
基于乐高采样的自监督表示学习方法
2023-10-22 08:00许亦博赵文义李灵巧杨辉华
桂林电子科技大学学报 2023年3期
许亦博 ,赵文义 ,李灵巧 ,杨辉华
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.北京邮电大学 人工智能学院,北京 100876)
由于无法获取较多的带标签的样本,自监督表示学习在自然语言处理[1]和计算机视觉[2]的诸多任务中发挥越来越重要的作用。自监督表示学习是使用无标签的数据,利用对比学习,设计不同的代理任务或使用混合任务以优化特征提取器,并将特征提取器应用到下游任务中。由于自监督学习在特征表示学习阶段不需要标签信息,因此在自然场景图像处理、医学图像处理、遥感图像处理、工业检测等领域有着非常广泛的应用。
目前,自监督表示学习算法主要包括对比学习[3-4]、代理任务[5-6]和混合监督任务3类研究方法。对比学习算法的主要思想是先使用特征提取器提取一个样本的不同视角的特征向量,然后建模2个向量的相似性与差异性,最后使用信息-噪声对比估计[7](information-noise contrastive estimation,简称InfoNCE)损失函数优化特征提取器。基于该理论,He等[3]提出基于动量更新的对比自监督表示学习方法(MoCo),该方法使用记忆库和孪生网络结构,通过使用记忆库的方法将特征向量存储起来以增加对比样本的数量,然后使用孪生网络的结构对同一样本的2个视角进行特征提取,最后通过建模2个向量的相似程度来优化模型。由于使用记忆库存储特征向量增加了存储空间,Chen等[8]通过改进动量更新的对比学习,简化复杂的结构并且去掉了记忆库,提出了一种自监督表示学习的简单结构(SimCLR)。而上述方法均无法获取图像的细节信息,因此,Wang等[9]提出一种基于密集映射用以保留局部细节信息的方法,利用密集预测的特性,将提取到的特征图分成若干个特征向量,并分别对比每个特征向量。由于每个特征向量对应不同的细节信息,该方法能在密集预测的下游任务(目标检测)中取得较好的效果,但对全局预测的下游任务(场景识别)并无帮助。上述基于对比学习方法依赖于大量的数据和较多的训练周期,并且无法同时获得局部信息和全局信息,导致数据不能充分利用。
基于代理任务的方法主要是通过人为设计一种监督学习的方法,根据设计的方法使用无标签数据做监督学习,从而优化特征提取器。如基于补丁排序[10]的方法和预测旋转角度[11]的方法被用来优化特征提取器。最近,He等[6]引入了基于非对称编解码网络(MAE),通过预测被掩盖的区域来优化模型,这种方法能获得较为鲁棒的特征提取器,但是需要使用计算量和参数量都较大的Transformer网络[12]才会有效果,加重了计算和存储负担。然而这些基于代理任务的方法在使用CNN 作为特征提取器时,收敛速度较慢且无法提取细节信息,导致在下游任务中表现较差。
基于混合监督任务的方法目前很少有研究涉及,Chen等[13]提出一种聚类和定位共同优化的混合监督方法,这种方法虽然能加快收敛速度,但细节特征的提取能力不强。
针对现有方法存在的收敛速度慢和无法获取细节特征的问题,提出了一种基于乐高采样的自监督表示学习方法。本文采用了混合监督任务的方法。整体模型中除了引入乐高采样模块和特征提取模块外,在混合优化模块还引入聚类分支、定位分支和细节对比分支,通过对不同补丁的聚类和定位分支来恢复原始图像,并学习全局特征;通过细节对比分支来学习细节特征,从而使模型在更多的下游任务中具有较强的适应性。
1 基于乐高采样策略的自监督学习模型
基于乐高采样策略的自监督学习模型如图1所示。对输入的任意大小的无标签图像,本方法首先引入乐高采样策略,生成一系列如图1所示的5个补丁组,其中4个补丁相互邻接,补丁5与这4个补丁均有重叠。将残差网络作为特征提取器对乐高采样补丁进行特征提取,输出对应的特征向量,其中每个特征向量代表一次乐高采样的补丁;然后对这些特征向量使用不同的损失函数进行优化。
1.1 乐高采样
由于在自监督表示学习的过程中需要大量的正负样本对以维持较高的性能,传统的采样方法在计算资源有限的情况下无法构造出较多的正负样本,考虑到特征提取器的作用只是将原始样本转换为低维的特征向量,因此可以使用通过拼接后的样本进行特征提取来增加样本数量,并以此来学习样本间的关系。假设有n个从无标签数据集中随机选择的单张图片样本X={x1,x2,…,xn},对一张输入图片,乐高采样模块输出m个大小为112×112的补丁,经过特征提取模块的提取,生成m个对应的特征向量,这些特征向量经过不同的映射后用来优化模型。在该方法中,每个样本都会经过乐高采样器,所以共生成nm个分辨率为112×112的补丁。随后将这些补丁随机打乱,并将每4个补丁拼接成一个224×224的完整样本,重新组合形成新的数据集,再将这些构造的样本送入特征提取器。乐高采样的结构如图2所示,图中蓝色标号5的补丁不仅能增加样本数量,还能促使模型学习更多的细节信息。

图2 乐高采样示意图
1.2 特征提取
为了公平对比,该方法的特征提取模块和其他方法的特征提取模块保持一致,使用ResNet-50 网络[14]作为特征提取器。该网络包含4个阶段,每阶段中卷积块的数量分别是3,4,6,3。每个卷积块包含一个1×1通道下降的卷积,一个通道不变的3×3卷积和一个1×1通道数上升的卷积,2个1×1卷积的作用是为了保持输入通道和输出通道数的一致,并降低3×3卷积处的计算量。除此之外,为了适应自监督学习,把网络最后的全局平均池化层和全连接层去掉,并使用混合优化模块代替。
1.3 混合优化
在混合优化模块中,使用全局聚类分支,全局定位分支和局部细节对比分支共同优化。用到的损失函数分别为有监督聚类损失函数、交叉熵损失函数和对比损失函数。
1.3.1 全局聚类分支
全局聚类分支的作用是将来自同一张原始图片的乐高采样并打乱后的数据聚类,该分支采用信息-噪声对比估计(InfoNCE),定义为将每个样本的采样结果聚类到一起,它最大化正负样本之间的距离,同时最小化正正样本之间的距离。在本实验中,将来自于同一个样本的采样结果视为正样本,将来自不同样本的采样结果视为负样本,根据以上分析,全局聚类分支的损失函数表示如下:
其中ls表示针对某一个特征向量的损失函数,
式中ls,j表示信息-噪声对比估计损失函数,可以用式(3)表示:
1.3.2 全局定位分支
全局定位分支的作用是辅助全局聚类分支将乐高采样并打乱后的数据恢复成原始状态。采用交叉熵损失函数(cross entropy,简称CE)进行优化,目的是用来判断每个补丁来自原图的哪个部位,辅助恢复原始图像。其损失函数如下:
式中:C表示经过特征提取后的特征向量集合;Cgt表示根据特征向量的相应位置生成的伪标签。
1.3.3 局部细节对比分支
细节对比模块优化的目标是将乐高采样的前4个补丁生成特征向量的加权平均与第5个补丁生成的特征向量进行对比,这样操作不仅能促使模型学习4个模块中语义一致性的特征,也能使模型更关注于细节特征,细节对比模块的操作如图3所示。使用传统的对比损失函数(CON)进行优化,损失函数表示为
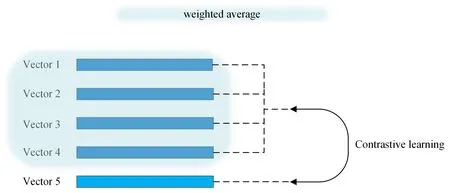
图3 局部细节对比分支
其中:Vi表示前4个向量的加权平均;Vh表示第5个向量。
最终整个模型的损失函数为3个损失函数的加权平均,定义如下:
模型优化的目标是最小化L。
2 实验结果及分析
为了验证提出方法的有效性,首先建立适用于自监督学习的数据集并对模型进行自监督表示学习,然后固定自监督学习阶段学习到的模型参数,将模型迁移到线性分类和目标检测的下游任务中进行测试。其中在自监督学习阶段使用的是无标签数据,在下游任务中使用的是有标签数据。本文使用提出的算法在线性分类和目标检测等下游任务中与4种经典的自监督算法进行对比,这些算法包括基于动量更新的对比自监督表示学习算法(MoCo)、简化的自监督学习算法(SimCLR)、改进的基于动量更新的对比自监督表示学习算法(MoCo-v2)[15]、基于拼接图像聚类的自监督表示学习算法(JigClu)。为了公平对比,使用相同的训练数据和参数对各个模型进行训练。仿真实验平台采用AMD EPYC 7302 16核CPU,内存为128 GiB,显卡型号为GeForce RTX3090 24 GiB,深度学习框架为PyTorch。
2.1 数据集构建与模型的训练
为了验证提出模型的有效性,使用ImageNet[16]、CIFAR[17]和若干细粒度分类数据集作为实验数据。其中,ImageNet数据集源于自监督训练阶段;CIFAR数据集用来快速验证提出模型的迁移性能;细粒度分类数据集用来验证模型对细节特征的提取能力。
ImageNet数据集常被用来验证模型的特征提取能力,是一个非常有挑战性的数据集,它包含128万张训练样本、50 000张验证样本,具有1 000个类别。CIFAR数据集作为计算机视觉最经典的数据集之一,常用来快速验证模型的性能和做简单的消融实验,CIFAR数据集包含50 000张训练样本和5 000张验证样本,其中CIFAR-10和CIFAR-100两个版本分别包含10和100个类别。
用3种常见的细粒度分类数据集Caltech-UCSD Birds (CUB-200-2011)[18]、Stanford Cars[19]和FGVC Aircraft[20]来验证模型对细节特征的提取能力。这些数据集的统计信息如表1所示。
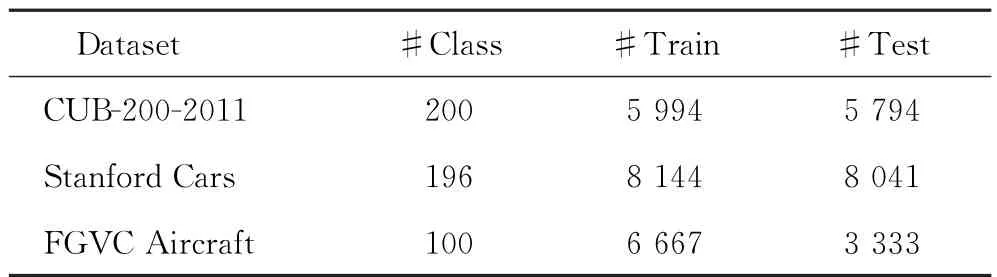
表1 数据集统计信息
在自监督训练阶段,设置批大小为256,初始化学习率为0.03,并且使用随机梯度下降的方法(stochastic gradient descent,简称SGD)优化模型参数,其中动量和权重衰减值分别设置为0.9和0.000 1,自监督阶段模型一共被训练了200个周期。在线性评估阶段,批大小被设置为256,初始学习率设置为10.0,并在第60和80周期衰减到原来的0.1倍,训练的总周期数为100。
2.2 客观评价结果
表2为本方法和几种经典方法在ImageNet的线性分类任务中对比的结果。
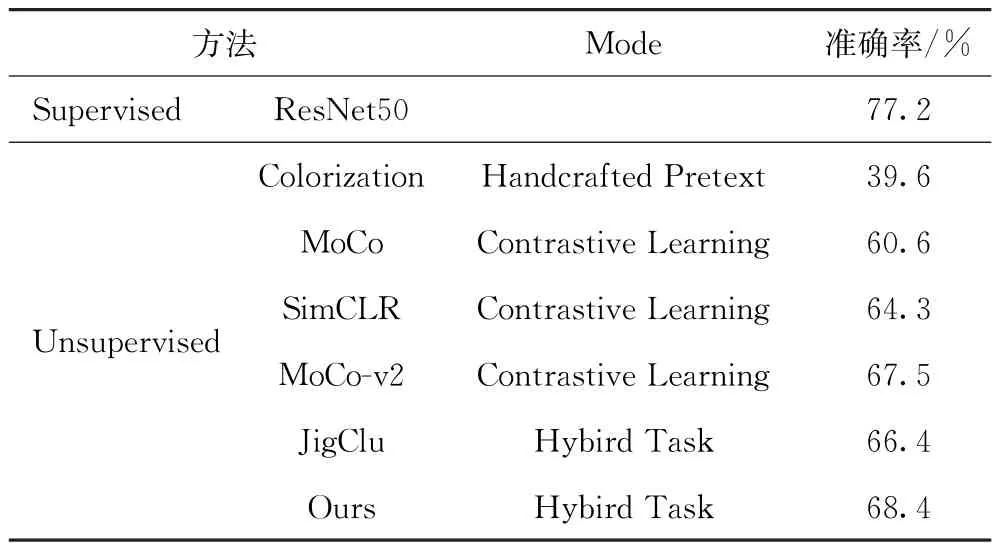
表2 分类任务结果
表2表明本方法在下游的线性分类任务中具有较高的准确率。此外,相比于MoCo、Moco-v2、Sim-CLR等基于孪生网络的结构,本方法在保持较高性能的同时节约了大量的计算量。
为了证明提出的模型有较强的鲁棒性和泛化性,同时具有较强的细节提取能力,在CIFAR数据集上和3种细粒度分类数据集上进行实验,结果如表3、4所示。

表3 CIFAR数据集实验结果
表3中:finetune代表使用较小的学习率更新权重;linear表示冻结权重,只更新线性层。而random init表示权重随机初始化,supervised表示有监督训练,Lego表示使用提出方法的预训练模型初始化权重。
从表3、4可见,本方法在CIFAR数据集表现出较强的迁移学习能力,在3种细粒度分类数据集中表现出对细节特征有更强的提取能力。
综上可得,本方法得到的预训练模型相较于MoCo、MoCo-v2、JigClu等几种经典方法具有更强的鲁棒性和泛化性。
2.3 主观评价结果
为了能直观地表示提出方法的有效性,使用类激活图(class activation mapping,简称CAM)来直观地展示提出模型的鲁棒性和对细节特征的提取能力。
图4表示使用预训练权重在不同数据集上生成的CAM。在CAM 中,红色区域表示模型重点关注的区域,也即激活区域,蓝色区域表示未激活区域。观察图4可以直观地看出本方法在应对不同形状、不同尺寸的全局特征,难以辨识的细节特征时能更好地激活相对应的区域。在图4中,(a)是原始图像,(b)和(c)是MoCo在layer3和layer4的CAM,(d)和(e)是MoCo-v2在layer3和layer4的CAM,(f)和(g)是JigClu在layer3和layer4的CAM,(h)和(i)是本方法在layer3和layer4的CAM。
3 结束语
提出了一种基于乐高采样的自监督表示学习方法。首先,利用乐高采样器对无标签数据进行采样并形成新的数据集;然后使用特征提取网络对新的数据集进行特征提取,并生成对应的特征向量;最后,使用不同的损失函数对不同的分支进行优化,以得到鲁棒性和泛化性较强的特征提取器。理论分析和实验结果表明,所提方法在客观评价指标和主观评价指标上皆获得较好的效果,能使自监督学习的下游任务得到更大的提升。
所提方法在自监督训练方法只是单纯使用RGB图像作为输入,目前很多实际应用场景中,除了RGB图像,各种模态的信息如文本、音频等也有着重要的使用价值,多模态学习是研究的热点之一。在未来,如何将自监督学习与多模态学习结合到一起,是一个值得深入的研究方向。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
玩具世界(2020年4期)2020-11-16
学与玩(2018年5期)2019-01-21
文苑(2018年18期)2018-11-08
幼儿画刊(2018年7期)2018-07-24
学生天地(2018年18期)2018-07-05
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
小主人报(2016年24期)2016-03-16
