
基于依存结构学习的中学数学术语鲁棒抽取
2023-10-25 02:11罗凯威罗文兵王明文
中文信息学报 2023年8期
罗凯威,罗文兵,2,黄 琪,2,王明文,2
(1. 江西师范大学 数字产业学院,江西 上饶 334000;2. 江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
术语是专业领域内知识概念的语言指称和主要载体[1],也是知识多模态表述中最重要的模态。术语抽取作为文本挖掘和信息抽取的首要步骤,也是机器翻译[2]、信息检索[3]、本体构建[4]、知识图谱[5]等领域的关键前提。自20世纪30年代初开始有研究者对术语相关领域展开广泛的研究[6],其中包括从耗时耗力的人工术语抽取方法到自动术语抽取(Automatic Term Extraction, ATE)模型的探索。近些年,在线智慧教育的兴起推进了基础教育领域中术语抽取方法的研究,且已在多个学科领域中取得不错成果。中学数学术语及其术语之间的关联作为中学数学学科知识表示的核心[7],其抽取的准确与否会直接决定所构建中学数学知识图谱的优劣。此外,学科知识库的不断丰富、中学数学教材的与时俱进,导致数学网络学习资源量迅猛增长。因此,如何从海量的非结构化中学数学知识中准确地自动抽取术语成为一大研究热点。
早期的术语自动抽取方法大多基于语言规则和统计,如术语抽取系统[8]依靠专业领域内总结的规则模板对术语进行筛查、Bolshakova等[9]通过计算词的TF-IDF(Term Frequency-Inverse Document Frequency)值评估某个词对某份文档的重要程度以实现术语抽取。两者在特殊学科领域内都取得了不错的抽取效果,但规则的不可穷尽性和统计值对语料库的依赖性分别导致这两类抽取模型的泛化能力较弱,迁移到中学数学术语抽取工作上的效果较差,且中学数学学科的知识表示大多又富有强逻辑性、结构性和多样性。这给中学数学术语抽取带来以下难点: ①中学数学存在的“点”“面”“高”等单字多义术语难以精准抽取,如“计算高楼的楼高”中只有“楼高”一词中的“高”是术语; ②中学数学存在的多重嵌套术语难以被完整抽取,如“无限不循环小数”中“无限”和“不循环”都是“小数”的修饰词,三者共同组成的“无限不循环小数”才是数学专业术语; ③复杂语境下术语抽取难度较大,如“点动成线”这一简明的定理同时包含两个连续的动词“动”和“成”,这种隐含的双谓语结构不易被挖掘,且“成线”这个动作事件易被误解为术语。此外,还有一些如“上”“中”等的方位词也易因在句中所作成分不同而加大相关术语抽取的难度。
为了解决上述难点造成低频词难以抽取的问题,李思良等[10]结合了基础教育资源的学科特性,提出了以挖掘术语定义与术语关系为主的综合构词规则和边界检测的术语抽取方法DRTE,并在中学数学数据集上取得了不错的抽取效果,但该方法较为耗时耗力,在复杂语境下术语抽取效果不佳。近年来,基于深度学习的术语抽取模型聚焦于丰富词嵌入表示或引入额外信息[11]以提升术语抽取性能,如Zhang等[12]提出了一种综合编码词级特征和字符特征的Lattice-LSTM模型,实现了句子语义表征的增强,且由此提高了抽取多义术语词的准确率。随着Transformer[13]模型的广泛应用,一些研究者将其与双向长短时记忆网络(Bidirectional Long Short-Term Memory, BiLSTM)、条件随机场[14](Conditional Random Field,CRF)结合并应用于多个领域[15-18]的专业术语抽取任务,其中华鑫等[18]提出了可增强标签预测的标签注意力层并结合了Lattice-LSTM模型,较好地解决了面向中学数学领域的部分多义术语词和嵌套术语词的抽取问题。但上述基于深度学习的自动术语抽取方法没有对句子本身存在的结构信息进行更深层的语义融合,导致模型对句子语义的理解有限,且没能很好地解决中学数学术语抽取存在的难点。
针对上述难点,有效捕获依存结构信息有助于提升术语抽取准确率。当前利用图神经网络获取依存结构信息表示的优异工作[19-21]已有许多,如Wu等[19]构建了一个语法融合编码器,通过整合依存边、依存标签以及词性标签等多种信息,增强了术语抽取模型的表现。但在复杂语境下由于依存结构分析器可能得到错误的分词结果或依存结构,导致图神经网络捕获的结构编码含有噪声。因此,为有效捕获句子依存结构信息并剔除其不利影响,本文提出了一种基于依存结构学习的中学数学术语鲁棒抽取模型DSL-ATRE(Dependency Structure Learning on Automatic Term Robust Extraction)。该方法利用图神经网络模型捕获句子的依存结构信息,并通过注意力机制融合结构信息和上下文信息以实现融入句子依存结构信息的同时缓解错误信息造成的影响。本文的贡献主要有:
(1) 本文是术语抽取领域第一个同时考虑句子依存结构信息与其可能存在错误分词或依存结构而带来负面影响的工作;
(2) 本文所提的DSL-ATRE模型利用注意力机制融合由图神经网络编码表示的结构信息和上下文信息以实现融入依存结构信息的同时缓解错误分词或依存结构信息的影响,从而提升模型在复杂语境下的术语抽取能力;
(3) 中学数学术语数据集上的实验结果表明本文所提的DSL-ATRE: ①在评价指标P和F1上比基准模型分别提升了2.21%、1.22%; ②在复杂语境下比基准模型具有更好的准确性和完整性。
1 问题描述
中学数学术语抽取任务旨在从文本序列集中自动抽取数学领域相关知识概念的词或短语表示,本质上可看作是一个序列标注任务。任务的形式化定义如下: 给定包含n个句子的数据集D={s1,s2,…,sn} ,每个句子s={w1,w2,…,wm}由m个单字元素构成,再利用包含k个候选标签的集合Label={Label1,Label2,…,Labelk}对每个字进行标注。该任务在本文中的形式化定义如式(1)所示。
Y=f(s)={y1,y2,…,ym|yi∈Label}
(1)
其中,Y对应句子s的预测标签序列,m为句子s所包含字的个数。本文将候选标签集规定为Label={B-T,M-T,E-T,S-T,O},这五种标签可将序列中的词或短语标注为三类: 多字术语、单字术语和非术语。对于多字术语,B-T表示术语的开始,M-T表示术语的中间字,E-T表示术语的结束;对于单字术语,标记为“S-T”;对于构成非术语的其他汉字,标记为“O”。由标签和术语词间的映射关系g可得句子s所含术语词的集合表示T,如式(2)所示。
T=g(Y)={term1,term2,…,termr}
(2)
其中,termi表示句子s中的第i个术语词,r表示句子s所包含术语词的个数。
2 模型
基于依存结构学习的中学数学术语鲁棒抽取模型DSL-ATRE如图1所示,该模型主要由六个模块组成: 语义表示、上下文语义表示、依存结构图构建、结构表示、语义融合和标签预测。下面详细介绍各个模块。
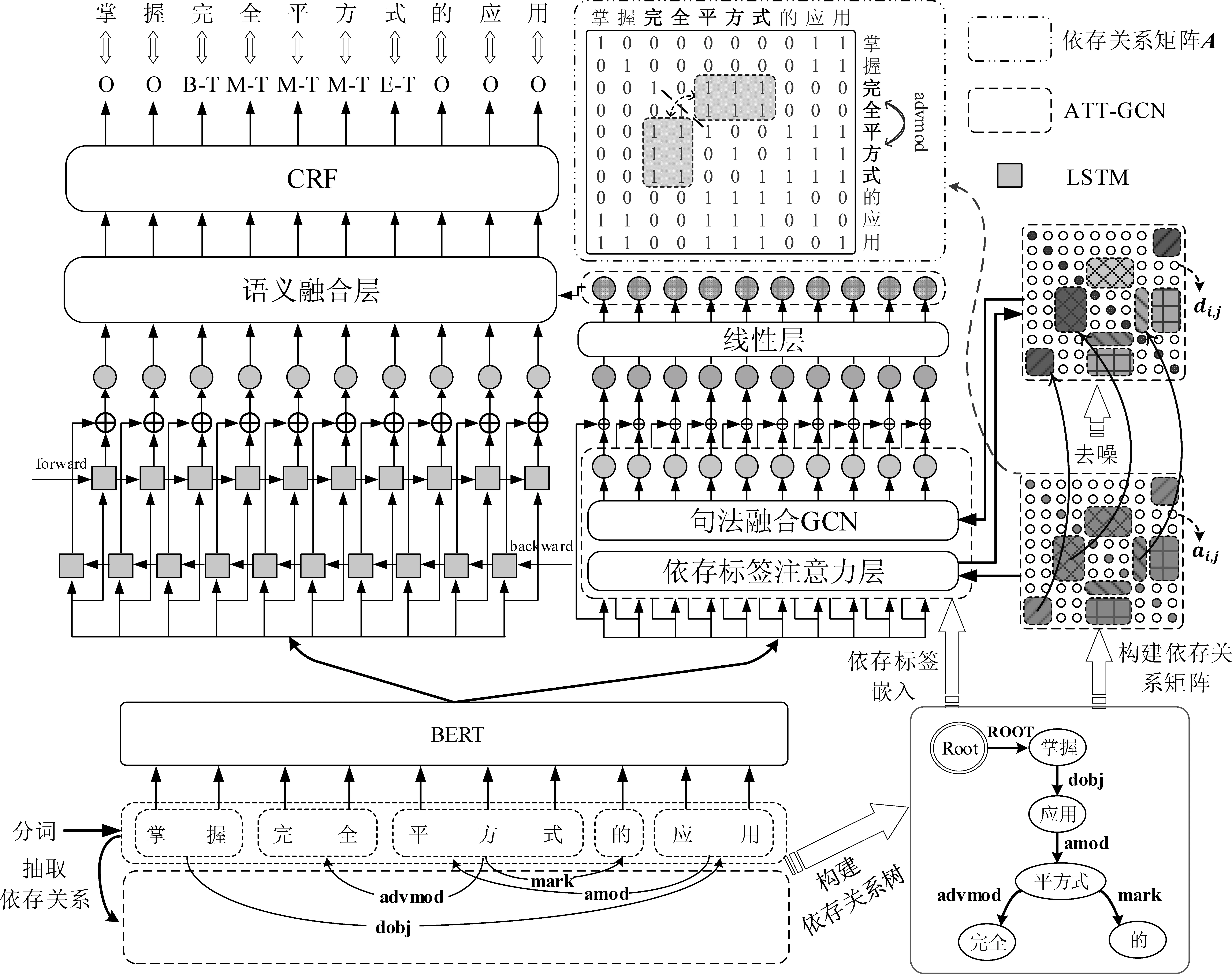
图1 DSL-ATRE总体框架图
2.1 语义表示
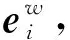
(3)
2.2 上下文语义表示
利用BiLSTM捕获文本的上下文语义信息,其中每个LSTM单元由遗忘门、输入门、输出门和记忆单元组成,其输入包括前一时刻单元隐层输出ht-1、前一时刻单元状态输出Ct-1以及当前时刻的输入xt。接着经遗忘门ft有选择地遗忘输入门信息it对单元状态的更新和输出门信息ot对下一个隐层状态的确定,由此得到最终隐藏层的输出ht。LSTM单元计算如式(4)所示。
(4)
(5)
其中,LSTMf、LSTMb分别表示前后向LSTM的输出向量,⊕表示级联操作。
2.3 依存结构图构建
借助StanfordCoreNLP工具对中文文本进行分词处理和依存结构分析,并将依存结构树转化为图结构以便模型后续的处理。
由于中文文本依存结构树中每个词节点可能由多个字构成,因此在构建依存结构图的边集合时,需将词与词间的连边转换成多字与多字的连边。为保证信息的双向流动和其语义表征的丰富性,将存在依存关系的两对词各自所包含的字相互构建无向连边,可得依存关系矩阵为A=(ai,j)m×m,其结构如图1中上部分所示。其中A为对称矩阵,m为图节点的个数,即句子包含词例的个数,且当i=j或包含字节点的词间存在依存关系时有ai,j=1,否则ai,j=0。
2.4 结构表示
受Tian[20]的A-GCN(Graph Convolutional Network,GCN)模型的启发,我们提出一种ATT-GCN模型(图2)。该模型由依存标签注意力层和句法融合GCN层组成,能够有效捕获图结构信息和缓解结构带来的噪声信息。下面详细介绍两层的结构。
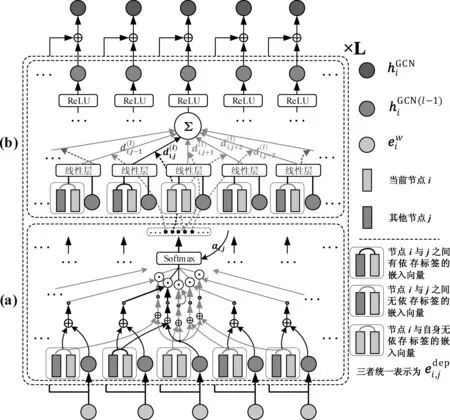
图2 ATT-GCN模型结构图 (a) 依存标签注意力层 (b)句法融合GCN层,模型展示了当前节点i得到第i个隐层输出的编码过程,其中,⊙表示当前节点i的分别与其他所有节点j的(包括与自身)的内积,⊕表示级联操作。

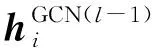
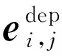
(9)

(10)
2.5 语义融合
由于结构表示模块捕获了依存结构分析器可能存在的错误分词或依存结构信息,导致所得结构编码含有噪声。为有效缓解上述噪声的影响,本文采用注意力机制将句子上下文信息与依存结构信息进行融合得到蕴含两者信息的语义向量表示。
(11)
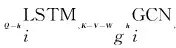
为获得上下文和结构信息的稳定表示,采用多头注意力机制对上下文信息和结构信息表示进行融合,具体计算过程如式(12)、式(13)所示。
(12)
Mhead(Q,K,V)=(head1⊕…⊕headh)
(13)
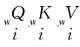
因此由式(14)得到语义融合层的最终输出Mi。
Mi=Mhead(Q,K,V)
(14)
2.6 标签预测
深度神经网络可以捕获长距离的文本信息,但其无法对预测的标签序列添加约束条件。为有效避免上述情况的出现,本文采用CRF对标签序列进行约束和预测。
如图3所示,将融合上下文和结构信息的输出Mi作为状态特征即字节点的状态分数表示,然后直接输入CRF,且经过训练能够学习一个转移分数矩阵,矩阵中的元素为{B-T,M-T,E-T,S-T,O}集合中任意两种标签组合的分数,表示各种组合的可能性。随着模型的迭代训练,CRF可以通过转移分数矩阵逐渐地判断出标签组合是否符合语料中的标注规则,并在预测标签序列时进行规则约束,如标签序列中不可能出现连续的“B-T”或“E-T”。
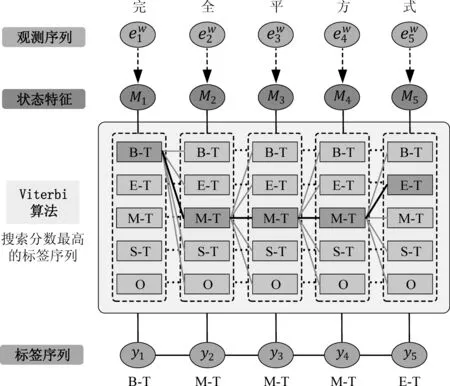
图3 CRF模型预测过程图
综上预测过程可得句子s预测标签序列Y={y1,y2,…,ym}的概率如式(15)所示。
(15)

3 实验结果及分析
3.1 实验数据集及评价指标
实验在我们已构建的中学数学术语数据集[18]上进行,该数据集内容来源于新人教版中学教材、试卷考纲、教案等数学相关文本,总共收集了10 934条句子,且考虑到语料中术语词分布的稠密性,绝大部分句子都包含术语词。再通过编写数据预处理程序对这10 934条句子依次进行句子去重、数据集划分、自动标注等操作,最后对标注结果进行人工检查矫正得到中学数学术语数据集。
在不改变原数据集规模的情况下,我们综合借鉴了最新的百度百科、数学教材以及术语词典[23]对原数据集的术语标注进行改进和优化,由此得到最终的中学数学术语数据集,详细信息如表1所示。另外,我们构建了一个具有复杂语境的实例集,用于验证所提模型的实用性。
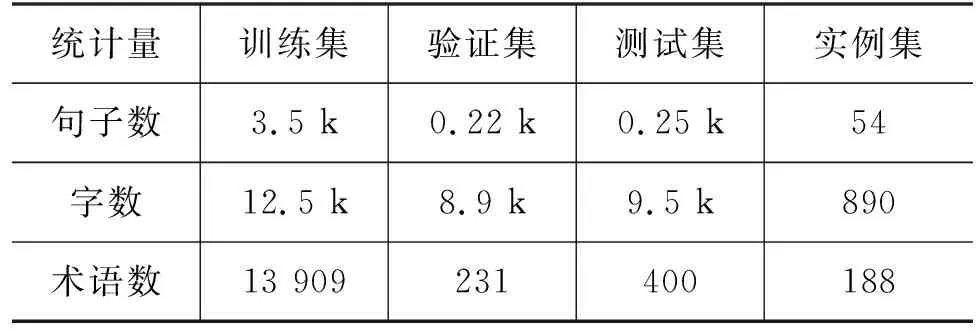
表1 中学数学术语数据集详细信息
标签一致性检验为验证优化前后数据标注的客观性,我们借助第三方标注员的标注结果并采用三种指标来衡量不同标注结果之间的标签一致性。三个指标分别为一致率(C-rate)、肯德尔相关性系数(Kendall)和Fleiss Kappa系数(κ)。其中C-rate表示两种标注结果中相同字符标签占总字符的百分比;Kendall表示两种标注结果的统计依赖性,是一个从0到1范围内的非参数统计量,且Kendall值越接近1表示两个标注结果的相关性越强;Fleiss Kappa是针对多个标注者进行一致性检验的方法,且当κ>0.8 时表示标注员的标注有几乎完美的一致性。
我们将优化前后的数据标注结果分别与第三方标注员的标注结果进行C-rate、Kendall、κ值的计算,且为避免标签不平衡的干扰,在计算κ值时不考虑所有标注者共同标为“O”的字符。图4中的对比结果表明我们优化后的标注结果与第三方标注员的标注结果更为贴切,其中C-rate、 Kendall、κ值较优化前分别高出2.48%、11.44%、25.72%。特别地,对于优化后κ=0.9960>0.8,表示我们的标注结果与第三方标注员的结果有着几乎完美的一致性。
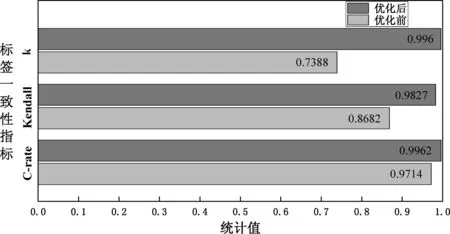
图4 数据优化前后的标签一致性结果对比图
评价指标选取实验采用准确率(Accuracy,Acc.)、精确率(Precision,P)、召回率(Recall,R)以及F1-score(F1)值作为模型算法的评价指标。为保证实验的可靠性和减少噪声的干扰,我们对所提模型和其他基准模型都进行了3次重复实验,并取四种指标的平均值作为最后的验证结果。
3.2 实验参数设置
实验使用的深度学习模型框架为PyTorch,使用的中文预训练模型中词向量嵌入维度为768,BiLSTM的神经元数设为256,依存标签嵌入向量的维度设为768维,经过线性层处理后的ATT-GCN隐层输出为200维。ATT-GCN的迭代层数L为1,多头注意力机制的头数h为5。为防止在训练过程中模型过拟合,设置Dropout的值为0.4,初始学习率设为0.001。
3.3 对比实验及结果分析
3.3.1 基准对比实验
为验证所提模型的有效性,本文选择以下模型作为基准方法:
BERT-BiLSTM-CRF吴俊等[15]事先利用BERT预训练模型获取具有丰富语义的中文字词向量,并结合BiLSTM-CRF实现了中文专业术语抽取。
Lattice-LSTMZhang等[12]提出的一种综合编码词级特征和字符特征的LSTM模型,该模型基于外部词典匹配,对文本序列中所有潜在单词进行编码,并将得到的词级特征编码融入处理对应字符特征的LSTM编码单元。
BERT-BiGRU-CRFGRU(Gate Recurrent Unit)与LSTM性能相近但参数更少,Lample等[24]通过构建BiGRU-CRF模型解决了英文命名实体识别任务。
LLA-CRF华鑫等[18]引用了Lattice-LSTM并提出了增强标签预测的标签注意力层,解决了中学数学部分多义术语词和嵌套术语词的抽取问题。
LLA-CRF在Lattice-LSTM 的基础上增加了标签注意力层,更好地学习了序列与标签的相关性。由表2可见,在Acc.、P、F1值上超过了Lattice-LSTM。而BERT-LLA-CRF较LLA-CRF性能又有着大幅度的提升,这说明BERT能够大大提高传统深度学习模型的性能。进一步来看,在基于BERT的术语抽取模型中,BERT-BiGRU-CRF和BERT-BiLSTM-CRF都是基于字实现的序列标注模型,虽然两者可以避免序列分词错误对模型性能的影响,但其向量表示欠缺更深层语义的表征,如依存结构信息。BERT-LLA-CRF在融入Lattice LSTM的词级语义表示基础上增设了计算序列与标签直接相关性的注意力机制,使模型更关注术语词的抽取,但BERT的引入反而干扰了词级信息在LSTM中的表示,并导致注意力层学习了序列与标签之间错误的相关性。从表2可以看出,Acc.、P、F1值较BERT-BiLSTM-CRF有所下降。而本文所提的DSL-ATRE模型利用图神经网络捕获了句子的依存结构信息,并设计语义融合层来减少融合依存结构信息时可能存在错误分词和依存结构分析的干扰,实验结果也表明DSL-ATRE在四个指标上均优于基准模型BERT-BiLSTM-CRF,其中P、F1值分别提升了2.21%、1.22%。
此外,表2中 DSL-ATRE*表示未引入依存标签注意力机制对输入的依存关系矩阵进行去噪,虽然模型性能相比DSL-ATRE有所下降,但P、F1值还是比基准模型BERT-BiLSTM-CRF分别高出1.99%、0.44%,这进一步表明所提框架是有效的。
3.3.2 消融实验
为进一步验证所提方法的有效性,我们在优化后的中学数学术语数据集上构建了两个消融实验,并将BERT-BiLSTM-CRF作为基准进行对比: ①移除了ATT-GCN模块,直接将BERT字嵌入输入语义融合模块中与BiLSTM隐层输出进行多头注意力机制计算; ②移除了语义融合模块,直接将BiLSTM与ATT-GCN的输出进行级联。
消融实验对比结果如表3所示,实验结果表明,在移除ATT-GCN模块后,模型没有融入依存结构信息,只是以Attention机制的形式对BERT字嵌入向量进行残差计算,这样得到的字向量语义依旧不足,导致此时模型的整体指标较基准略低。
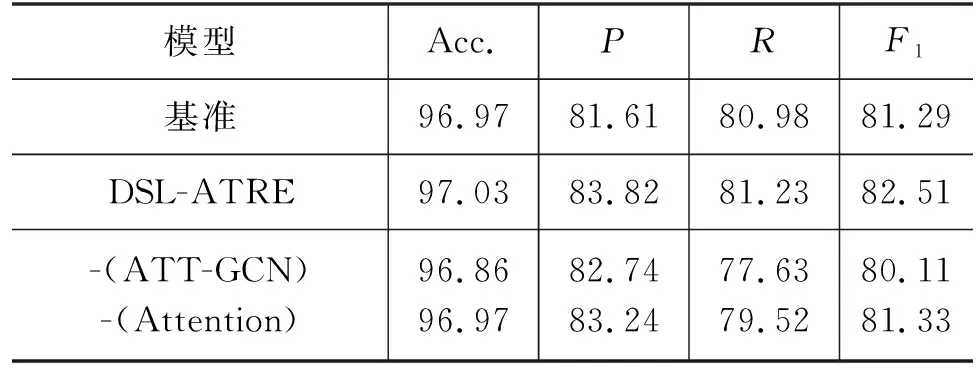
表3 消融实验结果 (单位: %)
对于去除语义融合模块后的模型在P值上较基准提升了1.63%,这表明ATT-GCN输出与BiLSTM简单的级联确实也可以丰富字向量的语义表示信息,但F1值只提升了0.04%,这说明在去除语义融合模块后,模型在最后的标签预测阶段受到了错误信息的干扰。
而本文将语义融合模块与ATT-GCN共同考量,实现了一个既可为字向量丰富句法语义也可缓解错误分词或依存结构的中学数学术语抽取模型,实验结果也表明所提的DSL-ATRE模型在F1值上较两个消融实验方法分别提升了2.40%、1.22%。对于中学数学表达中一些极简句型,在分词任务中会出现错误的分词结果,从而产生无效的依存结构信息,这些噪声信息会被本文引入的去噪机制事先削减,而残余噪声会在语义融合模块计算上下文信息与依存结构信息的相关性权重时被减弱。如图5所示,语义融合模块依据上下文语境增强“成”与“线”的谓宾关系,赋予蕴含了“动成线”或“成线”等错误成词的结构信息低权重,从而达到在不同分词情况下成功抽取“点”和“线”两个单字术语的目的。这也进一步表明了模型在含有噪声的依存结构学习中有较好的鲁棒性。
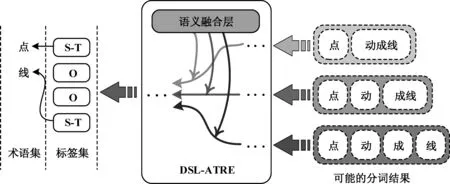
图5 不同分词环境下的DSL-ATRE术语抽取过程
3.3.3 实例抽取对比实验
为验证所提方法的实用性,我们在测试集上分别对基准模型BERT-BiLSTM-CRF和DSL-ATRE进行实例术语抽取,如表4展示了部分实例的嵌套术语抽取结果。分析发现DSL-ATRE模型对多重嵌套术语的抽取能力优于基准模型,比如表4中的“无限不循环小数叫无理数”,基准模型忽略了“无限”与“小数”之间的依存关系导致错误抽取。而DSL-ATRE模型由于采用了图神经网络捕获句子的依存结构信息,有效捕获了“无限”“不循环”“小数”三者间的关联信息,从而实现准确抽取。但由于数学语言的精简性,一些实例在基准模型和DSL-ATRE上的抽取结果会表现为“过度嵌套”,如模型从“对立事件概率之间的关系”中抽取出了“对立事件概率”的错误结果。

表4 部分实例的嵌套术语抽取结果
此外,我们在由复杂语境例句构成的实例集上进行了术语抽取实验,结果如表5所示。实验结果表明在一些复杂语境下DSL-ATRE模型抽取术语的完整性和准确性均优于基准模型。其中复杂语境常常由中文存在的省略词造成,如表5中第三个实例,“等腰梯形”与“上底”之间以及“下底”与“中点”之间都省略了结构助词“的”“上底”之后也省略了“中点”,这种省略形式易导致基准模型对句子语义解析混乱,即将“下”错误地理解为方位词,将“底中点”错误解析成术语。同时,这类例句由于分词结果不佳导致在依存结构分析阶段产生较多的无效依存关系,即第三个实例在真实的依存结构分析结果中包含“梯形”和“下底”之间错误的并列关系,“下底”作为形容词修饰“点”的关系,等,这易导致一些基于依存结构分析的模型忽略“上底”或无法完整抽取“中点”的情况,这是一种缺乏对上下文语义信息深层考量的表现。而DSL-ATRE模型综合考量了依存结构信息和上下文信息的重要程度,即模型融入“梯形”“和”“下底”作为分词结果中独立属性以及依存关系信息的同时,通过借助上下文信息,不仅增强了位于“梯形”与“和”之间的“上”“底”共同构成并列实体的可能性,还强化了“下底”对“中点”在语义上的修饰关系,从而正确预测出了“上底”“下底”“中点”才是实例所包含的真正术语。这进一步表明ATT-GCN与语义融合模块的组合可提升模型术语抽取的性能和鲁棒性。
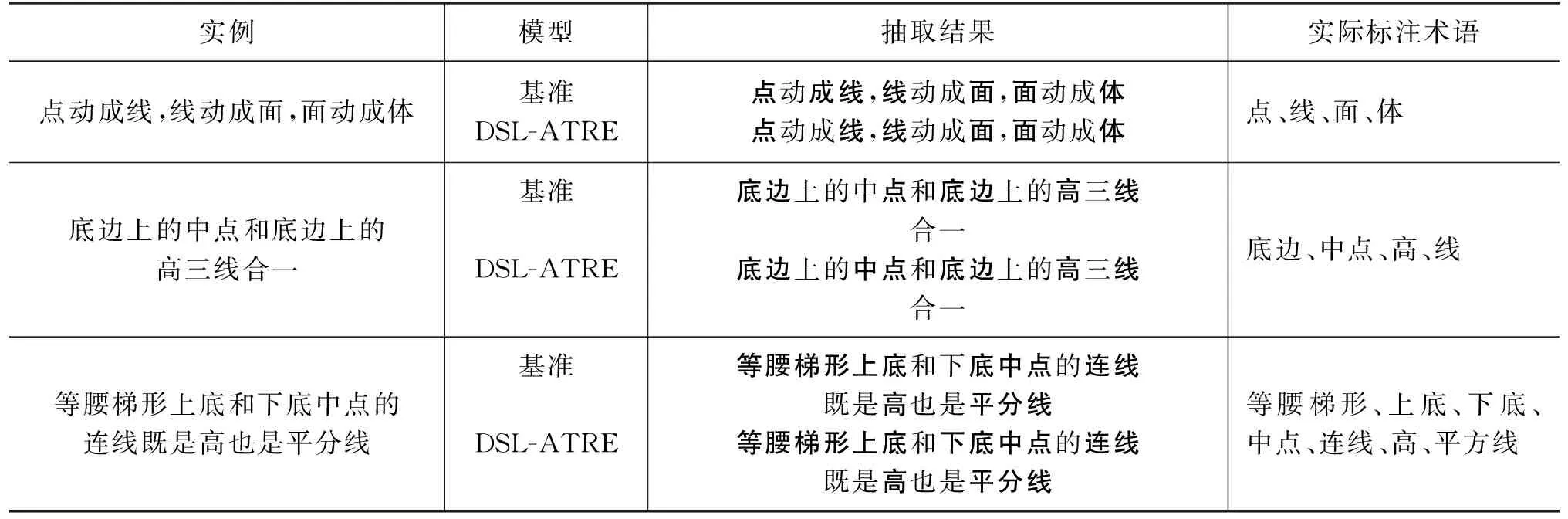
表5 基于复杂语境的部分实例术语抽取结果
4 总结与展望
针对中学数学术语抽取的难点,本文提出了一种基于依存结构学习的中学数学术语鲁棒抽取模型,该方法利用图神经网络模型捕获依存结构信息,并通过注意力机制融合结构信息和上下文信息以实现融入依存结构信息的同时缓解错误分词或依存结构的影响。在中学数学术语语料集上的实验结果表明,本文所提模型性能优于BERT-BiLSTM-CRF。进一步,我们打算提出针对中文依存关系矩阵更优的构造方式,同时考虑以多模态的形式融入与文本相关联的符号、公式和图片所蕴含的信息。
猜你喜欢
中学数学杂志(2022年6期)2022-11-18
中学数学杂志(2022年6期)2022-11-17
中学数学杂志(2022年6期)2022-11-14
中学数学杂志(2022年6期)2022-09-05
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
外语学刊(2011年3期)2011-01-22
