
基于改进PP-YOLOv2的红外图像电力设备检测
2023-10-29 01:31郭美青张兴忠
计算机仿真 2023年9期
高 伟,郭美青,张兴忠,刘 军
(1. 国网山西省电力公司互联网部,山西 太原 030000;2. 太原理工大学软件学院,山西 晋中 030600)
1 引言
保持电力设备安全稳定的运行是系统运维的首要任务,及时监测设备的运行状态,能够预防由设备缺陷或故障引起的电网事故发生。红外热成像技术具有非接触、全天候监测的特点,在电力系统运维的安全性、可靠性、经济性等方面具有明显优势。但目前对电力设备红外图像的分析仍需依赖经验丰富的工程师[1],需消耗大量人力和时间成本,极大地降低了设备状态监测效率,因此基于红外图像的目标检测及应用已成为当前电力领域人工智能研究的热点,而对目标快速精确地定位是实现电力智能巡检的前提和关键。
目前针对电力设备目标定位的计算机视觉技术主要分为两类:一类是基于图像处理的检测方法;另一类是基于深度学习的检测方法[2]。基于图像处理的检测方法大多基于提取目标的某些特征,或再辅以特征的训练得到特征分类器[3]。曾军[4]等提出改进的K-means算法对图像进行分割,然后结合SURF算法和感知哈希算法完成设备的定位。郭文诚[5]通过对电力设备提取Zernike矩特征,再应用相关向量机分类器实现设备的分类识别。但是该类方法通过手动特征提取的方法与目标特性紧密相关,在应用中具有一定的局限性,且检测时间较长,人工无法短时间实现对大规模复杂设备特征进行提取的设计工作,并不能满足电网快速发展的需求[6]。基于深度学习的目标检测方法在电力巡检工作中的应用,表现效果最好的还是以检测少类目标或背景简单的目标为主。刘子全[7]借鉴并改进Mask-RCNN方法,利用图像语义分割识别红外图像中的一个或多个电力设备,实现模型检测精度的进一步提高。黄锐勇[8]采用CenterNet结合结构化定位的算法模型,从复杂的红外图像中以较高的准确率将不同变电站设备及其部件识别定位。
相较于传统的图像处理方法,深度学习方法在检测效果上既提高了精度又提高了速度,但在应对复杂环境变化、精度、处理速度等方面仍需持续改进[9]。因此,研究者们也逐渐将研究重点转移到保证必要检测精度的前提下尽可能提高检测效率。YOLO系列算法以其又快又好的效果在学术及产业界全面风靡,郑含博[10]提出改进YOLOv3的电力设备红外目标检测模型,对设备快速精确地检测定位;刘杨帆[11]提出改进YOLOv4的空间红外弱目标检测方法,满足了空间红外弱目标检测任务的需求。舒朗[12]提出Dense-Yolov5的网络模型,提高了对红外目标尤其是特征不明显的小目标的识别效果。Huang X[13]等首次提出了PP-YOLOv2模型,在检测速度和精度上均表现出了巨大优势,本文将该模型首次应用于电力设备红外图像的目标检测。
研究发现原始模型存在几个问题:模型高性能是根据自然图像公开数据集中的目标得到,电力场景下的红外图像与自然图像存在较大差异,以往的目标检测算法没有充分考虑到这种情况,导致检测效果不理想,因此不完全适用于该目标检测任务;深度学习方法需要大量的训练样本,而复杂电力环境下获取大量完备红外图像进行分析的难度较高,因此对小样本数据集下目标检测有一定难度[14]。针对以上问题,本文基于PP-YOLOv2,提出小样本条件下的红外图像数据扩增方法Mix_Grid,增强模型的泛化能力及鲁棒性;在特征提取阶段,融合注意力机制,优化主干网络,提高检测精度;在模型训练损失函数部分,引入梯度均衡机制,解决正负样本与难易样本不平衡问题,提高对各类设备的识别能力。
2 数据集及预处理
2.1 数据集构建
本文建立的电力设备红外图像样本数据库,来源于运检部门历次采用FLIR_P630红外热像仪采集的红外图谱数据,包括绝缘子、套管、电流互感器、断路器、变压器、电压互感器、隔离开关等八种典型设备类型,图像分辨率640×480。数据集经筛选剔除后得到的总样本数为594幅。每张图像包含多个设备。该数据集是一个相对小型的数据集,图像数量未达到充足和完善的工业检测领域要求,为避免卷积网络的过拟合问题,数据增强技术是解决该问题最有效的方法。部分样本如图1所示。

图1 部分样本图
2.2 数据增强
红外图像具有对比度较低、设备特征信息不明显、各目标特征差异集中在较小部位等特点,为保持对真实数据的良好了解,避免严重破坏特征的完整性,设计了一种快速、高效的数据增强方法Mix_Grid,主要通过多样本数据增强方法与基于区域删除的Gridmask方法的结合,一方面旨在关注样本的显著性区域,丰富被检测目标的背景,增加数据集的多样性,另一方面有效加大训练难度,防止过拟合,在一定程度上增强网络的泛化能力,使网络具有更好的鲁棒性。Mix_Grid方法流程如图2。
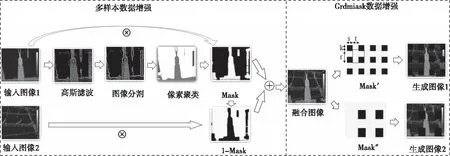
图2 Mix_Grid数据增强方法流程图
首先,多样本数据增强具体过程为:将图像进行灰度化与高斯滤波处理,去掉不必要的像素点;利用红外图像具有明显的亮度特征,对其进行Otsu阈值分割;采用DBSCAN算法对坐标值进行聚类,对其进行图像形态学处理,生成mask;两张图像分别与mask、1-mask相乘叠加的得到融合图像。
其次,Graidmask[15]方法通过删除图像的信息来减少数据的过拟合,增强模型对图像局部空间特征的学习,降低模型的泛化能力,提高网络鲁棒性。相较于其它信息删除方法,Graidmask通过简单的网格掩码,删除均匀分布的正方形区域,以极低的计算预算,避免过度删除图像中的重要信息,又避免没有删除到目标信息而不能起到增加网络泛化能力的作用。实现过程如图2右侧所示,主要通过生成一个和原图相同分辨率的mask,然后将mask与原图相乘,得到特定区域信息删除的新图像。其中虚线框部分为基本的mask单元,(s,k)表示第一个mask单元离图像边缘的距离,t为保留图像的比例,r为mask单元的边长。
3 电力设备红外图像目标检测模型
3.1 PP-Yolov2模型
PP-YOLOv2模型主要包括特征提取网络Backbone、特征融合网络Neck和多尺度预测网络Head三部分。首先模型选择ResNet50vd-DCN作为骨干网络,ResNet50vd是拥有50个卷积层的ResNet-D网络,并即在ResNet的最后一个阶段增加可变形卷积(Deformable Convolution,DCN),引入极少计算量而提高模型检测精度。其次模型采用路径聚合网络(Path Aggregation Network,PANet)作为特征融合网络。PANet避免了信息丢失问题,先进行自顶向下的特征融合,再进行自底向上的特征融合,使得底层信息更容易传递到顶层,拼接后的信息既包含底层特征也包含语义特征。在经过PANet结构后,输出3维特征图。Head部分使用卷积对其进行编码,然后将其经过矩阵非极大抑制算法后处理,调整先验框得到最终检测结果。
3.2 改进的PP-YOLOv2模型
数据集通过现场多种拍摄角度收集,可能存在温度间界限不明显、目标轮廓模糊、背景干扰较为严重、被红外探测设备显示的实时数据遮挡,导致检测难度较大等问题,此时算法的有效性和高效性尤为重要。PP-YOLOv2模型有较强的检测能力,但它对红外图像没有针对性,特征提取效果较差。针对PP-YOLOv2网络对因受部分遮挡和红外图像信息较少而使设备目标置信度较低、错检和漏检等情况,本文优化PP-YOLOv2模型,在特征提取阶段,融合协调注意力机制[16](Coordinate Attention,CA),优化主干网络,提高检测精度;在模型训练损失函数部分,引入梯度均衡机制[17](gradient harmonizing mechanism,GHM)解决样本不平衡问题,提高对设备特征的预测能力。最终该模型可在复杂背景下对相似目标、遮挡目标均具有很强的识别能力。改进模型的结构如图3所示。
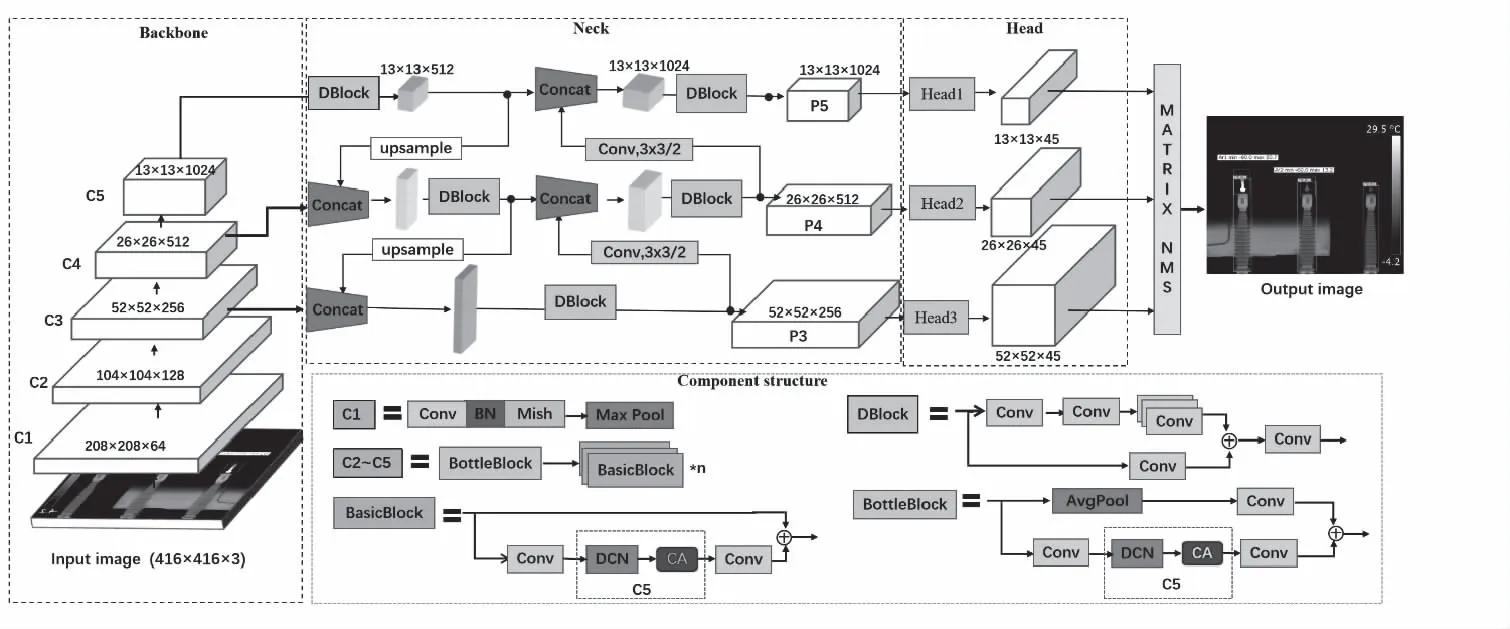
图3 改进的PP-YOLOv2网络结构
3.2.1 CA注意力模块
原模型中采用通道注意力机制(Squeeze and excitation Network,SENet)[18]为各种深层卷积架构带来性能提升。但SENet只考虑内部通道信息而忽略位置信息的重要性,位置信息对于生成空间选择性注意力特征图极其重要。与通常场景相比,复杂电力场景下的红外目标检测中对位置预测的要求更高。而CA注意力模块同时考虑了通道间关系和位置信息,不仅捕获跨通道的信息,而且包含位置敏感的信息,因此模型能更准确地识别并定位到目标区域。且注意力机制消耗的显存和计算量与输入大小成倍增长,嵌入位置会影响模型训练和测试效率,因此为了不影响骨干网络预训练参数的加载,本文仅在ResNet50_vd_dcn的最后三个卷积层添加CA模块,特征提取网络命名为ResNet50_vd_dcn_CA,通过把位置信息嵌入到通道注意力,从而使网络获取更丰富区域的语义信息,而避免引入更大的开销,提升网络获取全局信息的能力,增强网络对于目标检测任务的泛化能力,使其更加符合电力领域高准确率和实时检测的要求。CA注意力模块结构如图4所示,其中r是一个缩放参数,用于减少网络的参数量和计算复杂度。其步骤可总结如下。
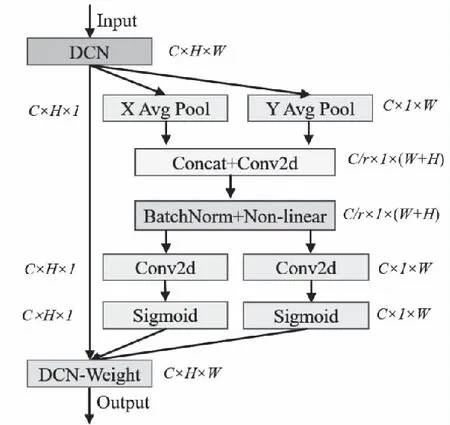
图4 CA注意力模块结构
1)分别使用尺寸为(H,1)和(1,W)的池化核沿水平坐标与垂直坐标对输入特征图x的每个通道进行编码,分别得到两个方向感知的特征输出和,其计算公式如下
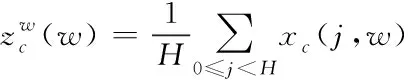
(1)
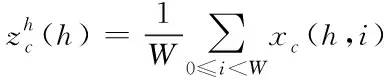
(2)
式中,w、h分别表示特征图的宽高,c表示通道数。
2)对输出特征和进行连接操作,将空间信息在水平方向和垂直方向进行编码得到中间特征映射f。
f=δ(F1([zh,zw]))
(3)
式中,[,]为沿空间维数的连接操作,δ为非线性激活函数,F1为卷积操作。
3)沿着空间维数将f分解为2个单独的张量fh和fw。利用另外2个1×1卷积变换Fh和Fw,分别将fh和fw变换为具有相同通道数的张量,得到两个方向对应输出。
th=σ(Fh(fh))
(4)
tw=σ(Fw(fw))
(5)
式中,σ是sigmoid激活函数。
4)最终得到经过CA注意力机制模块的输出特征图y。
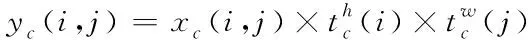
(6)
3.2.2 损失函数
模型的损失函数由分类误差、边界框坐标预测误差、置信度误差、用于学习预测框与真实框的损失函数四部分组成。研究发现,自建数据集中存在类别间的正负样本和难易样本不均衡问题,如电流互感器与电压互感器、断路器与避雷器等设备轮廓特征相近,分类任务较困难,而变压器、绝缘子等设备特征与其它设备外观差异较大,较易分类。模型若直接进行训练,对于正样本中预测概率不高的,负样本中预测概率较高的难分样本,很难被正确分类。
目前解决样本不平衡问题的方法,比如Focal loss[19],存在过多关注难分样本,忽略样本离群点从而影响检测效果以及超参数需进行大量实验调整等问题。而GHM方法从梯度分布的角度考虑,表示难度不同样本的不均衡性可体现在梯度模长的分布上,该梯度均衡化策略可优化训练过程,进而有效地改进单阶段检测器的性能。因此本文将分类损失嵌入到GHM分类损失中,修正不同属性样本的梯度贡献,从而解决样本不平衡问题,提高网络对目标正负样本和难易样本的判别能力。损失函数计算过程如下:
1)置信度误差Lobj的计算公式如下
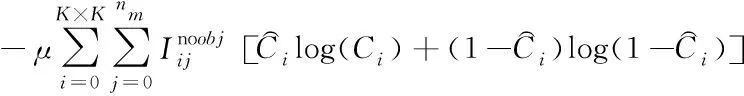
(7)
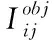
2)模型使用LIoU优化真实框与预测框的交并比(Intersection OverUnion,IoU),计算过程如下
LIoU=1-IoU2
(8)
3)用于学习预测框与真实框的IoU的损失函数LIoU_aware计算公式如下
LIoU_aware=-(IoU*log(σ(s))
-(1-IoU)*log(1-σ(s))
(9)
式中,s为该预测分支的原始输出。
4)原始模型的分类损失采用二进制交叉熵表示,如下所示
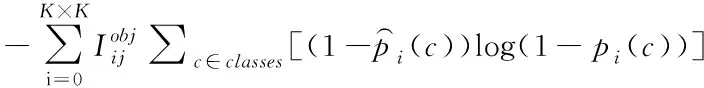
(10)
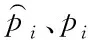
利用GHM对分类损失函数进行处理后得到最终分类损失LGHM_cls,通过交叉熵除以梯度密度,梯度密度大的损失会被抑制,减小简单样本和异常样本的权重,且梯度密度由每次迭代计算所得,因此权值随着训练动态改变适应,最终起到样本均衡的作用。计算过程如下
p=sigmoid(x)
(11)
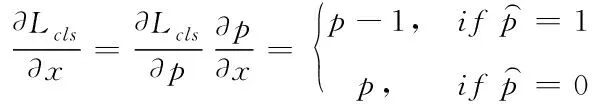
(12)
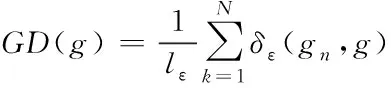
(13)
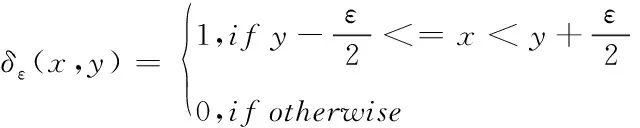
(14)

(15)
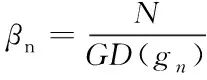
(16)
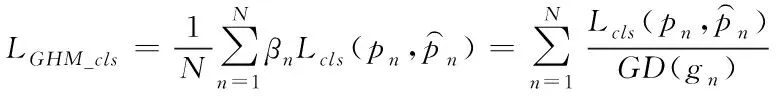
(17)
式中,x表示模型未经过sigmoid激活函数之前的输出,g为梯度的模长,GD为梯度密度,gn为第n个样本的梯度模长,ε表示一段可微的距离,δε表示该样本是否落在区间,lε表示区间长度。βn为梯度密度协调参数。
4 实验设计与结果分析
4.1 数据集
数据样本量经Mix_Grid方法扩充到1235张,包含3364个目标。本文在构建数据集时参考PASCAL VOC数据集的构建方法,严格按照标注规范对其进行标注,并划分数据集,其中训练集、验证集、测试集占比分别为70%、10%、20%。各类别样本分布情况见表1。
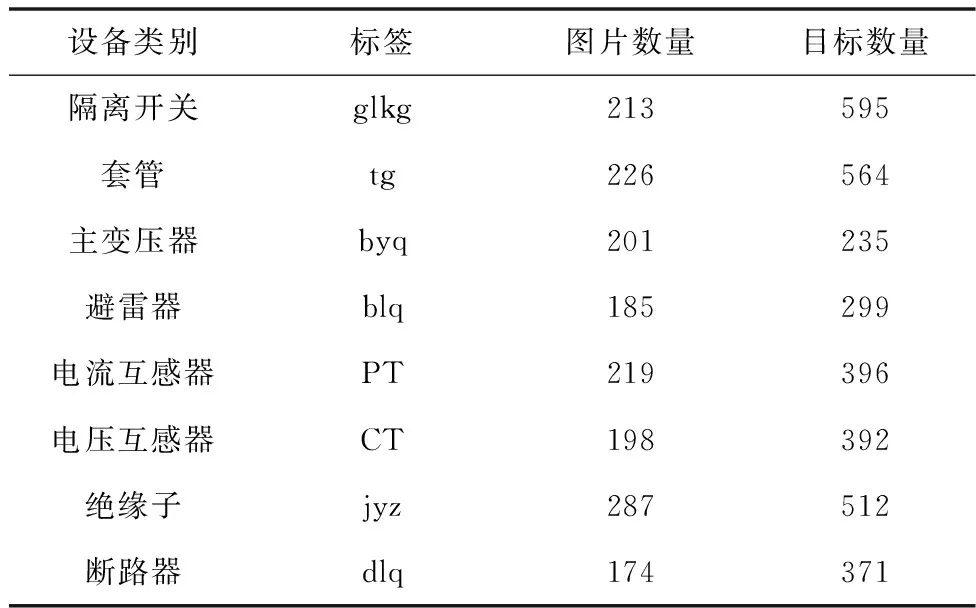
表1 数据集分布
4.2 实验环境与评价指标
操作系统为Linux ubuntu 18.04 LTS,Intel core i7-6800k CPU,采用paddle2.1.0、CUDA 10.1等环境搭建模型,运用搭载2块GeForce GTX 2080Ti显卡的服务器进行模型训练等。利用平均检测准确率(mean Average Preci-sion,mAP)以及每秒帧数(Frame per Second,FPS)作为模型定量的评估指标,mAP从召回率和准确率两个角度来衡量算法的准确性,是评价模型准确性的直观评价标准;FPS为各模型在单块2080Ti GPU上的推理速度。IOU>0.5被认定为检测成功。
4.3 模型训练
训练过程中四个损失值随迭代次数增加而变化的曲线如图5。随着训练轮次的增加,收敛速度较快,且误差波动范围逐渐缩小,当迭代次数到达800时,损失下降趋势明显变缓,且不再趋于降低。这表明模型达到较为理想的训练,训练过程中未出现过拟合现象。
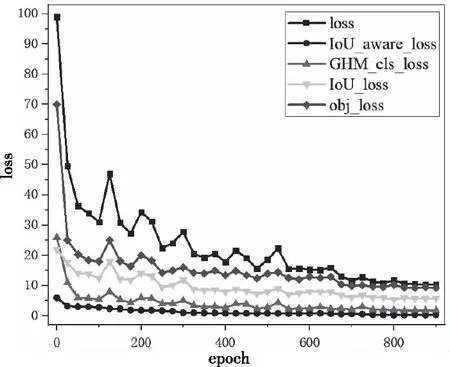
图5 训练过程中损失曲线
4.4 实验结果与分析
4.4.1 数据增强方法对比
为了验证本文所提数据增强方法Mix_Grid的有效性与实用性,将Mix_Grid、典型多样本数据增强方法Mixup[20]、Cutmix[21],信息删除数据增强方法RErase[22]、Gridmask与二阶段目标检测算法Faster R-CNN[23]、Cascade R-CNN[24]、一阶段目标检测算法YOLOv4[25]、YOLOv5[26]、PP-YOLOv2进行结合。数据增强方法在数据集上的应用效果如图6。

图6 不同数据增强方法效果
检测结果对比如图7。图中横轴“+”表示在模型基础上所使用的技术。结果显示,分别结合不同的数据增强方法后,模型性能均有所提高,mAP涨点从2.1%~2.6%不等。此外,Mix_Grid方法表现最佳,对于分类精度提升具有极大的推动作用。分析其原因可能是RErase随机选取掩码区域,容易出现对重要部位全掩盖的情况;Mixup需在样本间进行插值,抑制了模型学习特定特征的能力;CutMix选取一个固定的矩形区域,较容易覆盖重要区域。Gridmask可避免此类问题,因此也证明了所提方法中选择Gridmask的可行性。最终结果表明,Mix_Grid结合多样本数据增强方法与信息删除方法后,既为红外图像的目标检测提供了数据来源,又可以与不同目标检测方法相结合,有效提升检测精度,从而验证了本方法的先进性与可行性,应用于小型数据集对提高模型检测的精度有一定积极作用。
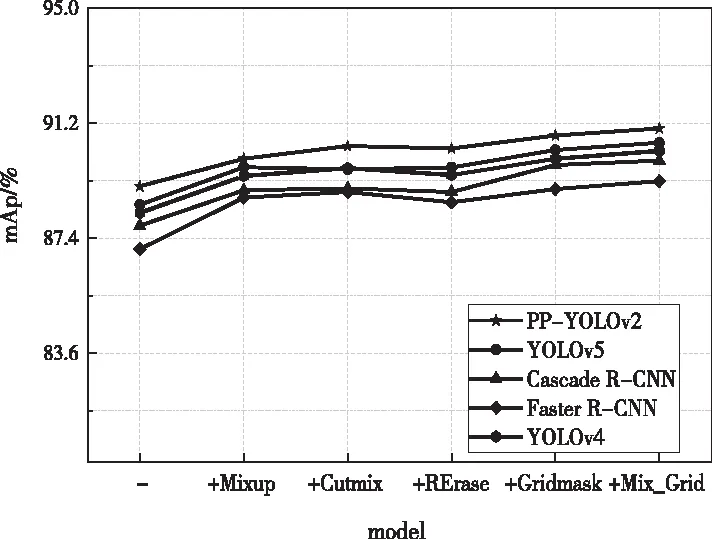
图7 模型与增强方法结合的检测结果
4.4.2 主流实时检测模型性能对比
为了验证本文模型的有效性,本部分将上述主流模型和本文提出的模型在经过数据扩充后的数据集上进行实验评估,并讨论实验结果。本文方法无论是在mAP还是预测速度上,本文算法表现均优于其它模型。对比PP-YOLOv2,本文方法mAP提升了2.3%,推理速度仅仅相差1FPS,虽增加了极少的计算量,仍满足目标检测任务中高精度与良好实时性的要求。实验结果见表2。
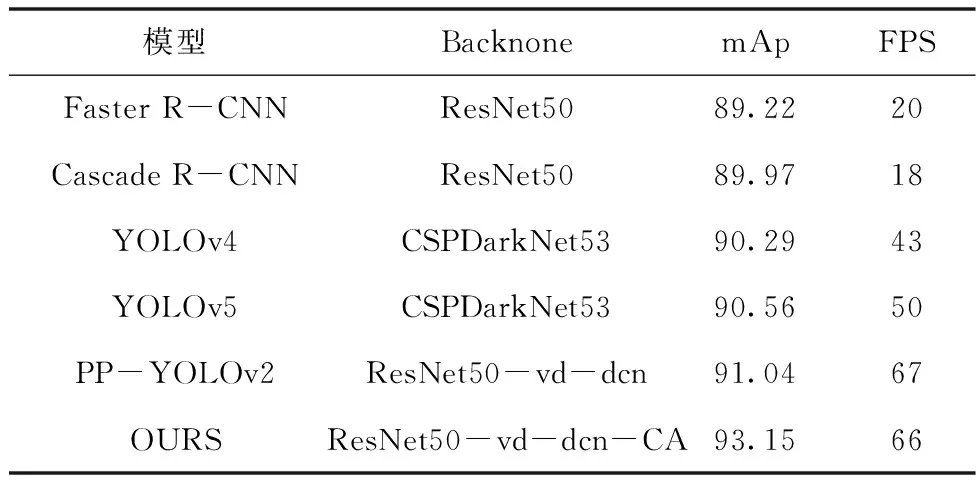
表2 主流目标检测方法性能对比
4.4.3 不同改进策略实验对比
为研究每种改进策略产生的性能增益,以PP-YOLOv2模型为基础网络,逐步添加CA模块和GHM策略,并分别计算在扩充数据集上的mAp和FPS。模型分别引入CA模块和GHM机制后,均带来检测精度的性能增益,同时添加CA模块与GHM机制后,模型检测精度提升更大,说明两种改进策略联合应用检测效果要优于单一改进的检测效果,且综合考虑方法检测精确度的提升与用时,模型足够适用于高精度与速度要求的红外图像电力设备检测场景。实验结果见表3。

表3 消融实验测试结果
4.4.4 与基准方法对比
改进模型与原始模型检测的8类设备的PR曲线对比如图8,进一步比较不同算法之间的性能差异。可以看出改进模型在扩充数据集上各类别的整体检测效果优于原始模型。其中电流互感器、断路器、避雷器3类设备AP结果提升较高,说明了本文方法不仅可以提升目标特征提取的效果,对这种设备轮廓相似的组件也有较好的检测效果,改进策略在模型整体检测效果上都起到了正向增益效果,有效缓解了复杂场景下引起的红外目标难检测问题。
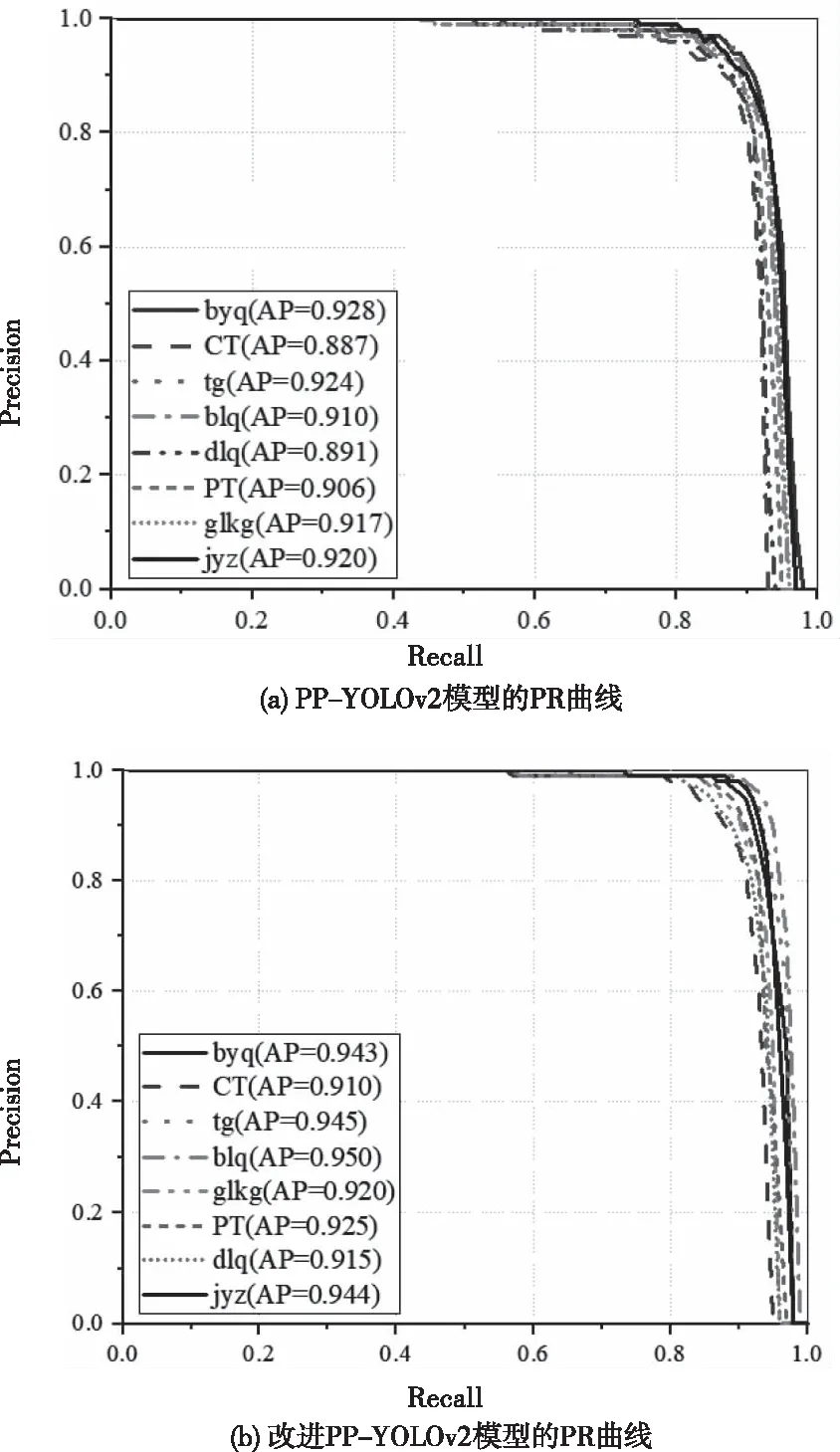
图8 不同检测识别模型的PR曲线
本文增加可视化实验来对比原始算法与改进算法在实际检测时的效果。从数据集中选取具有代表性的四幅图:选取图像温度场显著,设备边界清晰、少目标的样本时,两模型检测准确率均较高,而改进模型检测目标的置信度处在较高水平,对目标的检测画框会更精准些;选取存在目标密集重叠、遮挡严重等情况的样本,PP-YOLOv2出现的错检和漏检情况明显多于改进模型;选取存在失真、分辨率低、存在边缘模糊的小目标情况下的样本,PP-YOLOv2出现小目标漏检现象,而改进模型对特征不明显的小目标检测效果好很多;选取稍远距离拍摄,存在多种因被遮挡而关键区域信息缺失的设备的样本,此时PP-YOLOv2出现了误检与漏检,比如将隔离开关的一部分误识别为套管,在加引入CA模块和GHM策略后,模型对这种干扰情况能够得到一定程度的改善。总之,改进方法在绝大多数场景下的检测准确度高于基准算法,表明改进方法在保证检测效果的前提下适用于多种场景的红外图像目标检测任务。对比结果如图9。

图9 不同模型对同组图像的检测效果对比
5 结束语
针对复杂电力场景下对红外目标检测任务中存在的目标重叠、相似度高、部分遮挡以及目标样本稀缺、算法检测精度与速度不高等问题,本文提出了一种基于数据增强和样本均衡的电力设备红外图像检测模型。实验表明,所提数据增强方法可应用于小样本数据集,对提高模型检测的精度有一定积极作用,且改进模型在扩充数据集上mAP值达到93.15%,检测速度达66FPS,优于基准方法PP-YOLOv2,有效缓解复杂场景下多设备引起的难检测问题,能够满足电力场景红外图像目标检测任务的高精度与实时性需求。
猜你喜欢
环球时报(2022-05-23)2022-05-23
金桥(2021年4期)2021-05-21
中学生数理化·高一版(2021年2期)2021-03-19
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
电子制作(2019年7期)2019-04-25
知识经济·中国直销(2018年8期)2018-08-23
数学小灵通·3-4年级(2017年9期)2017-10-13
数学学习与研究(2017年3期)2017-03-09
光学精密工程(2016年3期)2016-11-07
