
基于机器学习算法的网络货运平台车货匹配预测研究①
2023-11-05 11:00刘存
佳木斯大学学报(自然科学版) 2023年5期
刘 存
(安徽商贸职业技术学院,安徽 芜湖 241000)
0 引 言
随着互联网在各行业渗透力的提升,网络货运平台应运而生,该平台通过互联网,对线下的车源、货源进行整合,并利用有关软件对二者进行匹配,以此解决信息不对称等问题[1]。因此,只有对网络货运平台车货匹配进行精准的预测,根据预测结果合理配置各方资源,才能提升车货匹配效率与成功率,帮助企业提高推送率,改善供需不平衡的问题。机器学习是人工智能发展的重要体现,是通过机器直接从经验(或数据)中学习如何解决复杂的问题,善于处理大量数据,具有学习性强、效率高的特点[2]。因此本文提出基于机器学习算法的网络货运平台车货匹配预测方法,对网络货运平台车货匹配进行精准、有效的预测,实用性强。
1 基于机器学习算法的网络货运平台车货匹配预测方法设计
1.1 网络货运平台车货匹配的特征提取
关于网络货运平台车货匹配的特征提取就是将网络货运平台车货匹配的原始数据利用有关方法转换为特征的过程。对网络货运平台车货匹配原始数据进行特征提取,首先应了解影响车货匹配的有关指标,然后根据实际业务情况,把采集的原始数据转换为符合实际业务特点的特征。
1.1.1 网络货运平台车货匹配特征集构建
网络货运平台车货匹配,主要是指在网络货运平台的作用下,将车主和货主联系在一起,完成货物与车辆的配载。因此,车货匹配成功与否的关键就是车货双方。本文依据影响网络货运平台车货匹配的指标及其相关内容对特征集进行构建。车货匹配的几个主要指标如下:
(1) 载荷量。载荷量即运送本次货物所需运输车的数量。根据该指标可以判断出是否存在超载或多次多辆运输的情况。关于载荷量的公式可以描述为式(1):

(1)
(2) 车长相似度。如果单独分析货主对车辆长度的要求或车主拥有车辆的长度没有实际意义,所以应将二者联系在一起进行分析,通过车长相似度指标便可以实现二者的联系,描述为式(2):

(2)
(3) 车型相似度。该指标主要表现为货主对车型的要求,可分为以下几类,如表1所示。

表1 车型相似度类型
(4) 货主与车主熟识程度。通常情况下,车主对熟悉的货主发出的承运申请具有一定的偏好,该指标可以通过二者在上一年度交易的单量来衡量。
(5) 货物类型。通过该指标可以判断适合运输本次货物的车型以及车主对运送货物种类的喜好。通常情况下这种喜好由收益水平决定,可以利用货物每公里单位运输价格如式(3):
货物每公里单位运输价格=
订单总价格/运输距离/货物重量
(3)
(6) 货物运送地址。该指标关系到货物运输的路线,并与车主喜好有着重要联系。对运输路线进行匹配时,不需要做到精准匹配,可以利用常用的网络地图(如百度地图)进行粗匹配。
根据上述指标并结合具体业务的实际情况便可以构建出网络货运平台车货匹配初始特征集。
1.1.2 网络货运平台车货匹配特征筛选
特征筛选可以通过包装筛选的方式实现,即把网络货运平台车货匹配的所有特征,包装在特定的算法中进行筛选。Lasso回归模型可以将价值不高的特征对应的回归系数压缩为零,所以该模型具有稀疏性,根据这个特性可以挑选出品质较好的车货匹配特征,其模型描述为式(4):
S(w)=‖y-Xw‖2/n+γ‖w‖1
(4)
式(4)中,特征向量用X描述,响应变量用y描述,样本数量用n描述,调节参数用γ描述,回归系数用w描述,L1范数用‖w‖1描述,并将其做为惩罚约束。通过改变不同的γ值,可得到不同的回归系数,当γ足够大时,回归系数就会趋于零,可以将这些趋于零的回归系数对应的特征舍掉,达到网络货运平台车货匹配特征筛选的目的。
1.1.3 网络货运平台车货匹配特征相关性分析
为了得到更为简练且精准的特征,采用皮尔森相关系数分析网络货运平台车货匹配特征相关性,该系数的作用是衡量两个变量之间的线性关系,描述为式(5):
ζXY=cov(X,Y)/(σXσY)
(5)
式(5)中,连续特征变量(X,Y)的协方差用cov(X,Y)描述,标准差用σX和σY描述。
ζXY的取值范围为[1,-1],当ζXY接近0时,其对应两个特征变量的相关性较弱;当ζXY接近1或-1时,其对应两个特征变量的相关性较强。如果两个网络货运平台车货匹配特征具有较高相关性,则说明二者表达的意思相近,可将其中之一舍去。
通过上述方法对网络货运平台车货匹配特征进行相关性分析后,便能够得到最佳特征集,可将其作为网络货运平台车货匹配预测模型的输入,进行车货匹配预测。
1.2 Stacking的网络货运平台车货匹配预测模型
1.2.1 Stacking集成学习预测模型构建
对于单独一个模型来说,在预测精度方面通常会出现边际效用递减的现象[3],为了避免这个现象的发生,本文采用Stacking集成学习模型对网络货运平台车货匹配进行预测,该模型将多种预测方法融合在一起,进而形成一个新的预测模型,这样会得到比单独模型更为优质的性能。关于网络货运平台车货匹配预测的Stacking集成学习模型如图1所示。
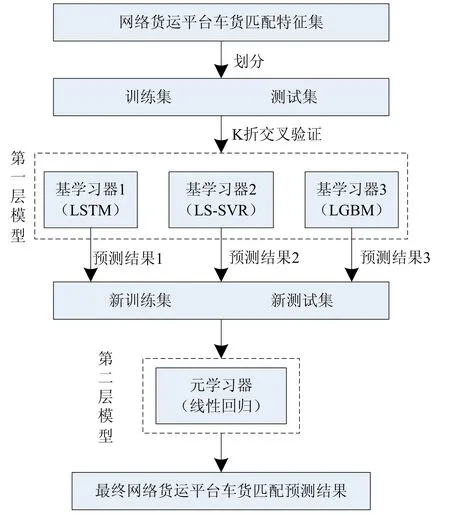
图1 Stacking集成学习模型
该模型首先对获取的网络货运平台车货匹配特征集进行划分,并对第一层模型的基学习器进行训练与测试,得到所有基学习器的预测结果,通过这些结果生成新的数据集,输入至位于第二层模型的元学习器中再次进行训练与测试,最后通过第二层的模型输出关于网络货运平台车货匹配的预测结果。
关于网络货运平台车货匹配预测的Stacking集成学习模型中,第一层模型选择的基学习器分别为长短时记忆网络算法、最小二乘支持向量回归机算法和轻型梯度提升树算法;第二层元学习器采用线性回归算法。各个学习器原理如下:
(1)长短时记忆网络(LSTM)算法
LSTM是一种深度学习的神经网络算法,由输入、输出及隐含三个层次构成,其优势在于可以较好地管控信息存储状态。LSTM拥有多个记忆单元,利用输入门、遗忘门以及输出门完成对记忆单元的阅读与编辑,并通过相关函数获取隐含层的状态,在预测问题中较为常用。设定t时刻网络货运平台车货匹配的输入特征分别为LSTM单元输入向量xt、输出向量ht-1和神经元状态向量ct-1。LSTM各个门利用输入特征,通过逻辑推理与非线性变换方法获取预测值,各网络货运平台车货匹配特征之间的关系可以描述为式(6):
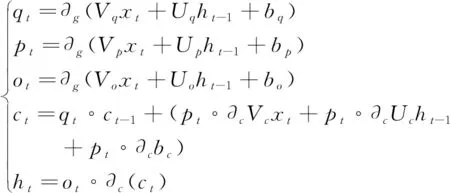
(6)
式(6)中,输入门、遗忘门和输出门的激活向量分别用pt,qt和ot描述;权重矩阵用V,U描述,偏置向量用b描述,V,U,b三者下标p,q和o分别对应输入、遗忘、输出门,tanh函数与sigmoid函数分别用∂g和∂c描述。
对LSTM的结构进行设计后,通过误差反向传播方法训练LSTM,损失函数则采用均方误差。
(2)最小二乘支持向量回归机(LS-SVR)模型
LS-SVR是支持向量机的扩展,可以将二次优化问题转换成线性方程组求解问题,具有计算简单、收敛速度快的优点,在各类预测问题中均有较好表现。设定网络货运平台车货匹配特征样本集为z={(x1,y1),…,(xm,ym)},(xi,yi)∈Zi=1,2,…,m,该样本的最小二乘向量机回归描述为式(7):
(7)
式(7)中,超平面法向量用v描述,惩罚系数用C描述,偏置向量用l描述,松弛系数用e描述,转置用T描述,映射用φ描述。
为获取目标函数最小值,建立拉格朗日函数描述为式(8):
(8)
式(8)中,回归系数用α=(α1,…,αi,…,αm)描述。
为了求取最优解,将上述优化问题转换为线性方程组的求解问题,描述为式(9):
(9)
式(9)中,y=(y1,y2,…,ym)T,Q=(1,…,1)T,H=φT(x)φ(x′),单位矩阵用I描述。
通过对式(9)进行求解,可以得到α和l值,在此基础上构建关于LS-SVR的预测模型,用于预测网络货运平台车货匹配情况,描述为式(10):
(10)
式(10)中,核函数用k(xi,xj)描述。
(3)轻型梯度提升树(LGBM)算法
LGBM算法在传统梯度提升树算法基础上进行了完善,在存储与运算速率上更具优势。该算法中寻找最佳分裂节点是关键,运用直方图的方法便可以对该节进行获取。首先把输入的连续网络货运平台车货匹配特征数据进行离散化操作,使其成为数量是E的整数,随之建立边长是E的直方图,在对特征数据进行遍历时,只需计算所有离散值在该直方图中累积的量即可。LGBM在寻求分裂节点时,会将直方图内全部节点根据权重进行降序排列,这样可以迅速且精准地找到最佳分裂节点,通过该分裂节点建立提升树,进而对网络货运平台车货匹配问题进行预测。
(4)线性回归算法
线性回归主要通过数理统计中的回归分析,确定自变量及预测量之间相互依赖的程度,根据二者的依赖程度对相关问题进行预测。为了更好地解决实际问题,通常采用具有多个自变量的多元线性回归模型来解决问题,其一般表达式可以描述为式(11):
(11)
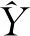
由于网络货运平台车货匹配预测样本中包含的特征较多,因此可以通过矩阵的方式对多元线性回归模型进行描述式(12):
(12)
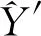
1.2.2 网络货运平台车货匹配预测实现
基于Stacking集成学习模型的网络货运平台车货匹配预测流程如下:
(1) 确定Stacking集成学习模型结构。选择LSTM,LS-SVR和LGBM作为Stacking集成学习模型中第一层模型的基学习器,选择线性回归算法作为第二层模型的元学习器。
(2 )将输入至Stacking集成学习模型中的网络货运平台车货匹配预测特征集分成原始训练集 与测试集T二部分。
(3) 通过K折交叉验证方法对Stacking集成学习预测模型中的基学习器进行训练,即将D平均分为K份,表示为(D1,D2,…,DK),每一个基学习器将其中的一份当作K折测试集,其余K-1份当作K折训练集。利用K折训练集,对各个基学习器进行训练,利用K折测试集获得预测结果,并将各个基学习器得出的预测结果进行整合,形成新的数据集,作为元学习器的训练集 。
(4) 利用所有基学习器对 进行预测,并求取预测结果的平均值,获取到集合(T1,T2,…,TK),将该集合当作元学习器的测试集T′。
(5) 第二层模型中的元学习器对训练集D′和测试集T′分别进行训练与测试,进而得到最终的网络货运平台车货匹配预测结果。
2 性能测试与分析
承运订单成交量是衡量车货匹配情况的主要指标,为了验证本文方法的有效性,实验对某网络货运平台未来一周内承运订单成交量进行了预测。实验首先利用本文方法对网络货运平台车货匹配特征进行了提取,提取的结果如表2所示。由表2可知,本文方法对网络货运平台车货匹配特征进行了准确提取,且较为全面,可以较好地对原始数据进行描述,为后续网络货运平台车货匹配的预测打好基础。
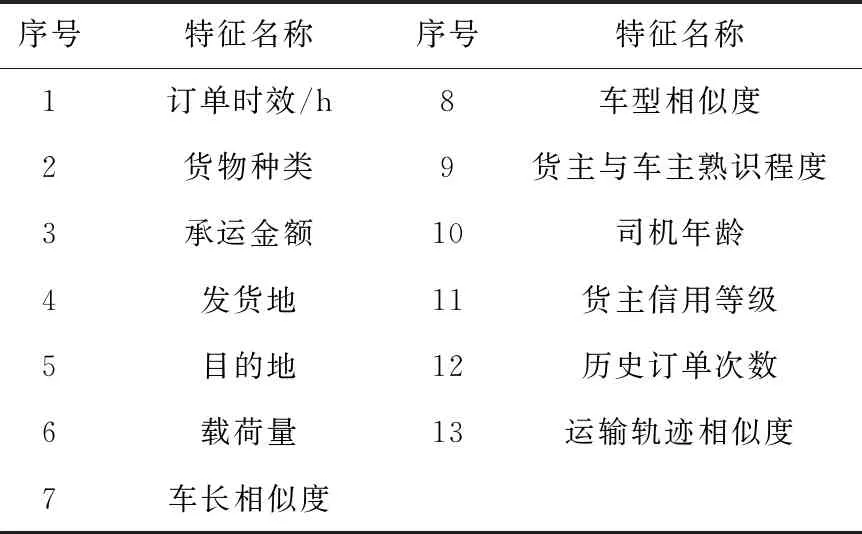
表2 网络货运平台车货匹配特征
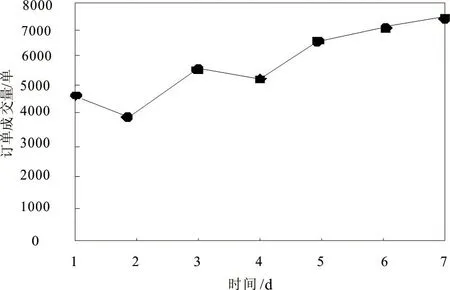
图2 网络货运平台车货匹配预测结果
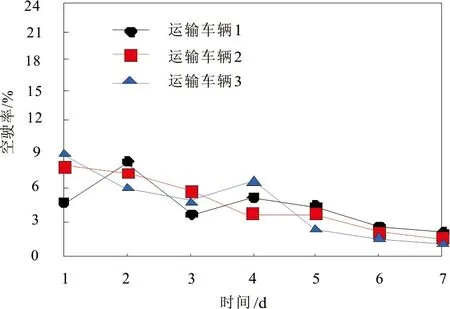
图3 运输车辆空驶率
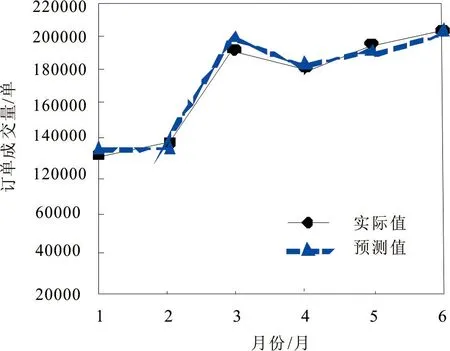
图4 预测值与实际值对比结果
根据提取的特征建立特征数据集,输入至Stacking集成学习模型中,最后得出的结果如图2所示。由图2可知,利用本文方法对该网络货运平台承运订单成交量进行了预测,从曲线走势可以看出,前4d的订单成交量相对较低且起伏较大;由于该平台从货主处获悉,在本周的第5d至第7d会有大批量货物需要运输,因此预测后3d订单成交量呈逐渐上升趋势。由此可以看出,本文方法可以对网络货运平台车货匹配情况进行有效预测。
从根本上说,车货匹配就是为了提升物流资源的利用率,而减少车辆的空驶率,尽可能地利用返程车辆就近运送货物,是合理配置资源的有效方法。空驶率指的是车辆空驶里程与总行驶里程的比率。实验利用本文方法对网络货运平台车货匹配进行预测后,根据预测结果对随机三辆回程的运输车辆与就近的货物进行匹配,得到的实验结果如图3所示。由图3可知,根据本文方法获取的网络货运平台车货匹配预测结果,对返程的运输车辆与就近货源进行匹配,有效地降低运输车辆的空驶率。在实验一周之内,随机选取的三辆运输车辆空驶率均未超过10%,尤其是第6d和第7d,空驶率已在3%以下,说明各方资源得到了合理利用,本文方法具有较好的应用价值。
为了衡量本文方法对网络货运平台车货匹配预测的准确性,实验从该网络货运平台选取近6个月的历史数据进行测试,经过测试得出的结果,如图4所示。由图4可知,利用本文方法可以对该网络货运平台车货匹配情况进行精准预测,尤其是1月、4月和6月订单成交量的预测值与实际值基本吻合,即使是在2月、3月和5月产生了差异,但差异也较小,对整体结果没有太大影响,由此说明,本文方法对于网络货运平台车货匹配的预测较为精准。
3 结 语
在"互联网+物流"的大环境下,网络货运平台已在货物运输市场占据着较大份额,为了精准地预测网络货运平台车货匹配情况,合理配置物流资源,本文提出一种基于机器学习算法的网络货运平台车货匹配预测问题方法。该方法采用具有双层模型的Stacking集成学习模型对网络货运平台车货匹配情况进行了预测,对比单一模型来说,Stacking集成学习模型具有更好的预测性能。通过实验证明,本文方法比较适合用于网络货运平台车货匹配的预测。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
无人机(2018年1期)2018-07-05
无人机(2017年10期)2017-07-06
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
高中生学习·高三版(2016年9期)2016-05-14
专用汽车(2016年5期)2016-03-01
