
融合注意力机制的人体关键姿态估计
2023-10-12 01:10薛晶霞刘才华
计算机工程与设计 2023年9期
冯 霞,薛晶霞,刘才华+
(1.中国民航大学 计算机科学与技术学院,天津 300300;2.中国民用航空局 智慧机场理论与系统重点实验室,天津 300300)
0 引 言
在特定人体动作识别[1-6]中,不同人体关键姿态(即不同人体关键点)的重要程度各不相同。如在检测是否存在货物暴力分拣行为时,与动作高度相关的手腕关键点识别比眼睛、鼻子等其它关键点识别更重要。而大多数现有人体姿态估计方法将人体所有关键点同等对待,如文献[7]通过融合多尺度特征增大局部区域感受野,改善整体关键点识别;文献[8]采用3个反卷积生成高分辨率热图,提升整体关键点的识别性能;文献[9]基于文献[8]框架,使用PixelShuffle上采样方法进一步提升了整体关键点识别性能。以上模型忽略了不同关键点的重要程度不同这一重要因素,而且在特征提取阶段对特征信息利用不充分。
针对以上问题,本文提出了一种融合注意力机制的人体关键姿态估计方法。首先在下采样-上采样两阶段融入注意力机制,引导模型在通道和空间维度自适应关注特征区域中的重要信息,弱化不重要的特征信息;其次提出一种代价敏感损失函数,使模型在学习过程中能聚焦于代价更大的目标关键点,提升模型对目标关键点的识别性能。在COCO公共数据集和CargoSorting数据集上的实验结果表明,本文方法在少量增加模型参数前提下,提升了目标关键点和整体关键点识别准确率。
1 方法设计
本文模型框架如图1所示。该框架主要包括3个模块。①浅层多尺度特征增强模块。本文采用Resnet50骨干网络提取特征。为了降低背景信息干扰和下采样导致特征空间信息的损失,在网络浅层采用空间注意力机制,帮助模型提取有效的空间信息。在L1~L4的Bottleneck模块中融入通道注意力机制,帮助模型提取重要的通道特征;②深层多通道特征选取模块。由于上采样操作会大幅降低特征通道维度,易造成有效特征丢失问题,因此在上采样之前加入通道注意力机制,帮助模型学习不同通道特征的重要程度;③代价敏感损失模块。在模型训练过程中,增加与特定动作相关的目标关键点的误识别代价,使得人体姿态估计模型在训练时更专注于目标关键点,从而提升模型对目标关键点的识别精度。
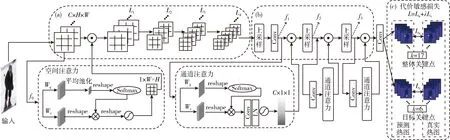
图1 人体姿态估计模型框架
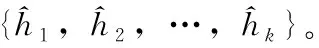
1.1 注意力机制模块
通道注意力机制通过建模特征通道间的关系,帮助模型筛选出对任务更加重要的特征[10]。在人体姿态估计中,模型输出的每个通道表示某个关键点的识别结果。提取与关键点相关的特征以及减少上采样阶段通道信息丢失非常重要。图1中(b)部分的fi(i=1,2,3) 表示特征,f1~f3特征的通道维度分别为1024、256、128,最后一层卷积层输出通道维度为17和6,可见上采样和最后生成热图的卷积操作,会使特征通道维度下降2~21.3倍,造成通道特征信息丢失和利用不充分。因此,本文在特征提取阶段和上采样生成关键点热图阶段融入通道注意力机制,模型分别如图1的(b)部分和图2所示。其中,图1(b)表示在最后卷积层和生成f2、f3特征之前融入通道注意力,图2表示添加通道注意力后的Bottleneck结构,本文以此结构作为骨干网络的第一个Bottleneck来构造L1~L4层。
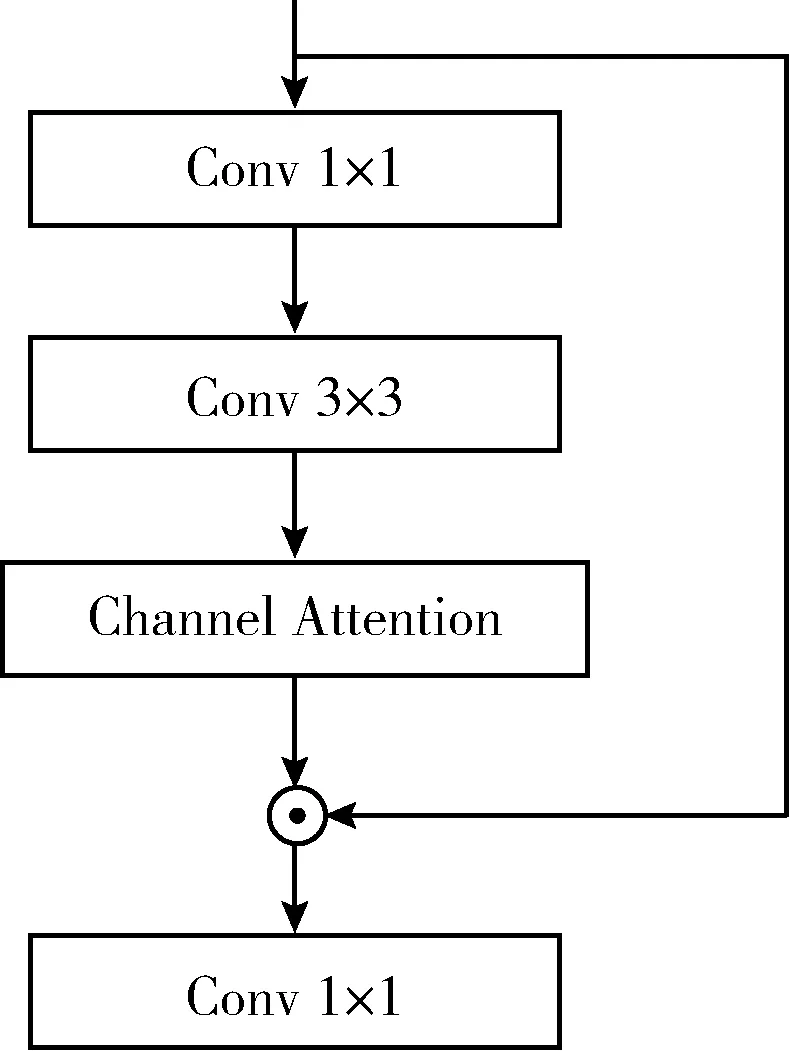
图2 融入通道注意力机制的Bottleneck
具体的通道注意力机制如式(1)~式(3)所示。首先利用1×1卷积Wq和Wv将输入特征fi(i=1,2,3) 生成分辨率不变的Q、V特征,其中,Q特征通道被压缩为1,V特征通道降为输入特征的一半。然后将两个特征分别reshape为N×1×1,C/2×N,N=H×W。为了弥补Q特征通道被完全压缩造成的信息损失,使用softmax对Q特征进行增强,并与V特征相乘后经过1×1卷积、LayerNorm和sigmod激活函数生成通道权重参数,如式(3)所示。最后将通道权重参数与输入特征fi相乘得到通道注意力图
Q=Wq(fi)
(1)
V=Wv(fi)
(2)
Ac=σ1(Wq(σ2(R1(Q)))×R2(V))
(3)
其中,Ac表示生成的通道权重参数,R1和R2表示两个reshape操作,σ1为sigmod激活函数,σ2为softmax激活函数,Wq和Wv为1×1卷积操作。
空间注意力机制通过建模特征内各像素间的关系,帮助模型关注更加重要的特征区域[11]。受文献[12]的启发,在特征提取网络之前加入注意力机制网络可以改善背景信息对关键点识别的影响。因此,本文在骨干网络第一个特征层之后加入空间注意力机制,增强重要特征信息,减弱不重要的特征信息,帮助模型更好地提取多尺度浅层特征,模型如图1(a)所示。
具体的空间注意力机制如式(4)~式(6)所示。与通道注意力机制相似,首先利用1×1卷积Wq、Wv将输入特征f0转为通道为原通道一半的特征Q和V,通过全局平均池化将V特征压缩为C/2×1×1来表示输入特征的全局信息,V特征的空间分辨率保持不变。然后将两个特征分别reshape为1×C/2和C/2×N,N=H×W。 为了弥补Q特征池化造成的信息损失,使用softmax对Q特征进行增强,并与V特征相乘后经过reshape和sigmod激活函数生成空间权重参数,如式(6)所示。最后将该参数与输入特征f0相乘得到空间注意力图
Q=Wq(f0)
(4)
V=Wv(f0)
(5)
As=σ1(R3(σ2(R1(GAP(Q))))×R2(V))
(6)
其中,As表示生成的空间权重参数,R1~R3为reshape操作,GAP表示全局平均池化操作,其它符号与式(3)含义相同。
本文使用的注意力机制对特征处理时,在空间维度和通道维度内均保持较高分辨率,没有对特征进行很大程度压缩,这对人体关键点识别具有重要意义[13,14]。此外,采用softmax-sigmod组合方式增强特征非线性表达,进一步提升了模型对关键点的识别。
1.2 代价敏感损失模块
本文的代价敏感损失旨在提升模型对目标关键点的关注度,模型如图1(c)所示。主要包括两个部分,整体关键点损失和目标关键点损失。整体关键点是指标注的所有人体关键点(本文共17个),目标关键点是指和特定动作识别高度相关的人体关键点(本文指和暴力分拣动作相关的人体左右手腕、手肘和脚踝共6个关键点)。可以通过代价敏感因子调整目标关键点损失在整个损失函数中的权重比例,从而控制目标关键点的代价敏感程度。代价敏感损失计算如式(7)所示
L=Ln+λLc
(7)
式中:L为模型的总损失,Ln为整体关键点损失,Lc为目标关键点的损失,λ为代价敏感因子。由式(7)可知,当λ的值为0时,L退化为标准的人体姿态估计损失,当λ的值逐渐增大时,目标关键点损失在总损失中的比例也相应增大。λ可实现平滑调节目标关键点损失占比。
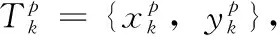
(8)
式中:(x,y) 用来表示关键点k的真实热图的位置,σk表示关键点k的尺度自适应方差。
人体姿态估计模型生成的整体关键点对应的热图损失Ln可由式(9)表示
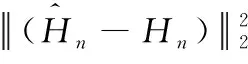
(9)
同样的方法,可计算目标关键点的预测热图和真实热图,目标关键点的热图损失如式(10)所示
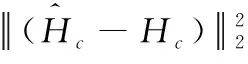
(10)
式(7)中,Ln项等同看待每个人体关键点,追求模型在整体关键点上的识别性能。在实际应用中,不同关键点重要性是动作依赖的,基于此,本文的代价敏感损失L在包含整体关键点损失的基础上,增加与特定动作相关的目标关键点损失,突显目标关键点的重要性。通过代价敏感因子λ值控制整体关键点损失和目标关键点的损失在总损失中的比重,λ值越大,意味着目标关键点损失占比越大,目标关键点识别错误产生的代价更大,模型对目标关键点的关注度越高。
2 实验验证
2.1 数据集
本文采用的数据集包括Miscrosoft COCO公共数据集和自建的CargoSorting数据集。其中COCO数据集包含约165 K张图像和150 K个人体目标实例。每个实例被标注了17个关键点,分别为鼻子、右眼、左眼、右耳、左耳、右肩、左肩、右肘、左肘、右手腕、左手腕、右臀、左臀、右膝、左膝、右脚踝、左脚踝。实验在超过118 K张图像的训练集上训练,在5 K张图像的验证集上进行验证。

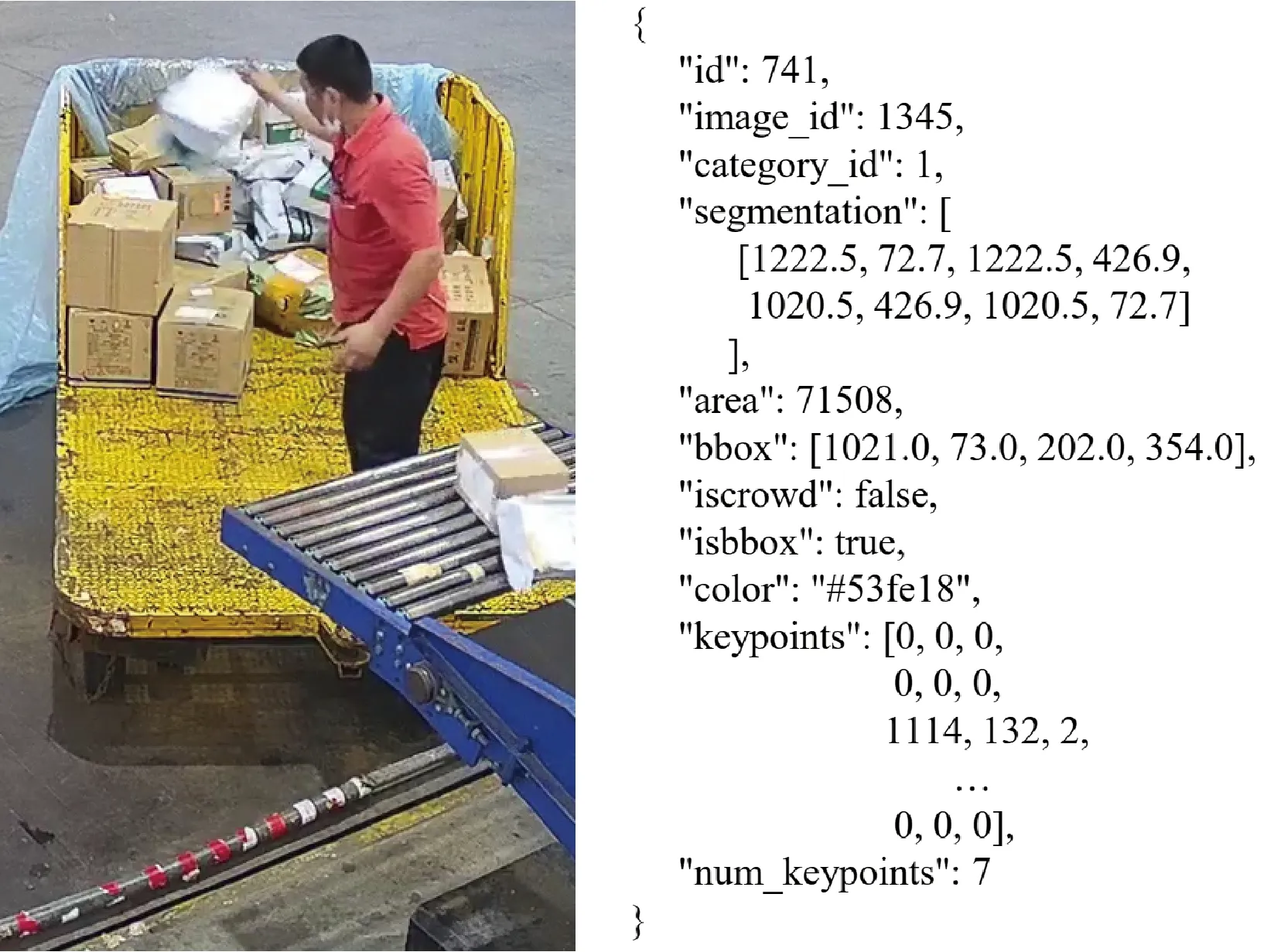
图3 CargoSorting数据集标注示例
2.2 实验性能评价指标
本文采用关键点相似性OKS(object keypoint similarity)评估模型性能,其计算如式(11)所示
(11)
式中:di表示关键点i的预测位置和真实位置之间的欧氏距离,S2表示人体的面积,ki表示类型为i的关键点归一化因子,vi表示真实关键点i的可见性,vi大于0表示关键点可被观察到,小于0表示该关键点不可见。
实验结果采用平均准确率AP(average precision)和平均召回率AR(average recall)表示。其中,AP是OKS值分别为0.5,0.55,0.60,…,0.95时所有准确率的平均值,AP50和AP75是OKS的值分别为0.5和0.75时的平均识别准确率,APM是中型目标检测精度,APL是大型目标检测精度,AR是OKS值分别取0.5,0.55,0.60,…,0.95时所有召回率的平均值。
2.3 实验设置
模型的输入大小为256×192,输出整体关键点热图大小为17×64×48,目标关键点热图大小为6×64×48。实验过程采用随机缩放、随机旋转和图像翻转的数据增强方式,ResNet50和YOLOv3-spp预训练模型都基于公开数据集ImageNet。实验采用Adam优化器进行优化,COCO数据集的初始学习率为0.001,CargoSorting数据集的初始学习率为0.0001,学习率衰减系数为0.1,在MSCOCO数据集和CargoSorting据集上的总训练周期分别为270和100,批训练大小都为32。
2.4 实验结果分析
为了评估本文模型的性能,表1和表2分别给出了本文算法和对比算法在两个数据集上的识别结果。表中k=17表示模型在17个整体关键点上的识别性能,k=6表示模型在6个目标关键点上的识别性能。在代价敏感损失的λ值设为0.3时,模型的性能最优。本文λ值选取是通过后续实验验证取得。
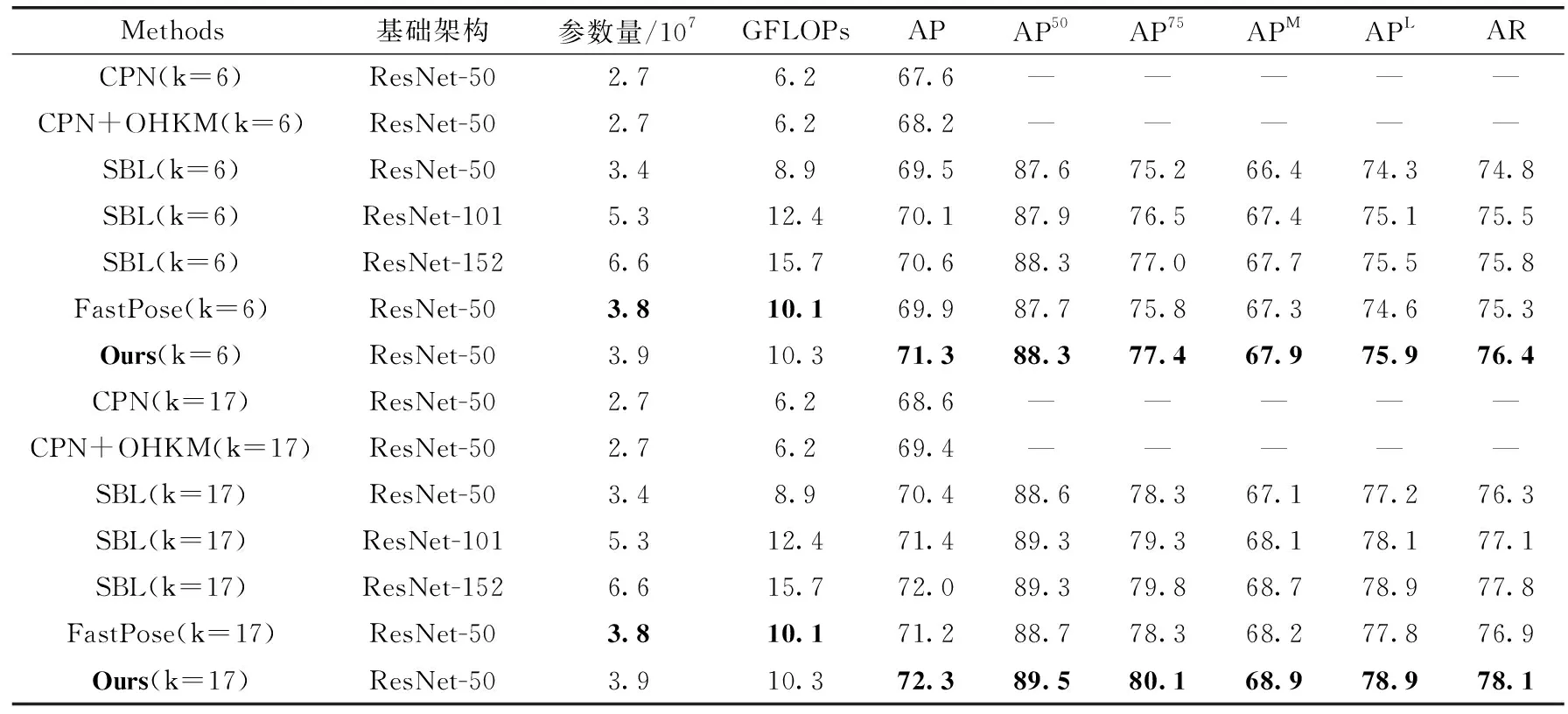
表1 本文方法和基准方法在COCO 2017验证集上的实验结果比较
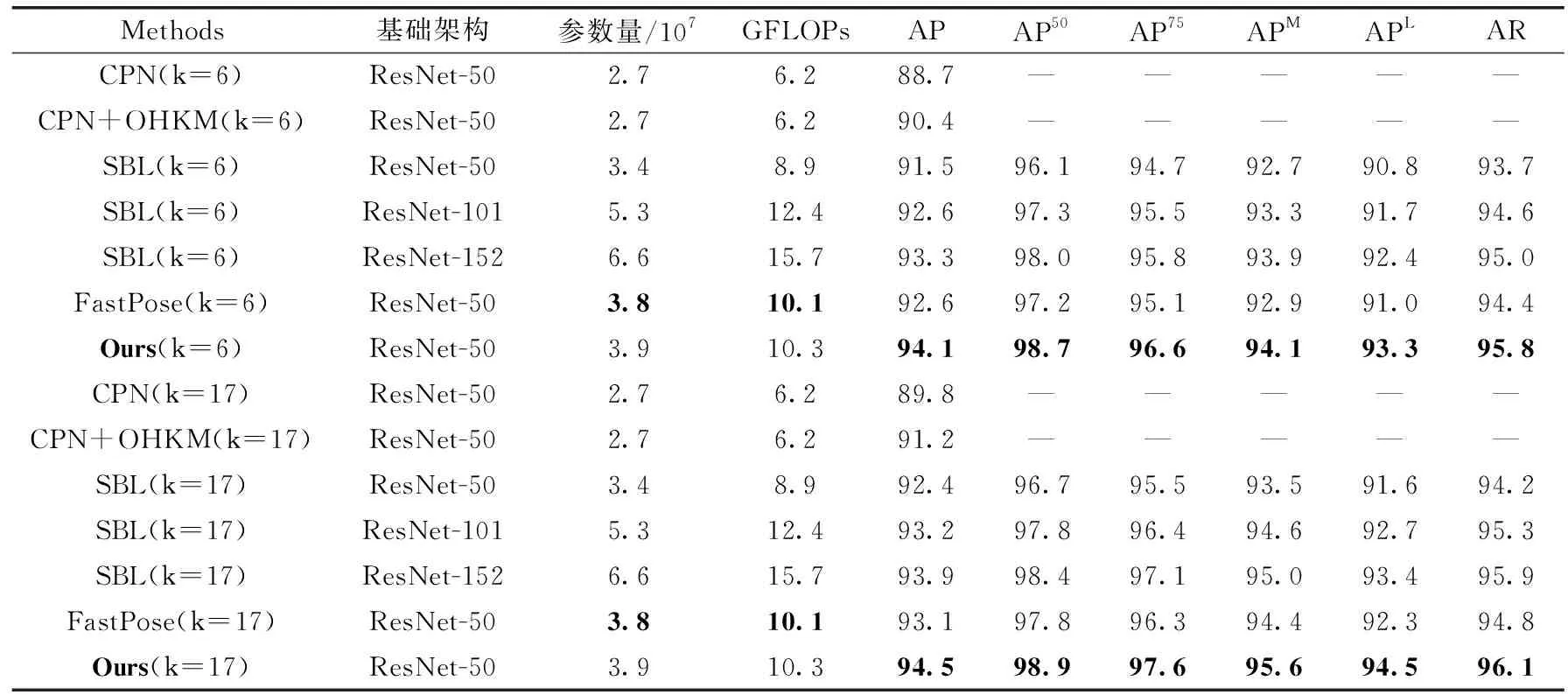
表2 本文方法和基准方法在CargoSorting数据测试集上的实验结果比较
从表1可以看出,本文方法与其它方法相比,提高了目标关键点和整体关键点的识别性能。具体地,相较于FastPose方法,本文方法在少量增加模型参数的前提下,目标关键点和整体关键点的AP指标分别提高了1.4%和1.1%,AP50、AP75、APM、APL以及AR指标也都有所提高。与CPN相比,目标关键点和整体关键点AP指标均提高3.7%,与CPN+OHKM相比,AP分别提高3.1%和2.9%,模型参数量增加了1.2。与采用不同骨干网络的SBL相比,目标关键点AP分别提高了1.8%,1.2%和0.7%,整体关键点AP分别提升了1.9%,0.9%和0.3%。当SBL的骨干网络采用ResNet-101和ResNet-152时,本文方法还能够减少模型的参数量。
表2是本文方法在CargoSorting数据集上与其它模型的对比结果,与FastPose方法相比,本文方法对目标关键点和整体关键点的AP分别提升了1.5%和1.4%,其它指标也都有不同程度的提高。与CPN相比,目标关键点和整体关键点AP指标分别提高5.4%、4.7%,与CPN+OHKM相比,AP分别提高3.7%和3.3%。与采用不同骨干网络的SBL相比,目标关键点AP分别提高了2.6%,1.5%和0.8%,整体关键点AP分别提升了2.1%,1.3%和0.6%。
本文方法在模型下采样阶段融入空间注意力和通道注意力促使模型关注重要特征区域,丰富了空间和通道特征表示,采用通道注意力弥补上采样导致特征通道信息损失,增强了模型的高分辨率表达能力。最后在模型训练过程中引入代价敏感损失,通过更多关注目标关键点的误识别代价,显著提升与特定动作相关的目标关键点识别准确率和整体关键点识别准确率。表1和表2的实验结果验证了本文方法的有效性。
代价敏感参数λ值的选择对模型识别结果影响不同,为了选择合适的参数值,将λ值设为0,0.1,0.2,…,1,并分别在两个数据集上进行实验,图4、图5分别给出了在COCO数据集和CargoSorting数据集上的实验结果。图4和图5都表明,当λ取值为0.3时,人体关键姿态估计模型的结果最优。
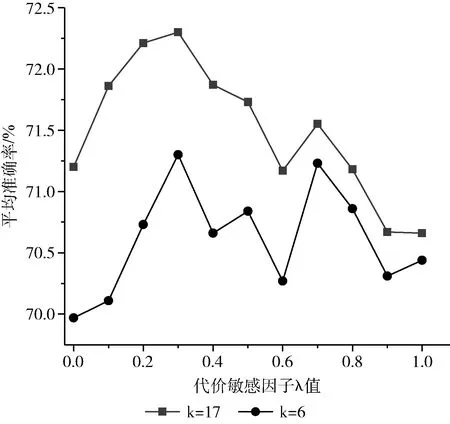
图4 不同λ值在COCO数据集上的结果
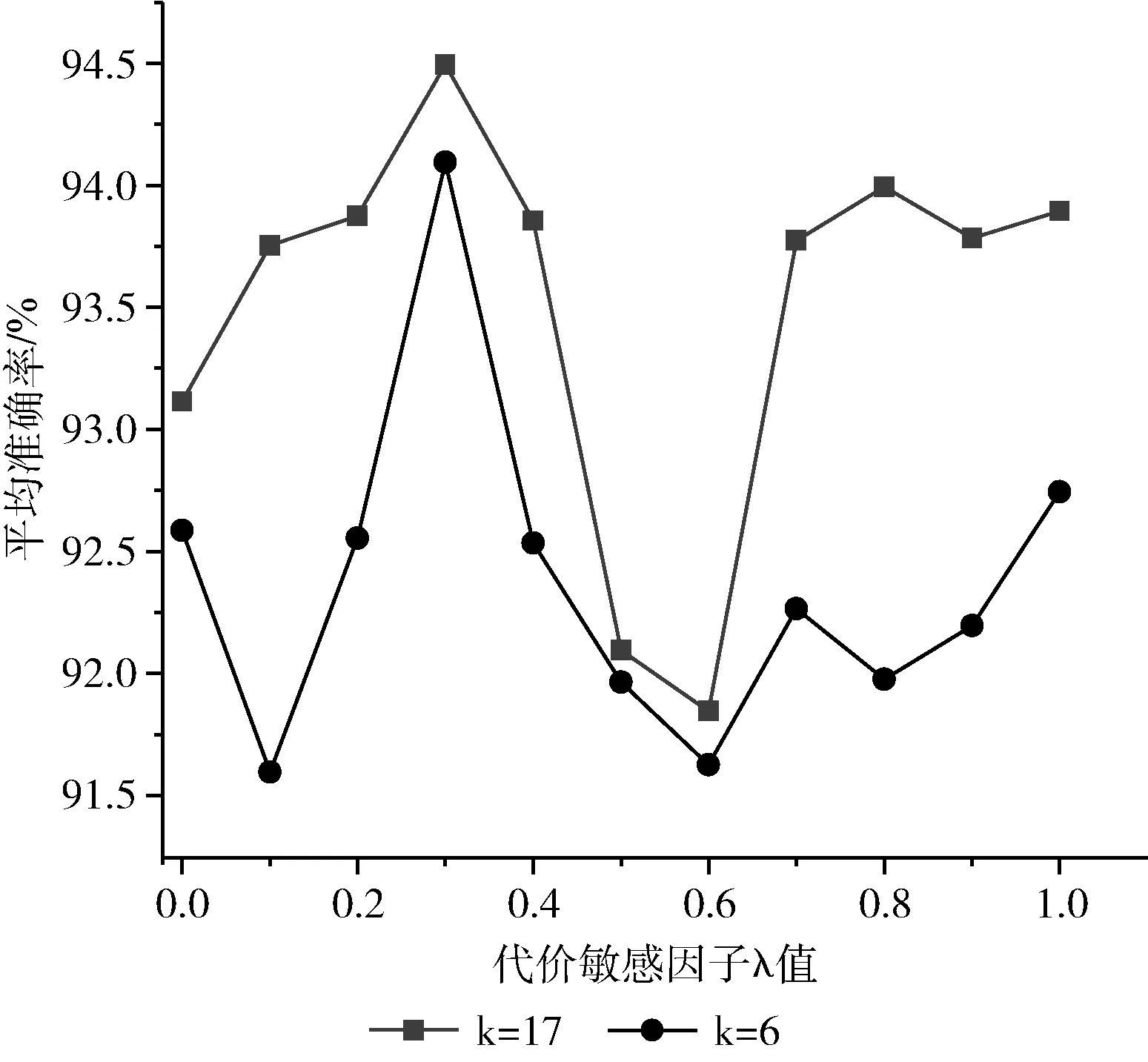
图5 不同λ值在CargoSorting数据集上的结果
2.5 消融实验
为验证本文方法中注意力模块和代价敏感损失模块的有效性,本文分别在两个数据集上对这两个模块做消融实验,结果见表3和表4。
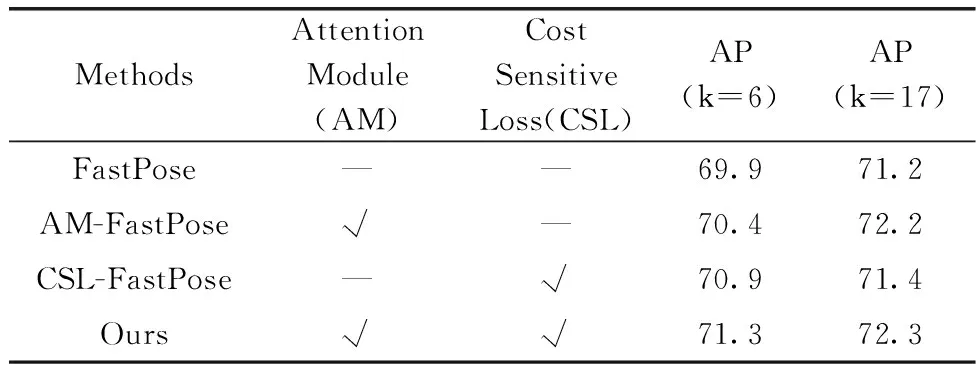
表3 MSCOCO-val数据集消融实验
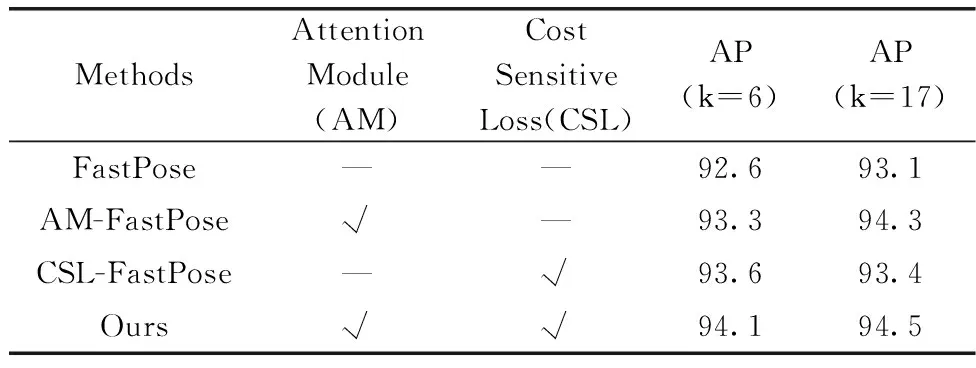
表4 Cargo Sorting-测试集消融实验
AM-FastPose为单独使用注意力机制模块,CSL-FastPose为单独使用代价敏感损失模块。由表3和表4可知,相比于基准方法,AM-FastPose模型在两个数据集上的目标关键点识别准确率分别提升了0.5%和0.7%,整体关键点识别准确率分别提升了1%和1.2%。CSL-FastPose模型在两个数据集上目标关键点识别准确率分别提升了1%和1%,整体关键点识别准确率分别提高了0.2%和0.3%。注意力机制模块帮助模型从空间和通道两个维度关注更加重要的特征信息,代价敏感损失模块帮助模型更好地识别与特定动作相关的目标关键点。本文方法通过融入空间通道注意力和引入代价敏感损失,提升了模型对整体关键点和目标关键点的识别准确率。
2.6 实验案例分析
为了直观解释本文方法的有效性,在COCO数据集上进行姿态估计的可视化结果如图6所示。其中,第一列表示输入图像,第二列和第三列分别表示利用FastPose方法和本文方法生成的人体姿态。为方便对比,在第一列输入图像中,用矩形框标注出那些由于拥挤、背景复杂和人体运动等导致的四肢关键点不同程度遮挡现象。从图6可以看出,当存在遮挡时,本文方法较之基准算法,均有更好的表现。

图6 本文方法和FastPose方法的可视化实验比较
具体而言,在图6(a)中,左侧目标人体的左肩、左肘和左手腕关键点被遮挡,右侧目标人体的下肢被物体遮挡,通过对比图6(b)和图6(c)可以看出,对于左侧人体,本文方法能够预测出其被遮挡的左手腕目标关键点,对于右侧人体,本文方法能够完整预测出被遮挡的脚踝和臀部关键点;图6(d)是在低分辨率情况下,与图6(e)对比可知,本文方法能够较好预测出目标人体的左脚踝关键点位置;在图6(g)中,目标人体左手腕位置处的外观颜色和背景颜色非常相似,容易造成混淆,由图6(h)和图6(i)的对比结果可知,本文方法仍然能够较准确预测出目标关键点的位置;在图6(j)中,目标人体的膝关键点被遮挡,通过对比图6(k)和图6(l),本文方法可以预测出与脚踝相连的膝关键点;在图6(m)中,目标人体由于运动左手腕产生了自遮挡,图6(n)和图6(o)的对比结果表明,本文方法可以较好地预测出目标人体的左手腕关键点。
3 结束语
本文提出了一种融合注意力机制的人体关键姿态估计方法,该方法可以有效提高与特定动作相关的目标关键点的识别准确率。本文将手腕、手肘、脚踝作为目标关键点,在特征提取阶段融入空间和通道注意力机制,降低背景等信息的干扰;在上采样阶段融入通道注意力机制,帮助模型筛选更重要的通道特征。考虑不同关键点的重要程度不同,本文设计了一种代价敏感损失来提高目标关键点的重要性。在两个数据集上实验,目标关键点识别准确率分别提高了1.3%和1.5%,表明了本文方法的有效性。如何自动选择更优的代价敏感因子以及在保证模型识别准确率的基础上降低模型复杂度是下一步工作的重点。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
海峡姐妹(2017年12期)2018-01-31
数学物理学报(2017年5期)2017-11-23
作文与考试·初中版(2017年12期)2017-04-19
中学生(2015年12期)2015-03-01
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
