
基于注意力机制的语义增强损失函数与全景分割
2023-10-24 01:37:54郑立冬滕书华谭志国元志安马燕新
激光与红外 2023年9期
郑立冬,滕书华,谭志国,元志安,马燕新
(1.河北省迁安市职业技术教育中心,河北 迁安 064400; 2.湖南第一师范学院 电子信息学院,湖南 长沙 410205;3.国防科技大学 气象海洋学院,湖南 长沙 410073)
1 引 言
图像分割技术是计算机视觉领域重要的研究方向。传统分割算法仅仅从人类的直观视觉特征出发,针对图像的颜色分布、纹理特征、点特征来进行分割和分类,其分割效果极大受限于不同场景。随着深度学习的推广和发展,图像分割进入全新的发展时期,Facebook AI研究院[1]于2018年提出全景分割的概念,并给出相关基准。相比于传统的语义分割和实例分割算法,全景分割任务需要在对图像像素点分类的同时区分不同实例并给出识别号。全景分割将语义和实例分割的优点进行了有效结合,既可以得到图像所有物体的分类结果,又可以区分不同物体实例个体,即同时实现了图像背景语义信息和前景实例对象分割的同时处理。
全景分割任务主要分为三个部分:特征提取、语义与实例分割分支和信息融合。通过对输入图像进行特征提取操作,为后续分割过程提供特征信息。主干网络ResNet[2]作为经典的特征提取网络模块,通过残差结构,在层数增加时依旧可以提升网络收敛性,为高级语义特征提取和分类提供了可行性。SENet[3]通过加入注意力机制,得到特征重要程度与特征之间的连接关系,使模型更加关注信息量大的特征。语义与实例分割分支分别进行语义分割和实例分割,提供语义类别和实例信息,常用网络结构为PSPNet[4]和Mask R-CNN[5]。信息融合部分将语义类别和实例信息进行融合,得到最终的全景分割结果。在融合过程中,主要有启发式算法和全景头部(Panoptic Head)两种方法,启发式算法可以在有限时间给出相对不错的结果,但全景头部结构可以得到与语义和实例分割结果一致性较高的融合结果,例如UPSNet[6]与OCFusion[7]算法。目前的全景分割算法大多聚焦于提高所有种类的平均分割精度,忽略了不同任务对于不同语义分割结果的需求和重视程度不同,进而导致很多全景分割的精度不理想,实用性不强。本文针对不同的语义类别,提出一种基于注意力机制的语义增强损失函数和全景分割方法,以提高对重要语义类别的分割精度,进而提高分割结果的实用性。
2 算法描述
2.1 语义增强损失函数
全景分割的损失函数通常由语义分割子分支损失函数和实例分割子分支损失函数结合构成:
L=αLsemantic+βLinstance
(1)
式中,Lsemantic为语义分割子网络损失函数;Linstance为实例分割子网络损失函数;α和β为权重系数。该传统损失函数针对所有语义种类给出了相同的损失代价,导致不同任务中重要性较高语义信息准确性不高。为解决该问题,本文提出一种基于注意力机制的语义增强损失函数,来区分不同重要性的语义信息,并提高重要语义信息的分类精度。本文仍然采取分开计算损失函数的结构:
L=λ1Lsemantic+λ2Linstance
(2)
其中,λ1为语义分割权重系数;λ2为实例分割权重系数。因为两个分支的损失设计具有不同规模和规范化策略,因而通过加权来进行不同损失校正。
在全景分割中,语义分割是决定语义分类的关键因素,所以主要对Lsemantic进行重新设计。常用于语义分割的损失函数有Cross-Entropy Loss[8]和Focal Loss[9],Focal Loss具有更高的准确率,Cross-Entropy Loss则具有更高的召回率,本文选用Cross-Entropy Loss来作为损失函数基准。Cross-Entropy Loss表示实际输出与期望输出之间的距离,用以刻画预测值与真值相似度,交叉熵越小,两个概率分布越接近,传统定义为:
(3)
其中,qi,j和pi,j都是长度为C(分类总数)的one-hot编码;qi,j为(i,j)处的真值向量,正确语义标签位置标注为1,其他标注为0;pi,j为(i,j)处的预测向量,每个数组元素对应相应分类预测概率;H和W分别为图像的高和宽。
对语义分割来说,交叉熵损失并不理想。因为对一张图来说,交叉熵损失是每一个像素损失的和,它并不鼓励邻近像素保持一致。此外,交叉熵损失无法在像素间采用更高级的结构,所以交叉熵最小化的标签预测一般都是不完整或者是模糊的,它们都需要进行后续处理。
在不同任务需求中,不同物体的语义信息往往重要性程度不同,所以需要对分类的语义信息进行重要程度的划分。如图1所示,本文在分割过程中加入注意力机制,将语义种类划分为四个等级,重要程度从R4到R1依次降低。其划分依据以回环检测任务为例:相比于动态物体(R2和R1),静态物体(R4和R3)能够提供更多的可靠鲁棒的参考信息;静态的实例物体(things,R4)又比静态背景(stuff,R3)更具有参考价值和路标功能。动态物体中,相较于车辆等物体(部分情况为静止,R2),人和动物(R1)属于高频移动物体,且出现频次较高,属于干扰信息。

图1 语义重要性等级划分示意图
根据分组定义向量V1、V2、V3和V4,分别储存4个分组中物体分类的交叉熵损失。例如第i组、第j个像素的损失值定义为:
(4)
式中,Oc,i,j为图像(i,j)处输出c分类可能性的张量;qc是第c个元素为1的one-hot编码。同样,定义W1、W2、W3和W4四个向量来记录4个分组中物体分类对应的损失权重,利用损失权重来有效抑制分类失衡问题。下面给出Wi的定义为:
(5)

利用加权操作来调整学习速度之后,设计重要性矩阵Mt来完成对不同语义信息的损失函数设定,其定义方式如图2所示。

(a)M1 (b)M2 (c)M3
重要性矩阵Mt主要有三部分:M1、M2和M3,Mt的大小为H×W。与图1一致,矩阵中第1行区域代表R1、第2行区域代表R2、第3行区域代表R3、第4行区域代表R4。矩阵中,1代表重要性高,0代表重要性低。例如R4所包含的1数量最多,代表R4包含的物体分类最重要。基于Mt定义重要性系数θ(Mt)(t=1,2,3)定义为:
(6)
式中,E为全1矩阵(幺矩阵);γ∈+为调参,本文实验取0.5,G为输出Oc,i,j在图像(i,j)处真值分类标签对应的预测概率;⊙运算表示矩阵对应元素相乘。γ取值决定了θ(Mt)的大小。当γ放大,输出G与Mt之间的差距便会扩大,尤其当Mt=1时。
语义增强损失函数的设计原则是提高对重要物体损失偏差的敏感性,利用图3所示结构来计算损失值。
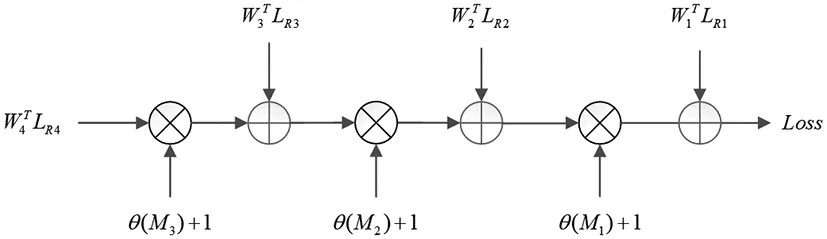
图3 损失函数计算结构
R1所在分组的重要性最低,设置R1组的重要性系数为1;R2组的重要性系数为θ(M1)+1;R3组的重要性系数为(θ(M1)+1)(θ(M2)+1);R4组的重要性系数为(θ(M1)+1)(θ(M2)+1)(θ(M3)+1)。最后,语义分割损失函数计算公式为:
(7)
实例分割子分支的损失函数设计由三部分组成:分类损失Lclass、边界损失Lbox和掩码损失Lmask。Lclass和Lbox由采样的感兴趣区域(Region of Interest,RoIs)数量归一化[10],Lmask通过前景RoIs数量归一化[11]。给出实例分割子网络的损失函数Linstance定义为:
Linstance=Lclass+Lbox+Lmask
(8)
最终,语义增强损失函数定义为:
L=λ1Lsemantic+λ2(Lclass+Lbox+Lmask)
(9)
通过调整权重系数λ1和λ2,可实现对语义和实例子分支的不同侧重,同时也可以分别对两个独立任务模块进行单模型训练,且计算量减半。当设计λ1=0,即实例分割单模型训练;当λ2=0,即语义分割单模型训练。
2.2 全景分割网络结构
本文构建全景分割的思路是利用特征金字塔网络(Feature Pyramid Network,FPN)[12]来修改Mask R-CNN,其结构思路如图4所示:完成全景分割任务的网络结构需满足如下条件:分辨率足够高以解析微小结构;语义编码足够多以准确预测物体分类;具备多尺度信息,以在不同分辨率上进行预测。FPN(初始用于物体检测)具备高分辨、丰富的多尺度特征提取的作用,因此可以通过附加语义分割网络来完成全景分割任务。如图4所示,FPN由两部分组成:多种空间分辨率特征的标准网络(本文应用ResNet[2])和一个带有横向连接的自上而下的轻型通道。自上而下的通道从最深层网络开始,逐步进行上采样,同时从自下而上的路径获取更高分辨率的特征转换。
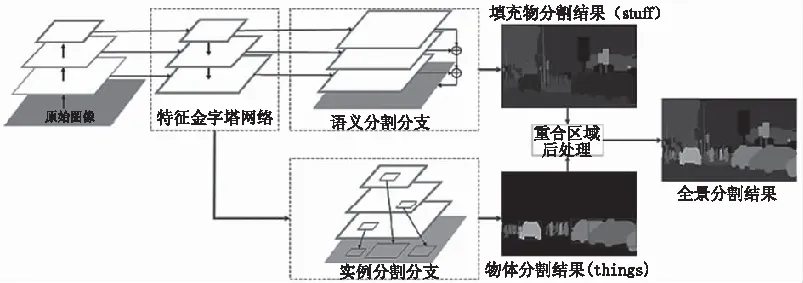
图4 全景分割网络示意图
FPN结构可以与基于区域的物体检测器直接相连(尤其是相同维度金字塔结构)。Faster R-CNN[10]在不同金字塔层级上执行RoIs汇集,并应用共享网络预测每个区域的精炼框和分类标签。如图5所示,使用Mask R-CNN来获得实例分割结果,通过添加FCN(Full Convolutional Networks)分支来扩展Faster R-CNN[10],以预测候选区域的二进制分割掩码。
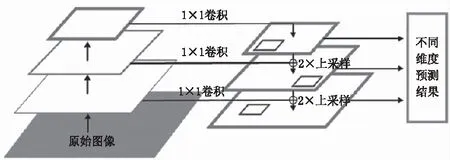
图5 实例分割分支示意图
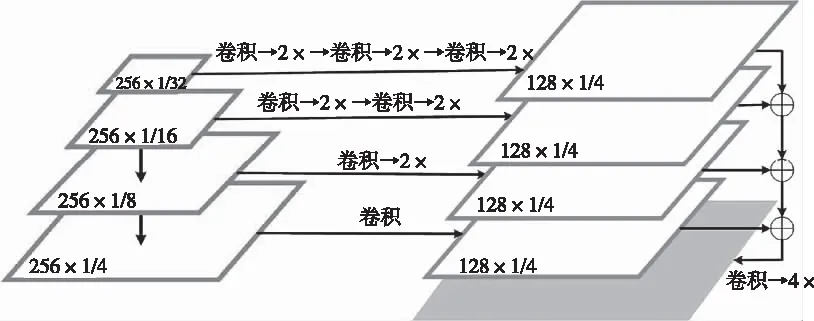
图6 语义分割分支示意图
为了利用FPN特征来获取语义分割结果,利用Panoptic FPN[13]中提出的一种设计方式,将FPN的所有金字塔等级的特征信息合并。 FPN最顶层为1/32分辨率比例,利用三次上采样操作得到1/4分辨率比例的特征图,其中每个上采样操作由3×3卷积、群体规范、ReLU和2倍双线性上采样组成。
在分辨率比例分别为1/16,1/8和1/4的FPN上重复此操作。每层的上采样结果是相同的1/4分辨率比例的特征图,之后按元素求和。最终加入4倍双线性上采样和1×1卷积来获取与原始图像相同分辨率的像素分类标签。除了填充物(stuff)类之外,在这个分支中增加一个特殊的“其他”类,以作为物体对象的额外像素点输出,可以避免强行预测像素点的填充物种类,造成误判。
本文采用的FPN配置每个尺度有256个输出通道,语义分割分支减少通道数至128。对于FPN之前的主干网络,使用批量标准(Batch Norm,BN)[14]在ImageNet[15]上预训练ResNet[2]模型。在微调时,用固定通道仿射变换来代替BN。
全景输出格式[16]需要为每个图像像素分配类标签和实例ID(stuff类不具备实例ID)。为避免网络结构中的实例和语义分割分支输出重叠问题,加入一种后处理方法,操作方式如下:
(1)不同实例重叠,据置信度得分进行取舍;
(2)语义和实例分割结果重叠,以实例结果优先;
(3)删除标注的“其他”类。
2.3 基于注意力机制的语义增强损失函数与全景分割方法步骤
下面给出本文基于注意力机制的语义增强损失函数与全景分割方法步骤如下:
(1)按重要程度将语义种类划分为若干语义等级,并利用预设初始语义损失函数对若干语义等级加权学习获得语义加强损失函数;
(2)利用预设重要性矩阵确定目标语义分割损失函数;
(3)基于预设权重系数对预设实例分割损失函数以及目标语义分割损失函数进行处理得到目标语义增强损失函数;
(4)利用目标语义增强损失函数对原始图像处理得到实例分割结果以及语义分割结果;
(5)根据预设重叠结果剔除规则对实例分割结果以及语义分割结果进行处理,输出最终目标分割结果。
3 实验及结果分析
3.1 实验数据与评价指标
为对算法进行系统的测算,采用COCO数据集作为全景分割训练和测试的数据集。COCO数据集提供80类语义种类,基本覆盖生活中常见物体的学习和分类。同时该数据集也包含了不同分辨率、不同视角和光线下的数据。
全景分割实验中,通常使用6种评价指标:平均准确度(Average Precision,AP)、平均召回率(Average Recall,AR)、交并比(Intersection-over-Union,IoU)、分割质量(Segmentation quality,SQ)、识别质量(recognition qulity,RQ)、全景分割质量(Panoptic quality,PQ)。上述评价指标的相关定义如下:
3.1.1 平均准确度
平均准确度(AP)用来反映语义种类的分割准确程度,其定义为:
(10)
式中,TP为真阳性数值(true positives),表示预测正例样本正确的个数;FP为假阳性数值(false positives),表示预测正例样本错误的个数。AP越高,说明模型的分割效果越好。
3.1.2 平均召回率
平均召回率(AR)用来反映语义种类的真正例召回比例,其定义为:
(11)
式中,FN为假阴性数值(false negatives),表示预测反例样本错误的个数。AR越高,说明模型的分割效果越好。
3.1.3 交并比
交并比(IoU)是模型对某一类别预测结果和真实值的的交集与并集比值,其定义为:
(12)
在检测过程中,当IoU大于阈值,则判定检测结果为正,反之判错。一般约定,IoU=0.5是阈值,loU越高,说明模型的分割效果越好。
平均交并比(mIoU)是模型对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果,其定义为:
频权交并比(FWIoU)是根据每一类出现的频率设置权重,权重乘以每一类的IoU并进行求和,其定义为:
3.1.4 分割质量
分割质量(SQ)指标用来测评语义分割网络,是匹配实例中常用的平均IoU度量。其定义为:
(13)
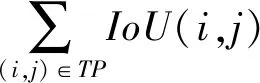
3.1.5 识别质量
识别质量(RQ)用来测评实例分割子网络,即计算全景分割中每个实例物体识别的准确性。其定义为:
(14)
3.1.6 全景分割质量
全景分割质量(PQ)指标联合分割质量参数和识别质量参数来对整体全景分割网络框架进行评价,其定义为:
(15)
3.2 全景分割实验结果
首先讨论梯度平衡的损失系数(公式9)对分割质量的影响。实验过程中,因为语义分割子网络是语义增强损失函数的主要作用点,所以将实例分割子网络系数λ2设置为1,通过测试不同语义分割损失函数系数λ1来进行分割预测,测试结果如表所示。PQth表示物体(things)的分割质量,PQst表示填充物(stuff)的分割质量。从表1可以看出,λ1过大或过小,网络平衡状态都会被打破,导致两个子网络学习效率均降低。另外当λ1过大,例如λ1=0.6时,填充网络传入基础网络的梯度幅值过大,此时RQ=50.94,大大降低了实例分割子网络的预测准确性。该实验表明,当λ1=0.4时,实例与语义分割网络处于最佳平衡位置,分割质量达到43.02 %。
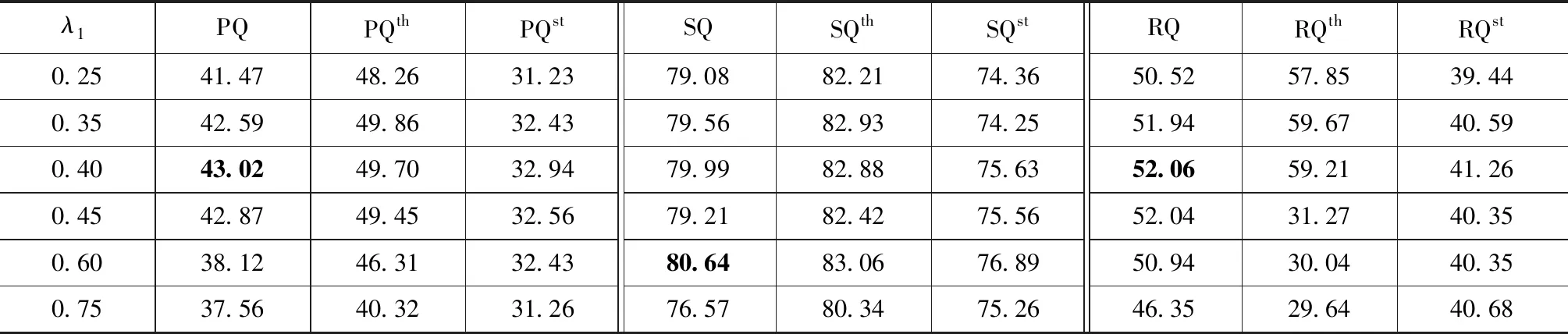
表1 不同分割损失系数权重对应的分割实验结果
找到最佳参数之后,采用2.2节所述的网络结构,进行语义增强损失函数和交叉熵损失函数的语义分割子分支对比实验。保持两组实验的超参配置不变,其实验结果如表所示。从表2可以看出,语义增强损失函数相比于交叉熵损失函数,IoU(即mIoU和FWIoU)指标有小幅度提升,填充物(stuff类)分割表现提高比较明显,全景分割质量PQ提高0.97 %,分割质量SQ提高了4.30 %,这是因为在分割过程中,填充物代表的语义分类大多被分到了较高的优先级,所以填充物分割质量提升较大。
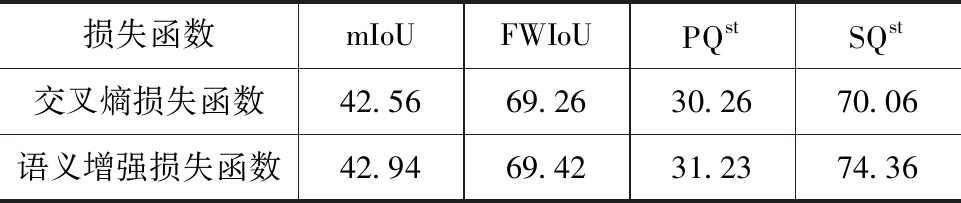
表2 交叉熵损失函数与语义增强损失函数语义分割对比试验
为更加直观地测试语义增强损失函数在全景分割过程的作用,下面按照图1中的语义种类等级对全景分割进行分组实验,表给出了不同语义分组的分割结果。从表3可以看出,相比于交叉熵损失函数,语义增强损失函数对R4中的电视语义分类准确度提高了3.93 %,对R4组内均值提高了2.17 %,对R3组内均值提高了2.13 %,语义增强损失函数有效提高了R3和R4分组中的语义分类准确度。在R1和R2组中,语义增强损失函数的分割准确度和交叉熵损失函数基本持平,语义增强损失函数对R2组内均值提高了0.49 %,对R1组内均值降低了0.45 %。综合上述结果可知,语义增强损失函数有效提高了优先级较高的语义分类的分割准确度,而其他非重要目标的语义分类准确性,少量类别会有轻微程度下降,达到了预期设计函数目标。

表3 语义增强损失函数与交叉熵损失函数全景分割AP(%)结果对比
图7给出了语义增强损失函数与交叉熵损失函数在不同实测环境下的全景分割结果。由图7可知,交叉熵损失函数对图7(1)中的绿化带以及电线杆上的静态标识、(2)中红绿灯旁边的静态标识以及背景中的天空、(3)中路边的限速标识等分割有误,而语义增强损失函数则有效的提高了上述场景中静态物体的分割效果。

图7 语义增强损失函数与交叉熵损失函数全景分割结果对比图
为了进一步验证本文分割网络在全景分割中的性能,我们选用COCO全景分割挑战赛上出现的Artemis、LeChen、MPS-TU Eindhoven[17]、MMAP-seg以及Facebook AI工作室提出的Panoptic FPN[13]方法与本文网络进行对比,实验结果如表4所示。由表4可以看出,本文网络对填充物的分割质量PQst明显优于其他5种方法,比效果较好的Panoptic FPN方法还高1.5;物体分割质量PQth稍稍低于Panoptic FPN方法,但明显高于其他四种方法;本文分割网络的全景分割质量均优于其他5种方法。因此,本文设计的带有语义增强损失函数的分割网络在COCO数据集上取得了较好的分割效果。
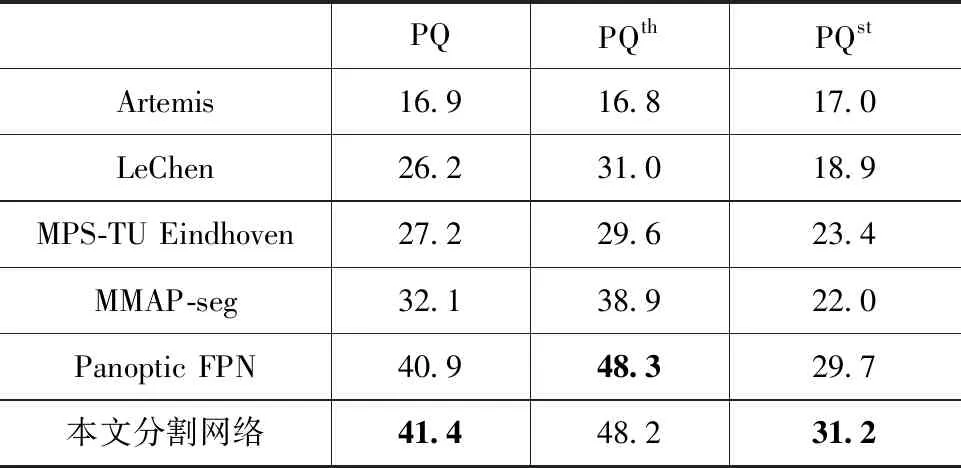
表4 COCO数据库中全景分割实验对比
4 结 论
为了提高不同应用场景下重要目标分割的准确度和可靠性,本文提出一种基于注意力机制的语义增强损失函数和全景分割方法。通过增加注意力机制,增强对任务关注语义信息的敏感度,提高对特定物体和背景的分类精度;同时设计相应的全景分割网络,提高对所需物体种类的分割精度。最后通过设计重叠结果剔除规则避免了网络结构中的实例和语义分割分支输出的重叠问题。对COCO数据集的对比实验表明,本文提出的语义增强损失函数有效提高了优先级较高语义类别的分割效果,为不同应用场景的全景分割提供了更加高质量的语义信息,进而增强了全景分割方法的实用性。
猜你喜欢
家庭影院技术(2020年11期)2020-12-28 01:22:36
开放教育研究(2020年2期)2020-03-31 01:54:14
英美文学研究论丛(2018年1期)2018-08-16 03:00:54
家庭影院技术(2017年12期)2017-02-06 02:32:12
特别文摘(2016年21期)2016-12-05 17:53:36
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
外语学刊(2011年1期)2011-01-22 03:38:33
