安排预留充足的反应时间.

表5 模型预测耗时
3 结论
为提高焦炉煤气发生量预测的准确性,本文结合Encoder-Decoder框架处理不定长序列的优势提出了编码器为LSTM、解码器为GRU的Seq2Seq结构深度学习预测模型,并在2组数据集上分别与GRU、LSTM、GRU2GRU、LSTM2LSTM预测模型进行了单步预测和多步预测的对比分析.得出结论如下:
1) 采用Seq2Seq结构可以有效提取数据的隐含信息,增强模型的拟合效果;在预测的准确性方面,较GRU、LSTM模型具有很大提升,证实了Seq2Seq结构的优越性.
2) 单步预测时,LSTM2GRU模型对原始趋势中峰谷值的拟合度最好,拟合结果偏离程度最小,误差指标最小,证明了该模型比其他模型可以更好地学习变量之间复杂的非线性关系,在单步预测方面具有明显的性能优势.
3) 多步预测时,LSTM2GRU模型受误差累积的影响最小;在相同时间步长下,误差增加的幅度最小,预测结果最佳,证明了该模型在多步预测方面具有较高精度.
然而,由于钢铁厂智能化改造仍在进行,目前数据获取有限特征数量并不多,所以需要监测更多相关因素的工业数据序列,探究模型鲁棒性和超参数优化,致力于模型在钢铁行业实际生产过程中切实应用.
猜你喜欢
四川化工(2022年1期)2022-03-12 04:25:34
四川化工(2022年1期)2022-03-12 04:22:34
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
建材发展导向(2021年14期)2021-08-23 00:56:18
南方农业·中旬(2021年2期)2021-06-24 08:17:56
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
昆钢科技(2021年6期)2021-03-09 06:10:26
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
现代农业科技(2018年22期)2018-01-15 11:44:10
