
基于不同机器学习的震后滑坡易发性建模研究
2023-11-04 03:36周天游舒建冬
自然灾害学报 2023年5期
周天游,刘 畅,薛 鹏,杨 豹,舒建冬
(1. 中国地质科学院探矿工艺研究所,四川 成都 610031; 2. 万融建工有限公司,四川 成都 610074;3. 中冶成都勘察研究总院有限公司,四川 成都 610023; 4. 四川省华地建设工程有限责任公司,四川 成都 610081)
0 引言
滑坡易发性评价是指在对区域滑坡调查的基础上,进行区域滑坡易发条件和空间发生概率的预测[1],主要包括滑坡编录与基础环境因子获取、训练与测试集的确定、易发性评价模型的选择、模型参数的确定、易发性评价结果分析等[2]。现阶段,滑坡易发性评价方法可被划分为启发式、基于力学模型的确定性方法、数据驱动模型(包含数理统计和机器学习模型)以及集成模型等[3]。其中,常见的机器学习模型包括逻辑回归、神经网络、多层感知器、模糊数学、支持向量机、决策树、随机森林以及深度学习算法等。研究表明,机器学习相比常规数理统计模型,具有样本数据少、泛化能力强、建模过程简单高效和精度高等优点[2],因此,越来越多的学者在区域面积较大的滑坡易发性研究中视其为更好的选择。
不同机器学习模型的易发性建模过程、预测精度甚至易发性指数分布特征结果往往差异较大,难以确定哪种模型效果最优,例如黄发明等[5]采用逻辑回归、多层感知器、支持向量机和C5.0决策树等方法,分别构建了基于原始滑坡因子和改进因子的机器学习模型以预测滑坡易发性,结果表明决策树模型预测性能最好;李文斌等[6]以江西省瑞金市为例,通过5种联结方法耦合4种机器学习模型,开展了20种模型下的滑坡易发性预测研究和易发性指数的不确定性分析;谢明娟等[7]开展了机器学习模型预测滑坡易发性的对比分析,认为支持向量机模型具有预测结果较为稳定和认可度较高等优点。值得说明的是,不同区域内的地质条件和环境背景差异较大,模型性能受到由特定研究区域内生成的建模数据的影响,因此,所得到的滑坡易发性分区结果的准确性及合理性也有所差异。
在构造活跃的西南山区,地震诱发滑坡是重要的次生灾害类型之一,地震波使得斜坡存在“裂”而未“滑”、“松”而未“动”的震裂山体,在强降雨和重力作用下会形成“滑坡/崩塌—碎屑流—泥石流”等链式次生灾害,因此,在震后及时准确地基于GIS平台开展滑坡易发性预测建模,有助于滑坡灾害防治及震后灾害演化机制研究工作的开展[8]。吉日伍呷等[9]以鲁甸地震为例,选取逻辑回归、K近邻、朴素贝叶斯和随机森林算法分别构建了4种滑坡易发性评价模型,并对模型的预测精度进行了对比。针对九寨沟Ms7.0地震同震滑坡灾害,张玘恺等[10]比较了信息量、确定性系数、逻辑回归模型及其耦合模型的快速评估方法对于九寨沟县范围内滑坡灾害开展易发性评价的适用性;罗路广等[11-14]基于层次分析法、确定性系数、逻辑回归模型、信息量模型、广义加权统计模型等不同评价方法和评价单元开展了评价模型的比较与耦合、历史地震情景滑坡发生概率反演、因子组合选取及风险评价等研究。上述研究结果均表明,数理统计模型能较好地评价九寨沟地区滑坡灾害易发性,然而机器学习模型是否具有适用性仍有待验证。针对此问题,本文选取4种代表性机器学习模型,选取地震因子、地形地貌因子、地质因子、水文因子以及人类工程活动等五个方面共14个滑坡初始环境因子,在因子共线性诊断的基础上,采用10折交叉验证数据取样方法、受试者特征ROC曲线和易发性指数分布特征(均值和标准差)等来探讨基于机器学习的滑坡易发性建模及其不确定性。以期对九寨沟地区震后短期或长期防灾减灾及推广机器学习模型在其他地区的易发性预测建模具有一定的参考价值。
1 机器学习模型
本文利用逻辑回归(LR)、支持向量机(SVM)、随机森林(RF)、人工神经网络(ANN)4种机器学习模型预测输出震后滑坡易发性指数p(范围介于0和1之间),并分别以p≥0.5或p<0.5对滑坡发生和滑坡不发生进行划分。基于R统计软件强大的函数功能和编程算法构建机器学习分类模型,并通过10折交叉验证(10-fold cross validation)取样方法对数据样本进行模型训练和测试,其原理详见文献[13]。
1.1 逻辑回归(LR)
逻辑回归(logistic regression,LR)利用因变量与多个自变量之间的线性回归关系,分析预测滑坡发生概率,是应用较为广泛的滑坡区域评价模型之一[2,5,11]。该模型描述二元因变量(滑坡是否发生)和自变量(x1,x2,…,xk)之间的关系,自变量可以是连续的也可以是离散的,不需要满足正态分布,表达式为:
ln[p/(1-p)]=β0+β1x1+β2x2…+βkxk
(1)
(2)
式中:p为滑坡发生概率;β0为截距常数项;β1,β2,…,βk为各滑坡因子所对应的回归系数;x1,x2,…,xk为各滑坡因子指标值。
1.2 支持向量机(SVM)
支持向量机 (support vector machine,SVM)通过在高维空间中找到分类间隔最大化的分离超平面对数据进行分类[5,15]。假设输入数据为xi(i=1, 2, 3, ……,n),对应二分类问题的输出为y(y=±1)。
(3)
yi=(ω·xi)+b≥1
(4)
(ω·xi)+b≥1+ξi
(5)
式中: ‖ω‖2为超平面法向量的范数;b为常数;L为拉格朗日定义的损失函数;λi为拉格朗日乘子;ξi为松弛因子。下一步可将式(3)表示为式(6),其中υ(0,1)为误分类问题。另外,本文选择径向基函数作为SVM的核函数:
(6)
1.3 随机森林(RF)
随机森林(random forest,RF)模型是由多个决策树集合而成的集成分类模型,利用随机方法构建决策树,其原理是首先利用bootstrap抽样从原始训练集中有放回地抽取K个样本,且各样本的特征数都与原始训练集相同;再分别对K个样本建立决策树模型,得到K种分类结果;各样本种随机选取n(n≤m)个特征作为分裂特征集,从中选择最优特征对节点进行生长,当n≤m时,每一棵决策树之间又存在差异性。节点分裂以基尼系数GI作为杂质函数,如式(7)所示:
(7)
式中:c为分类类别个数;t为决策树的节点;p为c的相对频率。最终,形成随机森林,根据K种分类结果进行投票表决以决定其最终分类。由于该模型每个树的训练样本及节点分裂属性均为随机选取,使得在一定程度上避免了过拟合问题。因此,利用RF方法进行滑坡易发性评价逐渐受到重视[2]。
1.4 人工神经网络(ANN)
人工神经网络(artificial neural network,ANN)以数学模型模拟神经元活动,是基于模仿大脑神经网络结构和功能而建立的一种信息处理系统[16]。ANN模型不需要知道输入、输出之间的确切关系,不需大量参数,只需要知道引起输出变化的非恒定因素,即非常量性参数。神经网络技术在处理模糊数据、随机性数据、非线性数据方面具有明显优势,对规模大、结构复杂、信息不明确的系统尤为适用。
2 研究区概况与滑坡环境因子
2.1 研究区概况
本文以2017年8月8日21时19分46秒四川省北部阿坝州九寨沟县漳扎镇发生的Ms7.0地震作为研究案例,九寨沟是长江水系嘉陵江西源白龙江右支流白水江上游的一条支沟,如图1(a)所示,因沟内有9个藏族村寨而得名。它地处青藏高原与四川盆地过渡的深切割高山峡谷地带,位于青海-西藏和扬子板块的边缘,平均海拔3000 m以上,地势南高北低,地质背景复杂,褶皱断裂发育,新构造运动强烈,地壳抬升幅度大,形成了形态各异的冰斗、U形谷、悬谷、喀斯特等多种地貌和以高山湖泊群、钙华瀑群及钙华滩流为特色的自然景观。九寨沟以自然、文化独特的科研价值、保护价值及旅游观赏价值等突出普遍价值,于1992年作为自然遗产被联合国教科文组织世界遗产委员会列入《世界遗产名录》。研究区总面积655.49 km2,受九寨沟“8·8”地震影响,区内斜坡岩体松动、破碎,在降雨作用下极易失稳产生滑坡灾害。
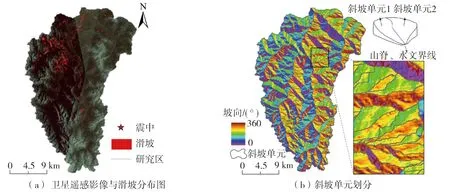
图1 研究区概况
2.2 数据来源与处理
滑坡易发性预测研究的基础工作包括建立滑坡数据库、划分评价单元以及提取滑坡环境因子等。本文的主要数据来源包括:①空间分辨率分别为0.2 m的Gaofen-1(日期:2017年8月16日)和3.0 m的Landsat-8(日期:2020年9月20日)卫星遥感影像,经过影像裁剪、几何校正、正射矫正、色彩和饱和度调整等,在ArcGIS软件中对比分析进行目视解译,建立了研究区九寨沟“8·8”地震震后滑坡数据库,圈定364处滑坡,如图1(a)所示,主要分布于研究区西北部震中附近及沿沟谷发育,滑坡总平面面积为2.11×106m2,最大、最小面积分别为5.39×104m2和3.89×102m2,规模以中、小型为主,经野外调查验证发现该滑坡编录数据具有较高的质量和完整性;②从美国地质调查局网站下载的分辨率为12.5 m的数字高程数据(digital elevation model,DEM)。目前常用的滑坡区域评价单元主要有栅格单元和斜坡单元[17],斜坡单元以山脊和山谷线为水文分界线,是真实反映滑坡发生的基本单元。根据DEM水文分析模型和斜坡坡向将研究区划分为1234个斜坡单元,如图1(b)所示,其中有163个斜坡单元内有滑坡发生,剩余斜坡单元则没有滑坡发生;③滑坡环境因子和地形地貌数据在ArcGIS软件中利用表面分析工具从DEM中提取;地质因子通过矢量化1∶50000地质图得到地层岩性、岩层产状及断层信息;降雨量数据来自于研究区气象水文观测站多年平均数据,采用克里金插值法获得;公路、水系均通过卫星遥感影像矢量化获取。
2.3 滑坡环境因子
基于数据的可获取性和前人研究结果[10,13],本文从地震因子、地形地貌因子、地质因子、水文因子以及人类工程活动等五个方面共选取了14个滑坡初始环境因子,其空间分布特征如图2所示。地震因子包括地震动峰值加速度PGA(图2(a))、发震断层距(图2(b))、震中距(图2(c))等,能够反映九寨沟地震动参数对斜坡稳定性产生的影响,其中以虎牙断裂的北西延伸段为发震断层[18];地形地貌因子主要包括海拔高程(图2(d))、斜坡坡度(图2(e))、坡向(图2(f))、剖面曲率(图2(g))以及平面曲率(图2(h));地质因子有断层距(图2(i))、坡体结构(图2(m))、地层岩性(图2(n))等,其中坡体结构可划分为横向坡、逆向坡、逆斜向坡、顺向坡和顺斜向坡等5个类型;水文因子有距水系距离(图2(j))和降雨量(图2(l));道路反映了人类工程活动活跃范围,以距公路距离(图2(k))来表示。相关因子距离分析均利用了ArcGIS的欧式距离分析工具。所有因子图层分辨率均被重采样为12.5 m×12.5 m,各指标值通过计算斜坡单元内栅格值得平均值获取。
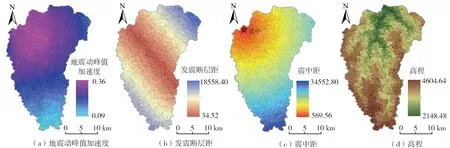
图2 研究区滑坡环境因子
3 滑坡易发性评价结果
3.1 因子相关性分析结果
滑坡易发性预测中为防止因子间存在共线性,可能增加模型的运行时间并降低模型精度,因此,在训练机器学习模型之前,需要对各因子进行相关性分析以验证其独立性[19]。图3为基于R统计分析软件得到的滑坡易发性评价因子皮尔逊相关系数矩阵,相关系数r取值介于-1和1之间,其中r>0为正相关,表明一个因子随另一个因子的增加而增加;r<0为负相关,情况则刚好相反。从图3可知,各因子间基本不存在共线性或相关性较弱可以忽略不计,然而地震动峰值加速度与震中距、降雨量均呈现较高的负相关性,相关性系数r分别为-0.96和-0.75,震中距与降雨量则呈现一定的正相关性(r=0.73)。综合考虑后,剔除震中距和距发震断层距离,仅保留地震动峰值加速度这一地震诱发因素。最终采用地震动峰值加速度、高程、坡度、坡向、剖面曲率、平面曲率、坡体结构、地层岩性、断层距、距公路距离、距水系距离和降雨量进行后续滑坡易发性建模。
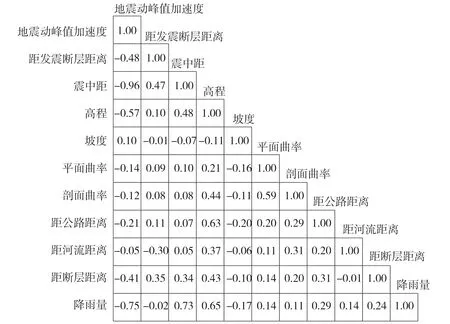
图3 滑坡易发性评价因子皮尔逊相关系数矩阵
3.2 震后滑坡易发性制图
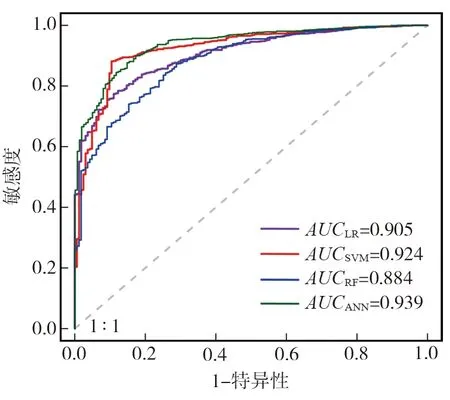
图4(a)~(d)分别为基于LR、SVM、RF和ANN模型得到的研究区震后滑坡易发性指数空间分布结果,其中LR模型反演得到的易发性指数为0~0.966,SVM模型的易发性指数介于0和0.671之间,RF模型的易发性指数为0~0.952,ANN模型得到的易发性指数分布于0~0.766。从图4可知,研究区大部分地区易发性指数均较低,易发性指数较高区靠近震中附近和沿沟谷发育分布,与震后滑坡编录结果一致,而年降雨量对滑坡灾害的影响较小,表明地震波对斜坡结构产生震损是滑坡易发的主要因素。
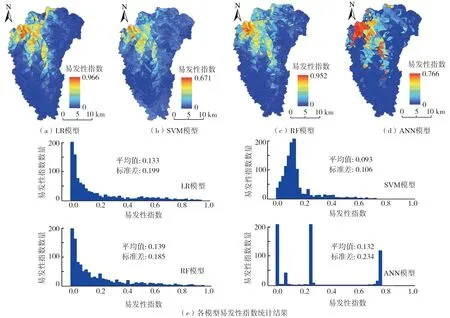
图4 4种评价模型易发性指数分布结果
3.3 易发性指数分布规律
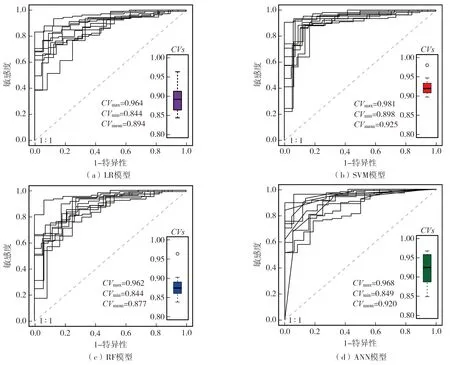
图4(e)为基于LR、SVM、RF和ANN模型得到的研究区震后滑坡易发性指数分布规律,为分析模型的不确定性,本文采用均值和标准差分别反映易发性指数分布的平均水平和离散程度。LR模型和RF模型的统计结果较为一致,在易发性指数值较低的区间分布集中,随着值增大而逐渐减少,SVM模型的易发性指数分布呈现先增加后减小的特征,而ANN模型则表现为“跳跃式”分布。各模型易发性指数p均值相差不大,其值从小至大依次为:SVM(0.093) 本文基于ROC曲线(receiver operating characteristic curve, ROC)和曲线下面积(area under curve,AUC)来进行机器学习模型性能评价。ROC曲线的横、纵坐标分别为1-特异性和敏感度,当曲线越靠近左上角,AUC值越接近1,表明该模型精度越高。根据已有的评判标准[20],当0.5 4种机器学习模型在研究区滑坡易发性评价的ROC曲线如图5所示。从图5可知, LR、SVM、RF、ANN模型均具有较好或出色的性能,准确率AUC值均超过0.88,除RF模型外,其余3个模型的AUC值均超过0.9。准确率AUC值从大至小依次为:AUCANN>AUCSVM>AUCLR>AUCRF。基于10折交叉验证取样方法对模型进行10次测试,获得10次预测精度CVs,如表1所示。图6为各模型预测精度ROC曲线和CVs分布箱型图,各模型的预测精度均值CVmean从大至小依次为:SVM(0.925)>ANN(0.920)>LR(0.894)>RF(0.877),可以看出,SVM模型的预测性能最好,RF模型的预测性能最差。根据已有评价标准,LR和RF模型具有较好的预测精度,而SVM和ANN模型的预测性能被判定为出色。此外,CVs标准差CVstd从小至大依次为:SVM(0.023) 表1 基于10折交叉验证的各模型预测精度 图5 各评价模型ROC曲线与准确率AUC值 图6 基于10折交叉验证的各评价模型ROC曲线与预测精度CV 1)通过皮尔逊相关系数分析各滑坡易发性评价因子间的相关性,剔除震中距和距发震断层距离,仅保留地震动峰值加速度这一地震诱发因素,最终采用12个滑坡影响因子进行滑坡易发性建模。 2)利用4种机器学习模型和斜坡单元开展九寨沟地区震后滑坡,结果表明,易发性指数较高区靠近震中附近和沿沟谷发育分布,与震后滑坡编录结果一致,表明地震波对斜坡结构产生震损是滑坡易发的主要因素。 3)基于10折交叉验证取样方法的ROC曲线和易发性指数分布特征结果表明,SVM模型是在九寨沟地区震后滑坡预测中性能表现最好的模型,ANN模型次之,LR模型紧随其后,RF模型效果最差。该结果可为震后滑坡减灾工作和推广机器学习模型在其他地区的易发性预测建模提供理论依据与参考。3.4 模型精度比较

4 结论
猜你喜欢
环球时报(2022-07-13)2022-07-13中国药学药品知识仓库(2022年9期)2022-05-23大众科学(2022年5期)2022-05-18环球时报(2022-03-14)2022-03-14今日农业(2021年10期)2021-11-27河北地质(2021年1期)2021-07-21今日农业(2021年1期)2021-03-19电影(2018年8期)2018-09-21北方交通(2016年12期)2017-01-15水利科技与经济(2016年6期)2016-04-22
