
基于改进MMA-Net的车道线检测算法
2023-10-29 01:46张宇航
计算机仿真 2023年9期
江 漫,张 乾,朱 瑜,张宇航
(贵州民族大学数据科学与信息工程学院,贵州 贵阳 550025)
1 引言
随着智能交通的发展,近年来,智能辅助驾驶技术已成为研究热点,而车道线检测是智能辅助驾驶的一项基本任务。目前基于计算机视觉的车道线检测技术已经广泛应用于自适应巡航控制系统、盲点监控系统、车道偏离预警系统等智能辅助驾驶系统[1]。准确识别车道线的位置能为车辆安全行驶提供重要信息,因此,研究车道线检测具有重要的现实价值。
在实际场景中,受天气环境、光照条件变化、道路复杂性、车道线磨损程度、路面阴影、来往车辆对车道线的遮挡等影响,车道线检测面临着诸多的挑战。此外,由于车道线形状细长,占图像面积较小,也给检测带来了一定的困难。
随着深度学习的发展,近年来,通过对大规模真实数据进行标注和训练,车道线检测取得了重大进展[2-6]。与传统的基于车道线的颜色、边缘等特征信息的方法[7-9]相比,深度学习网络大大提高了车道线检测的性能。
然而,现有的大多数深度学习方法都是对图像级数据进行车道线检测,忽略了视频帧前后的顺序信息。视频中的连续帧可以利用时间连贯性来解决图像模糊、遮挡、车道线磨损等问题,基于此,MMA-Net[10]将车道线检测从图像级扩展到了视频级,采集了一个新的视频车道线检测数据集VIL-100,并提出了一个多层记忆聚合网络(MMA-Net)进行视频实例车道线分割,该方法在VIL-100数据集上的性能优于目前最先进的车道线检测方法,故本文将其作为基础网络,提出改进的MMA-Net算法。
2 相关工作
从如何定义车道检测任务的角度,可以将基于深度学习的车道线检测方法分为四类:①基于分类的方法,其通常结合先验信息来确定车道线位置,如DeepLane[2]通过在网络中加入一些与位置相关的先验知识,克服了图像分类无法直接获得车道线位置的缺点,利用深度神经网络直接估计车道线位置。基于分类的车道线检测方法网络结构较简单,但应用场景有限,且后处理的计算复杂度较高。②基于目标检测的方法,其利用坐标回归检测车道线的边界框位置,如VPGNet[11]使用改进的消失点定位方法,提出了一个端到端的多任务网络,能够在多雨和低照明的恶劣天气条件下识别车道线,但需要进行点采样、聚类和车道线回归等复杂的后处理操作;文献[12]提出了一种基于时空深度学习的车道线检测方法,利用时间和空间约束缩小搜索区域范围,能够准确检测车道线边界,但其数据流和网络结架构复杂,且当初始假设不满足时,预处理不能提供有效的结果。③基于建模的方法,其采用数学模型对车道线进行建模,通过求解模型参数拟合车道线。文献[13]采用分段直线模型来拟合弯道车道线,利用启发式搜索算法在感兴趣区域(ROI)中搜索车道边界线,将检测到的车道线拟合为连续平滑的曲线,可以很好地逼近弯道,但该方法只适用于小曲率车道线,对大曲率车道线的检测效果不够精确。文献[14]采用双曲线模型拟合车道线,使两条双曲线收敛于同一点,有效地克服了直线和抛物线模型在直道与弯道连接处不连续的问题,但其在恶劣天气或存在其它车辆干扰的情况下检测效果较差。每种数学模型各有其优缺点,通常无法只通过一种模型就完美地拟合出车道线。④基于图像分割的方法,其将车道线和背景像素标记为不同的类,检测结果采用像素级分类的形式,与传统方法相比检测效果较理想,且通过端到端的学习鲁棒性更好。文献[3]提出一种改进分割网络(segmentation network,SegNet)算法,采用卷积与池化提取车道线特征,利用连通域约束实现了对二值化图像车道线的准确分割,但其结构复杂,实时性较差。LaneNet[4]是一种基于实例分割的车道线检测方法,有两个解码器,一个用于分割,一个用于嵌入,LaneNet可以在训练阶段而非后处理阶段对每条车道线进行聚类。CNN-LSTM[15]是一种将CNN和RNN相结合的混合深度网络结构,在编码器和解码器之间增加了两层LSTM,融合了时域信息,该方法在车辆遮挡、阴影、恶劣的天气条件下也能取得较好的性能,但将CNN和LSTM结合需要较大的计算量。
本文相关的MMA-Net[10]算法属于基于图像分割的方法,其采用4层CNN作为编码器提取车道线的局部和全局记忆特征,并利用局部全局记忆聚合模块(Local and Global Memory Aggregation Module,LGMA)对多层的局部和全局记忆特征进行聚合,来增强目标帧的特征,最后通过解码器预测车道线实例分割结果。针对MMA-Net算法存在的准确率低和漏检率高的问题,本文对MMA-Net算法进行改进:
1)由于CNN只能提取空间特征,没有考虑到长时记忆特征,将MMA-Net的编码器由CNN替换为GRU,以获取长时记忆信息。
2)将MMA-Net原本的对称结构改为编码多解码少的非对称网络结构,将编码器层数从4层增加到6层,以提取车道线的深层特征,更好地获取其细长形状结构。
3)采用两阶段训练方法,用4层循环神经网络(Recurrent Neural Network,RNN)作为特征提取主干进行预训练,获取视频帧序列的记忆信息。
在视频级数据集VIL-100上进行验证,并与11个先进的车道线检测方法进行了比较,结果表明,改进MMA-Net算法以最高的检测精度和和最快的检测速度显著胜于其它方法。
3 改进MMA-Net算法
改进MMA-Net的网络结构如图1所示。首先,将视频序列中的有序历史帧作为局部记忆,将打乱顺序后的历史帧作为全局记忆,采用6层GRU网络作为编码器提取局部和全局记忆特征,然后利用 LGMA模块中的注意力机制对多层的局部和全局记忆特征进行聚合,最后采用3个Refine模块[16]作为解码器来预测目标帧的车道线实例分割结果。
3.1 GRU编码器
由于卷积神经网络(CNN)只能提取空间特征,而门控循环单元(GRU)具有记忆功能,能够提取时间特征,考虑到视频历史帧的车道线记忆信息对于检测当前帧的车道线位置具有一定作用,将MMA-Net中的CNN替换为GRU,其利用更新门和重置门选择性地遗忘过去不重要的信息并记忆重要的信息。
较于原始MMA-Net的CNN编码器,改进的GRU编码器具有更强的长距离(long-range)特征捕获能力,可以获取视频帧序列的长时记忆信息,增强每个目标视频帧的低级和高级特征,更好地用于视频实例车道线检测。而且,GRU网络在保留长时序列信息的同时还减少了梯度消失问题,有效地提高了模型的检测精度,同时减少了网络运行时间。
3.2 非对称网络结构
MMA-Net的网络结构主要由编码器和解码器组成,编码器采用4层CNN网络对输入图像进行下采样,提取车道线特征,而解码器由3层Refine网络和1层卷积层还原图像大小,得到车道线分割结果。改进的MMA-Net将原本的对称结构改为编码多解码少的非对称网络结构,为提取车道线的深层特征,将编码器层数从4层增加到6层,增大感受野的同时,可以获得不同尺度的图像特征,这样更好地获取了车道线的细长形状,极大地提高了网络的检测精度。
如图1所示,为检测目标帧的车道线,将目标帧按顺序排列的前5帧图像{Ot-5,Ot-4,Ot-3,Ot-2,Ot-1}作为局部记忆,在打乱顺序后的历史帧中抽取5帧{St-5,St-4,St-3,St-2,St-1}作为全局记忆,输入编码器。然后,将每个视频帧传递给一个由6层GRU组成的编码器,获得局部记忆特征{Lt-5,Lt-4,Lt-3,Lt-2,Lt-1}和全局记忆特征{Gt-5,Gt-4,Gt-3,Gt-2,Gt-1}。
3.3 LGMA和MR模块
目前大部分记忆网络都是对有序的视频帧进行特征提取,提取的特征很大程度上依赖于时间信息,而LGMA模块利用从5帧打乱顺序的视频帧中提取的全局记忆特征{Gt-5,Gt-4,Gt-3,Gt-2,Gt-1}来去除时间信息,增强车道线检测的全局语义信息。而且,由于不同视频帧对车道线检测的贡献程度不同,故LGMA模块利用注意机制来为每个局部记忆特征和全局记忆特征分配不同的权重,以帮助当前帧识别背景像素。

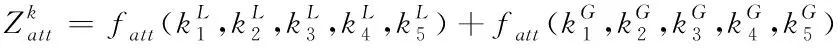
(1)
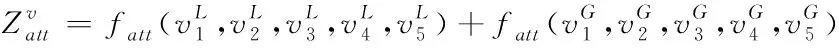
(2)
其中fatt(·)表示注意力运算,这里使用点乘运算。
3.4 解码器
网络的解码器利用MR模块的输出特征来预测目标视频帧的车道线检测结果。首先,通过一个卷积层和一个残差块(residual block)[17]将MR模块的输出特征压缩为256通道;然后,使用3个细化块(refinement block)[16]逐步融合编码器提取的特征;最后,通过一个卷积层和一个softmax层生成目标视频帧的车道线实例分割结果。
4 实验与分析
4.1 数据集
实验使用公开车道线检测视频数据集VIL-100,共10000帧图片,含100个视频,每个视频有100帧。包含10种道路场景:正常、拥挤、弯道、磨损道路、阴影、道路标线、眩光、雾霾、夜晚、十字路口,大小为640×368~1920×1080像素。将数据集按8:2的比例划分为训练集和测试集,训练集和测试集都包含这10种场景,以保证不同的方法在该数据集上可以进行公平比较。部分数据示例如图2所示。

图2 数据集示例
4.2 实验平台
实验环境配置为:Windows10×64操作系统,Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz 3.70 GHz处理器,NVIDIA GeForce RTX 3080 Ti显卡,64GB内存,实验采用Python 3.8编程语言,深度学习框架为PyTorch。
4.3 评价指标
算法评价指标采用准确率(Accuracy),误检率(False positives,FP)和漏检率(False negatives,FN)。一般来说,Accuracy越高,FP和FN越小,车道线检测效果越好。准确率的计算方式如下
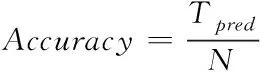
(3)
其中,表示预测正确的车道线数量,表示总的车道线数量。误检率和漏检率的计算公式:
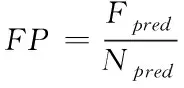
(4)
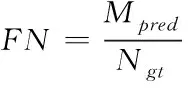
(5)
其中,Fpred表示预测错误的车道线数量,Npred表示预测的车道线总数量,Mpred为没有预测到但真实存在的车道线数量,Ngt为标签中的车道线总数量[18]。
4.4 两阶段训练
在预训练阶段,使用4层RNN作为编码器初始化特征提取主干(backbone),RNN的记忆功能有助于获取连续视频帧序列中车道线的长时记忆信息,更准确地预测车道线位置。原始MMA-Net的CNN编码器只能用于静态输出,而RNN可以用于描述时间上连续状态的输出,其获取的历史帧车道线记忆信息可辅助检测当前帧的车道线位置。
在正式训练阶段,利用预训练阶段得到的最优权重进行训练,使用6层GRU作为编码器,用随机梯度下降(SGD)优化器对网络进行优化,输入图像大小为240×427像素,学习率为10-3,学习动量为0.9,权重衰减为10-6,批量大小为1,迭代轮次(epoch)为60次。
4.5 算法性能对比
图3给出了改进MMA-Net算法车道线检测的部分可视化结果,从左到右4列分别为输入图像、真实标签、改进MMA-Net预测结果和原始MMA-Net预测结果。可以看出,改进MMA-Net算法在多种场景下都能准确地检测出车道线,同时检测结果更加接近真实标签,对原始MMA-Net中的漏检(如第1行)、预测车道线模糊(如第2行)等现象都有较大的改进。

图3 改进MMA-Net和MMA-Net的视觉对比
表1给出了改进MMA-Net算法与其它11个车道线检测算法在VIL-100数据集上的检测结果量化性能对比,其中LaneNet[4]、SCNN[5]、ENet-SAD[19]、UFSA[20]和LSTR[6]是图像级的车道线检测方法,而GAM[21]、RVOS[22]、STM[23]、AFB-URR[24]、TVOS[25]和MMA-Net[10]是视频级的车道线检测方法。可以看出,改进MMA-Net算法的准确率(Accuracy)最高,达到97.2%,同时误检率(FP)和漏检率(FN)最低,分别为7.6%和4.4%,都远远胜于其它算法。与原始的MMA-Net相比,准确率提升了6.2%,误检率降低了3.5%,漏检率降低了6.1%,性能显著提高了。
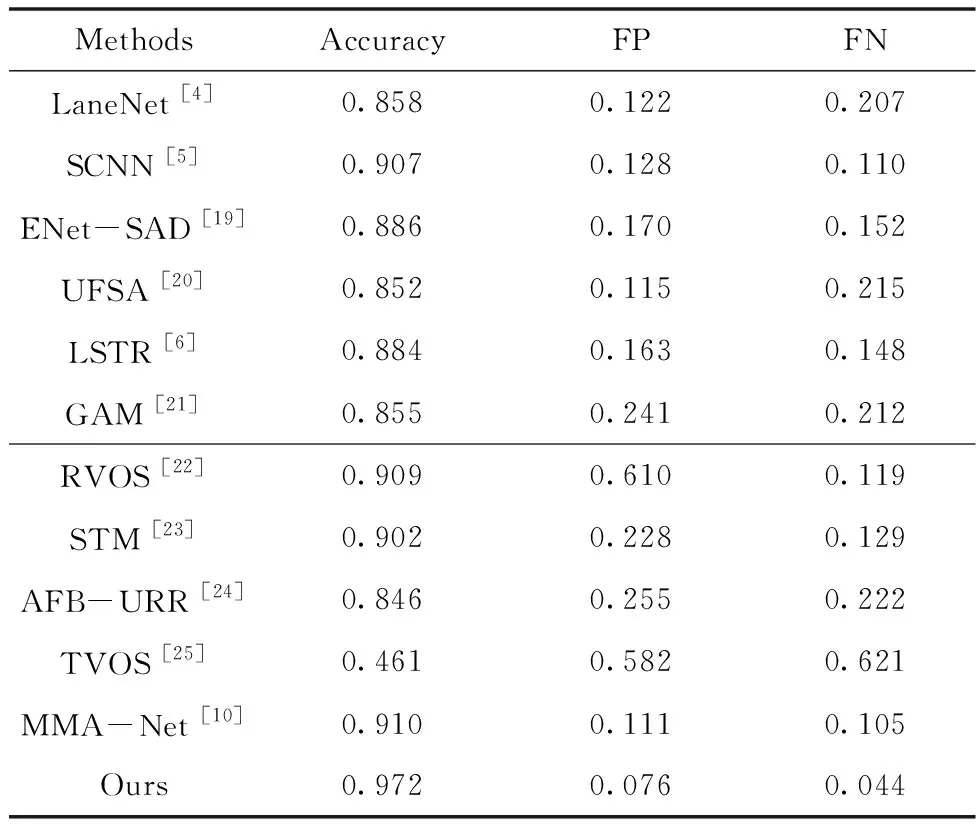
表1 各方法量化性能比较
4.6 消融实验
4.6.1 编码器模型
为了研究编码器模型对车道线检测结果的影响,对不同的编码器模型进行实验,在控制网络层数为4层的前提下,分别将CNN、RNN、LSTM、GRU作为编码器进行训练,结果见表2。可以看到,这四种编码器中GRU的准确率(Accuracy)最高,为91.9%,而RNN的误检率(FP)和漏检率(FN)最低,分别为10.8%和10.3%,LSTM的检测速度则最快,达到18.277帧/每秒(fps)。本文使用RNN编码器进行预训练,再用得到的最优权重对GRU编码器进行正式训练,有效地综合了各网络的优势,训练结果显示各个性能都有显著提升,准确率达到了94.7%,误检率降为9.9%,漏检率降为6.1%,同时检测速度也提高到18.391 fps。可见采用RNN进行预训练,再用GRU作为编码器的检测效果最好。
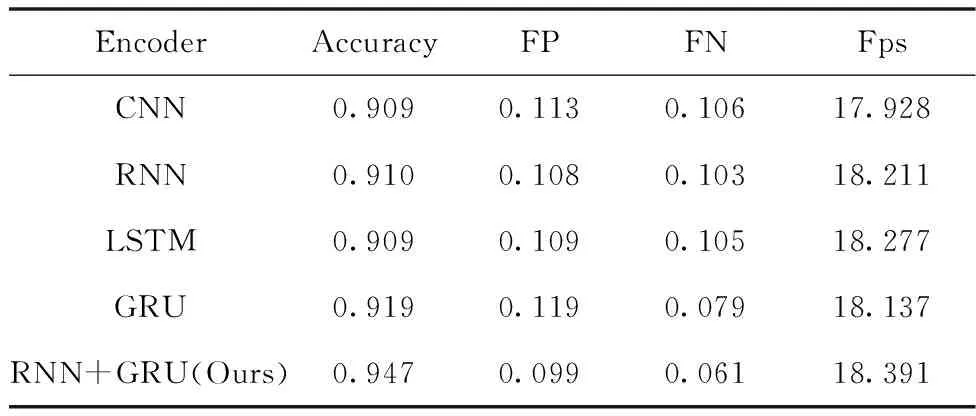
表2 编码器模型的定量评估
4.6.2 编码器层数
为了研究编码器层数取多少时车道线检测效果最佳,采用RNN预训练,GRU作为编码器,对不同层数的编码器进行实验。从表3可以看出,随着层数的增加,准确率呈现先上升后下降的趋势,在6层时达到最高,为97.2%;而误检率和漏检率则相反,呈现先下降后上升的趋势,同样在6层时达到最低,分别为7.6%和4.4%;而检测速度也是在6层时达到最快,为18.571 fps,较原始MMA-Net的4层CNN编码器(17.928 fps)提高了0.643 fps。这验证了选择编码器层数为6层是最佳的,可达到最高的检测精度和最快的检测速度。
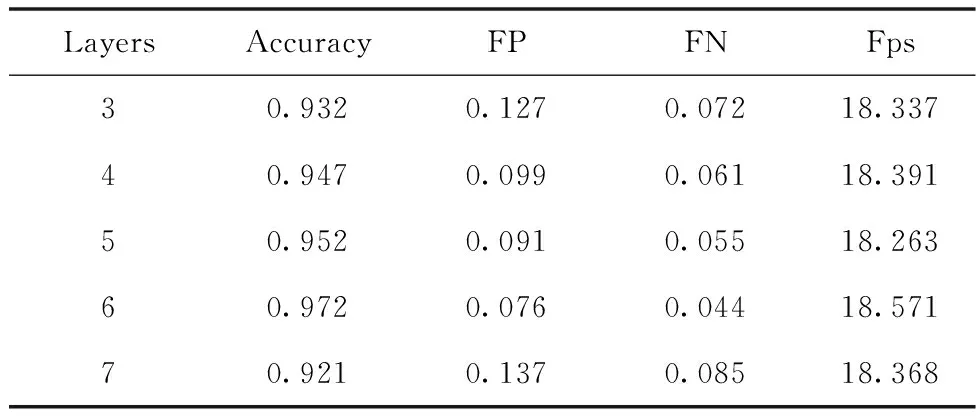
表3 编码器层数的定量评估
5 结论
本文提出了一种改进MMA-Net算法的车道线检测方法,将MMA-Net的编码器由CNN替换为GRU,增加长时记忆信息,同时将编码器层数增加到6层,形成编码多解码少的非对称网络结构,更好地获取车道线的细长形状。采用两阶段训练方法在VIL-100数据集上进行训练与测试,实验结果表明,改进MMA-Net算法的准确率和检测速度都明显高于原始MMA-Net,且远胜于其它车道线检测方法。下一步将在其它数据集上进行实验,对模型的泛化能力进一步深入研究。
猜你喜欢
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
成都信息工程大学学报(2018年3期)2018-08-29
作文周刊·小学一年级版(2016年27期)2017-06-03
电子设计工程(2017年20期)2017-02-10
新湘评论·下半月(2016年4期)2016-05-05
新湘评论·下半月(2016年4期)2016-05-05
海外文摘(2016年4期)2016-04-15
电子器件(2015年5期)2015-12-29
