
基于双重注意力的声音事件定位与检测
2023-10-10 10:38许春冬甄雅迪
计算机工程与应用 2023年19期
许春冬,刘 昊,闵 源,甄雅迪
江西理工大学 信息工程学院,江西 赣州 341000
随着数字声音分析技术的发展,声音事件定位与检测(sound event localization and detection,SELD)技术逐渐得到广泛应用,主要应用于智能家居[1]、安全监控[2]、野生生物检测[3-4]以及异常声音事件检测[5]等相关领域。SELD是指在识别单个或多个重叠声音事件的过程中,对声音事件的活动时间进行识别,同时估计其相对于麦克风的方向。SELD 可分为两个独立的任务主体:声音事件检测(sound event localization,SED)和声源定位。其中,SED 是一个多标签分类问题,目的是在时间上检测声音事件的开始和偏移,并进一步将文本标签与检测到的声音事件相关联。而声源定位的任务是对声源相对于麦克风的方向进行检测,只用于估计声音事件所在的方向,即声音事件的到达方向(direction of arrival,DOA)估计。
模板匹配法是SED早期主要使用的方法之一,不仅可以将高斯混合模型[6](Gaussian mixture model,GMM)、隐马尔可夫模型[7](hidden Markov model,HMM)作为独立的模型使用,也可以将以上模型结合后使用。然而,这些模型在使用过程中无法处理声音事件中存在的混叠问题。因此,基于非负矩阵分解[8]原理(non-negative matrix factorization,NMF)的方法被提出,它能以逐帧方式处理混叠的声音事件,一定程度上改善了模型匹配法在使用过程中的缺陷,却忽略了声音事件在时域的相关性。为进一步优化声音事件处理过程,出现了支持向量机[9]对声音事件进行分类的方法。传统的声源定位方法大致可以分为基于最大输出功率的可控波束形成技术[10]、基于高分辨率空间谱估计定位方法[11]以及基于时延估计的定位方法[12]。在噪声环境下,传统声源定位方法存在特征显化能力弱、定位精度低、误差大的缺陷。深度学习克服传统方法中提取特征效率低且不能准确地表达声音特性的缺点,保留了声音特征信号的有效信息,极大地提升了定位精度和降低了定位误差。因此,卷积神经网络(convolutional neural network,CNN)[13-14]、递归神经网络(recurrent neural network,RNN)[15-16]或卷积递归神经网络(convolution recurrent neural network,CRNN)[17-18]已开始用于SED 和DOA 估计任务。2021 年,文献[19]提出CNN-Conformer 模型,在CNN后引入Conformer模块,以便更好地利用时间上下文信息来处理SELD 任务。2021 年,文献[20]提出的CMA-SELD模型,使用了参数共享的方法,将CNN层的中间特征映射为SED 和DOA,通过在Transformer 解码器中使用交叉模态注意(cross-modality attention,CMA)学习融合信息,进一步提升了SED和DOA的性能。
近年来,注意力机制[21-22]在深度学习各领域得到进一步发展,无论是在图像处理,自然语言处理还是语音识别分类等任务中,都有优异的表现。注意力机制是从人类视觉的选择性注意力机制借鉴得来的,视觉注意力是人类大脑处理信号的特有机制。当人类快速查看一张图片时,大脑会选择性地关注一些具有区分性的区域,获取这一区域更多的细节信息,同时忽略其他无用区域的信息,将这种独特的信号处理机制,引入到深度学习的模型中,进一步提高了模型的效果。
在神经网络中,由于特征图的提取过程存在多次卷积和采样,致使网络对于空间信息和通道信息的保留较少,很难捕获空间信息和通道信息。为解决以上问题,本文选择ⅠCASSP 2022文献[23]提出的SALSANet作为基线,通过在卷积层中加入注意力机制来抑制特征图中的非显著性特征,首先在残差模块中引入CA(coordinate attention)模块以促进对空间信息的提取能力的提升,然后使用ECA(efficient channel attention)模块在特征图上高效地捕获位置和通道的关系。
1 提出的CECANet网络模型
声学特征的提取效果在很大程度上决定了模型预测不同声音事件的能力,并将影响最终的分类结果。注意力机制可使模型更加关注重要特征的区域,提高模型区分能力。坐标注意力机制简单灵活且高效,通过2D全局池化来计算通道注意力,在只增加了较低的计算成本下提供了显著的性能提升。本文将坐标注意力(CANet)加入残差模块中,让网络更加专注于有效特征的提取。并结合了轻量型高效通道注意力(ECANet),最终捕获了空间信息和通道信息的依赖关系,提高了网络对特征信息的敏感性。
1.1 SALSANet网络模型
SALSANet是Nguyen等人[23]提出来的,是一种用麦克风阵列输入的快速有效的复调SELD 网络模型。SALSANet 由CNN 和RNN 两部分构成,其网络结构如图1所示。CNN部分由两个卷积块(convolution module)、一层2×2 的平均池化层和四个残差模块组成。每个卷积块由一层核大小为3×3 的卷积、一层批归一化(batch normalization,BN)处理和一层ReLU 非线性函数组成。残差模块如图2 所示,每个残差块由两层核大小为3×3的卷积层,一层BN 处理和ReLU 函数组成。RNN 部分采用了2 个双向门控循环单元(bidirectional gated recurrent units,Bi-GRU),它的特点是在处理带有时间刻度的信息时,能结合过去和将来的信息进行预测。SALSANet网络模型结合了CNN和RNN的优点。网络模型输入是多通道对数线性频谱图和归一化通道间相位差特征图。
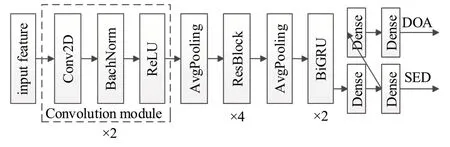
图1 SALSANet网络结构Fig.1 SALSANet network structure
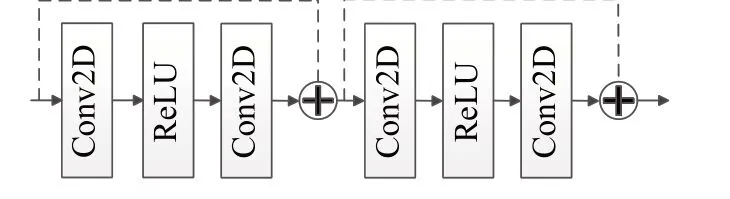
图2 残差模块网络结构Fig.2 Residual block network structure
1.2 CECANet网络模型
由于SALSANet网络多次池化采样,会造成位置信息和通道信息的丢失。因此,本文提出了CECANet 网络,其结构如图3所示。CECANet在每一个残差模块中加入CANet模块,帮助模型更精准地获得位置信息和声音事件类别信息,建立位置与局部特征之间的长依赖关系,增强声学特征的表达能力。在残差块后加入ECANet模块,调整深层网络下的特征图权重,进一步加强对通道信息的保留,在突出关键特征信息的同时,有效的抑制了背景噪声对特征图生成的干扰。

图3 CECANet网络结构Fig.3 CECA network structure
1.3 通道注意力模块
SENet(squeeze-and-excitation network)由Hu等人[24]提出。SE模块主要是通过建模,学习通道中的相关性,从而捕获通道信息,只增加了较少参数量和计算量,就取得了较好的性能提升。SE模块结构如图4所示。
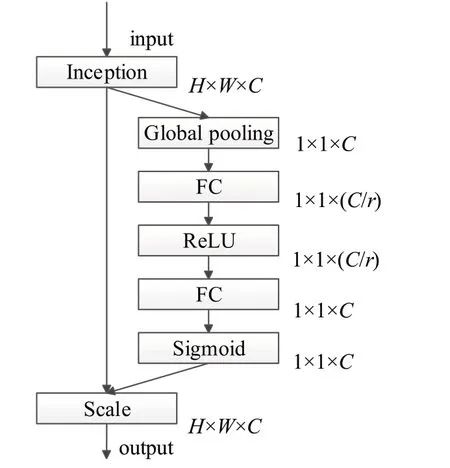
图4 SENet模块结构Fig.4 SENet module structure
SENet 模块包含挤压(squeeze)和激发(excitation)两部分,squeeze模块包含全局平均池化层(global average poolilng,GAP),将通道[H,W,C]压缩成[1,1,C],其中C是通道,H和W是图的高度和宽度。Excitation模块包含全连接层(W1)、ReLU层(δ)、全连接层(W2)和Sigmoid(σ)。给定输入为X,其特征通道数为C,r是控制模块大小的缩减率,则经过squeeze 模块计算公式为(1)所示:
其中Zc是经过GAP 层的输出。接下来就是excitation操作,如公式(2)所示:
SE 模块具有提升模型性能的效果,但其计算量较大,且只考虑内部通道信息而忽略了位置信息,而计算量的大小和视觉中目标的空间信息都很重要。因此,本文引用的ECANet 模块减少了SENet 模块的参数量,CANet模块获取了SENet模块所忽略的位置信息,极大地提升了模型的预测准确度。
1.4 坐标注意力
为了解决SE全局平均池化层造成的位置信息丢失这一问题,CANet 模块[25]将SENet 的全局平均池化层编码进行分解,形成两个并行的“X平均池化层”和“Y平均池化层”,分别代指一维水平全局池化层和一维垂直全局池化层,以有效地将空间坐标信息映射到通道注意中。CANet模块结构如图5所示。
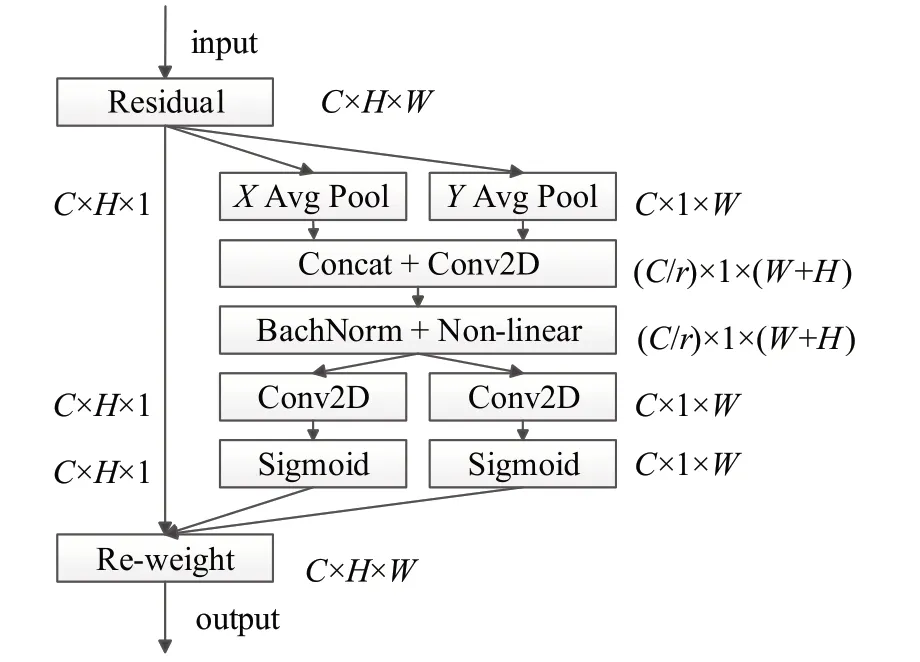
图5 CANet模块网络结构Fig.5 CANet module network structure
具体来说,其方法是将全局平均池化层中的公式(1)变成一维编码操作,让每个注意映射获得的特征图沿一个空间方向的远距离依赖关系。给定输入X,其特征通道数为C,使用两个空间范围的池化核(H,1)和(1,W)分别沿水平坐标和垂直坐标对每个通道进行编码。因此,第C通道在高度h的输出可以公式化为:
同理,宽度为w的第C个通道的输出可以写为:
上述两种变换分别沿两个空间方向聚合特征,生成一对方向感知特征映射。这与产生单一特征向量的SE模块squeeze操作不同。这两种变换还允许注意力沿着一个空间方向捕获长距离依赖关系,并沿另一个空间方向保留精确的位置信息,有助于网络更准确地定位感兴趣的对象。
接下来就是坐标注意力生成,将公式(3)和公式(4)生成的特征映射进行拼接,经过1×1卷积变换F1得到:
其中,[zh,zw]表示沿空间维度的拼接操作,δ是非线性激活函数,f∈ℝC/r×(H+W)是水平和垂直方向对空间信息编码的特征映射。然后将f沿着水平和垂直方向拆分为f h∈ℝC/r×H和f h∈ℝC/r×H,分别经过1×1 卷积变换Fh、Fw和激活函数σ,得到:
得到的gh和gw用于注意力权重。最后,坐标注意力模块的输出为:
因此,与通道注意力不同的是,坐标注意力在考虑通道的同时,也关注了空间位置信息,完成了水平方向和垂直方向的特征进一步提取,将原始输入与CANet模块的输出相加,形成残差学习方式,防止梯度消失,同时增强网络模型的学习能力。
1.5 高效通道注意力模块
ECANet模块[26]是一种极轻量级的高效通道注意力模块,其网络结构如图6所示。

图6 ECANet模块网络结构Fig.6 ECANet module network structure
SE模块中全连接层通过降维来降低网络模型的复杂度,但降维对模型带来了副作用,过量的通道之间所捕获的关系是低效且不必要的。因此,ECANet 模块移除了全连接层操作,避免降低通道维度对通道之间信息交互带来的副作用,从而减小了模型复杂性,通过卷积核大小为k的1D卷积来实现捕获适当的跨通道交互信息。
在全局平均池化操作后,ECANet 模块通过考虑每个通道及其k个邻居来捕获局部跨通道交互信息,保证了模型的轻量性和计算效率。接下来通过大小为k的快速1D卷积,公式如下:
其中,C1Dk代表卷积核大小为k的一维卷积。k代表了局部跨信道交互的覆盖率。卷积核大小k与通道的个数(C)成正比,即k和C之间存在线性映射关系,但是线性函数对相关特征具有局限性。因此,可以将线性映射关系改成非线性映射关系,公式如下:
已知通道数是C,卷积核的大小k可以根据公式(11)得到:
其中,|x|odd表示最接近x的奇数,本文采用的γ=2,b=1。
与含有SE模块的网络模型相比,带有ECANet模块的网络模型引入了很少的额外计算和几乎可以忽略的参数量,同时带来了性能提升。
1.6 损失函数
本文声音事件检测任务中使用L1损失函数优化网络模型,L1 损失函数的梯度为常量,有着稳定的梯度,相对于原基线中用的MSE 损失函数不会产生梯度爆炸,对声音事件检测误差的惩罚力度更小,公式如下:
其中,f(xi)和yi分别表示第i个声音事件检测的预测值及相应的真实值,n为声音事件的个数。
2 实验结果与分析
2.1 实验数据集
本文采用的数据集是TAU-NⅠGENS Spatial Sound Events 2021 数据集[27]。该数据集由坦佩雷理工大学收集,采样频率为24 kHz,包含600 个长为一分钟的录音文件,其中包括整合到各种声学空间中的12 种不同类别的声音事件,声音事件类别分别是警报声、婴儿哭泣声、碰撞声、狗叫、女性尖叫、女性演讲、脚步声、敲门声、男性尖叫、男性演讲、电话铃声、钢琴声。这些录音是从特定室内位置收集的空间房间脉冲响应,每个录音文件在时间和空间上最多可能发生3个重叠的声音事件,并且来自多个源方向和距离。此外,不属于任何这些类别的不同声音的录音也以相同的方式空间化以用作噪声干扰。数据集分为6个交叉验证部分,每部分有100个。其中400个用来训练,100个用来验证,100个用来测试。
2.2 评价指标
本文使用标准度量F1分数(F1-score,F1)和错误率(error rate,ER)来评估声音事件类别的识别,使用标准度量帧召回率(localization recall,LR)和定位错误率(localization error,LE)来评估声源位置信息。其中评价指标F1的计算公式如下:
其中,FN(false negatives)是声音事件类假阴性,TP(true positives)是声音事件类真阳性,FP(false positives)是声音事件类假阳性,定义如表1所示。
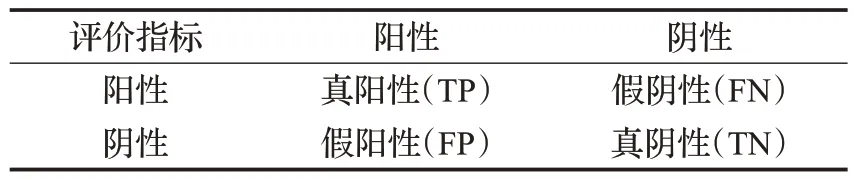
表1 评价指标Table 1 Evaluation indicators
评价指标ER计算公式如下:
N(k)是参考中活动声音事件类别的总数。S(k)是检测到的声音事件数量但预测错误,是假阴性和假阳性中较小者。剩余的假阳性和假阴性(如果有的话)分别计为插入I(k)和删除D(k),定义公式如下:
如果预测类和参考类相同,且小于20°,则认为预测是正确的。使用F1和ER度量标准共同评估SED任务,F1越大,ER越小,模型性能越好。只有当声音事件的类别预测正确,且其预测的DOA与DOA真实值角度小于D时,才会将其视为正确的检测,一般D取20°。
评价指标LR和LE的计算公式分别如下:
其中,uref和upre分别表示为参考声音事件和预测声音事件的单位笛卡尔位置向量。
2.3 实验环境及参数设置
本文实验运行环境的硬件设施为:CPU 主频为3.6 GHz,显卡为NVⅠDⅠA RTX 2080Ti,内存为32 GB;软件环境为:操作系统为Windows10,深度学习框架为PyTorch=1.7.0,编程语言为Python3.7。SED 和DOA 估计的损失权重分别设置为λ=0.3 和γ=0.7,数据集训练时均采用Adam 算法对模型收敛速度进行优化。实验的初始学习率设定为3×10-4,在15 个epoch后下降到10-4,共训练50个epoch。
2.4 实验结果分析
不同的声音事件通常有不同的持续时间。因此,在训练过程中使用的时间长度会影响模型的性能。TAUNⅠGENS Spatial Sound Events 2021 数据集上的声音事件时长通常在0.2~40.0 s,中位数为3.2 s,平均数8.3 s。本文分别在4 s、8 s、12 s、16 s四种不同输入时间长度下训练CECANet模型,其结果如表2所示。

表2 不同输入时间长度下训练CECANet模型的实验结果Table 2 Experimental results of training CECANet models with different input time lengths
实验证明,用8 s 的输入时间长度训练评价指标明显优于4 s,相比于12 s和16 s的时间长度,CECANet模型性能并没有进一步提升。因此,本文选取8 s 的输入时间长度。
为了验证本文提出的CECANet的有效性,将CECANet与其他先进的个人提出的网络模型进行了对比实验。选择作为对比的网络模型模型分别是SALSANet、CRNNNet、CNN-Conformer 和CMA-SELD。表3 展示了各网络模型在TAU-NⅠGENS Spatial Sound Events 2021数据集上的实验结果。

表3 不同模型在数据集上的实验结果Table 3 Experimental results of different models on dataset
由表3 可知,CECANet 相较于其他模型F1 均有较大程度的提升,ER和LE有较大程度的下降,LR只略低于CMA-SELD模型0.5个百分点,优于其他模型。实验证明,CECANet对SELD的定位和检测更准确,效果更好。
图7~12是TAU-NⅠGENS Spatial Sound Events 2021数据集中的fold6_room2_mix041 文件的可视化输出对比,横轴代表时间,SED 参考和预测图的纵轴代表独特的声音事件类别标识符,对于方位角参考和预测图,它表示沿笛卡尔轴的距离。其中图7 和图8 是CRNNNet模型的预测结果,图9和图10是SALSANet模型的预测结果,图11 和图12 是CECANet 模型的预测结果,图中的不同颜色代表不同声音事件类别,蓝色代表警报声、红色代表婴儿哭泣声、绿色代表碰撞声、黑色代表女性尖叫声、蓝绿色代表女性演讲声、红紫色代表脚步声。由图7、图9、图11可知,CECANet模型预测声音事件的轨迹是最为精确的,并密切遵循基本事实。CECANet模型能够在不同数量的重叠声源(最多3 个重叠声源)之间正确检测声音类别并估计DOA。在第4 s和第12 s之间,未知干扰被错误分类为其他声音类别。由于使用类输出格式来训练模型,当22 s和24 s之间有两个重叠的声音事件时,模型只预测了一个声音事件。

图7 CRNNNet SED参考和预测Fig.7 CRNNNet SED reference and prediction
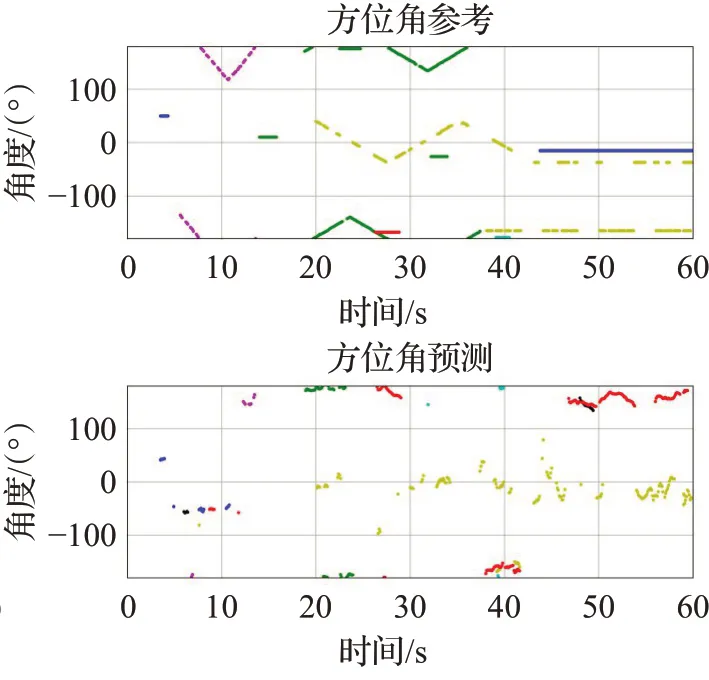
图8 CRNNNet方位角参考和预测Fig.8 CRNNNet azimuth reference and prediction

图9 SALSANet SED参考和预测Fig.9 SALSANet SED reference and prediction
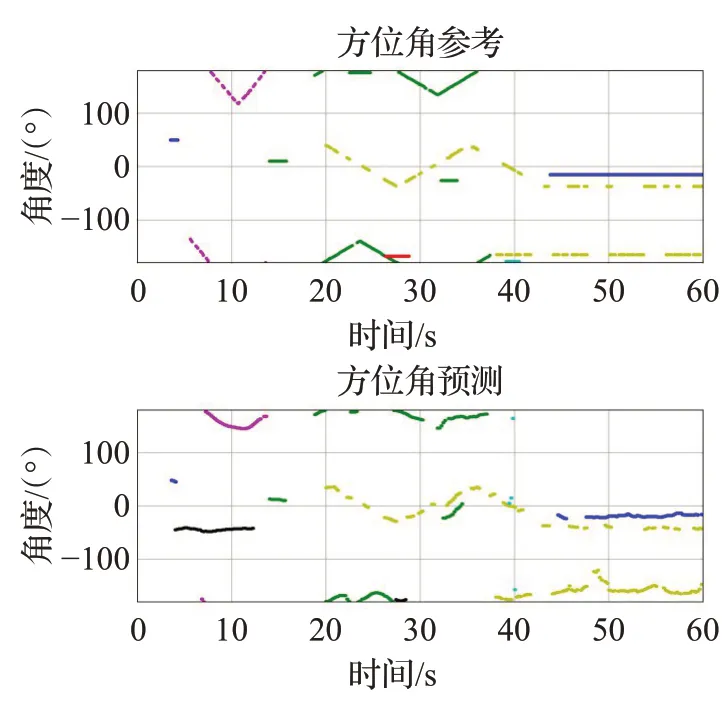
图10 SALSANet方位角参考和预测Fig.10 SALSANet azimuth reference and prediction

图11 CECANet SED参考和预测Fig.11 CECANet SED reference and prediction
2.5 消融实验
为了验证CECANet 模型中每一步改进的有效性,在SALSANet分别加入CANet和ECANet模块,在TAUNⅠGENS Spatial Sound Events 2021 数据集上进行了测试,并计算其参数量。实验结果如表4 所示,CANet模型是在SALSANet 模型基础上加入CANet 模块的实验结果,ECANet模型是在SALSANet基础上加入ECANet模块的实验结果,CECANet模型是在SALSANet基础上加入CANet 和ECANet 模块的实验结果。由表4 可知,仅加入CANet模块,使网络模型的ER下降了1.2个百分点,F1提升了1个百分点,LE下降了0.7°,LR提升了0.3个百分点。加入ECANet 模块时,ER 下降了0.6 个百分点,F1提升了0.8个百分点,LE下降了0.11°。最终实验表明,同时加入CANet 和ECANet 模块,ER 下降了1.6个百分点,F1 提升了1.3 个百分点,LE 下降了0.63°,LR提升了1.2个百分点,进一步提高了SELD定位和检测的准确度和效果。
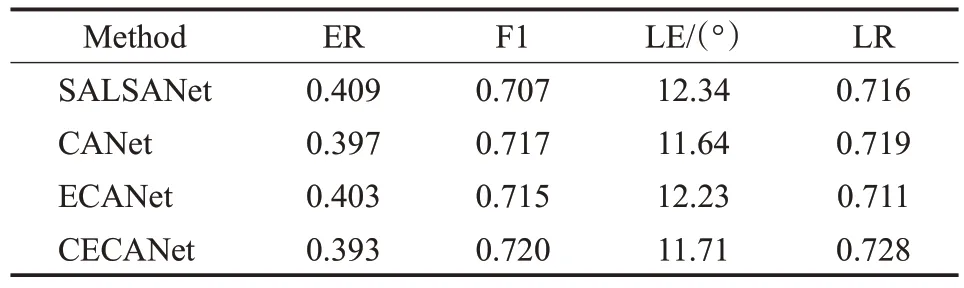
表4 各改进步骤的实验结果Table 4 Experimental results of each improvement step
3 结语
针对SELD定位难、效果差等问题,本文以SALSANet为基线模型,结合坐标和高效通道注意力设计出CECANet 模型。该网络模型优势在于,通过加入坐标注意力和高效通道注意力,可以更好地捕获特征图在空间和通道上的信息,进一步提高了SELD 的指标性能。并在TAU-NⅠGENS Spatial Sound Events 2021 数据集上实验证明,本文提出的CECANet 相对于SALSANet在F1 和LR 均有较大程度的提升,ER 和LE 均有下降,相较于其他模型对SELD 的检测和定位也具有一定优势。在以后的研究工作中,还可以从声音事件特征提取方向着手,研究出更加轻量级的网络结构,进一步提高声音事件定位与检测的速度和准确性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
