
数据驱动的图书馆阅览空间光环境提升研究*
2023-10-11 00:50黄兆旭
南方建筑 2023年9期
黄兆旭,宣 蔚
引言
数据驱动型设计作为一种高效的逻辑集成化设计方法,近年来受到建筑学相关领域学者们的普遍关注。尤其是在建筑性能优化领域中,相较于以往通过反复将建筑设计模型导入到性能模拟软件中进行穷举寻优的方法而言,参数化技术的合理运用会极大程度上提高建筑性能的优化效率与多目标权衡能力,体现在只需对模型中的关键设计参数进行多目标寻优,便可实现建筑性能的全局优化。然而,以参数化技术为依托的建筑性能优化模式也往往受制于建筑模型的复杂程度与计算机配置,导致性能优化过程普遍耗时较长,难以及时得出优化结果以指导建筑师进行方案深化。因此,目前在建筑设计实践中该技术并没有得到广泛运用。
当前,人工智能飞速发展,相关机器学习技术已经介入到各个研究领域。由于众多建筑性能预测问题可以看作为回归预测问题,其中也包括了建筑采光性能的预测。同时,机器学习算法在解决结构化数据回归预测问题具备广阔的应用前景。因此,结合机器学习与多目标优化算法开展更为高效的数据驱动型建筑性能优化研究成为了当下趋势[1-3]。在理论层面,姚佳伟等人提出了环境性能驱动的建筑生成模式及其工作流程,以人机交互与协同性的观点看待建筑设计[4]。朱姝妍与马辰龙提出了“知情式”建筑生成与优化方法,并将建筑性能优化问题区分为量化优化与多解优化[5]。在通过机器学习实现建筑性能预测方面,Chuan-Hsuan Lin 等人通过训练ANN 代理模型,实现了对不同类型建筑立面的采光性能预测的功能[6]。Ke Yan 等人提出了基于物联网数据训练的建筑能耗预测模型框架[7]。韩昀松等人基于ANN 代理模型,提出了具有较高泛化能力且预测准确度较好的采光性能预测模型[8]。燕海南等人构建了基于数据驱动的办公建筑性能预测工作流,实现对建筑性能的综合评估与快速预测[9]。在通过遗传算法进行建筑性能多目标优化方面,杨焕宇等人基于参数化平台,针对典型民居进行建筑室内采光性能模拟,并提出了影响民居室内光环境的因素及其优化措施[10]。刘博等人使用遗传算法求解北京地区典型中小学教室采光窗口的最优反光构件形态[11]。Afshin Razmi 等人基于宿舍建筑,提出了PCAANN 集成遗传算法的研究框架,实现了一种高效且准确的建筑性能预测与优化方法[12]。这些研究均取得了较好的成果,充分证明了数据驱动型建筑性能多目标优化在建筑设计初期决策中的可行性与必要性。
阅览空间作为图书馆建筑的核心功能空间,良好的自然采光条件不仅可以为使用者提供舒适的阅读环境,还能够起到降低人工照明能耗的作用[13],进而实现建筑节能减排的目的。然而,在当今图书馆建筑实际使用过程中,阅览空间普遍存在沿房间进深方向照度分布不均匀的问题,接近采光口处照度过高,远离采光口处又存在明显的照度不足,白天室内拉窗帘与开灯并存的现象屡见不鲜。对于建筑采光性能优化方面,目前相关研究主要聚焦在提升室内照度水平的方法上,而对于室内采光均匀度较差、采光过曝引起的视觉不舒适、眩光等因素考虑较少。由于图书馆阅览空间功能的特殊性,将照度值控制在合适的范围内以及确保合适的采光均匀度显得尤为重要。为解决该类问题,本文以夏热冬冷地区图书馆阅览空间简化模型为例,通过引入三项采光性能指标以达到采光性能多目标优化,有效解决建筑室内空间照度分布不均导致的眩光问题与照度不足问题。同时,通过引入机器学习与遗传算法优化等数据驱动型设计方法,从而加速建筑性能优化效率,为建筑设计初期的方案决策提供理论支持。
1 研究方法
1.1 总体研究思路
本研究的核心在于基于数据驱动型方法对图书馆阅览空间的采光性能进行多目标优化,其流程可以归纳为建立实验模型、设计参数采样、采光性能模拟、回归模型训练以及遗传算法寻优5个步骤(图1)。
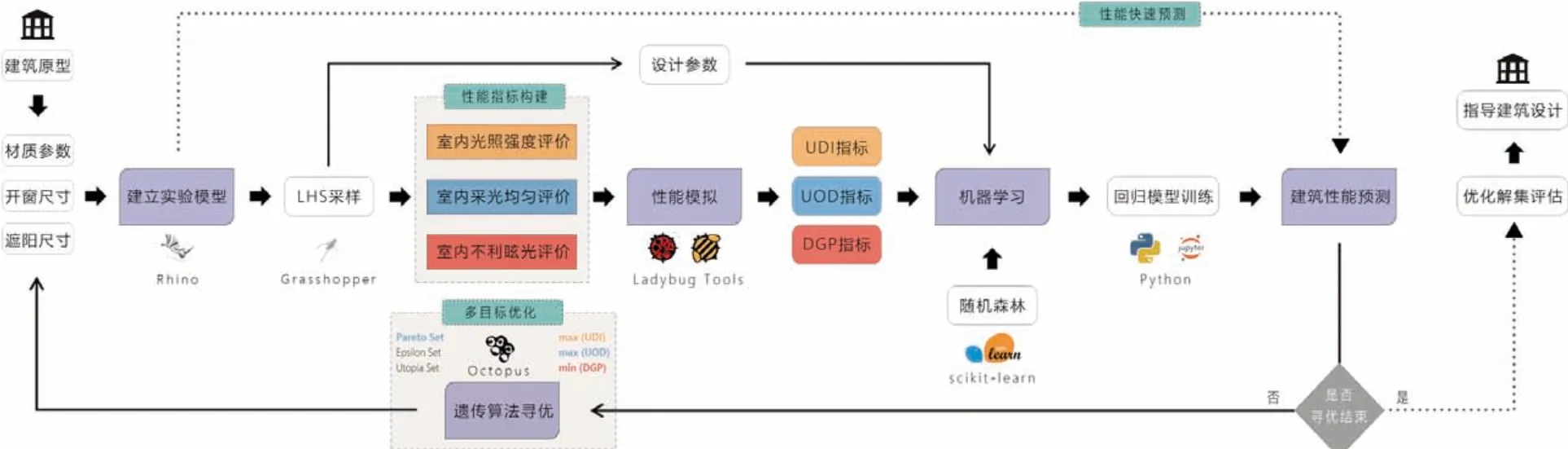
图1 总体研究思路与技术路线
首先,依据相关建筑设计资料搜集与调研结果,建立阅览空间简化模型,并将模型中的待优化设计参数在参数化设计平台中实现联动调控。其次,针对待优化设计参数进行数据集采样以得到一系列设计参数组合,并将每种参数组合对应下的阅览空间模型进行采光性能模拟,以得到与设计参数组合相对应的性能模拟结果。在此基础上,通过数据集预处理与机器学习模型训练,得到能够快速预测建筑性能的机器学习代理模型,并验证其训练效果与预测准确性。最后,在机器学习代理模型的基础上运用遗传算法优化插件对各项设计参数进行多目标寻优实验,一方面得到一系列设计优化解集,另一方面可以进一步分析数据以得到各项设计参数对于三种采光性能评价指标的非线性影响趋势。通过对数据驱动型设计方法的整合运用,有望提高建筑性能优化流程的效率与精度,为数据驱动型设计在建筑学领域的应用提供参考。
1.2 研究指标选取
图书馆阅览空间采光性能优化涉及到多目标权衡问题,其中包含了照度适度问题,采光均匀问题以及眩光问题等。其中,有效天然采光百分比、采光均匀度以及日光眩光概率三项采光性能评价指标在该领域认可度较高,并且三者对于室内采光品质的评判标准与侧重点各不相同,因此将三种采光性能评价指标相结合能够实现对图书馆阅览空间采光性能更加全面的评价。
有效天然采光百分比(Useful Daylight Illuminance,后文简称UDI)是 2005 年由Mardaljevic.J 和Nabil.A 提出的一种动态采光评价指标[14]。UDI 指标依据一年中测量平面自然光的照度值处在100~2000lx 范围内的时间占工作总时间的百分比进行室内采光性能评价[14,15],其规定低于100lx 会被判定为照度不足,高于2000lx 会被认定为照度过大。因此,UDI 指标可以充分考虑到照度不足或照度过大对室内照度所产生的影响。同时,《图书馆建筑设计规范 JGJ38-2015》规定我国图书馆阅览室侧窗采光照度标准值是 450 lx[16],因此本研究将UDI 指标的限制范围设置为450~2000lx,对图书馆阅览空间的采光性能评价更具有参考意义。
采光均匀度(Uniformity of Daylighting,后文简称UOD)是指在采光测量面上照度最小值与平均值的比值[17]。在图书馆阅览空间中,均匀的采光分布往往是营造良好图书阅读环境的必要条件,较差的采光分布会导致某些区域过度昏暗或过度明亮,从而给读者带来不适感和视觉疲劳[18]。UOD 指标能够很好地反映室内采光的均匀度情况,其值越接近1 代表室内采光越均匀,通过优化UOD指标可以有效避免阅读空间照度分布不均匀等问题。
日光眩光概率(Daylight Glare Probability,后文简称DGP)。眩光是指在人眼视线范围内,局部亮度过高从而导致人眼的极度不舒适的光线[17]。作为供人们进行书籍阅读的图书馆阅览空间,在设计之初就需要避免出现眩光问题。DGP 指标是目前相关领域主要参考的眩光评价指标[19,20],随着DGP 数值越大,表明人受到的眩光干扰程度越大[17]。对于图书馆阅览空间而言,依据国际照明委员会CIE 标准以及相关领域研究,本文以阅览桌平面中心向上0.75m 水平高度为测量点,测得其DGP指标小于0.35 为限制标准[20]。
1.3 研究工具选取
本研究选取基于 Grasshopper 平台的 Ladybug Tools 插件进行建筑性能模拟,该插件能够与主流的Radiance 建筑采光性能模拟引擎进行衔接[21],其模拟准确性得到相关学者们的普遍认可[22]。同时,通过采用Python 第三方库中的随机森林回归模型(Random Forest Regression)机器学习算法进行模型训练与回归预测,其能够有效减少结构化数据训练时出现过拟合的风险,在处理建筑采光性能预测问题时具有良好表现。最后,通过 Grasshopper 平台的遗传算法[23]插件Octopus[24]进行建筑性能多目标优化,其具有实现多目标优化的功能,并且拥有较为完备的优化算法组合系统以及计算结果可视化功能。
2 模型建立与性能模拟
2.1 阅览空间简化模型设定
如果以整栋图书馆建筑为研究目标进行采光性能模拟与优化,则会花费大量时间与计算资源。因此,本研究采用建立阅览空间简化模型的方式,依据《图书馆建筑设计规范 JGJ38-2015》[16](后文中简称为“规范”)以及笔者实地调研国内部分夏热冬冷地区公共图书馆阅览空间的设计尺寸特点,形成用于采光性能优化实验的阅览空间简化模型(图2),具体设计参数选取依据如下。
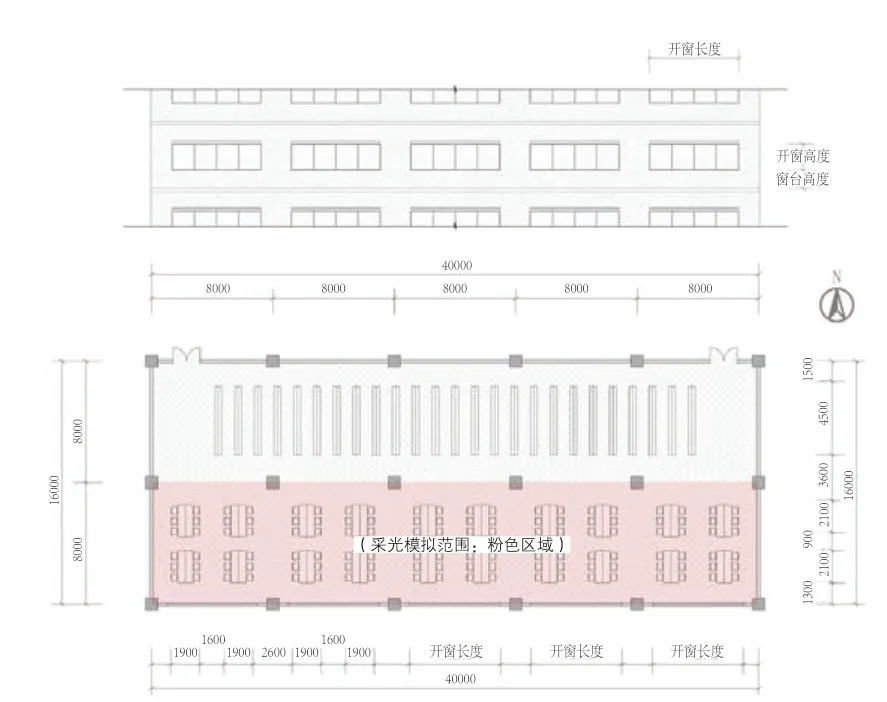
图2 阅览空间简化模型立面图与平面图
对于图书馆阅览空间设计尺寸而言,调研结果表明大部分阅览空间进深处于12m 至28m范围内,其中以16m 居多。结构柱跨普遍集中在7.2m 至8.8m 左右,其中以8m 居多[25]。同时,规范中明确规定对于进深跨度大于9m 的阅览空间,规范要求其层高需要大于4.5m[16]。对于室内空间布局而言,目前图书馆阅览空间主要采用六人双面阅览桌平行式布局[26],阅览桌位于采光侧窗附近,而书架靠近内墙侧。基于上述调研结果,本研究中阅览空间简化模型设计数据如下:朝向正南,面阔40m,进深16m,层高4.5m,框架结构柱跨8m。在室内布局上,采用开架阅览方式,置有双面书架与六人双面阅览桌。其中,图2 粉色区域(阅览区域)为本研究中采光模拟范围。
2.2 设计参数设定与采样
由于研究涉及到机器学习模型训练与遗传算法寻优相关技术,因此在数据集采样环节中需要先赋予五项设计参数较高的调节自由度以获得广泛的设计解空间。同时,结合建筑调研结果,形成表1 中阅览空间简化模型开窗长度、开窗高度、窗台高度以及遮阳板挑出深度、遮阳板旋转角度五项设计参数的取值范围与调整步长。

表1 室内开窗遮阳方式相关参数取值范围
拉丁超立方采样(Latin hypercube sampling,后文简称LHS)是一种常用的多维随机采样方法[27],通过LHS得到的数据集有助于提高机器学习模型的泛化能力[28]。本研究通过对五项设计参数组成的数据集进行拉丁超立方采样,共采集1800 组设计参数,用于后续的建筑采光性能模拟与机器学习模型训练过程。
2.3 采光性能模拟及其参数设定
本研究通过在 Grasshopper 参数化平台中编写程序,将阅览空间简化模型中的墙体、楼板、窗体、遮阳板4 种类别的建筑构件分别实现参数控制,并针对不同的材质类型赋予不同的光学属性,实现了采光性能模拟模型的搭建工作。其中,窗体材质的透射率为0.65,遮阳板材质的反射率为0.6,各面围护墙体材质的反射率为0.5,建筑屋顶天花板材质的反射率为0.8,室内地面材质的反射率为0.2[29,30]。同时,根据《采光测量方法(GB/T 5699—2017)》规定,模拟过程中采用合肥市EPW 气象数据文件作为输入[31],模拟天空为气象数据通过测量全年8760h 所得到的真实天空[10]。并将工况时间设置为每天上午9 时至下午5 时。最后,本次模拟采用 Ladybug Tools 中的测量网格工具设置本次照度测量网格。为保证本次实验的测量精度,照度测量点所在的网格间距为1m,并且测量点高度位于距室内水平面0.75m 的高度,以符合图书馆阅览空间中人们的实际使用方式[24,25]。最后,将1800 组设计参数导入至采光性能模拟运算器中进行模拟(图3),得到了对应的UDI、UOD、DGP 三组采光指标模拟结果。
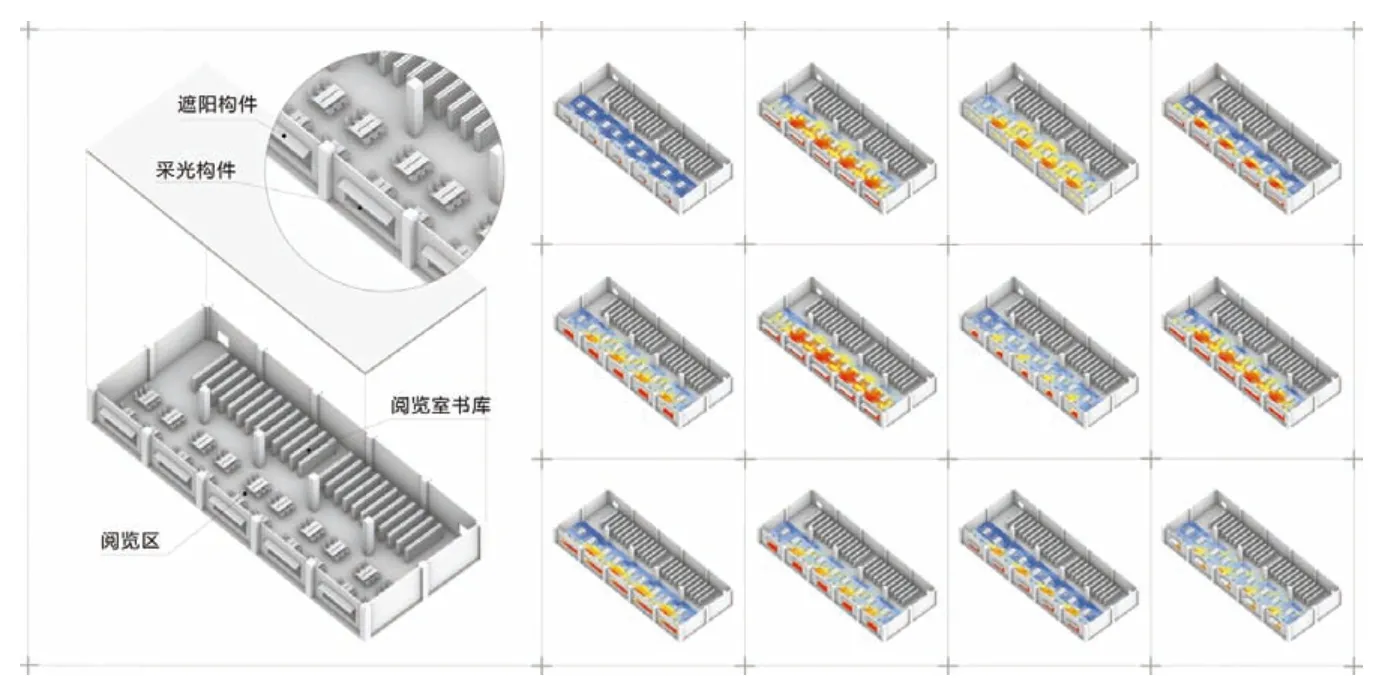
图3 部分阅览空间采光性能模拟结果
3 模型训练与性能优化
3.1 机器学习模型训练
本研究用于模型训练的数据集包括1800组设计参数作为机器学习的特征输入,以及与之相对应的模拟结果作为目标变量。经过数据集归一化处理后,随机选择80%的数据集作为训练集,剩下20%作为测试集,将两者载入随机森林回归模型[32]中进行训练,并采用贝叶斯算法进行模型超参数优化[33]。
随机森林回归预测模型训练完成后,其R2score 为0.98,表明其预测结果对数据的拟合效果较好,能够解释因变量中98%的方差。同时,图4 为记录模型训练过程的学习曲线,红色线为训练集曲线,随着模型迭代训练,其上升趋势趋近于平稳,最高值接近0.994,表明其具有较好的拟合效果。而绿色线则为交叉验证集曲线,随着模型迭代训练,其值越接近训练集曲线,代表模型训练没有出现过拟合现象,并且有较强的泛化能力。
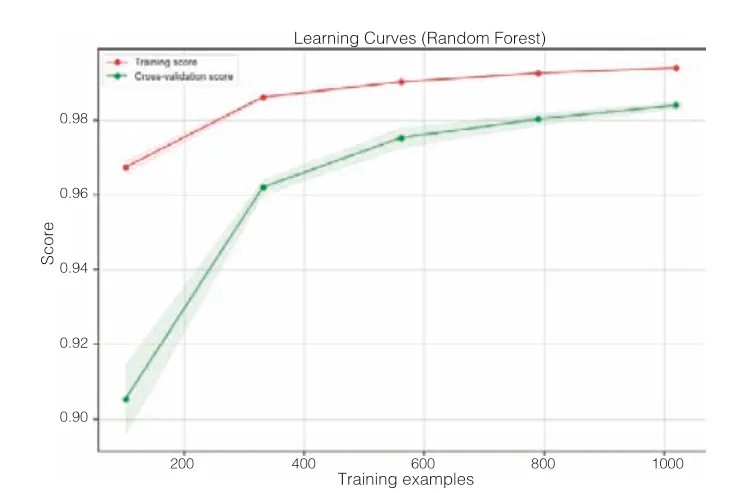
图4 随机森林回归模型学习曲线
通过绘制原始数据与预测数据的三维散点分布图(图5),可以更直观地了解预测结果与真实结果之间的差异,以分析机器学习模型的训练情况。图中,预测结果的散点分布与原始数据的散点分布拟合程度较高,颜色映射图也显示出预测结果的误差相对较小,整体呈现出较为平滑的过渡,证明模型预测结果的准确性和稳定性较高。
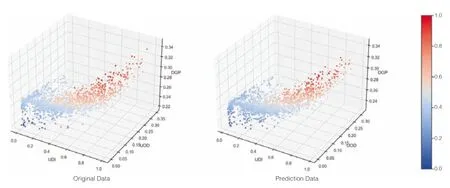
图5 原始数据与预测数据的3D 散点图分布图
3.2 建筑性能多目标优化
本研究通过 Octopus 遗传算法插件进行多目标寻优。在遗传算法相关参数的设定中,种群规模设置为100,进化最大代数设置为手动终止,交叉率设置为0.8,变异率设置为0.9[34]。本研究经过遗传算法第50 代寻优后,顺利完成收敛。共得到796 个基于UDI 指标、UOD 指标以及DGP 指标三者的帕累托前沿解集。
对于图书馆建筑而言,相关规范要求阅览室窗地比不应低于1/6[16,18],同时DGP 指标应小于0.35。因此本文对796 个优化解集按照该标准进行筛选,最终共有344个解集满足该要求。图6 为从344 组解集中选取的6 组具有代表性的优化解集,其中有3 组源于通过K-MEANS聚类算法[35]将344 个帕累托前沿解集依据其优化结果中三个性能指标评分进行聚类分析得到的三组聚类结果的中心位置,另外3 组源于三项性能指标各自最优解的解集位置。
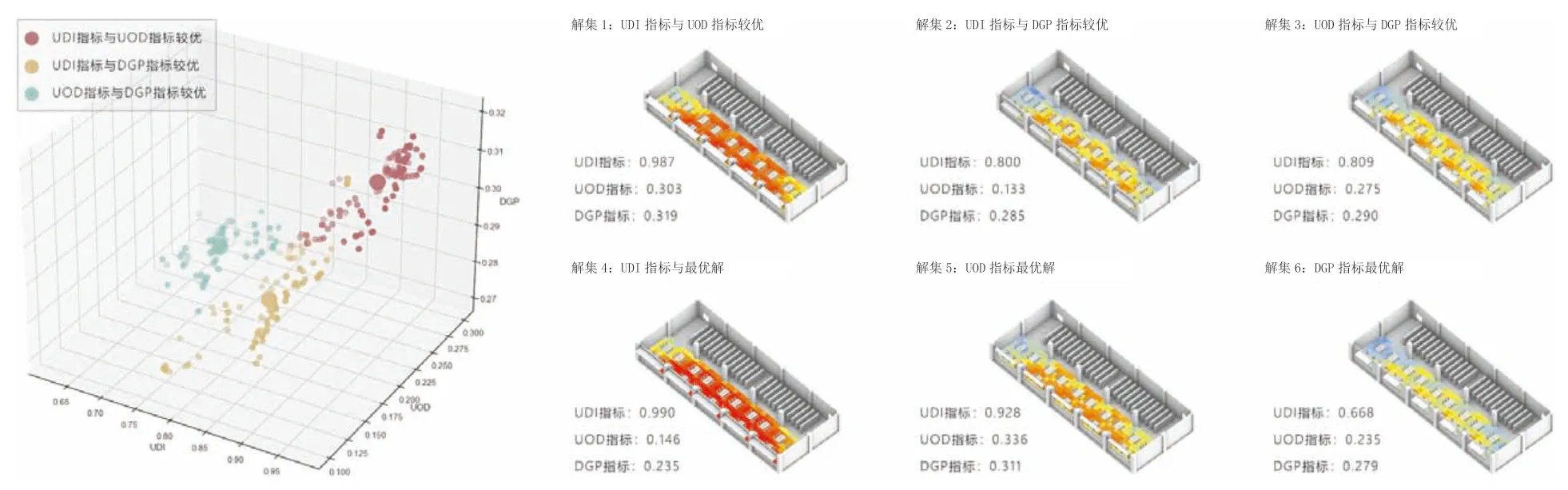
图6 聚类分析结果与6 组代表性解集展示
在这6 组解集中,解集1 特点为采光较为充足且照度分布均匀,但会存在轻微的眩光干扰。解集2 特点在于具有充足采光的同时也能够很好的避免眩光干扰,但采光分布不够均匀。解集3 特点在于能够提供较为均匀采光的同时也能够很好的避免眩光干扰。解集4 为UDI 指标的最优解,其能够提供适宜的光线亮度。解集5 为UOD 指标的最优解,其能够提供较为均匀的采光分布。解集6 为DGP 指标的最优解,其能够有效避免眩光干扰问题。
3.3 建筑采光性能预测准确性分析
为了验证机器学习预测的准确性,本文选取上述6组优化解集数据,通过将设计参数导入建筑性能模拟插件进行计算得到性能指标模拟结果,并与机器学习模型预测结果进行误差比对分析,得到了以下结果(表2)。可以发现,在使用机器学习代理模型进行建筑性能预测时,其预测值与模拟结果仍然存在着一定的误差,但大部分误差低于2%,处在合理误差范围内。
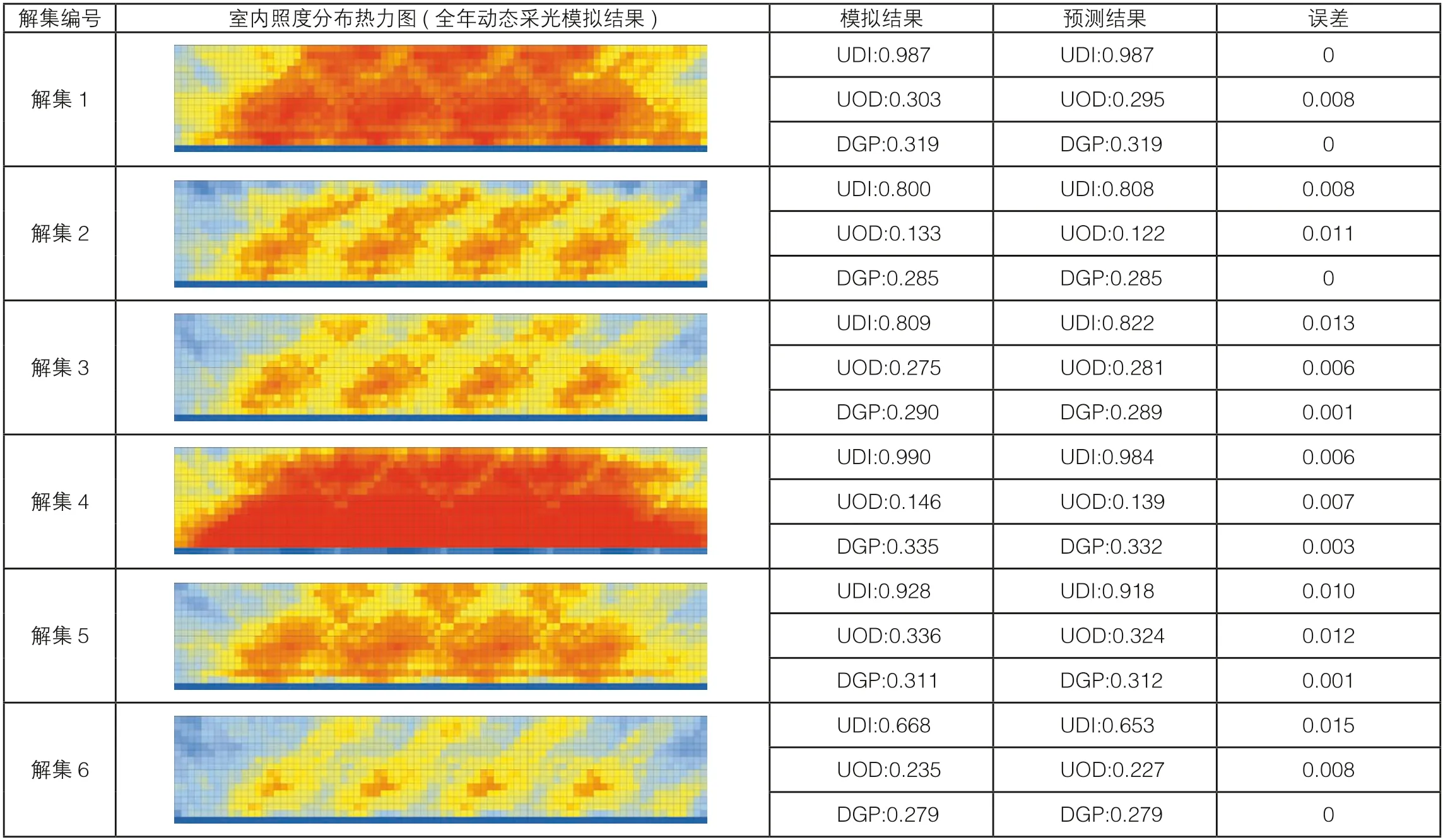
表2 优化解集预测准确性分析
4 结果讨论
4.1 设计参数与性能目标变化趋势分析
基于数据驱动方法得到的数据分析结果能够更加准确的描述不同设计参数在调整过程中对于建筑采光性能的非线性影响趋势,进而为建筑师提供精准的优化策略。图7 为基于采样数据得出的五项设计参数与三项性能指标之间的变化趋势分析。
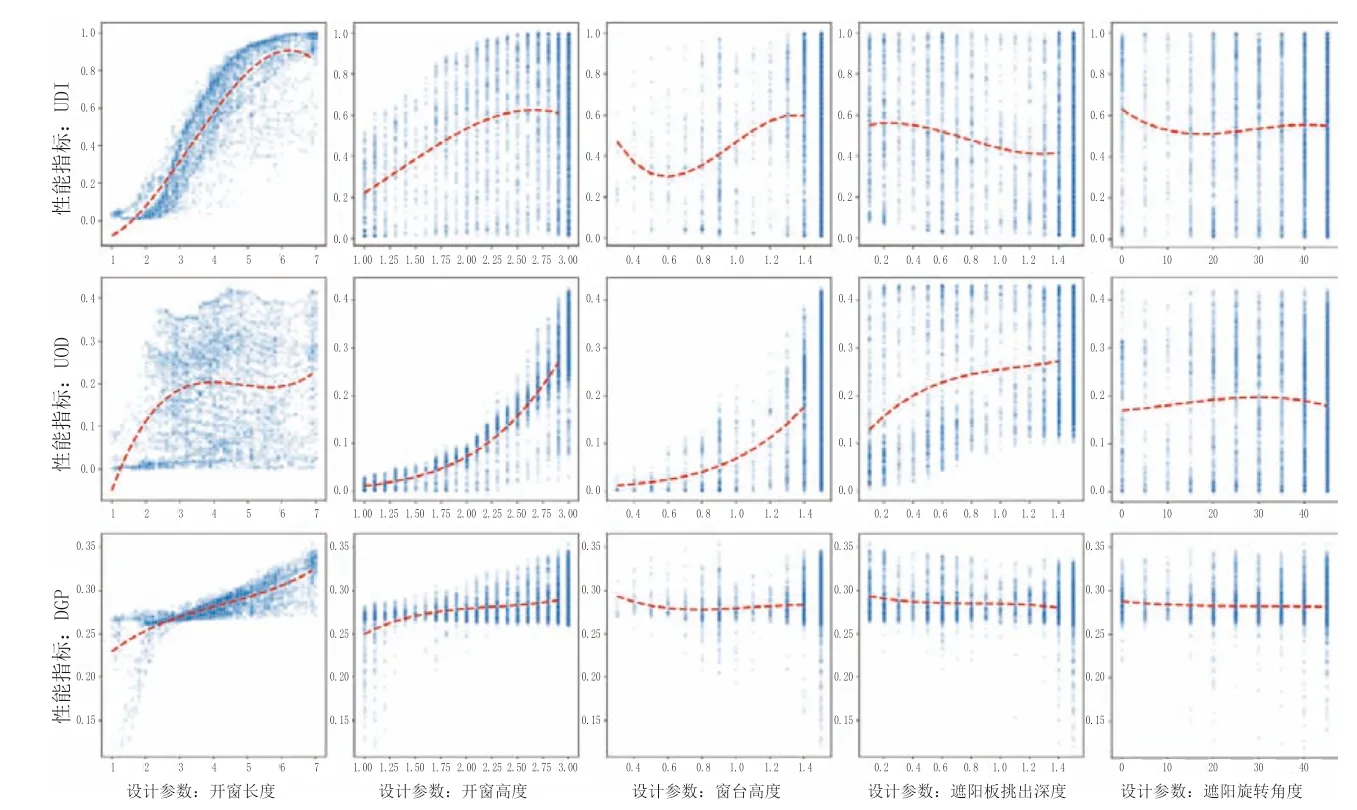
图7 设计参数与性能目标变化趋势分析
对于UDI 指标而言,随着开窗长度不断增加,其在6m 处时UDI 指标的达到峰值,继续加大开窗长度则会导致UDI 指标降低。开窗高度在2.6m 处时,UDI 指标达到峰值。窗台高度对于UDI 指标的影响较为复杂,随着窗台高度的增大,UDI 指标先出现降低趋势,在0.6m 处达到UDI 指标的最小值,随着窗台高度继续增大,UDI 指标随之上升,并在1.3m 处取得UDI 指标的最大值。随着遮阳板挑出深度增大,UDI 指标会出现小幅度降低,遮阳板挑出深度在1.5m 处达到UDI 指标的最小值。遮阳板旋转角度会在0°处取得UDI 指标的最大值,随着遮阳板旋转角度加大,UDI 指标存在略微降低趋势。
对于UOD 指标而言,开窗长度从1m 增大至3.5m 时,UOD 指标存在快速升高的现象,而当开窗长度继续增大时,UOD 指标则基本保持稳定不变状态。随着开窗高度、窗台高度以及遮阳板旋转角度三项设计参数的增大,UOD 指标都会出现升高趋势,其中开窗高度在3m 处得到了UOD 指标最大值,窗台高度在1.5m 处达到UOD指标的最大值。遮阳板旋转角度改变对于UOD 指标的影响相对较小,其在30°处得到了UOD 指标最大值。与之不同的是,随着遮阳板挑出深度增大,UOD 指标会出现显著增高趋势,并在1.5m 处达到UOD 指标的最大值。
对于DGP 指标而言,开窗长度参数的改变对其影响较大,随着开窗长度不断增大,DGP 指标呈现快速上升趋势,开窗长度在7m 处取得DGP 指标的最大值。同样,开窗高度的增大也会使得DGP 指标上升,开窗高度3m处取得DGP 指标的最大值。相反,窗台高度、遮阳板挑出深度以及遮阳板旋转角度三者的增大会略微降低DGP指标,但影响较为微弱。
4.2 阅览空间采光设计策略分析
依据上述量化分析结果,针对阅览空间简化模型可以得到以下采光设计策略。
(1)增大开窗长度可以有效的改善室内照度水平,获得较为明亮的阅览空间,但是过大的开窗长度也会导致室内局部照度过曝等问题,同时其对于室内采光均匀度的改善效果也有限。
(2)开窗高度是调节室内光环境的关键设计参数之一,适当增大开窗高度对于室内采光均匀度的增益较大,能够显著改善室内照度分布问题,并且不会明显增大室内眩光隐患,但是过大的开窗高度在补足进深较远处室内照明的同时,也会造成离开窗过近处的照度过曝。
(3)调节窗台高度对于室内照度的影响较为复杂,原因在于增大窗台高度的过程中会导致近窗处的窗台下部阴影空间面积增大,但随着窗台高度继续增大,侧窗采光便能够照射到室内进深较远的空间,室内整体照度水平会得到相应的提升。
(4)增大遮阳板挑出深度在一定程度上会削弱室内照度水平,但能显著提升室内采光的均匀性,由于其可以遮挡一部分近窗处过亮的光线,使得室内采光更为均匀,并且能够有效避免眩光影响,但过深的遮阳板挑出也会导致室内进深较远的空间难以获得足够的自然采光。
(5)增大遮阳板旋转角度同样可以阻挡一部分靠近采光口的太阳直射光,对于进深较远处的采光则受到的影响较小,虽然降低了近采光口处的照度水平,但也会形成更为均匀的室内采光环境,并可以有效解决室内眩光问题。
值得注意的是,在实际的阅览空间采光优化过程中,不同的项目会因其所处的环境而存在特异性的采光问题。因此,建筑师应针对不同的采光问题与实际需求,合理地调整各项设计参数,从而实现采光性能的全局优化。
4.3 数据驱动型设计方法的优势探讨
本研究通过构建完整的数据驱动型建筑性能优化工作流程,实现了对阅览空间简化模型采光性能的快速预测与多目标耦合优化。基于此研究,可以得出数据驱动型建筑性能优化流程其优势主要体现在以下几个方面:
(1)客观性:数据驱动的建筑性能优化方法以性能指标数据为判断依据,通过计算机大量迭代计算与算法寻优,进而为建筑师提供更加客观、准确的建筑性能优化结果,有效降低由建筑师主观认知偏差所带来的不利决策。
(2)高效性:数据驱动的建筑性能优化方法中结合了遗传算法和机器学习等技术,能够在短时间内生成大量的优化解集供建筑师进行后续的筛选与深化。对于大型建筑项目而言,由于其通常涉及到复杂的设计参数和多项优化目标,传统的建筑性能优化过程往往需要耗费大量的时间和资源,而数据驱动方法则能够显著的加快设计优化进程,极大程度上减少人力、物力以及时间成本的付出。
(3)全局性:数据驱动的建筑性能优化方法能够有效解决多目标耦合优化问题。建筑师可以根据实际的设计需求,设定多个优化目标,程序便可通过遗传算法进行迭代寻优,进而全方位协同考虑多种不同的乃至相互对立的建筑性能需求,为建筑师提供更为合理的全局优化设计方案。
(4)创新性:数据驱动型方法能够通过对大量输入数据与输出数据进行分析学习,提取隐藏在数据中潜在的规律和趋势,从而在建筑性能优化过程中为建筑师提供更为广阔的设计启发与创新,帮助建筑师跳出传统的思维模式,探索更多在建筑性能优化策略上的可能性。
结语
本文基于图书馆阅览空间简化模型,通过构建三项采光性能评价指标的多目标优化体系,并运用数据驱动的建筑性能优化方法,得到了一系列关于阅览空间室内采光性能的优化结果与设计策略,并探讨了数据驱动的设计方法的可行性与优势所在。
在能源问题日益加剧的当代社会中,以环境性能为导向的数据驱动型建筑设计方法无疑可以有效地化解传统建筑行业能源消耗过渡的问题。随着社会群体对于建筑低碳节能的要求不断加大,使用者对于建筑使用舒适性的不断提高,建筑师进行建筑设计决策的困难程度也会大幅度提升,仅仅依靠人力则很难做到众多建筑性能优化难题的权衡考虑。通过运用数据驱动型设计方法,一方面能够充分辅助建筑师去分析、简化建筑性能优化问题,另一方面也可以让建筑师摆脱凭借直觉去解决某些客观的建筑设计问题的习惯,使得建筑师在面对客观问题时可以依据准确的数据从而得到较为可靠的设计决策,极大程度上避免了传统设计方法容易出现的主观性与盲目性[36]。
图、表来源
本文图、表均为作者绘制。
猜你喜欢
设备管理与维修(2020年20期)2020-02-15
汽车实用技术(2019年17期)2019-09-21
家庭影院技术(2019年8期)2019-08-27
光源与照明(2019年4期)2019-05-20
电子测试(2018年9期)2018-06-26
汽车维护与修理(2016年8期)2016-04-07
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
火炸药学报(2014年1期)2014-03-20
城市建设理论研究(2012年22期)2012-09-06
