
改进蝠鲼觅食优化的粒子滤波算法
2023-10-12 01:27陆星辰静大海杨佳林李文栋
计算机工程与设计 2023年9期
陆星辰,静大海,杨佳林,李文栋,黎 瑶
(河海大学 计算机与信息学院 阵列与信息处理实验室,江苏 南京 211100)
0 引 言
现代工程应用中,如目标跟踪、声呐探测、视觉定位、电池检测等领域[1,2],贝叶斯滤波[3]一直扮演着重要的作用。粒子滤波[4](PF)是使用序贯蒙特卡洛法代替贝叶斯估计的样本积分的递推滤波,用以解决线性非高斯系统的滤波问题。
粒子滤波存在着多次迭代使粒子退化[5,6]的问题,为解决以上问题,很多学者引入智能优化算法。遗传算法[7]可以应用于粒子滤波,高权值的粒子交叉变异概率较高,这样在不损失多样性的条件下,代替传统的重采样方法[8]。文献[9]通过自适应设定交叉概率和变异概率,在交叉步骤的相反方向选择变异操作,增加了粒子的信息多样性,缓解粒子的贫化。文献[10]使用粒子群算法优化粒子滤波,每出现一个新观测值,群中粒子便向高似然区移动,粒子适应度达到最高时获得最优解,增强了估计的精确度和鲁棒性。将蝙蝠算法[11]优化粒子滤波,可以使局部搜索以及全局搜索间相互转换,粒子更容易向最优位置移动,扩展了粒子的状态搜索空间。
以上方法一定程度上缓解了粒子退化的现象,避免因重采样而造成的粒子贫化问题[12],但是重要性函数[13,14]选取的不适会使粒子权系数方差变大,较多的迭代次数会提高算法的时间复杂度,降低运算效率。蝠鲼觅食优化算法[15]是最新提出的群智能算法,已经证明该算法在全局寻优、收敛精度等方面优于传统的粒子群算法等智能优化算法,具有很强的实用性。基于此,本文采用蝠鲼觅食优化算法改进粒子滤波,既提高估计精度,加快迭代速度,又解决粒子滤波存在的问题,减少滤波误差。
1 粒子滤波算法
贝叶斯估计理论[3]是将随机变量的先验分布结合传感器得到的观测值结合起来,得到随机变量的后验分布,估计方差最小。粒子滤波[4]是k时刻目标状态后验概率密度分布可以由样本粒子集加权求和得到,后验概率密度p如表达式(1)所示
(1)

粒子滤波(SIR)[4]基本步骤如下:
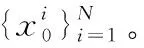
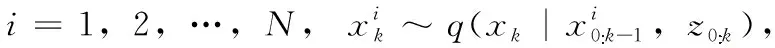
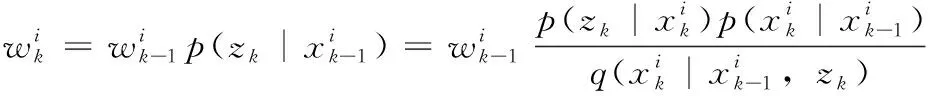
(2)
步骤3 对重要性权值进行归一化
(3)
(4)
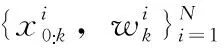
步骤5 结合权值进行提取状态估计
(5)
2 蝠鲼觅食优化算法
蝠鲼觅食优化算法(MRFO)[15]是基于海洋里蝠鲼捕鱼进食的运动规律而获得的求取最优解的搜索算法,其在避免局部最优、收敛速度和收敛精度等方面优于传统智能算法。该算法由三阶段组成,分别是链式觅食、螺旋觅食、翻滚觅食。
(1)链式觅食:当蝠鲼进行捕猎时,该群体会以一定的概率一只只排成一排,向猎物位置游动,即链式捕食。领头的蝠鲼以猎物位置为目标,不断向其游动,位置不断更新,紧邻的前一只蝠鲼和猎物位置决定了接在后面的蝠鲼移动方向和步长。搜索模型如表达式(6)所示,参数α由表达式(7)决定
(6)
(7)
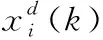
(2)螺旋觅食:除了链式觅食,蝠鲼群体也按一定概率进行螺旋觅食,蝠鲼个体按首尾相接进行螺旋前进且不断地向猎物靠近,每一只蝠鲼的螺旋游动方向和步长由紧邻的前一只蝠鲼和随机的新位置决定,则此算法就具备了全局搜索的搜索能力,可以搜索到全局最优解。其搜索模型如式(8)所示,β是螺旋游动的权重系数,如表达式(10)所示
(8)
(9)
(10)
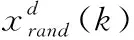
除了具备搜索全局最优解的能力,还应有局部搜索的能力,当算法迭代到一定次数时,将猎物位置随机替换为一个猎物位置,围绕这个位置再进行螺旋觅食,以此增强算法最优解邻域内的局部搜索能力,其搜索模型如表达式(11)所示
(11)
(3)翻滚觅食:在蝠鲼觅食算法中,翻滚觅食过程是最后一道过程,也是必须要经历的一段过程。蝠鲼个体以猎物位置为中心点,通过旋转游动,随即到达一个新位置。搜索空间的大小由个体位置到猎物位置距离决定,两者距离比较大,说明翻滚之后位置到猎物位置距离也比较大,搜索空间变大;反之,搜索空间变小。搜索模型如表达式(12)所示
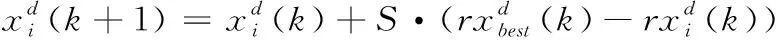
(12)
式中:S为翻滚因子,取常数2;r是0到1的均匀分布随机数。
3 蝠鲼觅食优化的粒子滤波算法
本文选取蝠鲼觅食优化算法[15]改进粒子滤波(MRFO-PF),该优化算法所用参数较少,通过链式觅食和螺旋觅食两个过程在全局最优值的引导下,驱使粒子不断地向高似然区移动,拥有出色的局部搜索能力、收敛性以及稳定性且求得的最优解的数值精度高于其它的智能优化算法,但是该算法仅在螺旋觅食时有一定概率引入随机点扰动,这样优化算法仍然易陷于局部最优的情况,需要对蝠鲼觅食优化算法进行针对性的改进。本文加入粒子交叉和粒子分组两项操作,以便加快收敛速度提高求解精度的同时更好地提升粒子滤波算法的性能。
3.1 粒子交叉
本文在前两种觅食行为之后,引入横向交叉[16]以增强优化算法全局搜索能力,保障粒子的多样性,避免粒子过于集中。横向交叉指的是搜索空间中两个状态不同的粒子进行的算术交叉过程。具体的操作是每一次迭代过程中,随机选取当前时刻的粒子来组合配对,然后粒子之间以一定概率进行交叉来获得的两个新粒子,粒子的更新位置如表达式(13)和表达式(14)所示
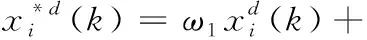
(13)
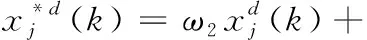
(14)
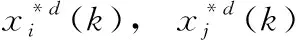
通过表达式(13)和表达式(14)引入横向交叉操作,将粒子的状态信息有效地推广传播到整个滤波空间,同时此刻的最优粒子也具备更多的机会跳出当前的最优选择。总体上来说,一方面,将横向交叉同蝠鲼觅食优化算法结合起来,相较于原始优化算法降低了粒子陷于局部最优的概率,减少了对粒子空间盲点的处理,加快迭代收敛;另一方面,基于随机交叉得到的新粒子增加了状态信息的广泛性,扩展了粒子的状态搜索空间,同时也有利于后续的对粒子进行的分组操作,更好提升了粒子滤波的性能。
3.2 粒子分组
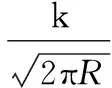
(15)
式中:x是运算粒子即预测观测值,R是观测噪声的方差,zk是当前观测值。高权值组的粒子按表达式(16)更新,表达式(16)受文献[17]的启发,本文进而对表达式(12)进行如下的改进
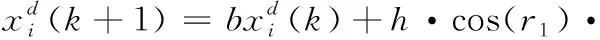
(16)
当hcos(r1) 处于1到2时,粒子在进行大范围翻滚,保持全局状态空间搜索,小于1时翻滚范围较小,此时进行局部状态空间开发,调节系数h决定了余弦波的振幅,影响着迭代时的搜索步长,惯性系数b增强算法灵活度,形成对全局最优值的扰动,两者定义分别如表达式(17)和表达式(18)所示
(17)
(18)
其中,k和T分别是当前迭代次数和最大迭代次数,μ、ψ和λ分别取5、0.01、1.2。h是单调递减的正切函数,数值迭代初期比较大,随后数值逐渐递减,这就实现了搜索步长从大到小的变化;相应地,初期收敛速度比较缓慢,伴随着逐步的迭代,收敛速度逐渐加快,这样既有利于粒子收敛到最终的最优位置,减少了算法收敛时间。惯性权重b是基于余弦函数选取的,起到调节迭代过程中全局和局部粒子的作用,提高收敛的精度。
考虑要到保留并改进低权值组的粒子,需要利用全局最优粒子对其进行线性组合从而产生新的粒子,区别于表达式(16),表达式(12)做出如下的修改
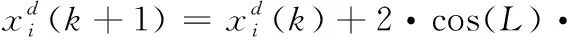
(19)
(20)
其中,L表示移动的步长,N表示粒子总数目,q表示粒子在当前时刻全局最优值的空间邻域内的分布概率。
由表达式(19)可以看出,低权值的粒子经当前时刻全局最优粒子的引导,慢慢地向高似然区方向靠拢,迭代过程中跳跃距离小且距离比较固定,粒子位置最终逐渐稳定;分布概率较大的低权值粒子要围绕全局最优的粒子做左右跳跃,仍与最优粒子保持相应距离,保证了低权值的粒子不完全聚集在最优粒子附近。平衡高低权值的粒子是整个蝠鲼觅食优化算法优化粒子滤波算法的关键所在,对于解决粒子退化问题起决定性作用。基于此线性组合的方法使得MRFO-PF算法并不是简简单单地复制高权值的粒子,低权值的粒子既配合高权值的粒子快速地向最优粒子靠拢,同时自身又避免被剔除舍弃。改进的翻滚觅食方式使低权值的粒子以新粒子的形式存在于滤波之中,避免了重采样,减少了粒子种类多样性的损失,使迭代后的粒子分布更接近于实际的状态后验概率分布。
3.3 MRFO-PF算法基本步骤
改进的蝠鲼觅食优化粒子滤波算法具体步骤如下所示:
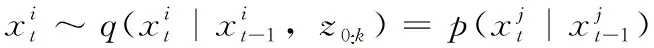
步骤2 第一个领头的粒子依概率按表达式(6)和式(8)进行链式或螺旋觅食,接着身后粒子按表达式(6)和式(8)进行链式或螺旋觅食,迭代一定程度后表达式(8)转式(11)进行螺旋觅食。
步骤3 按式(13)、式(14)随机对粒子进行配对交叉。
步骤4 按适应度阈值对粒子群进行高低分组,高权值组和低权值组分别按表达式(16)和表达式(19)进行翻滚觅食。
步骤5 当高似然区粒子数达到规定数目(0.5N到0.05N)时,跳出循环停止迭代,如果没有则转步骤2继续进行直到符合数目或达到迭代最大次数。
步骤6 按表达式(2)根据所获得的粒子和当前时刻的观测值重新计算重要性权值。
步骤7 按表达式(3)对重要性权值进行归一化。
步骤8 结合各粒子权值按表达式(5)进行状态提取并输出。
MRFO-PF算法流程如图1所示。考虑到算法的实时性,设置高似然区粒子数目阈值,当高权值组粒子数目符合条件即退出循环迭代,这样一方面极大地提高了算法的运算效率,令一方面确保粒子不完全聚集于最优粒子附近。步骤3利用横向交叉过程,扩大粒子的搜索范围,增加粒子的多样性,粒子之间的差异越大,所获得的状态信息将会越丰富,滤波也会获得更好的效果,获得令人满意的估计精度;步骤4用粒子分组优化的方法代替传统的重采样算法,既缓解了部分粒子因权值过小而产生的粒子退化现象,真实做到让每个粒子都可以起到更新迭代的作用,减少计算资源的浪费,同时又尽量避免了粒子贫化而产生的状态信息缺失的问题,克服样本的种类枯竭。
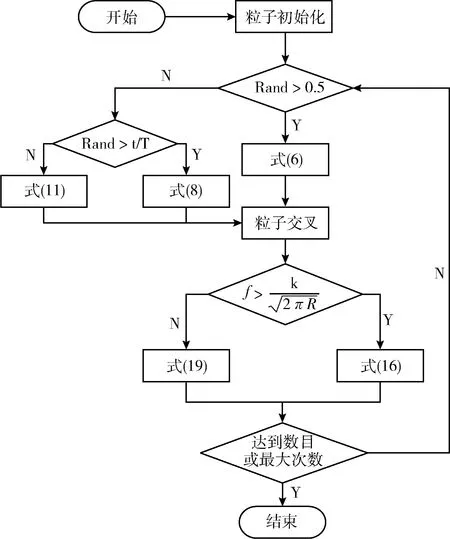
图1 MRFO-PF算法的流程
4 实验内容及结果
为了验证MRFO-PF算法的有效性和时效性,本文将其与常规粒子滤波算法(PF)[4]、粒子群优化粒子滤波算法(PSO-PF)[10]、蝙蝠优化粒子滤波算法(BAT-PF)[11]进行仿真比较。具体是将这4种滤波算法分别在单变量一维非静态增长模型和二维纯角度观测模型两种非线性系统下进行对比实验。
4.1 单变量一维非静态增长模型
单变量一维非静态增长系统的状态模型x(t) 和观测模型z(t) 如表达式(21)以及表达式(22)所示
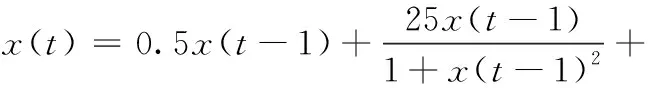
(21)
(22)
其中,x和z分别是预测状态量和观测量,ω和v分别是均值为0的高斯噪声,w是系统噪声,其方差Q为1,v是观测噪声,其方差R为1。基于模型的建立和参数的选择,该模型处于高度的非线性状态,常规滤波算法解决起来有一定难度,所以适用于检测和对比各滤波算法的作用和性能。
图2至图3是在粒子数N设置为100,滤波步长为50,数目阈值为0.4N的实验条件下得到的各滤波器的仿真结果。图2是4种滤波算法的滤波轨迹图,显示了真实的状态,图3表示4种滤波算法的距离误差在各时间点的变化情况。
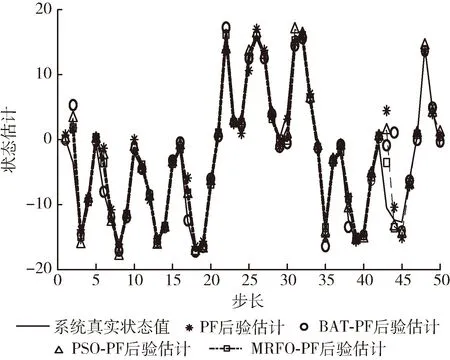
图2 一维滤波轨迹
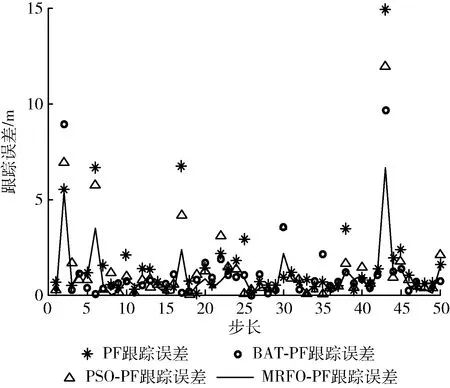
图3 一维距离误差
从图2和图3可以看出,通过对粒子的迭代,经过智能算法优化后的粒子滤波算法距离真值的误差基本小于常规粒子滤波,MRFO-PF滤波曲线和真实值曲线拟合程度是最高的,其误差曲线的起伏程度是滤波算法中最小的。这说明了优化算法在滤波过程中起到聚合粒子从而调整分布的作用,减少了由于重采样产生的粒子种类缺失的问题。图3更直接地表示出MRFO-PF滤波曲线比其它两种优化后的算法更贴近系统真实值。以时刻43为例,其它时刻滤波误差点都在MRFO-PF曲线上方,即同一时刻滤波估计值与真实值之间的距离误差最小。误差曲线直观地表示了蝠鲼觅食优化的粒子滤波的滤波性能。
表1和表2分别是粒子数为100、50、20时4种算法的RMSE值以及单次滤波的运行时间,表中数据是做50次MCMC后取的平均值。观察表格,横向来看,随着粒子数的减少,单次滤波的运行时间减少,各算法RMSE均有提高,故滤波性能下降,常规粒子滤波尤为明显。纵向来看,相同的粒子数下,智能优化算法也要优于常规粒子滤波算法,其中MRFO-PF的RMSE较其它三者最少,滤波效果基本与图片显示结果一致。3种不同粒子数情况下,本文算法较常规粒子滤波算法滤波精度提高约30%,较PSO-PF算法提高约16%,较BAT-PF算法提高约12%,因此要和常规粒子滤波算法达到同等精度下,MRFO-PF减少了滤波所需的粒子数目。本文将权值小的粒子线性优化变成新粒子,故相较于抛弃权值小粒子的重采样过程的粒子滤波算法,使起滤波作用的粒子并不仅仅局限于权值较大的粒子,粒子退化程度更小,同时保证粒子种类的多样性,降低了滤波误差。
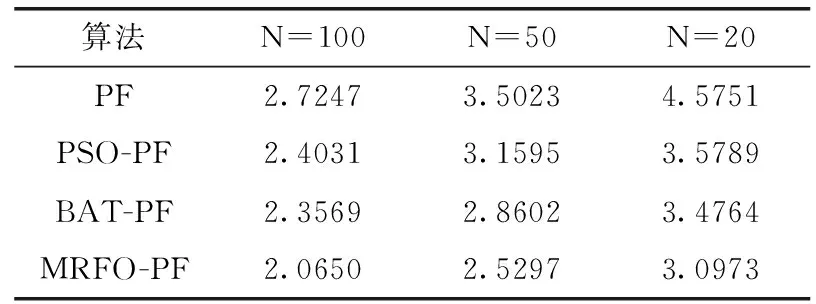
表1 实验4.1的RMSE结果对比/m
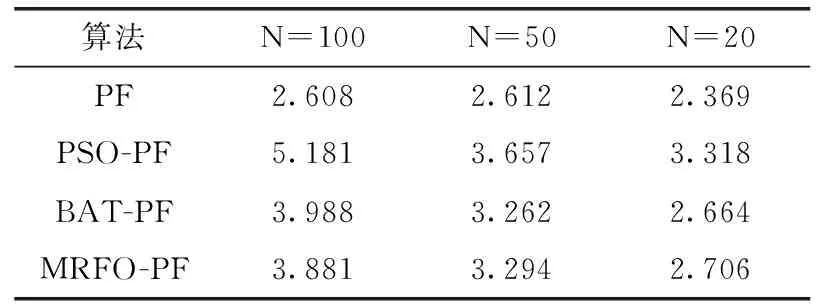
表2 实验4.1平均单次滤波所需时间/10-3s
时间方面,由于粒子滤波没有粒子寻优迭代的过程,所以其所需时间最少。本文算法改进了粒子寻优方式,加快了收敛速度,经过粒子交叉和粒子分组两个操作后,相同的迭代次数下MRFO-PF的寻优精度最高,所以在满足相同粒子数阈值的条件下MRFO-PF所需的迭代次数最少,这样达到相同的滤波精度的所用时间较少,故MRFO-PF所需时间基本次优。总体来看,PSO-PF迭代次数平均要多于另外两种滤波方法。本文算法由于迭代较少,具备一定的实时性。
4.2 二维纯角度观测模型
粒子滤波在雷达目标跟踪中应用非常广泛,这里使用在国防工业中应用广泛的二维空间中纯角度的跟踪模型,确定站点的位置只测得目标的相对角度的观测值而不能获得距离的观测值。相应的,系统的状态模型如表达式(23)所示,观测模型如表达式(24)所示
X(t+1)=FX(t)+Γω(t)
(23)
Z(t)=h(X(t))+v(t)
(24)
其中,X=[x,vx,y,vy]T,x、y分别是目标横纵坐标,vx、vy分别是目标的水平和垂直方向上的分速度。此外
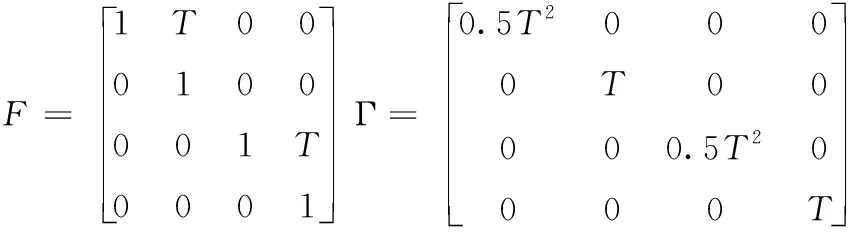
(25)
式中:观测模型h是线性模型,x*、y*分别是站点横纵坐标,T是单位时间。类似的,系统噪声w均值为0,方差Q为10-4,观测噪声v均值为0,方差R为π/1800。
图4~图6是在粒子数为20,滤波步长为30,粒子数目阈值为0.1N的条件下得到的各滤波器的实验结果,从而比较出MRFO-PF滤波性能。图4表示各滤波算法的轨迹,图5表示30步长内各滤波算法较真实值的距离误差,图6则表示每个采样周期内各滤波算法的所用时间。图4和图5直观地表现出随着时间的增大,4种算法距离真实值的误差越来越大,但是不难看出同一时刻本文算法比其它任何算法距离误差更小,即更接近于真实值,误差曲线基本位于其它曲线的下方,其较真实值的距离误差最小;图6表示本文算法运行时间基本少于其它智能算法优化滤波方法,仅高于缺少迭代常规粒子滤波算法,虽然牺牲了一定的时效性,但得到了更高的滤波精度和更低的滤波误差。

图4 二维滤波轨迹
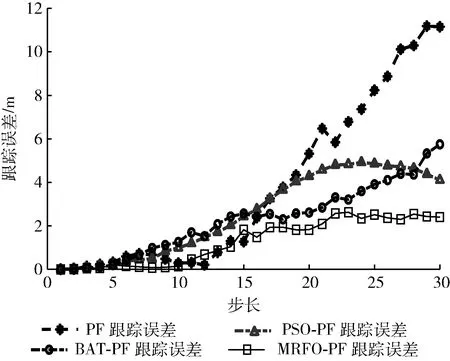
图5 二维距离误差
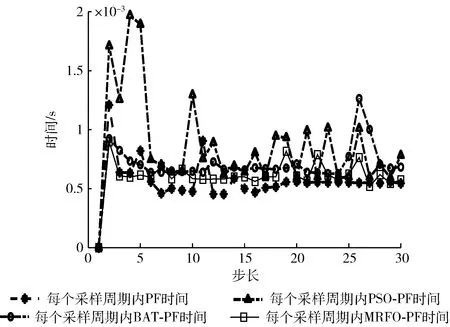
图6 单位周期内二维滤波各算法的时间对比
为方便比较不同滤波器的滤波效果,本文在100、50、20这3种不同粒子数下进行50次MCMC后取平均值,实验的结果汇总成表3。从实验得到的数据来分析,随着粒子数的减少,各个分量上[x、vx、y、vy]的RMSE都在增大。以x方向上RMSE为例,在3种不同的粒子数下,对比PF、PSO-PF、BAT-PF这3种不同滤波算法,本文算法滤波误差平均分别减少37%、28%、19%。同样可以看出本文算法在其它分量上也基本优于其它算法,实验4.2的数据结果基本与一维实验一致,大量数据进一步地验证了本文算法的有效性以及滤波的稳定性。

表3 实验4.2的RMSE结果对比/m
5 结束语
经过两组实验对比,MRFO-PF算法滤波效果基本优于粒子滤波和其它智能优化的粒子滤波。从实验结果来看,本文算法提高最优解的求解精度,减少估计误差,降低运算时间。从实验数据来看,本文算法滤波精度较常规粒子滤波提高30%,满足滤波精度的条件下,减少所需粒子数目。
MRFO-PF算法优越处主要有以下几点:①在链式觅食和螺旋觅食两个过程后随机对粒子进行横向交叉,增大粒子搜索范围,提高粒子种类,降低陷入局部最优的概率;②按适应度分组粒子,分别利用改进的翻滚过程更新,用全局最优值引导粒子,加快收敛速度,同时线性优化低权值组,保留并改进低权值粒子,改善粒子退化问题,避免因重采样而造成的粒子贫化现象。有效性、实时性以及稳定性的提高使MRFO-PF算法具备理论意义和使用价值,具备较好的跟踪性能,接下来的研究主要是考虑如何将MRFO-PF算法应用于实际的工程应用以及进一步地探索在不同的应用背景和滤波条件下粒子数该如何选取。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
成都信息工程大学学报(2022年3期)2022-07-21
数学物理学报(2022年2期)2022-04-26
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
现代计算机(2019年6期)2019-04-08
金桥(2018年4期)2018-09-26
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
