
基于云模型相似度的不确定知识排序方法
2023-10-18 06:52李金武
许昌学院学报 2023年5期
李金武
(郑州科技学院 大数据与人工智能学院,河南 郑州 450064)
知识是智能化的基础,同时也是软件智能化的重要研究对象,随着大数据与人工智能技术的发展,如何从海量数据中发现知识概念并有效表示,显得尤为重要.由于人类主观判断的不确定性,不同知识表现为模糊性和随机性,导致知识表达的不确定性.不确定知识表达主要包括知识表达概念和知识表达方法,传统的不确定知识表示及处理方法有:确定性理论、主观贝叶斯方法、可能性理论、D-S证据理论、灰色系统理论、粗糙集理论、概念图、集对分析等[1-3].
借鉴现有不确定知识表示方法,利用云模型的随机性和模糊性来描述知识的不确定性[4,5].云模型在数据挖掘、自然语言处理、决策分析等领域得到了广泛应用[6-8].虽然云模型可以对不确定知识进行描述,但是针对同一论域空间提取出的多个知识概念,用云模型表示后,若采用自然语言变量值对知识概念进行定义,如何将语言变量值准确地同云模型表示的知识概念进行映射,此问题目前研究较少,因此提出一种基于云模型相似度的不确定知识排序方法,将云模型表示的知识概念排序后,再与语言变量值进行对应,可以有效解决上述问题.
1 云模型及知识表示
1.1 云模型理论
基于概率论和模糊数学知识,李德毅院士首创地提出云,用自然语言描述定性概念与其定量数值之间的不确定性转换关系.其概念如下:设U是一个论域U={X},C是论域U相联系的语言值,表示某定性概念,对任意x∈U,x关于C的隶属度y=u(x)∈[0,1]是一个具有稳定倾向的随机数,(x,y)在U上的分布称为云[9].
用期望Ex、熵En、超熵He三个数值表示云的数字特征,其中期望Ex是最能够代表定性概念论域中心的点,熵En是对定性概念模糊性的度量,超熵He是对云滴离散程度的度量,反映了隶属度随机性变化.云模型C(Ex,En,He)充分反映了定性概念的模糊性和随机性,具有较大的客观性.
云模型论域空间维度可以是任意的,即一维云模型C(Ex,En,He),二维云模型C(Ex,Ey,Enx,Eny,Hex,Hey)和多维云模型C(Ex,Ey,…,Enx,Eny,…,Hex,Hey,…).例如,仅考虑生理年龄定义“青年”概念,用一维云模型C(25,3,0.3)表示,如图1所示,图1同时描述了云模型数字特征的含义.若同时考虑生理年龄和心理年龄定义“青年”概念,用二维云模型C(25,25,3,3,0.3,0.3)表示,如图2所示.
1.2 不确定知识表示
针对不确定知识表示,可使用语言变量进行描述,所谓语言变量,即用自然语言中的词或句子表示的变量.云模型描述了定量数据与定性概念的不确定性转换关系,云模型的定性概念可通过使用语言变量来描述,该语言变量的取值可以是低、很低、不很低、高、很高、不很高等,利用云模型可以对不确定知识进行表示.然而对于论域空间划分的多个知识,如何将语言变量与云模型表示的知识准确地进行映射,是研究的主要问题.
对于单属性数据,划分出多个知识概念,并用一维云模型描述,定义多个语言变量值.通过比较一维云模型的期望值,可以比较容易地将一维云模型表示的知识概念同语言变量值进行映射.
比如,按照常识,普通成年人依据年龄可以定义为“非常年轻、年轻、中年、老年和晚年”5个等级,以2022年中国工程院院士群体年龄为例,将院士群体划分为5类,并用云模型表示,即C1(52.3,2.7,0.42),C2(66.0,3.4,0.78),C3(74.4,2.4,0.64),C4(78.6,2.8,0.75),C5(83.5,3.4,0.89),如图3所示.通过云模型期望值比较,可将云模型“C1,C2,C3,C4,C5”表示的概念依次映射为“非常年轻、年轻、中年、老年和晚年”.

图3 五等级一维云模型
然而,对于多属性数据,划分出多个知识概念,使用多维云模型进行描述.如何将多维云模型表示的知识概念与定义的语言变量值与之对应,若采用比较云模型期望值的方法,显然不合理.
比如,评估主机的安全性,考虑CPU利用率和内存利用率2种属性,并将主机的安全性定义为“非常低、低、中、高、非常高”5个等级,用云模型表示,即C1(13.41,42.32,4.34,5.56,0.27,0.58),C2(61.31,52.46,8.78,7.13,1.39,0.89),C3(40.52,30.67,5.82,6.61,0.57,0.38),C4(25.76,53.17,6.86,7.93,0.48,0.31),C5(92.47,51.39,8.50,6.72,1.18,0.82),如图4、5所示.若比较CPU利用率期望值,云模型“C1,C2,C3,C4,C5”表示的概念依次映射为“非常高、低、中、高和非常低”.若比较内存利用率期望值,云模型“C1,C2,C3,C4,C5”表示的概念依次映射为“中、非常高、非常低、高和低”.如何准确将云模型表示的知识概念与定义的语言变量值与之对应,提出了一种基于云模型相似度的知识概念排序方法,进而将云模型表示的知识概念映射到不同的语言变量值,该方法不仅适用于一维云模型表示的知识概念,同时还适用于多维云模型表示的知识概念.
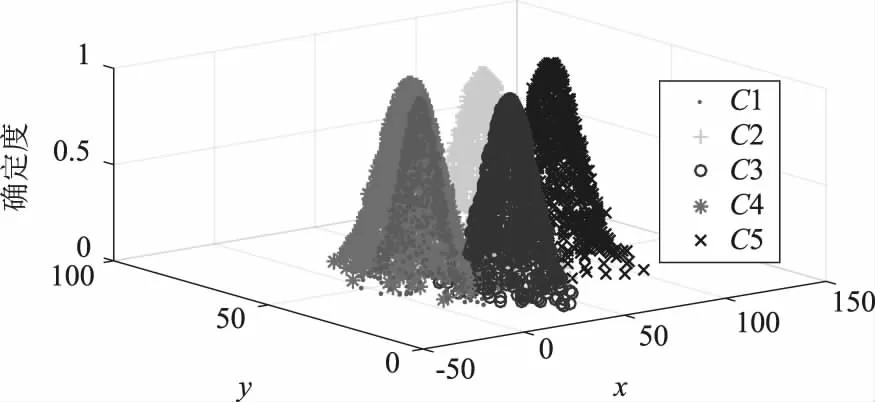
图4 五等级二维云模型
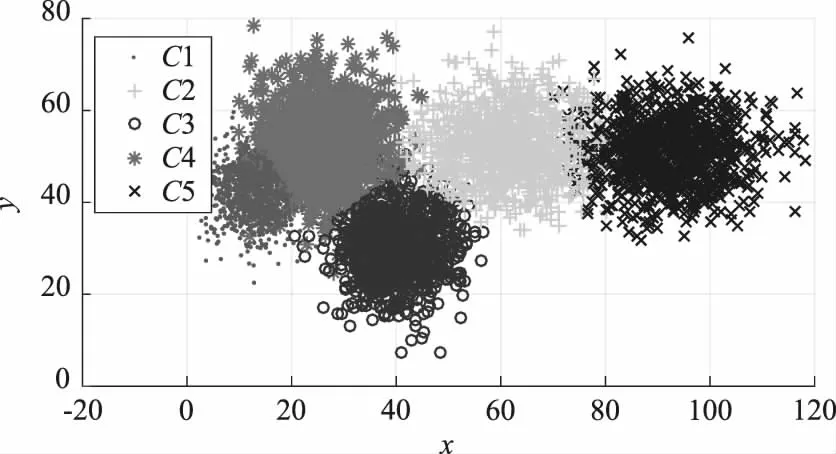
图5 五等级二维云模型投影
2 云模型相似度及知识排序方法
2.1 云模型概念相似度


(1)
为减少计算复杂度,考虑云模型期望曲线形状,利用云模型期望曲线在水平和垂直两个方向的重叠度来计算其相似度.具体步骤如下.

(2)
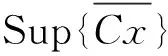

图6 云滴上界和下界示意图
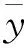
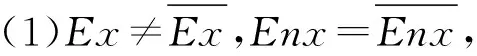
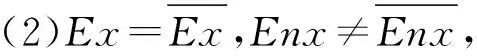

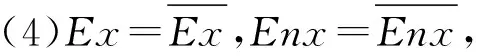

图7 云交点示意图
对于(1)和(2)存在单交点x0的情况,若x0不在区间[Ex-3En,Ex+3En]内,u(x)=0,若x0在区间[Ex-3En,Ex+3En]内,u(x)=u(x0).
对于(3)存在双交点x0和x1的情况,若x0和x1都不在区间[Ex-3En,Ex+3En]内,u(x)=0,若x0和x1其中一个在区间[Ex-3En,Ex+3En]内,假设x0在区间内,则u(x)=u(x0),若x0和x1都在区间[Ex-3En,Ex+3En]内,则u(x)=max{u(x0),u(x1)}.

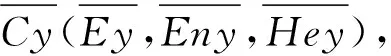
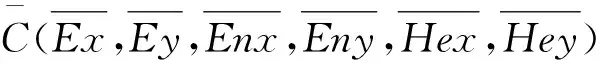
TOM=OMx×OMy,TOM∈[0,1].
(3)
2.2 知识概念排序方法
使用云模型对论域空间中的不同知识进行划分表示,并计算云模型彼此之间的相似度,云模型之间相似度越小,说明其对应的知识概念描述越相近.假设某论域空间划分出k个云模型概念{C1,C2,C3,…,Ck},即对应k个知识概念.若云模型概念Ci和Cj相似度TOM∈(0,1),则具有邻居关系,记为
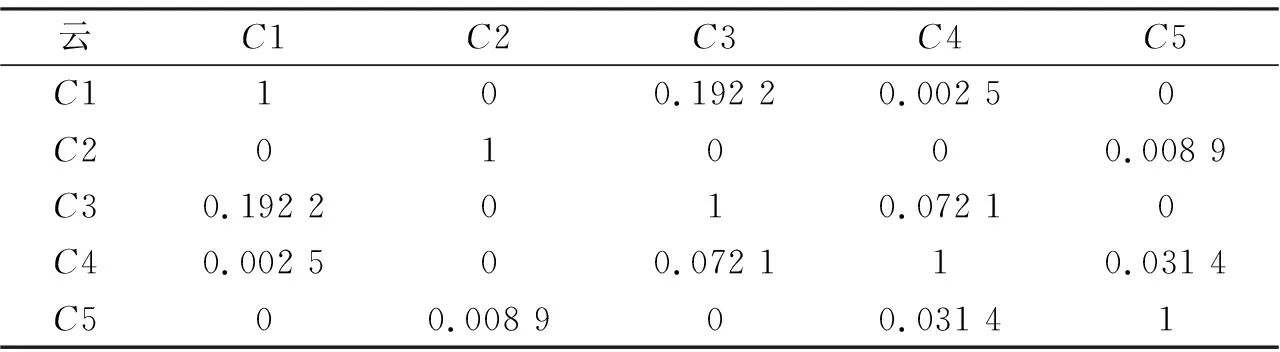
(1)某个云模型概念Ci,由于云模型“亦此亦彼”的性质,至少存在一个相邻云模型.将其相邻的云模型个数设为m,若1 (2)由于概念的软划分特性,边界概念(最小或最大概念)至少存在一个相邻云对,非边界概念至少存在两个相邻云对. 基于云模型的知识概念排序,以相似度为主要依据,可进行线性排序,具体步骤如下. 步骤1:初始化边界概念.若按升序排列,需确定最小概念,选取期望值最小的作为最小概念CInf. 步骤2:循环遍历概念CInf的相邻云对,找寻其强邻云对,作为概念CInf的后序概念CInf-f. 步骤3:删除概念CInf,将概念CInf-f重新作为最小概念CInf,重复执行步骤2,直至所有概念都被遍历.若遍历过程中,出现中断,即概念CInf不存在强邻云对,需返回步骤1,重新初始化边界概念.最终将遍历次序作为概念排序结果输出. 实验数据采用交通卡口某天实际的交通流量,从0:00到23:55每隔5分钟,采集一次车流量信息,形成288条车流量数据信息,车流量数据如图8所示.为了更好描述道路车流状况,以原始车流量数据信息为基础,在时间维度上考虑车流量的增速,对数据集进行处理,定义第一时刻车流量增速为零,从第二时刻开始,车流量增速为当前时刻车流量与前一时刻车流量差值.数据集转换为二维属性,以便更好地验证所提出不确定知识排序方法. 图8 车流量数据 针对转换后的数据集,数据集包含当前车流量和车流量增速两个属性,利用高斯混合模型云变换算法[14-16],对数据集知识概念进行提取,并对知识概念云模型表示,如表1所示,该数据集划分五个知识概念.利用云模型概念相似度度量方法,将提取到的云模型概念投影到不同的一维平面,计算各维度方向一维云模型相似度,最后联合计算给出整个知识概念云相似度,如表2所示. 表1 云模型概念 表2 云模型概念相似度 由云模型相似度可知,C1存在2个相邻云对, 图9 概念云邻居关系图 依据概念云模型相似度,对概念进行线性排序.首先确定概念云C2为边界最小概念,遍历C2的相邻云对,将强邻云对对应的概念云C5作为后序概念.然后删除C2,遍历C5的后续概念,循环遍历,直至所有概念都被遍历.最终将云变换得出的5个概念云进行升序排列,即C2,C5,C4,C3,C1.概念云C2和C1为边界概念,概念云C2描述的道路车流状况最好,不宜堵车,概念云C1描述的道路车流状况最差,容易造成堵车.在此定义5个定性语言变量“好,较好,中等,较差,差”,来描述道路车流状况,可将排序后的知识概念“C2,C5,C4,C3,C1”,映射为定性语言变量“好,较好,中等,较差,差”. 云模型描述了定量数据和定性概念的不确定性转换关系,利用云模型对不确定性知识进行表示,可以对任意维度数据进行处理.针对云模型表示的知识概念,当使用语言变量值进行定义时,为了准确将知识概念同语言变量值进行对应,提出了一种基于云模型相似度的知识概念排序方法,综合考虑云模型期望曲线在各维度方向上的重叠度,给出云模型相似度的计算方法,同时基于云模型相似度,确定知识概念相邻关系,构造知识概念图,提出一种知识概念排序方法,能够将知识概念映射到合适的语言变量值,该方法在处理多维云模型表示的知识概念上表现较好.但是通过知识概念图进行排序时,如何更好地判断第一个知识概念,是下一步研究的关键问题.3 实验分析
3.1 数据集描述

3.2 概念排序


4 结语
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
成都信息工程大学学报(2021年6期)2021-02-12
中成药(2018年12期)2018-12-29
测控技术(2018年10期)2018-11-25
广东石油化工学院学报(2016年3期)2016-05-17
电源技术(2016年2期)2016-02-27
数学教学通讯·初中版(2015年5期)2015-06-17
中国检察官(2015年14期)2015-02-27
中国检察官(2015年12期)2015-02-27
中国交通信息化(2014年6期)2014-06-05
