
改进YOLOv7的复杂环境下铅封小目标检测
2023-10-10 10:38张海镔雷帮军
计算机工程与应用 2023年19期
张海镔,裴 斐,雷帮军,夏 平
1.三峡大学 计算机与信息学院,湖北 宜昌 443002
2.水电工程智能视觉监测湖北省重点实验室,湖北 宜昌 443002
近年来,随着我国进出口货量大幅攀升,港口集装箱吞吐量增长迅猛,集装箱在运输和交接工作中需要对箱内货物安全进行识别,而铅封就相当于集装箱的“锁”,每一个铅封都对应着一个独一无二的封号,客户通过集装箱上的号码与货单上的编号对比,即可确认集装箱在运输过程中是否被打开过,进而得出货物是否完好无损的结论。因此对铅封进行实时准确的识别具有重要的应用价值。
传统的铅封识别方法大都为人工检测,存在着主观性强、人力成本高昂、效率低等问题,已不能满足目前集装箱业务大幅增长的需要,对集装箱信息的识别进行智能化和自动化升级,开发高精准的铅封识别方案成为亟须解决的问题。
目前,深度学习在图像识别和目标检测领域取得了出色表现,而卷积神经网络则是深度学习最具代表性的方法之一。基于深度学习的目标检测模型主要分为两类:两阶段(two-stage)模型和单阶段(one-stage)模型。前者通过各种算法生成目标的待检区(pegion proposal),然后通过卷积神经网络对目标进行准确分类和定位,如:R-CNN[1]、Fast R_CNN[2]、Faster R_CNN[3]、Mask RCNN[4]。one-stage 直接将目标的定位问题转换为回归问题进行处理,是端到端的实现方式,如:YOLO 系列(v1[5],v2[6],v3[7],v4[8])、SSD[9]等。ReDet[10]、oriented bounding boxes[11]以及box boundary-aware vectors[12]通过旋转预测框和旋转检测器提升了小目标检测效果,但其只针对摇杆场景,针对较复杂背景的不规则小目标效果不佳。杨杰敏等人[13]采用基于深度卷积网络的相关系特征图检测,相比R-FCN、Faster R-CNN、SSD等算法可以快速准确进行铅封识别,但其只能解决普通集装箱小铅封检测,对光照、恶劣条件以及拍照角度可变等因素效果不佳。针对复杂场景的小目标研究,在夜间环境下,针对荔枝等果实小目标的检测,Liang等人[14]在YOLOv3的基础上提出了一些改进方法,通过确定荔枝果实的边界框来确定检测目标的ROⅠ区域,实现了夜间自然环境中荔枝果实和果茎的检测。熊俊涛等人[15]则提出了一种改进的YOLOv3检测算法,通过引入密集连接网络和残差网络实现了多层特征的复用与融合,以提高对夜间环境中柑橘小目标的识别能力。尽管以上方法针对复杂小目标检测,已具备一定的鲁棒性和泛化能力,但在实际全天候作业的铅封小目标检测中,仍面临一些挑战。铅封的尺寸小、类型多样,形状也具有多变性。此外,铅封常常受到阴影遮挡、光线强弱不均等因素的干扰。仅将以上小目标检测或与背景区分程度较高的小目标检测方法应用在形状多样化、背景与颜色相近的铅封小目标检测,仍存在自适应性不够强,导致严重的漏检和误检问题。
YOLOv7[16]是目前图像识别与目标检测领域较为先进的深度学习方法,尽管YOLOv7算法框架在常见任务场景(如车辆检测和行人检测)中表现出色,但将它直接应用于复杂场景的小目标检测上还是面临着不少困难与局限:(1)与普通的任务场景比较,集装箱图像上的铅封大多随手挂在右箱门上把手或下把手上,仅以水平框对图像中的小铅封加以标注,并不能很好利用复杂场景下的目标与上下文信息,给小目标检测造成了障碍。(2)在特征提取和特征融合模块中的E-ELAN[16]结构虽然能增强网络的学习能力,但其检测铅封小目标的形状与尺寸的改变敏感性不佳。(3)MPConv[16]结构仅能用于类似于传统的池化操作,但在池化时对每个位置周围的采样位置是无法进行自适应调整的,从而对于目标形变和位置变化鲁棒性较差。(4)集装箱图像中铅封由于受光线强弱程度差异不同、与铅封的不同色彩相似度,会形成不同的复杂背景,而因为缺乏适当的处理复杂背景的注意力机制,造成在复杂背景下的铅封会漏检与检测不准确。(5)损失函数方面,默认的坐标损失在铅封小目标上,因为物体的尺寸很小,所以相对于整张图片来说,物体所占的像素数很少,导致物体的位置和形状的偏差对默认的坐标损失的影响显著;分类损失函数方面,交叉熵损失针对数据集中集装箱上铅封距离远近不同、受光程度不同,不考虑样本质量的问题,对所有样本一视同仁,不按照样本质量对Loss进行加权或调整。针对上述问题,本文以YOLOv7为基础进行改进。
1 相关工作
1.1 网络结构
YOLOv7是当前较为先进的目标检测算法之一,其速度和精度在每秒5帧到160帧的范围内都超过了大多数已知的目标检测算法。YOLOv7网络由输入(Ⅰnput)、骨干网络(Backbone)、脖颈(Neck)、头部(Head)这四个部分组成。输入模块的作用是将输入的图像经过缩放处理后,满足Backbone的输入尺寸要求。首先,当对图像完成预处理、信息增强等操作后,图像被输入骨干网络中,这一部分负责在经过处理后的图像中提取特征。接着,由Neck模块对提取到的特征进行融合处理,形成大、中、小三种不同尺寸的特征。最后,这些融合后的特征被送入检测头,进行检测之后得到结果输出。
YOLOv7 网络模型的骨干网络部分主要由卷积、E-ELAN 模块、MPConv 模块构建而成。其中,E-ELAN(extended-ELAN)模块,在原始ELAN 的基础上,改变计算块的同时保持原ELAN 的过渡层结构,并通过expand、shuffle、merge cardinality 的思想来实现在不破坏原有梯度路径的情况下增强网络学习的能力。MPConv 卷积层在CBS 层的基础上增加了Maxpool 层,构成上下两个分支,最后使用Concat操作对上下分支提取到的特征进行融合,提高了网络的特征提取能力。Neck 模块中,YOLOv7 与YOLOv5 网络相同,采用了传统的PAFPN(path aggregation feature pyramid network)结构,使得网络适用于多尺寸输入,然后通过信息传递,实现高层特征与底层特征的融合。检测头部分,本文的基线YOLOv7 选用了表示大、中、小三种目标尺寸的ⅠDetect 检测头,将Neck 精炼的特征信息进行解耦,通过REP(RepVGG block)结构对PAFPN 输出的不同尺寸的特征进行通道数调整,结合1×1 卷积,得出目标物体的位置、置信度和类别的预测。
1.2 注意力机制
注意力机制[17](attention mechanism)是一种被广泛应用于图像信息处理、语音辨识和自然语言信息处理等应用领域的信息处理方式。在目标检测任务中,研究表明增加注意力模块能够一定程度上增强目标网络模型的表征能力,从而有效降低无效目标的干扰,进而提高关注目标的检测效果。在机器学习中,注意力机制主要分为通道注意力机制、空间注意力机制和自注意力机制。
1.3 IOU损失函数
目标检测网络中,目标定位依赖一个边界框回归模块,而ⅠOU(intersection over union)用于评价预测框和真实框的交集和并集之比如公式(1)。通过使预测框靠近正确目标从而提升目标框的定位效果,ⅠoU越大说明预测框与真实框重合程度越高,预测框质量越高;在针对两框不相交情况下,ⅠoU很难衡量回归框好坏。
表1分别对GⅠoU[18]、DⅠoU[19]、EⅠoU[20]、CⅠoU[21]进行介绍描述。

表1 不同ⅠOU的比较Table 1 Comparison of different ⅠOU
2 改进YOLOv7的铅封小目标检测方法
在处理单张图片时,文章采用将上下文信息直接融入目标检测的方法。在铅封周边信息标记后,可以作为上下文信息,在网络的PAFPN 结构中进行不同尺度下的特征信息进行高效融合,以尽可能获取更多的目标信息。文献[22]中提出一种基于注意力的特征交互方法,通过添加一个个的小网络到常规特征提取器的每个模块后,来获得注意力权重,减少冲突信息。文献[23]提出用不同尺寸大小的卷积核生成多尺度的特征图,融合成具有全局信息的特征表达方式。以上改进在一定程度上能提升检测的精度,但通过增加网络的深度宽度的方式,导致参数过多,产生计算量过大等问题,不利于小目标检测,无法在实际应用中高效提升检测效果。本文方法在不增加额外的层带来的额外计算和内存开销下,网络的深度并未增加,高效地提升小目标的检测效果。其次,对YOLOv7 模型进行改进,包括ELAN 模块的改进、MPConv模块的改进,Neck部分包括对SPPSCPC模块、Cat 结构的改进,使整体成为自适应特征融合Neck结构,综合提高复杂环境下铅封小目标检测的适应性,提升鲁棒性。最后,改进损失函数,平衡高低质量样本对损失贡献的大小,同时使模型具备更好的小目标适应性。
2.1 YOLOv7模型改进
YOLOv7 模型的改进,在Backbone 部分最后一个MPConv与E-ELAN模块嵌入可变形卷积,在Neck部分引入自注意力机制,改进YOLOv7结构如图1所示。

图1 改进YOLOv7结构Fig.1 Structure of improved YOLOv7
2.2 基于可变形卷积的ELAN模块
像机拍摄角度不同、铅封自身类型不同,导致铅封形状信息丢失,铅封的精准识别产生极大困难,本文针对以上情况,在骨干网络EALN模块嵌入具有偏移学习能力的可变形卷积模块,使卷积采样可以根据铅封图像改变感受野形状和尺寸,基于可变形卷积的DCBS模块结构如图2所示。
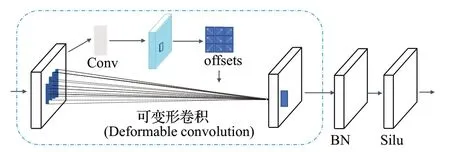
图2 基于可变形卷积的DCBS模块Fig.2 DCBS module based on deformable convolution
传统的卷积一般为规则卷积,只能实现对固定大小的采样,可变形卷积(deformable convolution v2)[24]能够使感受野随着拍摄角度、铅封形状和尺寸的不同而改变,通过偏移量与局部或全局交互,具有长距离建模能力,通过调指标量mk和偏移量pk根据输入不同进行学习进而变化,具备类似自适应空间聚合能力,受“Exploring large-scale vision foundation models with deformable convolutions”[25]启发,本文采用deformable convolution v3[25]相比deformable convolution v2,引入了多组机制,增强算子的表达能力;同时共享了卷积权重,降低算法的复杂度,通过归一化调制标量,提高训练过程的稳定性。在多形变的铅封小目标检测任务中,目标的尺度和形状会发生较大变化,这会导致网络的内部协变量偏移问题。如图2 所示,本文所设计的DCBS 模块,采用batch normalization进行标准化,是一种对每个小批量的输入进行标准化的方式,使网络对输入数据中的变化更加鲁棒,提高模型的泛化能力;同时减少了训练过程中的内部协变量偏移问题,使网络能更容易学习到目标的一致特征表示。DCBS 模块中,新增了一个Silu激活函数来更好地捕捉特征之间的复杂关系,有助于提升网络的表达能力和拟合能力。可变形卷积计算如公式(2)所示:
式中,X为输入特征图,G为group 的数量,K为第几个调制因子,wg为每组内共享投影权重,mgk为第g组第k个采样点的归一化后调制因子,pk为卷积核中的第k个点,p0为输入输出特征图上的p0点,Δpgk为可变形卷积采样点的偏移量。改进后的ELAN模块如图3所示。

图3 基于可变形卷积的ELAN-DeformConv模块Fig.3 ELAN-DeformConv module based on deformable convolution
2.3 基于可变形卷积的MPConv模块
在铅封目标检测时,由于拍摄的铅封尺寸往往比较小,而最大池化的作用是从输入的特征图中提取最显著的特征,因此导致了一些信息的丢失和模糊化,影响检测精度。嵌入可变形卷积层能够在卷积过程中自适应地调整感受野大小和位置,使池化时的每个位置周围的采样位置自适应,更好地适应铅封小目标的形状和尺寸,从而提高检测精度,改进后的MPConv 模块如图4所示。
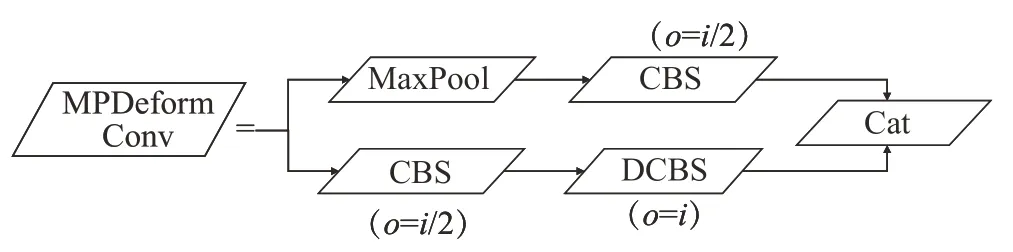
图4 基于可变形卷积的MPDeformConv模块Fig.4 MPDeformConv module based on deformable convolution
2.4 嵌入SimAM注意力机制
注意力机制中,卷积注意力模块多注重输入与输出的关系,自注意力模块主要注重输入之间的关系。对于集装箱铅封检测模型这一具体任务而言,铅封所处的背景由于一年四季24小时作业,光照亮度不同、集装箱颜色种类多、铅封自身尺寸形状不同、集装箱大小不同、铅封的远近不同,铅封小目标存在较大的位置变化和朝向角度变化,引起的复杂多变环境,对模型定位与检测能力要求较高,在不增加模型复杂度的前提下,使网络能够自适应地选择更加关注铅封,因此本文采用自注意力机制(SimAM)[26]以增强铅封小目标特征,减弱铅封所在背景干扰,在保持高效检测前提下,一定程度上提高铅封检测的精度,并通过了消融实验证明。SimAM 结构如图5所示。
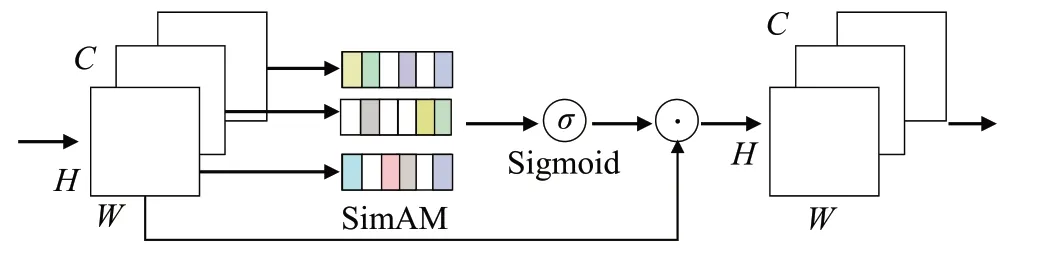
图5 SimAM注意力机制Fig.5 SimAM attention mechanism
SimAM 建立在视觉神经科学理论基础之上,具有更多信息的神经元与其相邻神经元相比表现更加显著,在集装箱上的铅封检测任务中,这些网络的神经元往往负责提取出铅封的关键特征需进行加强赋予更高的权重。本文使用的特征提取骨干网络由CSPDarkNet53改进而来,仍属于深度卷积神经网络,嵌入SimAM后对特征提取能力提升不大(在消融实验中证明了这一点),本文在YOLOv7 模型的Neck 网络中引入了SimAM 注意力对骨干网络提取出的特征进行优化,同时兼顾网络的宽度、深度与检测速度,在增加较少网络参数的情况下来提高铅封检测准确率,通过端到端的方式减少由铅封与集装箱颜色相近、光照、远近尺寸不同等背景噪声对检测的干扰,如公式(3)~(5)所示,SimAM 通过定义线性可分性的能力函数对每个网络中的每个神经元进行评估,其中t为目标神经元,x为相邻神经元,λ为超参数,et∗能量越低表明神经元与相邻的区分度越高,神经元的重要程度也越高,如式(6)所示,通过1/et∗对神经元根据重要性进行加权。依据神经科学理论中的能力函数评估各处特征的重要性提出的SimAM更具有可解释性,无须引入可学习参数。
Neck中的SPPCSPC模块的作用是提高特征提取的效率和准确率。SPP层可以捕获不同尺度和比例的物体信息,CSP 连接可以增强特征的表达能力和稳定性,而Conv层可以进一步提取特征。本文在SPPCSPC结构中嵌入SimAM注意力机制,提高模型对不同尺度、比例、方向等变化的适应性,从而提高检测的准确率,如图6所示。

图6 嵌入SimAM注意力机制的SPPCSPC模块Fig.6 SPPCSPC module embedded with SⅠMAM attention mechanism
在Concatenate 层引入SimAM 使网络更好地捕捉输入铅封与上下文特征中的相关性,强调更为关键的特征,使特征图对于当前任务更具有判别能力,降低不相关特征的干扰,从而提升模型性能,改进后的自适应特征融合Neck如图7所示。
2.5 损失函数改进
YOLOv7网络中损失函数如式(7)所示:
损失函数当中,置信度损失和分类损失均采用BCEWithLogitsLoss 函数来进行计算,而坐标损失则通过CⅠoU进行计算,计算公式(8)如下:
在消融实验中,引入了一个可学习的超参数Alpha,这个超参数会被用于计算convex diagonal squared 和center distance squared。Alpha 的作用在于控制CⅠoU的收敛速度,Alpha=0 时CⅠoU的计算结果就是ⅠoU,随着Alpha的增大,CⅠoU的计算结果越来越接近于CⅠoU,相比于直接使用固定的值计算Alpha 计算结果更加灵活,这种Active CⅠOU使模型具备更好的小目标适应性。
受到“Focal and efficient ⅠOU Loss for accurate bounding box regression”[20]启发,本文采用Focal Loss分类损失函数替换交叉熵损失,以平衡高质量铅封样本和低质量铅封样本对Loss贡献,在定位损失方面,通过改进EⅠOU、CⅠoU代替原始CⅠoU进行消融实验,使模型更关注预测框与真实框的重叠度,提高损失计算的准确性,同时适用对目标形状大小的变化性。Focal CⅠoU Loss 函数所用到的公式如式(9),其中参数λ作用为调节高低质量样本对Loss贡献。
3 实验结果及分析
3.1 集装箱铅封数据集
3.1.1 数据来源
本文的实验数据来源某港口4 种不同角度车道的闸口进闸车辆上的集装箱数据集,大集装箱的大小为45尺;小集装箱的大小为20尺,其中小箱相对大箱距离摄像机更远,每道车道为进入堆场区域的单向车道,摄像机安装在2个车道之间用于铅封检测。如图8所示,为4道不同车道拍摄到的图片,其中图(a)、(b)、(c)、(d)分别为车道1到车道4。

图8 多角度车道拍摄Fig.8 Multi-angle lane shooting
设备采用海康摄像头,24 小时小时监控,采集3 月份、6月份、12月份不同白天晚上监控拍摄到的图片,图9 为列举的不同类型的铅封,其中图(a)、(b)、(c)、(d)、(e)、(f)、(g)、(h)、(i)、(j)、(k)、(l)分别为放大的圆形铅封、圈绳状铅封、侧向铅封、矩形铅封、放大的圆形铅封、放大的倒立多边形铅封、放大的侧向铅封、放大的圆锥形铅封、放大的瓶子状铅封、放大的圈绳状铅封、放大多边形铅封、放大圆形倒立铅封。

图9 不同形状类型的铅封Fig.9 Various shapes and types of lead seals
3.1.2 数据标记
总计为902 张集装箱铅封数据集,分别为如下情况:其中有光照干扰大箱103张,有光照干扰小箱40张,有阴影遮挡大箱26张,有阴影遮挡小箱26张,白天无光照大箱数据集246张,白天无光照小箱数据集150张,晚上大箱数据集208张,晚上小箱数据集103张,见表2。
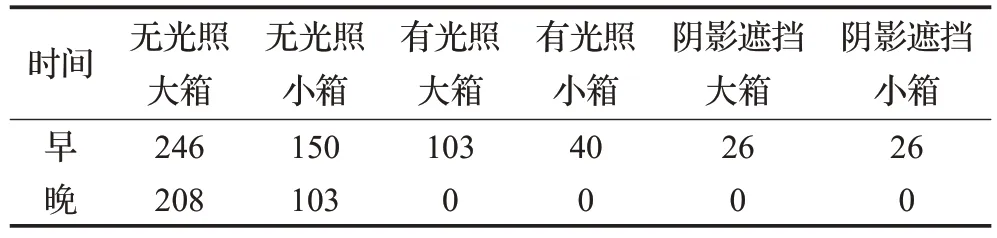
表2 实验训练验证数据集分布情况Table 2 Experimental training validation dataset distribution
对采集的视频每隔2 s截取1张图片,取出相似度过高的图像,便于更准确测试光照强弱干扰、与背景颜色相近、远近不同等场景下的检测效果。数据集总计902幅图像,并用LabelⅠmg标注软件进行标注。整个铅封检测数据集按9∶1 的比例划分训练集、验证集,测试集为总计126张包含6种场景均为21张的数据图片,实际应用中,可采用镜像翻转、旋转、缩放、平移等数据扩增技术来增加训练集样本数据,也可通过推理获取识别到的图片,采用半监督标注增加样本数据量。
3.2 实验平台及训练过程
本实验环境为:NVⅠDⅠA GeForcce RTX3090,Ubuntu18.04 操作系统。编程语言为python,cuda 为11.5,深度学习框架为pytorch为1.11.0。
训练时采用了YOLOv7 作者提供的YOLOv7 预训练权重来训练自己的网络,加快网络收敛速度,batch size设置为32,训练1 000个epoch。
3.3 评估指标
本文通过对比同样实验环境下,选取P-R(准确率-召回率)曲线、平均准确率(average precision,AP)、平均精度均值(mean average precision)三个指标,计算公式如如下:
公式(10)中P为准确率,TP表示正确预测,FP表示错误预测,包括把不是铅封的目标检测为铅封和漏检两种情况;公式(11)中R为召回率,FN表示误把铅封检测为其他的类别。在P-R曲线中,P-R曲线与坐标轴围成的面积大小等于AP值大小。对所有类别的AP取平均值得到mAP来对整个目标检测网络模型的检测性能进行评价,结合召回率表示漏检程度。
3.4 结果对比与分析
在不同复杂条件下的铅封检测情况如图10~15 所示,其中图(a)、(b)、(c)分别为原YOLOv7检测效果、结合上下文信息后的YOLOv7 检测效果与本文算法的检测效果。

图10 与背景颜色相近的铅封目标检测结果对比Fig.10 Comparison of detection results of lead sealed targets with similar background colors
铅封在夏天闸口阴影遮挡下、光照过强、小箱上的远铅封检测导致铅封漏检率相对严重,如图10(c)、图11(c)、图13(c)、图14(c)、图15(c),改进后的模型依旧可以准确检测上述复杂场景下的铅封目标;如图12(b)所示,上下文信息特征融合尽管能解决部分场景识别问题,但对于铅封过远且光照干扰强烈情况下仍然会造成算法的漏检,如图12(c)所示,本文在光照强烈且铅封较远的情况下,依旧能识别出铅封。其次,铅封颜色与背景颜色相近时也是影响铅封检测精度的原因之一,在实际工业应用中,采用上下文特征融合的方式对此问题有一定解决效果,而本文改进后的算法,对解决该问题效果更佳。综上所述,改进的YOLOv7算法对复杂场景中的集装箱铅封检测的鲁棒性更强,这表明改进后的网络在不同光照、阴影遮挡、铅封过远、铅封颜色与背景颜色相近等目标场景下泛化能力有所提升。但目前本文算法目前在应对强烈光照干扰且同时检测目标过远的情况时,mAP值相对较低,仍可能会存在一定程度的漏检。

图11 大箱在太阳光照下的铅封目标检测结果对比Fig.11 Comparison of lead seal target detection results of large boxes under sunlight

图12 小箱在太阳光照下的铅封目标检测结果对比Fig.12 Comparison of lead seal target detection results of small boxes under sunlight

图13 大箱在光线较暗下的铅封目标检测结果对比Fig.13 Comparison of lead seal target detection results of large boxes in low light

图14 小箱在光线较暗下的铅封检测结果对比Fig.14 Comparison of lead seal target detection results of small boxes in low light

图15 小箱在白天的铅封目标检测结果对比Fig.15 Comparison of lead seal target detection results of small boxes in daytime
3.4.1 消融实验
在实验过程中,确保实验的公平比较,除改进部分外,控制其他训练参数不变,同时数据集均以640×640分辨率大小的图像为输入。本小节在集装箱铅封数据集上进行实验,验证所提模块的有效性。以未做任何改动的YOLOv7为基准+表示模块混合改进。嵌入注意力机制模块的消融实验结果见表3。

表3 注意力机制模块的消融实验Table 3 Ablation experiment of attention mechanism module
自注意力机制模块方面的横向对比实验结果显示,SimAM 在Backbone 中效果不如Neck 的可能原因,Backbone是主要负责提取图像特征的模块,自注意力机制是在通道维度上操作的,可能造成在多个通道之间分配注意力而无法明确地区分哪个通道对关注的类别最为重要。加入自注意力机制对Backbone的特征提取能力提升不大。而Neck负责对Backbone提取的特征进行进一步加工,此时输入特征已经比较丰富和具有区分度,同时通道数没有Backbone多。这种情况下,引入注意力机制会更好地捕捉特征之间的交互信息,进一步提升特征表达能力。
针对卷积算子的改进进行消融实验,以未做任何改动的YOLOv7为基准+表示模块混合改进,对原始的ELAN与MPConv 当中的3×3 普通卷积进行改进替换为可变形卷积DeformConv2、DeformConv3,实验结果见表4。

表4 可变形卷积模块的消融实验Table 4 Ablation experiment of deformable convolution module
普通卷积替换为DeformConv2,mAP值虽有不错的提升,而本文嵌入的DeformConv3 相较于普通卷积,mAP 值显著提升4.8 个百分点,其引入的多组机制,使算子表达能力得以加强,同时使模型可以使用更多的上下文信息;通过共享的卷积权重、归一化调制标量,降低了铅封小目标检测算法的复杂度,同时提高了模型稳定性,使针对铅封小目标检测变得更为高效。
针对损失函数模块的改进进行消融实验,以未做任何改动的YOLOv7为基准,对EⅠoU、原始定位损失函数CⅠoU均进行改进实验,分类损失函数方面,采用了Focal Loss分类损失函数替换交叉熵损失,实验结果见表5。

表5 损失函数模块的消融实验Table 5 Ablation experiment of loss function module
损失函数方面的横向对比实验结果显示,定位损失方面,改进后的Active CⅠoU相比于直接使用原始CⅠoU中固定的值计算Alpha计算结果更加灵活,mAP值结果提升了1个百分点,使模型具备更好的小目标适应性。
分类损失函数方面,改进后Focal Loss相比原先交叉熵损失,优化了因没有较好的机制处理集装箱上铅封距离远近不同、受光程度不同导致高质量铅封样本和低质量铅封样本对Loss 贡献不平衡问题。结合定位损失Focal Active CⅠoU,相较原先的YOLOv7,mAP 值结果提升了1.5个百分点。
综合消融实验结果如表6所示,本文算法采用的融合上下文信息+脖颈部分引入注意力机制+Focal+Active CⅠoU+DeformConv3 相比初始YOLOv7、+注意力机制、+上下文信息+脖颈部分引入注意力机制、+上下文信息+在脖颈部分引入注意力机制+Focal+Active CioU,mAP 值分别提升了20.2、19.1、7.6、5.5 个百分点。综合而言,本文算法采用了融合上下文信息+脖颈部分引入注意力机制+Focal+Active CⅠoU+DeformConv3 的组合改进效果最佳,其在集装箱铅封小目标在复杂场景下的检测效果比其他组合更好,尤其相比基线YOLOv7只对铅封进行检测mAP 值显著提升了20.2 个百分点,漏检率降低了15.8个百分点。
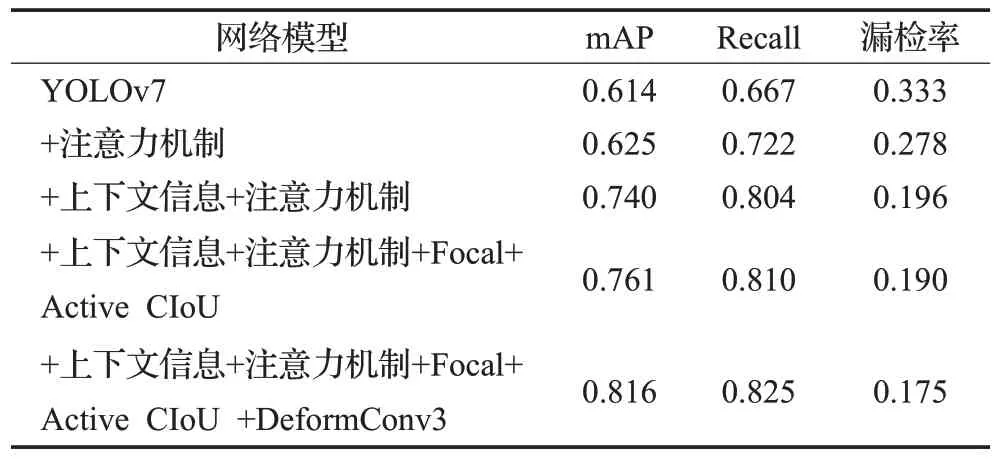
表6 不同模块的综合消融实验Table 6 Comprehensive ablation experiments of different modules
3.4.2 对比实验
为验证本文所提出方法的有效性与先进性,在同一实验环境下设计了一实验,对比文献[3]的Faster R-CNN、文献[9]的SSD、文献[16]的YOLOv7 检测算法与铅封小目标检测算法,以及文献[13]基于深度卷积网络相关性特征图检测,对比结果见表7。
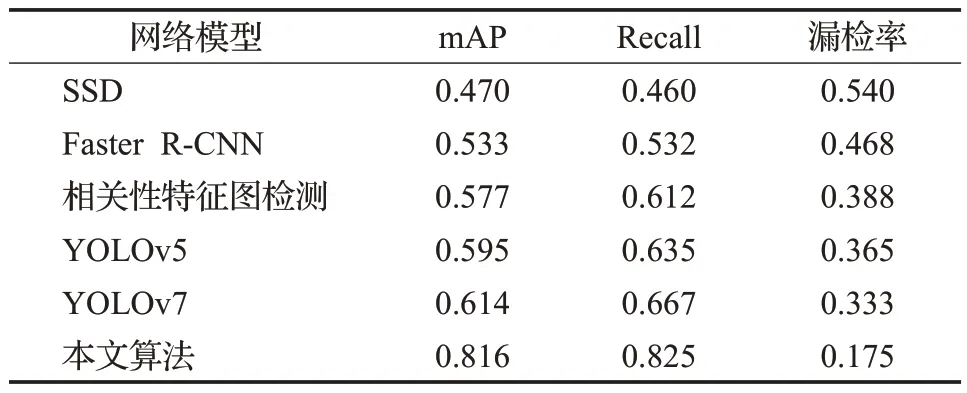
表7 不同的铅封小目标检测算法的性能比较Table 7 Performance comparison of different lead sealed small target detection algorithms
由表7可知,SSD、Faster R-CNN、YOLOv5、YOLOv7的mAP分别为0.470、0.533、0.595、0.614,说明这四种检测方法在一定程度上能够处理噪点干扰问题,但其召回率与平均准确率仍较低,鲁棒性较差。杨杰敏等人[13]提出的采用基于深度卷积网络的相关性特征图铅封小目标检测,相比Faster R-CNN、SSD 等算法可以快速准确进行铅封识别,但只研究了港口较好场景下的集装箱小铅封检测,对数据集存在光照、恶劣条件以及拍照角度变动等因素效果不佳。本文改进后的YOLOv7 网络模型准确性和鲁棒性均优于其他目标检测网络。这是因为本文的检测网络在处理不同场景时,如:光照变化场景图11(c)、图12(c);阴影遮挡场景图13(c);远铅封小目标图14(c)、图15(c);检测目标与背景颜色相近图10(c),针对上述情况,通过上下文信息特征融合方式,嵌入注意力机制和替换卷积操作,对损失函数进行优化,极大提高模型的鲁棒性,减少了铅封检测漏检情况,且不需要控制特定的环境,速度和精度基本达到实际集装箱港口的铅封检测要求。
4 结束语
本文提出并实现了一种改进的YOLOv7 复杂环境下铅封小目标检测算法。该算法针对复杂场景下的铅封小目标检测问题,首先采用一种将上下文信息直接融入目标检测任务的方法,结合PAFPN 结构进行不同尺度的特征信息融合,提高辨别准确度;其次,针对小铅封特征在训练过程中出现消失的问题,在骨干网络嵌入可变形卷积模块,适应形状大小不同输入的铅封特征图,在特征融合时保证更多浅层语义信息的特征图被送入分类网络,增加模型复杂场景下的学习能力;同时,在Neck 部分融入自注意力机制,自适应地选择输入中的重要信息,提高在复杂多变背景下模型表现能力;最后,针对数据集中集装箱上远近铅封的样本质量不同,采用Focal Loss分类损失函数替换交叉熵损失,平衡高质量样本和低质量样本对Loss 贡献,引入可学习的超参数Active CⅠoU Loss 定位损失,控制模型收敛速度,使模型更关注预测框与真实框的重叠度,提高损失计算的准确性,综合提高模型针对复杂场景下铅封小目标检测的自适应能力及提升了模型的鲁棒性。消融实验结果表明,与原YOLOv7算法相比,改进后的算法模型mAP可达81.6%,提高了20.2 个百分点。对比实验结果表明,与YOLOv5、Faster R-CNN、SSD铅封识别算法相比,本算法检测效果均优于其他经典目标检测网络。在铅封较远、光照不良以及与背景颜色相近等复杂场景,本文提出的改进的YOLOv7算法减少了铅封漏检的情况,具备较好的准确性和鲁棒性;在时间性能上,平均每张图像的识别时间为0.058 s,符合实际集装箱港口铅封检测的实时性要求,在强烈光照干扰且同时待检测的小目标拍摄距离过远时的情况下的铅封小目标检测精度相对较低,后续将进一步探索。
猜你喜欢
军事文摘(2023年5期)2023-03-27
小雪花·成长指南(2022年1期)2022-04-09
中国测试(2022年3期)2022-03-30
东北电力技术(2021年2期)2021-04-08
现代装饰(2019年7期)2019-07-25
机电元件(2018年3期)2018-07-04
中国公路(2017年8期)2017-07-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
专用汽车(2015年2期)2015-03-01
