
融合双端注意力网络的知识图谱推荐算法
2023-10-10 10:38石山山
计算机工程与应用 2023年19期
王 光,石山山
辽宁工程技术大学,辽宁 葫芦岛 125000
为了更及时高效地为用户提供有效信息以提升用户的体验感,多种推荐算法被广泛地应用在不同的领域,比如音乐[1]、电影[2]、饮食[3]等物品的推荐。目前,常用的推荐算法主要可以分为三类:基于协同过滤的推荐算法[4-5]、基于内容的推荐算法[6-7]和基于知识的推荐算法[8-9]。由于前两个算法存在着数据稀疏、解释性不强等问题,可以采取引入辅助信息的方式来补足稀疏数据中所缺失的交互信息,比如用户浏览历史记录、社交网络、评论信息、物品关联信息等,以此来加强推荐算法的性能。
知识图谱(knowledge graph,KG)作为包含实体属性信息的异构网络,通过关系路径扩展实体的邻域节点从而获得实体的嵌入表示。而用户的偏好可以通过向知识图谱中输入用户的评分、用户评论信息、浏览时长等参数进行计算。目前基于知识图谱所设计的推荐算法大概可以分为三类:基于embedding的方法[10-12]、基于PATH的方法[13-14]、联合方法[15-17]。(1)基于embedding方法是将数据信息转化为低维稠密的实体向量。文献[10]将隐藏的知识层面的度量加入算法中,首先将新闻投入到知识图谱中获得相关实体,然后通过KCNN(knowledgeaware convolutional neural network)转化为向量表示,最后使用注意力机制(attention-based user interest extraction)获得用户历史向量表示以提升推荐的精确度;文献[11]将通过知识图谱学习到的嵌入加入到TUP(translation-based user preference)中对物品与用户的隐式反馈进行建模,提升算法的可解释性;文献[12]采用距离感知抽样方法计算最短路径并对其进行排序并根据最短的K条路径构建高阶子图,首先将其转化为Matrix 矩阵,然后采用图神经网络来计算权值并使用门控更新,最终使用MLP 进行预测。由于嵌入方法可能会依赖知识图谱内的语义关系而导致很难直观地表征物品间的联系。(2)基于PATH的方法是根据知识图谱内部路径进行学习。为了能够自动学习实体之间的路径,文献[13]首先获取知识图谱中实体对之间的路径,然后采用循环网络技术对其进行编码并采用共享公共参数以避免出现过拟合的现象,最终使用池化操作根据用户的偏好区分路径以生成推荐列表。基于PATH的方法是以获取到的路径为基础进行操作导致设计路径困难且很难对算法进行优化,因此提出了将二者进行联合的方法。(3)基于联合的方法是前两种算法进行结合。文献[15]首次提出将基于嵌入与基于路径的方法进行结合,以用户的历史兴趣为基础沿着知识图谱中的路径进行传播以获取到用户的潜在兴趣,与基于元路径的方法不同的是Ripple net 根据概率进行实体的传播,从而获得实体的邻域集合并将其转化为特征;文献[16]与文献[15]相似,以物品为基础,将获得物品的特征与用户特征相结合以获得用户的点击率。由于知识图谱传播过程中会产生较大的噪声,文献[17]提出加入注意力网络,从知识图谱中获得邻居节点的特征并不断地递归传播,使用注意力机制对节点进行区分以提高推荐的精准性。
目前已有的双端知识图谱推荐算法中,文献[18]提出融合知识图谱的双端在线学习资源推荐算法以提高推荐的准确性,但该算法注重用户端的信息提取,忽视了物品方面本身所具有的特性。文献[19]提出使用卷积网络对用户和物品属性及其关系进行推荐的双端知识图谱算法,明显地提升了推荐算法的性能,但算法中忽视了用户与实体交互信息的重要性。上述的论文中采用引入外部信息提升推荐系统的效果,但没有过多考虑到用户偏好与物品特性的关系,不能非常准确地计算用户的偏好以及基于用户偏好的物品特性。相同的电影对于不同的用户来说可能是不同类型的,因此本文将用户嵌入向量引入到物品端的计算中,可以使物品邻域信息的传播方向更符合用户的喜好。
目前已有的基于神经网络的研究算法中,文献[20]提出将CNN(convolutional neural network)与LSTM(long short-term memory)进行融合的金融交易算法以拥有更好的鲁棒性。文献[21]提出使用DQN 网络结合用户的长短期兴趣以更精准地建模用户兴趣。文献[22]提出将层次知识网络与多层感知机进行结合以提高话题的推荐效果。在诸多论文的实验中可以看出,Ripple Net[15]、KGCN[16]、KGAT[17]等算法最优结果层数为两层。以KGCN[16]算法为例,为减少计算量,采用固定数量采样法以及随机性的邻域传播方向,其选取的数据并未取决于用户的喜好。因此采用注意力网络可以指定更准确的传播方向,根据注意力权值对邻域进行选择,减少噪声的引入。
由于已有论文中忽视用户与物品的联结作用,导致推荐模型存在缺陷,为此提出基于知识图谱和注意力网络的双端推荐算法。本文的主要贡献有以下三点:(1)利用知识图谱内的异构信息,设计双端注意力网络从用户端与物品端中获取更有效的邻域。(2)为更准确地计算用户是否喜欢该物品,在物品端的注意力网络中添加用户偏好以计算更符合用户喜好的物品嵌入向量。(3)对数据集MovieLens-1M和Book-Crossing进行实验,评估算法的有效性,与基线模型相比,评估指标AUC、F1、precision、recall均有提升。
1 本文算法
1.1 总体框架
为了解决已有的知识图谱-推荐算法中忽略用户端与物品端的信息交互以及邻域实体计算方式存在的问题,本文将双端注意力网络与知识图谱进行融合,总体框架如图1 所示。该模型以用户浏览记录(user view record)和物品信息(item)作为输入。框图由三个主要层次组成:(1)知识传播层:根据双端注意力网络计算的权值,沿着KG 中的链路进行传播以获取邻域集合。(2)注意力网络层:将知识传播层获取的邻域集合进行注意力权值计算,用户端注意力网络对用户浏览记录中的三元组进行权值计算以获取有效邻域;物品端注意力网络将用户的偏好与物品邻域三元组结合以计算符合用户喜好的有效邻域。(3)预测层:聚合不同层次的用户和物品的向量表示以生成用户表示向量和物品表示向量,使用预测函数进行预测。
用户的浏览记录及其邻域信息可以体现用户对于某一类物品的喜好。以向用户推荐电影为例,用户u1观看过属于科幻片系列的《复仇者联盟》,可以认为该用户喜好科幻片系列的电影。在算法中,获取用户观看记录的邻域信息,通过embedding层生成嵌入向量并聚合以表示用户。对于物品节点,物品邻域包含着对于物品本身信息的扩展。电影《复仇者联盟》的导演是乔斯·韦登,则可以沿着知识图谱中的链路对该导演的信息进行扩展,在注意力网络中加入用户的偏好获取更符合用户喜好的邻域信息,将邻域信息进行聚合以表示物品。由于邻域的权重分配是提高推荐算法性能的重要因素之一,KGCN[16]是使用关系的重要度作为邻域节点之间的权重值,KGAT[17]是采用注意力网络对不同节点分配权值,CKAN[23]是采用知识感知注意网络对节点分配权值。受以上算法启发,本文为用户端与物品端分别设计注意力网络对路径分配权值,获得用户向量和物品向量以预测用户点击率。
1.2 用户端信息获取
用户的浏览记录可以有效地展示用户的偏好,例如用户如果经常看《钢铁侠》《复仇者联盟》《绿巨人》等电影,有理由认为用户对科幻类型的电影感兴趣;用户如果经常看某个导演的电影,则可以认为用户对这位导演的电影感兴趣;用户对演员、电影所属国家的选择也是如此。为更好地计算用户偏好,本文采用基于用户的注意力网络对用户浏览记录中三元组信息进行计算以获取更符合用户喜好的邻域,从而计算用户的有效表示。对于用户u,将其浏览记录定义为Vu={v|yuv=1},则用户的偏好表示可以定义为:
其中,N0u ={(h,r,t)|(h,r,t)∈Gandh∈Vu}为用户浏览记录的邻域信息,et为尾部实体的嵌入表示,为面向三元组的注意力得分,根据图1中注意力网络,将h、r、t输入至网络中获得用户的偏好得分。
在网络中加入dropout 层以防止发生过拟合,首先使用伯努利分布生成随机失活向量ru∈Rm,然后生成dropout层加入网络中。注意力网络表述如下:
其中,u∈U表示用户,r∈R 表示关系,p为随机失活概率。非线性激活函数选择Tanh与Sigmoid,将首部实体与尾部实体加入至激活函数中。选择使用Tanh函数可以使注意力权值依赖于三者的关系,并且使用Sigmoid可以更加细微地进行分类。W与b为可训练的参数,其下标代表其所属层数。
最后将获取到的注意力权值进行归一化:
由于用户浏览记录在知识图谱内传播的实体较多,因此为获取用户更精准的偏好,将注意力权值进行排序并选用排名前ku的样本作为邻域。其表述如下:
其中,ku为用户端邻域采样大小。
为了提高算法的聚合效果,本文选择了三种聚合方法,如公式(7)~(9)所示:
最终将获取到的用户表示u与其邻域表示向量uNu使用聚合器进行聚合,从而获得用户嵌入表示u。
1.3 物品端信息获取
物品v通过知识图谱G获取其邻域信息,对于实体h,本文采用Nh={(h,r,t)|(h,r,t)∈G} ,其中h∈ε,r∈R,t∈ε。采用Trans方法通过嵌入embedding获取到三元组的向量{(eh,er,et)|eh,et∈Rm,er∈Rn} ,本文根据三元组在关系空间中的距离判断eh与et的关系:
设定距离阈值为ε,若distance≤ε,则判定在关系空间中eh与et是接近的,否则二者应远离。由此设置函数d(h,r,t)计算三元组(h,r,t)距离的得分:
其中,Wr∈Rm×n为基于关系r的转换矩阵,将实体eh与et投影至关系空间中。若d(h,r,t)数值越大,说明eh与et越贴近,三元组越符合用户的喜好。
由于物品的信息较多,则需要在邻域的初始集合中选择更符合用户喜好的元组,即d(h,r,t)排名前kv的三元组可以作为中心实体的初始集合S0v。
其中,kv为物品端采样数量。
为使正负样本之间得分差距变大,设置函数:
其中(h,r,t′)∉G是通过在三元组(h,r,t)随机将t进行替换而获得的无效三元组,通过学习损失函数Ld可以更好地获得物品的嵌入表示。
以用户观看电影为例,有些用户会以演员为主选择相应的电影,有些用户也会以电影题材或者导演等因素为主选择电影,由此认为用户偏好侧重点会影响到用户对实体的选择。知识图谱中各个实体e∈E的邻域权重由πru(u,r,t)决定。选用聚合器将获取到的邻域实体与权重进行聚合以获取物品v的最终表示:
其中,(h,r,t)是基于关系r的首部实体和尾部实体之间的权值,加入用户对关系的偏好则为(u,r,t)。
在物品端加入dropout 层,根据概率p′使用伯努利分布生成随机失活向量rv,注意力网络表述如下:
其中,非线性激活函数、参数的选择与用户端一致,在这里不过多叙述。最后将注意力权值进行归一化:
由于Sv计算复杂度较高,因此将每个节点的注意力权值进行排序,采样排名前kv的样本作为邻域的方式来降低复杂度。
根据公式(14)~(18)、(7)~(9),使用聚合器将物品与物品的邻域不断从外向里进行聚合,最终获得物品向量Vu。
1.4 预测部分
通过在上文中所获得的用户u与物品v的最终表示u和Vu,使用预测函数:
其中,σ(x)为Sigmoid函数。损失函数如下:
其中,第一项为所有用户的真实值与预测值之间的交叉熵的损失,使用p(x)函数作为服从正态分布的负采样,Cu=|{v:yuv=1} |为用户u的负采样。
2 实验分析
2.1 数据集
为更好地对算法性能进行评估,本文选择拥有用户与物品交互信息的数据集MovieLens-1M 与Book-Crossing。其中MovieLens-1M是包含电影信息、用户评价信息的数据集,用户的评级为0~5;Book-Crossing 数据集是包含书籍信息、用户评价信息的数据集,用户的评级为0~10。具体信息如表1所示。
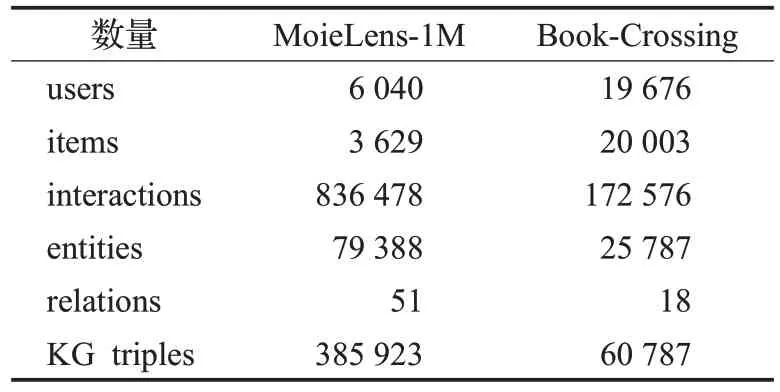
表1 选用数据集的具体信息Table 1 Details of selected datasets
2.2 对比实验
为了验证算法的有效性,本文选用四种基于知识图谱的推荐算法作为比较对象。
KGCN[16]:物品信息放入知识图谱内进行扩展,以固定数量采样的方式获取领域并计算特征。
CKAN[23]:将协同传播与知识图谱相结合,设计一个动态的知识感知注意机制以获得头部实体与关系的权值,实现尾实体的注意力嵌入。
KGCN-LS[24]:将知识图转化为特定于用户的加权图,为避免评分过少导致的过拟合现象,加入标签平滑正则项对损失函数进行优化。
KCAN[25]:提出全局相似度保持和局部知识蒸馏以挖掘更准确的用户偏好。
2.3 实验设置
本文采用的实验环境为Win10,使用python-3.8、sklearn-0.24.1、tensorflow-2.5.0。在两种实验场景中进行实验:(1)在点击率(CTR)预测中,将测试集放入算法中进行预测,使用AUC 和F1 评估预测性能。(2)在Top-K推荐中,将测试集放入算法中为用户推荐点击率前K的物品,使用precision@K、recall@K对数据集进行评估。具体参数设置如表2所示。
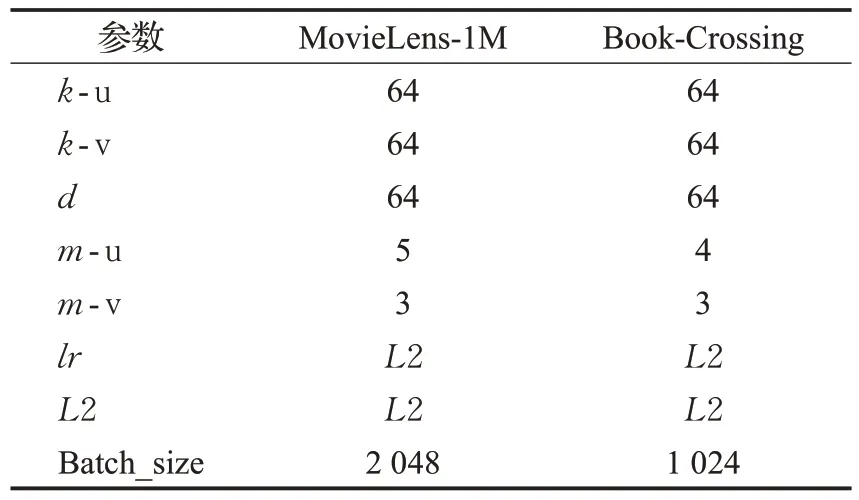
表2 参数设置Table 2 Parameters setting
表中-u 为用户端,-v 为物品端,k为采样数,d为维度,m为跳数,lr为学习率,L2 为正则化权重。
2.4 对比实验结果
按照6∶2∶2比例将数据集划分为训练集、验证集和测试集,每个基线算法重复3 次实验并取平均值,点击率(CTR)预测场景的实验结果如表3所示。
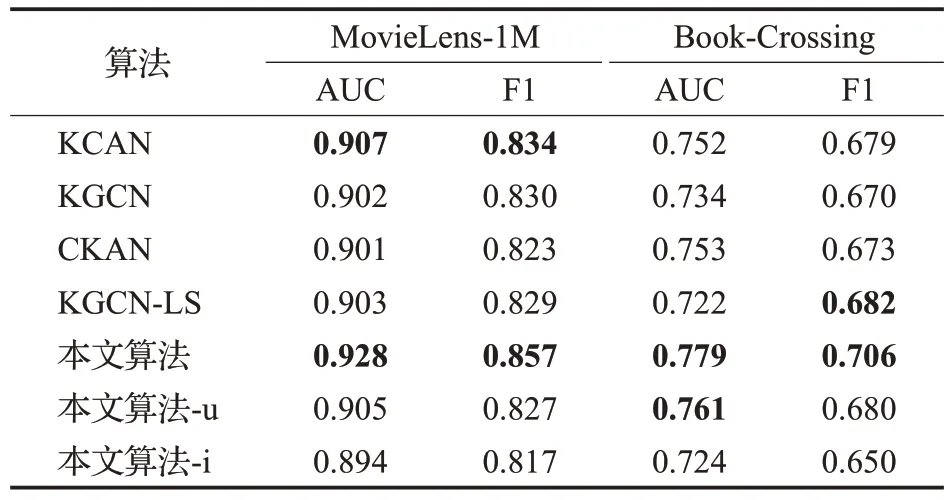
表3 CTR场景下的AUC和F1预测结果Table 3 Results of AUC and F1 in CTR prediction
通过观察四种基线算法可以发现:KCAN侧重于实体的相似度,而KGCN、KGCN-LS仅聚合物品的邻域信息,CKAN考虑首部实体与关系的权值却忽略了尾部实体重要性。针对上述提到的不足,本文提出了双端注意力网络的知识图谱推荐算法,实验证明在数据集MovieLens-1M 中,相比于最优算法AUC 提升了2.1 个百分点,F1 提升了2.3 个百分点。在数据集Book-Crossing中,相比于最优算法AUC 提升了2.6 个百分点,F1 提升了2.4个百分点。在表中的-u表示仅在用户端设定注意力网络,-i 表示仅在物品端设定注意力网络。通过对比,说明双端注意力网络可以有效提升算法的性能。
通过与其他算法的对比可以看出,在算法中提出两端聚合可以有效地提高算法性能,将尾实体考虑至注意力网络中可以进一步提高算法的有效性。在Top-K推荐场景下的实验结果如图2~5所示。
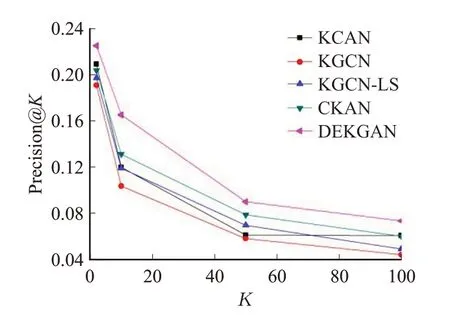
图2 MovieLens-1M数据集上Top-K推荐准确率Fig.2 Precision@K in Top-K recommendation on MovieLens-1M dataset
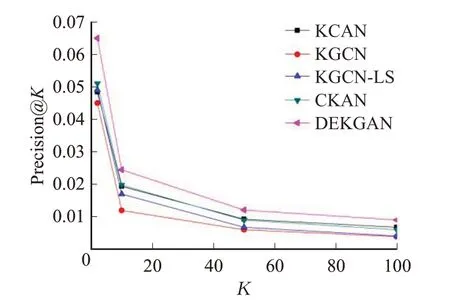
图3 Book-Crossing数据集上Top-K推荐准确率Fig.3 Precision@K in Top-K recommendation on Book-Crossing dataset
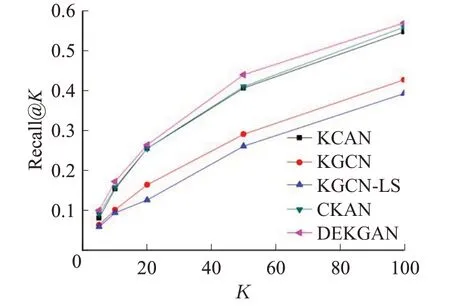
图4 MovieLens-1M数据集上Top-K推荐召回率Fig.4 Recall@K in Top-K recommendation on MovieLens-1M dataset
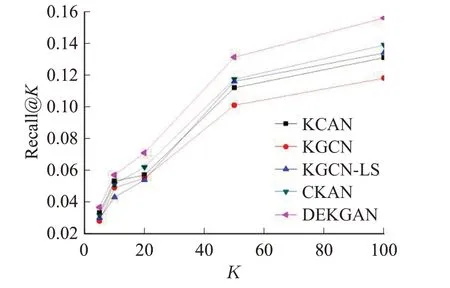
图5 Book-Crossing数据集上Top-K推荐召回率Fig.5 Recall@K in Top-K recommendation on Book-Crossing dataset
从上述四张图中可以看出,本文算法的准确率、回归率在MovieLens-1M 和Book-Crossing 数据集上均明显高于其他基线算法,表明添加注意力机制可以有效提升算法性能。KCAN与KGCN准确率与回归率较低,说明用户端与物品端相结合可以提高算法的性能;CKAN与其他算法相比加入了动态知识感知注意机制,说明加入注意机制对邻域信息的选择有重要意义。但由于CKAN是将首部实体与关系加入知识图谱,未考虑到尾部实体的重要性,因此本文提出根据用户与物品的不同属性分配相应注意力值的双端注意力网络。通过实验证明,使用两种注意力网络是可行的,并且不会导致算法的复杂度较高。当采样大小为4 与4 时,运行时间为2 min/epoch;当采样大小为64 与64 时,运行时间为5 min/epoch。经调查可知KGCN 算法的运行时间是优于其他基线算法的,KGCN 运行时间为7 min/epoch,因此证明本文算法的时间复杂度较低。
2.5 参数敏感性分析
表4表示跳数对AUC的影响,从中可以看出跳数取值过低、过高都会影响AUC,过高会引入噪音,过低则会减少算法内所聚合的信息,从而影响算法性能。表5表示嵌入维度对AUC 的影响,从中可以看出提高维度可以有效地提升AUC,但维度过高会导致AUC下降,说明合适的嵌入维度可以更加有效地编码信息。
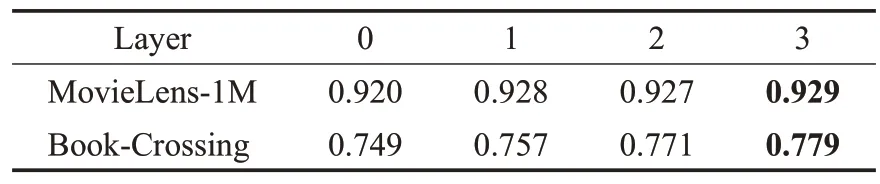
表4 跳数对AUC的影响Table 4 Ⅰmpact of layer on AUC value
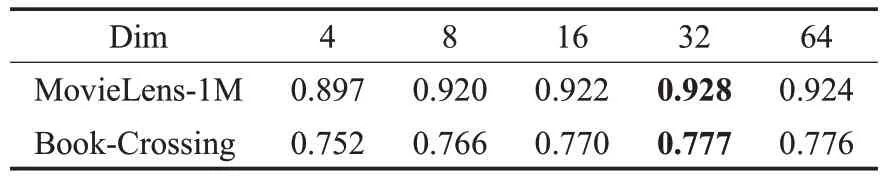
表5 嵌入的向量维度对AUC的影响Table 5 Ⅰmpact of embedding vector dimension on AUC value
表6表示聚合器的选择对AUC的影响,从表中可以看出MovieLens-1M 数据集使用Sum 聚合器表现最好,Book-Crossing 数据集使用Concat 聚合器表现最好,因此说明合适的聚合器对提升算法性能是很重要的。

表6 聚合器选择对AUC的影响Table 6 Ⅰmpact of aggregator selection on AUC value
表7~10表示两个数据集中不同的采样大小对AUC与F1 的影响,从表中可以看出随着采样大小的增大,AUC 和F1 也随之增大,但取值过大或过小都会引起性能的下降。在数据集MovieLens-1M 中,当采样大小设置为user-64 与item-8 时,AUC 与F1 取得最大值。在数据集Book-Crossing 中,当采样大小设置为user-64 与item-64时,AUC与F1取得最大值。因此说明合适的取样大小可以提高算法的性能。
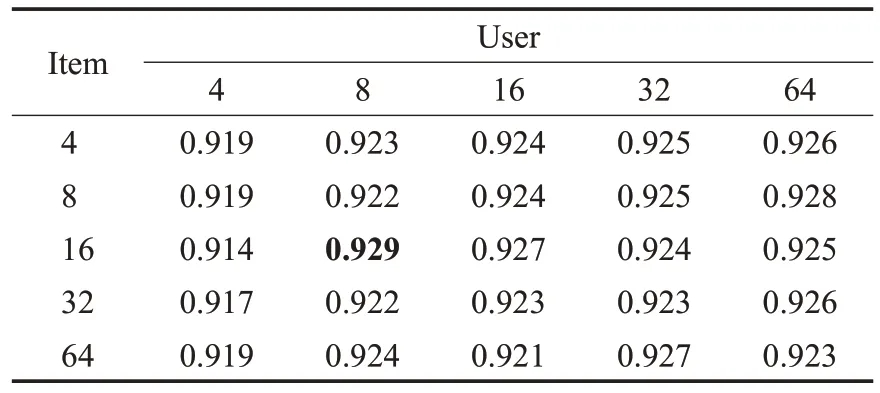
表7 数据集MovieLens-1M中采样数对AUC的影响Table 7 Ⅰmpact of different sampling sizes on AUC in MovieLens-1M dataset
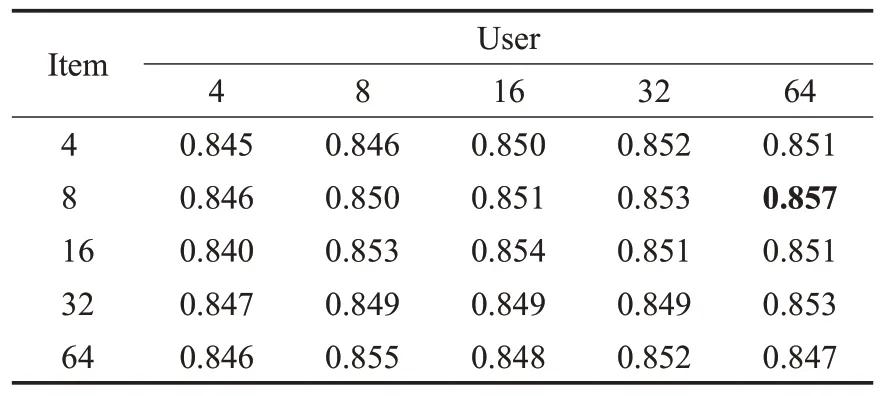
表8 数据集MovieLens-1M中采样数对F1的影响Table 8 Ⅰmpact of different sampling sizes on F1 in MovieLens-1M dataset
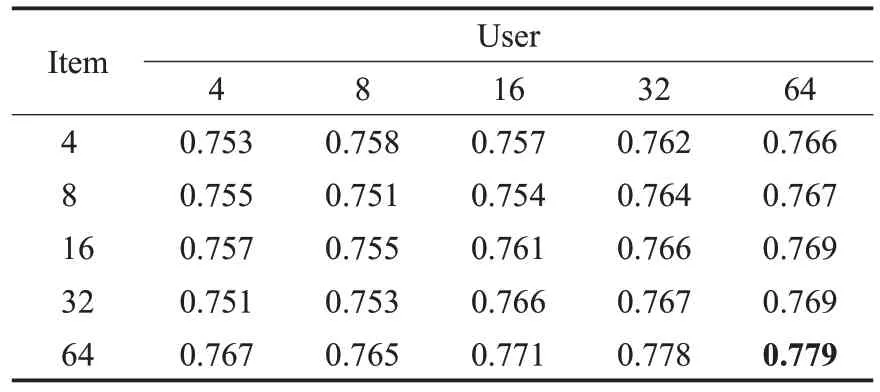
表9 数据集Book-Crossing中采样数对AUC的影响Table 9 Ⅰmpact of different sampling sizes on AUC in Book-Crossing dataset

表10 数据集Book-Crossing中采样数对F1的影响Table 10 Ⅰmpact of different sampling sizes on F1 in Book-Crossing dataset
2.6 可解释性分析
假设电影神奇四侠和钢铁侠是被用户观看过并给予较高的评分,DEKGAN 经过计算为用户推荐电影复仇者联盟。表11表示待推荐电影复仇者联盟的实体联系及其各元组权值排序,从中可以看出用户对相同演员的电影更为偏爱,因此推荐复仇者联盟的理由可以认为是用户喜欢科幻类电影,尤其是拥有相同主演的电影。由此可以看出推荐结果是基于用户的偏好以及知识信息,以此获得更好的推荐结果可解释性。

表11 推荐复仇者联盟的解释Table 11 Explanation of recommended avengers alliance
3 结束语
将知识图谱与推荐算法相融合是为了可以获取用户与物品的更多信息,以辅助算法更准确地向用户进行推荐。许多用户对物品的喜爱点通常是不同的,但现有的推荐算法是单独考虑用户偏好和物品向量,因此研究用户对物品喜好的侧重点是很重要的。本文针对用户-关系-物品三者之间的信息进行探索,提出一种融合双端注意力网络的知识图谱推荐算法。该算法提出双端注意力网络,分别对用户-关系、物品-用户、实体三元组赋予基于知识的权重,以更好、更准确地形成用户向量和物品向量。尽管本文算法提高了推荐性能,但算法中网络优化问题仍有待进一步解决。在未来工作中,如何设计注意力网络对用户范围进行分析以完成物品对用户的预测,是进一步研究的方向。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少先队活动(2020年12期)2021-01-14
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
传媒评论(2017年3期)2017-06-13
中成药(2017年3期)2017-05-17
第二课堂(课外活动版)(2016年2期)2016-10-21
周口师范学院学报(2016年5期)2016-10-17
领导科学论坛(2016年9期)2016-06-05
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
