
基于傅里叶描述子的吸烟行为检测方法*
2023-10-25 01:12:24赵鉴福梁金幸史宝军
传感器与微系统 2023年10期
赵鉴福,梁金幸,史宝军,3
(1.河北工业大学 省部共建电工装备可靠性与智能化国家重点实验室,天津 300401;2.河北工业大学 机械工程学院 河北省机器人感知与人机融合重点实验室,天津 300401;3.国家技术创新方法与实施工具工程技术研究中心,天津 300401)
0 引 言
石化厂区内的吸烟行为是引发火灾、爆炸事故的重要原因之一,因此吸烟行为检测作为一种安全监测方法越来越受到重视。与火灾事故发生产生的滚滚浓烟不同的是,吸烟产生的烟雾表现为一种半透明的烟雾。传统烟雾传感器[1]只有烟雾接触到传感器且烟雾浓度到达设定阈值时会发出警报,传感器普遍布置于屋顶或倾斜墙壁,对吸烟产生的烟雾不敏感。随着计算机视觉的发展,基于视频图像的烟雾检测成为可能。烟雾的扩散运动规律可以有效区分烟雾和非烟物体,姚太伟等人[2]通过分析烟雾的运动规律,采用分块和背景自适应的方法建立烟雾的颜色模型。Chen T H等人[3]分析烟雾的三原色(RGB)三通道图形信息,发现烟雾在三通道的对应像素之间像素值差几乎可以忽略,利用RGB 颜色模型可以区分部分烟雾。Tian H 等人[4]利用混合图像模型区分烟雾与背景,提出一种优化算法求解烟雾的不透明度。Yuan F N等人[5]提出了一种基于积分图像的累积运动模型,该模型能有效减少人工灯光和非烟物体的干扰。在此基础上,进一步研究了噪声和非烟物体杂乱运动干扰的消除技术[6]。张洁等人[7]提出了一种结合烟雾纹理特征与轮廓光流失量的烟雾识别方法,对可疑区域进行分析,提高检测效率。但是,不同的光照、气象条件对获取的烟雾视频质量产生了较大的影响,进而影响了吸烟检测的精确率。
针对上述情况,以烟支为检测对象的目标检测技术被应用于吸烟行为检测中,相比烟雾特征,烟支是一种相对稳定的吸烟行为特征。由卷烟机生产的烟支分为不加过滤嘴与加过滤嘴的两种,中国市面上的大多数过滤嘴烟支的规格为长度84 mm,直径7.8 mm,它包括19 mm 的过滤嘴、65 mm的烟支长度,不加过滤嘴卷烟烟支的长度70 mm。Wu W C等人[8]提出了一种基于人脸分析的吸烟行为检测方法,在YCbCr颜色模型中确定人嘴所在区域,在HSV 颜色模型分割烟支并判断是否为吸烟行为。程淑红等人[9]提出了一种基于人脸分析的公共场所吸烟行为检测方法,构建了基于多任务级联卷积神经网络(multi-task cascaded convolutional neural network,MTCNN)和MobileNet-V1 的吸烟行为检测模型,在自建数据集中有较好的准确率。韩贵金等人[10]提出了一种基于深度学习的烟支检测技术,改进特征提取方案,将浅层局部特征与深层全局特征进行融合,有效降低了烟支目标检测的漏检率,提升了检测效率。但是,在吸烟行为中,烟支通常与人体手部的运动关联,且深度学习的应用对硬件要求较高。
针对上述问题,本文提出了一种基于傅里叶描述子的吸烟行为检测方法。首先,基于Azure Kinect传感器获取的人体关键点信息,动态调整手部目标区域。获取手部区域后,在YCbCr颜色模型上进行烟支的分割,分析并提取烟支的傅里叶描述子形状特征,然后利用支持向量机(SVM)对提取的特征进行分类。最后,自建行为检测数据集验证方法的可行性。
1 手部目标区域的获取
图1为获取手部目标区域的流程,首先,由RGB[11]相机和深度相机分别获取RGB图片和人体关键点信息,并制定手部目标区域获取规则;然后,通过像素与坐标的转换将深度图像坐标系与RGB 图像坐标系对齐;最后,分割RGB图片获取手部目标区域。

图1 获取手部目标区域流程
1.1 手部目标区域获取规则
图2为Azure Kinect传感器检测手部目标区域结果的示意,获取的人体手部区域关键点分别为图示点A,B,O。以O为中心,2OB +60 mm的经验值为边长的矩形为待检测的手部目标区域。

图2 检测手部目标区域结果示意
1.2 坐标系变换
由Azure Kinect Body Tracking SDK 获取人在深度图像坐标系下关键点位置坐标信息,在深度图像坐标系中,点以[X,Y,Z]坐标三元组的形式表示,单位为mm。图3 给出了RGB相机坐标系{A}与深度相机坐标系{B}之间的关系。

图3 深度相机与RGB相机坐标系间关系
由张氏标定法获取Azure Kinect传感器RGB相机的内参为MRGB,TOF 深度相机的内参为MD,深度相机相对于RGB相机的旋转矩阵为R,平移矩阵为T,内参矩阵分别为
式中 fx,fy为相机的焦距,u0,v0为相机光轴相对于像素坐标系的偏移坐标。
在深度图中的一点PD,其在深度图像坐标系中的坐标为(uD,vD,DepD),则PD在RGB图像坐标系中的映射点为
棋盘格相对于RGB 相机和深度相机的旋转矩阵和平移矩阵分别为
与式(1)对应系数相同得到旋转矩阵R 和平移矩阵T为
RGB像素坐标中对应点Pf的坐标为(uf,vf),则RGB相机图像坐标系与像素坐标系的转换方程为
得到(uD,vD)与(uf,vf)的关系,完成深度图中像素点到RGB像素点的转换。
1.3 目标区域的获取
得到RGB相机坐标系下的目标区域后,分割获取的RGB图片,图4为图片分割得到的RGB图像的手部目标区域,采用Visual Studio 2019 配置Azure Kinect SDK 所需环境,OpenCV环境为3.4.1,编程实现手部目标区域的获取。

图4 获取目标区域示例
2 预处理与烟支形状特征提取
2.1 待检测目标的分割
YCbCr是在视频标准研制过程中被提出的,其中,Y 为亮度,Cb,Cr为颜色。YCbCr 颜色模型压缩了数据量,在计算机系统中应用较多。文献[12]提出了YCbCr 颜色模型,结合本文数据集修改烟支分割阈值:CbY =Cb-128,CrY =Cr-128,|CbY-CrY |>25,y -|CbY |-|CrY |≥95。其中,CbY与CrY为计算中间值。
图5给出了使用修改后上述阈值的不同颜色模型的分割结果。可以看出,HSV颜色模型分割的结果引入较多的干扰,YCbCr颜色模型分割的结果最大程度地保留了待检测目标的形状特征,所以本文选择YCbCr 颜色模型分割手部目标区域。

图5 不同颜色模型的分割效果
2.2 分割图像后处理
图6分别给出了YCbCr颜色模型分割、高斯滤波、均值滤波和中值滤波的结果。由图可以看出,高斯滤波和均值滤波不能有效去除原图中的噪点,并且使图片中的形状特征模糊,但中值滤波可有效去除原图中的噪点,并保留图片中的形状特征,所以本文选择中值滤波。

图6 不同滤波方法的结果比较
2.3 形状特征与SVM分类器的训练
2.3.1 目标区域的傅里叶描述
首先,采用Canny算子[13,14]对目标区域进行边缘检测;然后,将轮廓上的K 个像素点的二维坐标s(k)=[x(k),y(k)],k =0,1,2,…,K -1,转换为复数表示,即s(k)=x(k)+jy(k),j为虚数单位。这种表示方法将二维轮廓信息转换为一维信息,降低了轮廓特征维度,式(7)给出了s(k)的离散傅里叶变换(DFT)
式中 u =0,1,2,…,K -1,a(u)称为轮廓的傅里叶描述子[15]。
由于图片轮廓像素点数量多且各不相同,造成提取特征维数多和特征维数不同的问题,选用不同长度的傅里叶描述子重构图像,用最少的傅里叶描述子完整描述形状特征。图7给出了不同维数的傅里叶描述子重构轮廓的示例,自左向右依次为10,20,30,40,50 维傅里叶描述子的重构示例。
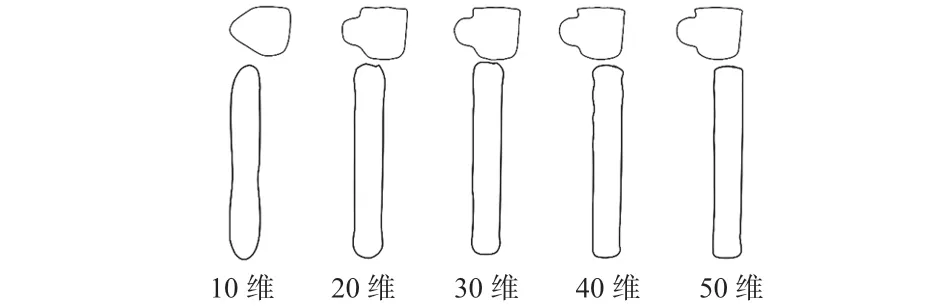
图7 不同维数傅里叶描述子重构轮廓示例
由图7可以看出,傅里叶描述子的维数越低,特征表达轮廓的形状越粗略;维数越高,特征表达轮廓的形状细节越丰富。所以,选取可以表征轮廓且维数较少的30 维特征描述子作为分类器的输入。
2.3.2 基于SVM的烟支分类器构建
SVM[16~18]是一类有监督的机器学习分类器,其本质是将特征向量映射为空间中的点,求解超平面实现间隔最大的划分不同类别的点。划分的超平面应具有抗干扰强、泛化性优、鲁棒性好的特点。本文采用LibSVM[19]工具箱,对目标区域提取的傅里叶描述子进行二分类,并采用交叉验证的方式,选择最优的参数训练。
3 实验与结果分析
3.1 实验平台与自建数据集
本文实验采用英特尔酷睿i9—10900KF CPU、NVIDIA GeForce RTX 2080 Ti显卡、1TB +2TB双硬盘、32 GB运行内存、Windows10操作系统的计算机作为处理设备。目前,没有公开的吸烟行为数据集,本文使用Azure Kinect传感器录制吸烟行为与其他行为的待检测视频并分帧处理,另外在网络中搜集相关的吸烟行为图片。自建数据集共500 张图片,其中,训练集355 张、验证集145 张。图8 所示为数据集中的部分正负样本图片。

图8 数据集中部分正、负样本
3.2 方法流程
图9给出了吸烟检测流程。

图9 吸烟检测流程
3.3 实验结果
实验结果评价指标[20,21]使用准确率A(accuracy)、精确率P(precision)和召回率R(recall),定义分别为
式中 TP为吸烟视频帧正确分类的帧数,TN 为非吸烟视频帧正确分类的帧数,FN 为吸烟视频帧错误分类的帧数,FP为非吸烟视频帧错误分类的帧数。
分别对数据集中的图片使用文献[8]中的烟支分割颜色模型和本文提出的分割模型进行烟支颜色分割处理。然后提取傅里叶描述子形状特征特征并分别使用反向传播(back propagation,BP)神经网络、SVM 作为分类器,在自建数据集上进行吸烟检测实验。实验结果与识别效果评价指标如表1所示。

表1 实验结果与识别效果评价指标
文献[8]中首先检测人嘴区域,在本文数据集中烟支与人手一起移动,所以只采用文献[8]中的颜色模型来分割相同数据集,并与其他方法比较结果。实验结果表明,提取手部目标区域的傅里叶描述子和SVM 分类器的方法表现最优,评价指标均达80%以上,其中,A为86.21%,P为93.33%,R为82.35%。
4 结 论
针对目前烟雾传感器与视频烟雾智能识别受外界环境影响较大的问题,本文提出了一种以烟支为检测对象的吸烟行为检测方法。首先,提出了一种基于Azure Kinect传感器的手部目标区域获取方法;然后,在YCbCr颜色模型下修改颜色阈值,并提取基于傅里叶描述子的形状特征;最后,利用SVM分类器实现吸烟行为的分类判断。为验证方法的有效性,建立行为检测数据集,本文提出的方法在数据集上表现良好。由于数据集图片的数量与质量对最终的检测结果有较大的影响。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31 09:48:02
中国新技术新产品(2022年24期)2022-03-24 03:07:32
装备制造技术(2021年12期)2021-04-23 01:41:14
湖南文理学院学报(自然科学版)(2020年4期)2020-11-25 00:42:08
数学物理学报(2019年2期)2019-05-10 11:32:38
测控技术(2018年7期)2018-12-09 08:58:26
西南农业学报(2016年4期)2016-05-17 05:42:15
舰船科学技术(2016年1期)2016-02-27 15:39:21
实用手外科杂志(2015年4期)2015-08-27 01:54:14
电测与仪表(2015年5期)2015-04-09 11:30:44
