基于单试次脑电解码的类自举法谎言预测研究
2023-10-30 10:13白帅帅代璐瑶何晖光
自动化学报 2023年10期
白帅帅 陈 超,2 魏 玮 代璐瑶 刘 烨 邱 爽,6 何晖光,6
说谎,是人类特有的一种心理现象,是指说话人主观刻意扭曲或隐瞒某些事实真相的行为.合理高效且准确的谎言检测技术对于维护国防安全、社会稳定、司法公正等方面具有重大的现实意义[1].目前,利用多导生理仪采集心电、血压、皮电等生理信号进行测谎的研究取得了长足的进步,但仍存在结果容易受到外界环境干扰,无法摆脱反测谎策略[2]的问题,致使基于多导生理仪测谎的性能不稳定.
近年来,利用脑电(Electroencephalogram,EEG)信号的事件相关电位(Event-related potential,ERP)测谎技术获得了关注和研究.脑电是脑神经活动产生的电信号,反映了大脑的认知活动,并具有时间分辨率高、便于采集等优势.与外周生理信号相比,基于脑电的测谎研究更有望从神经机制的层面揭示谎言的诱发过程[3].P300 电位[4]是目前ERP 测谎技术研究中较为广泛使用的一种ERP成分,体现在波形上是一个在刺激产生后300 ms左右脑电幅值正向的偏移,其波幅反映了工作记忆中背景更新的程度[5].P300 电位测谎技术基于上述背景更新理论,犯罪者相对于无辜者而言,往往掌握对案件更多的关键信息,对于犯罪相关信息有更深刻的认知加工.因此,当案件相关信息作为探针刺激呈现时,相比无关刺激会诱发犯罪者更显著的P300 电位,而对于无辜者则不会.
事件相关电位测谎技术的研究主要包含测谎范式和脑电解码方法两个方面.其中,测谎范式的研究,一方面是为了提高谎言检测的准确性,另一方面是为了摆脱反测谎策略的影响.在测谎研究中广泛使用的隐藏信息测试(Concealed information test,CIT)基于背景更新理论,通过设置与犯罪情节相关或无关的多项选择问题来判断被试是否诱发了定向反应,从而进行谎言检测,但CIT 范式仍然无法避免因被试通过对无关刺激与特定任务相关的反测谎策略造成的阳性率降低.Rosenfeld 等[6]提出了一种复合反应范式(Complex trial protocol,CTP),将单个刺激分成简单反应与辨别反应.其中,简单反应可以使被试诱发显著的P300 电位;辨别反应是为了确定被试的认知注意保持在实验任务之上,从而摆脱反测谎策略的影响,是近年来在测谎应用中研究更为广泛的范式.2020 年,Chang 等[7]在CIT 范式上加以改进,开发了一种基于视听刺激的ERP 谎言检测范式,将被试姓名编辑为音频文件作为音频刺激,与作为图片刺激的被试自传体信息共同呈现,但是无法保证听觉刺激不被其他非探针被试所知悉,导致其他非探针被试同样会诱发显著P300 成分.2022 年,Wang 等[8]基于快速序列视觉呈现(Rapid serial visual presentation,RSVP)范式的隐藏信息测试方法,提出了一种RCIT (RSVP-based concealed information test)测谎范式.在此实验范式框架下,高速出现的图像刺激使得被试无暇分配更多认知资源施加反测谎策略,但同时作者也在原文中指出,这种范式依然受制于探针刺激不易选取的问题.
在事件相关电位测谎研究的脑电解码中,传统方法是对多个试次脑电叠加得到的ERP 成分的波幅、波面积和潜伏期等指标进行峰值检测、靴值分析等统计学分析.之后,基于机器学习与神经网络的方法在谎言检测中得到了研究和进步.2019 年,彭丝雨等[9]将互信息分析方法应用至脑电分析领域,采用CIT 测谎范式,通过量化构建说谎与诚实人群具有显著性差异的电极对的互信息作为特征分类依据,构建出大脑功能网络.2020 年,Dodia 等[10]提出了一种基于极限学习机(Extreme learning machine,ELM)的ERP 谎言检测算法,通过傅里叶变换提取脑电特征集,采用ELM 对特征集进行训练分类.上述方法均涉及对脑电特征的手工设计,近年来,一些端到端的脑电分析方法在测谎应用中得到了研究.同年,Baghel 等[11]利用卷积神经网络在所采集的14 导基于CIT 范式的脑电信号数据集上进行谎言检测,其正确率为84.44%.2021 年,Bablani 等[12]基于CIT 范式,采用Fuzzy 系统,提取EEG 信号的空间特征进行分类,取得了93.54%的平均预测正确率.2022 年,Javaid 等[13]提出一种由EEG 信号引导基于视听信息的多模态谎言检测模型,采用卷积神经网络对视听信息分别在时域与频域提取特征,利用一个双向长短时记忆网络对EEG 信号进行表征,采用权重赋值的后期融合方式将3 种模态的特征信息进行融合,最终得到83.5%的检测正确率.
目前,已有的基于脑电谎言检测的解码技术,在方法层面,传统方法依赖研究人员手工设计特征,存在主观性,无法摆脱因被试个体差异性造成个别被试的特征信息冗余或缺失[14].在数据层面,仅使用一个或少量导联,忽略了脑电在空间上的特性[15].近年来,随着脑-机接口技术的发展,新的端到端单试次脑电解码算法和全脑脑电采集都有了长足的进步,在避免手工设计特征带来缺陷的同时提供了更丰富的脑电信息,为推进测谎技术进一步发展提供了基础.如基于神经网络的脑电解码算法[16-19],可以在不同脑-机接口范式中实现准确的单试次脑电分类,在谎言检测场景下也有相关研究.由于脑电的个体差异性,此类方法一般需要为每个个体训练对应的解码模型.训练过程需要谎言相关信息作为标签用来进行有监督的模型训练,但这一信息在应用中是无法获得的.如记录了犯罪嫌疑人对N条犯罪信息(N类刺激)的脑电响应,但无从知晓其中哪些信息是与嫌疑人有关的(探针刺激),哪些是无关的(无关刺激),导致此类方法的训练和测试模式在实际中难以应用.
基于背景更新[5]相关理论,相较与被试无关的信息而言,与被试有关的信息更能使被试诱发出显著的P300 电位.也就是说,真正的探针刺激与真正的无关刺激所诱发的脑电样本存在显著差异;而真正的无关刺激之间却没有这种差异性.解码模型可以通过脑电样本的显著差异性实现探针刺激与无关刺激的分类.基于此,本文提出了类自举法,从数据分布假设的角度,解决了当前单试次脑电分类方法的训练和测试模式无法应用的问题.
基于上述背景,本研究开展基于CTP 的自我面孔信息识别任务实验,采集了18 名被试的64 导联全脑脑电信号.研究近年提出的端到端P300 脑电解码算法在测谎中的应用,以及训练数据量对不同算法结果的影响.针对当前单试次脑电解码训练和测试模式无法在测谎中实际应用的问题,提出了一种类自举法,基于不同的单试次脑电解码算法,可以实现在少量数据情况下的准确谎言预测.
1 基于自我面孔信息的CTP 实验
本实验招募共计18 名被试,其中男性8 名,女性10 名,平均年龄为23.39±2.5 岁,且均在18~29岁之间.每名被试在实验开始前均签署知情同意书.
1.1 实验范式
自我面孔识别任务采用复合反应范式,探针刺激是由被试提供的本人证件照,无关刺激设置为4张由软件合成的现实世界并不存在的人脸图片(https://thispersondoesnotexist.com),以避免被试对无关刺激的知晓.探针刺激和无关刺激比例为1 :4.实验任务共10 组,每组任务包含60 试次,每个试次包含一个图片刺激(人脸)和一个数字刺激;每张人脸图像随机呈现12 次.
单个试次流程如图1 所示(图中人脸图片为软件合成),每个试次包含一次简单反应和一次辨别反应.每次反应呈现时间均为300 ms,需要被试在接下来的空屏时间内进行特定行为学响应.具体实验流程为:图片刺激呈现300 ms,紧接着呈现1 300~1 650 ms 随机时长的空屏.被试需要在空屏时间内按下按键“A”表示自己看到了人脸图片.而后呈现数字刺激300 ms,紧接着呈现1 300~1 650 ms 随机时长的空屏,若数字为“11 111”,被试需要在空屏时间内按下方向键“←”;若为其他数字,按下方向键“→”.之后进入下一个试次呈现刺激图片,依次循环.其中随机时长的刺激间隔可以避免被试对即将出现的刺激产生固定预期.为了强制被试关注图片刺激,每组任务中,每20~30 试次会对被试进行随机测试,要求被试识别上个试次的图片刺激.每个试次时长约3.5 s,每组任务时长约4 min,组间强制被试休息超过30 s,10 组任务时长共计约45 min.

图1 单试次实验流程图Fig.1 Flow chart of a single-trial experiment
对于每名被试,正式实验开始之前需要记录被试的静息脑电,包括闭眼静息脑电和睁眼静息脑电.完成静息后,给予被试标准化任务指导语,并利用一些日常用品图像让被试进行按键练习.之后实验正式开始.
1.2 脑电采集与预处理
本实验的脑电信号采集系统使用Neuroscan 公司生产的64 导脑电仪.脑电电极按照10/20 系统排布,采用左侧乳突M1 为参考电极,前额GND 电极为地电极,电极与头皮之间的阻抗均降至5 kΩ以下,并通过SCAN 软件同步记录脑电数据,由放大器放大,采样频率为1 000 Hz.在正式实验开始后,被试均被要求不能频繁眨眼,头部保持静止,身体尽量保持不动,且实验过程中保证实验环境静音.
对于采集的脑电数据,按照实验分组使用EEGLAB 工具箱[20]进行预处理.首先进行通带为0.5~15 Hz 的带通滤波,采用3 阶巴特沃斯线性相位滤波器实现.接着将数据降采样为250 Hz.最后进行数据分段,选择每试次中图像刺激诱发的脑电,从图像刺激发生时刻开始,到之后的1 000 ms 进行数据分割,获得一个单试次脑电样本.由于基于神经网络的脑电解码方法对于输入的归一化需求,对每个单试次脑电样本按照导联进行归一化(零均值、单位方差).对于每名被试者,可以获得60 × 10 (试次 × 组)个单试次脑电样本,每个脑电样本大小为63 × 250 (导联 × 时间).
2 类自举策略与P300 脑电分类方法
2.1 类自举策略
在基于自我面孔信息的CTP 实验中,对数据进行预处理后,每名被试有脑电数据,其中,xi∈R63×250为每张图片刺激诱发的单试次脑电样本,ypici∈{0,1,···,4}为诱发脑电的图像标签.探针预测的基本任务是对于每名被试,利用D预测探针刺激的标签Y∈{0,1,···,4}.对于单试次脑电任务而言,需要对每个脑电样本xi,预测对应的脑电标签,0 表示xi为无关刺激所诱发的脑电,1 表示xi为探针刺激所诱发的脑电.单试次脑电分析模型的训练中,需要每个脑电样本xi和对应的.但在实际测谎中,一方面,难以保证图像探针标签的正确选取或者泄露[8],从而也无法获得对应以训练脑电分类模型;另一方面,脑电信号信噪比低,单试分类的结果往往不稳定[21](如同一刺激,在不同试次呈现所诱发的单试次脑电被分为不同类),且探针预测任务需要正确判断某类刺激是否为探针刺激而往往并不关注单试分类的结果.针对上述问题,本研究提出一种基于单试次脑电分类的类自举算法,旨在实现一种在测谎应用场景下实际可用的脑电解码方法.
在本文进行的CTP 实验任务中,呈现给被试的刺激包括探针刺激与无关刺激.探针刺激为被试的自我面孔信息,无关刺激为现实世界并不存在的面孔,对于被试而言是陌生且无意义的.根据背景更新[5]理论,相较于无关刺激,探针刺激会诱发更为显著的P300.从数据分布的角度,在类别空间中,探针刺激诱发的不同脑电样本属于同一分布,无关刺激诱发的不同脑电样本属于同一分布,而两者之间数据分布存在差异性.如图2 所示,在此假设前提下,若将自我面孔信息作为探针刺激标签,构造脑电样本标签训练分类算法时,算法可以根据各类数据分布实现有效的模型训练和分类(图2(a));若将陌生人脸图像作为探针刺激的标签,算法无法根据同分布数据实现有效训练,模型不具备分类能力(图2(b)).基于此数据分布假设,类自举法分别将不同类的刺激视为探针刺激训练模型和测试,依据分类性能对探针刺激进行预测.
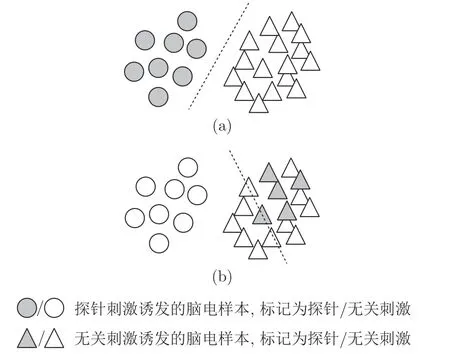
图2 类自举法的分布假设示意图Fig.2 Schematic diagram of distribution hypothesis of the class bootstrap method
类自举法对被试进行探针刺激预测时,输入数据D,输出预测的探针刺激对应的标签Y.算法的主要流程是将5 种类别刺激依次视为探针刺激,分别构建对应的脑电样本标签,划分训练集和验证集;在训练集上训练单试次脑电分类器,并在验证集上进行测试,获得分类均衡精度;综合5 种刺激分别作为探针刺激时验证集的分类均衡精度,最高精度对应的图像刺激为探针刺激,并将其输出.
对应本文的实验场景,类自举法实现的伪代码如算法1 所示.
输入为单试次脑电分类模型f(·),脑电数据X=对应图像标签,其中,∈{0,1,2,3,4};输出为探针刺激.
算法1.类自举法
2.2 脑电P300 分类算法
在应用中,每名被试者能获取的脑电数据有限,导致训练数据十分稀有.基于此,在单试次脑电样本分类算法的选择上,本文选择了几种在小训练数据量上有较好性能表现的端到端脑电分类算法,包括传统机器学习方法(HDCA[22]、MDRM[23])及神经网络方法(EEGNet[24]、OCLNN[25]和PLNet[26]),上述分类算法模型结构简单,训练参数量小,鲁棒性好.此外,采用常用的传统P300 脑电分类算法作为对比方法.
1)分层判别成分分析(Hierarchical discriminant component analysis,HDCA)[22]:是一种在空间、时间维度依次提取脑电特征并进行分类的方法,由Gerson 等[22]于2006 年提出,应用在基于快速序列视觉呈现的目标检索任务的P300 分类中.对于单试次脑电样本(导联 × 时间),在时间维度切分k个时间窗,对于每时间窗的数据分别训练一个线性判别分类器(Linear discriminant analysis,LDA),计算在导联(空间)的投影,将投影后的各时间窗拼接,训练一个时间维度的LDA 分类器,并进行分类.HDCA 算法具有简单、计算量小的优势.
2)最小黎曼均值方法(Minimum distance to riemannian mean,MDRM)[23]:是一种基于黎曼几何的P300 分类方法,由Barachant 等[23]于2012 年提出,应用于P300 脑电二分类问题.该方法在训练中构建包含P300 的模板,在导联维度拼接模板和单试次脑电,通过计算样本协方差矩阵将脑电转换到黎曼流形空间,在流形空间分布计算类别均值,按照最近邻的思想进行分类.MDRM 方法对P300不同的潜伏期和训练数据量具有较好的鲁棒性.
3)EEGNet[24]:是一种基于卷积神经网络的脑电分类方法,由Lawhern 等[24]于2018 年提出,可应用在脑电P300 分类中.EEGNet 中包含多个卷积层,分别从导联、时间维度提取特征,再利用深度卷积融合特征信息及全连接层进行分类.EEGNet 具有网络结构紧凑、应用范式多样的优势.
4)OCLNN (One convolutional lager nerual network)[25]:是一种单层卷积神经网络的脑电分类方法,由Shan 等[25]于2018 年提出,应用于基于P300 电位的脑-机接口拼写器中.网络仅包含一个卷积层,同时从时间和导联维度提取特征,并使用全连接层进行分类.OCLNN 具有网络结构简单、参数量小、易于训练的优势.
5)PLNet[26]:是一种基于卷积神经网络的脑电分类方法,由Zang 等[26]于2021 年提出,应用于基于快速序列视觉呈现的目标检索任务的P300 分类中.类似于EEGNet,网络不同的卷积层分别对脑电的时间空间维度提取特征,通过维度转换的方式实现不同维度特征的融合提取,全连接层进行分类.PLNet 是目前提出的最新的脑电P300 分类算法,并实现了优于EEGNet 的性能.
2.3 实验设计
2.3.1 实验方法
为了研究近年提出的P300 脑电分类算法在谎言预测任务中的有效性以及类自举法的性能,设计了两种实验:单试次脑电分类和基于脑电的探针预测任务.此外,基于自我面孔信息的CTP 实验中每名被试包含10 组数据,在脑电分析实验中也对使用数据量对方法性能的影响进行了分析.
单试次脑电分类实验使用单试次脑电数据xi及对应的探针标签训练脑电分类算法,对测试样本进行二分类.在单试次脑电分类实验中,研究不同训练数据量及不同脑电分析方法的分类性能,结果主要用于对不同算法在测谎应用中的有效性分析.具体实现为,对于每一名被试,选择其前P组(P∈{1,2,3,4,5})作为训练集训练单试次脑电分类模型,采用余下的10-P组数据作为测试集,测试模型分类性能.实验对比了不同端到端单试次脑电分类方法:传统机器学习方法HDCA、MDRM与基于神经网络的方法OCLNN、EEGNet 和PLNet.此外,选择了不同的传统脑电分类算法进行对比,分别使用时域特征、空域特征和小波域特征训练分类器(SVM (Support vector machine)或LDA)进行分类,相关特征在基于脑电的测谎中已有研究[12,27-28].在基于神经网络算法的单试次脑电分类实验中,采用了10 折交叉验证的方式对训练集进一步划分训练集和验证集,最后分类结果为多折平均结果.
在基于脑电的探针预测实验中,使用探针预测算法对每名被试进行探针(Y)预测.研究不同数据量、不同方法对探针预测准确性的影响.具体实现为,分别使用每名被试脑电数据的前P组(P∈{2,3,4,5,6})进行探针预测任务.对于类自举法而言,在算法执行中,使用前[P/2]组数据作为类自举法训练集,余下的P-[P/2]组数据作为类自举法验证集,每名被试进行一次探针预测.其中,基于神经网络的方法进行了10 折交叉验证.在基于脑电的探针预测实验中,采用自举波幅差法(Bootstrapped amplitude difference,BAD)[6]作为对比方法.BAD是一种当前普遍采用的探针检测算法[26],对所有刺激类别,首先取该类刺激的P300 波幅的峰峰值(PP)或基峰值(B-P)平均值;随后随机抽取与该类刺激同等样本量的剩余刺激并重复100 次,逐次平均,获得剩余刺激的P300 波幅的峰峰值(P-P)或基峰值(B-P)池;最后检测该类刺激的P300 波幅值在剩余刺激的P300 波幅值池中的百分位排名,如该类刺激的P300 波幅值在剩余刺激P300 波幅值池中的百分位排名大于95%,则预测该类刺激为探针.
2.3.2 实验参数
表1 列举了单试次脑电解码实验中所采用脑电分类方法的主要参数和代码来源.
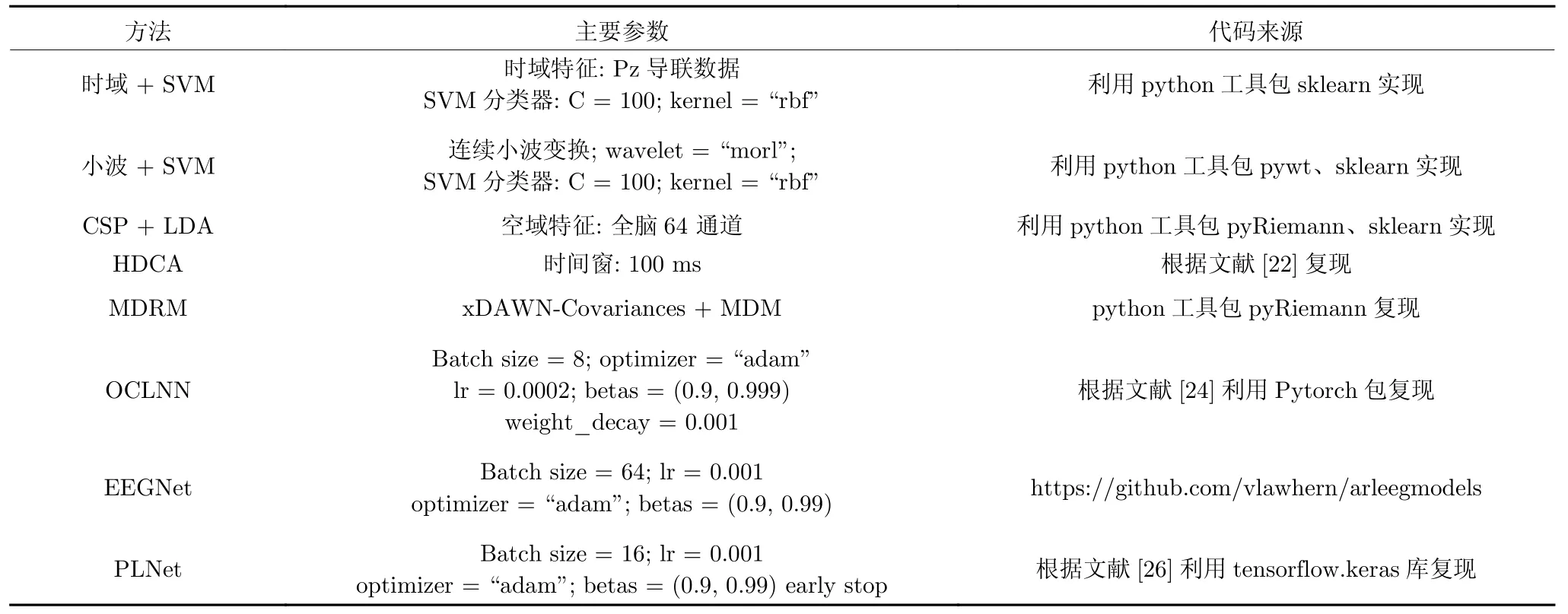
表1 单试次脑电解码实验主要参数Table 1 Main parameters of single-trial EEG decoding experiment
由于探针刺激与无关刺激的比例为1 :4,存在类不均衡问题.因此,对于神经网络方法(OCLNN、EEGNet 和PLNet),按类别比例对损失函数加权,正样本权重为 1,负样本权重为 0.25.实验均在一台拥有12 GB 内存和NVIDIA GeForce GTX 1080 Ti GPU 的Linux 服务器上进行.
2.3.3 实验度量指标
为了对比与分析方法性能,本文采用两种度量指标:均衡精度(Balanced accuracy,BA)及探针预测正确率.均衡精度用于衡量单试次脑电分类任务的性能,单试次脑电分类为脑电的二分类问题,探针刺激诱发的脑电为正类,无关刺激诱发的脑电为负类,正负样本比例为1 :4.由于类别之间存在着数量上的不均衡性,本研究采用均衡精度作为评价模型性能的指标.均衡精度表示了正样本和负样本分类正确率的平均值,是类别不均衡问题中更能反映模型正负样本均衡正确率的指标.计算式为
其中,TPR为正样本的分类正确率,TNR为负样本的分类正确率.TP代表被分为正类的正样本数;TN代表被分为负类的负样本数;FN代表被分为负类的正样本数;FP代表被分为正类的负样本数.
探针预测实验中,对每一名被试进行一次探针预测,即判定图像刺激中的某一个为探针刺激,若判定的图像刺激确为探针刺激则预测正确.探针预测正确率为正确预测探针被试数占所有被试的百分比.
3 实验结果与分析
3.1 事件相关电位分析
图3 展示了本文所采集的18 名被试的Pz 导联的平均事件相关电位波形.

图3 事件相关电位波形图Fig.3 Event-related potential waveform
图3 中实线为探针刺激所诱发的事件相关电位波形,虚线为非目标刺激所诱发的事件相关电位波形,对应阴影区域为两者标准差.从图3 中可以看出,探针刺激和无关刺激均可以诱发包含P300 成分的ERP.探针刺激所诱发的P300 电位峰值潜伏期为556 ms,无关刺激所诱发的P300 电位峰值潜伏期为604 ms,探针刺激所诱发的P300 电位幅值大于无关刺激.图3 结果表明了所设计实验和采集数据的有效性.
3.2 单试次脑电分类结果
表2(*表示在每个训练数据量下,对比方法与最优性能方法均衡精度之间具有统计显著性差异性,*:p<0.05;**:p<0.01;***:p<0.001,p表示显著性概率值)展示了不同方法在不同训练数据量下的单试次脑电样本分类均衡精度.双因素重复测量方差分析的结果表明,不同训练数据量和不同方法两种因素对于单试次脑电解码均具有显著性影响(不同方法:F(4,68)=33.179,p<0.01;不同数据量:F(1.734,29.470)=77.438,p<0.01,F表示方差分析的F 统计量),且因素间存在显著的交互作用(F(5.967,101.447)=4.902,p<0.01).在1 组训练数据量下,EEGNet 单试分类性能显著优于传统机器学习方法(所有p<0.01),显著优于OCLNN(p<0.001),性能高于PLNet (无统计显著).在2~5 组训练数据量下,PLNet 单试分类性能显著优于其他对比方法(均有p<0.05).
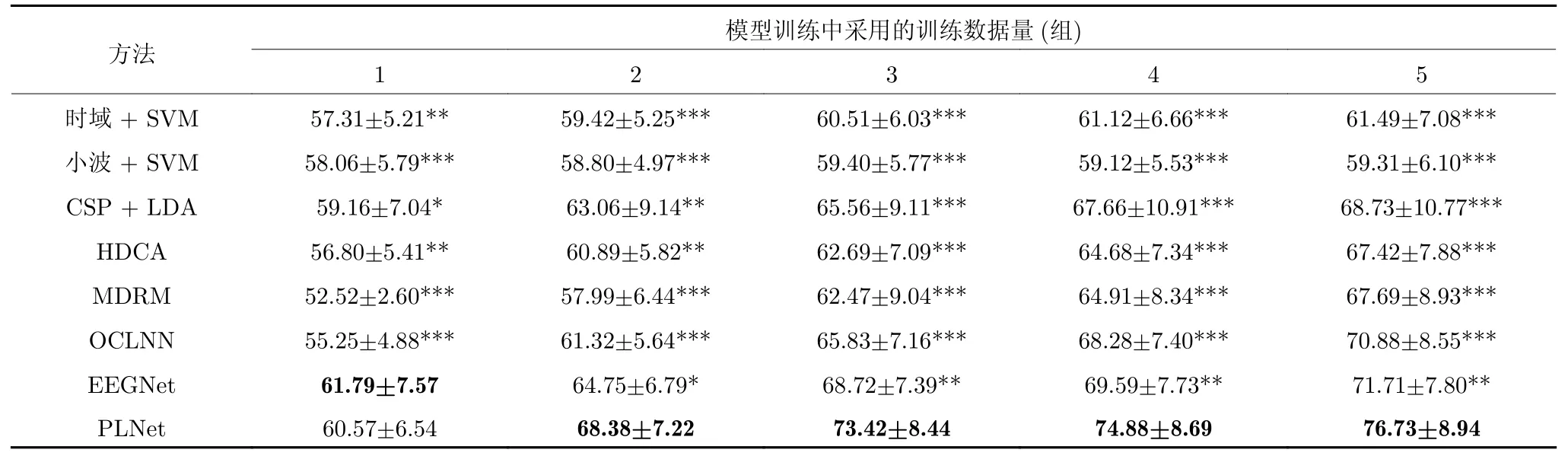
表2 不同方法在不同训练数据量下的分类均衡精度(均值±标准差)(%)Table 2 Balanced accuracy of different methods under different training data (mean±standard deviation)(%)
从表2 的结果可见,对于不同的单试次脑电分类方法,均呈现了分类精度随着训练数据量增加而增加的趋势.在一组训练数据量下,EEGNet 取得了最佳的单试次脑电分类性能,随着训练数据量的提升,在2~5 组训练数据量下,PLNet 取得了优于其他算法的显著性能;传统脑电解码方法在小训练数据量(1 组)下,单试分类性能要优于一般的端到端方法机器学习算法(HDCA、MDRM),但是随着训练数据量的增加,领先优势逐渐消失,在3 组训练数据量下,基于传统机器学习的端到端方法的单试分类性能优于时域及小波域两种传统分类方法.随着训练数据量的提升,基于神经网络的方法均显著优于其他脑电分类方法.此外,随着训练数据量的增加,在相同训练数据量提升下,与传统方法相比,基于神经网络的方法的分类精度提升更大.
3.3 探针预测结果
基于脑电的探针预测结果如表3 所示.从表3的结果可见,在使用不同数量的脑电数据情况下,基于PLNet 的类自举法探针预测结果准确率最高,并高于对比方法.在仅使用2 组数据情况下,基于PLNet/OCLNN 的类自举法探针预测可以实现88.89%的预测准确率;随着使用的脑电数据量的增加,探针预测的准确性随之提升,在使用3~6 组脑电数据情况下,基于PLNet 和EEGNet 的类自举法探针预测性能相同且为对比方法中最优,在6 组数据量下,可实现100.00%正确探针预测.对比方法BAD (P-P)在使用3 组数据的情况下可实现与基于神经网络的类自举探针预测方法相同的性能.
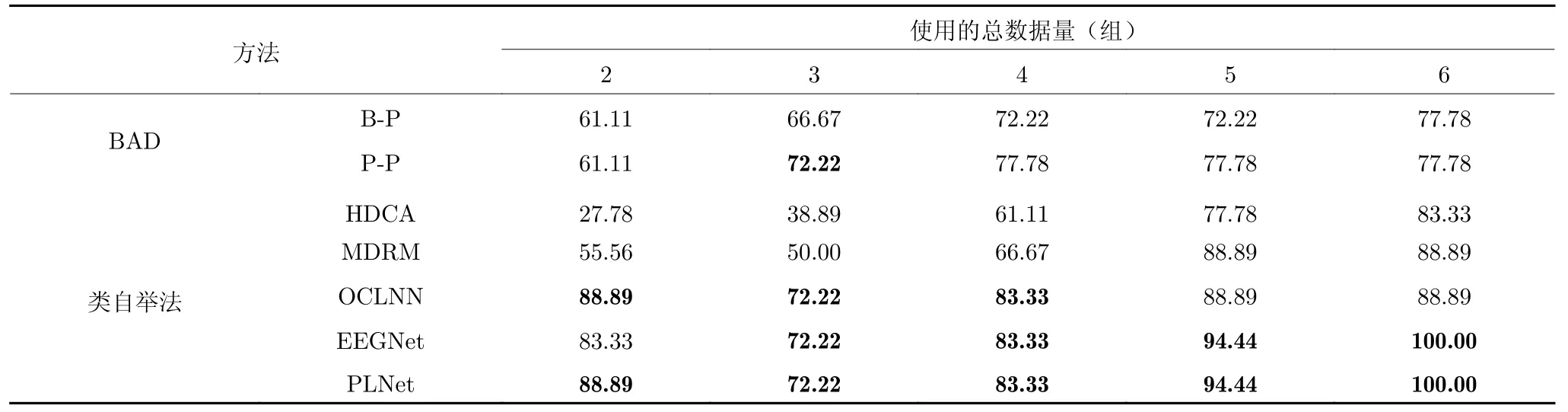
表3 不同方法在不同数据量下的探针预测正确率 (%)Table 3 Probe prediction accuracy of different methods under different data volume (%)
随着使用数据量的增加,BAD 方法的探针预测性能呈现了增加(2~4 组数据)而后到达平台期(4~6 组数据)的变化趋势.类自举法的探针预测性能整体呈现了随使用数据量增加而增长的趋势.基于神经网络的类自举法在仅需要更少的数据情况下(OCLNN、EEGNet 和PLNet 在2 组数据下)便可以实现传统方法在更多训练数据情况下(如BAD、HDCA 和MDRM 在5 组数据下)才得以实现的探针预测性能.此外,统计类自举法的算法耗时的结果表明,在采用PLNet 进行类自举探针预测的情况下,使用不同数据量的情况下训练时间十分相近,平均时长为17.5±0.7 min.采用BAD 方法进行探针预测的算法耗时短,平均时长为1.46±1.39 s.虽然BAD 算法的计算复杂度低,不需要额外训练模型的时间,但其探针预测精度低于类自举法.类自举法的实验结果表明,使用越多的任务数据,探针预测性能越高,也会导致实际中任务实施时长的增加.类自举法在实际应用中,可以按照实际的时间与任务精度需求实施.综合单试分类、探针预测准确率的结果看,数据驱动的端到端脑电分类算法受到训练数据量的影响较大,模型准确率随着训练数据量的增加而增加.由于训练样本少,单试次脑电分类性能较差;而本文所提出的类自举法结合神经网络方法可以实现准确的探针预测.
3.4 可视化分析
为验证本文所提出的类自举法的假设及方法的有效性,本研究对模型输出特征进行了可视化分析,图4 展示了其中一名被试在类自举法使用5 组数据情况下的可视化结果.使用前3 组脑电数据,分别将5 类图像刺激视为探针刺激构造对应单试次脑电的二元标签(探针刺激:1,无关刺激:0),训练PLNet.使用后2 组数据作为输入,将PLNet 模型中卷积网络所提出的特征,使用tSNE 方法降至二维,并绘制散点图.

图4 类自举法中不同脑电标签训练解码模型的特征可视化Fig.4 Feature visualization of decoding models trained with different EEG labels in class bootstrap method
如图4(a)所示,真正的探针刺激作为正样本构建脑电标签情况下,所训练模型的特征空间中,探针刺激所诱发的脑电样本分布集中,且与无关刺激脑电样本具有一定的可分性.而图4(b)~4(e)的结果表明,在无关刺激被视为探针刺激构造单试次脑电标签进行训练后,模型无法学习到有效的分类模式,不同图像刺激所诱发脑电样本的分布十分混乱,探针刺激与无关刺激之间不具有可分性.上述结果也表明了类自举法的数据分布假设的正确性和方法的有效性.
4 总结与展望
本文面向谎言预测的脑电信号解码研究,设计了基于CTP 的自我面孔信息任务,开展实验采集了18 名被试者的任务脑电数据,研究分析了近年来广泛应用于脑-机接口领域的P300 脑电分类方法在测谎场景下的应用.针对当前单试次脑电分类方法的训练与测试模式无法应用等问题,基于数据分布的假设,提出了一种类自举法以实现实际可用的探针预测方法.实验结果表明,端到端的单试次脑电分类算法在测谎应用中具有可行性,且分类性能受到训练数据量的影响;所提出基于单试次脑电分类的类自举法可以实现准确的探针预测,可视化分析的结果也表明了类自举法的前提假设与方法的有效性.
在本研究所开展的基于CTP 实验中,每名被试均有自我面孔信息作为探针刺激,因此,被试中不包含无辜者.虽然本文所进行的探针预测任务不包含对无辜者的甄别,但是提出的类自举法可以通过设置分类性能的阈值来进行无辜者判定,这也是我们后续继续推进的研究内容,并将开展相关实验进行分析和验证.此外,针对知情无辜者的问题,有研究证明[29],早期后部负电位(Early posterior negativity,EPN)会在与自我相关的背景信息中得以显著诱发,可作为区分有罪者与知情无罪者的一种ERP 成分.后续研究拟在P300-CTP 组合测谎模式中加入对EPN 成分的分析,来进一步探究EPN成分的诱发效应与无辜者甄别能力.
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
现代检验医学杂志(2016年3期)2016-11-15
现代电生理学杂志(2016年3期)2016-07-10
现代电生理学杂志(2016年4期)2016-07-10
现代电生理学杂志(2016年1期)2016-07-10
三峡大学学报(自然科学版)(2016年6期)2016-04-16
现代电生理学杂志(2015年1期)2015-07-18