
面向藏文临床病历的医学实体识别研究
2023-10-29 01:32卓玛措桑杰端珠才让加羊毛卓么
计算机仿真 2023年9期
卓玛措,桑杰端珠,才让加,羊毛卓么
(省部共建藏语智能信息处理及应用国家重点实验室,青海 西宁810008)
1 引言
医学实体识别(Medical Entity Recognition,MER)[1]是临床自然语言处理(Clinical Natural Language Processing,CNLP)的基础性任务之一,它为医学方面的信息检索、临床诊断等下游临床自然语言处理任务提供重要的特征信息。早期的实体识别方法更多地依赖人工特征工程以及许多现成的工具包,并且较难实现领域适应。然而近年来,深度学习的发展减少了模型对人工特征工程以及工具包的依赖[2-13]。特别是在实体识别任务方面,有一种网格长短期记忆(Lattice-LSTM)模型在中文命名实体识别任务上取得了较好的效果[14]。由于Lattice-LSTM网络结构能够将显性的字信息和该字隐性的词信息充分融合,因此可以有效避免分词错误向下游任务的传递。
针对藏文通用领域的实体识别研究,已经有一些研究结果[15-17]。但是,面向藏文临床文本的自然语言处理资源稀缺导致相应的工具包十分匮乏,极大地影响了藏文临床自然语言处理的发展进程。特别是面向藏文临床文本的医学实体识别研究还处于起步阶段。
鉴于此,本文旨在开展针对藏文临床病历的医学实体识别研究工作。因此,本文基于Lattice LSTM CRF深度学习模型并结合藏语的音节(一个音节相当于汉语中的一个字)特征构建了适合藏文临床病历实体识别的S-Lattice LSTM(音节网格长短期记忆)模型。藏文词汇是构成藏文句子的基本单元,而藏文音节是构成藏文词汇的基本单位。S-Lattice LSTM网络结构能够将藏文的音节信息和该音节隐性的词信息充分融合,从而有效避免分词错误向下游任务的传递。实验结果表明,本文的方法对藏文临床病历文本的医学实体识别正确率、召回率和F1值分别达到91.89%、93.15%和92.52%,取得了较好的识别性能。
2 模型
在英文领域,Hammerton等人首次采用神经网络进行实体识别的研究,使用了单向LSTM模型。由于LSTM模型良好的序列建模能力,LSTM-CRF模型成为实体识别的基础架构之一,很多方法都是以LSTM-CRF为主体框架,在此之上融入各种相关特征[18]。本文将LSTM-CRF作为主要网络结构并结合藏语的音节特征,在该模型对一系列输入字符(包含藏语的音节)进行编码的同时将所有与词典匹配的词汇网格结构融入模型中。


表1 藏文临床病历医学实体识别的音节序列和标记序列举例
2.1 基于音节的模型
基于音节的实体识别模型输入向量为音节序列。此模型存在一种显著缺陷,即忽略了词序以及词的显性信息。模型如图1所示。
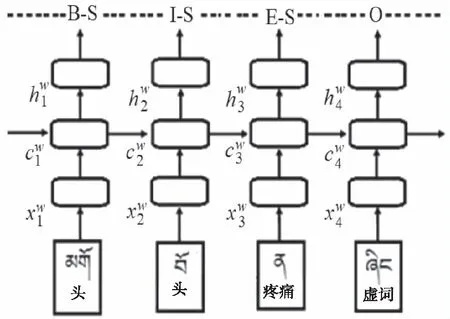
图1 基于音节的模型
2.2 基于词的模型
基于词的模型原理与基于音节的模型类似,区别就在于此模型输入的向量为分词后的词序列。因此,这种模型会导致分词错误的传递,并最终影响实体识别的性能。模型如图2所示。
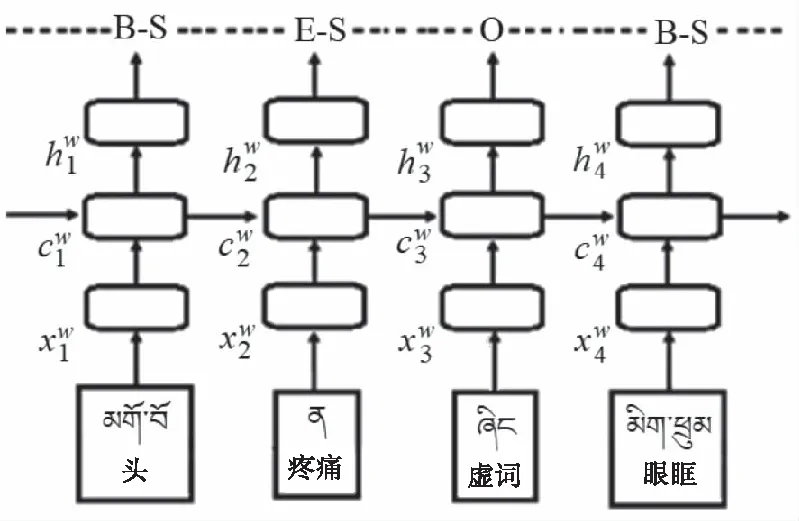
图2 基于词的模型
2.3 S-Lattice LSTM模型
本文采用S-Lattice LSTM模型来处理句子中的藏语词汇词(lexicon word),从而把所有潜在的藏语词信息整合到基于藏文音节的LSTM-CRF基本框架中。本文采用构建的词表对句子进行匹配,从而构建基于词的藏文Lattice网格。因为网格中存在词到音节的指数级数量的路径,因此,对藏文临床病历中的句子从左到右的信息流使用Lattice LSTM模型结构来进行自动控制。门控神经单元将来自不同路径的信息动态的传送到每一个藏文音节。在完成数据的训练后,S-Lattice LSTM模型能够学会自动从信息流中找到有用的词,从而提升医学实体识别性能,整体模型框架如图3所示。与基于藏文音节和基于藏文词的实体识别方法相比,本文的模型利用词汇的显性信息对句子进行分词,而不只是自动关注。因此,减少了分词带来的误差。

图3 S-Lattice LSTM模型
2.4 LSTM层
循环神经网络(RNN)在理论上可以处理任意长度的序列信息,但是在实际应用中,如果序列太长就会出现梯度消失现象,并且也不容易学会长时间依赖的特征。为此,Graves等人对RNN进行了改进,提出了LSTM 模型[19]。LSTM 模块通过输入、输出和遗忘三个模块来控制信息的传输。长短期记忆网络(Long Short-Term Memory,LSTM),是一种特殊的RNN,能够学习长期的规律,它们在各种各样的NLP任务上应用非常广泛。LSTM编码单元如图4所示。
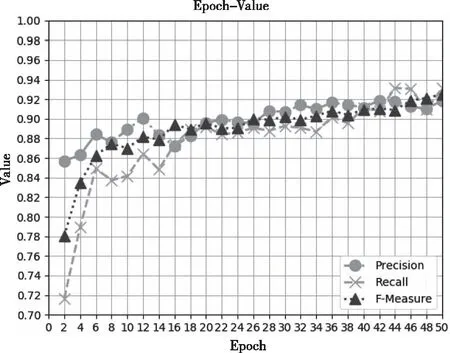
图5 迭代次数和 P、R 和 F1 值的变化趋势
it=σ(Wiht-1+Ui+bi)
(1)
ft=σ(Wfht-1+Ufxt+bf)
(2)
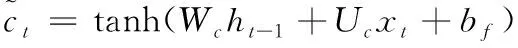
(3)
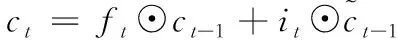
(4)
ot=σ(Woht-1+Uoxt+bo)
(5)
ht=ot⊙tanh(ct)
(6)
其中,σ表示Sigmoid 激活函数,⊙是点积。xt表示t时刻的输入向量,ht表示t时刻的隐藏状态,也表示输出向量,包含前面t时刻的全部有用信息。ct是一个改良模块,掌控信息传入下一个环节;ft是一个复位模块,掌控信息遗失;而隐藏状态的输出是由二者共同决定的。
3 实验及结果分析
3.1 实验数据
3.1.1 音节向量
为了构建藏语音节向量,本文从中国藏族网通网站下载了包含4.53亿个音节的新闻数据,并用GloVe[20]模型进行训练,生成的音节向量维度为50。
3.1.2 实验数据集
由于目前藏文临床病历医学实体识别缺乏公开的标注数据集,因此本文对现有的530份电子病历进行标注构建了一个藏文临床病历医学实体识别数据集。对以上病历数据以病历文档为单位进行任意比例的划分,其中由305份文档构成训练集,由225份文档构成测试集。本数据集中包含症状 (SYMPTOM)、方剂 (PRESCRIPTION)和疾病 (DISEASE)三大类医学类实体,其类别数量分布如表2所示。

表2 藏文临床病历医学实体识别数据集
3.2 标注策略与评价指标
常见的医学实体识别标注方法有OBI 策略,OBIE策略,SOBIE策略。本文采用的是SOBIE标注策略,其中B是实体的首部,I是实体的内部,E是实体的尾部。O表示非实体或实体外部,S表示单音节实体。实体识别包括预测实体的边界和实体的类型,所以待预测的标签一共11种,分别是O,S,B-S,I-S,E-S,B-D,I-D,E-D,B-P,I-P,E-P。当识别实体时,只有在一个实体的边界和类型都预测的完全正确时,才认为该实体被准确识别。
藏文临床病历实体的识别性能评测指数有正确率(P)、召回率(R)和综合指数F1值。具体计算方法如式(7)所示。其中Tp表示模型准确识别的实体个数,Fp表示模型识别到的无关实体个数,Fn表示同类实体但模型没有准确识别的个数。
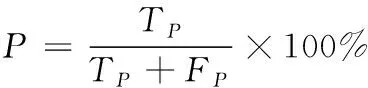
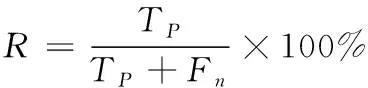
(7)
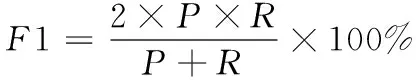
3.3 实验环境与超参设置
本研究中的实验环境为Python 2.7,深度学习框架为Pytorch 0.3.0.post4
神经网络的超参数取值会影响神经网络的性能。本文的神经网络超参设置如表3所示。

表3 神经网络超参取值
3.4 实验设计与结果
为了验证本研究中所使用的模型对藏文临床病历实体识别数据集中的症状、疾病、方剂三大类实体的识别性能,分别设计了以下两组实验。实验的评测指数有正确率(P)、召回率(R)和综合指数F1值。
实验1 不同模型对藏文临床病历实体识别结果比较。表4分别给出了CRF(条件随机场)模型和S-Lattice LSTM模型的识别结果。
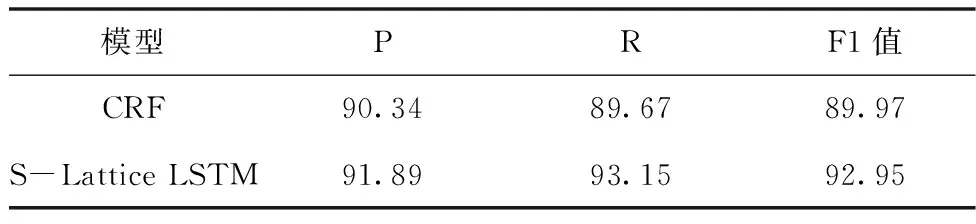
表4 不同模型对藏文临床病历文本实体识别性能对比(%)
实验结果表明,S-Lattice LSTM模型的F1值比CRF模型的F1值提升了2.55%,这说明深度神经网络模型比传统的统计模型在藏文临床病历实体识别任务上表现性能较好。并且证明使用表示学习的神经网络模型可以较大程度的减少模型对人工特征的过度依赖。
实验2 基于词向量的CNN-BiLSTM-CRF模型与S-Lattice LSTM模型对藏文临床病历文本进行实体识别性能对比。S-Lattice LSTM模型可以同时对音节序列信息和它对应的词序信息进行编码,并且提供给模型自动取用。相较于音节粒度(字符级)的编码,后者加入了词信息,丰富了语义表达,可以有效避免分词错误传递问题。表5说明了S-Lattice LSTM模型能有效提升实体识别的性能。
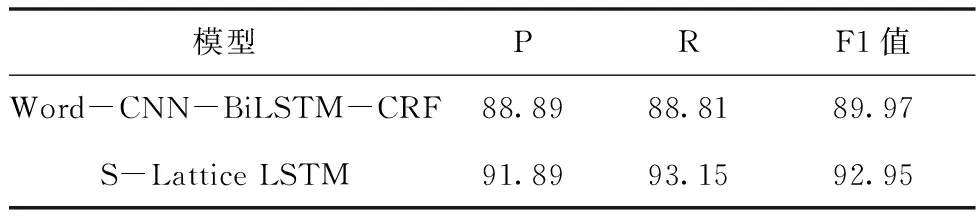
表5 基于词向量的模型与S-Lattice LSTM模型的性能对比(%)
症状、疾病和方剂三类实体的正确率(P)、召回率(R)和综合指数F1值如表6所示。
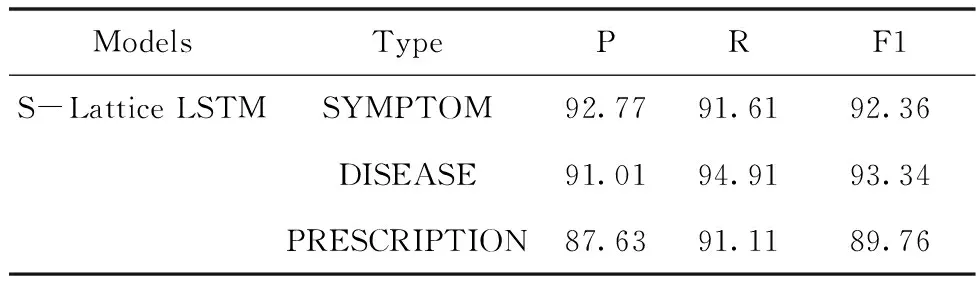
表6 不同类型实体识别结果

3.5 实体识别实例
以某份住院病历中的一个句子为例展示S-Lattice LSTM模型的实体识别效果。具体实例如表7所示。

表7 藏文临床病历文本医学实体识别实例
4 结束语
本文针对藏文临床病历中医学类实体的识别问题,提出了一种适用于藏文临床病历医学实体识别的深度神经网络模型。该结构用网格LSTM来代替传统的LSTM单元,在藏文音节模型的输入端同时利用显性的藏文词汇和词序信息。因此,有效避免了分词错误向下游任务的传递。整体架构的隐藏层是具有长短期记忆功能的LSTM模型,解决了藏文临床病历中部分结构较长的医学实体识别准确率较低的问题;最后的标签推理层使用CRF模块,解决文本序列标签之间的依赖问题。在已构建的藏文临床病历医学实体识别数据集上进行实验,结果证明S-Lattice LSTM模型是有效的。
基于深度学习的藏文临床病历医学实体识别模型S-Lattice LSTM 也可以推广到其它具有类似特点的垂直领域,具有一定的通用性。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
布达拉(2020年3期)2020-04-13
快乐作文(1.2年级)(2019年9期)2019-09-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
西夏学(2019年1期)2019-02-10
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
中国音乐教育(2014年11期)2014-05-18
外语学刊(2011年3期)2011-01-22
