
结合特征调整与联合自注意力的图像修复
2023-10-10 10:39李晓明
计算机工程与应用 2023年19期
彭 豪,李晓明,2
1.太原科技大学 计算机科学与技术学院,太原 030024
2.太原科技大学 计算机科学与技术学院 计算机重点实验室,太原 030024
图像修复的目的是为图像中的缺失区域生成视觉上合理的图像结构和局部细节[1]。图像修复在图像编辑中得到了广泛的应用,如照片编辑[2]、对象移除[3]和计算机辅助文物修复等[4-5]。近年来,深度学习在图像修复领域取得了成功。然而,如何在图像破损区域合成与现有上下文区域结构语义一致、内容准确、细节丰富的局部图像信息仍然是图像修复中需要解决的难点问题[6]。
在人们将深度学习技术广泛应用于图像修复之前,人们使用了传统的图像修复技术。这些方法主要分为两类:基于扩散的方法和基于样本的方法。基于扩散的方法利用待修复区域的边缘信息,同时采用一种由粗到细的方法来估计等照度线的方向,并采用传播机制将图像已知信息传播到待修复的区域内,以便得到较好的修复效果。基于样本的方法通过搜索缺失区域外的已知样本来填补缺失区域。然而,缺失区域的图像并非总能在已知图像中找到,而且在重建图像中也容易出现重复的图案。基于扩散的方法和基于补丁的方法都倾向于在缺乏对图像的高级语义理解下使用未缺失区域的低层次特征,以某种方式对缺失区域进行修复。因此,它们可能在某些具有重复结构的图像中工作良好,但无法为具有独特结构的缺失图像生成合理的修复结果。
图像特征中的高级语义和丰富的空间信息存在于不同的分辨率/尺度级别中[7]。如何有效地生成不同尺度的特征成为完成图像修复任务时需要克服的关键问题之一[8]。一般来说,有两种常见的方法来解决这个问题。第一种是在不降低空间分辨率的情况下,使用不同扩张率的atrous convolutions[9]来有效捕获语义上下文信息,另一种是使用自上而下的网络结构[10]来构建不同尺寸的具有高级语义信息的特征图。更具体地说,高级语义空间上的特征图在与自底向上路径的对应特征图合并之前需要进行上采样。然而,由于常用的上采样操作的不可学习性以及下采样和上采样的重复使用,自底向上的特征与上采样的特征之间存在着不准确的对应关系。这种不准确的特征对应关系反过来又会对后续层的学习产生不利的影响,导致模型在处理不规则缺失区域时,经常会出现像素不连续的结果,这是一种明显的语义差距,尤其是在物体边界附近。
因此,本文认为保持上采样的特征图与自底向上特征图的特征空间位置一致性和加强模型对图像不同尺度特征的利用是提升图像修复性能的关键。本文的主要贡献总结如下:
(1)引入了一种上下文特征调整模块(contextual feature adjustment,CFA),该模块通过调整卷积核中的每个采样位置,使上采样的特征图与对应特征图保持一致,减少了自底向上和上采样特征之间存在的特征位置偏移问题。
(2)设计了一种联合自注意力模块(joint self-attention,JSA),通过在空间和通道维度内部保持比较高的分辨率,并采用了Softmax-Sigmoid联合的非线性函数,使得模型能够在图像修复任务上获得更好的性能。
(3)本文将这两个模块整合到一个自上而下的金字塔结构中加强了模型对图像不同尺度特征的利用,并提出了一种结合上下文特征调整和联合自注意力的图像修复方法。本文在多个标准数据集上进行实验,通过定性和定量比较表明:当修复任务涉及大面积缺陷或复杂结构时,本文的方法比现有的主流方法具有更高的修复质量。
1 相关工作
1.1 基于生成模型的图像修复方法
基于生成模型的图像修复方法指利用生成模型强大的图像生成能力来基于缺失图像已知先验分布推测未知分布的修复方法。生成式对抗神经网络[11]作为一种非监督的生成式深度学习模型,能够自动学习和捕捉数据中的重复可用特征,在图像语义修复任务上取得了巨大进展。但是现阶段基于生成式对抗网络的图像修复算法仍然有许多值得完善的地方,如深度卷积神经网络[12]没有完全利用已知区域的信息,导致修复后的区域有严重的贴片感,甚至会产生不合理的修复内容。在生成对抗网络之后,context encoders[7]利用深度神经网络生成缺失区域。上下文编码器通过从原始图像中提取特征来填补缺失区域。然而,这种方法的缺点是生成的图像包含太多的视觉伪影。为了获得更真实的修复效果,Ⅰizuka等人[13]扩展了上下文编码器的工作,并提出了局部和全局鉴别器,以使生成的图像更逼真。Shift-Net[14]使用具有特殊移位连接层的U-Net[15]体系结构来指导图像生成。Zhang等人[16]将图像修复任务视为一个课程学习问题,提出了从外到内的逐步修复策略。该方法能够逐步缩小原始图像中的缺失区域。Li 等人[17]提出了一个递归特征推理模块,该模块可以反复推断缺失区域边界的特征映射并将其用作下一步推断的线索。基于生成模型的方法可以实现多样性修复,但由于生成模型存在训练不稳定,该类方法目前仅能处理较低分辨率的图像。
1.2 基于注意力机制的图像修复方法
传统图像修复方法中,基于纹理合成的图像修复方法中的块匹配方法是在像素或图像块层面进行修复,缺少对图像语义和全局结构的理解。基于此,研究者们尝试将图像块匹配思想引入图像特征空间,在注意力机制的引导下为缺失区域寻找最相似的特征块进行特征匹配,最终提出了一系列基于注意力机制的图像修复方法。随着注意力机制的提出和应用[18],Liu等人[19]引入了连贯语义注意力层,以改善相邻像素的连续性。Wang等人[20]介绍了一种特殊的多级注意力模块,该方法将编码器编码的高级语义特征进行多尺度压缩和多层级注意力特征传播,以实现包括结构和细节在内的高级特征的充分利用。Yu 等人[21]认为图像结构扭曲和纹理模糊的原因是卷积神经网络在明确地从遥远的空间位置借用或复制信息方面的无效性。因此,他们引入了上下文注意力机制来增强模型的远距离建模能力,但是该模型无法从远处像素获取准确的特征信息,并且无法充分利用图像中不同尺度的特征信息。
2 结合上下文特征调整的多级注意力特征融合的图像修复模型
本文提出的图像修复算法的体系结构如图1 所示。本文在编码器encoder 和解码器decoder 的相应层之间使用跳跃连接[15]。跳跃连接将不同的编码器级别与作为解码器的分层主网络的级别连接起来。本文在CelebA数据集上对EfficientNet中B1~B7不同的网络结构进行了图像修复质量测试,如表1所示EfficientNet-B7实现了最高图像修复质量,因此本文在backbone 部分使用EfficientNet[22]网络中B7网络结构。EfficientNet网络主要探究增大网络的宽度、深度以及分辨率来提升模型的性能。本文通过调整EfficientNet网络中子模块(MBConvBlock模块)的stride来修改不同阶段所输出的feature map的分辨率。如图1,经过stride=n的feature map输出,n为2、4、8、16。首先解码器中对应编码器的特征图都使用联合自注意力模块来强化有效特征,然后使用双线性上采样,并在上下文特征调整模块帮助下与下一个分辨率更佳的特征图连接。本文鉴别器使用patch-based discriminator network[23]用于判别接收到图像的真假。下面将具体阐述本文的上下文特征调整模块和联合自注意力模块。
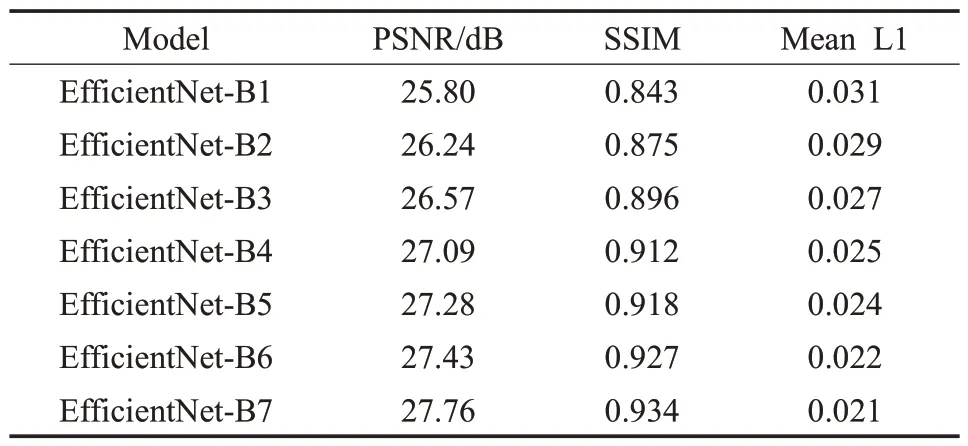
表1 EfficientNet B1~B7在CelebA上的图像修复质量测试Table 1 EfficientNet B1~B7 image inpainting quality test in CelebA

图1 提出的图像修复算法的体系结构Fig.1 Architecture of proposed image inpainting algorithm
2.1 上下文特征调整模块
在特征提取过程中,由于重复使用下采样操作导致上采样特征图与相应的自底向上的特征图Ui之间存在一定的空间偏差,导致直接使用element-wise addition或者channal-wise concatenation的融合会损害目标边界的预测。因此,本文在特征融合之前,使用文献[24]中的特征调整方法对图像修复任务中的上采样特征F和下采样的特征Ui进行调整。在特征融合之前,根据相应的自底向上的特征图Fi-1提供的空间位置信息调整上采样特征图Ui。空间位置信息是通过二维特征图来表示的,其中每个偏移值可以看作是在二维空间中F每个点与其Ui对应点之间的偏移距离Δi。上下文特征调整的过程可以看作是两个步骤:首先从上采样和下采样特征图中,f1为学习空间偏差Δi:
然后通过f2将偏差Δi作用于下采样特征图Ui,进行调整得到调整后的特征图F:
其中,f1、f2都是使用可变形卷积[25]和同样卷积核大小的标准卷积组成。
本文使用可变形卷积来完成本文的特征调整功能。本文首先定义一个输入特征映射Fi∈RHi×Wi和K×K大小的卷积,在卷积核之后的任意位置x输出特征F为:
其中,N为K×K卷积核大小的卷积,wn和Bn分别表示对于第n次卷积采样位置的权重和预先指定的偏移量,除了预先指定的偏移外,可变形卷积还尝试学习其他偏移ΔBn适用于不同的采样位置,公式表示如下:
其中,ΔBn是一个(h,w)元组,h∈(-Hi,Hi),w∈(-Wi,Wi)。
2.2 联合自注意力机制
图像修复任务要求模型在低计算开销下,能够有效地建模高分辨率输入/输出特征的远距离依赖关系,进而来估计高度非线性的像素语义。卷积神经网络中的注意力机制能够捕获远距离的依赖关系,但是这种方式比较复杂并且是对噪声比较敏感的。本文采用的是encoder-decoder 结构,encoder 用来降低空间维度、提高通道维度;decoder采用的是上采样,用来提高空间的维度、降低通道的维度。因此,连接encoder 和decoder 的tensor通常在空间维度上比较小。虽然这对于计算和显存的使用比较友好,但是对于像图像修复这样的细粒度像素级任务,这种结构显然会造成性能上的损失。
如图2所示,本文的注意力机制由通道注意力分支和空间注意力分支两种组成。本文注意力机制主要有两个设计上的亮点:(1)在通道和空间维度保持比较高的分辨率,在通道上保持C/2 的维度,在空间上保持[H,W]的维度减少降维造成的信息损失;(2)采用Softmax-Sigmoid联合的非线性函数。

图2 联合自注意力机制示意图Fig.2 Diagram of joint self-attention mechanism
通道注意力分支的权重计算公式C(x)如下:
其中,z1、z2和z3为张量重塑操作,FS是Softmax操作,F为Sigmoid 函数,×为矩阵积运算。将输入的特征x通过1×1的卷积得到q和v特征,其中q的通道被完全压缩,而v的通道维度依旧保持在一个比较高的水平(也就是C/2)。由于q的通道维度被压缩,为了避免信息损失,本文首先通过Softmax对q的信息进行了增强,然后将q和v进行矩阵乘法,并在后面接上1×1卷积将通道上C/2 的维度升为C。最后用Sigmoid 函数使得所有的参数都保持在0~1之间。
空间注意力分支计算权重的公式S(x)如下:
与通道注意力分支的权重计算相似,本文先用了1×1的卷积将输入的特征转换为q和v特征。其中,本文使用FGPglobal pooling 将q特征空间维度压缩为1×1的大小,而v特征的空间维度则保持在一个比较高的水平(H×W)。由于q的空间维度被压缩了,所以本文使用Softmax对v的信息进行增强。首先将q和v进行矩阵乘法,然后使用reshape操作和Sigmoid激活函数使得所有的参数都保持在0~1 之间。最后对通道分支和空间分支的结果进行了并联得到最终联合自注意力JSAp:
其中,x∈RC×H×W,⊙c为channel-wise 上的乘法运算,⊙s为spatial-wise 上的乘法运算。本文采用的是selfattention[18]的方式来获取注意力权重,充分利用了selfattention 结构的建模能力,并且本文对q也进行了特征降维,所以在保证计算量的情况下,实现了一种非常有效的远距离建模。
2.3 损失函数
为了更好地恢复缺失图像中的语义和真实细节,本文将对抗损失、像素重建损失、感知损失、风格损失结合起来共同训练本文的模型。
2.3.1 对抗损失
对抗损失[11]可以提高生成图像的视觉质量,常用于图像生成[26]和图像风格迁移[27]。此外,对抗损失使得生成器和鉴别器不断优化,提高了生成图像的细节质量。本文的图像修复网络的对抗损失为:
其中,Pdata(Igt)表示真实图像的分布;Pmiss(Ipred)表示修复图像的分布;minΘ生成器在尽可能地使该式的结果最小化;而maxD判别器却在尽可能地使结果最大化,模型在这种对抗中不断得到优化。
2.3.2 像素重构损失
像素重构损失Ll1[28]计算的是修复图像Ipred与真实图像Igt之间的像素差。像素重建损失的L1-Norm范数误差表示为:
2.3.3 感知损失
对抗损失改善了纹理质量,但这种损失在模型学习结构信息时是有限的。这些损失仍然无法捕获高级语义,不适合生成与人类感知[29]一致的图像。与此不同的是,感知损失是将卷积得到的特征与真实图像进行比较。这种损失可以度量图像[30]之间的高级语义的相似性,有效地改善了修复图像的结构。图像修复网络的感知损失为[28]:
其中,ϕi是从ⅠmageNet[31]数据集上预先训练的VGG-16[32]网络的池化层中提取的图像I的第l层特征图,hl、wl和cl分别是ϕi(I)的长度、宽度以及通道数。
2.3.4 风格损失
虽然对抗性损失和感知损失可以有效地改善图像的纹理和细节,但它们无法避免修复结果产生视觉伪影。因此,本文在损失函数中添加了风格损失,以提高整体一致性,图像修复网络的风格损失定义为:
其中,Gram矩阵用于计算特征间的相关性。Gram矩阵是通过计算内积的Hermitian矩阵得到,其构造定义为:
2.3.5 模型目标
根据上述损失函数,本文模型的总体目标损失函数如下:
其中,α、αp、αs和αl1是平衡不同损失项贡献的超参数。在本文的实现中,本文根据文献[11]设置了α=0.1,αp=1,αs=250,αl1=1。
2.4 算法流程
结合上下文特征调整的多级注意力特征融合的图像修复算法如下:
输入:受损原图,随机掩码。
输出:本文算法修复后的图片。
Begin algorithm
1.首先从训练数据中批量采样图像x,然后为每一批图像中的每一张图像使用随机掩码来获得受损图像。
2.if stage==1。
3.训练生成器=True;训练判别器=False。
4.epochs 为40,每轮4 000 次迭代,在重建损失、感知损失、风格损失和TV惩罚项的加权损失函数下更新生成网络来得到修复图。
5.elif stage==2。
6.训练生成器=False;训练判别器=True。
7.epochs 为10,每轮2 000 次迭代,在对抗性损失函数下更新判别器。
8.elif stage==3:
9.训练生成器=True;训练判别器=True。
10.加权所有损失函数来更新整个网络,epochs 为10,每轮2 000次迭代。
3 实验及分析
在模型训练过程中,输入图像均被缩放至256×256大小。所有实验都是在Ubuntu 17.10系统上使用Python进行的,该系统配有i7-6800K 3.40 GHz CPU 和11 GB NVⅠDⅠA RTX2080Ti GPU。
3.1 实现细节
训练分为三个阶段:首先训练生成网络,批处理大小设为6,每轮4 000次迭代,共40轮,学习率为0.000 2;然后固定生成网络,训练2 个判别器,批处理大小设为6,每轮2 000 次迭代,共10 轮,学习率为0.05。最后,将生成网络和2个判别器联合训练,批处理大小设为6,每轮2 000次迭代,共10轮,学习率为0.000 2。
3.2 实验数据集和图片掩码
本文在3个公共数据集和1种掩码上评估了本文的方法。
CelebA[33]:这个数据集是香港大学在2015年发布的一个大型人脸属性数据集,包括约20万张名人图片。
Paris StreetView[34]:该数据集包含14 900 张训练图像和100 张从巴黎街景中收集的测试图像。这个数据集侧重于城市的真实街道场景。
Places2[35]:数据集中包含来自365 个场景的800 多万张图像。
Ⅰrregular masks:本文使用了[36]中的掩码集,它有12 000 个不规则掩码,根据掩码的大小预分为3 个区间(10%~20%,30%~40%,50%~60%)。
3.3 模型对比
将本文的方法与几个主流的方法进行比较。这些模型在与本文相同的实验设置下被训练到收敛,这些模型如下所示。
EC[37]:边界信息引导的图像修复模型,利用边界信息来完成图像修复。
CA[21]:算法采用encoder-decoder结构去推断已缺失图像区域的上下文,利用了高层次的上下文注意特征细化纹理细节。
MFE[38]:用于图像修复的互编解码模型。来自浅层的CNN特征表示纹理,来自深层的特征表示结构。
RFR[17]:特征推理修复模型,通过逐步填充缺失区域的信息来完成图像修复。
3.4 实验结果
在这一部分,将本文的模型与上一节中提到的几种最先进的方法进行了比较。分别进行了定性分析和定量分析,以证明本文方法的优越性。
定性比较:图3展示了本文方法与对比方法在CelebA、Places2和Paris StreetView数据集上的对比结果,GT为真实图像。在大多数情况下,本文的修复结果比对比方法具有更准确的结构重建能力,明显减少了不一致性,与其他方法相比,产生了更详细合理的修复结果。

图3 不同模型的图像修复结果定性对比Fig.3 Qualitative comparison of image inpainting results for different models
定量比较:本文用结构相似度指数(SSⅠM)、峰值信噪比(PSNR)和mean L1 loss来客观衡量修复结果的质量。其中,PSNR 和SSⅠM 可以大致反映模型重构原始图像内容的能力,为人类的视觉感知提供了良好的近似。mean L1 loss 损失直接测量重建图像与真实图像之间的L1 距离,是一个非常实用的图像质量评估指标。如表2所示,本文的方法在掩码率为50%到60%时拥有最高的SSⅠM、PSNR和最小平均L1 loss。
3.5 消融研究
3.5.1 上下文特征调整模块的消融实验
为了验证上下文特征调整模块的有效性,本文比较了没有使用上下文特征调整模块的图像修复效果和使用上下文特征调整模块的效果。实验结果如图4所示。本文发现使用上下文特征调整模块的生成图像中具有更准确和完整的结构信息,从而证明了上下文特征调整模块能够有效地保持图像修复中语义结构信息的完整性。

图4 有/无CFA的图像修复结果Fig.4 Ⅰmage inpainting results with/without contextual feature adjustment
3.5.2 联合自注意力模块消融实验
联合自注意力被设计用来提高本文方法中的修复性能。为了研究它们的有效性,本文进行了消融研究。如图5所示。本文发现在生成的图像中,使用联合自注意力模块可以更好地恢复图像中的纹理细节,从而证明了联合注意在恢复图像细粒度纹理方面的优势。

图5 有/无JSA的图像修复结果Fig.5 Ⅰmage inpainting results with/without Joint self-attention
3.5.3 模块有效性研究
为验证上下文特征调整模块以及联合自注意力的有效性,本文以平均L1 损失为性能参考进行了对比定量研究,结果如表3 所示。其中,CFA1 至CFA4 为上下文特征调整组件,JSA为本文所提出的联合自注意力模块。一般来说,随着模块的增加,平均L1 损失越小,修复性能更高。具体而言,上下文特征调整模块有助于学习更精确的场景布局,使用联合自注意力可以生成更真实的纹理,两者结合进一步改进了修复图像的结构和纹理的完整性。

表3 模块有效性研究Table 3 Module validity study
4 结束语
本文提出了一种结合上下文特征调整与联合自注意力的图像修复模型。该模型主要由两部分组成:(1)上下文特征调整模块;(2)联合自注意力模块。通过上下文特征调整模块使上采样的特征图与对应特征图空间位置保持一致,减少了自底向上和上采样特征之间存在的特征位置偏移问题。通过使用联合自注意力机制在保证计算量的情况下,实现了一种非常有效的远距离建模,使得模型能够在图像修复任务上获得更好的性能。本文将这两个模块整合到一个自上而下的金字塔结构中,加强了模型对图像不同尺度特征的利用,并形成了一个新的图像修复模型。实验表明,本文的方法可以为最终结果提供稳定的性能提升,特别是当图像修复任务涉及大面积缺陷或复杂结构时,本文的方法在质量上和数量上都优于现有的主流方法。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
开放教育研究(2020年2期)2020-03-31
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
大连民族大学学报(2015年2期)2015-02-27
