
基于改进残差网络的多准则备件分类方法
2023-10-25 10:35刘梦飞李西兴
湖北工业大学学报 2023年5期
刘梦飞, 周 伟, 李西兴
(湖北工业大学机械工程学院, 湖北 武汉 430068)
随着农业科学技术的不断进步,大型生产机械越来越得到广泛应用。要保证工厂中大型生产机械的正常运转,备件的供应保障就显得尤为重要。当大型机器出现故障以后,能否快速恢复生产,主要取决于库存部门备件的种类和数量。分类已经成为了备件管理的一项重要技术,它可以为决策者的策略提供可靠的理论依据[1,2]。备件分类已经被学者们广泛研究,在传统的分类方法中,被广泛运用的是Pareto提出的ABC分类法,使用年度总成本对备件进行分类,没有考虑库存周转率的问题,不能满足企业的生产要求[3]。类似的VED分析则是基于经验丰富的专家来简单定性的决策方法,过于主观,不能完全反映备件的管理要求。良好的备件分类应该是一个评价体系[4]。Hadi-Vencheh[5]等基于Ng模型,采用非线性优化算法计算系统中各备件的权重,作为计算各备件总分的基础。虽然基于多准则分类的方法在某些方面是有效的,但是由于其矩阵分配的主观性和学习能力的有限性,在实际应用中无法实现有效的备件的分类[6]。
为了解决多准则模型在权重分配和学习能力方面的缺陷,学者们尝试优化启发式智能算法,如人工神经网络[7]、遗传算法、支持向量机[8]及其组合等。Partovi[9]等在神经网络中使用反向传播和遗传算法来实现可靠、准确的库存分类。Liu[10]等根据某钢铁企业的多属性的实际需求,运用模糊神经网络和决策树相结合的方法对备件进行了分类。Yang[11]等采用深层的卷积神经网络对船舶备件进行了多准则的备件分类,对关键部件的监控和库存控制提供了决策支持。基于智能或启发式算法的模型可以处理非线性的样本数据,但是选取了过多的分类属性一方面会导致算法的参数过多,另一方面,没有考虑图像提取时各属性间的关联性和差异性,造成机械堆叠从而使分类结果不理想[6],
以上模型在备品备件分类方面均取得了成果,但在当前备件领域仍面临着如下问题:无论是多标准还是传统的人工神经网络都不能为决策者提供直观的、视觉上的可视化数据;另外选取了过多的属性很容易造成参数过多,程序繁琐。此外没有考虑各属性间关联性和相似属性间的差异性也会造成分类结果不准确。因此,本文提出了一种基于改进的残差网络的多准则备件分类的方法来解决上述存在的问题。首先通过数据预处理将备件信息转换为具有时间维度的彩色结构图像,将图片输入网络模型以后会自动得到分类结果。解决了多准则分类中主观性和学习能力差的问题。此外残差模块中的SENet结构,加强了各个特征提取通道之间的联系,提高了备件的分类准确率。
1 基于残差网络的备件分类方法
备件的需求量受多种因素的综合影响,基于历史需求数据和备件对设备的重要性,运用科学的方式对数据进行分析,对备件的每个属性进行数据的预处理,将每一个备件的信息转换为彩色结构的图像,最后利用卷积神经网络对备件进行分类。转换成的图上具有时间维度,可以很直观地看到备件各个属性在某个时间段的具体情况。
1.1 多准则的选取和数据的预处理
备件的分类准则影响着备件的分类结果,合理的备件分类准则必须能全面反映备件对生产流程的影响程度,备件的价值以及获得该备件的难易程度,所以本文根据获取难度、可替换性、关键性、脆弱性、经济性五个方面[12-13]确定了备件分类的准则,其中主要考虑经济性指标,详细信息如图1和表1所示。
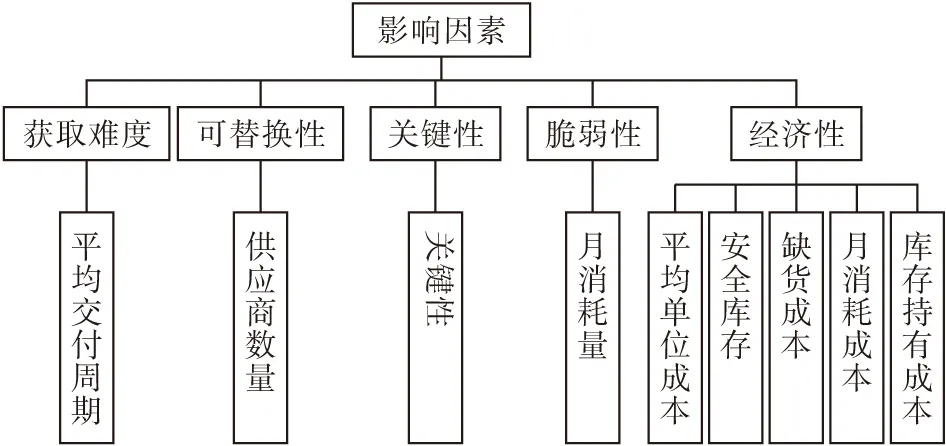
图1 备件分类影响因素

表1 备件分类的多准则选取
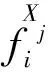
(1)
(2)
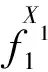
1.2 残差网络结构
He[14]等提出了残差神经网络(residual neural net work ,ResNet),随着各种硬件性能的提升,传统的卷积神经网络模型结构越来越深,出现了梯度消失和爆炸的问题,从而导致网络深度越大效果反而不好。残差网络成功地解决了这个问题。
神经网络的深度很重要,网络越深,它所提取的特征就越多,层次越丰富。残差模块(residual building block , RBB)是Resnet的核心,传统的卷积神经网络深度增加到一定值时,精度趋于饱和,深度一旦再增加会迅速出现网络退化的现象。而Resnet在增加层数的方式是在浅层网络上叠加恒等映射,构建的残差模块如图2所示。当得到的结果不满足要求时会被舍弃,满足要求时则会被保留如式(3)(4)所示。当卷积层的输入和输出的维度相同时则会直接输出,当维度不同时,则会使用1×1的卷积核来升维或降维来达到输出的条件,并能够减少大量参数的输入。
y=F3(x)+x
(3)
y=F3(x)+H(x)
(4)
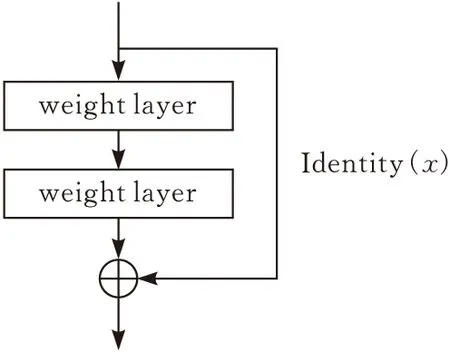
图2 深度残差学习模块
2 改进的残差网络结构
2.1 激活函数
ReLU作为最常见的激活函数,当输入的图像不满足要求时,这类值就会被舍弃,会影响模型对备件分类的准确率。利用LReLU作为激活函数来解决这个问题,其如公式(5)所示:
(5)
其中,x和y是LReLU激活函数的输入和输出;实验证明α的取值范围在0~0.5时效果最好。
2.2 挤压和激励的网络结构
为了增强各个通道之间的联系,提高模型的性能,He[15-16]等提出了挤压和激励的网络结构(SENet)。挤压的结构就是为了得到一个全局感受野的实数,将每一个特征图进行压缩,具体如公式(6)所示:
(6)
其中:xi为第i个特征图,其输入的尺寸为H×W。
为了帮助捕获通道相关性,生成对应通道的权重,可以进行激励操作。其如公式(7)所示:
y3i=F3ex(F3sq(xi),ω)=σ(ω2δ(w1F3sq(xi)))
(7)
其中:F3sq表示挤压操作过后的输出值,ω1表示第一个全连接层计算,ω2表示第二个全连接层计算。δ表示激活函数ReLU;σ表示Sigmoid激活函数,具体公式如(8)所示:
(8)
其中:x表示经过两次全连接的输出值。
2.3 交叉熵损失函数
Softmax一般作为最后输出层的激活函数,具体公式如式(9)所示:
(9)
其中:n表示分类任务标签的个数,xj表示上一层的第j个输出,y3j表示第j个预测值。
2.4 改进的残差模块
原本的残差网络是在增加网络层数的基础上叠加恒等映射,符合条件的保留,不符合条件的舍去。改进的核心部分是在残差模块的第二个卷积层之后添加了SENet结构,它可以通过自动获得每个通道的重要性,增强各个通道之间的联系,与上一层的卷积层的输出结果相乘,从而得到提升模型性能的目的(图3)。
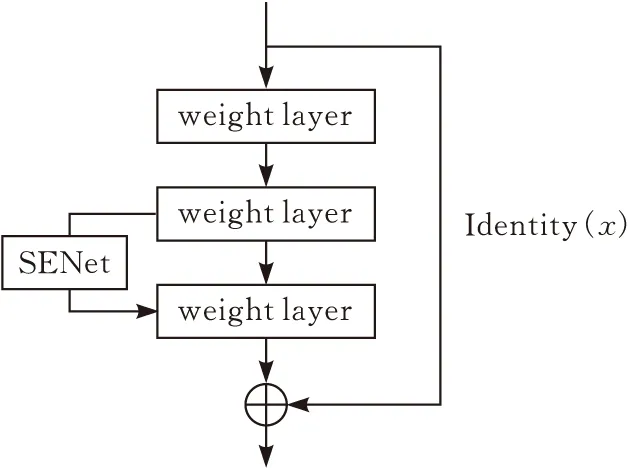
图3 改进的残差模块
2.5 改进的残差网络模型
本文根据原有的Resnet-34模型的基础上进行了改进,改进的备品备件分类的残差网络模型如图4所示,将上文所述的备件属性图像作为输入,备件的属性图像会依次经过卷积层(Conv)、最大池化层(Pooling)、改进的残差模块(RBB)、Dropout层(为了防止参数过多造成的过拟合问题)、全连接层(FC),最后通过softmax函数输出备件的分类结果。
3 实例分析
3.1 实验背景和数据来源
为了验证该算法模型的可行性,实验背景以某拖拉机集团的备件管理系统为基础。拖拉机厂是典型的长期设备系统,在整个使用周期内,它们需要定期的修理和保养。一般生产拖拉机的设备备件高达上万种,其维修备件也能达到上千种,繁多的备件种类使得库存管理成本逐渐增加。在第二节中我们已经说明了备件的多准则的选取和数据预处理的过程,模型构建完后,在专家的建议下,最终的目标输出分为A、B、C、D四类。A类备件的库存成本很高,但很少需要。但是这些备件一旦缺少会造成很大的经济损失。B类备件的库存成本也很高,但是没有A类高,并且B类备件更换频繁。所以保证B类备件的库存数量和保证供应是至关重要的。C类备件指那些定期订购的,作为维护的正常消耗的一部分,库存成本一般,供应难度也不大。D类备件是对运行影响不大的日常消耗品。
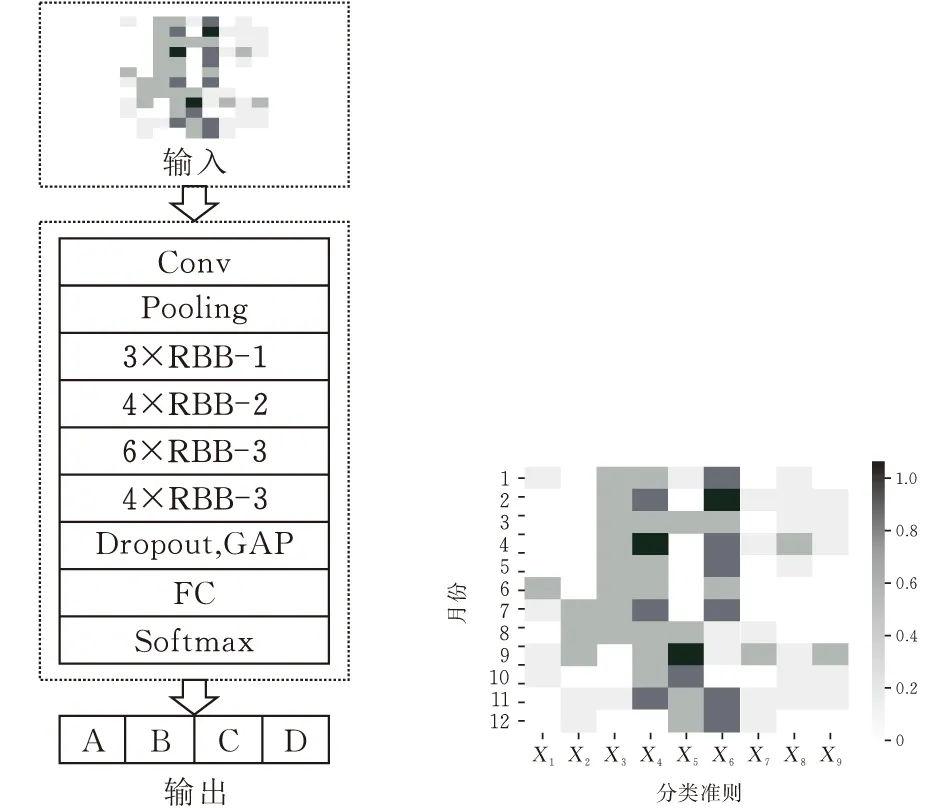
图4 本文的网络模型 图5 8号备件的信息图片
如表2所示,是某大型生产设备8号备件的原始数据,根据管理系统的信息得知该备件属于C类备件,经过数据预处理以后,会得到如图5所示的备件信息的图像。根据图像可以很直观的看到备件每个属性在某个时间段的趋势变化。在本文实验中,在备件管理信息系统中导出了标注备件1000个,A类100个,B类450个,C类250个,D类200个,将所有的备件数据转换成图像并保存,数据集按照3∶1∶1分为训练集、验证集和测试集。
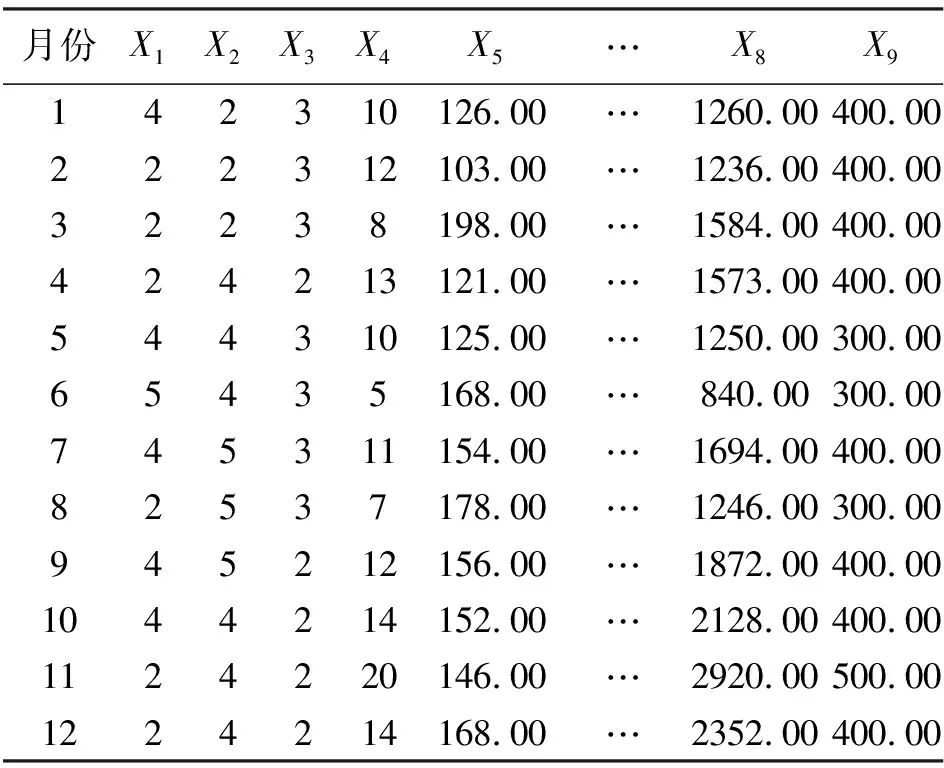
表2 8号备件的原始数据
3.2 模型结构参数设置
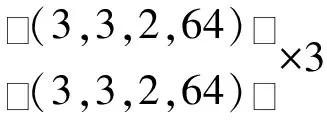
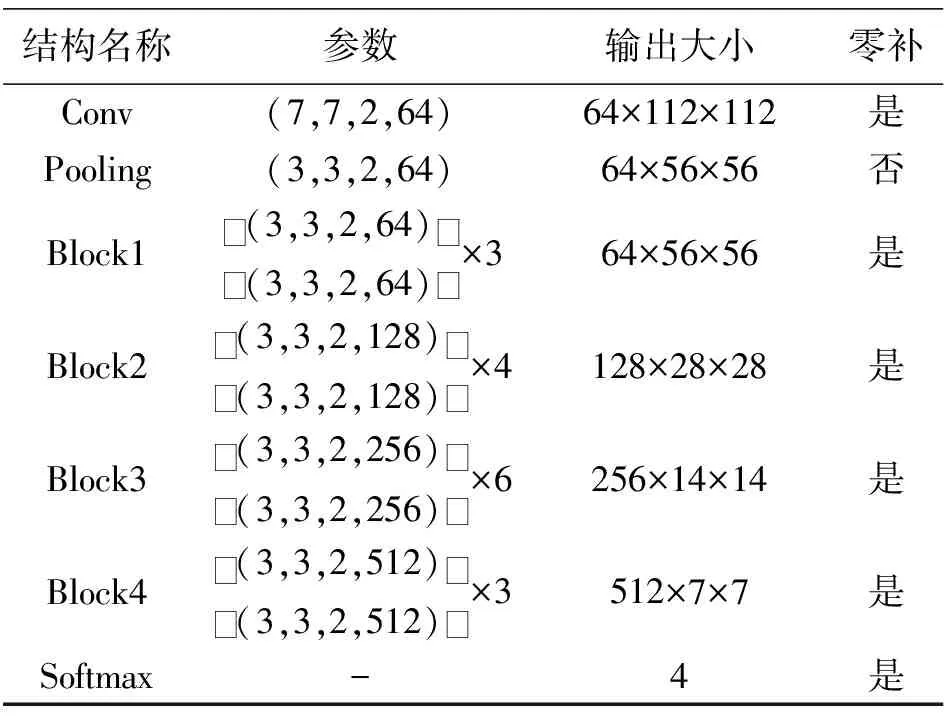
表3 模型参数设置
3.3 实验算法流程
基于改进的残差网络模型的备件分类方法的算法流程图如图6所示,从管理信息系统中导出1000个标记的备件作为原始样本,并将其划分为600个训练样本、200个验证样本和200个测试样本。每一个备件的信息都会进行数据预处理,并转换成全年的指标图像。输入的图像经过本文的网络模型的残差模块以后输出一个7×7×512的一个特征向量,经过平均池化以后输出一个1×1×512的一个特征向量,全连接层会将特征向量降维到1×4,利用softmax函数来获得最终的分类结果。在模型训练期间,比较实际输出与预期输出之间的误差。当误差不满足要求时,反向追踪模型的权重。当误差满足要求时,输出训练模型。在验证过程中,模型会使用验证子样本,评判模型的改进效果。模型测试主要是将测试样本作为模型的输入,通过训练模型实现备件的分类。

图6 本文的算法模型
3.4 实验结果与分析
经过改进残差网络模型的训练会得到如图7和图8所示的训练集和验证集的准确率和损失率的曲线图。从图中可以很容易的看出,在训练过程中,随着epochs的不断增加,训练集的准确率曲线逐渐收敛,并趋近与1;验证过程中随着epochs的不断增加,其准确率虽然有所波动,但是收敛趋势表现良好,并最终接近于99.69%左右。损失曲线,验证集的损失率收敛趋势也表现良好,并最终收敛于0.008%左右。
构建的模型对额外的200张备件信息图进行测试,并采用指标查全率r和查准率p来评价其性能如公式(10)和(11)所示:
(10)
(11)
其中TP为真阳性,被正确分类为阳性,FN为假阴性,被错误分类为假阴性,FP假阳性,被错误分类为阳性,每个类别的测试精度如公式(12)所示:
(12)
其中TN是一个真正的负数,被正确地归类为负数。FP、TP、TN、FN的分类结果见表4,由表4可知,A类备件的识别准确率为95%,B类的准确率为97.78%,C类识别准确率为100%,D类识别准确率为97.5%。实验的r、p结果见表5,由上述结果可以证明该模型可以得到理想的分类结果。并且,后续如果有新的备件引入,可以利用该网络备件对其进行分类以后再入库。
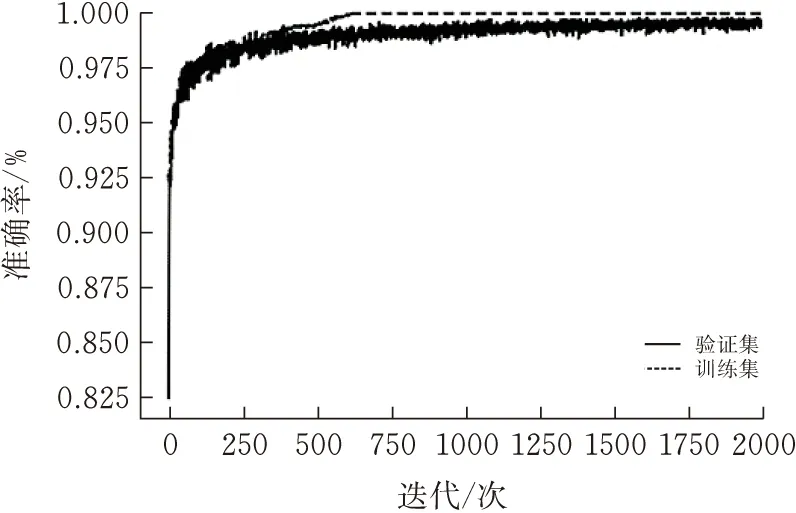
图7 模型训练和验证的准确率曲线
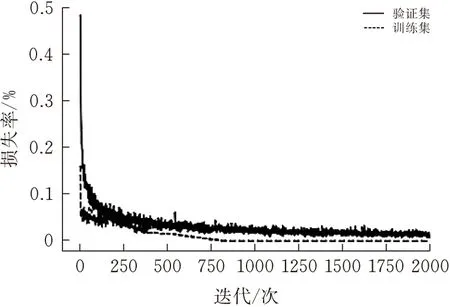
图8 模型训练和验证的损失率曲线
3.5 模型对比
为了验证网络模型改进部分对备件分类的准确率是否有提高作用,设置了三个变量。第一个变量是没有加入Dropout;第二个变量是使用了ReLu激活函数;第三个变量是不使用改进的SENet的残差模块。实验结果如表6所示,由图中可以看出直接使用ResNet模型的效果最差,表明不做任何改进的迁移学习对备件的识别率误差最大。可见每个改进部分都提升了模型对备件识别的准确率。相对于原有的ResNet的模型准确率提升了14.57%。证明改进效果还是比较理想的。验证了本文的模型可以对大型生产设备备件实现精准分类,可以为企业的库存策略提供良好的决策支持。
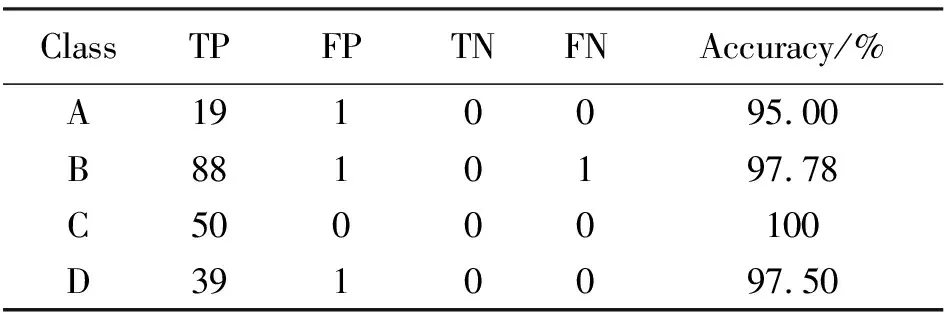
表4 FP、TP、TN、FN的分类结果
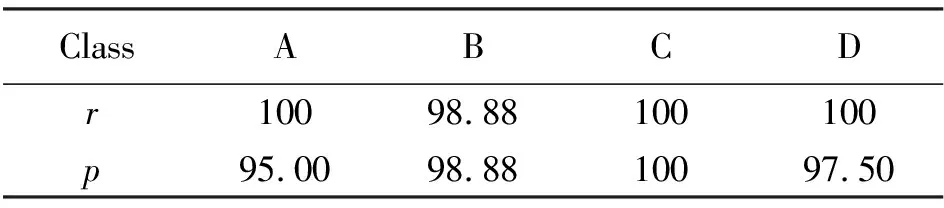
表5 r、p的分类结果 %

表6 不同模型的识别准确率
4 结论
本文针对传统的备件分类方法过于依靠设计者的经验知识,没有一定的学习能力和泛化能力等缺点,提出了基于改进的残差网络的多准则的备件分类方法。通过对某拖拉机集团备件数据的实验,证明了本文提出了分类方法的有效性和合理性。
1)本文采用的残差网络结构将传统的分类问题转换为了图像识别问题,实现了备件可视、准确的分类。构建了考虑无限准则的分层分类结构,并根据实际情况进行调整。解决了传统ABC只采用单一指标分类的局限性。加入了SENet结构,解决了因分类准则过度而造成的数据机械堆叠的问题。
2)经实验验证,本文的分类效果可以满足企业的备件分类要求,可以提高库存效率,更好地为决策者提供备件的管理依据,提高服务质量。
3)该分类方法,由于很好地加入了时间维度,可以为后续基于时间序列的预测模型对备件需求进行预测,精准补货,使精准库存管理成为可能。
猜你喜欢
水泥技术(2023年4期)2023-09-07
水泥技术(2022年4期)2022-07-27
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
数学物理学报(2020年1期)2020-04-21
活力(2019年15期)2019-09-25
自动化学报(2019年6期)2019-07-23
中国核电(2017年1期)2017-05-17
系统工程与电子技术(2016年7期)2016-08-21
浙江共产党员(2015年11期)2015-05-23
