
数据挖掘技术的微信影响力预测模型①
2023-11-05 11:00林恭兴
佳木斯大学学报(自然科学版) 2023年5期
林恭兴
(泉州工艺美术职业学院,福建 泉州 362500)
0 引 言
在网络发展快速环境中,微信增长趋势十分显著,其对人们生活模式、工作模式均存在不可忽视的作用。微信影响力预测,能够准确分析微信平台中某个文章、某个事件的影响力[1]。对此,本文构建一种基于数据挖掘技术的微信影响力预测模型,将数据挖掘技术引入微信影响力预测问题中,能够充分优化微信影响力数据挖掘的全面性[2]。
1 数据挖掘技术的微信影响力预测模型
1.1 粗糙集理论和BP神经网络的微信传播数据挖掘
基于粗糙集理论的数据挖掘通常为属性规约,属性规约的流程是:先使用判断矩阵得到属性规约的关键之处,之后通过规约算法运算规约集,按照某类评价标准设置最优规约集[3]。粗糙集约简的停止条件或称为BP神经网络训练数据数目选取条件为粗糙集理论的难点。训练数据数目选取对BP神经网络训练耗时存在较大干扰[4]。现在还没有一种合理的训练数据数目设定方法,只有一种粗略计算方法,训练数据数量和连接权数量相比,差异显著。
可用于预测微信影响力的训练数据数目选取和神经网络准确率存在不可分离的关系。一般情况中预测微信影响力的数据学习能力主要通过均方根误差来描述。均方根误差函数是:
(1)
式(1)中,训练集的样本eji数目设成n;神经网络的输出单元xji数目设成m。
按照公式(1)显示,如果预测微信影响力的训练数据数目增多,误差降低,因此,增多用于预测微信影响力的数据数目能够降低误差。此时,用于预测微信影响力的训练数据数目每提升一倍,网络训练耗时也提升一倍。为此,使用代价函数克服此问题。代价函数能够体现用于预测微信影响力的训练数据数目与误差间关联性。将误差函数变为:
(2)
式(2)中,引进一种自变量Y,Y值是1时,函数保持不变,代价函数是:
(3)
式(3)中,y表示系数,取值范围不小于1,x描述代价指标。
获取代价函数后,便能够获取用于预测微信影响力的训练数据选取凭据,还能够获取粗糙集规约停止凭据。针对存在多个属性的微信数据样本,将最优代价设成用于预测微信影响力的训练数据选取凭据。针对数据挖掘而言,微信数据存在海量性,因此,为了顾及到某些例外的状况,本文设置了数据量低、条件属性低时的选取标准。
1.2 基于主成分分析的微信影响力预测模型
微信影响力预测并不是针对某一个小变量实施评价预测,属于一种宏观变量预测。目前使用较多的预测方法均以指标加权形式实现。为了防止出现权重设定缺乏客观性的情况,使用主成分分析方法,将上小节挖掘出的有效微信数据实施降维操作,获取有效主成分,运算每个微信数据的变量在主成分中分数,判断其对微信影响力的影响程度。
1.2.1 数据标准化
因为在分析微信影响时,差异数据间的量纲将对主成分分析结果存在较大干扰,所以,将获取的全部有效微信数据实施标准化无量纲操作,使用Z-Score法实施标准化,则有:
(4)
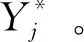
1.2.2 主成分分析法
十九世纪时Pearson提出主成分分析法,该方法为了降低数据维数,将协差阵实施特征分析。简而言之是使用几种主成分描述多种变量的内部特征,不但对微信数据原始变量信息不存在干扰,且能够保障微信数据原变量的全部特征[5]。详细运算方法是:
(5)
式(5)中,Xm,Yq依次描述第m个主成分、第q个变量;hmq,Hm′表示微信影响力传播时间矩阵系数。
使用新变量取代原始的10种微信数据变量Y1,Y2,…,Y10,当中第一主成分X1需要具有充分的原变量特征。若第一主成分中原变量特征较少,则使用第二主成分X2,若第二主成分中原变量特征较少,则使用第三主成分X3。
主成分数目需要按照每个主成分累计方差贡献度α实现判断。一般状况中,累计贡献度提升为较大的百分数便可停止。则:
(6)
式(6)中,每个主成分相应的微信数据特征值设成θ。
将特征值最大的前10种数据类型设成微信影响力预测指标,并将特征值排列前三的预测指标设成主成分因子。
1.2.3 整体预测
通过主成分分析将设置的预测指标实施信息总结后,便能按照获取的预测指标实施整体预测。将三种核心预测指标依次设成头条热搜度、微信文章点击率以及微信文章推广率,再通过主成分的方差贡献度判断其主成分权数,以此能够提升指标设定的客观性,优化微信影响力预测精度。
将预测指标主成分的特征根实施归一化并设置权重ϖ:
(7)
然后建立整体预测函数实现微信影响力整体预测:
S=ϖ1X1+ϖ2X2+ϖ3X3
(8)
2 实验结果及分析
实验数据是针对个人微信账号与某些知名的公众微信账号为着手点,将微信平台里影响力预测的关键词设成“校园暴力”,并挖掘有关“校园暴力”的微信文章传播信息。预测中用到的指标由头条热搜度、微信文章点击率以及微信文章推广率构成,微信影响力整体预测的样本总值是5327条,排除已删除内容和与关键词无关的信息后,有效数据是5185条。此5185条微信的发布时间是2019年6月8日~2019年7月9日。由于微信影响力预测的运算公式都是正值,所以对微信影响力预测值的标准化方式为:
(9)
式(9)中,微信影响力最高值与最低值依次设成max(ϑj),min(ϑj)。
实验把微信影响力设定在0~100之间,通过运算获取的微信影响力数值和100相乘,便能够获取新的微信影响力值,取值区间是[0%,100%]。有关 “校园暴力”微信文章影响力实际值见表1:
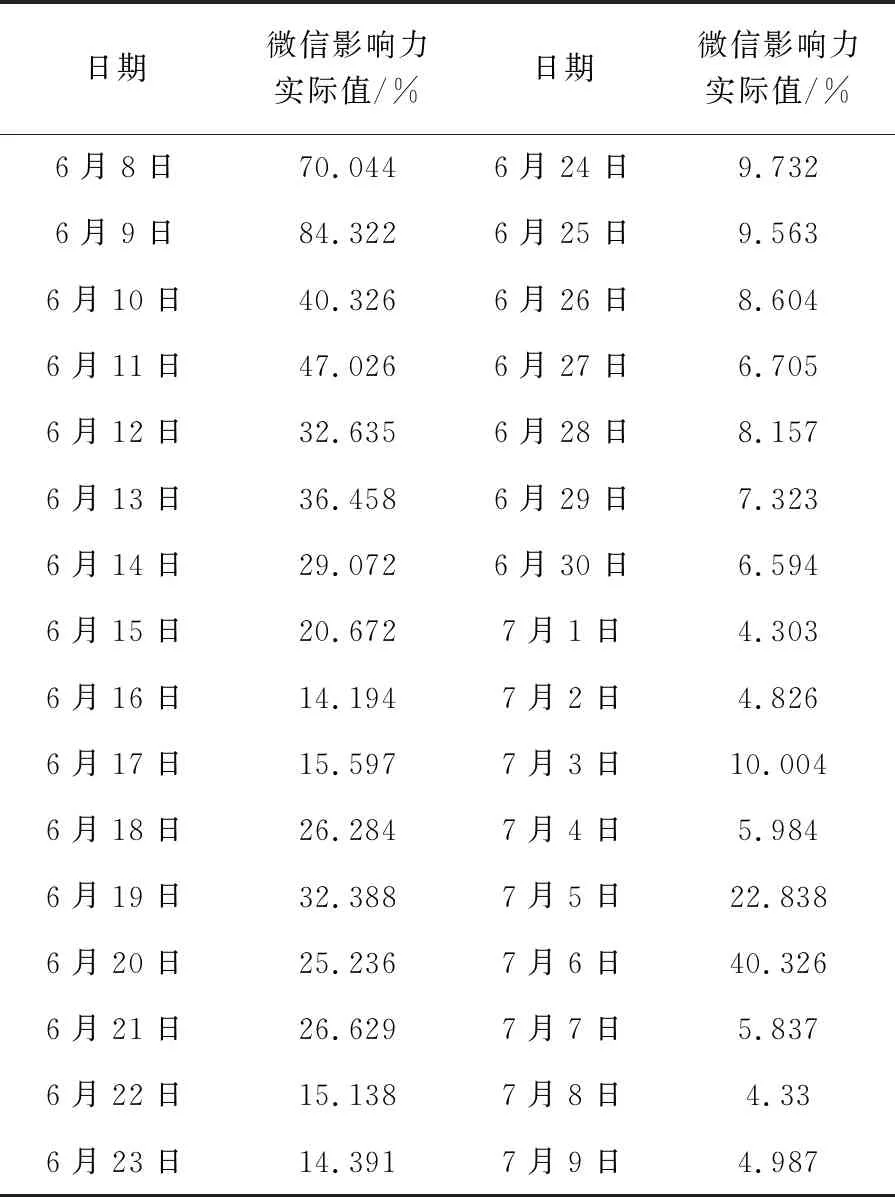
表1 有关 “校园暴力”微信文章影响力实际值
本文模型预测结果和实际结果的对比见图1:由图1可知,本文模型预测的微信影响力和实际高度吻合,预测误差最大值仅有1%,表示本文模型预测结果可信。
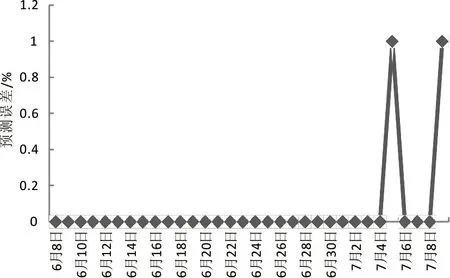
图1 本文模型预测精度
为了测试本文模型的预测性能,分析本文模型、基于加权K-Means和局部BPNN的影响力预测模型、基于回归树与衰减函数的在线影响力预测模型在预测关键词是“校园暴力”的微信文章影响力时,对微信“校园暴力”文章影响力数据挖掘的查全率,结果见图2。分析图2可知,三种模型对比之下,本文模型的查全率最高,高达0.9899,两种对比模型的查全率低于本文模型。
分析三种模型对微信影响力预测时,对关键词是“校园暴力”微信文章的头条热搜度、微信文章点击率以及微信文章推广率三种预测指标的查准率,结果见图3。由图3可知,本文模型的查准率占据一定优势,对比模型的查准率始终低于本文模型,本文模型查准率高达0.9934。
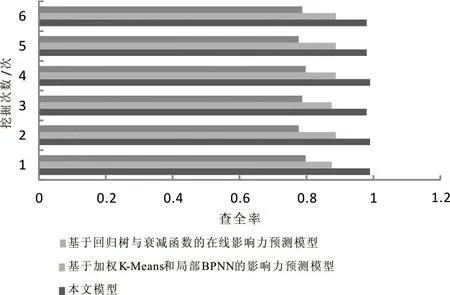
图2 三种模型查全率对比结果
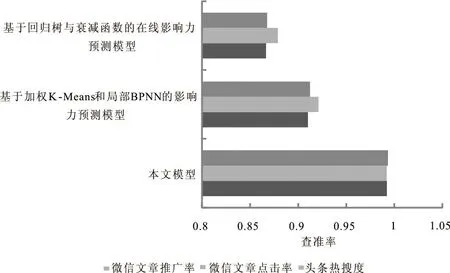
图3 三种模型查准率对比结果
3 结 论
预测模型利用数据挖掘技术中的粗糙集理论、BP神经网络以及主成分分析技术,实现微信数据挖掘、降维以及微信影响力预测。实验采用本文预测模型围绕关键词是“校园暴力”的微信文章进行影响力预测,由此验证了本文模型有效性与使用价值。在未来工作中,将深入优化本文模型中所用的主成分分析法,优化本文模型预测速度,将微信影响力的演化与发展状态实施更进一步的分析与预测。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
大众投资指南(2021年35期)2021-02-16
河北理科教学研究(2020年2期)2020-09-11
NBA特刊(2018年14期)2018-08-13
电力与能源(2017年6期)2017-05-14
人大建设(2017年11期)2017-04-20
信息通信技术(2015年6期)2015-12-26
数学年刊A辑(中文版)(2015年2期)2015-10-30
瞭望东方周刊(2015年12期)2015-04-14
人间(2015年21期)2015-03-11
