
基于标记感知消歧的偏标记学习算法
2023-10-22 08:00殷建华刘振丙魏黄瞾
桂林电子科技大学学报 2023年3期
殷建华,刘振丙,魏黄瞾
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
在机器学习中,监督学习是研究最广泛的一种单标记学习框架。在该学习框架中,每个训练示例都必须有准确的标记信息。而在很多现实场景中,由于标记需要耗费大量的人力和时间且标记信息存在不确定性和模糊性,导致完全正确且标记唯一的监督数据难以收集。因此,如何利用更符合实际场景的弱监督数据进行学习,已经成为当前机器学习的一个热门课题[1-3]。
偏标记学习是弱监督学习框架中的一个重要分支,在偏标记学习数据集中,每个训练示例对应一组候选标记集合,其中只有一个是真实标记,且不能由学习算法直接获取。偏标记学习的关键在于利用有限的监督信息学习一个多分类模型,并有效地预测未见示例的标记。在现实世界中,具有冗余标签信息的数据比具有显式标签信息的数据更容易获得,而偏标记学习为模糊数据的学习提供了一种有效的解决方案,并被广泛应用到许多现实生活场景。例如,在医学诊断任务中[4],医生可以排除某些疾病的可能性,但通常很难从几种症状相似的疾病中做出诊断。又如,在人脸自动标注中[5],给定一张包含多个面孔的图片和对应的标题,通过标题可以很容易地获取图片中各面孔的语义信息,但是在图片中,某个特定人脸的语义信息就很难被匹配。此外,偏标记学习在人体动作识别[6]、Web 挖掘[7]、生态信息学[8]、在线标注[9]和自然语言处理[10]等场景也得了实际应用。
偏标记学习的目的是从偏标记训练数据集中训练一个分类模型,可以形式化为:给定训练数据集D={(xi,Si)|1≤i≤m},其中每个偏标记示例xi是一个d维的特征向量,Si为示例xi对应的候选标记集合。yi∈Si为训练示例xi的真实标记,最终目标是基于数据集D学习一个映射函数ƒ:x→y。
1 标记感知消歧方法
解决偏标记学习问题的关键是对候选标记进行消歧,而现有的偏标记学习算法主要通过挖掘样本的标记空间信息对候选标记进行消歧,忽略了特征信息对消歧过程的促进作用,且在衡量示例相似度时都侧重于对特征空间的处理,缺乏对标记空间信息的利用,这些均可能导致方法不是最优的。针对上述存在的缺陷,提出一种基于标记感知消歧的偏标记学习算法(partial label learning algorithm based on label-aware disambiguation,简称PL-LAD),该算法更全面地刻画了示例的相似关系,并将示例的相似关系与标记消歧过程融合,以提高偏标记学习的消歧结果。算法包括3个过程,分别为构建示例相似度矩阵、框架形成、交替优化。
1.1 构建示例相似度矩阵
由于描述训练示例的相似度矩阵对提高学习模型的消歧能力起着重要的作用,如何充分挖掘示例之间的关系至关重要。PL-LAD算法考虑到包含相同候选标记的训练示例应该具有更高的相似性这一假设,采用协同特征空间和标记空间的判别信息来计算相似度矩阵W。具体来说,PL-LAD 先为每个类别标记λl,构造了一个基向量,基向量是由标记λl所对应正例与负例均值的差异确定的,其表达式为
其中:Pl和Nl分别为标记λl对应的正样本集和负样本集;si是与示例xi相关的标记向量。式(1)中的统计量可以反映类别标记的整体标记分布,且已经被证明有利于在特征空间中对判别信息进行编码[11]。因此,可以利用组合基cl中的信息来刻画示例特征空间的相似度。根据对应组合基之间的余弦相似度来计算示例特征空间的相似度矩阵E=[elk]q×q:
为更加全面地刻画偏标记示例之间的关系,定义一个用于描述标记空间相似度关系的矩阵B=,
其中,blk对应同时包含标记λl和λk的训练样本。这里的blk≠bkl,即标记之间的关系是非对称的。最后,PL-LAD通过整合特征空间和标记空间来计算最终的相似度矩阵W=[wij]m×m,
其中,系数α∈(0,1)用来平衡特征空间和标记空间在计算相似度矩阵中的相对贡献。
1.2 框架形成
以往偏标记学习算法在模型训练过程中通常会忽略不同候选标记对消歧过程做出的贡献不同,即将所有候选标记同等对待,这将导致模型的泛化性能不佳。为此,PL-LAD考虑到示例的相似关系也应保持在标记空间这一流形假设,利用相似度矩阵W和标记空间中的重构误差来实现候选标记的消歧过程。此外,PL-LAD算法基于最小二乘损失提出一个统一框架,该框架在充分考虑流形假设和模型输出的情况下,将真实标记分布作为潜在标记置信度矩阵P∈Rm×q,同时进行模型训练与标记消歧过程,具体表达式为
式(5)中的第1项为损失函数,利用最小二乘损失对预测模型进行优化,第2项确保了标记置信度矩阵P的最优估计,第3项表示模型复杂度。第1个约束项保证了在标记传播过程中分配给每个训练示例的标记分布是一致的。第2个约束项则确保了标记只在候选标记之间传播,且真实标记严格地出现在候选标记集合中,且每个非候选标记的置信度必须置零。
1.3 交替优化
式(5)中的优化问题是一个双凸优化问题[12],PL-LAD算法采用交替迭代优化的方法来解决这个问题。该方法先通过固定变量P来优化更新模型参数Θ和b,然后在固定变量Θ和b的基础上优化更新变量P。不断迭代重复这个过程,直到算法收敛或达到最大迭代次数。
根据变量P当前的值优化模型参数Θ和b,在固定变量P的基础上,利用高斯核函数对示例进行非线性扩展,即zi=ϕ(xi),其中ϕ(·)表示一个高维希尔伯特空间的初始特征空间的映射。将式(5)中的优化问题表示为
由于式(6)中的损失函数是可微的,可用标准的梯度下降法进行求解。PL-LAD 采用了常用的拉格朗日乘子技术,式(6)中的约束优化问题的拉格朗日函数可以表示为
其中,A为拉格朗日乘子矩阵。根据KKT条件求解可得:
通过求解上述线性方程组可得
其中,Γ=(1/2μ)K-1/2Im×m,且K=ZZT,最后,根据式(9)求出预测模型的输出矩阵:
根据更新的模型参数Θ和b优化变量P。考虑到偏标记数据原始的标记矩阵带有噪声,PL-LAD将模型输出矩阵Q作为每次迭代的初始标记置信度矩阵,以在迭代中调整每个候选标记的置信度。在固定Θ和b的基础上,式(5)中的优化问题可表示为
上述优化问题是一个约束标记传播问题,先将其重写为一个标准的二次规划问题,然后借助现成的QP工具进行求解。最后,在整个迭代优化过程完成之后,根据式(9)的模型参数对未见示例进行标记预测。
1.4 PL-LAD算法流程
PL-LAD算法实现分构建示例相似度矩阵、框架形成、交替优化3个阶段。第1阶段是利用特征空间和标记空间的信息刻画偏标记示例之间的相似关系。第2阶段是将示例的相似关系传递到标记消歧过程,并与最小二乘损失共同生成优化框架。第3阶段是通过交替迭代优化的方式训练最优模型参数。算法的详细过程如下:在给定偏标记训练集,首先计算出每个类别标记的基向量(步骤1-3),并通过计算组合基之间的余弦相似度来描述示例特征空间的相似度(步骤4),然后构建一个相似度矩阵来描述示例之间的相似性(步骤5)。接着,迭代更新模型参数和标记置信度矩阵(步骤6-10),直到达到最大的迭代次数或该算法收敛。最后,根据式(9)的最优参数对未见示例的标记进行预测。
算法1PL-LAD算法流程
2 实验
2.1 实验设置
为分析、评估PL-LAD的性能,在2种数据集上进行了实验,分别为3组人工合成UCI数据集和6个真实的偏标记数据集。表1和表2分别给出这2种数据集的详细信息,包括数据集的样本数目、特征数目和标记类别数目。此外,UCI数据集还给出了实验配置,真实数据集给出了每个数据集的平均候选标记数目和应用领域。

表1 UCI数据集的数据特征
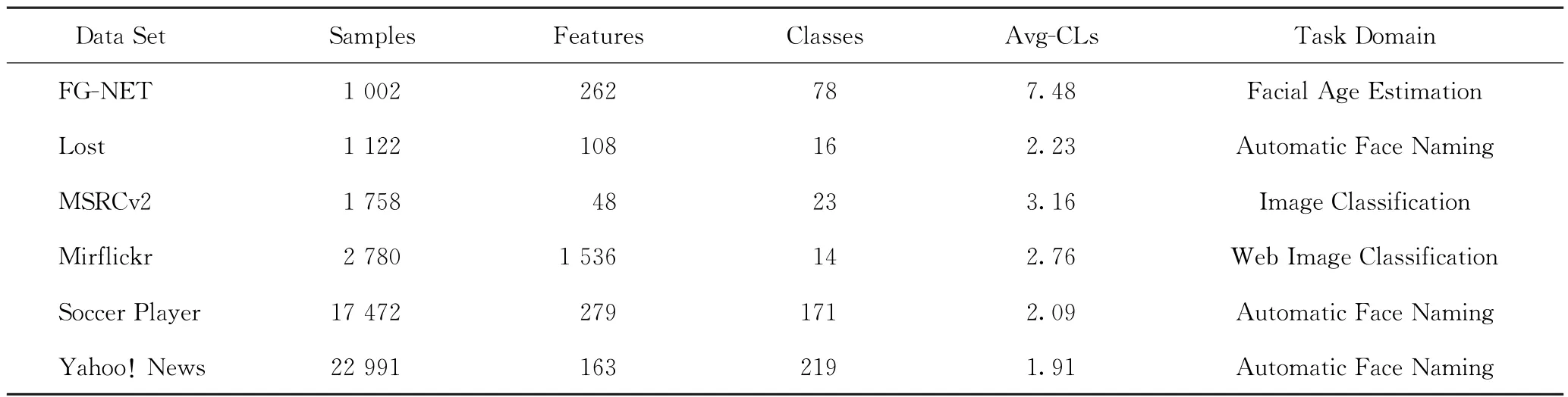
表2 真实数据集的数据特征
在3组UCI数据集上进行实验,分别为deter、vehicle和segment。对于每个UCI数据集,依照前人工作中的协议[13-15],通过控制3个参数p、r和ε的不同配置产生噪声标记。其中:p为偏标记样本所占比例;r为候选标记集合中伪标记的数量,这里r个假阳性标记是从标记空间中随机挑选出来的;ε为特定的假阳性标记与真实标记同时出现在候选标记集合中的概率。表1列出了详细的参数配置,共28(4×7)种。按照这种参数配置,共生成3×4×7=84个不同的人工UCI偏标记数据集。
真实世界的数据集来源于多个应用领域,其中数据集FG-NET[16]来源于面部年龄估计任务,数据集Lost[5]、Soccer Player[17]和Yahoo! News[13]来源于图像和视频中的人脸自动命名任务,数据集MSRCv2[18]和Mirflickr[19]来源于目标分类任务。真实世界数据集的特征如表2所示。
2.2 对比实验算法
为了进一步证明PL-LAD 的有效性,将其与5种先进的偏标记学习算法进行了实验对比。每种对比算法具体如下:
1)PL-KNN[20]:一种基于平均策略的消歧方法,利用k近邻的加权投票来预测未见示例。
2)LSB_CMM[18]:一种基于混合模型的最大似然偏标记学习算法,该算法提出了一个基于逻辑斯蒂结棍过程改进的概率模型来解决偏标记学习问题。
3)M3PL[21]:一种基于最大间隔准则的偏标记学习算法,通过最大限度地增加真实标记和非真实记之间的间隔确定目标函数。
4)PL-ECOC[22]:一种非消歧学习算法,该算法采用纠错输出编码技术来解决偏标记学习问题。
5)PALOC[23]:一种基于问题转换的非消歧算法,将偏标记学习的多分类任务基于一对一的分解策略划分为二分类任务进行解决。
2.3 实验结果
2.3.1 UCI数据集
PL-LAD算法在3个UCI数据集展开实验,图1~3分别展示了当噪声标记个数r为1、2、3时,偏标记训练样本占比p以步长0.1从0.1增加至0.7各对比算法的分类准确率。图4展示了当r和p都为1时,共现概率ε以步长0.1从0.1增长到0.7各对比算法的分类准确率。观察图1~4可以得出:

图1 r=1各算法的分类精度

图3 r=3各算法的分类精度
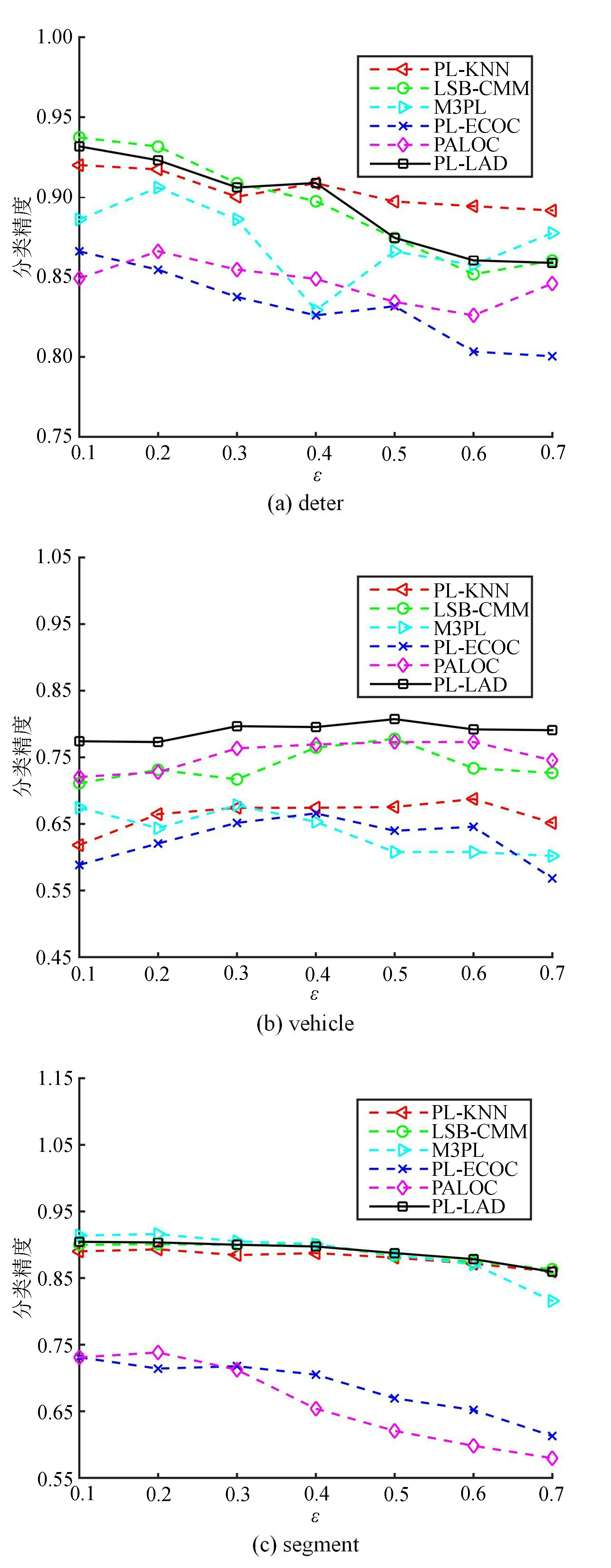
图4 r=1,p=1各算法的分类精度
1)在UCI数据集上,PL-LAD 算法的性能整体优于其他比较算法。
2)在deter数据集上,PL-LAD算法分类精度与LSB_CMM 基本持平。在r=1、2中,PL-LAD 在p=0.6时,以1.43%和1.71%低于LSB_CMM。在r=3、p=0.1~0.2时,PL-LAD算法仅以1.41%和1.63%低于M3PL,在r=3、p=0.5~0.7时,略差于LSB_CMM,在r=3、p=0.3时,分类精度达到最高值为92.87%。
3)在vehicle数据集上,PL-LDA 算法的分类性能显著优于所有对比算法。
4)在segment数据集上,PL-LDA算法分类精度与LSB_CMM 基本持平,仅以0.7%的差距劣于M3PL算法,并优于其他对比算法。
2.3.2 真实数据集
基于十折交叉验证及显著性为0.05的成对t检验,表3给出了PL-LAD 算法和其他对比算法在真实数据集上的性能(平均分类准确率±标准差)。以表3可看出:

表3 各比较算法在真实数据集上的分类准确率
1)与PL-KNN、LSB_CMM 算法相比,PL-LAD算法在所有数据集上取得了更优的分类性能;
2)与M3PL算法相比,PL-LAD 仅在Lost数据集上劣于M3PL,在其他数据集上的分类性能都优于M3PL。而PL-LAD 仅在数据集MSRCv2 上劣于PL-ECOC,且仅在数据集Yahoo! News 上劣于PALOC算法,在其他数据集上均优于PL-ECOC、PALOC算法;
3)在数据集FG-NET、Mirflickr和Soccer Player上,算法PL-LAD 的分类性能均优于其他对比算法。在Mirflickr和Soccer Player上,PL-LAD 的分类精度最多提高了17.4%和6%;
4)在数据集Lost上,PL-LAD 算法分类精度仅比M3PL低3.6%,优于其他对比算法,其原因在于Lost数据集中各类数据分散较为均匀,M3PL可以更好地实现聚类任务。在数据集MSRCv2 和Yahoo! News上,PL-LAD 仅以3%和2.4%低于PLECOC算法和PALOC算法。由于数据集MSRCv2和Yahoo! News数据集存在类别不平衡的问题,而PL-ECOC和PALOC则是针对不同的类别划分多个数据集,并训练多个分类器,最后对所有分类器加权投票来预测未见示例,可以缓解数据中的类不平衡问题。因此,相比PL-ECOC和PALOC,本研究提出的PL-LAD的性能表现略差;
5)在30组(5种对比算法 6个数据集)结果中,PL-LAD在83.3%的情况下显著优于所有比较算法,在6.7%的情况下取得了与其他算法相当的分类性能。
3 结束语
提出了一种基于标记感知消歧的偏标记学习算法,解决了已有算法计算样本相似度时标记信息利用不充分的问题,并利用样本相似关系促进标记消歧过程,以提升模型分类效果。大量实验表明,PL-LAD算法整体获得了较好的分类性能。利用不同的方法度量样本之间的相似性可以得到不同的消歧和分类性能,而PL-LAD 算法仅可以较好地表征样本之间的关系。因此,在后续工作中,可考虑采用更准确的样本相似度计算方式,来衡量样本间的关系,进而得到更佳的分类性能。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15
哈尔滨工程大学学报(2020年8期)2020-11-13
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
山东冶金(2019年1期)2019-03-30
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
电脑与电信(2018年12期)2018-03-23
数学物理学报(2017年5期)2017-11-23
