时滞取值概率未知下的线性时滞系统辨识方法
2023-10-30 10:13刘鑫
自动化学报 2023年10期
刘 鑫
系统辨识作为一种有效的系统建模手段,在过去的一段时间里受到国内外学者的广泛关注[1-5].与传统的第一原理建模方法相比,系统辨识方法直接通过可测的系统数据提炼出与实际系统等价的数学模型,无需深入窥探系统的内部复杂机理,因而使得建模过程变得简单、高效[6-11].在系统辨识领域,由于长时间的数据传输、数据获取方式的不同等因素,常常导致不同的过程变量之间存在未知的时间延迟(时滞).时滞作为一个常见的现实问题,很容易降低辨识数据的数据质量并且对辨识算法的设计提出更高的要求[11-13].在辨识算法设计的过程中,忽略时滞因素的影响会导致有偏的参数估计,甚至错误的辨识结果[14-16].
在实际的工业过程中,过程变量之间的时滞大体上可以分为两类:固定时滞和时变时滞[13-18].对于包含固定时滞的系统辨识问题,传统的方法一般是分为两个步骤进行:1)对输入-输出数据利用相关分析法,先求解未知的时滞参数;2)基于时滞参数求解未知的模型参数[17-21].但是这样的解决方案实质上是将时滞估计和参数估计独立分开执行,很容易造成误差累计,进而影响辨识结果的精度[17].为了解决误差累计的问题,文献[22]在统计学的框架下并基于极大似然判据提出了一类有效的迭代辨识算法.利用期望最大化(Expectation maximization,EM)算法首先将辨识问题公式化,将未知的时滞变量当作隐含变量来处理.在辨识过程中,不断计算时滞的后验概率密度函数(Probability density function,PDF),通过比较后验概率密度函数的值来判断未知时滞的取值.该方法的主要优点包括:1)给出了显性的时滞估计公式;2)能够同时给出时滞参数和模型参数的极大似然估计,避免了误差累计降低辨识结果的精度.随后该辨识思想被重新利用在线性变参数时滞系统过程中,文献[23]采用多模型方法对线性变参数时滞系统设计有效的局部辨识算法.首先在每一个工作点处,选取线性自回归时滞模型为局部模型,每一个局部模型的时滞参数各不相同;然后利用期望最大化算法同时估计各子模型的时滞参数、模型参数以及有效宽度参数;最后利用输出插值策略估计系统的全局输出.在每一个采样时刻,将系统全局输出写成每个子模型输出数据的加权组合的形式.此外,文献[24]结合了冗余法则以及递归最小二乘算法针对一类线性时滞系统进行了辨识研究.核心思想是扩展原系统的维数,然后再辨识扩展系统的模型参数.如果某项系数趋近于零,则认为该项在原系统中不存在,并依据于此来判断时滞参数.这种辨识思路无形中增加了算法的复杂度.
针对时变时滞系统辨识而言,首先要确定未知时滞的变化机制.在现有的文献中,最常用的变化机制是首先假定时滞可能的取值范围,然后假定时滞在取值范围内服从均匀分布,即在每个采样时刻,时滞取每个值的概率相同[3,14,16,18-19].文献[25]针对多率采样时滞系统提出了一类有效的辨识方法.输入、输出变量分别采用快率、慢率采样,且输入和输出变量之间存在服从均匀分布的时变时滞.利用期望最大化算法实现上述系统辨识问题,将未知的时滞变量当作隐含变量来处理,上述辨识问题可归纳为:在慢率输出基础上同时估计时滞参数和模型参数.另外,基于辨识得到的有限脉冲响应模型还可以进一步促进输出丢失情况下的输出误差模型和传递函数模型的辨识问题.文献[14]采用多模型局部辨识的思想针对线性变参数输出误差模型辨识进行深入研究.能够同时给出各子模型的时滞参数和模型参数的估计公式,由于目标代价函数与模型参数呈非线性关系,采用阻尼牛顿法来迭代搜索模型参数的最优解.此外,文献[18]在输入输出数据双率采样的条件下考虑了线性状态空间时滞模型的辨识问题.首先利用离散化技术得到待辨识系统的慢率采样模型;利用数学工具将慢率采样模型转化成能观标准型;利用卡尔曼滤波算法估计未知的状态变量;最后利用随机梯度算法和递归最小二乘算法辨识模型参数.在辨识过程中考虑了状态变量与输出变量之间存在未知的时变时滞,且假定时滞在可能的取值范围内服从均匀分布.
然而,对于时变时滞系统而言,认为时滞在可能的取值范围内服从均匀分布这个假设通常过于严格,在很多情况下很难得到满足.为了解决这个问题,本文在时滞取值概率未知的条件下研究线性时滞系统辨识问题.仍旧假定时滞可能的取值范围先验已知,但是时滞取每个值的概率各不相同,即在时滞的取值范围内,时滞取每一个值的比重各不相同.不难看出,时滞服从均匀分布可以看作本文研究内容的一个特例,因此本文的研究更加贴近实际应用.采用极大似然算法搭建辨识框架,将时滞当作隐含变量来处理.在每个采样时刻不断计算时滞的后验概率密度函数,且该函数作为权重自适应地分配给每一个数据点,因此提高时滞的估计精度也能促进模型参数估计精度的提升.同时给出模型参数、噪声参数、控制概率向量中的每一个元素和未知的时滞的估计公式,最后利用一个数值例子验证算法的有效性.
1 辨识问题阐述
考虑以下线性双率采样时滞系统
其中,u1:N={uk}k=1,···,N表示快速率采样的输入数据且假设采样周期为Δt;xk表示理想的无噪声快率采样输出;表示慢速率采样的真实输出数据,它的采样周期假设为快率采样的整数倍,即fΔt,其中f表示一个任意的正整数;τ1:M={τi}i=1,···,M表示未知的时变时滞;eTi表示输出测量噪声且服从零均值的高斯分布,即G(z-1)表示系统的多项式传递函数并且有
其中,m表示系统的阶次.结合式(1)和式(2),系统的模型可改写为
其中
并且待辨识的模型参数θ定义为
此外,系统输出量测过程则可改写为
由式(6)不难看出yTi服从以下高斯分布
在本文中,将未知的时变时滞τi当作隐含变量来处理.首先假设时滞的取值范围已知,即[1,J].在每个采样时刻,假设时滞的取值为[1,J]中的任意一个整数,但取值概率不同且未知,用数学语言描述如下:
并且
不难看出,服从均匀分布的时变时滞系统可看作是本文的一个特例,即
在本文中,慢率采样的输出数据和快率采样的输入数据构成了可用辨识数据集Cobs={yT1:TM,u1:N};利用未知的时变时滞构造隐含数据集Cmis={τ1:M};待辨识的参数集构造为Θ={θ,β1:J,r}.因此本文的主要任务可以进一步总结为:基于可用数据集Cobs设计有效的辨识算法,同时估计参数集Θ和未知的时变时滞τ1:M.
2 基于期望最大化(EM)算法的辨识算法推导
2.1 EM 算法简介
在系统辨识领域,EM 算法对于解决数据丢失问题或者隐含变量问题非常有效.EM 算法是一个迭代优化算法,通过不断重复执行期望步骤(E-step)和最大化步骤(M-step)以实现待辨识参数的估计.在E-step 中首先构造系统对数似然函数为
由于隐含数据集不可用,使得计算上述似然函数变得尤为困难.这里通过计算其相对于隐含变量的期望来构造代价函数如下:
其中,Θs表示在第s次迭代中得到的参数估计值.在M-step 中,通过优化目标代价函数以得到新的模型参数估计值
重复执行E-step 和M-step,直至参数收敛[26].期望最大化算法实质上是通过不断迭代优化L1的条件期望函数来代替直接优化L1函数,最终得到所需的模型参数估计值.算法1 总结了EM 算法的具体实施步骤.
算法 1.EM 算法
2.2 基于EM 算法的辨识过程推导
1)E-step
首先构造系统的对数似然函数如下:
其中,C1=logp(u1:N|Θ)表示一个与参数无关的常数项.基于式 (4)和式(6)不难看出,在每个采样时刻,慢采样输出yTi与之前一段时间的输入变量、未知时滞τi以及模型参数Θ有关,因此等式右边的概率密度函数可进一步化简为
再结合式 (7),可以进一步化简为
此外,由于时滞τi与模型参数以及输入变量无关,因此logp(τ1:M|u1:N,Θ)可以进一步化简为
结合式 (16)和式(17),系统的对数似然函数最终化简为
其中,C2=C1-(M/2)log 2π是参数无关项.此时再基于式 (12),可求得
由于时滞变量τi属于离散变量,因此
观察式 (20)可得,想要优化代价函数Q(Θ|Θs),首先需要计算时滞取值的后验概率密度函数p(τi=j|Cobs,Θs).根据文献[17]中给出的计算公式可得
为了方便优化,可将代价函数Q(Θ|Θs)拆分成以下形式
其中,
2)M-step
在此步骤中通过优化上述代价函数来得到参数估计.首先Q1(θ,r)属于一个复合函数,它同时是模型参数θ以及噪声参数r的函数,只能采取循环优化的方式得到优化的参数估计.当优化θ时,令r=rs为定值;反之,当优化r时,令θ=θs为定值.将函数Q1(θ,r)对r求偏导并令导数等于零,得
由于模型参数θ与代价函数Q1(θ,r)并非呈线性关系,因此无法直接利用导数的方式求得θ的估计公式.结合式 (3)、(4)和(23),可将代价函数Q1(θ,r)改写为
其中,向量ϕTi-j定义为
此时,函数Q1(θ,r)与模型参数θ呈线性关系.再进一步对Q1(θ,r)求偏导可得
此外,根据函数Q2(βj)求解βj的迭代估计公式,需要构造拉格朗日函数.首先假设Lβ为拉格朗日因子,结合式 (9)可构造所需的拉格朗日函数如下:
通过求解上述拉格朗日函数可得
并且在每个采样时刻,未知时变时滞的迭代估计公式如下:
至此,基于期望最大化算法的未知参数和未知时变时滞估计公式全部推导完成.值得注意的是,在参数循环迭代的过程中,只用到了前一次的模型参数θs和噪声参数rs.因此在执行算法初始化时,只需设置θ和r的初值.本文提出的辨识算法可总结如算法2 所示.
算法 2.时滞取值概率未知下的线性时滞系统辨识算法
3 辨识算法验证
3.1 算法性能验证
考虑以下双率采样的线性时滞系统
其中,输入信号选取为幅值在 [-1,1]之间的高斯白噪声,即uk=-1+2×N(0,1).输出数据采用慢率采样且采样周期是输入的5 倍,即f=5.在每个慢率采样时刻,时滞取值范围分布在[1,4]中,并且按照概率[0.35,0.2,0.25,0.2]取值,即
输出测量噪声选取为方差r=0.01 的高斯噪声,且输出噪声与输入信号相互独立.对于输入数据生成N=2 000 个数据点,则收集到的辨识数据如图1 所示.
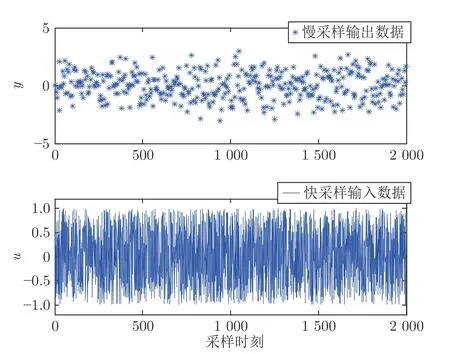
图1 输入输出辨识数据Fig.1 The input-output identification data
在执行辨识算法之前,首先需要将待辨识的参数初始化.模型参数θ的初始值选取为
噪声方差r的初始值选取为
然后执行算法2,经过50 次迭代之后,得到的时滞分布向量估计值如下:
同时,得到模型参数的收敛曲线如图2 所示.
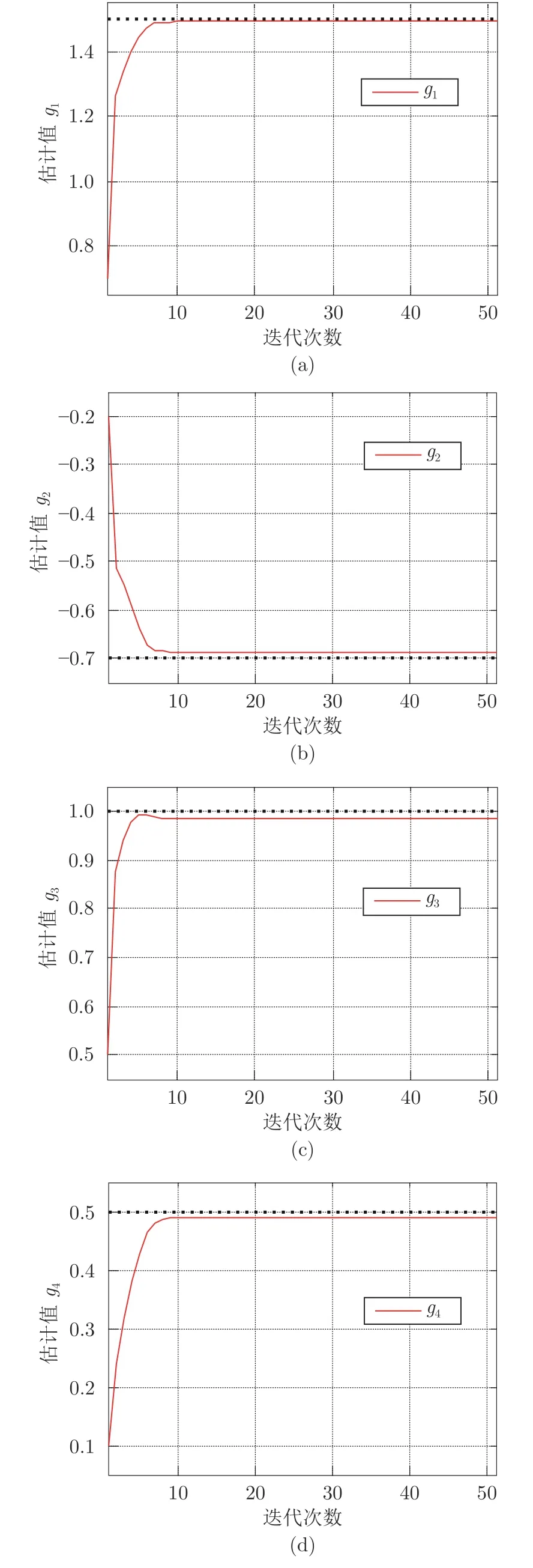
图2 经过50 次迭代得到的模型参数估计值Fig.2 The estimated model parameters after 50 iterations
通过图2 可以看出,本文提出的辨识算法具有非常良好的收敛性,经过少量的迭代之后,每个模型参数都能精确地收敛到真实值附近.此时,未知的噪声参数迭代曲线如图3 所示.
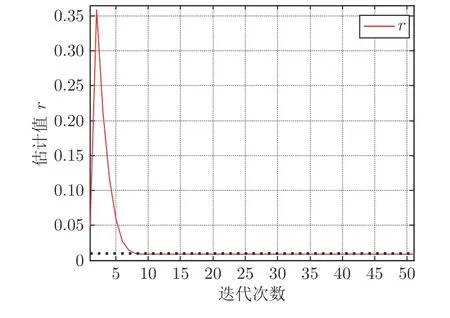
图3 噪声方差的收敛曲线Fig.3 The convergence curve of the identified noise variance
此外,结合式 (31),得到未知时滞的估计结果如图4 所示.
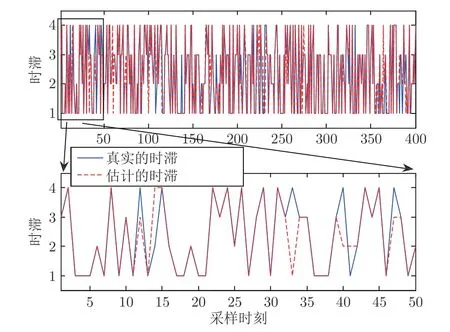
图4 时滞的估计值与真实值对比Fig.4 The comparison between the estimated and true delays
在图4 中,蓝色的实线表示真实的时滞;红色的虚线表示估计的时滞.经过统计,时滞估计的正确率在91% 以上.由此可见,本文提出的辨识算法能够同时估计模型参数以及未知的时变时滞.
为了更加系统地验证本算法的有效性,本文还设计了蒙特卡洛模拟仿真实验对算法进行更加系统的测试.在接下来的测试中,运行100 次独立的蒙特卡洛仿真,迭代次数设置为50 次.与文献[1]中类似,每次独立的蒙特卡洛仿真的初始值都从以真实参数为中心的对称区间中选取未知的初值θ0.得到的蒙特卡洛辨识结果如图5~7 所示.
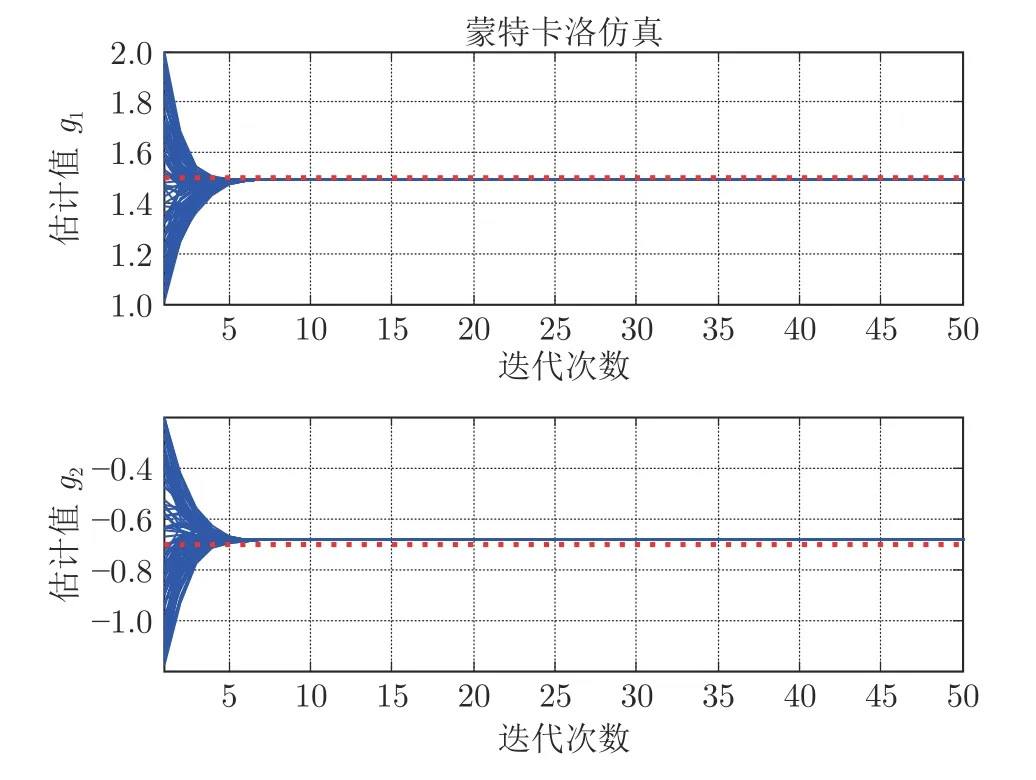
图5 参数g1和g2的蒙特卡洛辨识结果Fig.5 The identifiedg1andg2in Monte Carlo simulations

图6 参数g3和g4的蒙特卡洛辨识结果Fig.6 The identifiedg3andg4in Monte Carlo simulations

图7 噪声参数的蒙特卡洛辨识结果Fig.7 The identified noise variance in Monte Carlo simulations
此外,本文还在不同的噪声条件下测试了算法的性能.首先定义信噪比 (Signal-to-noise rate,SNR)的计算式为
其中,var(·)表示方差操作符.分别在信噪比等于10 dB,15 dB,20 dB,25 dB,30 dB时执行算法2,并且得到辨识结果,如图8、图9 和表1 所示.
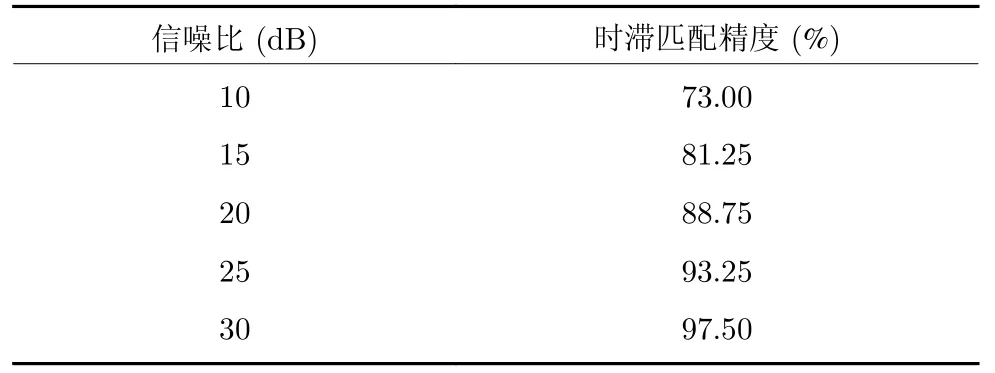
表1 不同信噪比下的未知时滞估计精度Table 1 The estimation accuracy of the unknown delays under different SNRs
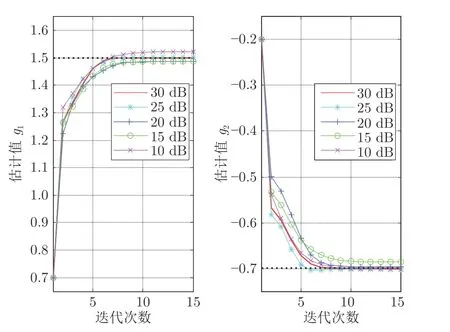
图8 不同噪声下的g1和g2估计结果Fig.8 The identifiedg1andg2under different noise levels
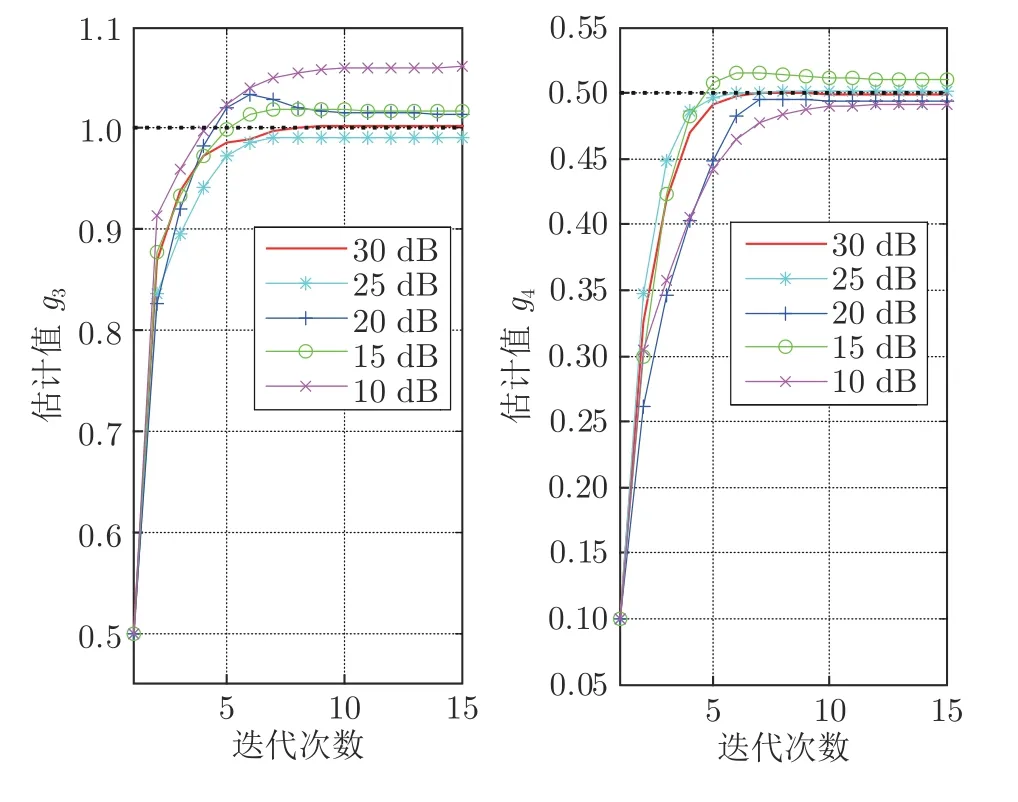
图9 不同噪声下的g3和g4估计结果Fig.9 The identifiedg3andg4under different noise levels
从上述辨识结果可以得出以下结论:
1)从图2~4 可以看出,本文提出的辨识算法能够同时给出模型参数、噪声方差和时变时滞的估计值.经过少数迭代之后,模型参数和噪声参数可以精确地收敛到真实值;同时时滞的估计值和真实值之间的匹配精度达到91%以上,证明了所提算法的有效性.
2)从图5~7 可以看出,在蒙特卡洛仿真中,本文提出的辨识算法依然稳定,在不同的初始值条件下得到的模型参数估计以及时滞参数估计都能精确地收敛到真实值,这进一步证明了所提算法的稳定性.对于迭代过程中出现的数值差异,是由于参数初始值不同而造成的.
3)从图8、图9 和表1 可以看出,当信噪比不断增大时,意味着噪声不断减少且数据质量不断变好,模型参数和时滞参数的估计精度不断提高,并且随着数据质量不断提升,模型参数收敛到真实值的速度也不断加快.上述辨识结果也再次验证了所提算法的有效性.
3.2 对比实验验证
为了进一步验证算法2 的有效性,本文还设计了比较实验.将算法2 分别与两个基于递推最小二乘 (Recursive least squares,RLS)辨识方法进行比较.在第1 种方法中,假设时滞参数精确已知,将这种算法命名为 RLS-accurate;在第2 种方法中,忽略未知的时滞,将这种算法命名为 RLS-ignore.输出量测噪声采用信噪比为20 dB的高斯白噪声,通过执行上述三种辨识算法得到的结果如表2 所示.
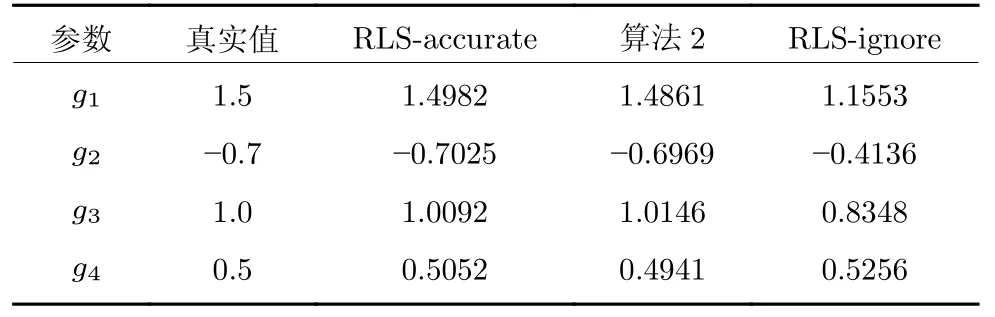
表2 对比实验结果Table 2 The identification results of the comparison tests
由上述辨识结果可以看出:
1)本文提出的辨识算法在参数估计精度上与RLS-accurate 方法相当.再结合表1 的辨识结果可以进一步看出,本文提出的辨识算法在估计时滞参数的同时,也能够精确地给出模型参数的估计结果.
2)由RLS-ignore 方法的辨识结果可以看出,如果忽略时滞因素的影响会造成有偏的参数估计,这从侧面证明了本文提出的算法2 的有效性.
4 结束语
针对时滞取值概率未知的情况,本文基于期望最大化算法提出了一类有效的线性时滞系统辨识算法.将时滞的取值概率当成未知的参数来处理,在辨识过程中所提出的算法能够有效地同时估计模型参数、噪声参数和时滞参数.仿真结果表明,本文提出的辨识算法具有快速的收敛速度以及较强的稳定性.基于本文的研究内容,未来的研究工作可注重以下两方面:
1)跳过高斯假设,在更加复杂的数据条件下,例如在非高斯噪声、自相关噪声以及量化的输出条件下研究时滞系统辨识方法;
2)进一步考虑相邻时刻时滞间的相关性,对于包含相关时滞 (例如:马尔科夫时滞)的系统辨识问题进行深入研究.此方向的研究甚至可以扩展到马尔科夫切换系统辨识方法的研究.
猜你喜欢
数学物理学报(2020年5期)2020-11-26
数学年刊A辑(中文版)(2020年3期)2020-10-27
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
智富时代(2017年4期)2017-04-27
智富时代(2017年4期)2017-04-27
广东石油化工学院学报(2016年6期)2016-05-17
中国铁道科学(2015年4期)2015-06-21
四川师范大学学报(自然科学版)(2015年2期)2015-02-28
噪声与振动控制(2015年4期)2015-01-01
应用数学与计算数学学报(2014年3期)2014-09-26