
基于Lucene 的校园中文问答采集平台检索技术研究与实现
2023-11-04 18:14:22吴志霞叶根梅
通化师范学院学报 2023年10期
吴志霞,叶根梅,甘 丽
随着信息技术的发展,通过搜索引擎查询问题答案已成为日常生活中一种普遍现象.问答系统(Question Answering System,QAS)[1]作为信息检索系统的一种,是一种在检索技术上发展的、可以给用户一定反馈的系统.创建服务于校园的问答系统,需要先采集服务于校园领域的问答集,然后运用问答集进行训练生成训练模型.为采集校园问答集,需要开发采集问答的平台.在设计实现问答采集平台过程中,设计开发者必须考虑为平台提供问题的检索服务.传统的问题检索大多基于关系数据库的关键字查询,检索方式比较单一,随着数据量的增多,检索效率也会降低.Lucene 是一种性能优异的开源全文搜索框架,利用它可以方便地定制符合自身需求的搜索引擎.本文采用Lucene 的中文分词、倒排索引、结果相关度排序、高亮等关键技术,设计并实现了服务于某高校基于Web 应用的校园中文问答采集平台,采用MySQL 关系数据库存储的14 万条问答记录验证了检索的准确性和高效性[2-6].
1 开发实例及数据表介绍
1.1 开发实例介绍
校园中文问答采集平台基于Web 开发模式,采用Spring+SpringMVC+MyBatis 框架技术实现.开发实例提供问答样本数据集采集模块、问答样本数据集管理模块、文本制度文件导入模块、问答样本数据集输出模块和智能应答五个模块.其中,需要运用Lucene 搜索架构,实现问答采集平台的问句检索.
1.2 校园问答采集系统相关数据表介绍
运用Lucene 搜索架构实现问答采集平台,利用四张数据表存储通过平台导入的校园规章制度文件数据,以及针对这些规章制度文件采集到的问答集.
(1)规章制度文件表(subject).用来存储导入的规章制度文件主题信息,主要包括id、导入的制度文件主题描述、顺序编号等信息.具体描述如表1 所示.

表1 规章制度文件表(subject)
(2)章节表(chapterTitle).用来存放导入的制度文件的章节名称.主要包括id、导入的制度文件章节名称、顺序编号、章节归属的规章制度文件id 和创建时间等信息.具体描述如表2 所示.
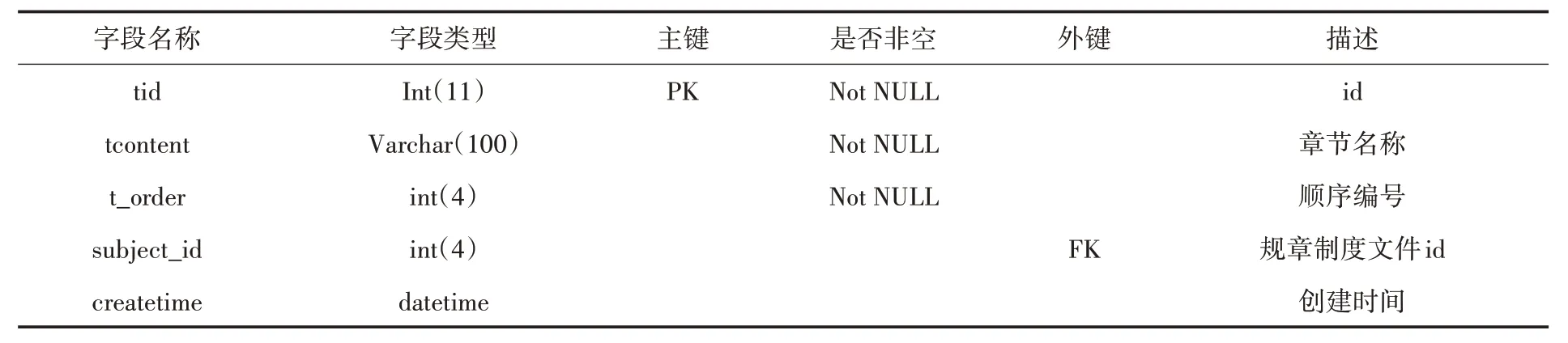
表2 章节表(chapterTitle)
(3)条例表(rules).用来存放具体的条例,主要包括id、导入的制度文件条例标题、条例内容、顺序编号、章节归属的规章制度文件id、条例归属的章节id 和创建时间等信息.具体描述如表3 所示.

表3 条例表(rules)
(4)问答表(qanswer).用来存放采集到的问答样本数据,主要包括qid、问题、答案、参考信息文本块、问题归属的条例id、问题归属的规章制度文件id、问题归属的章节id、创建人、创建时间、第一审核人、审核时间、审核级别、第二审核人、审核时间、审核级别、核定级别和状态等信息.具体描述如表4 所示.

表4 问答表(qanswer)
2 采用Lucene 搜索架构实现问答采集平台数据检索
2.1 Lucene 简介
Lucene 是一种运用Java 语言编写的开源全文搜索框架,属于Apache 软件基金会Jakarta项目组下的子项目.Lucene 作为一个搜索工具包,提供了完整的查询引擎、搜索引擎和某些语言的分析引擎.开发人员可以利用其强大的索引和搜索功能为目标系统添加信息检索功能[3].
2.2 基于Lucene 搜索架构实现平台数据检索基本流程
基于Lucene 实现平台数据检索流程如图1 所示.第一步,搜集数据.数据可以是文件系统、手工输入、网络上的数据和数据库中的数据;第二步,通过数据创建索引;第三步,用户输入要查询的关键字;第四步,通过关键字创建查询器;第五步,根据查询器到索引里获取数据;最后,把查询结果展示给用户.

图1 基于Lucene 实现平台数据检索流程图
2.3 基于Lucene 搜索架构实现问答采集平台问题候选问句的检索
基于Lucene 实现通过问答采集平台输入要查询的问题并得到多个候选问答集,根据问题得到候选问题集的检索程序流程图如图2 所示.获取用户输入的针对问题需要查询的关键字;准备中文分词器,调用业务逻辑中的方法获取数据库中所有的问答对数据;运用中文分词器与问答对数据创建索引;依据中文分词器和针对“问题”的字段去创建查询器;执行搜索;由指定的界面展示查询出来的候选问题集和对应的答案,得到的候选问题都标有相应的匹配得分,匹配得分越高显示越靠前.

图2 候选问题集的检索程序流程图
运用中文分词器与问答对数据创建索引的核心代码如下:


在“创建索引”的代码块中,应用程序把每一条数据记录都转换成一个文档(Document),并写入索引文件中.用户输入查询关键字,执行搜索的程序流程如图3 所示.创建IndexReader 类型的对象reader;基于reader 创建搜索器;指定每页要显示多少条数据;执行搜索,得到数组,返回的数组类型为ScoreDoc;运用搜索器、数组、查询器和中文分词器,返回符合条件的查询结果.
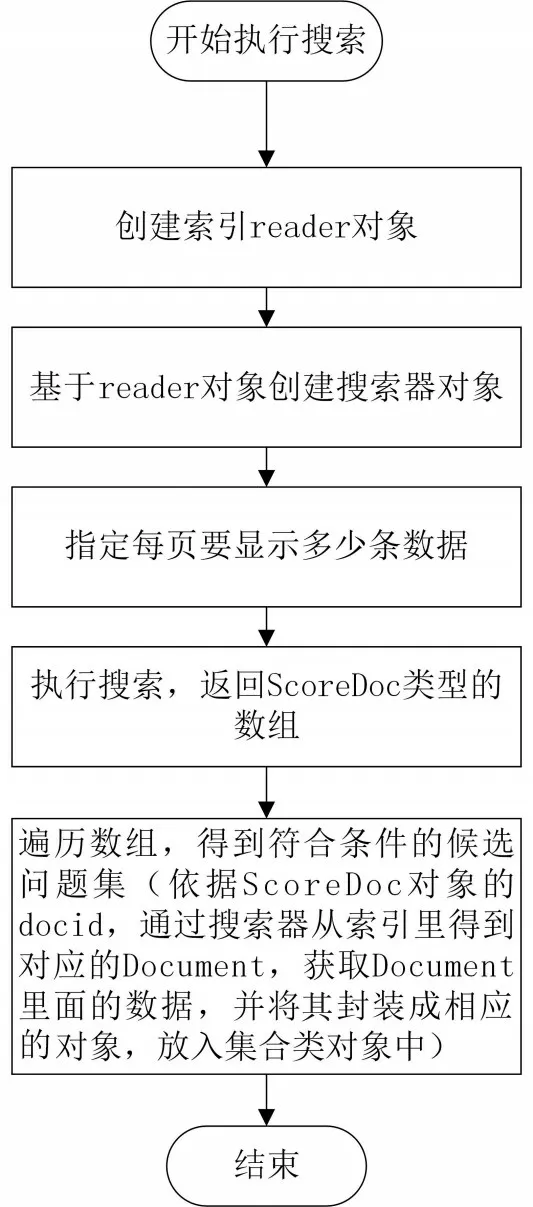
图3 执行搜索程序流程图
2.4 运行效果
用户在本文中的搜索引擎输入查询关键字,搜索结果如图4 所示.分值表示当前行的匹配度得分,得分越高在问答集列表中越靠前显示.为提升用户的使用体验,应用程序中关键字都进行了突出标识,在图4 中用黑框标识出突出的字体.
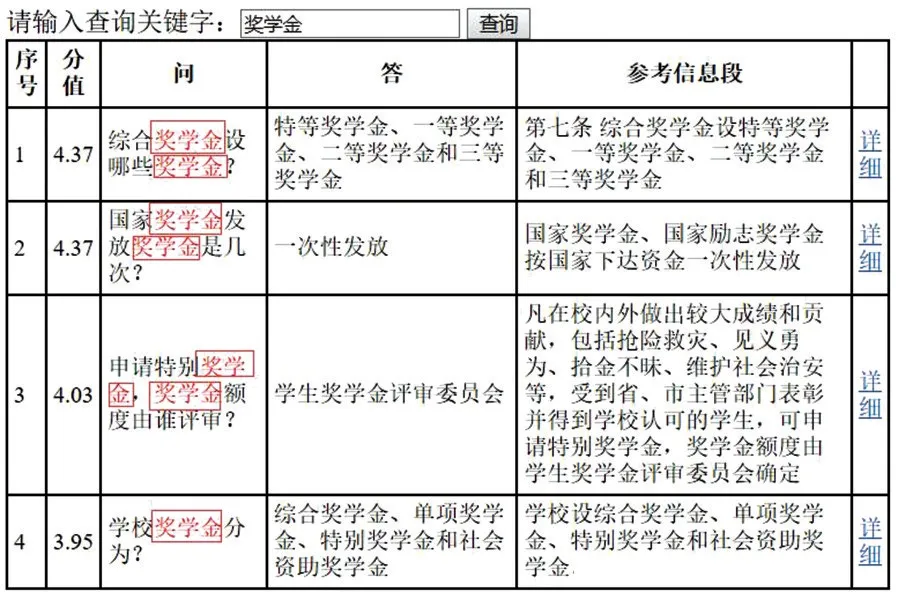
图4 搜索结果
2.5 平台检索对比实验
数据检索主要考虑检索的效率与检索的准确性.本文对比了基于Lucene 的全文检索和基于MySQL 数据库表“SELECT * FROM qanswer WHERE qname LIKE %检索词%”方式的模糊查询检索功能.文中选取了不同词长的8 个具有代表性的检索词,对MySQL 数据表中的14 万条问答记录分别采用这两种方法进行搜索,比较其搜索效率和准确度.实验结果如表5 所示.

表5 基于Lucene 的检索与模糊检索结果对比
对比基于Lucene 的检索和MySQL 数据库表的模糊查询,两者在检索效率和数量方面都存在差异.采用倒排索引技术的Lucene 检索框架,检索效率更高.在检索结果数量方面,Lucene 匹配以词元为单位,会进行分词,导致Lucene 检索普遍比模糊查询的结果数量多.例如,搜索“公益活动”,使用Lucene 检索能够切分出“公益”和“活动”两个词元,所以能够匹配“公益活动”“公益”和“活动”等多条记录,而MySQL 模糊查询无法搜索出这些结果.
3 结语
在传统的应用软件中,对数据的搜索大多采用关系数据表的模糊查询方式,每次查询请求,需要遍历数据表中的全部记录.本文将开源Lucene 搜索架构运用到校园中文问答采集平台,能够快速检索到数据,对数据进行相关度排序,并提供突出显示,让用户体验得到提升,为数据检索提供了一种实践思路.
猜你喜欢
中国交通信息化(2022年4期)2022-06-17 01:04:52
党员生活(2020年2期)2020-04-17 09:56:30
福建基础教育研究(2019年11期)2019-05-28 07:25:10
铁道通信信号(2018年10期)2018-12-06 09:34:56
中学数学研究(广东)(2018年24期)2018-03-12 00:44:34
装备学院学报(2017年3期)2017-07-21 10:04:21
装备学院学报(2017年2期)2017-06-05 14:20:11
玉溪师范学院学报(2015年1期)2015-08-22 02:52:02
计算机工程(2015年8期)2015-07-03 12:20:35
中国石油企业(2014年4期)2014-11-30 06:13:06
