
基于改进条件生成对抗网络的书法字骨架提取
2023-10-17 05:50张子珺陈劲松钱夕元
计算机工程 2023年10期
张子珺,陈劲松,钱夕元
(1.华东理工大学 数学学院,上海 200237;2.上海宏弈源软件科技有限公司,上海 200233)
0 概述
书法以汉字为载体,承载着中华民族文化,见证了中华上下五千年的文明,是中国传统文化的重要组成部分。近年来,国家投入大量资源发展书法教育,书法逐渐走入课堂。书法学习是一个模仿、对比、改进的过程,老师在课堂中扮演的角色是对书法字进行合理评价,指导学生如何改进。一般而言,课堂上的书法字评价是老师通过书写经验主观地评判学生的书写结果,并观察学生书写过程中的姿势和运笔等给出改进建议。这一教学方式受制于教学地点的局限以及师资力量的短缺。
随着互联网的飞速发展,许多教育培训机构尝试将人工智能技术应用到书法教育领域,促使书法教育进一步的发展。书法字主要通过运笔改变笔画的粗细和走势以获得美感,这些特征是评价书法字体的重要依据。书法字骨架提取技术使用极少的像素信息却能保留完整的拓扑结构,传达了形状识别的关键信息,对于评价书法字符笔画结构极为重要。
常见的骨架提取算法主要有基于像素点邻域的书法骨架提取算法,以ZHANG-SUEN(Z-S)细化算法[1]和AHMED-WARD(A-W)细化算法[2]为主,基于目标像素点在邻域上的连通性进行删除和保留操作,以此不断剥离二值图像的边界像素,直到保留物体的中轴线。基于邻域的细化算法应用到笔画骨架提取时,会产生大量毛刺、骨架非单像素宽度以及交叉区域扭曲等问题。文献[3-5]改进上述细化算法,消除了骨架毛刺并提取出单像素宽度的骨架。文献[5]通过模板将骨架进一步细化,引进门限机制的判定方法去除了骨架毛刺;文献[6]提出一种基于笔画连续性检测的改进算法,对骨架笔画进行了校正处理;文献[7]基于手写汉字骨架,利用局部关联度来提取笔画,定位并删除模糊区域,根据方向信息和平滑信息将属于同一笔画的笔画段连接起来以修正模糊区域的骨架畸形,但无法修正模糊区域笔画严重扭曲的情况,对一些字体的泛化能力不高。另外一类骨架提取是基于距离的算法,变体的方法主要是因为距离函数有所不同:如欧氏距离[8]、街市距离[9]或约束德劳内三角剖分距离[10]等。通过计算目标像素点到边界的距离,找到图像中的所有局部极大值点,根据物体的拓扑结构将极大值点关联起来,生成定位准确的骨架,这类方法的困难性主要在于不能保证骨架的连通性。
上述基于像素点计算的骨架提取方法通常对噪声不鲁棒,并具有较低的精度,在复杂场景下不能得到令人满意的结果。由于无法提取到图像的深度特征,提取的汉字骨架极易在交叉区域扭曲,且在骨架化的过程中无法保留笔画的原始走势,这给笔画提取以及结构分析带来了困难。
近年来发展起来的深度学习算法使得提取图像的深层特征成为可能。文献[11]提出了融合与尺度相关的深度侧输出(Fusing Scale-associated Deep Side,FSDS)来提取自然图像的骨架,以解决复杂场景和对象多样性带来的困难,但全卷积网络无法保证相似像素之间的平滑度,另外由于比例预测不准确,FSDS 经常产生更粗的骨架;文献[12]提出基于全卷积网络的手写汉字骨架提取方法,通过继承预训练的 HCCR-CNN9Layer[13]的权重并进行微调,优化数据集使得网络可以学习到手写汉字的丰富特征,但网络输出只能得到相对粗略的结果,需要通过K 均值(K-Means)聚类来消除笔画断裂问题;文献[14]使用pix2pix cGAN 来实现ESPI 条纹图像骨架的批量提取,相较于Cycle GAN 和U-Net 方法,可以更快地获得准确、完整、光滑的骨架,且具有一定的鲁棒性;文献[15]评估了pix2pix cGAN 方法在几何形状理解上的效果,但近年来很少有学者在骨架提取上对pix2pix cGAN 进行改进以优化效果。
本文提出一个基于改进的条件生成对抗网络的书法字骨架提取算法,可以学习到书法字图像的深层信息,端到端的生成器使得模型可以直接提取书法字骨架。使用在线伪书法字作为训练集,以获取运笔信息,使骨架特征更具有代表性。该算法通过改善现有方法在提取书法字骨架时出现断裂以及毛刺的问题,使得提取出的骨架图像能够展现书法字的形态。
1 pix2pix 骨架提取算法
条件生成对抗网络(conditional Generative Adversarial Network,cGAN)[16]将监督学习的思想加入到生成模型中,每个输入的图像数据都对应一个标签。经过大量训练后可以根据网络输入的标签生成对应的输出,有效地解决了GAN 自由生成的结果不可控的缺点,使网络朝着期望的方向生成样本。由于cGAN 强大的图像生成能力和端到端的结构,在语义分割[17]、图像去雾[18]、图像着色[19]等众多领域得到了广泛应用。近年来,研究人员尝试将cGAN应用于书法图像处理,如书法字符生成[20-21]、笔画分割任务[22-23]等,取得了较好的效果。
pix2pix[24]属于条件生成对抗网络,通过训练配对数据,学习从输入图像到输出图像的映射等。pix2pix 由生成器和鉴别器两部分组成,其条件为图片,生成器为U-Net,可以实现图像到图像的转换。
条件生成对抗网络的目的是完成输入图像x和随机矢量z到图像y的映射,其目标函数可表示如下:
pix2pix 网络在条件生成对抗网络的损失函数基础上增加L1距离函数来恢复图像的低频部分,生成更加清晰的图像,提高生成器的性能。与cGAN 不同,不需要输入随机噪声z。新的目标函数表示如下:
其中:LL1(G)=Ex,y[‖y-G(x)‖1];λ为超参数用于平衡两个目标函数。
生成器的目标是通过使其输出与目标图像具有相同的分布来欺骗鉴别器。因此,在训练生成器时,损失函数需要最大化D(x,G(x))。鉴别器的目标是不要将生成的图像识别为真实图像,因此它的损失函数需要最大化D(x,y),同时最小化D(x,G(x))。通过大量的训练,生成器产生的输出,令鉴别器无法将其与“真实”图像区分开来,而鉴别器能够尽可能地检测出生成器的输出为“假”。
图1 所示为pix2pix 模型进行骨架提取的示意图。从图1(a)和图1(c)可以看出,pix2pix 模型可以很好地提取出骨架图。从图1(b)和图1(c)可以发现,骨架的整体定位在视觉上基本一致,但是骨架端点、拐点和交叉点会有一定程度上的偏移,笔画的平滑度不高。

图1 基于pix2pix 模型的书法字符骨架提取效果图Fig.1 Calligraphy character skeleton extraction renderings based on pix2pix model
2 基于改进的条件生成对抗网络骨架算法
目前的骨架提取算法都是对二值图进行骨架提取,需要进行一定的预处理工作,文献[12]基于3 通道图像进行骨架提取,但需要后处理来消除笔画的大量断裂。本文提出一个改进pix2pix 的书法字骨架提取算法,通过CASIA 在线手写汉字数据集生成一一对应的伪书法图像和骨架图像进行模型训练。将真实的书法图像输入网络,得到二值化的骨架图像来测试网络的泛化性。本文方法的总体结构如图2所示。

图2 网络总体结构Fig.2 Overall structure of the network
2.1 生成器架构
本文使用文献[23]中没有搭载注意力机制的基于pix2pix 的改进框架作为基线网络(Baseline),该框架将pix2pix 生成器的8 次下采样缩减为6次,在编码器阶段用1×1 卷积使得特征图在传递到下一层之前实现降维,通过实验发现U-Net 结构更适合生成笔画,残差结构可以提高每个生成笔画交叉区域的准确性。生成器架构如图3 所示。

图3 生成器架构Fig.3 Architecture of the generator
与书法风格迁移任务不同,骨架提取不需要多样性的结果,因此可以不用执行减少参数数量的处理。生成器的ResU-Net 结构虽然使用了跳跃连接来融合深层和浅层的语义信息,但在下采样和上采样的过程中仍会丢失大量信息。骨架提取任务可以近似于语义分割任务,而骨架所占图像比例极低,需要模型学习到更为精确的像素级预测。因此,在生成器的每一层都添加了分层空洞卷积模块使模型可以学习到不同尺度下的长距离上下文信息,下采样层的激活函数使用Leaky ReLU 函数。在模型底部搭载微调的CCA 模块,以连续的方式学习注意力系数和偏移来获取近似全局自我注意力。通过实验发现,该模块能有效地提高笔画的连通性和平滑度,很大程度地提升了模型的泛化能力。由于希望生成一个单通道的字符骨架,因此调整生成器输出图像的通道数为1,以此来获得二值化的字符骨架图像的近似输出。
2.1.1 分层空洞卷积模块
空洞卷积已经被证明在很多分类和分割任务上有优异的表现,书法字符的骨架提取可以看作是图像分割任务,文献[25]提出密集扩张卷积合并(Dense Dilated Convolutions Merging,DDCM)模块来进行图像分割,通过不断增大膨胀速率与之前不同膨胀速率的特征层并合并在一起,有效地扩大核的接受场,获得融合的局部和全局上下文信息,以促进周围的判别能力。为了让生成器在下采样和上采样的过程中捕获到更加完整的上下文信息,受上述模块启发提出分层空洞卷积合并(Hierarchical Atrous Convolutions Merging,HACM)模块,在本文任务上得到了较DDCM 模块更优的结果,如图4 所示。首先将输入的特征图通过一个1×1 的卷积,将其分别与通过不同膨胀因子空洞卷积的输出堆叠在一起馈送到下一层,然后将不同膨胀率输出的特征图堆叠在一起通过一个3×3 的卷积,得到的输出与模块的初始输入堆叠在一起通过一个1×1 的卷积。线性增加的扩张因子使得网络的感受野增大,减轻了上下文信息丢失。在每个卷积层中使用PReLU激活函数,避免随着网络层数增加而梯度消失的情况。
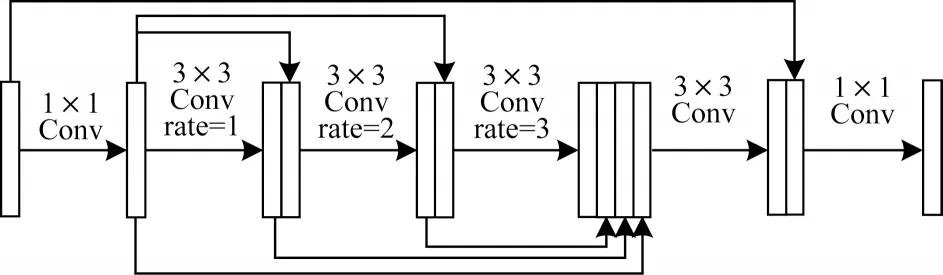
图4 分层空洞卷积合并模块Fig.4 Hierarchical atrous convolution merging module
2.1.2 交叉注意力模块
文献[26]提出交叉注意力(Criss Cross Attention,CCA)模块以改进引入注意力机制需要消耗大量计算资源的问题。交叉注意力模块通过使用几个连续的稀疏特征图来代替普通的单密度连通图,高效地获取全图的上下文信息。文献[27]通过修改交叉注意力模块并集成在U-Net 架构中来标记相对较小的数据。
在基线网络上添加了HACM 模块后,发现网络提取的骨架在指标上较大提升,但生成的骨架线条并不光滑,存在较为明显的锯齿形线条。本文将CCA模块集成在pix2pix 生成器U-Net 架构的底部对网络进行改进。如图5 所示,区别于交叉注意力模块,在pix2pix 生成器编码过程中,下采样4 次后,特征层数不再增加,因而在特征送入模块后进行3×3 卷积时,不进行特征层数减少的操作。
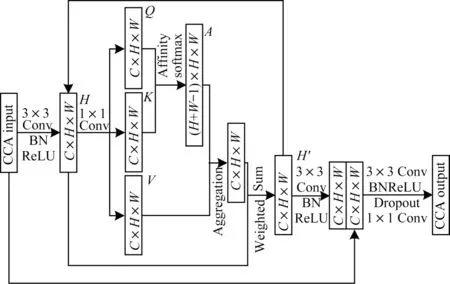
图5 交叉注意力模块Fig.5 Cross attention module
2.2 鉴别器架构
鉴别器网络是一个70×70 像素的PatchGan,广泛用于图像到图像转换的网络架构。PatchGan 输出为30×30 的矩阵,矩阵中的每个值代表每个70×70 的patch 为真样本的概率,使得模型更能关注图像的细节信息。GAN 通常被认为难以训练,通过实验发现,对于本文的任务,到后期损失函数仍会大幅震荡,训练过程极为不稳定。
Lipschitz 条件可以限制函数变化的剧烈程度,即函数的最大梯度。假设鉴别器D:I→R,其中I是图像空间。如果鉴别器是K-Lipchitz 连续的,即函数的最大梯度为K,那么对图像空间中的任意x和y,有:
其中:‖·‖为L2-norm,如果K取到最小值,那么K被称为Lipschitz 常数。
谱归一化[28]使得鉴别器D满足1-Lipschitz 条件,已经被证明可以限制函数变化的剧烈程度来稳定模型训练。因此,将鉴别器每个卷积层后的归一化层用谱归一化替代,使用Leaky ReLU 函数作为激活函数,如图6 所示。通过约束鉴别器的Lipschitz常数得到稳定的训练结果,该替代不需要额外超参数调整,计算成本相对较小。
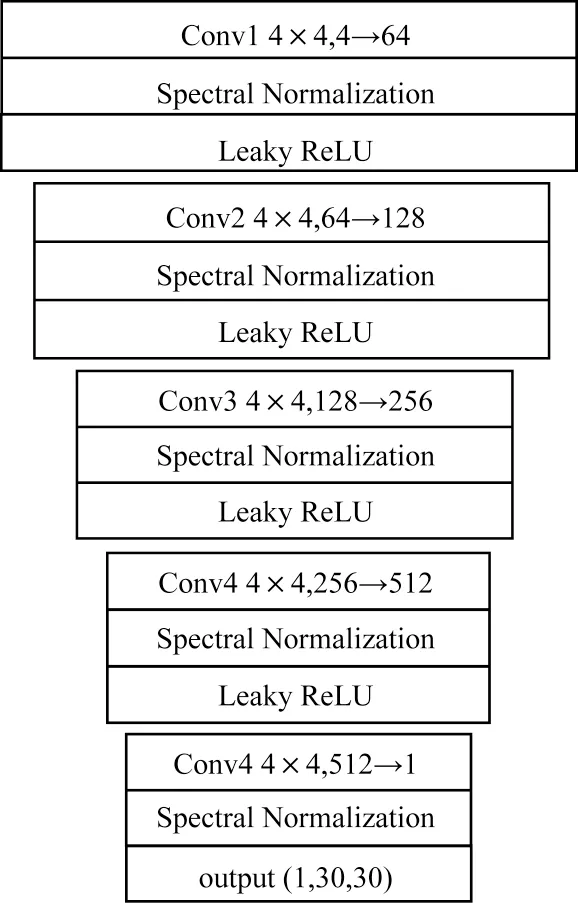
图6 鉴别器架构Fig.6 Architecture of the discriminator
3 实验与结果分析
3.1 网络训练
3.1.1 数据集准备
对于监督模型,需要准备大量的书法字及对应的真实骨架,采用人工标注骨架或细化算法提取骨架难以保留书法字的书写原始路径且丢失大量的用笔信息等。在线手写样本[29]通过(x,y)坐标序列记录书写过程,保留了用笔书写的过程信息,可以视为骨架,如图7(a)所示。在此基础上,通过扩大笔画宽度,在交叉区域和端点进行膨胀腐蚀操作并控制边缘平滑度和前景灰度生成如图7(b)所示的合成图,构成配对的伪书法字图像和骨架的学习样本。

图7 在线手写字与离线书法字Fig.7 Online handwritten character and offline calligraphy character
3.1.2 训练细节
所有实验均使用相同的设备完成,操作系统为CentOS Linux release 8.5.2111、显卡为Tesla T4、处理器 为 Intel®Xeon®Platinum 8163 CPU @2.50 GHz,在Python3.8,PyTorch1.7-cuda11.0 的环境下运行。
生成器和鉴别器的初始学习率设置为0.000 2,在训练到50 个epoch 后学习率调整为0.000 1,使训练结果逐步收敛,采用Adam 优化器加速训练过程,其参数设置保持默认值,λ设置为10,批训练量的大小设置为16,在训练过程中随机改变输入图片的亮度、对比度和饱和度以提高模型的泛化性。
3.2 评价指标
骨架提取图像为二值图,图像中像素点的灰度值均为0 或者255,本文的任务实际上是一个二分类任务。为了评价本文方法在骨架提取上的性能,采用5 个常用于骨架提取评价指标进行定量评价:即准确度(ACC)、召回率(Recall)、精度(Precision)、F1 值(F1)以及联合交并比(Intersection over Union,IoU),这5 项的评价指标的定义如下:
其中:TTP是网络输出为正确的骨架像素的数量;TTN是网络输出为正确的非骨架像素的数量;FFN是网络输出为不正确的骨架像素的数量;FFP是网络输出为正确的非骨架像素的数量。
在二值化骨架图中,骨架点和非骨架点类别极度不均衡。F1 值考虑了真实骨架图和生成的图像中的骨架和背景像素的数量,可以衡量骨架像素点和非骨架像素点之间类别不平衡的影响程度,值越大,影响程度越低。ACC 和F1 值越大,网络生成的骨架图像的整体结构越好,召回率和精度分数越高,生成骨架的网络性能越好,IoU 则显示了骨架定位的准确性。
为了更加直观地描述不同模型的性能,文献[12]提出了最小平均距离(AMD)来度量不同模型生成骨架的效果:
其中:D为生成骨架点和目标骨架点两两之间的欧氏距离;H为匈牙利算法,通过求解对应骨架点集之间的最大匹配问题来计算骨架相似度。AMD 值越低,生成骨架与原始骨架的相似性越高。
3.3 消融实验
为了验证所添加的模块的有效性,对添加模块后的网络结构进行定量分析,如表1 所示。从表1 可以看出,在基线网络上添加了HACM 模块和CCA 模块后,指标都有明显提升,ACC、Recall 和Precision指标分别为0.983 5、0.825 4 和0.845 5,IoU 指标的提升显示出本文算法在骨架定位上的优势,AMD 指标显示出生成骨架与目标骨架相似程度较高。
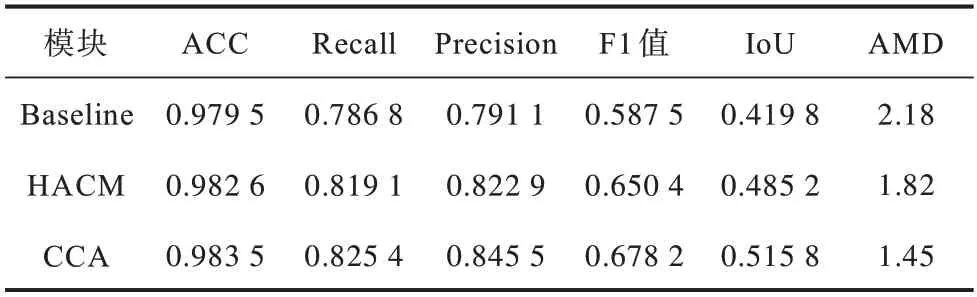
表1 不同网络结构的定量比较Table 1 Quantitative comparison of different network structures
图8 所示为在改进的pix2pix 模型上,鉴别器的卷积层分别使用Batch Normalization 和Spectral Normalization 进行模型训练过程中生成器和鉴别器损失函数的变化。其中,G_BCE 和G_L1 为生成器的二元交叉熵损失和L1 损失,D_real 和D_fake 分别为真实骨架图和生成骨架图的判别损失。从损失函数的振荡情况来看,使用谱归一化的鉴别器可以得到更加稳定的训练过程。
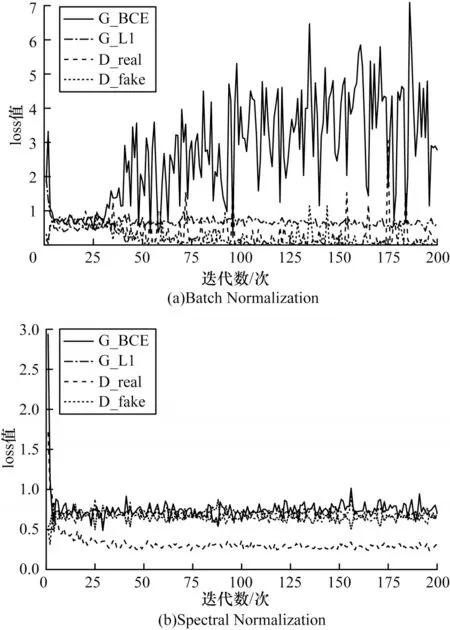
图8 骨架提取算法的局部对比图Fig.8 Local contrast map of skeleton extraction algorithms
表2 所示为不同激活函数实验结果的定量比较,可以看出修改激活函数为Leaky ReLU 的模型相较于仅使用ReLU 作为激活函数的模型在各项指标上都显示出更优的表现。

表2 不同激活函数的定量比较Table 2 Quantitative comparison of different activation functions
3.4 对比实验
在生成器的损失函数中,L1 Loss 用于生成图像的低频部分,超参数λ用于平衡Gan 损失和L1 损失。如图9所示,在λ=5的情况下,L1 Loss波动较为 剧烈,而λ在10、15、20 以及25 的情况下几乎没有明显区别,因此认为在本文任务中,λ取值不敏感,采用默认取值10。
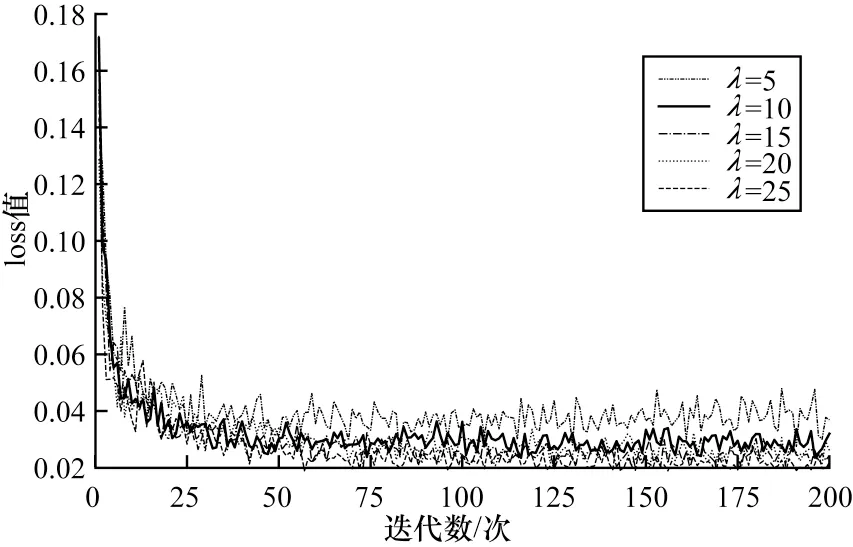
图9 不同λ 取值下L1 loss 的对比Fig.9 Comparison of L1 loss with different λ values
将本文算法与Z-S 细化算法、常庆贺等[5]提出的改 进Z-S 细化算法、FSDS算法、pix2pix cGAN算法以及应用于书法图像笔画分割的改进pix2pix 算法SSGAN 等现有的骨架提取算法进行比较分析,对比结果如表3 所示。

表3 不同算法在合成的书法字数据集上性能的定量比较Table 3 Quantitative comparison of the performance of different algorithms on synthetic calligraphy character dataset
从表3 可以看出,本文算法与其他算法相比在性能指标上有明显提升。IoU 的显著提高表明本文算法可以获得更准确的字符骨架定位。FSDS 算法生成笔画较粗,显示出更高的精确度和较优的AMD值,但IoU 和F1 值较低,表明其生成骨架在整体结构上的劣势。
图10 所示为书法字测试集在不同算法下的骨架提取效果,其中,从左到右依次为合成书法字、真实骨架、Z-S 细化算法、FSDS 算法、pix2pix cGAN、SSGAN、本文的算法。从图10 可以看出:Z-S 细化算法在交叉区域扭曲严重,丢失大量信息;基于全卷积网络的FSDS 生成的字符骨架优化了传统算法在交叉区域的扭曲,但生成笔画较粗,且有大量断点;pix2pix cGAN 算法极易产生笔画断裂的情况,难以获得相对平滑的骨架;SSGAN 算法十分接近原始骨架,但无法准确地分隔开粘连部分的骨架,更易产生脏背景的情况;采用本文算法的骨架提取结果最接近真实骨架,笔画连贯清晰,形态自然。

图10 不同算法在合成的书法字数据集上的骨架提取结果Fig.10 Skeleton extraction results of different algorithms on the synthesized calligraphy character dataset
为了评价网络的泛化性,随机拍摄了字帖上的书法字进行骨架提取,并将其与其他骨架提取算法的提取结果进行了比较。图11 所示为本文算法与传统基于邻域的骨架提取算法的局部对比。从图11中笔画的局部可以看出,改进Z-S 算法可以在保证骨架连通性的前提下去除冗余像素,但骨架交叉区域的扭曲情况无法改善。值得注意的是,在离线图片上虽然显示笔画粘连,但是交叉区域并非实际书写时的落笔的重心位置,本文的方法可以更好地捕捉到这类深层信息。

图11 骨架提取算法的局部对比图Fig.11 Local contrast map of skeleton extraction algorithm
不同算法在真实书法字上的骨架提取结果如图12 所示,其中,从左到右依次为书法字、Z-S 细化算法、FSDS 算法、pix2pix cGAN 算法、SSGAN 算法、本文算法。由于FSDS 的输出骨架较粗,图12 对FSDS 的输出结果使用Z-S 细化算法进行了后处理使其具有可读性。从不同算法的输出结果可以看出,本文算法可以成功地提取字帖书法字的骨架,不会产生过多的背景噪声,泛化能力较高。

图12 不同算法在真实书法字上的骨架提取结果Fig.12 Skeleton extraction results of different algorithms on real calligraphy characters
值得一提的是,与其他算法相比,本文算法有效地保留了书写过程中的运笔信息,例如起笔、收笔以及笔画转折处的细节信息,在笔画交叉区域也表现得非常好。
4 结束语
本文提出一种改进pix2pix 算法用于书法字骨架提取,通过添加HACM 和CCA 模块加深网络对图像深度理解,对鉴别器使用谱归一化来稳定模型训练过程。实验结果表明,该算法相较于传统的Z-S 算法和改进的Z-S 算法、FSDS 算法,可以获得离线字符丢失的书写过程信息,较好地解决现有算法在提取字符骨架时极易产生笔画断裂的情况。此外,F1、IoU 指标值的提升以及AMD 的降低,说明该算法可以有效地提高骨架提取的完整度和定位的准确性,在保持骨架图像结构信息基础上提升了模型的泛化能力,应用到真实的书法字数据集上可以达到提取完整自然骨架的效果。本文的训练数据集在字体类别上还存在一定的限制,后续将进一步丰富数据集以完善模型。
猜你喜欢
通信学报(2022年10期)2023-01-09
电子乐园·上旬刊(2022年5期)2022-04-09
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16
学生天地(2020年14期)2020-08-25
中国新技术新产品(2020年5期)2020-05-06
国防科技大学学报(2019年4期)2019-07-29
小天使·二年级语数英综合(2018年10期)2018-10-15
创新作文(小学版)(2017年5期)2017-05-13
系统工程与电子技术(2016年5期)2016-11-02
中国煤层气(2014年3期)2014-08-07
