
无监督动作迁移再修复的人脸重演方法
2023-10-10 10:39陈俊彬杨志景
计算机工程与应用 2023年19期
陈俊彬,杨志景
广东工业大学 信息工程学院,广州 510006
给定一段驱动人物肖像视频和一段目标人物肖像视频(以下简称驱动视频与目标视频),人脸重演的目的是合成一段新的目标人物视频。该视频中的目标人物动作与驱动视频中人物动作保持一致。人脸重演在计算机视觉和机器学习研究中越来越受关注。随着合成的视频变得更加逼真,可以应用于电影后期制作、社交媒体和虚拟主播等多种应用。然而,由于视频涉及到每一帧的真实度及视频整体的流畅度,完整地迁移动作并合成一个流畅的人像视频是一个困难的任务。
现阶段的全头部重演方法可以划分为:(1)针对特定主体的重演方法[1-3];(2)面向不同主体的重演方法[4-6]。
针对特定主体方法通常为基于生成式对抗网络(generative adversarial network,GAN)[7]的方法,可以充分利用目标人物的视频信息,合成高质量的视频。然而现有针对特定主体方法[1-3]常利用参数化人脸模型[8]或人工标注的面部关键点进行动作迁移,无法充分地迁移整个上半身的运动,可能导致合成的头部与肩部不匹配。
面向不同主体的重演方法仅基于一张或几张目标人物图片的信息,合成一段新的目标视频。由于利用的信息较少,难以合成高质量的视频。随着无监督学习的提出,一系列面向不同主体的重演方法[4-6]以无监督的方式训练,对运动与外观进行解耦,进而实现人物动作的迁移。尽管该系列方法依然存在由于信息不足导致的画质差的问题,但更充分地迁移了整个上半身的动作。
本文结合两类重演方法的优点,提出了一套基于无监督运动迁移模型再修复的人脸重演方法,把人脸重演分为动作迁移与图像修正两个阶段。首先,基于一种无监督动作迁移模型充分地迁移人像的动作,获取一个粗糙的视频。然后,设计一个针对特定人物的神经网络修复迁移动作后的视频。该生成网络带有时空结构,利用了前后帧的历史信息协助修复,基于三维卷积充分提取前后帧的上下文信息,并融入了注意力机制以更好地指导图像的修正。此外,假设背景是固定的,将背景信息嵌入于网络尾部,避免网络合成错误的背景。最后,加入了嘴部增强损失,确保了牙齿的真实度。该网络以一种对抗的方式训练,很大程度地还原了目标人物的细节。
1 相关工作
1.1 生成式对抗网络
生成式对抗网络(GAN)是一种基于深度学习的框架。GAN模型使用一个生成网络与一个判别器进行对抗训练。生成器试图欺骗判别器使其无法分辨合成的图像与真实图像。判别器则不断增强区分真实图片和合成图片的能力。当合成图像与真实图像难以区分时,对抗训练达到了平衡。此时生成器可以合成逼真的图像。与其他的一些深度生成网络相比,GAN 可以合成更真实的图片。自GAN提出以来,在视频合成、无条件图片生成、图像翻译、图像处理等方面都受到了广泛的关注[9]。
1.2 人脸重演
人脸合成领域包括人脸身份合成、人脸动作合成等多类任务。其中,人脸身份合成任务需要在保持人物动作不变的情况下,改变其妆容[10]等身份属性;人脸动作合成任务旨在改变人物原来的动作,同时保存人物身份属性。在人脸动作合成中,根据音频[11]或文本[12]等信息改变人物动作的任务常被称为说话人脸生成。说话人脸生成任务需要研究如何合成与给定音频或文本相匹配的人物视频;根据一段驱动人物视频,将驱动人物的动作迁移到目标人物的任务常被称为人脸重演。人脸重演是本文所研究的内容,其关键在于如何更好地迁移动作并合成高质量的视频。人脸重演可以按重演的区域划分为面部重演与全头部重演两个方面。
1.2.1 面部重演
面部重演关注的是头部动作不变的情况下进行面部区域动作的修改。胡晓瑞等人[13]结合面部动作编码系统与人脸表情生成对抗网络,实现了对人物表情的改变。Thies等人[14]在面部区域建立了一个三维模型。在测试时,驱动三维模型合成新的动作。由于需要在目标视频基础上修改的区域较小。现有基于图形学的方法与基于深度学习的方法都可以获得一个较好的效果。然而,只关注表情的传递,不考虑头部的动作,有时会导致动作不协调,且不能满足一些实际应用的需求。
1.2.2 全头部重演
全头部重演可以把驱动人物的整个头部的动作迁移到目标演员,而头部的动作通常伴随着头部以外区域的改动,因此相对于面部重演是更具有挑战性的。
近期一些面向不同主体的重演方法仅需一张目标人物的图像,即可合成给定任意的动作下目标人物的肖像视频。例如,Zakharov等人[15]提出从驱动人物中提取关键点,并将关键点信息注入到生成器中。由于关键点是人为标注的,集中在人脸区域,在肩膀动作的迁移和身份保存上会出现问题。因此,许多头部重演框架采用无监督方法[4-6],不需要任何人为标注的人脸关键点或三维人脸模型来合成人像视频。给定一张参考目标图片和驱动视频,Monkey-Net[5]从驱动视频学习一组无监督关键点,以此估计一个密集运动场,根据该运动场对从目标图片提取的特征进行扭曲,并最终根据扭曲后的特征合成迁移动作后的图片。在此基础上,FOMM(first order motion model for image animation)[6]学习一组无监督关键点以及其局部仿射变换来建模更复杂的运动。这些方法在大规模人像视频数据集训练后,可以应用到其他人像图片。此外由于这些方法是以无监督的方式学习的,关键点能建模肩膀的运动,实现更完整的人像动作迁移。然而,当合成的姿势与动作与参考目标图片有较大差异时,往往效果较差。此外,背景等区域也存在被误扭曲的情况。
另一方面,针对特定人物的模型可以合成更真实的人像视频。给定一段特定目标人物的视频,Vid2Vid[2]训练了一个针对特定人物的生成神经网络,将人脸关键点转化为较为真实的视频帧。然而,不同人物关键点分布可能存在不小差异,可能导致身份的保存出现问题。Kim等人[3]提出DVP(deep video portraits),基于参数化人脸模型对目标视频和驱动视频进行三维人脸重建,将人脸解耦为姿势、表情、眼神、身份、光照参数。通过结合驱动视频的姿势、表情、眼神参数以及目标视频的身份、光照参数进行GPU渲染,得到一段粗糙的人脸视频。最终利用一个带有时空结构的神经网络将GPU渲染的结果转化为具有真实感的人脸图像。Head2Head++[1]在DVP的基础上,参考前一帧合成新的帧,提高了视频的流畅度。然而,由于三维人脸模型只能重建人脸区域,转移头部的动作,肩膀等区域的动作并不能由驱动人物直接控制。因此,合成的肩部与头部可能存在不匹配的状况,进而影响视频的质量。
2 本文方法
在给定一定长度目标视频Vt={I1t,I2t ,…,I N t}和任意驱动视频Vd={I1d,I2d,…,I M d}的情况下,本文方法旨在驱动视频的动作完整地迁移到目标视频,合成逼真的目标视频。本文方法的总体流程如图1 所示。本章首先简要介绍了第一阶段的基于无监督学习的运动迁移模型,然后对本文提出的在第二阶段中用于修复细节的网络PC-UNet(portrait correction UNet)的结构和训练过程进行详细介绍。
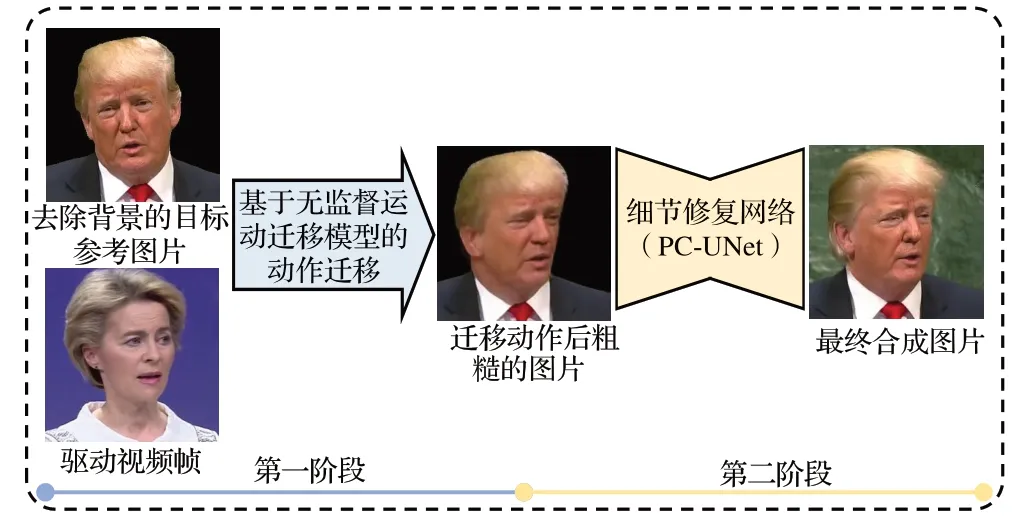
图1 本文方法的总体流程Fig.1 Overall process of proposed method
2.1 基于无监督学习的运动迁移模型
给定一段驱动视频Vd和一张目标人物参考图片It,本阶段需要将Vd的动作迁移到It上。基于无监督学习的运动迁移模型能更完整地迁移人物各个部分的动作。本文基于一种经典的无监督运动迁移模型FOMM[6]实现第一阶段的动作迁移。以下对该模型做简要介绍。
模型的框架如图2 所示。首先使用一个编码E 器从目标参考图片It中提取外貌相关特征Ft:

图2 运动迁移模型的框架Fig.2 Framework of motion transfer model
然后利用运动估计模块去计算It与驱动视频帧Iid之间的运动p,具体来说,该运动可以用一个光流表示。此外,运动估计模块同时估计了一个遮挡图O。遮挡图用于指示出扭曲后缺失的区域。接着,将估计到的运动作用于Ft中,得到扭曲后的外貌特征F͂s:
式中,W(⋅,⋅)表示扭曲操作,⊙表示哈达玛积。最后将扭曲后的特征通过解码器D生成一张迁移动作后的图片:
在训练时,目标参考图片与驱动视频帧来自于同一段视频的不同帧,以一种自我重演的方式训练。目标函数约束合成的图片需要与驱动视频帧保持一致。为了能由参考目标图片提取的特征重构出驱动视频帧,运动估计模块必须具备充分建模图片中各部分区域运动的能力。因此,训练完成后,运动估计模块能充分地建模并迁移包括肩膀在内各部分动作。这相对于人工标注的面部关键点或一些参数化人脸模型在动作迁移能力上都具有更大优势。
在人像视频数据集训练完成后,模型可以应用于不同身份的人像图片。在测试时,有标准和相对两种模式迁移动作。在标准模式下,计算Idi与It之间的运动,并作用到It上,合成图片。在相对运动迁移模式下,需要从Vd中提取一张姿势与It相似的图片Id′,提取Id′与Idi之间的运动并作用到It上,得到图片。以这种方式,可以将Vd的动作迁移到目标人物上从而得到一个与驱动人物动作一致的粗糙目标视频=
由于相对模式迁移动作更利于保持目标人物身份特征,本文后续实验皆采用相对模式。此外,由于背景区域常被错误地扭曲。因此,本文方法基于人像分割技术[16],去除It中的背景再进行动作的迁移,并在下文的PC-UNet重新合成背景。
2.2 PC-UNet的网络结构
第一阶段只基于一张目标图片It进行扭曲和填充合成图片,图片中无法基于It扭曲得到的区域是依靠一个面向不同主体的解码器进行填充修复。最终效果与真实图片存在较大的差异。本文设计一个神经网络PC-UNet 并基于一个目标视频Vt对其进行训练,学习解码器的扭曲和填充规律,对第一阶段合成的视频进行修复。具体来说,PC-UNet的输入是第一阶段中迁移动作后粗糙的视频V͂d→t。该网络需要修复V͂d→t中牙齿,头发等出现错误的区域和填补缺失的背景,将V͂d→t转化为逼真的目标视频Y。本文提出的PC-UNet结构如图3所示。

图3 PC-UNet网络结构Fig.3 Network structure of PC-UNet
PC-UNet 结合了的前后w帧修复,其输入为。前后帧为图片的修复提供了历史与未来信息的上下文信息,增加合成视频的流畅度。PC-UNet采用三维卷积处理带有时域信息的。具体来说,沿时域维度进行拼接,得到一个大小为(2w+1)×H×W×3 的4 维张量。其中H和W为图片的长宽,w是时域窗口半径,决定了输入进网络的图片数量。
PC-UNet 的最前部为一个编码器(图3 中灰色箭头的集合),该编码器基于移除时间跨步与末尾全连接层的18 层3D-ResNet[17]修改而成,总共包含5 个三维残差卷积块,如图3(a)所示。由于第一阶段合成的图片中部分区域是具有参考价值的,为更好地保留空间上的低层次特征同时避免依赖大量的算力,移除5个三维残差卷积块中第1个的空间跨步。
编码器之后,使用一个解码器(图3 中粉色箭头的集合)从低维特征对人像进行修复,并得到修复后特征。解码器基于转置卷积块(图3(b))对低维特征进行上采样。此外,与经典的U-NET[18]类似,网络的编码器和解码器之间加入了跳跃链接并通过拼接的方式进行特征融合。值得注意的是,在解码器中,最后一层不需要空间跨步,与编码器的设计对应,以方便部署跳跃链接。
此外,网络编码器和解码器的每个模块中都加入了一种注意模块(图3(c))。注意力机制可以协助网络关注重要的区域,在如图像识别等[19]众多深度学习相关的任务中都有应用。具体来说,本文注意力模块以大小为Ci×(2w+1)×Hi×Wi的张量作为输入,此处Hi×Wi为特征图的长宽,Ci为特征通道数。不妨记这个张量为Xi。Xi通过一个时空池化层,得到一个张量Xpool。然后Xpool输入进一个全连接层处理,得到长为Ci的Xatt。Xatt的值代表着Xi各个通道的注意力权重。Xi每个通道的值都乘以其对应的权重,得到最终输出。注意力可以增加特征图中某些通道的权重,这些通道可能包含对肖像修正有用的信息,比如指出需要大幅修正的区域。
解码器的输出是一个(2w+1)×H×W×C大小的三维特征图,其中C为输出通道数。为了将解码器输出的三维特征图转换为二维特征图,将时间维度的特征沿通道进行拼接。拼接过程如图3(d)所示。以此得到一个大小为H×W×(2w+1)C的二维特征图。该二维特征图通过二维卷积对时间特征进行聚合,得到大小为H×W×3 的特征图。
第一阶段中合成的视频背景可能被误扭曲,包含着错误的信息,因而被抛弃了。PC-UNet需要对背景进行重新修复。在背景纹理复杂的情况下,依赖网络进行修复可能会与真实背景存在差异。为解决该问题,本文假设背景是静态的。基于人像分割技术提取目标参考图片中的背景,并再将背景信息嵌入到网络中,作为网络的固定参数置于网络的末尾部分。因此,PC-UNet只需预测背景的小部分区域,保证了背景的稳定性。
2.3 网络的训练细节
2.3.1 训练集的获取方法
网络的训练依赖于一段目标人物的视频Vt,从该视频中提取一个目标参考图片。这里不妨假设以I1t为目标参考图片,首先基于FOMM将I1t与Ii t的运动提取出来,并作用到I1t上。以自我重演的方式合成一段相对粗糙的视频与Vt可组成训练对以用于训练网络。这里不妨把PC-UNet 生成器网络记为生成器网络G ,则:
其中,yi为最终合成的视频Y中的第i帧。网络需要把精确地还原为Ii t,即让yi尽量接近Ii t。
2.3.2 判别器
网络基于GAN架构训练以合成更真实的图片。在训练过程中,需要使用一个判别器D。判别器用于学习区分真实帧Ii t和合成帧yi,与生成器进行博弈,使得生成器可以合成更真实的图片。本文使用的判别器基于Pix2PixHD[20]提出的判别器扩展而来。具体来说,将其拓展到能容纳与yi或Ii t作为输入。
2.3.3 目标函数
生成器以一种对抗的方式训练,本文采用最小二乘损失(least square loss)以稳定训练的过程,目标函数与LSGAN 原文[21]保持一致,即a=c=1 和b=0。此时,G的对抗目标函数为:
由于嘴部是非常具有表情表达能力的区域,也是关注的重点。牙齿细节的缺失容易导致视频的真实度大幅降低。本文加入了一个嘴部增强损失,用于改善口眼部位的质量。具体来说,基于Dlib 库提取Ii t中嘴巴区域的关键点,并根据关键点得到一个嘴部掩膜Miaug。嘴部增强损失如下:
最后,生成器的目标函数为:
为了平衡各个损失项的权重,设置α=1,β=100,γ=500。
3 实验与结果分析
本章介绍了实验的具体实施细节及评价指标,详细分析了消融实验,并将本文方法与目前其他先进的人脸重演方法进行对比。
3.1 数据集与实施细节
实验所采用Head2Head++[1]公开发布的数据集测试本文的方法。该数据集包含Trump、Von Der Leyen、Macron、Mitsotakis、Sanchez 和Johnson 等不同人物至少10 min长的原始目标视频,覆盖了不同的性别与不同的动作幅度。文中所有的图片皆源自于该数据集。实验采用与Head2Head++相同的方法对原始视频进行预处理,每个视频被裁剪并调整为长宽为256 像素的图片。本文所有实验都在一个安装了Tesla V100 GPU 的Ubuntu 18.04 服务器上进行,所有模型都基于PyTorch实现,并使用默认参数设置的Adam 优化器[22]进行优化。训练过程需要60 个周期,批大小为5,学习率为0.000 15。在测试期间,每一帧图片进行动作迁移的耗时约为0.024 2 s,PC-UNet修复细节则需要约0.01 s。总的来说,在Tesla V100 GPU服务器中,本文方法可以达到每秒29帧图片的合成速度,具有一定的实时性。
3.2 重演方法及评价指标
实验可以划分为自我重演与跨身份重演两个方面。自我重演实验主要用于定量评估。在自我重演实验中,目标视频与驱动视频来自于同一段视频的前后两部分。具体来说,一个目标视频Vt被划分为训练集Vt-train及测试集Vt-test。在基于Vt-train合成训练完成后,把Vt-test作为驱动视频进行测试。测试时,由于合成视频Ytest所对应的真实视频Vt-test是已知的,可以定量地衡量合成视频的质量,后文中的定量指标皆基于自我重演实验获取。为便于比较,训练集和测试集的划分与Head2Head++相同。为了衡量合成视频与真实视频的差异,采用了如下评价指标:
(1)平均真假图片像素间的L2 距离APD(average pixel distance)。该指标直观地反映出真假图片之间的差异。
(2)真假图片中人像区域平均的像素间L2 距离APD-P(average pixel distance for portrait)。该指标使用人像分割技术提取真实视频的人像区域,并计算真假图片间人像区域的ADP。该指标能关注于人像区域与真实的差异,一方面反映了人像区域的细节,另一方面反映了模型是否能更完整地迁移人物动作。
(3)用于衡量真实图像与合成图像特征层面的差异的指标FⅠD(Fréchet inception distance)[23],该指标可以反映图片的真实感。
(4)用于衡量视频真实感的指标FVD(Fréchet video distance)[24]。
对于所有指标,数值越低代表效果越好。自我重演实验的例子如图4所示。

图4 自我重演实验的样例Fig.4 Example of self-reenactment
跨身份重演实验可以定性地评估实际的合成效果,此时驱动视频与目标视频为不同视频。基于FOMM将驱动视频的动作作用到I1t上,合成粗糙的视频,然后采用PC-UNet 进行修复。跨身份重演可以揭露出身份保存等自我重演无法发现的问题,结果更接近于实际的应用场景。跨身份重演的样例如图5所示。

图5 跨身份重演实验的样例Fig.5 Example of cross identity reenactment
3.3 消融实验
本节详细介绍关于PC-UNet的上下文信息输入、网络结构、背景嵌入网络,以及嘴部增强损失多个方面的消融实验。
3.3.1 上下文信息的重要性
本文中的PC-UNet 利用第一阶段动作迁移的结果前后w帧的上下文信息去修复,以合成更高质量的视频。本小节通过改变时域窗口半径的大小w,调整输入到PC-UNet 的上下文信息的长度,探究其对PC-UNet 修复效果的影响,以验证其重要性。表1 为基于不同时域窗口半径进行自我重演实验得到的结果。由于训练集中存在动态背景视频,为了更好地关注人像部分的指标,消融实验部分去除了数据集中动态背景的视频,表中数据为静态背景视频实验结果的平均值。当w=0 时,PC-UNet的输入没有无上下文信息,仅有单独1 帧图片。当w=1 时,PC-UNet 的输入为共3帧图片。从表1可以看到,w=1 时各项定量指标远优于w=0 的结果。其中,反映视频整体质量的指标FVD最为明显,从w=1 时的45.92大幅上涨到w=0 时52.97。这主要表现在了合成视频的流畅度上。当w=0时,合成的视频中存在明显的抖动现象。这说明了上下文信息对修复效果以及视频流畅度的重要性。然而,当进一步将PC-UNet 的输入继续拓展为w=2 时,可以观察到总体指标进一步提高,得到了更好的结果,但效果提升的程度大幅降低,这可以解释为待修复帧与距离越远的帧关联性越低。继续增大时域窗口难以进一步提高修复效果。此外,随着时域维度的增加,计算量也将随之增加。因此,为了取得计算量与效果之间的平衡,在本文后续的实验中采取w=1 的设定。

表1 不同时域窗口半径大小的消融实验Table 1 Ablation experiment of different temporal window radius
3.3.2 三维卷积及注意力机制
上下文信息对视频修复效果有明显的帮助。为了更好地利用上下文信息,本文为PC-UNet引入了三维卷积以提高合成视频的效果。为了验证这一设计的重要性,实验使用一个基于二维卷积的经典U 型神经网络(2D-UNet)替换本文PC-UNet作为用于修复细节的网络。该网络由DVP[3]提出,具有较为优异的性能。该2D-UNet与去除注意力模块的PC-UNet(3D-UNet)进行对比,对比结果如表2所示。将2D-UNet改换为3D-UNet后,在网络参数量下降的情况下,FVD指标从49.6优化为47.1,视频的整体质量有所提高。这表明基于三维卷积的网络可以更好地利用时间维度上的信息,合成更加流畅的视频。

表2 不同网络结构的对比Table 2 Comparison of different network structures
此外,本文在PC-UNet 中引入了一种注意力机制,图6 展示了注意力机制在修正过程中的作用。具体来说,实验提取了PC-UNet的编码器中最后一个下采样模块中最大注意力权重对应的三维特征图。三个维度中,两个对应空间,一个对应时间。实验可视化了位于时间维度中间的特征图。可视化的特征图中的颜色代表该处值的大小(红色为最大,蓝色为最小)。将该特征图与对应的输入进行重叠可以发现,注意力机制可以关注到需要大幅度修改的区域,这有利于人像修正的过程。

图6 注意力最大值对应特征图的可视化Fig.6 Visualization of feature map with max attention value
图7直观地展现出了PC-UNet去除注意力模块前后修复效果的差异。放大观察图像可以发现,在PC-UNet的注意力模块去除前,合成的面部纹理细节相较于注意力模块去除后更加丰富。定量对比的结果如表2中后两行所示,加入注意力模块后(表2中3D-UNet+注意力),关于图像、视频的质量指标FⅠD、FVD 都得到一定程度的优化。这与定性比较结果是相符的,体现了注意力模块的重要性。

图7 注意力模块的重要性Fig.7 Ⅰmportance of attention module
3.3.3 背景信息嵌入网络
在PC-UNet 的设计中,为了确保背景合成的效果,实验假设背景是固定的,并在网络中嵌入了背景的信息作为网络的固定参数保持不变。如图8 对比了有无背景信息嵌入的差异,展示了这个设计的重要性。观察放大的区域可以发现,有背景信息嵌入的PC-UNet合成的背景能与真实的背景保持一致。相比之下,将背景信息嵌入去除后,合成的背景部分与真实的图片出现了细小差异,一定程度上影响了视频的真实感。

图8 背景信息嵌入网络的重要性Fig.8 Ⅰmportance of embedding background information into network
3.3.4 嘴部增强损失
嘴巴是人像中最有表现力的区域,也是人们关注的重点,嘴部的细节非常影响合成视频的质量。为了确保嘴部真实性,本文加入了嘴部增强损失Laug,确保嘴部的牙齿的细节与真实度。如图9 展示了嘴部增强损失加入前后的差异。可以看出,当去除Laug后,牙齿部分的细节将会丢失,牙齿糊成一片,影响了视频的真实感。加入Laug后,合成的牙齿颗粒分明,这体现出了嘴部增强损失的重要性。

图9 嘴部增强损失的重要性Fig.9 Ⅰmportance of mouth augment loss
3.4 对比实验
本节将本文方法与当前先进的人脸重演方法进行对比。对比的方法包括面向不同主体的模型(X2Face[4]和FOMM[6])及针对特定主体的方法(Head2Head++[1]和Vid2Vid[2])。对比方法在与本文方法相同的数据集上进行了自我重演实验,得到定量指标如表3 所示,表中指标为数据集中所有人物的结果的平均值。以下对对比实验进行详细的分析。

表3 与目前优秀方法的对比结果Table 3 Results of comparison with current state-of-the-art methods
本文与面向不同主体的模型X2Face 和FOMM 的自我重演实验对比结果,如图10所示。由于此类方法没有利用目标人物的视频信息,仅依赖单张图片进行人脸重演,其最终合成效果与真实图片在各个部位都存在显著的差异。相比之下,本文方法充分利用了目标人物的视频的信息,为每个目标人物训练一个专用的PC-UNet,合成效果非常接近真实图片,视觉效果大幅优于上述两种面向不同主体的模型。这与表3 中定量对比的指标一致。值得注意的是,与FOMM 的对比也验证了PC-UNet的有效性。经过PC-UNet的修复,FOMM产生的粗糙视频可以转变为与真实几乎无异的视频。这再次体现了PC-UNet的修复效果。

图10 与FOMM和X2Face的对比Fig.10 Comparison with FOMM and X2Fce
实验进一步与针对特定人物的方法Vid2Vid 和Head2Head++进行对比。这两个模型都是目前的优秀的人脸重演方法,可以合成逼真的视频。
Vid2Vid 基于有监督的人脸地标进行动作迁移,在迁移后使用针对特定人物的人脸地标到图片转换网络合成最终图片。如图11 为本文方法与Vid2Vid 在跨身份重演实验上的对比效果。从参考目标图片中观察目标人物的真实脸型,将其与Vid2Vid 最终合成的目标人物进行对比,可以发现两者之间出现了较大差异。Vid2Vid合成出的脸型相对于真实目标脸型更加修长,变得驱动人物的脸型相一致。这是由于Vid2Vid基于有监督的人脸地标进行动作迁移。在跨身份重演中,不仅迁移了动作,还迁移了驱动人物的脸部轮廓等身份信息,出现了身份保存问题。相比之下,本文方法合成的脸型与目标人物真实的脸型是保持一致的。这说明本文基于无监督动作迁移模型进行相对动作迁移再修复的方案可以有效避免身份保存问题。

图11 与Vid2Vid的对比实验Fig.11 Comparison with Vid2Vid
另一方面,Head2Head++基于三维参数化人脸模型迁移动作,并利用一个针对特定人物神经网络将三维人脸模型渲染的视频转化为真实的视频。三维参数化人脸模型可以解耦身份与姿势相关参数,解决了身份保存问题。然而,三维参数化人脸模型没有建模整个上半身各个区域的动作,因此Head2Head++的动作迁移能力较为有限。如图12 所示,驱动人物由时刻A 的姿势变为时刻B的姿势时,Head2Head++合成目标人物的动作幅度与驱动人物出现了一定的差异。例如肩膀部分,不妨以领带为参照物,驱动人物的领带明显向下移动,而Head2Head++合成的人物的领带并没有发生明显的移动。相比之下,本文方法合成的目标人物的领带是跟随驱动人物往下移动。对比之下不难发现,本文方法可以将驱动人物的动作更完整地迁移到目标人物。

图12 与Head2Head++的对比实验Fig.12 Comparison with Head2Head++
此外,Head2Head++中三维人脸模型没有建模肩部的运动,迁移肩部的动作。这可能导致最终合成的头部与肩部不匹配。如图13 所示,在Head2Head++合成的图片中,头部姿势与肩部姿势出现了明显的割裂,这影响了最终合成视频的真实感。对比之下,本文方法基于无监督运动迁移模型进行动作的迁移,可以更充分地迁移肩膀的动作,避免了该问题的出现。

图13 与Head2Head++的进一步对比实验Fig.13 Further comparison with Head2Head++
在表3本文方法与Head2Head++和Vid2Vid的定量对比中,各项指标皆优于对比方法。其中,值得关注的是本文方法的人像区域的像素间距离APD-P 远低于对比方法,这也定量地验证了本文方法能更大程度地迁移动作,合成更真实的图片。此外,本文方法在代表视频流畅度与图片真实感的指标FVD 与FⅠD 中,也取得了相对于对比方法更优的成绩,与前文定性对比的结论相符。
3.5 局限性分析
虽然本文方法在多数场景中可以获得逼真的重演结果,但也存在一些局限性。一方面,与其他基于GAN的方法[1-3]一样,本文的方法的合成效果依赖于训练集中目标人物姿势的丰富度。在合成训练集中未出现的极端姿势时(例如大角度扭头),合成视频的质量会出现下降。另一方面,在某些目标视频的拍摄过程中,相机可能存在一定程度的移动。所以,训练集中的背景可能不是固定的。以这类动态背景的视频训练模型会导致合成错误的背景,影响视频观感。图14 为基于自我重演实验获取的合成结果,展示了本文方法存在的局限性。对比图14 中前两张图片中的人脸区域可以发现,在合成大幅度扭头的极端姿势时,图像的面部区域出现了差错。对比图14 后两张图片的背景区域,如果训练集中目标视频背景不是固定的,合成的背景可能会产生伪影。

图14 局限性分析实验Fig.14 Limitation analysis experiment
上述问题无论是在本文方法还是先前方法都没得到有效解决。在未来的工作中,还需进一步研究具有更强泛化能力的算法和具有动态背景处理能力的模型。
4 结束语
本文设计了一种无监督动作迁移再修复的人脸重演方法。基于一种无监督运动迁移模型进行人物动作迁移。针对迁移动作后粗糙的视频,考虑视频的流畅度与画质,设计了一个针对特定目标人物的生成网络PCUNet。网络融合了三维卷积、注意力机制等技术,对粗糙的视频进行修复。本文方法可以合成出真假难辨的视频。此外,与目前先进的人脸重演方法的对比实验也进一步验证了本文方法的效果。然而,无论是先前方法还是本文方法都仍无法较好地解决泛化性问题和处理动态背景。在未来的工作中,还需要针对这些问题进行进一步的研究。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
动漫星空(2018年9期)2018-10-26
小学生作文(低年级适用)(2018年3期)2018-04-17
少儿科学周刊·少年版(2015年4期)2015-07-07
西南科技大学学报(哲学社会科学版)(2015年1期)2015-02-28
发明与创新(2015年33期)2015-02-27
连环画报(2014年6期)2014-11-14
奇闻怪事(2014年5期)2014-05-13
青年文摘·上半月(1998年12期)1998-12-31
雕塑(1995年4期)1995-07-12
