
智能+技术背景下基于聚类算法的自动化审计研究①
2023-11-05 11:51:34李巍
佳木斯大学学报(自然科学版) 2023年5期
李 巍
(安徽中医药大学,安徽 合肥 230012)
0 引 言
进入人工智能时代之后,数据和算法成为创新工作模式的重要内生动力,企事业单位的各类审计工作中应积极引入此类新技术和新工具。聚类算法依靠特定的评价维度进行数据分类,能够从海量数据中挖掘出隐藏规律,该算法与审计工作的深度融合能够实现审计自动化和智能化,其应用价值较为突出,在研究中需重点解决算法模型构建问题。
1 自动化审计的技术框架
(1)基础设施层
基于聚类算法的自动化审计以程序代码调用审计数据,完成分析和计算。其基础设施层由服务器、网络、数据库以及其他必要的软硬件设施组成,主要功能为部署算法程序、采集和存储审计基础数据、执行审计过程、输出和展示审计结果[1]。由于自动化审计的运算量较大,在服务器硬件方面应适当提高CPU主频以及内存空间。存储系统设计应考虑基础审计数据的规模以及数据安全性问题。
(2)数据中心层
审计数据存储分为两步,第一步是存储日常工作产生的业务大数据,其目的是复制业务原始数据,无需做转换和处理。第二步是根据聚类算法的数据需求进行预处理(采用ETL模式),降低运算量和运算难度。因此,数据中心层的数据库按照原始数据和预处理数据分两类进行设计。
(3)审计指标层
在自动化审计中需明确审计指标,依托审计相关的法律法规、内部审计的制度要求、财务规范等,结合阶段性经营目标以及年度总目标,制定出详实、合理的审计指标层。
(4)数据服务层
数据服务层的功能包括数据处理、数据挖掘、数据查询和利用,聚类算法主要在数据服务层发挥作用。按照数据处理和应用的先后顺序,该层的工作流程如图1所示。
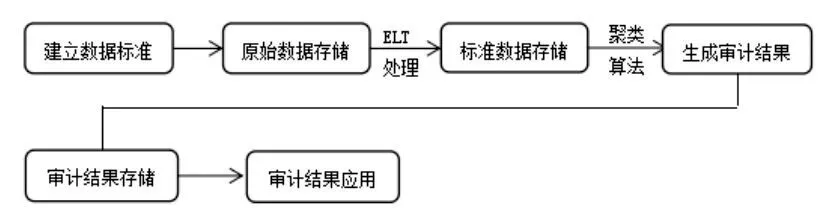
图1 自动化审计数据服务层工程流程简图
2 基于聚类算法的自动化审计构建及应用策略
(一)确定审计数据源
(1)数据源
自动化审计的目标、方向、用途等决定了具体的数据源。在企业中,审计活动涵盖设备物资采购、税务、各部门运营成本、人员工资发放等。以企业的物资采购审计为例,其数据源可分为三类。
1)内部审计数据
内部数据主要来自企业的物资采购计划、采购预算、审批结果、采购合同信息、实付资金。采购计划中详细地统计了物资类型、规格、数量以及所属部门,采购预算中根据市场情况设置了各类物资的预估单价,分类计算出采购成本以,汇总后形成总预算。可见,内部数据是自动化审计的核心原始数据。
2)外部审计数据
企业的外部合作方、采购物资的市场价格信息、投资金额、融资金额等构成了外部数据源。外部合作方主要涵盖投资方、融资方、供应商、租赁服务机构。物资价格信息统计了实际采购单价,而价格决定于市场以及合作对象。
3)中间审计数据
在数据源和审计结果之间还存在一定量的中间数据,通常是针对原始数据的简单分类或分析,呈现为特定的业务指标。另外,账户交易数据、财务检查数据亦可作为中间数据,并发挥特定的审计功能。
(二)构建数据仓库
数据仓库应符合审计数据的存储特点,突出主题性和集成性,在工程实践中主要采用分层设计,具体如下。
(1)ODS层
ODS层用于复制和存储业务数据,其表名称、字段名称、字段类型基本与业务数据库保持一致。业务数据依据相关主体的实体模型进行建模,因而ODS层的库表结构也具有显著的ER实体模型特点。根据物资采购的数据结构及类型,其存储内容具有明确的指标名称,以数值、文字信息为存储值。传统的关系型数据库适用于此类场景,可选用SQLServer或Mysql进行数据存储。
(2)DW层
DW层的主要任务是存储预处理后的数据,具体又可细分为DWD层和DWS层。当ODS层的审计原始数据经过规范的预处理之后,将转变为高度一致的干净数据,其数据粒度较小,基本不进行汇总,存储于DWD层。DWS层对部分同类审计数据进行轻度汇总或者合并,其数据粒度比DWD层略粗,汇总存储的优点在于降低数据调用和分析时的运算量和系统开销,DWS数据通常可覆盖80%的应用[2]。
(3)DM层
DM层用于存储针对特定主题的数据,具有较高程度的汇总性。在审计管理中,DM层可存储审计报表或综合性的审计指标,不体现明细数据,其数据粒度大于DW层。
(三)审计数据预处理方法及数据标准
数据源是对业务数据的复制,其数据品质、数据格式、数据规范性不一定能满足聚类算法的应用要求。因此,在自动化审计中需设计数据预处理环节,根据数据仓库的库表结构和字段信息,采用ELT模式对数据进行预处理。
(1)数据预处理方法
1)业务数据抽取(Extract)
数据抽取是根据审计目标,从业务数据库中抽取符合审计需求的业务数据。如果ODS层建立的库表结构与业务层完全相同,可使用SQL语句直接进行Select和Insert操作,完成数据复制。如果业务数据库和ODS层的数据库存在差异,无法直接查询和插入数据,此时应开发程序脚本或者程序接口,利用代码对业务数据进行适当的处理,然后按照一定时间间隔定期采集新生成的业务数据,可借助Linux操作系统的Crontab定时任务实现数据定期抽取。利用数据库管理软件进行导入也是抽取特定业务数据的有效方式。
2)业务数据清洗(Cleaning)
①处理不完整的审计数据
如果原始业务数据中部分字段的存储内容缺失或者不完整,此时应对其进行过滤或者补全处理。对于较为重要的字段,如供应商名称、供应商分类标识、物资采购单价,一旦缺失,可实施过滤操作。当字段信息对审计的影响较小时,可根据现有信息进行补全操作。
②处理错误的审计数据
错误数据指存储内容的格式、数值范围、主题等明显违背表字段要求。此类情况大多产生自原始业务数据录入环节。在数据入库时应进行必要的校验,防止存储错误。数据清洗环节需重新校验抽取的数据。同样的,重要字段错误时应直接过滤。
3)数据转换(Transform)
数据转换是从算法处理的角度出发,对数据的存储格式、量纲等进行统一,从而降低算法的运算开销,常见的转换方式如下。
①不一致转换
在审计管理中,同类数据的存储方式可能存在差异。例如,系统中的时间可存储为时间戳或者DATETIME格式。再如,含有金额的字段往往带有小数点,但小数点后保留的位数可能不同。不一致转换是对同类数据进行统一处理,使其在格式、单位、结构或长度方面保持一致。
②归一化处理
数据归一化是将量纲不同的数值映射到区间[0,1]之间,去除单位对数据的制约,以便进行数值比较和运算。常用的归一化方法为Z-score标准化法和min-max标准化法。以前者为例,其计算方法如式(1)。
(1)
式(1)中:σ表示所有样本的标准差,μ为所有样本的标准差,x为样本中任意一个元素,x*是按照Z-score法处理之后的结果。
(2)确定数据存储标准
数据库对表字段进行了严格的规定,以关系型数据库SQLServer为例,其常用字段及存储特点如表1。在设计各类表的字段类型时,应综合对比使用便捷性和运算速度,合理进行设置。以money字段为例,这种类型可存储审计中涉及的金额,其精度为小数点后保留四位,实际应用中也能使用decimal存储金额类数据,设计表时应对比其各自的优劣性。

表1 SQLServer常用字段类型及特点
(四)聚类算法在自动化审计中的应用示例
聚类算法在机器学习中应用广泛,其作用是对数据进行自动分组。根据研究现状,聚类算法包括K-means,Mean-shift,HAC等多种技术路径,其适用范围也存在差异[3]。从性能角度看,K-means算法运行速度非常快,故选用该算法进行自动化审计。由于算法总是与具体的应用场景密切相关,以下利用K-means聚类算法审计物资采购审批过程的合理性,从而说明其在自动化审计中的应用方法。
(1)选取审计评价指标
物资采购审批过程中需评价审批效率以及审批质量等因素。审批质量用于描述采购物资的用途合理性、数量合理性以及价格合理性,审批效率以时间为评价维度。研究过程中建立以下多级评价指标。
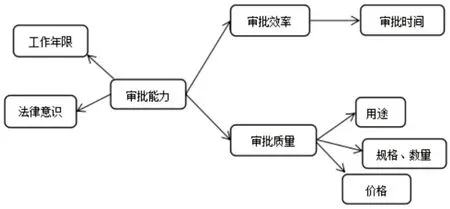
图2 物资采购审批合理性审计评价指标
(2)确定聚类准则
聚类准则是完成聚类任务时必须遵守的规则,可用于计算特征相似度,如通过距离、密度或连通性评价指标相似度[4]。根据物资采购审批合理性审计的指标特征,宜采用距离相似度量准则,以欧式距离为例,其计算公式如式(2)。
(2)
式(2)中,两个参数分别代表待评价指标及其各簇中心,差值表示二者之间的距离。显然,距离越小时,表明指标相似度越高。
(3)数据归一化处理
可采用min-max方法对评价指标进行归一化处理,提高其可比性,计算方法如式(3)。
(3)
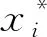
(4)基于聚类算法的自动化审计建模
①数据集
数据集用于表示所有的合理性审计评价指标,将数据总量记为n。将单条数据记为Xi,则Xi对应的属性可表示为Xij。按照该规则,数据记录Xi可表示为式(4)。
Xi={Xi|Xi=(Xi1,Xi2,…,Xim),
i∈(1,2,3,…,n)}
(4)
②聚类个数
聚类个数对K-means聚类算法的影响较为突出,当聚类个数较小时,算法可达到较高的运行速度,但聚类效果却相对较差[5]。反之,如果聚类个数设置较大,算法的聚类效果较好,但却可能出现过度拟合或者运行时间过长的问题。因此,在工程实践中需利用训练数据检测不同聚类个数下的聚类效果和运行时间,通常将其设置在3到6个之间。
③初始化聚类中心
在K-means算法中,假设将数据聚类为n个组,此时需选择n个随机点,将其作为聚类中心。或者利用最长距离法,先随机指定一个聚类中心,然后对比其他样本与该聚类中心的最大距离,将距离最远的一个选定为第二个聚类中心,按照这一规则,直至产生n个[6]。将初始化所形成的聚类中心记为集合E,其表达式如下。
Ei={Ei|Ei=(Ei1,Ei2,…,Eim),
i∈(1,2,3,…,n)}
(5)
④欧式距离计算
这一步骤采用公式(2)进行计算,其作用是求得各个审计指标和聚类中心的欧式距离。
⑤检验收敛性及输出结果
聚类中心在数据迭代过程中会发生多次变化,只有当迭代达到收敛状态后,聚类中心才完全确定下来,不再发生变化[7]。将迭代次数的上限设置为m次,观察算法能否在m次内达到收敛,然后利用可收敛的模型开展合理性审计,输出结果。以上为针对企业物资采购审批合理性的聚类自动化审计算法模型,可通过该算法评价采购审批人员和审批活动是否合理。
(5)基于聚类算法的自动化审计模型效果检验
①企业采购审批相关数据采集
根据采购审批合理性的自动化审计评价指标,收集某企业的相关数据,建立数据存储表,其字段包括订单编号、采购物资种类、采购规格、物资单价、总支持、数量、审批总时长、各节点审批时长、审批人员工作年限、审批人员历史审批结果的风险性等。
②数据标准化处理结果
通过ELT操作,并进行数据min-max归一化处理,得到标准化数据,表2为数据示例。
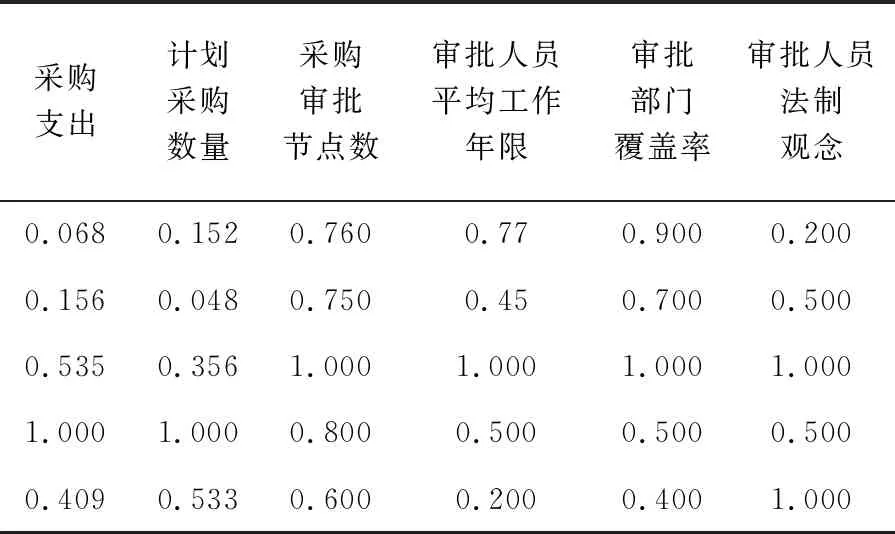
表2 某企业采购审批合理性审计的标准化数据示例
③算法自动化审计结果分析
按照以上方式收集400条标准化数据,并将其导入模拟软件中,事先在软件中建立自动化审计的算法模型。软件模拟结果主要包括以下几点。1)各审计指标的重要性排序。按照重要性由高到低的顺序,排序为计划采购数量、审批部门覆盖率、采购支出、最长节点审批时间、审批人员工作年限、审批总时长等;2)通过自动化审计算法输出不同聚类的物资采购审批合理性总得分,聚类1到聚类4的结果分别为49.1%,25.6%,16.9%,10.3%。
3 结 语
自动化审计的构建方法为收集原始业务数据、抽取并存储待审计的业务数据、清洗缺失数据和错误数据、进行归一化或标准化处理。同时,利用聚类算法构建符合业务特点的审计模型,包括设置审计指标、生成聚类中心、训练算法模型、观察收敛效果、检测审计效果等。标准化数据用于训练和检验审计模型,经实测,相关审计模型确实提升了审计效率。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
新闻传播(2018年4期)2018-12-07 01:09:34
计算机与生活(2018年3期)2018-03-12 08:38:11
武大国际法评论(2017年6期)2017-05-29 01:08:23
法哲学与法社会学论丛(2017年0期)2017-05-20 09:31:54
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
湖北警官学院学报(2015年11期)2015-02-27 13:13:59
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
