
面向文本检测的NMS加速器设计
2023-10-12 01:11屠程力陈章进
计算机工程与设计 2023年9期
屠程力,陈章进,2,乔 栋
(1.上海大学 微电子研究与开发中心,上海 200444;2.上海大学 计算中心,上海 200444)
0 引 言
对自然场景中的文本图片进行批量检测是自动驾驶和场景分类等工业应用的基础,鉴于自然场景中的文本有宽高比差异大和背景光照复杂等特点,使用神经网络提取特征并输出多个高置信度候选框的深度学习检测方法受到广泛欢迎。该方法根据候选框提取的方式不同分为区域建议,如SegLink[1]、RRD[2]和分割融合,如EAST[3]、SPC-Net[4]。鉴于神经网络输出的是多个置信度不同的候选框,因此通过非极大值抑制算法,即NMS(non-maximum suppression)作为后处理算法[5],将交并比较高而置信度较低的候选框删去,其伪代码[6]如下,其中N为交并比阈值,B为检测框集,S为检测框对应的置信度集,D为保留的目标框集。
NMS algorithm
(1)D←{}
(2) whileB≠empty do
(3)m←argmaxS
(4)M←b[m]
(5)D←D∪M;B←B-M
(6) forb[i] in B do
(7) if then iou (M,b[i])≥N
(8)B←B-b[i];S←S-s[i]
(9) end if
(10) end for
(11) end while
随着拍摄像素的提高,经过神经网络产生的检测框数由数十个上升到数百个,NMS为高复杂度的贪婪算法,其耗时与检测框数的平方成正比,因此后处理耗时的比重不断提高。以EAST算法为例,NMS算法的效果如图1(a)所示,检测算法各部分的耗时如图1(b)所示,NMS作为后处理算法占总检测时间的41%,严重阻碍了检测算法的实时性。

图1 NMS算法效果和耗时分析
本文优化候选框的排序方法和单次交并比的计算公式,实现低耗时和低功耗的NMS加速器,可以作为异构加速器与神经网络检测并行运算。
1 相关工作
针对NMS算法延迟过大的问题,文献[7]将后处理与神经网络中的池化层相结合,利用神经网络专用框架进行加速,充分利用高效软件库的接口,但该方法缺少泛用性,需要针对特定文本数据集进行训练。为此,在不改变神经网络结构的前提下,文献[8]针对语义分割后,检测框紧密围绕目标文本的特点,将交并比较高的检测框以置信度为权重进行坐标合并,在精简的检测框集合上进行NMS后处理,但该方法的初衷是降低后处理的计算复杂度,本质仍是基于CPU的顺序运算,其延迟较高无法满足实时性的要求。
目前,对复杂算法进行加速不再局限于CPU平台[9],神经网络各阶段的加速平台开始向TPU[10]和FPGA[11]转移,受到上述研究影响,对NMS算法进行加速的通常做法是在计算结构上进行改良,以图2(a)中的3个目标和8个检测框为待处理示例,3种常见的加速方法如图2所示。其中图2(b)为文献[12]与卷积加速一同提到的高并行NMS方法,通过36个计算单元同时计算出8个检测框之间的交并比,并将交并比与阈值的比较结果存入8×8的布尔矩阵,最后采用逻辑“与”的运算删去冗余检测框。但该方法需要的计算单元与检测框的平方成正比,同时需要额外的存储空间存放中间数据。因此为了改进计算单元消耗过大和中间数据存放过多的问题,文献[13]提出了基于PBBT(position-based bit table)的加速方法,如图2(c)所示,先将检测框以置信度从高到低排序,第一次迭代时,以首个检测框为滑动窗口起始点,将该框与剩下的检测框依次计算,其结果存储在PBBT表中,用1 bit状态位表示与起始点相比是否冗余并附加检测框的存储地址,以此大幅节约中间数据的存储空间,第二次迭代时,以第二个“1”状态所在的检测框为起始点重复上一轮操作,直到遍历完所有“1”状态框。该方法采用多个滑动窗口来保证每次迭代能同时进行,但需要对检测框提前排序,导致计算延迟较高。
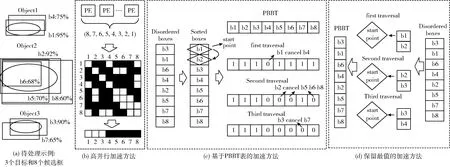
图2 3种常见的加速方法
为了避免提前排序带来的延迟,文献[14]提出的保留最值办法,如图2(d)所示,针对置信度大小排列为乱序的检测框,加入一个最值模块,该模块存储前一次迭代中置信度最高的n个检测框,下次迭代从n个检测框中挑选置信度次高的检测框,并以该检测框为起点,逐个比较次高检测框与其它框的重合程度。鉴于该方法的起始点由前次迭代产生,因此不同迭代之间无法并行计算,另外,容易存在置信度次高框在前一次迭代中满足交并比条件,归类为冗余框后删除,造成最值模块未命中下一个起点,需要重新迭代寻找高置信度检测框的步骤。
2 面向文本检测的加速方法
在采用深度学习方法检测文本的算法中,神经网络输出的是批量随机位置的检测框,而随着检测框数的逐步提升,以文献[13]为代表的加速方法并行度较高但需要提前排序,其计算复杂度为O(N2), 不适合文本检测任务,而文献[14]的方法能处理乱序排列的检测框,但其并行度较低,无法充分利用嵌入式设备并行计算的优势。
本文首先分析文本检测检测框特点,如图1(a)所示,待消除的冗余框紧密包围目标框,同时冗余框在横坐标的位置偏离不超过目标框的长度,在纵坐标的位置偏离不超过目标框的宽度。因此考虑在比较交并比之前,先将检测框基于位置范围分类,而检测框之间的交并比可以在各类之间并行计算,提高整体并行度。按位置范围将两个检测框分为同类的依据如式(1)、式(2)所示,其中x1、y1、L和W分别为前一个检测框的左下坐标和长宽,x2、y2为下一个检测框的左下坐标,不等式左右两边为该类的4个位置阈值,存入阈值表
(1)
(2)
为了保证数据能够被高效存储,借鉴文献[13]的PBBT(position-based bit table)方法,也采用附带存储框地址的位表来记录检测框状态。但由于需要记录类别信息,因此将比特位扩展到7位,其中前5位用来记录该框所属的类别,后2位记录该检测框经交并比比较后的3种状态,其中写入“0”表示该框交并比超过阈值被删除且后续不进行其它操作,“1”表示作为起始框与其它框进行比较,“2”表示该框交并比低于阈值并进入下一轮比较。
以图2(a)为待处理示例,本文方法如图3所示,一共分为两阶段。第一阶段如图3(a)所示,根据检测框的坐标位置将检测框分类,将各类的位置范围存入阈值表,将该框所属的类别写入PBBT,PBBT的存储顺序与检测框的存储地址为一对一映射,因此无需改变检测框的存储空间,在计算交并比时,直接通过PBBT中存放的地址索引下一个检测框的坐标信息。

图3 面向文本检测的加速方法
第二阶段为图3(b)所示,分类完成后进入检测框的交并比计算阶段,该阶段需要包含两次迭代过程:
第一次迭代按类别进行并行计算,同一类别内的比较采用文献[13]中单个起始点并行计算多个检测框的模式,但处理状态位的方式不同:所有检测框的状态初始化为“2”,第一步将首个存储框的状态修改为“1”,以该框为起始点与其它框比较交并比,若交并比高于阈值N则不修改检测框状态,若低于阈值则将检测框删去并将状态位修改为“0”。第一步中同时比较置信度大小,若起始点置信度低于检测框而交并比高于阈值,则状态修改后交换状态,并将该检测框为起始点与剩余的检测框比较交并比,保证状态“1”所在检测框为对应目标的置信度最高位置。第一步结束后,若存在状态“2”的检测框,则进行第二步,将首个状态“2”修改为“1”框并与剩下的状态“2”进行比较。重复上述步骤,直到不存在状态位“2”时为止。以图3(b)中的类别3为例,第一步中b3将b8状态修改为“0”,第二步中的b5将b7状态修改为“0”,此时不存在状态“2”检测框。
第二次迭代,比较所有状态“1”之间的重复率,删去超过阈值的检测框,此时剩余检测框数较少,无需通过修改状态“2”的方式保留中间数据。如图3(b)中的b2检测框删去b5检测框。
基于位置范围的分类本质是将目标周围的检测框视为同类,但同类检测框可能混入属于其它目标的检测框,因此需要第二次迭代,在按类删去检测框的基础上比较剩余检测框之间的交并比,此时剩余的检测框少,计算复杂度低。若从内存中取出坐标并计算所消耗的时间视为一次计算延迟,以图1(a)中3个目标和8个检测框为例,为了完成一次NMS算法,文献[13]在比较前需要冒泡排序,所需的延迟为67次。文献[14]按最值模块全部命中计算,一共需要32次延迟。而本方法在第一阶段中,基于位置范围的分类需要8次延迟,在第二阶段中,类间和类内的计算可以同时进行,因此本文一共需要12次延迟,计算复杂度大幅降低。
3 硬件结构
3.1 系统结构
面向文本检测的NMS加速器由DDR存储器、控制模块、阈值表THT(threshold table)、位表PBBT和计算单元组(computation unit)组成。整体结构如图4所示。
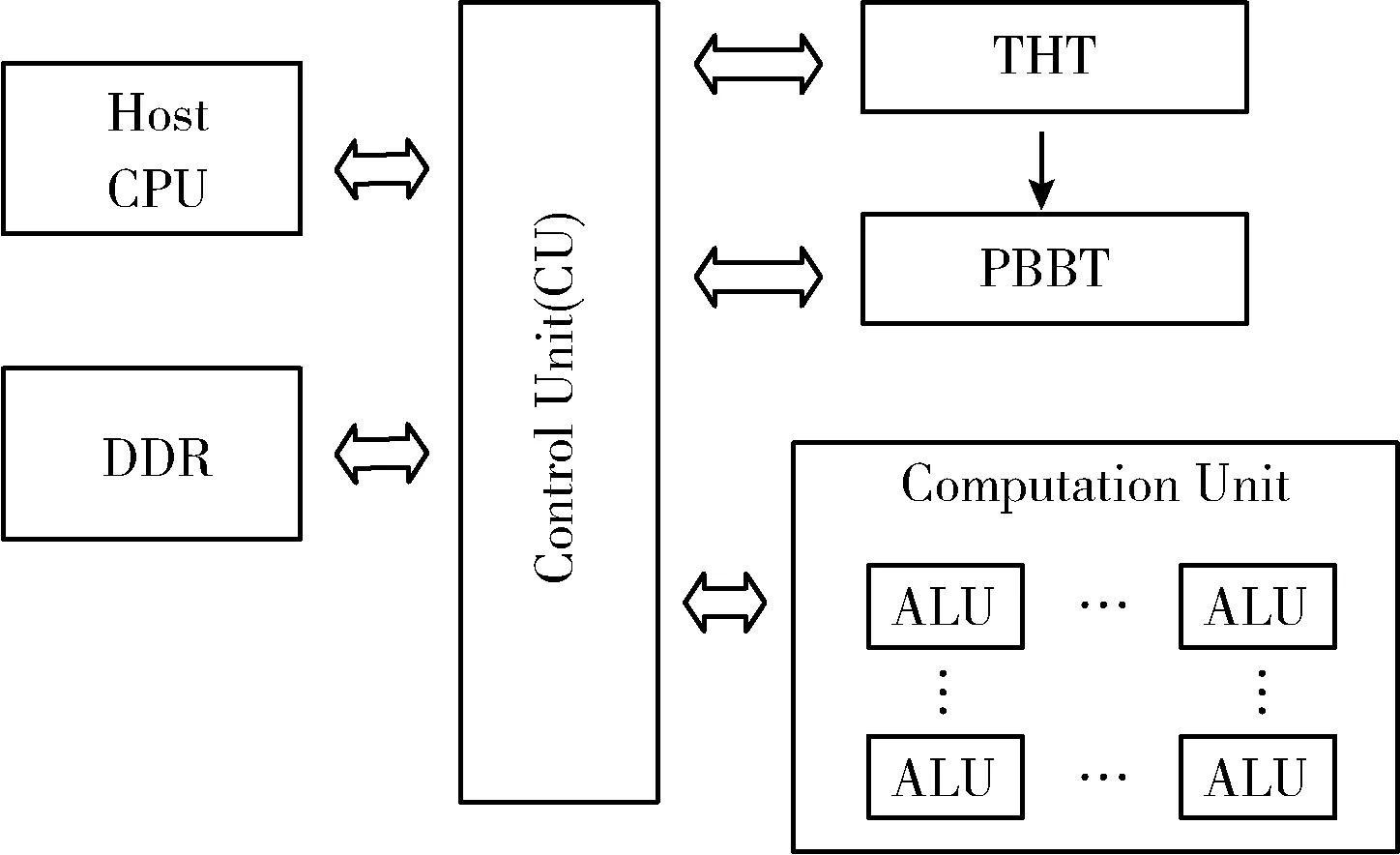
图4 系统结构
DDR存储器存放检测框的坐标信息和置信度。控制单元根据PBBT中存储的状态位是否为“1”,决定迭代起始点并分配检测框数据,计算单元组负责在各类检测框之间并行计算交并比,同时比较交并比是否超过阈值、检测框之间是否完全覆盖和起始点置信度是否为较大值。
为了更好地说明阈值表和PBBT如何存储对应数据,将实验过程的中间数据进行展示,如图5(a)所示,阈值表用来记录基于位置范围分类的阈值信息,XL、XR、YU、YD和C分别表示该类位置区域的左右横坐标范围、上下纵坐标范围和类号。如图5(b)所示,PBBT负责记录检测框的状态、分类和存储地址,Key、C、S分别表示偏移地址、类号和状态。如图5所示,该实验一共分为18类检测框,偏移地址为“01”的检测框为“02”类的起始检测框,偏移地址为“02”的检测框交并比高于阈值被删除,偏移地址为“FF”的检测框为待比较检测框。

图5 阈值表和位表的存储示例
加速器启动时,THT和PBBT被初始化,其中PBBT上的状态位初始化为“2”,其它位清零,控制单元迭代所有检测框并基于位置范围分类:
首先,第一个检测框视作第一类,将该框的阈值范围存入THT,将该框的偏移地址和类号写入PBBT。其次将下一个检测框与第一类的位置阈值进行比较,若检测框的左下点坐标在阈值范围内则视作同类,否则视为第二类并将该类阈值写入THT。重复上述操作,直到整张图片的检测框都遍历一遍,此时完成基于位置范围的检测框分类。在ICDAR2015数据集上的实验结果表明,分类后的类别数不超过20个,检测框数不超过900个,因此THT的长度设为32,PBBT的长度设为1024。
基于位置范围的分类完成后,控制单元负责派发各检测框数据,考虑到各类之间的交并比可以并行计算,因此结合数据集的实际情况将计算单元组的列数设为8,每列负责一类,最大支持8类检测框的并行计算。同时将行数设为16,保证在确定起始点后,同类的检测框之间,支持16个剩余检测框与起始点同时比较交并比。控制单元根据PBBT中的偏移地址将“1”和“2”状态的检测框数据发送到计算单元组,最大不超过128个,同时根据返回的比较结果更新PBBT数据。
3.2 针对交并比的计算单元优化
ALU为计算单元组中的基础模块,负责计算两个检测框之间的交并比并比较置信度大小。以检测框B1和B2为例,比较两者交并比是否大于阈值的计算如式(3)所示
(3)
上述公式中关于面积的计算需要4个乘法器和一个除法器来完成,鉴于计算单元决定了加速器的整体功耗和资源消耗,而乘法和除法操作占用的硬件资源远高于其它运算,因此考虑对不等式两边进行缩放来减少乘法和除法运算。
将检测框B1和B2的位置分别用左下点坐标 (x1,y1)(x2,y2), 框宽w1w2和框高h1h2表示。首先,观察到交并比公式中两框的并面积与最大面积之间存在式(4)所示的大小关系,因此采用式(4)对式(3)的分母进行缩放。再对不等式两边开方,并将新的分母移到不等式右侧,此时的不等式如式(5)所示
(A(b1)+A(b2)-A(b1∩b2))≥max(A(b1),A(b2))
(4)
(5)
若忽略开方运算,此时不等式不包含除法操作,但仍需四次乘法才能比较阈值,鉴于存在两值平均值大于等于两值开方的定理,即式(6)。为了满足定理条件,通过式(7)将两框并面积用坐标和宽高来表示,此时可以将不等式的左侧按式(6)进行缩放,同时将框最大面积的也用坐标和宽高来代入,即式(8)
(6)
A(b1∩b2)=(min(x1+w1,x2+w2)-max(x1,x2))×(min(y1+h1,y2+h2)-max(y1,y2))
(7)
max(A(b1),A(b2))=max(w1×h1,w2×h2)
(8)

(9)

ALU模块负责比较交并比和置信度,引入额外约束会大幅增加计算单元的面积。因此考虑在实现完全覆盖约束时,将式(9)中的部分条件判断复用,减少硬件资源的消耗。复用后的约束条件如式(10)、式(13)所示,当4项公式全部成立时,b2是被b1完全覆盖的小尺寸框,b2成为待删去的冗余框。完整的判断逻辑如图6所示,ALU单元的输入是待比较候选框的左下坐标、框宽和框高,输出交并比和置信度的比较结果。将交并比的判断条件复用后,计算是否完全覆盖只需额外的两个与门、一个后门和两个比较器,进一步降低计算单元对硬件资源的消耗
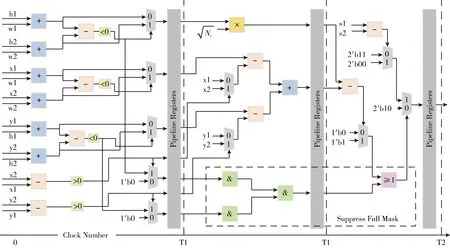
图6 三级流水线的ALU单元
x1+w1≥x2+w2&x1≥x2
(10)
x2+w2≥x1+w1&x2≥x1
(11)
y1+h1≥y2+h2&y1≥y2
(12)
y2+h2≥y1+h1&y2≥y1
(13)
在时序约束方面,鉴于乘法器的延迟较大,而硬件实现过程中有平衡各周期延迟的要求,因此将ALU单元划分为三级流水线结构,如图6所示,第一个周期完成加减法和初始条件判断,延迟相近的双与门级联和乘法器安排在第二个周期,置信度和交并比的比较在最后一个周期,此时各个关键路径的延迟最小。
鉴于计算单元同时包含置信度的比较,ALU采用双比特输出表示计算结果:控制模块负责分发起始框和检测框的数据,将两框的左下坐标、框宽和宽高输入ALU,经过计算后,输出“10”表示该检测框不满足交并比条件,控制单元将PBBT对应的状态位设为“2”;输出“00”表示两框的交并比超过阈值或两框满足完全覆盖条件,该检测框为需要删除的冗余框,PBBT的对应状态位设为“0”;输出“11”表示额外满足检测框置信度较大的条件,此时该检测框成为新的起始点,PBBT的状态位设为“1”,起始点对应的状态位设为“0”,完成一次交并比计算。
4 实验与结果
为了评估硬件资源消耗情况,本文选择PYNQ-Z2平台,并以ZYNQ-XC7Z020芯片为核心部署面向文本检测的NMS加速器,通过Verilog语言描述硬件模块后,在vivado2019.1环境中进行布局布线,工作频率设为100 MHz,并通过内置时序分析报告,确定加速器各条关键路径满足时序要求。加速器的资源消耗见表1,其中BRAM主要完成阈值表和PBBT的存储,LUTRAM存放中间比较数据,与文献[14]相比LUT占用减少12%,BRAM减少41%,说明通过多次缩放来优化计算公式,减少计算交并比所需的乘法器与除法器和重用判断条件等优化方法能够有效降低硬件资源的消耗。
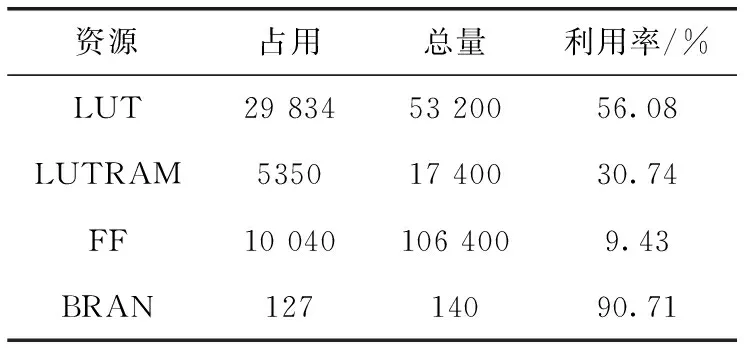
表1 NMS加速器资源消耗情况
本文采用多次不等式缩放来简化单次交并比的计算过程,该方法本质上放宽了交并比的约束条件,保留了部分交并比在阈值附近的冗余框,为了探讨是否能通过降低交并比阈值来删去上述冗余框,采用计算机模拟缩放算法,设置阶梯阈值进行实验,其中文本检测前置算法采用EAST方法,文本数据集为ICDAR2013水平文本数据集,其结果见表2,缩放后的NMS与标准NMS相比,在阈值为0.4时准确率降低0.2%,而在阈值为0.8时准确率降低5.1%,验证了降低阈值能减少不等式缩放损失的猜想,但阈值过高和过低都会带来误检和漏检的问题,因此本文NMS的阈值设为0.6。

表2 交并比阈值对准确率的影响
为了进一步评估FPGA平台上本文加速器的文本检测效果,我们对检测指标、计算延迟和性能等方面进行评估,实验现场如图7所示。

图7 实验现场
首先将EAST文本检测算法在ICDAR2013数据集上的处理结果预先存在SD存储卡中,并将PYNQ-Z2上的PS处理器作为验证实验的数据控制器,通过AXI-Lite总线读取候选框的位置信息,最后通过Jupyter Notebook添加测试任务并输出实验结果。
为了比较不同后处理方法后的文本检测指标,我们在检测框乱序存储的基础上,后处理方法分别选择CPU实现的高准确率NMS、本文的加速器方法和文献[12]的模拟方法。实验结果见表3,相比误差最小的NMS-CPU,本文方法的准确率降低2.4%,召回率降低0.8%,同时与比文献[13]相比,准确率提高1.2%,召回率提高2.1%。说明虽然缩放过程会损失一定的准确率,但本文引入完全覆盖的约束条件,能删去部分遗漏的冗余框,提高检测准确率。

表3 不同方法在ICDAR2013数据集上的效果
为了评估面向文本的NMS加速器性能,分别挑选文本目标数为5、10和15的待处理图片,采用本文方法、CPU上实现的NMS算法和NMS的优化方法LANMS[3]作为后处理方法,比较三者的计算延迟,实验结果见表4。本文加速器的性能比NMS-CPU方法提高67倍,比LANMS方法提高38倍。说明本文能通过检测框分类的方法降低计算复杂度,通过优化计算公式的方法能减低单次交并比计算所需的周期。同时,按列并行计算异类检测框和列内并行计算同类检测框的计算结构有效,能通过提高NMS计算并行度的方式减低延迟,在多目标的图片上的延迟较小。

表4 不同目标框数的计算延迟
为了衡量本文加速器与不同平台实现NMS算法的优势,我们选择同类后处理加速文献进行比较,鉴于文献中给出的实验候选框数最多不超过1000且最少不低于500,因此将处理725个检测框时的数据作为本文结果,比较结果见表5,对比数据来自对应文献。本文方法针对NMS的计算速度比CPU平台的文献[15]方法提高63倍,比同为FPGA平台上的文献[16]和文献[14]分别提高7.1倍和1.8倍,同时硬件功耗与上述方法相比最低,仅为3.28 W。与TSMC工艺的文献[13]相比算法延迟较大,但该方法要求检测框的存储按置信度从大到小排列,不支持乱序检测框。上述对比说明,本文提出的面向文本检测的NMS加速器延迟较低,能作为并行加速器提高文本检测算法的实时性。

表5 NMS算法在不同平台的性能比较
5 结束语
本文提出一种低延迟和低功耗NMS加速器设计方法,首先,该方法基于位置范围对检测框分类,通过各类并行和类内并行的方式提高加速器的运算效率。其次,通过多个缩放公式优化交并比的计算方法,减少计算所需的乘法器和除法器,并补充完全覆盖的约束条件,改善缩放造成的小尺度候选框保留问题。最后,复用交并比的判断条件,并设计三级流水线的计算单元,进一步减少硬件资源消耗较少。实验结果表明,在100 MHZ的FPGA平台上,本文提出的NMS加速器相比CPU平台计算性能提高67倍。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
核科学与工程(2021年4期)2022-01-12
少先队活动(2021年6期)2021-07-22
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
计算机应用(2018年5期)2018-07-25
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
轴承(2015年2期)2015-07-25
