
融合分散自适应注意力机制的多尺度遥感影像建筑物实例细化提取
2023-10-13 12:16江宝得许少芬
测绘学报 2023年9期
江宝得,黄 威,许少芬,巫 勇
1. 中国地质大学(武汉)计算机学院,湖北 武汉 430074; 2. 中国地质大学(武汉)国家地理信息系统工程技术研究中心,湖北 武汉 430074
建筑物数据在城市规划、灾害评估及数字城市建设等领域发挥着重要的基础数据作用[1]。近年来,随着对地观测技术的飞速发展,利用高分辨率遥感影像快速提取大范围建筑物数据成为当前研究的一个热点[2]。然而,遥感影像中建筑物种类繁多、尺度大小不一、形状各异、所处背景复杂,导致从遥感影像中自动提取建筑物十分具有挑战性[2]。传统方法大多基于遥感图像的浅层视觉特征,如光谱、纹理、几何及上下文信息等,通过人工设计特征等方法进行建筑物轮廓提取,其适应性受到很大的限制[3]。
近年来,深度学习算法特别是卷积神经网络(convolutional neural network,CNN)在图像分类、目标识别及语义分割等任务中取得了重大突破,已逐渐发展成为遥感影像建筑物自动提取的主流方法[4]。其中,文献[5]提出的全卷积网络(fully convolutional networks,FCN)及其改进算法[6]被广泛应用于遥感影像语义分割。然而,由于遥感影像中建筑物的纹理和尺度差异较大,FCN难以充分把握不同尺度的建筑物特征,导致FCN进行建筑物轮廓提取时容易出现漏提或提取结果不完整的情况[7]。为了充分利用多尺度特征图蕴含的语义信息,文献[8]提出了特征金字塔网络(feature pyramid network,FPN)模型,通过将分辨率低但具有较强语义信息的全局特征与分辨率较高但语义较弱的细节特征相融合,实现了语义信息的增强。但由于FPN结构所融合的两组特征图内部缺乏联系交流,且融合时忽略了浅层特征和深层特征之间的语义差距,最终导致分割结果中的小尺度建筑物丢失及建筑物边界模糊等问题。注意力机制的提出能够捕获不同空间或不同通道的卷积特征之间的依赖性,从而实现特征之间的全局关系分析。引入注意力机制能够有效地提高分割算法的性能,如文献[9]利用多任务并行注意力网络实现建筑物提取,有效地提高了模型的分割准确率;文献[10]将SE-attention[11]融入残差R-CNN(region convolutional neural network)模块中,提升了建筑物的边界信息;文献[12]设计了通道注意力挤压模块用于自适应的衡量并行多尺度路径中每个通道的权重,进而获得了多层次建筑物定位的细节信息及丰富的语义信息。尽管这些方法在建筑物提取方面取得了较好的效果,但是它们大多无法区分相连的建筑物,难以实现建筑物实例分割提取。
为了实现建筑物实例提取,实例分割的方法也被应用到建筑物的掩膜提取中。目前主流的实例分割方法可以分为两大类。一类是基于检测的方法,首先检测每个实例区域,然后在检测区域内进行掩码预测,最后将每个预测结果作为不同的实例输出。如文献[13]提出的Mask R-CNN,在Faster R-CNN[14]目标检测基础上添加了一个分割分支来实现实例分割;文献[15]提出了一种混合任务级联框架,将检测和分割交织在一起进行联合多阶段处理,有效提升了实例分割的效果。另一类是基于像素聚类的方法,首先预测每个像素的类别标签,然后使用聚类方法对它们进行分组以形成实例分割结果。如文献[16]提出的基于像素实例分割方法(single-shot instance segmentation with affinity pyramid,SSAP),采用语义分割和亲和力金字塔联合学习来生成多尺度实例预测;文献[17]利用像素嵌入来区别相连的实例。由于输入数据的特征图上往往存在大量特征平滑区域(即相邻像素点的分类标签一致),如果在高分辨率的特征图下对每一个像素点进行分类预测,会导致计算冗余。因此,为了平衡欠采样和过采样,实例分割算法通常选择一个较低的图像分辨率对像素点进行分类预测,如语义分割选用输入图像的1/8大小的特征图进行分割[5],实例分割采用大小为28×28的特征图[13]。而较低的分辨率会导致图像分割的边界不够清晰,出现边界模糊的问题。针对此问题,不少研究提出了一些改进方法,如文献[18]在分割网络的最后一层引入二次训练条件随机场作为后处理模块,对分割结果进行优化;文献[19]在分割网络中引入一个专注于边界信息处理的分支,通过训练联合边界感知损失的损失函数来获得分割结果;文献[20]引入了整体嵌套边缘检测模块来增强边界的提取;文献[7]设计了一种残差细化模块,用于进一步细化建筑物的边界。但是这些改进方法又大多难以同时兼顾不同尺度大小的建筑物,导致小尺度建筑物不同程度的漏检。
综上所述,虽然基于深度学习的方法在遥感影像建筑物自动提取方面已经取得了不少成果,但是现有方法在不同程度上仍难以同时兼顾不同尺度大小的建筑物实例精确提取,存在小尺度建筑物漏检、提取的建筑物轮廓边界模糊及无法区分单个建筑物实例等问题。针对这些问题,本文提出一种融合分散自适应注意力机制的多尺度遥感影像建筑物实例细化提取方法(multi-scale building instance refinement extraction convolutional neural network,MBRef-CNN),用于实现遥感影像中不同尺度大小的建筑物轮廓精确自动提取。通过MBRef-CNN在特征金字塔结构的骨干网络中引入分散自适应注意力机制,以聚合多尺度上下文信息,来保留不同尺度建筑物的特征,从而提高对小尺度建筑物的检测能力;并在实例分割分支中引入细化特征分支对建筑物的模糊边界进行处理,以提高掩膜边界的精度。
1 研究方法
本文提出的融合分散自适应注意力机制的多尺度遥感影像建筑物实例细化提取模型(MBRef-CNN)主要由3部分组成:分散自适应注意力机制的多尺度特征提取网络(split attention-feature pyramid network,SA-FPN)、区域候选网络(region proposal network,RPN)和边界细化网络(boundary representation network,BndRN),如图1所示。首先,将高分辨率遥感影像输入到SA-FPN中,通过SA-FPN来提取并融合建筑物的多尺度特征;其次,使用RPN从上一步的多尺度特征图中进行建筑物实例搜索,并采用ROI Align将特征图处理成特定大小;然后输入到分割分支中得到粗分割结果;最后,采用BndRN对粗分割结果的边缘像素点进行迭代精细化处理,直至得到高精度的掩膜结果。该模型可实现端到端的训练,能自适应遥感影像建筑物的多尺度特征,实现不同大小的建筑物实例提取,同时精细化建筑物实例的边界。下面对各组成部分进行详细介绍。
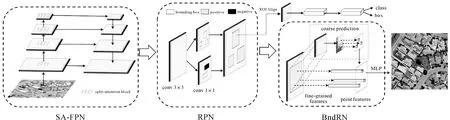
图1 本文提出的MBRef-CNN模型总体架构Fig.1 Overview of the proposed MBRef-CNN model
1.1 分散自适应注意力机制的多尺度特征提取网络(SA-FPN)
遥感影像中的建筑物尺度大小不一,普通的卷积网络在下采样过程中容易丢失小尺度的建筑物信息。为了增强卷积网络对全局信息与细节信息的综合感知,提高建筑物的检测精度,本文采用SA-FPN来获取建筑物的多尺度卷积特征。SA-FPN的结构如图2所示,该网络主要由3部分组成。第一部分为自底向上的特征提取结构,这一部分使用分散注意力块(split-attention block,SA block)[21]以重构模型的主干网络,该模块通过分组卷积来实现更细粒度的建筑物特征提取,并引入通道注意力机制[22]赋予特征通道以不同权重,从而增强建筑物特征的表达。此部分经由5个阶段的卷积操作逐步降低特征的分辨率,扩大卷积核的感受野,得到顶层全局特征,每个阶段输出的特征图分别为{C1,C2,C3,C4,C5},其相对于原始输入图像的尺寸比例分别为{1/2,1/4,1/8,1/16,1/32}。第二部分为横向特征连接路径,将第一部分输出的特征图{C2,C3,C4,C5}分别经过一个1×1卷积,用于将通道数量统一到256维,得到{M2,M3,M4,M5},这些在不同感受野层次下的特征图分别具有建筑物的低级视觉特征和高级语义特征信息。第三部分为自顶向下的特征融合路径,通过将高层特征与底层特征融合,实现图像全局特征与细节特征的充分感知以及多尺度特征的耦合,从而提高小尺度建筑物的分割提取精度。

图2 SA-FPN结构细节Fig.2 Structure details of SA-FPN
另外,第一部分中的分散注意力块的具体结构如图3所示。将输入的特征图使用分组卷积分为32个大组,并对每个大组应用不同卷积核参数学习组别间多样化细节特征。每个大组内部先采用1×1卷积降低通道数减少计算量,再将其按通道数拆分为两个小组。对每个小组进行3×3卷积升维增加特征表达的健壮性。每个小组经过一系列映射运算后再进行通道注意力操作(如图4所示)。其过程是:首先,将两个拆分小组相加融合,并进行全局池化,得到1×1×C的特征图;其次,将这个向量输入全连接层生成1×d的向量;然后,再将此向量通过两个r-SoftMax函数[23]计算得到两个d维的权重向量;最后,将得到的两个权重向量分别与两个原始分支split 1和split 2相乘,从而实现对两个分支的特征图进行自适应注意力机制的逐通道权重设置。由于不同通道的特征图对建筑物的特征表达程度不同,因此,通过引入通道自适应注意力机制能为通道赋予不同权重,增强建筑物特征的表达能力;而分组卷积策略符合人眼视觉观察的分治机制,能够实现对特征图进行更细粒度的信息提取,从而提高对小尺度建筑物的检测识别能力。
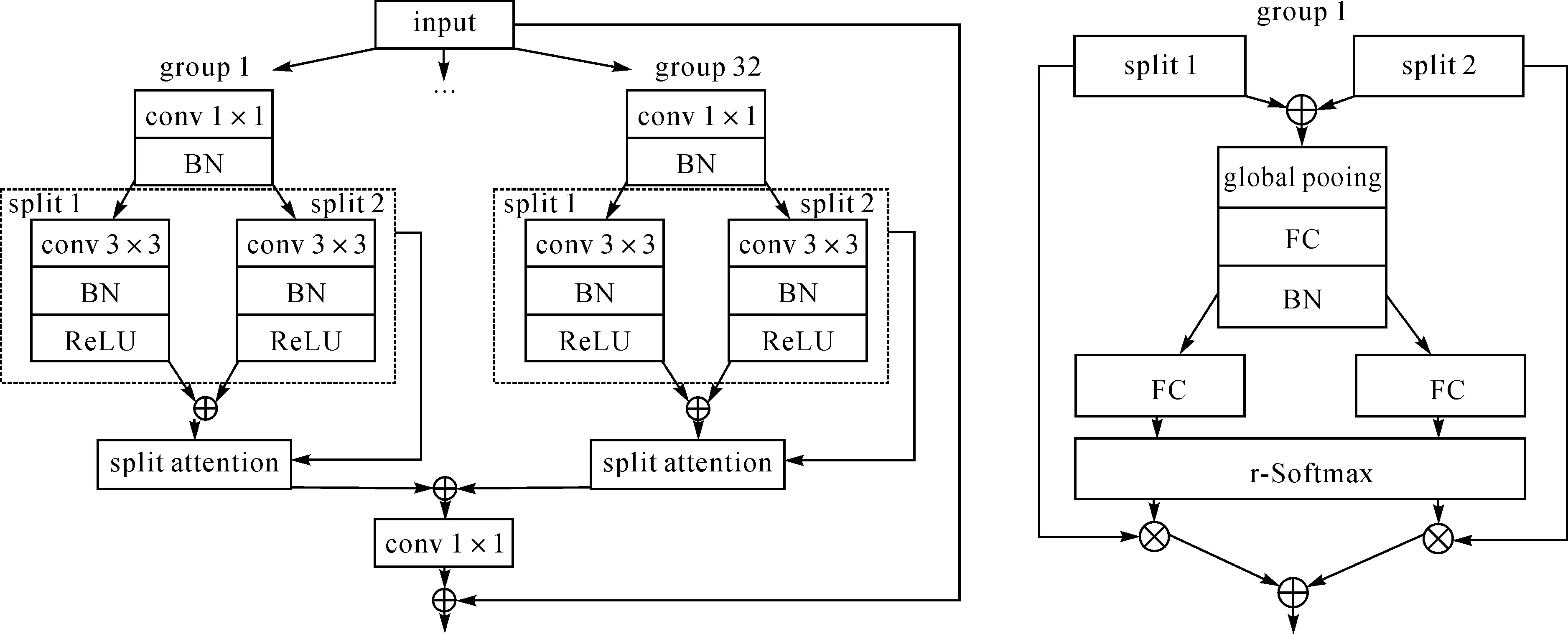
图3 分散组卷积块 图4 通道自适应注意力机制 Fig.3 Split-attention block Fig.4 Channel adaptive attention mechanism
1.2 区域候选网络(RPN)
通过SA-FPN提取遥感影像不同尺度大小的建筑物特征图之后,进一步采用RPN来定位遥感影像中的建筑物位置,其结构如图5所示。RPN引入了锚点框(bounding box)的概念,即对特征图上的每个像素生成k个大小和长宽比都不相同的预测框。通常情况下,k默认为9,分别为3种大小和3种长宽比组合而成。为了兼顾小尺度建筑物目标对象的提取,本文将锚点框的大小设置为8、16、32,长宽比设置为1∶1、1∶2、2∶1。将每个像素上的k个锚点框分别输入到两个并行的卷积分支中,并对锚点框的分类进行评分和对锚点框的位置进行回归计算。经过卷积计算后,分类分支输出2k个参数,分别表示预测框的建筑物(positive)和背景(negative)得分;回归分支输出4k个参数,即框的中心点坐标(x,y)和框的宽(w)、高(h)的位移修正值。若特征图的大小为W×H,则整个特征图上会生成W×H×k个锚点框。最后,这些生成的候选锚点框将用于后续的建筑物分类、检测及分割提取。

图5 RPN的结构Fig.5 Architecture of RPN
1.3 边界细化网络(BndRN)
通过RPN检测得到建筑物实例位置后,本文进一步采用BndRN来获取建筑物的精确分割掩膜。该模型结构由一个粗预测分支网络和一个特征细化分支网络组成,如图6所示。首先,将大小为C×W×H规则的特征图输入到粗预测分支网络中,经过全卷积层计算出每个建筑物实例的粗特征图结果(例如28×28)。其次,为了细化边界,将粗特征图输入到特征细化分支网络中,从粗特征图上对不确定的边缘点进行随机采样,并将上采样得到的边缘点特征与SA-FPN输出的P2特征图对应位置的细节特征相联合,得到边缘点的表征特征向量。最后,用一个conv1×1的MLP(multiLayer perceptron)网络对边缘点的表征特征向量进行判断,更新插值后的粗预测结果。重复上述优化过程直至输出的预测结果图的分辨率与输入的遥感图像分辨率一致。

图6 边界细化网络结构Fig.6 Boundary refinement network structure
其中,对不确定边缘点进行随机采样方法如下:如果需要得到N个随机点进行分类修正,则首先在特征图上随机采样kN个点(k>1);然后引入超参数β(0<β<1),保留kN个点中的βN个分类最不明确的点(前后景得分值各为0.5);最后剩下的(1-β)N个点从全图随机选取。本文中k为3、β为0.75。通过以上随机选点的策略,能够保证得到的随机点在侧重于不确定的边界区域的同时保留一定程度的全局覆盖性,如图7所示。

图7 不同的点采样方法Fig.7 Different point sampling strategies
另外,对BndRN的计算复杂度分析可知,在目标分辨率是M×M,粗分割分辨率为M0×M0的条件下,BndRN的预测分析时间复杂度为Nlog2(M/M0),其中,N为每次随机采样点的个数,远远小于直接在M×M的分辨率下作预测。例如,本文的目标分辨率为256×256,起始分辨率为28×28,每次随机采样28×28个点做预测细化,则只需要28×28×3次预测,远小于256×256。因此,本文采用的方法能在较低计算量的条件下实现建筑物掩膜的精细化预测。
1.4 损失函数
本文采用的损失函数为多任务损失函数[14]
Ltotal=Lcls+Lbox+Lmask
(1)
式中,Lcls是分类损失;Lbox是回归框损失;Lmask为平均二值交叉熵损失。Lcls的计算公式为
(2)
即目标与非目标的对数损失,其中,pi是锚点框预测为目标的概率。Lbox的计算公式为
(3)

Lmask为mask分支上的损失函数,输出大小为K×m×m,其编码分辨率为m×m的K个二进制mask。对于一个属于第k个类别的RoI,Lmask仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)

(1-y)×ln(1-sigmoid(x))]
(4)
式中,1k表示当第k个通道对应目标的真实类别时为1,否则为0;y表示当前位置的mask的label值,为0或1;x则是当前位置的输出值,sigmoid(x)表示输出x经过sigmoid函数[13]变换后的结果。
2 试 验
2.1 试验数据及环境
为了验证本文方法的有效性及泛化性,分别在WHU aerial imagery dataset[25]数据集和Inria aerial image labeling dataset[26]数据集上进行建筑物提取试验。其中,WHU aerial imagery dataset数据集为覆盖新西兰基督城450 km2范围的航拍影像,影像的空间分辨率为0.75 m,像素大小为512×512,包含187 000栋不同用途、纹理、大小和形状的建筑物,其中训练集图片4736张,含有建筑物13万余栋,测试集2416张,含有建筑物4万余栋。Inria aerial image labeling dataset数据集是一个用于城市建筑物检测的遥感图像数据集,由360张大小为5000×5000的航拍正射图像组成,影像的空间分辨率为0.3 m,该影像数据集占地810 km2,分布在10个不同的城市,涵盖人口密集的地区和人口稀少的森林城镇,对于评估模型的泛化能力具有一定的价值。为了进行公平的比较,本文对数据集进行随机划分,其中,155张图像用于训练,25张图像用于验证,其余180张图像用于测试,并且将训练和验证图像裁剪成512×512像素大小,统一按照Microsoft COCO的形式进行组织和试验。
本文试验环境采用的操作系统为Ubuntu 18.04.5 LTS,GPU硬件配置为两块10 GB显存的Nvidia GeForce RTX3080,同时使用CUDA11.1进行计算加速,所有模型均在PyTorch框架下进行编码、训练和测试。试验超参数设置如下:每个GPU的batch size设置为4,使用SyncBN方法[27]实现全局样本归一化;训练时首先采用预热学习策略,以预热因子为0.001的线性预热方式进行1000次训练迭代并逐步上升到设置的初始学习率0.025,随后采用按需调整学习率策略,按照1×10-4的权重衰减率和1×10-4的偏差进行学习率衰减,直至损失收敛;使用动量SGD优化器进行梯度优化,动量参数设置为0.9。模型在训练之前使用随机裁剪与缩放、随机仿射变换、随机变换RGB通道值的方法进行了数据增强,以增加模型的健壮性。通过采用以上超参数和训练策略,本文模型约进行65个epoch训练即达到损失函数收敛。
2.2 评价指标
在WHU aerial imagery dataset数据集上进行试验时,本文基于每个像素的平均精度(average precision,AP)指标来定量衡量本文所提出的模型的性能。AP值可通过积分计算精确率-召回率(precision-recall,P-R)曲线与坐标轴所围成的下方面积得到。精确率(Precision)和召回率(Recall)的计算公式为[28]
(5)
式中,TP指真正例(对正样本的真实预测);FP指假正例(将负样本预测为正);TN为假负例(将正样本预测为负);FN为正负例(对负样本的真实预测)。这些指标可通过计算预测值与真实标签之间的交并比(intersection over union,IoU)获得,只有IoU大于某一阈值时,建筑物才被标记为正样例。在本文的试验中,目标检测分支的IoU定义为建筑物真实标注框和预测矩形检测框的相交部分占相并部分的比例,分割分支的IoU则定义为真实建筑物掩膜和预测建筑物掩膜的相交部分占相并部分的比例。本文的试验选取了4个不同交并比阈值设置下的AP值作为评价模型检测和分割性能的指标,分别为AP50、APS、APM、APL。其中AP50为IoU阈值设置为0.5时的AP值,可用于衡量模型对建筑物的整体检测和分割能力;APS、APM、APL分别表示小尺度建筑物(检测框或掩膜像素面积小于32×32)、中等尺度建筑物(检测框或掩膜像素面积位于32×32到96×96区间)、大尺度建筑物(检测框或掩膜像素面积大于96×96)的AP0.50:0.95值,计算方式为
(6)
在Inria aerial image labeling dataset数据集上进行试验时,选择了两个评价标准,即总体精度(overall accuracy,OA)和交并比IoU从数值上评价模型的有效性。其中,OA为正确预测的像素数与所有测试集中像素总数的比值
(7)
式中,N(correct_pixels)是正确预测像素的数量;N(total_pixels)是测试像素总数的数量。IoU度量预测和目标标签之间的相关性,广泛应用于二进制语义分割任务。这里,IoU定义为
(8)
式中,A是预测;B是目标标签。IoU=0表示A和B不重叠,1则表示A和B相同。
2.3 试验结果分析
本文将MBRef-CNN模型与目前表现较优的主流实例分割算法进行对比试验,如Mask R-CNN模型、VoVNetV2-99 CenterMask模型、ResNet101 FPN构成的CenterMask模型以及Cascade Mask R-CNN模型。其中CenterMask是单阶段无锚点的代表模型,其分割分支中的空间注意力模块能将注意力集中于建筑物要素上;Cascade Mask R-CNN使用了级联检测器,具有更好的检测精度。以上模型均使用相同的试验环境在WHU aerial imagery dataset数据集上进行训练,并在测试数据集上分别对建筑物的目标检测框和分割掩膜进行了定量指标评价。
表1给出了不同算法在建筑物目标检测框上的平均精度,从中可以看出,本文提出的MBRef-CNN在AP50上超过普通Mask R-CNN约3.2%,超过使用级联检测器的Cascade Mask R-CNN约2%,而比使用不同骨干网络的CenterMask方法均高出8%左右的精确度。比较APS、APM、APL3个指标可以看出,MBRef-CNN在APS指标上表现最好,分别比CenterMask及普通Mask R-CNN的方法高8%左右,比Cascade Mask R-CNN也高出1.26%,说明MBRef-CNN在小建筑物的提取上性能良好,精度远高于其他对比方法;另外,MBRef-CNN在APM、APL上也均有不错的表现。图8给出了建筑物实例分割的部分可视化结果,图中分别选了位于郊区、居民区、工业区等不同环境下的建筑物遥感影像,由图8中可以看出,在这几种不同场景下,除了本文提出的MBRef-CNN方法外,其他算法均存在错检或漏检的情况(见图8上框选部分),同时也说明本文方法对不同大小尺度的建筑物尤其是小尺度建筑物的检测识别性能提升较高。

表1 建筑物目标候选框平均像素精度指标评价
为了验证本文提出的建筑物掩膜边界细化模型的分割效果,进一步对上述对比模型的掩膜精确度进行分析结果见表2。由表2可知,本文方法在掩膜分割的精确率上AP50值为88.477%,远高于其他方法,比第二的Cascade Mask R-CNN高约2%,比其余方法高4%~9%不等。比较APS、APM、APL3个指标,MBRef-CNN在APS指标上仍然表现最好,比其他方法的平均像素精度高3%~9%不等。值得注意的是,本文方法的APM为81.854%,也取得了最好的精度表现,考虑到在上述建筑物目标候选框的精确度比较中,MBRef-CNN算法在中尺寸的建筑物的提取精度略低于VoVNetV2-99 CenterMask,说明本文模型中的边界细化网络(BndRN)有效地提高了建筑物掩膜的分割精度。图9给出了建筑物实例分割的部分可视化结果,图中分别选了位于郊区、居民区、工业区等不同环境下的建筑物遥感影像,由图9可知,本文模型的分割结果对建筑物的几何特征保留良好,具有更精细的边界特征。
另外,为了验证本文方法的泛化性,进一步在Inria aerial image labeling dataset数据集进行建筑物提取试验,相关参数设置采用与WHU aerial imagery dataset数据集相同的配置。图10列出了本文模型在几个具有挑战性的住宅区预测结果的部分例子,涵盖了不同密度、规模、形状和周围环境的建筑物。第一行为建筑物影像原始图片数据,第二行为本文方法的提取结果。通过观察模型预测结果以及计算模型的总体精度OA和交并比IoU可知,对于Inria aerial image labeling dataset数据集,模型的总体精度OA达到了96.51%,IoU为76.82%,表明本文方法依然取得了良好的提取效果,而且由图10中可以看出,即使建筑物被部分障碍物(如树木、道路等)的阴影遮挡,也能实现较好的分割提取。

图10 Inria aerial image labeling dataset的建筑物提取结果实例Fig.10 Examples of building extraction results on Inria aerial image labeling dataset
最后,为了验证本文方法中SA-FPN和BndRN两个改进模块对建筑物分割提取精度的贡献程度,进一步对这两个模块进行消融试验。消融试验以ResNet101 FPN Mask R-CNN为基准方法,分别在基准方法上加入SA-FPN、BndRN及两者的综合MBRef-CNN。消融试验的结果见表3,从试验结果可以看出,在基准方法上加入SA-FPN模块后,其检测框和分割掩膜的AP50指标相比于基准方法均提升了约3%,APs指标提升了约7%,由此可以推断出本文的SA-FPN模块能充分把握建筑物尺度变化幅度大这一特点,能够有效提高小尺度建筑物的提取精度。在基准方法上加入BndRN模块后,其分割掩膜的APS、APM、APL指标比基准方法均提升了约2%,由此可以推断出BndRN模块能在分割时纳入更多细节特征以提升分割掩膜的精细度。从综合以上两者改进的MBRef-CNN方法提取结果来看,其AP50、APs、APm指标值比单一的SA-FPN或BndRN指标值都高,说明两者综合后的MBRef-CNN能进一步提升建筑物分割提取精确度,但在APL指标方面,MBRef-CNN只比SA-FPN精度略高,不及BndRN的指标值。这说明SA-FPN是上述评价指标的主要贡献者,在其所产生的耦合多尺度特征图上,BndRN能纳入更多的细节特征作为分割判别依据,从而获得更高的分割精确度。

表3 消融试验指标评价
图11展示了本文提出的BRef-CNN方法在更多场景下的试验结果。其中,第1行和第3行为带掩膜标签的真实值,第2行和第4行为本文方法的预测值。由图11中可以看出:①本文方法建筑物实例分割的综合性能良好,对小尺度的建筑物具有良好的感知能力,有效避免了错检、漏检的情况发生;②本文方法有效地保持了建筑物边界的精细化特征,减少了其他分割算法中普遍存在的边界模糊、平滑等问题;③从本文方法对密集居民区、复杂工业区、郊区大尺度建筑物的实例分割结果可以看出,本文方法在复杂场景下仍能取得良好的建筑物轮廓实例分割提取效果。

图11 不同场景中建筑物实例分割试验结果Fig.11 Experimental results of building segmentation in different scenes
3 结 论
遥感影像建筑物准确、高效的自动提取在城市规划、灾害评估、GIS数据更新及数字城市建设等方面有着广泛的用途。本文针对现有遥感影像建筑物提取方法难以兼顾不同尺度大小的建筑物实例精确提取,存在小尺度建筑物漏检、提取的建筑物轮廓边界模糊及无法区分单个建筑物实例等问题,提出一种融合分散自适应注意力机制的多尺度遥感影像建筑物实例细化提取模型(MBRef-CNN)。该模型主要由3个部分组成:融合自适应注意力机制的遥感影像多尺度特征提取网络(SA-FPN)、区域候选网络(RPN)和边界细化网络(BndRN)。其中,提出的SA-FPN模块在传统的FPN骨干网络中引入了分组卷积和自适应通道注意力机制,以实现更细粒度的建筑物特征提取和多尺度建筑物特征的感知,减少了小尺度建筑物目标信息在特征图中无法有效表达的可能性。提出的BndRN模块基于不规则多尺度迭代分割理论,能在较少的计算量情况下获得更精确的掩膜边界,并通过不均匀采样策略使得细化采样点的权重偏向于像素值有较大方差的区域,从而能更好地利用边界信息进行边界细化。另外,该模型可实现端到端的训练,能自适应融合遥感影像建筑物的多尺度特征,实现不同尺度大小的建筑物实例提取,同时精细化建筑物实例的边界。在WHU aerial imagery dataset数据集上,通过与现有主流方法进行对比试验表明,本文方法的建筑物提取精确度高于其他表现优秀的主流分割算法,在多尺度建筑物提取上表现出良好的综合性能,尤其在小尺度建筑物提取上具有更明显的精度优势,并且在Inria aerial image labeling dataset数据集上也表现出较好的泛化性能。目前,本文的多尺度遥感影像建筑物特征提取仍然依赖于特征金字塔结构,该结构具有较大的计算复杂度,后续将考虑发展轻量级的骨干网络,以提高模型的实时性及可迁移性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
制造技术与机床(2017年10期)2017-11-28
太空探索(2016年5期)2016-07-12
科技资讯(2016年21期)2016-05-30
时代英语·高三(2014年5期)2014-08-26
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
雕塑(2000年2期)2000-06-22
