基于通用逆扰动的对抗攻击防御方法
2023-10-30 10:13陈晋音吴长安郑海斌
自动化学报 2023年10期
陈晋音 吴长安 郑海斌 王 巍 温 浩
随着计算机硬件计算力的发展,深度学习技术[1]凭借其良好的性能和较强的拟合能力广泛应用于计算机视觉[2]、自然语言处理[3]、语音识别[4]、工业控制[5]等领域.然而,近期研究发现,深度学习模型容易受到精心制作的微小扰动的影响[6].对抗攻击可以定义为:在模型测试阶段,攻击者通过在原始数据上添加精心设计的微小扰动得到对抗样本,从而使得深度学习模型完全失效并以较高置信度误判的恶意攻击.在应用深度模型的各个领域,对抗样本均可实现较高概率的攻击,如何设计高效的防御方法提高深度学习模型的鲁棒性是其进一步推广应用的安全保障[7].
已有大量面向深度学习的对抗攻击研究工作,根据其对抗样本生成原理不同,可分为基于梯度的攻击方法、基于优化的攻击方法和其他攻击方法[7].其中,基于梯度的攻击方法利用模型的参数信息,通过目标损失函数对输入的求导得到梯度信息,获取对抗扰动,例如:快速梯度符号法(Fast gradient sign method,FGSM[8])、动量迭代的快速梯度符号法(Momentum iterative fast gradient sign method,MI-FGSM[9])、基于雅克比的显著图攻击(Jacobian-based saliency map attack,JSMA)[10]等.基于优化的攻击方法通过多次查询样本的输出置信度或类标,优化对抗扰动,或者通过等价的梯度信息进行攻击,例如:基于零阶优化的攻击(Zeroth order optimization,ZOO)[11]和基于边界的攻击(Boundary)[12].相比于基于梯度的攻击,基于优化的攻击方法由于需要多次查询计算,因此算法复杂度和运行成本都较高.除此之外,还有基于生成式对抗网络(Generative adversarial network,GAN)的攻击[13]、基于迁移的攻击[14]等.
随着对抗攻击研究的深入,相应的对抗攻击防御方法的研究也相继展开,根据防御方式的差异,可分为基于数据修改的防御、基于模型修改的防御和基于附加网络的防御[7].其中,基于数据修改的防御对模型的输入进行修改,包括数据重编码、数据变换、对抗训练等;基于模型修改的防御包括修改模型的目标损失、在模型中加入随机层、“蒸馏”得到新的网络等;基于附加网络的防御包括添加扰动整流网络、自编码器网络、生成式对抗网络等.已有的防御方法研究大多关注防御成功率,在实际应用中仍面临以下一些挑战:
1)对抗样本依赖,即防御的效果依赖于预先已知的对抗样本的数量和质量,如对抗训练,当遇到新的攻击方法时防御效果不明显;
2)影响良性样本的识别精度,即防御的效果以牺牲良性样本的识别精度为代价,如随机缩放图像操作虽然能够破坏对抗扰动,但也干扰了良性样本识别;
3)参数敏感性与防御实时性,即需要根据数据集和攻击方法调整参数,如数据变换中的图像缩放和图像旋转需要多次测试得到合适的参数,附加网络防御方法增加了计算步骤,降低了模型的处理速度.
通用对抗扰动攻击方法[15]是不断对对抗样本的扰动进行叠加和优化,得到通用扰动,随后叠加到任意良性样本上都能够实现攻击.受到通用对抗扰动攻击[15]的启发,本文提出一种基于通用逆扰动(Universal inverse perturbution,UIP)的对抗样本防御方法(UIP defense,UIPD),通过设计具有通用逆扰动的矩阵,叠加到对抗样本,实现对抗样本的重识别防御.此外,对抗样本鲁棒特征的提出[16],认为样本包含鲁棒特征和非鲁棒特征,且都会影响预测结果.良性样本中两者一致因此得到正确识别结果;而对抗样本中鲁棒特征不受影响,非鲁棒特征变化较大,影响了识别结果.因此,可以通过设计强化样本中的非鲁棒特征,即类相关特征,实现对对抗样本的防御,抵消对抗扰动对非鲁棒特征的影响;而且根据非鲁棒特征在数据分布中的相似性和通用性,设计生成通用逆扰动进行抵消.
本文的主要贡献如下:
1)设计一种基于通用逆扰动的对抗样本防御方法UIPD,仅依据良性样本即可快速生成通用逆扰动矩阵,有效防御多种未知的攻击方法;
2)UIPD 不影响良性样本的识别,在生成UIP的过程中,通过对良性样本的类相关特征进行强化,实现良性样本识别精度提升的效果;
3)UIPD 的参数敏感性低且防御速度快,在多个数据集和多个模型上的实验结果表明了UIPD对各类攻击都具有良好的防御效果.
本文其余部分结构如下:第1 节介绍了对抗攻防的相关工作;第2 节详细说明了UIPD 方法;第3 节实验从多个角度验证UIPD 的性能;最后对全文进行总结和展望,更多的通用逆扰动可视化图示例参见附录A.
1 相关工作
本节主要介绍实验中涉及到的对抗攻击方法与已有的防御方法.
1.1 对抗攻击方法
已有的对抗攻击方法众多,根据对抗样本的生成机理,可以分为以下两类:
1)基于梯度的攻击:指在基于梯度的迭代过程中,寻找图像中关键的像素点进行扰动.Szegedy 等[6]首次证明了可以通过对图像添加无法察觉的扰动误导网络做出错误分类.但由于问题的复杂度太高,于是转而求解简化后的问题,将其称为约束型拟牛顿法(Box-constrained limited memory Broyden-Fletcher-Goldfarb-Shanno,L-BFGS).Goodfellow 等[8]在此基础上,提出快速梯度符号法(FGSM),通过计算单步梯度快速生成对抗样本.Madry 等[17]提出投影梯度下降法(Project gradient descent,PGD),可以将其看作是FGSM 的改进版——KFGSM (K 表示迭代的次数),每次迭代都会将扰动限制到规定范围,提高攻击的有效性.Kurakin 等[18]提出基本迭代法(Basic iterative methods,BIM),将一大步运算扩展为通过多个小步增大损失函数,从而提高对抗样本的攻击成功率并且减小对抗扰动.Carlini 等[19]提出一种对抗攻击方法C&W,通过梯度迭代优化的低扰动对抗样本生成算法,限制L∞、L2和L0范数使得扰动无法被察觉,但是攻击速度较慢.Moosavi-Dezfooli 等[20]提出了深度欺骗攻击(DeepFool),通过迭代计算的方法生成最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类.此方法添加的对抗性扰动比FGSM 更小,同时能够达到相似的攻击效果.一般攻击方法均采用限制L2或L∞范数的值控制扰动,而Papernot 等[10]提出基于雅克比的显著图攻击(JSMA),采取限制L0范数的方法,即仅改变良性样本几个像素生成对抗样本,使得添加的扰动更小.一般的攻击方法只能针对单个样本生成对抗扰动,Moosavi-Dezfooli 等[15]研究并设计了一种通用对抗扰动(Universal adversarial perturbation,UAP)攻击,与DeepFool 攻击相似,使用对抗扰动将图像推出分类边界,但是同一个扰动针对的是所有的图像,结果显示即使是当时最优的深度网络模型也难以抵抗通用扰动的攻击.此外,通用的对抗扰动具有很强的迁移性,即跨数据集、跨模型有效.
2)基于优化的攻击:通过将对抗样本的生成问题转化为多目标的优化问题,使分类模型损失最大化,对抗扰动最小化,导致模型分类错误.Brendel 等[12]提出边界攻击,通过对样本引入最小扰动来改变模型对样本的决策.受C&W 攻击的启发,Chen 等[11]提出基于零阶优化的攻击(ZOO),使用对称差商来估计梯度,进行对抗扰动的优化更新.通过在样本中添加噪声并进行对抗扰动优化是一种常见的对抗攻击方法,Rauber等[21]提出在样本中添加高斯噪声(Additive Gaussian noise attack,AGNA)使分类器出错,添加的扰动是通过多次迭代优化直到使分类器出错的最小扰动.除此以外,Rauber 等[21]通过改变添加的噪声类型,提高攻击的效率,如添加均匀噪声(Additive uniform noise attack,AUNA)和添加椒盐噪声(Salt and pepper noise attack,SPNA).
本文提出的UIPD 在上述的对抗攻击中均取得了良好的防御效果,除了上述的对抗攻击方法以外,还有很多其他优秀的对抗攻击方法:Su 等[22]提出单像素攻击(One pixel attack),使用差分进化算法,对每个像素进行迭代的修改生成子图像,并与原图像对比,根据选择标准保留攻击效果最好的子图像,仅改变图样本中的一个像素值就可以实现对抗攻击.Baluja 等[23]训练了多个对抗性转移网络(Adversarial transformation networks,ATNs)来生成对抗样本,可用于攻击一个或多个网络模型.Cisse 等[24]通过生成特定于任务损失函数的对抗样本实现对抗攻击,即利用网络的可微损失函数的梯度信息生成对抗扰动.Sarkar 等[25]提出了两种对抗攻击算法:精确目标的通用扰动(Universal perturbations for steering to exact targets,UPSET)攻击和生成恶意图像的对抗网络(Antagonistic network for generating rogue images,ANGRI)攻击.UPSET 攻击为针对原始样本生成具有通用扰动的对抗样本,且可以使模型误分类为指定的目标类别,而ANGRI 攻击为针对原始样本生成具有特定扰动的对抗样本,且可以使模型误分类为指定的目标类别.
以上攻击方法都是基于肉眼不可见扰动的对抗攻击,除了基于对抗扰动的攻击外,还有一类基于对抗补丁的攻击.Brown 等[26]提出一种在物理空间的对抗图像补丁的方法.Karmon 等[27]利用修改后的损失函数,使用基于优化的方法提升对抗补丁的鲁棒性.为了提高视觉保真度,Liu 等[28]提出了PSGAN 框架来生成类似涂鸦的对抗补丁,以愚弄自动驾驶系统.为了解决对抗补丁泛化能力差的问题,Liu 等[29]利用模型的感知和语义上的偏见,提出了一个基于偏见的框架生成具有强泛化能力的通用对抗补丁方法.综上,基于补丁的对抗攻击也是一种有效的攻击方法.
1.2 对抗防御方法介绍
根据防御效果,防御方法可分为仅检测防御和重识别防御,仅检测防御是对检测出的攻击样本进行甄别,而不做进一步处理;重识别防御则是将对抗样本进行还原处理,重新识别其正确类标,UIPD属于重识别防御方法,因此在实验中采用的对比算法同样都属于重识别防御.而根据防御作用对象的不同,可以进一步分为以下三类:
1)基于数据预处理的防御:指在模型训练前,或模型测试的过程中,对数据进行预处理,从而提高模型对于对抗样本的防御性.Xie 等[30]研究发现,对图像进行尺寸变换或者空间变换能有效降低对抗样本的攻击性能,这是一种非常简单有效的数据预处理防御方法,但无法从根本上提升模型的防御能力.Song 等[31]提出了对抗训练方法,通过生成的大量对抗样本,然后将对抗样本作为模型的训练集执行对抗训练,从而不断提升模型的鲁棒性,该方法需要使用大量高强度的对抗样本,并且网络架构要有充足的表达能力,高度依赖于对抗样本的数量和质量,面对多种攻击组合时防御的泛化能力较弱.为此,Miyato 等[32]和Zheng 等[33]分别提出了虚拟对抗训练和稳定性训练方法提升防御效果.Dziugaite等[34]提出基于数据压缩的方法,使用JPG 图像压缩的方法,减少对抗扰动对于模型的干扰,但同时也会降低对良性样本的分类准确率.此外,Das 等[35]通过研究数据中的高频成分,提出了集成防御技术.Luo 等[36]提出基于“Foveation”机制的防御方法提高显著鲁棒性.对抗训练能够提高深度模型的鲁棒性,但是需要生成大量的对抗样本,存在防御代价大、无法防御没有出现过的攻击等问题.
2)基于网络修正的防御:指通过添加或者改变多层/子网络、改变损失/激活函数等方式,改变模型的架构和参数,从而滤除扰动,提高模型的防御性.受到将去噪自编码器(Denoising auto encoders,DAE)堆叠到原来的网络上会使其变得更加脆弱这一特性的启发,Gu 等[37]引入深度压缩网络(Deep compression network,DCN),减少对抗样本的扰动.Rifai 等[38]通过添加平滑操作训练DCN 滤除扰动.Ross 等[39]提出使用输入梯度正则化以提高对抗攻击鲁棒性,该方法和对抗训练结合有很好的效果,但防御代价以及防御的复杂度都会提高一倍以上.Hinton 等[40]提出可以使用“蒸馏”的方法将复杂网络的知识迁移到简单网络上后,Papernot 等[41]基于“蒸馏”的概念设计对抗防御方法,通过解决数值不稳定问题扩展了防御性蒸馏方法.Nayebi 等[42]受生物启发,使用类似于生物大脑中非线性树突计算的高度非线性激活函数以防御对抗攻击.Cisse 等[43]提出了在一层网络中利用全局Lipschitz 常数加以控制,利用保持每一层的Lipschitz 常数来减少对抗样本的干扰的防御方法.Gao等[44]提出DeepCloak 方法,在分类层的前一层加上特意为对抗样本训练的额外层以掩盖对抗扰动.此外,Jin 等[45]通过引入前馈神经网络添加额外噪声减轻攻击的影响.Sun 等[46]基于统计滤波设计了超网络提高网络鲁棒性.Madry 等[17]从鲁棒优化角度研究了对抗防御性.通过网络修正的方式改变模型内部结构和参数的优化能够有效提高模型的鲁棒性,采取梯度隐蔽、蒸馏结构、激活函数重设计等措施提高模型防御性能.
3)基于附加网络的防御:指在保持原始深度学习模型结构不变的前提下,添加外部模型作为附加网络来提高原始模型防御性能.针对对抗攻击的防御,Akhtar 等[47]通过添加扰动整流网络,利用一个单独训练的网络附加到目标网络上,以抵御通用扰动产生的对抗性攻击,达到不需要调整原本的网络参数也能对对抗样本产生良好的防御效果的目的.Hlihor 等[48]在训练过程中将对抗样本提供给自动编码器,从而滤除对抗性扰动,并减少输出样本与干净样本之间的距离.孔锐等[49]研究了基于GAN 框架训练目标模型的鲁棒性.Samangouei 等[50]使用GAN 生成与对抗样本相似但不含扰动的样本,实现防御.Lin 等[51]在Samangouei 等[50]的工作基础上,在GAN 结构中引入自编码器,提高防御效率.Jin 等[52]提出对抗扰动滤除的生成式对抗网络(Adversarial perturbation elimination with GAN,APE-GAN),利用对抗样本训练基于GAN 的防御模型,达到正确识别对抗样本,同时不影响干净样本的识别的目的.Xu 等[53]提出特征压缩法,用两个近似模型检测图像中的对抗扰动.Ju 等[54]研究了多个模型的集成决策防御,提出了一种集成对抗防御方法.
本文提出的通用逆扰动对抗防御方法与贝叶斯案例模型(Bayesian case model,BCM)[55]通过选择数据中具有代表性的典型样本,然后提取典型样本中的重要特征,达到对基于案例推理算法和原型分类算法的解释,在思想上相似,但是主要任务、技术方法与应用场景均不同.
2 基于通用逆扰动的防御方法
2.1 基本定义
通常,神经网络的前向传播过程表示为f:RM →RN,其中M表示输入的维度,N表示输出的维度.进一步,可以将整个模型表示为:f(x,θ):X →Y,其中x∈X表示模型输入,Y表示模型的输出,θ表示模型的内部参数.进一步将θ表示为深度模型的各层非线性权重与偏置组合:θ=w×ϕ(x)+b,其中w表示权重矩阵,在训练的过程中更新,x∈X表示输入矩阵,即原始数据集中的良性样本,b表示偏置,ϕ(x)表示输入样本特征.y∈Y表示良性样本的真实类标经过one-hot 编码后的数组,l=arg max(y),arg max(·)表示数组元素值最大的位置的坐标作为真实类标,l∈{0,1,2,···,N-1}.=f(x,θ)表示良性样本的预测置信度数组,表示预测类标,.当时,则预测正确,反之则预测错误.以交叉熵为例,定义模型训练的损失函数为
其中,m表示训练样本数,分别表示数组y和在位置i处的值,log(·)表示对数函数.训练的优化目标是最小化损失,即arg minLossCE,一般采用梯度下降法,梯度计算式为
进一步得到权重的更新式为
其中,lr表示学习率.
当模型受到攻击后,攻击者会在良性样本上添加精心设计的扰动得到对抗样本,表示为x*=x+Δx,其中Δx表示对抗扰动.将对抗样本输入模型后,得到是对抗样本的预测置信度数组,表示预测类标,={0,1,2,···,N-1}.当时,则无目标攻击成功;当时,其中lt是攻击者预设的攻击目标,则目标攻击成功;当时,则攻击失败.攻击的目的是实现损失的增大,即arg maxLossCE,同样采用梯度下降计算
进一步得到对抗样本的更新式为
其中,ε表示迭代步长,“+”运算表示样本与对抗扰动叠加.
最后,使用防御方法加固模型后,重新实现损失的最小化.根据前面的定义,可以采用对权重更新,也可以采用对样本更新,UIPD 方法是对样本进行更新实现防御,恰好是式(5)的逆过程,可以粗略表示为
2.2 通用逆扰动生成方法
通用逆扰动的通用性体现在:测试阶段,只需单个逆扰动,就可以对不同攻击方法生成的任意对抗样本实现防御;训练阶段,不涉及到攻击方法和对抗样本.生成过程如图1 所示,其中UIP 与训练集样本的尺寸和维度一致,首先初始化为0;然后分别和训练集中的每一张样本叠加后输入到深度模型中,计算损失函数;最后根据损失的趋势得到逆扰动在特征空间中的位置,反馈训练更新通用逆扰动.
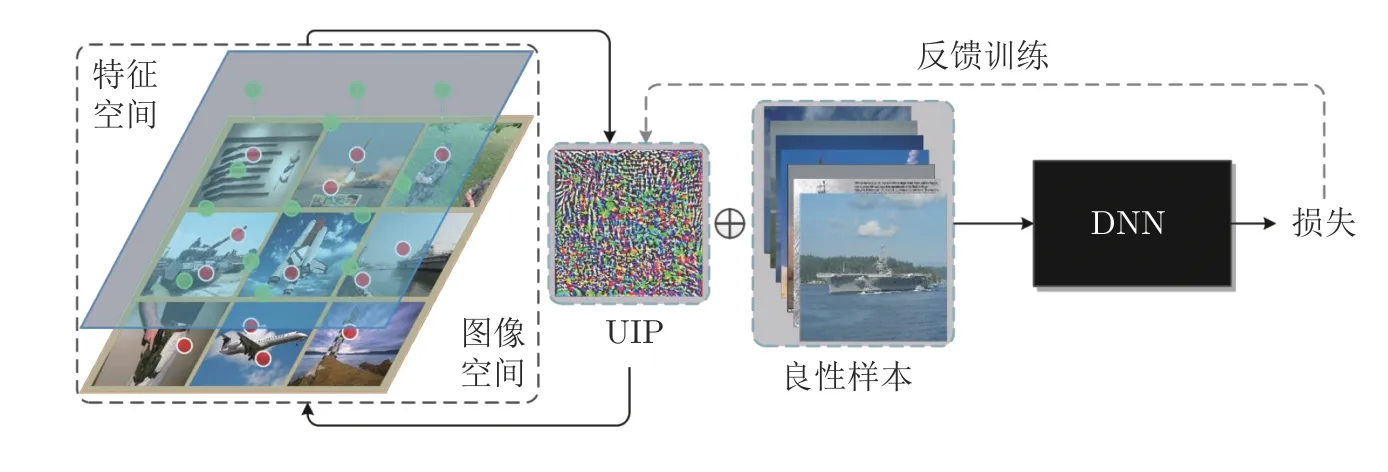
图1 通用逆扰动防御方法框图Fig.1 The framework of UIPD method
图1的方法框图中包括UIP、良性样本和深度神经网络(Deep neural network,DNN)模型三部分,UIP 通过对图像空间的特征进行不断迭代强化,提取良性样本的特征,并通过反馈训练对UIP 不断进行加强.在迭代过程中,图1 形象地展示了通用逆扰动与良性样本、特征空间的关系.在前文中提到,通用逆扰动强化了良性样本的类相关特征,因此能够保持良性样本的识别准确率,甚至在一定范围内提升识别准确率.但是通用逆扰动不是直接采样自样本空间,而是通过损失反馈训练学习其在高维特征空间中的分布,这解释了通用逆扰动对数据样本和攻击方法具有较好的通用性,但是对同一个数据集的训练模型的通用性则较差.
根据式(6)和图1 的说明可以得到通用逆扰动的生成式.首先令,则深度模型变为
其中,xi表示原样本,表示通用逆扰动矩阵,表示原样本叠加上通用逆扰动矩阵后的样本.
此时的梯度是损失函数对叠加后的输入进行求导,得到
其中,gxi表示此时的梯度,LossCE表示交叉熵损失函数.
进一步得到修改后的UIP 迭代式
因为其中良性样本在迭代前后不变,所以两边减去一个xi,得到最终UIP 迭代式其中,εuip表示通用逆扰动矩阵的迭代步长.
需要说明的是,图1 中的UIP 即是在Image-Net 数据集、VGG19 模型上优化得到的通用逆扰动,为了更好的可视化,将其归一化到[0,1]的范围内进行可视化,原始的UIP 的均值为:-0.0137,方差为:0.0615,是十分微小的.UIPD 方法的详细伪代码如算法1 所示.
算法 1.UIPD 方法
2.3 算法复杂度分析
对算法的时间复杂度进行分析,UIPD 的时间复杂度包括训练时间复杂度和测试时间复杂度,根据算法1 可知,其训练的时间复杂度和测试的时间复杂度都是O(n),都是与样本数呈一阶增长关系.尽管在算法1 中存在两个“For”循环语句,但是最大epoch 数是一个常数,因此训练时间复杂度是O(ntrain);而测试时,只需要将良性样本与UIP 做“+”运算操作(“+”运算操作是指将训练完成的UIP 与良性样本进行像素上的叠加,即将UIP 以一种“扰动”的形式添加到良性样本图像上去,在完成“+”操作的过程中,需要先将UIP 与良性样本转化为数组像素值,完成“+”操作后再以图像形式输出),因此也是O(ntest),其中ntrain和ntest表示训练样本数和测试样本数.相比于数据修改防御中的数据变换操作,如resize、rotate 等,UIPD 方法多了训练的时间复杂度,但是由于UIP 能够进行离线训练和在线防御,训练样本是有限的,即ntest≫ntrain,因此其训练时间复杂度是可以忽略的;相比于对抗训练,UIPD 方法不需要使用大量的对抗样本进行训练,节省了大量的对抗样本生成时间.
分析空间复杂度,无论是在训练过程,还是在测试过程,UIPD 方法都是只需要占据一个UIP 存储的空间,因此空间复杂度是O(1).
2.4 通用逆扰动有效性分析
本文从高维特征的决策边界和样本的鲁棒安全边界两个角度说明通用逆扰动的有效性.基于样本在高维特征空间中的分布和决策边界,分析UIP 具有防御效果的原因.如图2 所示,UIPD 方法不改变模型的决策边界,因此决策边界是固定的,但样本在决策空间的位置与决策边界是相对而言的,UIP导致样本在决策空间中的位置发生了变化,导致样本与决策边界的相对位置发生了变化,使得原本在错误决策空间的样本重新回到正确决策空间.当训练好一个模型,良性样本被正确分为C1 类和C2类,其中还存在C2 类的一个样本被误分类为C1(图中的灰色方块).当良性样本叠加了UIP 后,能够促使样本在特征空间中的分布向类中心移动,从而改善良性样本识别结果 (即将原本分类错误的样本进行正确识别).当模型受到攻击,原本处在决策边界附近的样本越过边界进入错误类的特征空间(即图中的红色圆点).此时,当对抗样本叠加了UIP 后,能够重新回到正确的特征空间并向类中心移动.
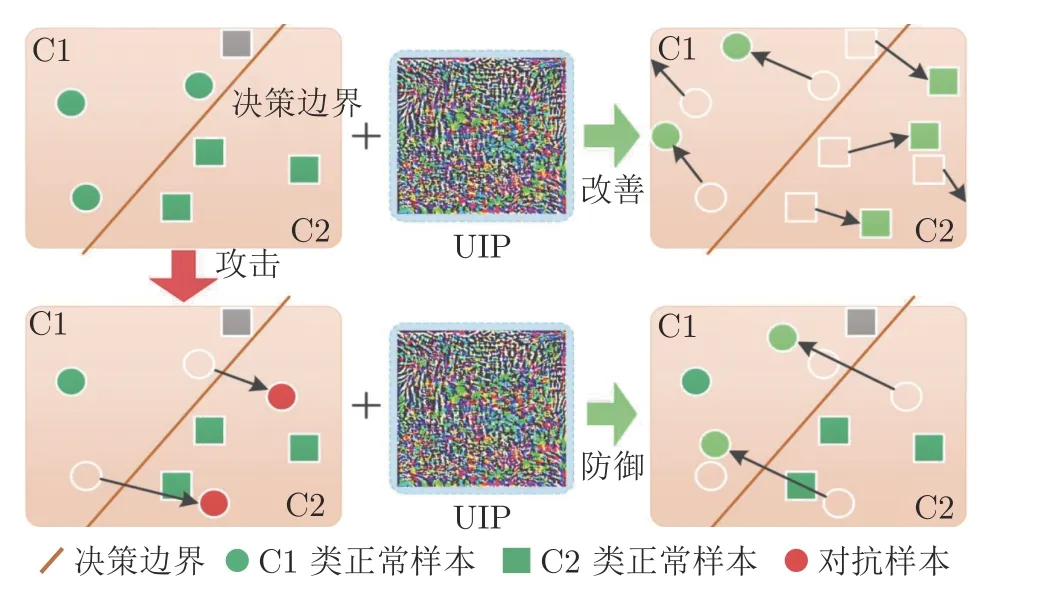
图2 基于特征分布和决策边界的UIPD 分析示意图Fig.2 The UIPD analysis based on feature distribution and decision boundary
基于样本的鲁棒安全边界说明UIP 具有防御效果的原因,具体如图3 所示.最优化观点认为,模型的鲁棒性可以等价为一个最大最小模型.最大化攻击者的目标函数,其物理意义是寻找合适的扰动使损失函数在(x+Δx,y)这个样本点上的值越大越好;最小化防御者的目标函数,其目的是为了让模型在遇到对抗样本的情况下,整个数据分布上的损失的期望还是最小.基于最优化观点建模的计算式为
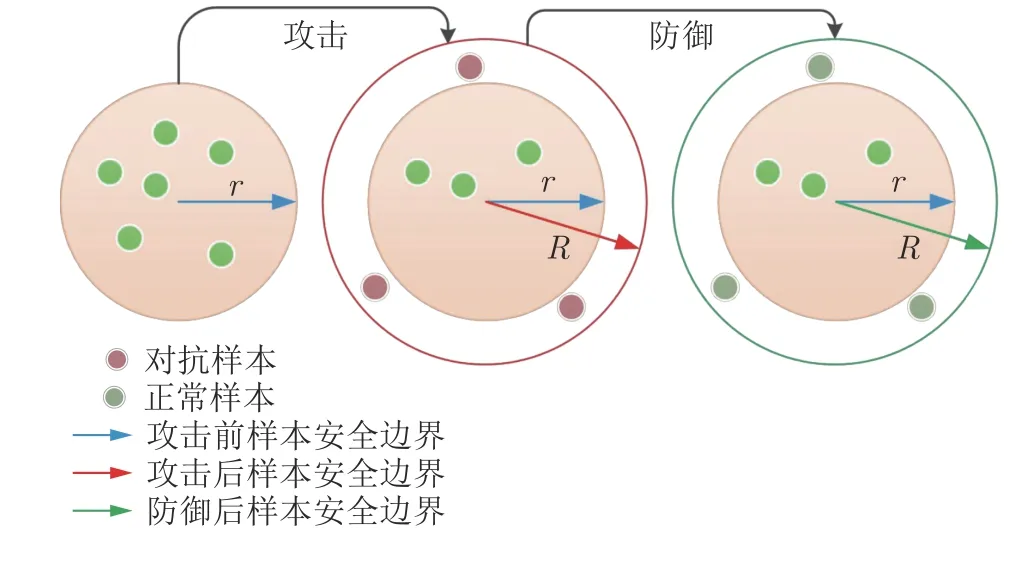
图3 基于鲁棒安全边界的UIPD 分析示意图Fig.3 The UIPD analysis based on robust security boundaries
其中,ρ(·)是需要最小化的防御目标,w表示权重矩阵,x表示输入矩阵,y表示样本标签,E(x,y)~D[·]表示平均损失,D(x,y)表示输入和标签所在的联合概率分布,Δx表示对抗扰动,L(·,·,·)表示损失函数.式中Δx∈Sx,即此时对抗样本的扰动落在Sx范围内都是安全的,因此将Sx称为输入扰动的安全边界.
图3中,良性样本的安全边界原本是r,即Sx ≤r时为安全;受到攻击后,发生了样本点落在半径r以外的事件,但是若此时能够将安全边界由r拓展到R,则可以实现新的鲁棒边界;UIPD 方法的防御过程就是通过学习数据样本在高维特征空间中的类相关重要特征,然后反映在图像空间中,最后等效于将Sx ≤r的安全边界拓展为Sx ≤R.
3 实验与结果
本节首先介绍实验基本设置,包括软硬件环境、数据集、深度模型、攻击方法、防御方法、评价指标等.然后,从UIP 在攻击方法上的通用性、数据样本上的通用性,与不同防御方法的防御效果比较,在良性样本识别中的性能改善、参数敏感性和时间复杂度等方面进行实验和分析.
3.1 基本实验设置
1)实验硬件及软件平台:i7-7700K 4.20 GHz×8 (CPU),TITAN Xp 12GiB×2 (GPU),16 GB×4 memory (DDR4),Ubuntu16.04 (OS),Python3.7,Tensorflow-gpu 1.1.14,Tflearn 0.3.2.2.
2)数据集:实验采用MNIST、Fashion-MNIST (FMNIST)、CIFAR-10 和ImageNet 四个公共数据集.其中,MNIST 数据集包括10 类共60 000张训练样本及10 类共10 000 张测试样本,样本大小是28×28 的灰度图像;CIFAR-10 数据集由10类共50 000 张训练样本及10 类共10 000 张测试样本组成,样本是大小为32×32×3 的彩色图片;FMNIST 数据集包括10 类共60 000 张训练样本及10 类共10 000 张测试样本,样本大小是28×28的灰度图像;ImageNet 数据集由1 000 多类共计200 多万张样本组成,本文随机挑选训练集中的10类图片进行实验,每类1 300 张样本,其中70%作为训练样本,30%作为测试样本.实验中的所有图像像素值都归一化到[0,1].
3)深度模型:针对MNIST 数据集,分别使用AlexNet、LeNet 和自己搭建的网络结构(M_CNN);针对FMNIST 数据集,分别使用AlexNet 和自己搭建的网络(F_CNN);针对CIFAR-10 和Image-Net 数据集,都使用VGG19 网络.由于MNIST 和FMNIST 数据集十分相似,实验中M_CNN 和F_CNN 使用相同的结构,如表1 所示.深度模型的训练参数采用Tflearn 提供的默认参数.
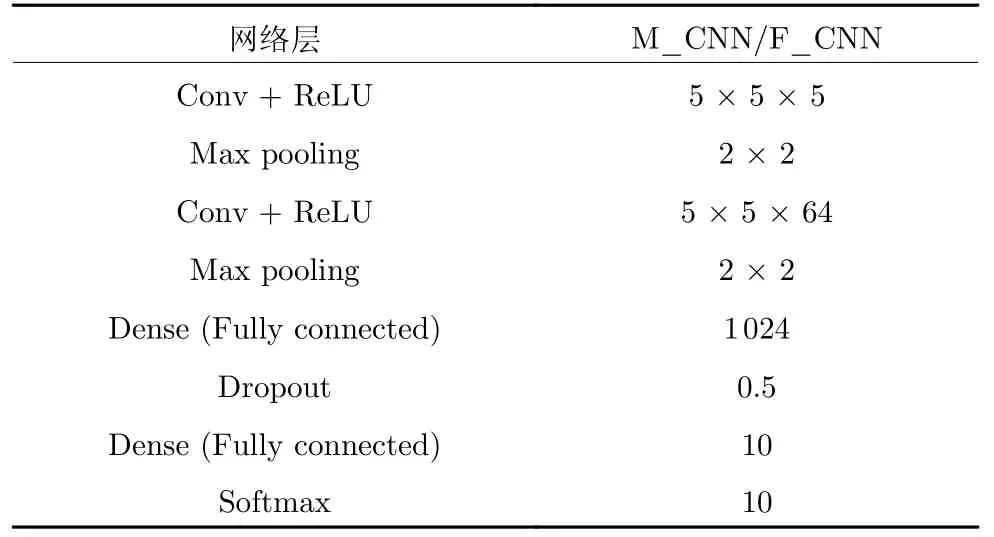
表1 自行搭建的网络模型结构Table 1 The network structure built by ourselves
4)攻击方法:为了证明生成的UIP 对于不同攻击方法的通用性,采用了FGSM[8]、BIM[18]、MIFGSM[9]、PGD[17]、C&W[19]、L-BFGS[6]、JSMA[10]、DeepFool[20]、UAP[15]、Boundary[12]、ZOO[11]、AGAN[21]、AUNA[21]、SPNA[21]共14 种攻击方法,攻击调用foolbox[21]的函数,参数默认.
5)防御方法:实验选择了8 种防御方法作为对比算法,分别是resize[30]、rotate[30]、Distillation Defense (Distil-D)[41]、Ensemble Defense (Ens-D)[54]、Defense GAN (D-GAN)[50]、添加Gaussian 噪声(GN)、DAE[37]和APE-GAN[52].为了使对比实验更全面,选取的对比算法包含了重识别防御的3 类防御方法,其中resize、rotate 和GN 是基于数据预处理的防御;Distil-D 是基于网络修正的防御;Ens-D、D-GAN、DAE 和APE-GAN 是基于附加网络的防御.以下对参数进行具体说明,其中选定的缩放尺寸和旋转角度参数都是经过多次修改测试,挑选出最优的参数.
a)resize1:对于MNIST 和FMNIST,首先将样本缩小为6 × 6,再放大回28 × 28.对于CIFAR-10,首先将样本缩小为16 × 16,再放大回32 × 32;对于ImageNet,首先将样本缩小为128 × 128,再放大回224 × 224.
b)resize2:对于MNIST 和FMNIST,首先将样本放大为32 × 32,再缩小回28 × 28;对于CIFAR-10,首先将样本放大为56 × 56,再缩小回32 ×32;对于ImageNet,首先将样本放大为512 × 512,再缩小回224 × 224.
c)rotate:对于MNIST、FMNIST、CIFAR-10和ImageNet 数据集,首先将样本顺时针旋转45°,再逆时针旋转45°.
d)Distil-D:对于MNIST、FMNIST 和CIFAR-10 数据集,蒸馏训练epoch 设置为20,批尺寸为64,学习率为0.001,优化器为Adam;对于Image-Net 数据集,蒸馏训练epoch 设置为50,批尺寸为16,学习率为0.0001,优化器为Adam.
e)Ens-D:对于MNIST、FMNIST,集成3 种模型:AlexNet、LeNet 和M_CNN;对于CIFAR-10 和ImageNet,集成3 种模型:AlexNet、VGG16和VGG19.
f)D-GAN:对于MNIST、FMNIST,训练生成式对抗网络的参数:epoch 设置为10,批尺寸为32,学习率为0.001,优化器为Adam;对于CIFAR-10,生成式对抗网络的参数:epoch 设置为30,批尺寸为32,学习率为0.001,优化器为Adam;对于Image-Net,训练生成式对抗网络的参数:epoch 设置为50,批尺寸为16,学习率为0.001,优化器为Adam.
g)GN:在样本上添加均值为0、方差为1 的随机高斯噪声,作为UIP 的对照,说明UIP 具有一定的规律.
h)DAE:对于MNIST、FMNIST,训练编码器和解码器的参数:epoch 设置为10,批尺寸为64,学习率为0.001,优化器为Adam;对于CIFAR-10,训练编码器和解码器的参数:epoch 设置为20,批尺寸为64,学习率为0.001,优化器为Adam;对于ImageNet,训练编码器和解码器的参数:epoch 设置为50,批尺寸为32,学习率为0.001,优化器为Adam.
i)APE-GAN:对于MNIST、FMNIST,训练生成式对抗网络的参数:epoch 设置为20,批尺寸为32,学习率为0.001,优化器为Adam;对于CIFAR-10,训练生成式对抗网络的参数:epoch 设置为40,批尺寸为32,学习率为0.001,优化器为Adam;对于ImageNet,训练生成式对抗网络的参数:epoch 设置为50,批尺寸为16,学习率为0.001,优化器为Adam.
6)评价指标:本文采用分类准确率(Accuracy,ACC)、攻击成功率(Attack success rate,ASR)、防御成功率(Defense success rate,DSR)和相对置信度变化(Rconf)来评价UIPD.具体为
其中,N表示待分类的良性样本数,nright表示分类正确的良性样本数,nadv表示攻击成功的对抗样本数,即成功被深度模型错误识别的样本数量,表示防御后重新分类正确的对抗样本数量.
其中,confD(ltrue)表示防御后真实类标的预测置信度,confA(ltrue)表示攻击后真实类标的预测置信度,confA(ladv)表示攻击后对抗类标的预测置信度,confD(ladv)表示防御后对抗类标的预测置信度.
7)实验步骤:首先,如图1 所示,通过良性样本的特征空间与深度学习模型的损失进行迭代训练,生成通用逆扰动,具体算法如算法1 所示:输入包括良性样本集X,分类器f(x),逆扰动步长εuip和最大epoch 数N,接着初始化通用逆扰动ρuip,利用良性样本集的样本特征和标签对通用逆扰动进行迭代训练,训练完成后得到通用逆扰动.随后,在不同的攻击算法下针对深度模型分类器f(x)生成各类型的对抗样本.最后,训练得到的通用逆扰动添加到对抗样本中,完成识别防御.
3.2 UIPD 的攻击方法通用性
本文主要验证了同一个数据集和模型的UIP在不同攻击方法下的通用性.具体实验结果如表2所示,实验中采用DSR 来衡量UIPD 方法对不同攻击的防御有效性.
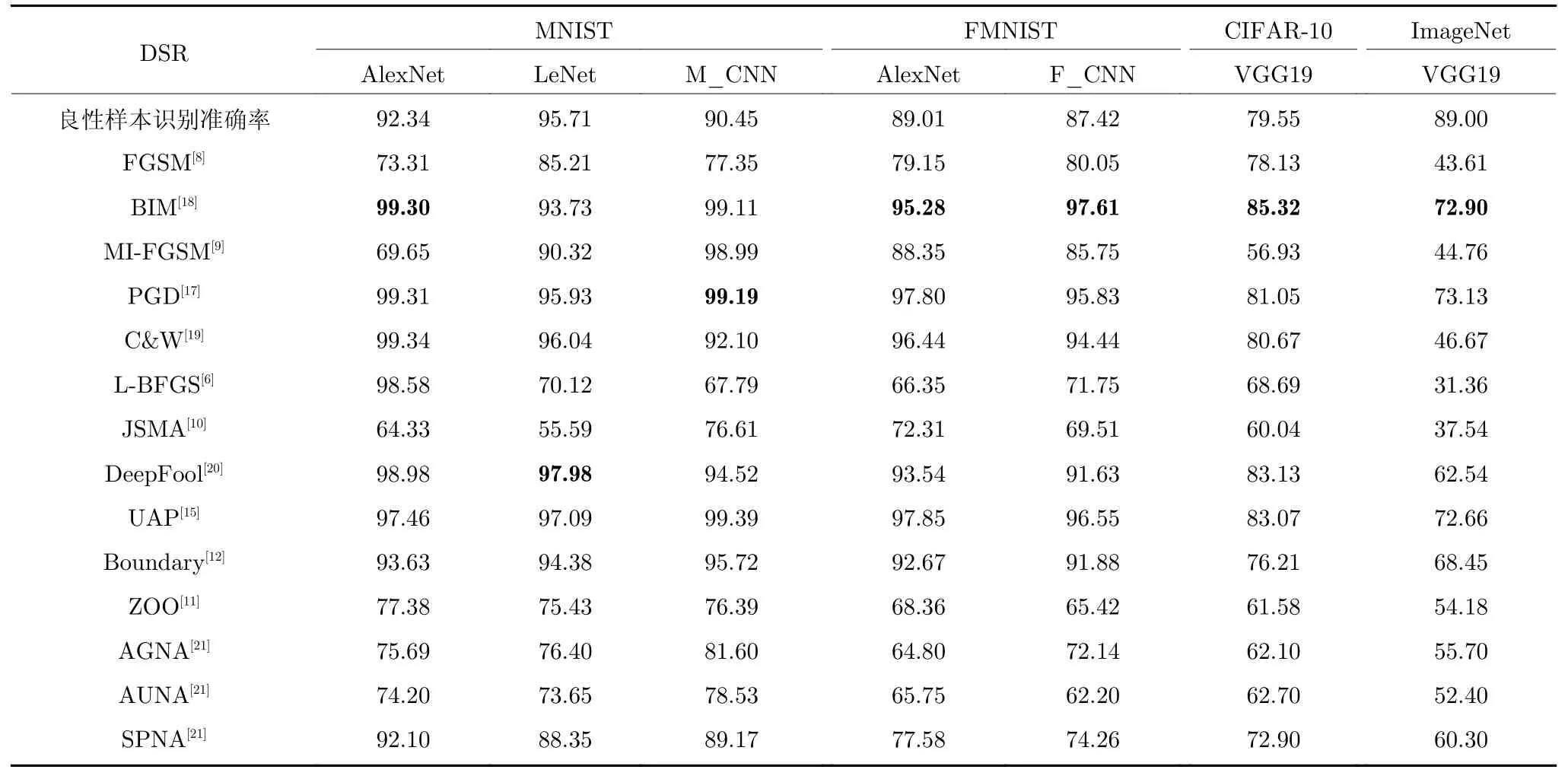
表2 UIPD 针对不同攻击方法的防御成功率(%)Table 2 The defense success rate of UIPD against different attack methods (%)
由表2 可知,在MNIST、FMNIST 和CIFAR-10 这三个小数据集上,每个模型训练得到的UIP在不同攻击方法下都能达到50%以上的防御成功率,大部分情况下能达到70%以上.对于Image-Net 大数据集,通用逆扰动防御在不同攻击方法下的防御成功率也能达到30%以上.UIP 对不同攻击方法的防御能力在小数据集上普遍优于大数据集,这是因为小数据集的图像尺寸小,所包含的特征信息也远小于ImageNet 大数据集中的图像,所以训练UIP 时更容易收敛,而且包含的非鲁棒性特征更加全面,导致UIP 的防御效果更优.
除此之外,还可以观察到,同一个UIP 虽然对不同的攻击方法都有效果,但是防御效果在不同攻击方法上也是有差异的.同一个UIP 在DeepFool和PGD 上的防御效果明显优于JSMA,这是因为不同攻击方法生成的对抗扰动的大小和约束条件不同.DeepFool 和PGD 要求扰动的L2范数尽可能小,这导致了虽然这些攻击方法生成的对抗样本更加隐蔽,但对抗样本中包含的非鲁棒性特征更容易被UIP 抵消,所以防御效果更好.但是JSMA 的攻击中限制扰动的个数而不限制单个像素点的扰动大小,攻击时一旦发现非鲁棒性特征的像素点,就会改变很大的像素值去激活非鲁棒性特征,所以UIP很难完全抵消被激活的非鲁棒性特征,这就导致了防御效果更差一点.基于优化的攻击通过不断优化对抗扰动,生成扰动较小但攻击性强的对抗样本,因此,UIPD 在针对基于优化的攻击上的防御效果普遍低于基于梯度的攻击.
在式(11)的基础上,使用最优化观点看待UIP的防御过程,具体为
其中,ρ(·)是需要最小化的优化目标,x表示输入,y表示样本标签,E(x,y)~D[·]表示平均损失,D(x,y)表示输入和标签所在的联合概率分布,Δxuip表示通用逆扰动,L(·,·,·)表示损失函数.上述建模中Δxuip∈Sx,即此时扰动落在Sx范围内都是安全的,因此将Sx称为安全边界.UIP 使用梯度下降的优化算法进行迭代训练,在已训练好的模型基础上进一步朝着损失函数下降的方向进行UIP 的扰动优化,这一过程中能够提取更多的样本特征,强化良性样本中的类相关特征,使得样本向着类中心移动,UIP 的训练使用的是全局样本,即训练集所有样本,因此同一个全局UIP 能够对不同类都能使用.
综合而言,UIP 在不同攻击方法上都有较好的防御效果.
3.3 UIPD 对数据样本的通用性
本节主要介绍UIPD 方法在同一个模型和数据集上对所有样本数据的通用性.表3 展示了UIPD 在M_CNN 模型上、MNIST 数据集中不同样本的通用性(更多模型上的数据集通用性展示见附录A).图4 展示了MNIST 数据集中不同模型的UIP 可视化图(更多数据集中不同模型的UIP可视化图见附录A).

图4 MNIST 数据集中不同模型的 UIP 可视化图Fig.4 The UIP visualization of MNIST dataset in different models
由表3 的前两组数据可知,MNIST 数据集中0 到9 个良性样本在加上同一个UIP 后,类标和置信度都没有改变,体现了UIPD 在不损失良性样本分类准确率上的通用性.表3 的第3 组表示分类错误的0~9 个对抗样本.由第4 组可知,在加上同一个UIP 后,9 张对抗样本都以较高的置信度重新正确分类,这体现了UIPD 在防御同一数据集中的对抗样本的通用性.
图4中的UIP 可视化图由python 中的matplotlib 库里面的pyplot 以rainbow 的涂色形式绘制,像素值归一化到[0,1].由图4 可知,同一数据集下的不同模型的UIP 都不相同,但是UIP 的均值和方差都很小,所以图像加上UIP 后的效果不影响人的视觉感受.由式(5)和式(6)可知,UIP 通过对样本进行更新生成的过程是对抗样本生成的逆过程,对抗样本与UIP 的生成过程都是通过样本反馈到损失函数,进而完成对模型预测输出的影响,不同之处在于,对抗样本生成扰动的方向是损失函数增大的方向,而UIP 生成扰动的方向是损失函数减小的方向,因此,UIP 不仅不会对模型的预测准确率产生不良影响,反而能够对模型分类精度有一定提升作用.由算法1 可知,在UIP 的迭代过程中,输入深度模型分类器f(x)是已经训练完成的收敛模型,因此UIP 在较小的逆扰动步长εuip下,最终生成的UIP 的扰动大小在较小范围内就能够使模型达到收敛.
3.4 不同防御方法的防御效果比较
在本节中,本文主要比较了UIPD 与其他防御方法针对不同模型、不同数据集,采用不同攻击方法生成的对抗样本的防御效果.具体实验结果如表4 和表5 所示,其中表4 是不同防御方法针对基于梯度的各种攻击方法的防御效果,表5 是不同防御方法针对基于优化的各种攻击方法的防御效果.本文用DSR 和Rconf 来衡量不同防御方法之间的防御有效性.表4 和表5 中的DSR 均是两类攻击方法中不同攻击的平均防御成功率.
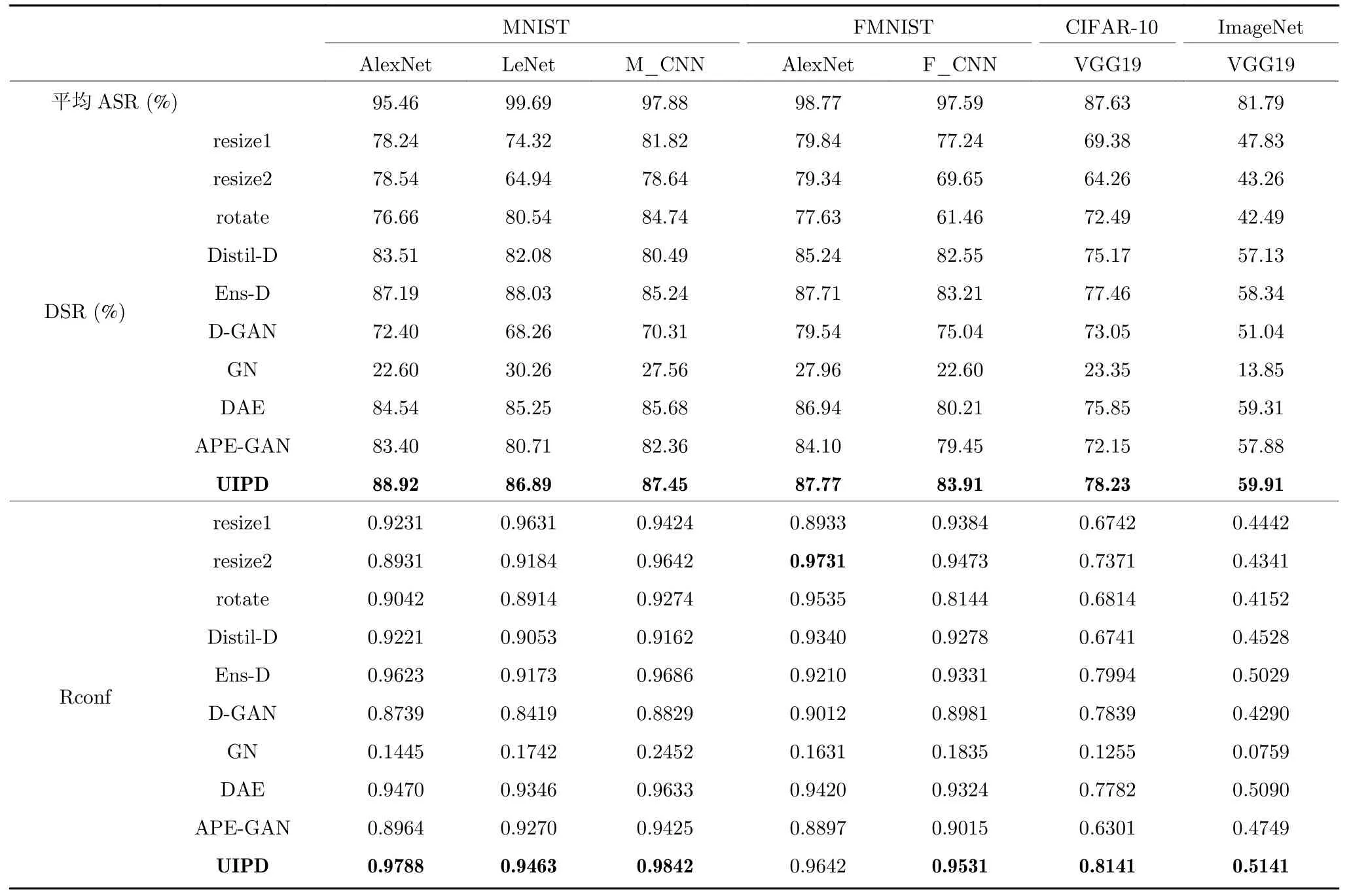
表4 不同防御方法针对基于梯度的攻击的防御效果比较Table 4 The performance comparison of different defense methods against gradient-based attacks
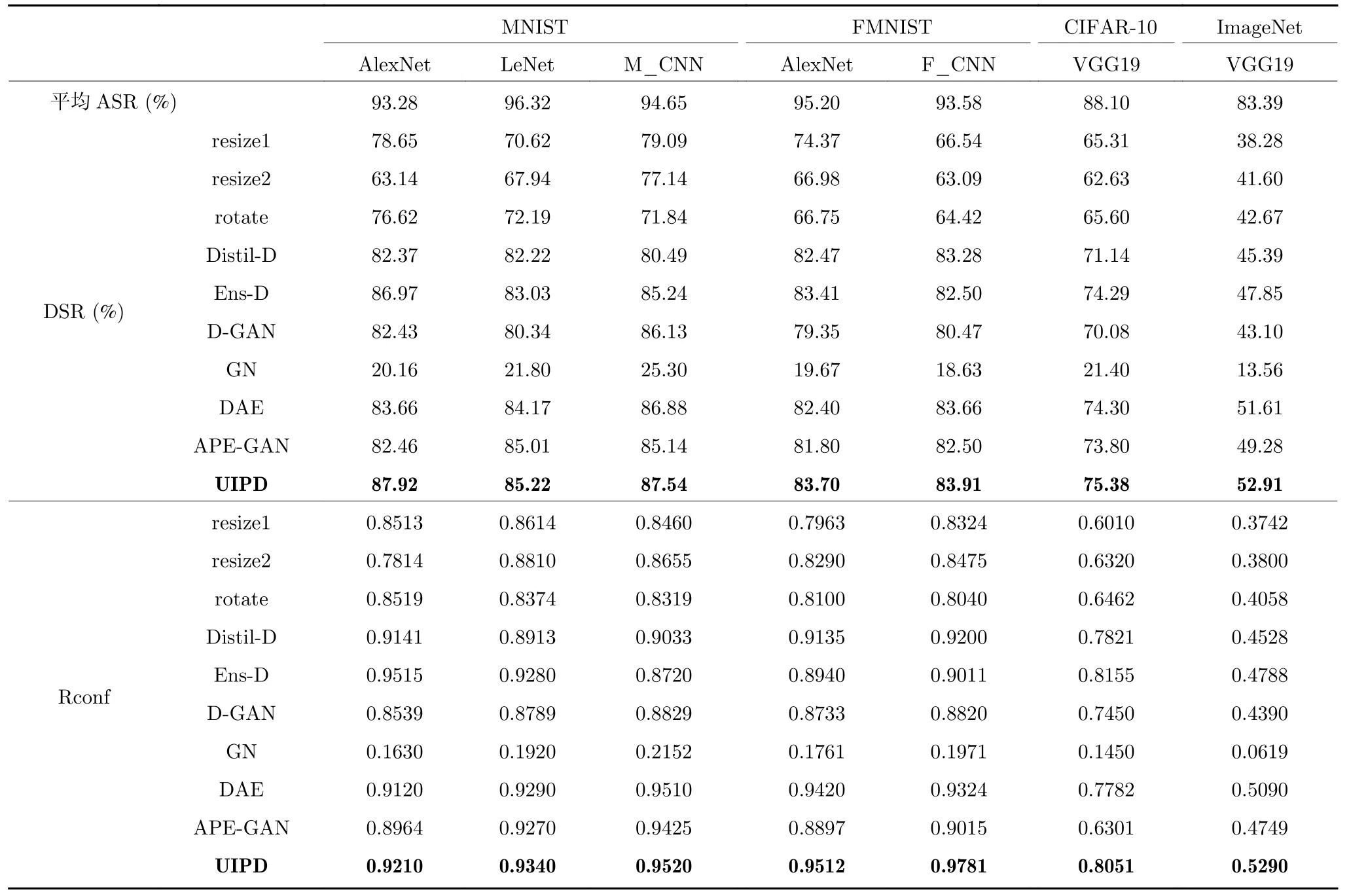
表5 不同防御方法针对基于优化的攻击的防御效果比较Table 5 The performance comparison of different defense methods against optimization-based attacks
首先,本文比较表4 和表5 中不同防御方法在不同模型和不同数据集下的DSR.在任意模型和数据集中,UIPD 的DSR 均高于图像缩放、图像旋转、基于GAN 的防御、基于自编码器的防御、高斯噪声、蒸馏防御和集成防御,本文提出的UIPD 不需要依赖大量的对抗样本,也不改变模型的结构和训练量,与这些同样不依赖对抗样本的对比算法相比,本文提出的UIPD 防御效果是最好的.图像缩放和图像旋转这些简单的预处理操作也能对攻击起到较好的防御效果,这间接说明了造成对抗攻击的非鲁棒性特征的脆弱性,激活效果能够被UIP 所抵消,说明了UIPD 方法的防御可行性.添加高斯随机噪声起到的防御效果微乎其微,这体现了用训练的方法获得UIP 的必要性.此外,小数据集的ASR 和DSR均高于大规模的数据集,这是由于大规模数据集图像所包含的特征信息远多于小数据集中的特征信息.
其次,本文比较表4 和表5 中不同防御方法在不同模型和不同数据集中的Rconf 指标.在任意模型数据集下,UIPD 的Rconf 均高于图像缩放、图像旋转、蒸馏防御、基于GAN 的防御、基于自编码器的防御、高斯噪声和集成防御.置信度变化越大,表示防御后的对抗样本越鲁棒,体现了防御的可靠性.不同防御方法在不同模型数据集下的置信度变化与防御成功率保持高度的一致,这显示了UIPD在防御成功率和防御可靠性上都有很好的表现.由表4 和表5 可知集成防御的防御效果也优于其他防御,但是集成防御需要训练多个模型,训练代价更大,所以相较之下,UIPD 方法是一个更好的防御选择.
3.5 不同防御方法对良性样本识别的影响
本节主要分析UIPD 与其他防御方法对良性样本识别的准确率的影响.具体实验结果如表6 所示,本文统计了不同数据集中的良性样本在不同防御方法下的分类准确率(ACC).
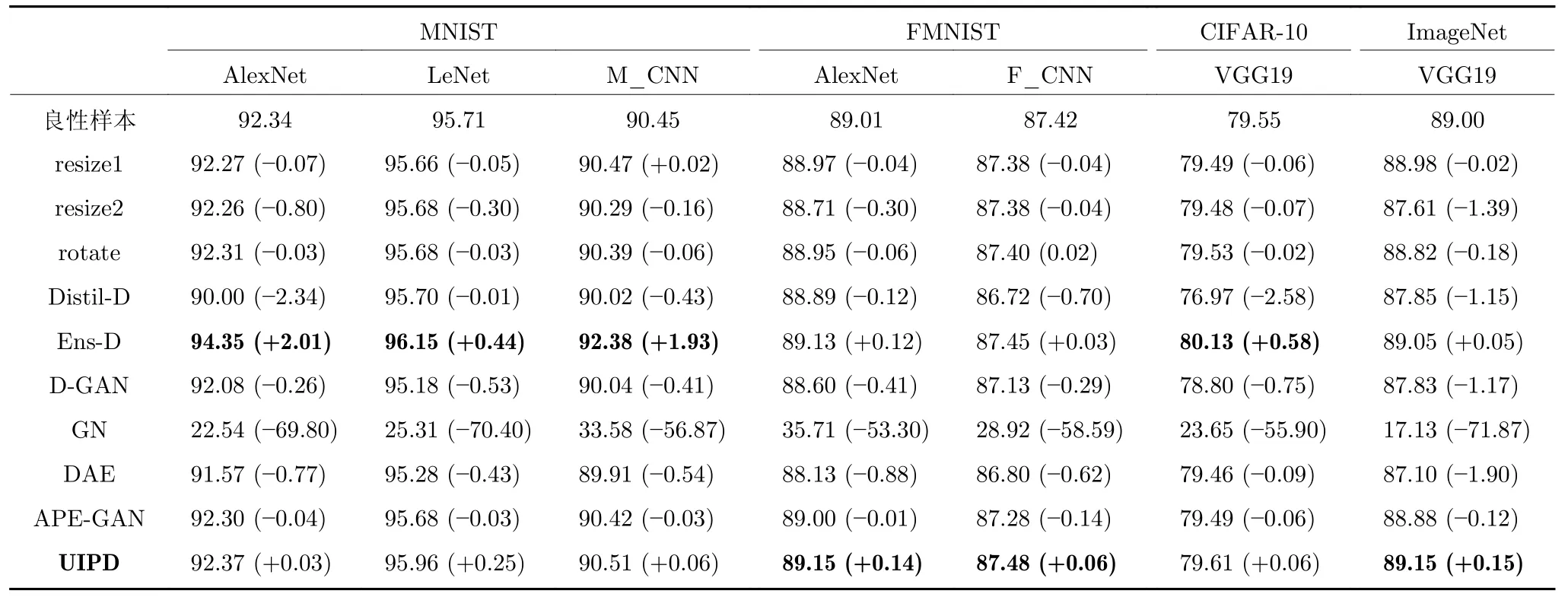
表6 不同防御方法处理后良性样本的识别准确率 (%)Table 6 The accuracy of benign examples after processing by different defense methods (%)
由表6 可知,不同数据集的良性样本在UIPD防御和集成防御后分类准确率有了略微的上升,但在其他防御方法防御后都有了一定程度的下降.为了抵抗对抗攻击,各种高性能的防御方法相继提出,但是防御方法在提供防御有效性的同时,会牺牲一定程度的良性样本分类精度.然而UIPD 防御后不仅没有损失良性样本的分类性能,反而有略微的改善效果,这得益于UIPD 在训练时用良性样本作为训练数据集,进一步的训练提升了原有的分类精度.集成防御虽然同样能够提高分类准确率,但是需要训练多个模型,增大了训练成本.
3.6 参数敏感性和时间复杂度分析
在本节中,主要对UIPD 方法迭代步长的敏感性和时间复杂度进行分析.
图5展示了迭代步长敏感性实验结果,横坐标表示训练UIPD 的迭代步长,纵坐标表示UIPD 的防御成功率.实验使用MNIST 数据集,目标模型是AlexNet.本文选择BIM、PGD、C&W、L-BFGS 和DeepFool 五种方法进行敏感性实验.从实验的结果可以看出,当生成UIP 的迭代步长变化时,UIPD 对于各攻击方法的防御成功率变化幅度都在0.3%以内.实验结果表明,UIPD 是一种稳定的迭代训练方法,当训练UIPD 的迭代步长产生变化,并不会影响最后UIPD 的防御效果.所以,UIPD是一种稳健的防御方法,具有一定的鲁棒性.
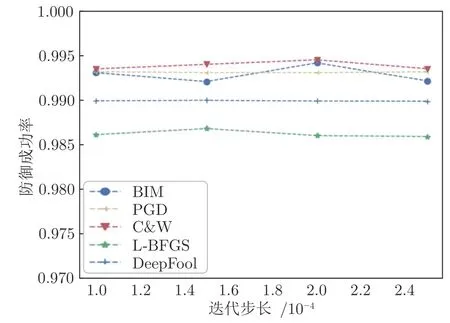
图5 参数敏感性实验结果图Fig.5 The results of Parameter sensitivity experiment
图6展示了不同防御方法实施1 000 次防御的测试阶段时间消耗对比,数据集是MNIST,采用的模型结构是LeNet.由图6 可知,UIPD 所消耗的时间少于或十分接近其他的防御方法,可知UIPD 属于时间复杂度低、防御速度快的一种对抗防御方法.
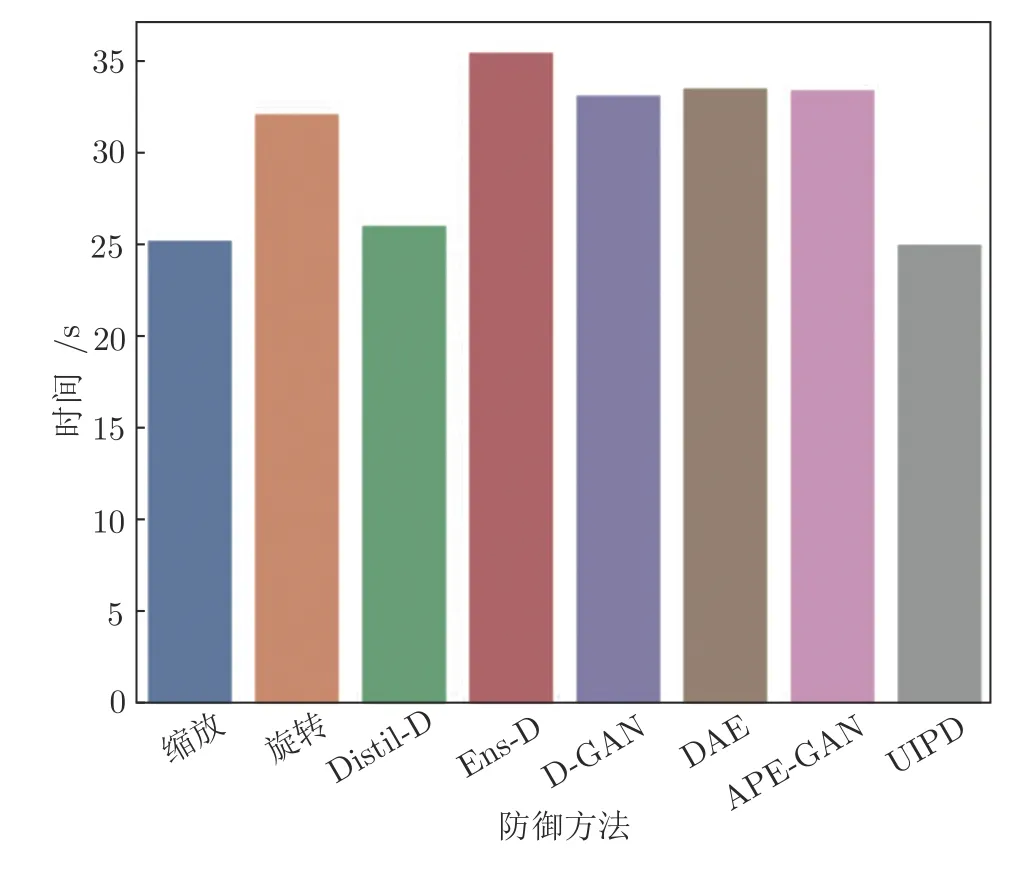
图6 不同防御方法实施1 000 次防御的时间消耗Fig.6 The time cost in 1 000 defenses of different defense methods
3.7 对抗补丁攻击的防御分析
在本节中,主要对UIPD 方法在基于对抗补丁的攻击下的防御进行分析.
图7是针对基于补丁的攻击的防御结果,攻击方法是Adversarial-Patch (AP)[26]攻击,在AP 攻击后,样本识别准确率大幅度下降,可见基于补丁的对抗攻击是一种强大的攻击方法.UIPD 方法对于基于补丁的攻击有着一定的防御效果,但是相比于基于扰动的防御效果而言,性能略差.这是由于基于扰动的对抗攻击生成的扰动是肉眼不可见的,而基于补丁的攻击添加的扰动是肉眼可见的局部大范围补丁,两者在扰动的量级上是存在明显差异的.
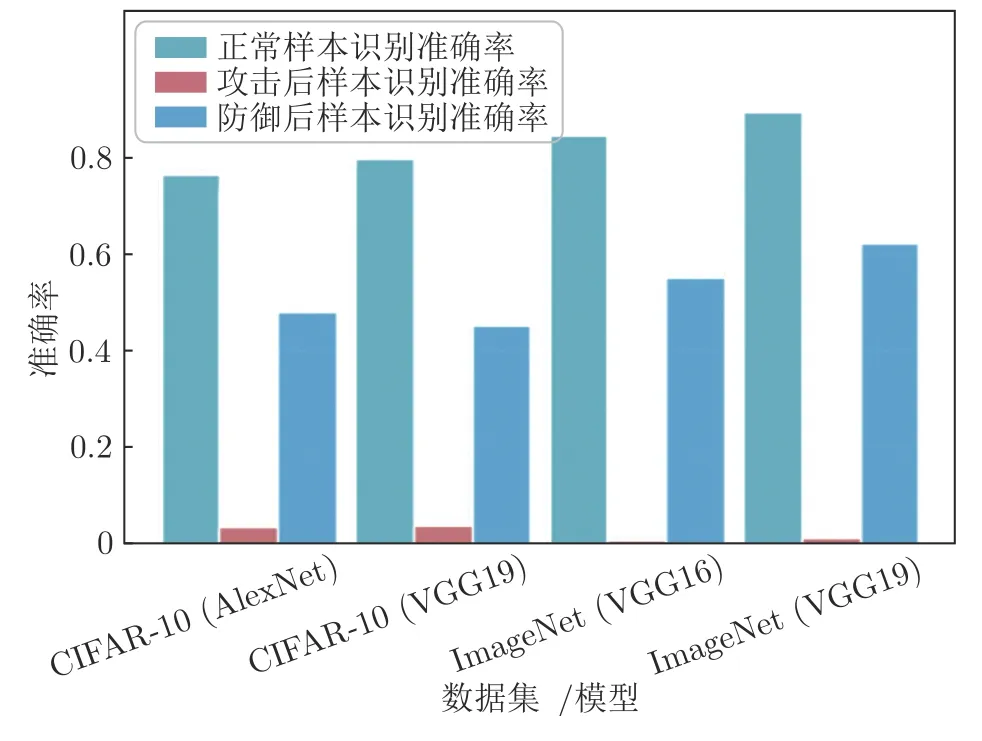
图7 UIPD 对AP 攻击的防御实验结果Fig.7 The results of UIPD against AP attacks
4 总结与展望
本文提出了一种基于通用逆扰动的对抗样本防御方法,对数据样本、攻击方法都具有通用性.在训练生成UIP 的过程中,只需要使用良性样本,不需要任何关于对抗样本的先验知识,即不依赖于对抗样本;UIP 会强化样本的类相关特征,因此不会影响良性样本的识别,甚至能够在一定范围内提升良性样本识别精度;UIP 的生成涉及到迭代步长的设置,实验发现在一定范围内,不同的迭代步长对UIP 的防御效果几乎没有影响,说明参数敏感性低;在测试过程中,只需要单个UIP 叠加在任意待测试的样本上,就能实现防御,只需增加一个矩阵的“+”运算操作,大大加快了防御速度.因此,UIPD 方法防御对抗攻击是可行且高效的.
此外,研究中也发现UIPD 方法存在针对基于对抗补丁的攻击防御效果较差的问题,这是由于基于对抗补丁的攻击生成的是局部大范围的扰动,UIP 无法完全抵消由对抗补丁带来的扰动干扰,如何提升UIP 对基于补丁的对抗攻击的防御效果,是需要在后续工作中继续研究的.同时,研究中还发现UIPD 方法虽然在数据样本上有较好的通用性,但在模型间通用性不佳,这是算法采用迭代优化造成的,使得对模型具有较好的鲁棒性,但是模型间泛化能力较差.因此,在未来的研究中,将继续研究基于生成式对抗网络的通用逆扰动生成方法,改善在模型间的通用性与泛化能力.
附录A UIPD 不同数据样本的通用性举例和可视化
UIPD 方法在不同数据集上针对不同数据样本的通用性比较参见表A1~A3.在不同数据集上,不同模型的UIP 可视化图见图A1.
图A1 不同数据集和模型的UIP 可视化图Fig.A1 The UIP visualization of different datasets and models
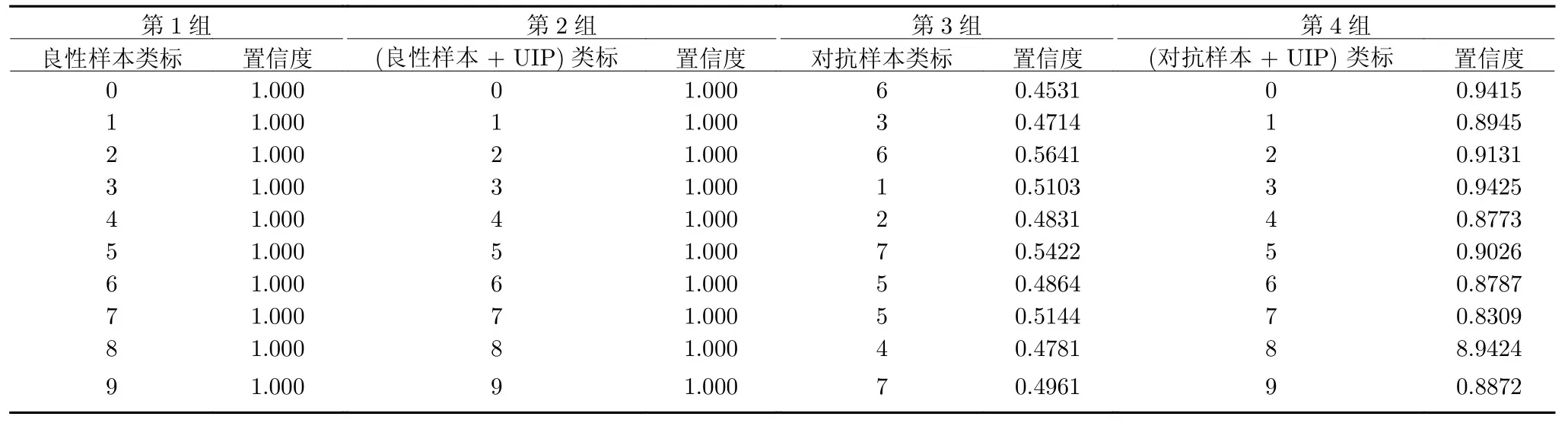
表A1 UIPD 针对不同数据样本的通用性(FMNIST,F_CNN)Table A1 The universality of UIPD for different examples (FMNIST,F_CNN)
猜你喜欢
数学物理学报(2022年4期)2022-08-22
中老年保健(2022年6期)2022-08-19
内蒙古林业(2021年6期)2021-06-26
中学生数理化·高一版(2021年2期)2021-03-19
数学物理学报(2019年4期)2019-10-10
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
贵州师范学院学报(2016年3期)2016-12-01
中国卫生(2016年9期)2016-11-12
中国老区建设(2016年1期)2016-02-28