
融合生成对抗网络与时间卷积网络的普通话情感识别
2023-10-08 02:28:28李海烽张雪英段淑斐贾海蓉HuizhiLiang
浙江大学学报(工学版) 2023年9期
李海烽,张雪英,段淑斐,贾海蓉,Huizhi Liang
(1.太原理工大学 电子信息与光学工程学院,山西 太原 030024;2.纽卡斯尔大学 计算机学院,泰恩-威尔 泰恩河畔纽卡斯尔 NE1 7RU)
情感识别(emotion recognition, ER)是人机交互的重要接口[1],其目的是让计算机具备理解和识别情感的能力.融合声学与发音特征转换的ER是情感研究领域中的重要分支,涉及情感数据库搭建、预处理、特征提取、特征转换和分类识别算法等问题.具有丰富情感信息的多模态数据库、高精度的特征转换算法和有效的分类识别算法是提升ER系统性能的重要部分.
在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2]、NNIME[3]和IEMOCAP[4]等.每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍.在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5].正向映射[6]和反向映射[7]是声音与发音器官的关联性研究中较深入的2类.正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征.深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8]通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9]提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别.这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题.Guo等[10]提取相位特征并探索如何将相位特征应用于语音情感识别.双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)[11]、卷积神经网络(convolutional neural network, CNN)[12]、深度递归神经网络(recurrent neural network, RNN)[13]和深层神经网络(deep neural network, DNN)[14]等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用.
ER研究的现状如下:1)数据库存在局限性,暂未发现公开可用的、以普通话为语种的、为并行声学与发音学信号的情感数据库;2)传统的特征转换模型的精度偏低;3)识别算法没有充分利用特征所含的情感信息;4)正向映射、反向映射对普通话情感识别的影响暂无研究成果.本研究提出融合声学与发音特征转换的情感识别系统.该系统由特征转换网络和分类识别网络组成,其中双向映射生成对抗网络(bi-directional mapping generative adversarial network, Bi-MGAN)负责声学与发音特征转换任务,基于特征-维度注意力的残差时间卷积网络(residual temporal convolution network of feature-dimension attention, ResTCN-FDA)负责情感分类识别.
1 相关理论
1.1 循环生成对抗网络
在设计之初,循环生成对抗网络(cycle generative adversarial network, CycleGAN)通过学习样本空间X与Y的转换关系来解决图像风格转换问题[15].CycleGAN已被应用到不匹配数据的语音增强[16]和情感识别[17]领域.CycleGAN包含2个生成器和2个判别器(DX和DY),生成器对X与Y的转换关系建模,判别器对真实特征与映射特征进行评判,并使用对抗性损失函数和循环一致性损失函数来训练模型.对抗性损失函数用于衡量映射特征与真实特征的可分辨性,GX→Y和DY的损失函数为
1.2 时间卷积网络
时间卷积网络(TCN)可以并行处理特征序列, 为了提升TCN的建模能力, Lin等[18]将自注意力机制与TCN结合,提出多级SA-TCN网络;Pandey等[19]提出TCNN模型,用于探索时域中的实时语音增强;Zhang等[20]改良TCN,并将改良TCN用于声道的语音分离.ResTCN利用TCN来快速并行处理特征序列,并通过残差连接使模型在训练过程中产生稳定的梯度优化路径.其中残差连接式为
式中:h(xi)为直接映射,xi为i层输入特征,为残差连接,w(i,d)为第i层膨胀因子为d的卷积.
2 STEM-E2VA数据库与特征集
2.1 STEM-E2VA数据库的构建
包含发音、声门、视频和音频数据的普通话情感数据库(Suzhou and Taiyuan emotional dataset on Mandarin with electromagnetic articulation, electroglottography, video and audio, STEM-E2VA)由苏州大学与太原理工大学联合录制,语料内容由528个韵母和2 464个汉语句子组成,其中汉语句子包含7种情感,分别是中性、狂喜、愉悦、愤怒、冷漠、悲伤和痛苦.STEM-E2VA的数据采集招募22名被试者,其中62.5%为学士学位,37.5%为硕士学位,平均年龄25岁,男女比例为1∶1.在采集数据之前,所有被试者均通过了《症状自评量表SCL-90》的检测.
STEM-E2VA的设计借鉴人体发声机理,将喉、舌和唇作为重要的发音器官,赋予语音丰富的情感信息.本研究使用电子声门仪(electroglottography,EGG)采集声门信号,使用电磁发音仪(electromagnetic articulography, EMA)采集声学和发音学数据,使用SONY摄像机采集面部微表情数据.将传感器固定在发音器官上,EMA通过电磁耦合以250 Hz的采样率采集传感器的笛卡尔坐标作为发音学数据,并同步记录声学数据,形成并行的声学与发音学数据,如图1所示.如图2所示, EMA数据采集共设置13个传感器,分别为3个参考面传感器、3个咬合板传感器、4个唇部传感器和3个舌部传感器.参考面传感器分别设置在被试者的B1、B2和B3位置,用以排除采集数据时因头部运动带来的误差;咬合板传感器分别布置在咬合板面的P1、P2和P3位置;唇部和舌部的传感器负责采集发音器官的运动轨迹数据,分别布置在左唇、右唇、上唇、下唇、舌根、舌中和舌尖.在传感器可以稳定传输数据后,受试者按要求表述语料内容.

图1 电磁发音仪采集声学与发音学数据的过程Fig.1 Electromagnetic articulography acquisition process for acoustic and articulatory data

图2 电磁发音仪采集数据时的传感器设置Fig.2 Sensor settings for data acquisition by electromagnetic articulography
2.2 数据预处理
选取数据库中的声学数据和发音学数据,研究声学与发音特征转换对情感识别的影响.EMA采集的发音学数据以电压幅值的形式存储,为便于后续的实验操作,须进行数据预处理.预处理步骤:1)将电压幅值数据转换为原始三维空间数据,2)利用参考面传感器生成三维空间数据,3)将空间数据转换为ASCII码,4)使用Visartico软件筛选出合格的发音学数据.
在声学数据预处理中,让6名母语为普通话且听力正常的志愿者按照如表1所示的评估量表进行声学数据评分,选择评分不低于2.5的声学数据.在预处理后,得到并行的声学和发音学数据共2 415条.其中悲痛情感的为337条,狂喜情感的为335条,愉悦、愤怒情感的各345条,忧伤情感的为349条,中性、冷漠情感的各352条.

表1 声学数据评估量表Tab.1 Acoustic data assessment scale
2.3 特征提取
从声学和发音学数据中分别提取MFCC和发音特征.MFCC特征能够模拟人耳对语音的处理,Kumaran等[13]发现MFCC特征转换出的发音特征具有良好的映射性能.本研究选用MFCC作为声学特征,定义MFCC特征集为
式中:Sx、Sy、Sz分别为发音器官在x、y和z轴的位移参数,V为发音器官的速度参数,共28维发音特征.
3 融合Bi-MGAN和ResTCN-FDA的情感识别系统
融合Bi-MGAN和ResTCN-FDA的情感识别系统将声学与发音特征转换引入语音情感识别研究:1)Bi-MGAN负责将已知的真实特征转换为对应的映射特征;2)将真实特征与映射特征融合,使融合后的特征集同时包含声学和发音特征所表征的情感信息;3)将融合特征集输入ResTCNFDA,利用FDA给不同特征的不同维度通道分配不同的权重系数,再经过Softmax层进行情感分类.如图3所示,、分别为映射的发音特征和循环的发音特征,、分别为映射的声学特征和循环的声学特征;虚线箭头表示将发音特征和映射发音特征融合后输入ResTCN-FDA,点划线箭头表示将声学特征和映射声学特征融合后输入ResTCN-FDA;以此探索声学与发音特征转换中的正向与反向映射对情感识别的影响.
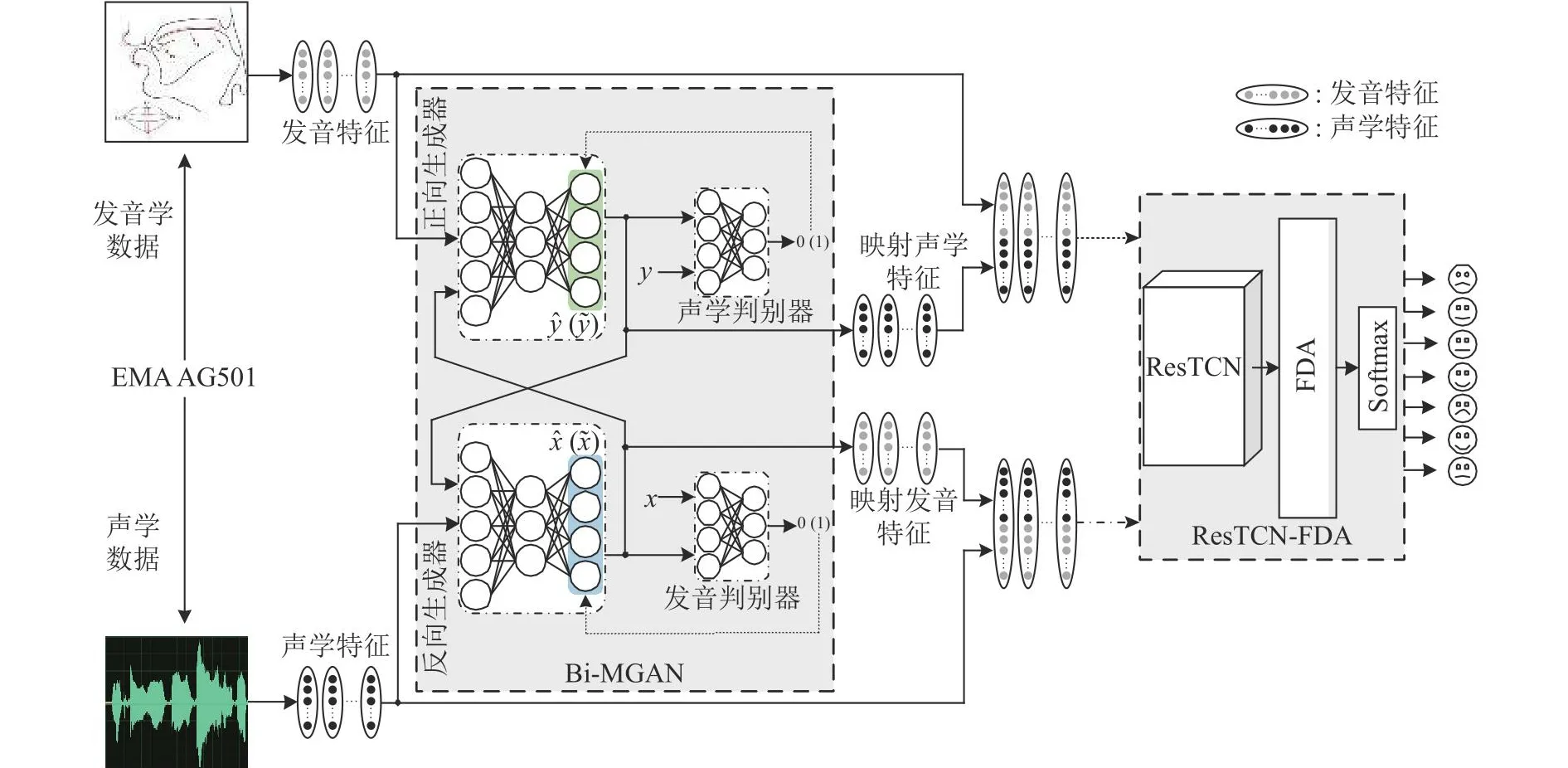
图3 融合Bi-MGAN和ResTCN-FDA的情感识别算法整体结构Fig.3 Overall structure of emotion recognition algorithm fusing Bi-MGAN and ResTCN-FDA
3.1 Bi-MGAN
转换网络的目的是利用真实特征生成高精度的映射特征,进而探究映射特征对语音情感识别的影响.CycleGAN应用在图像风格转换任务时不要求成对的训练数据[21],这与声学与发音特征转换任务不同.人体多数语音都是依靠独特的声道形状产生[5],这就要求声学与发音学数据的并行性.为了增强转换模型的映射能力,本研究对CycleGAN的网络结构和损失函数进行优化改进,提出适用于声学与发音特征转换任务的Bi-MGAN,如图4所示.图4(a)中Bi-MGAN将真实发音特征x转换为映射声学特征,再将转换为循环发音特征:1)将真实的声学特征x转换为对应的映射发音特征;2)利用y与的误差,计算声学特征映射损失;3)将映射发音特征转换为循环声学特征;4)利用x与的误差,计算发音特征循环一致性损失.同理,图4(b)中Bi-MGAN将真实声学特征y转换为映射发音特征,再将转换为循环声学特征.
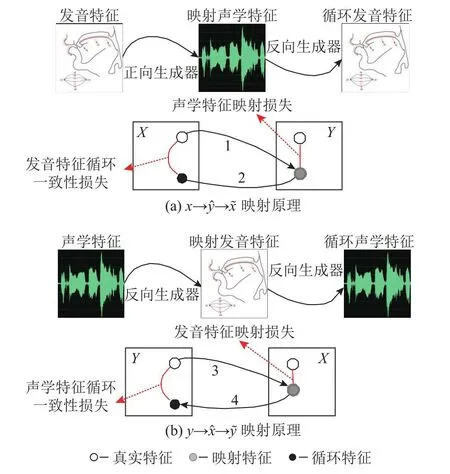
图4 双向映射生成对抗网络的网络原理图Fig.4 Network schematic of bi-directional mapping generativeadversarial network
声学与发音特征转换任务的计算量相对较小,为了减少转换网络的冗余度,避免梯度消失,提高映射精度,对生成器和判别器进行优化.Bi-MGAN由正向生成器GX→Y、反向生成器GY→X、发音学判别器DX和声学判别器DY构成.正向生成器的结构设计利用发音特征映射出对应的声学特征,目的是使声学判别器无法正确判断映射的声学特征和真实的声学特征.为了减少模型冗余度,选用Dense层来构建上、下采样模块.上采样模块将输入的28维发音特征扩展到512维,下采样模块负责将高维度的发音特征转换为60维的声学特征.反向生成器的结构设计的不同之处在于反向生成器利用MFCC特征映射出对应的发音特征,目的是使发音学判别器无法正确判断映射的发音特征和真实的发音特征.发音学判别器对真实的发音特征和映射的发音特征进行判别和计算,并利用损失函数回调反向生成器的权重参数,提高映射特征的精度,达到对映射发音特征的监督和反馈效果.发音学判别器本质为二分类识别器,恰好与反向生成器的期望相反,目的是能够正确的判别映射的发音特征和真实的发音特征,如此映射模型将会在两者的交替迭代优化中找到全局最优解.声学判别器是对真实的声学特征和映射的声学特征进行判别,并利用损失函数回调正向生成器的权重参数,达到对映射声学特征的监督和反馈效果.
Bi-MGAN的损失函数的优化主要体现在2个方面:生成器损失函数和束缚性映射损失函数.Bi-MGAN在训练期间考虑4种类型的损失:生成器损失、对抗性损失、循环一致性损失和束缚性映射损失.1)生成器损失函数:新增Lg作为生成器的基础映射函数,增强生成器的转换能力.GX→Y、GY→X的生成器损失函数分别为
式中:Lbce为交叉熵损失函数.使用Lbce对GX→Y(x)进行判定;若判定结果为真,则说明GX→Y(x)与真实特征y难以区分;若判断为假,则将产生误差.2)束缚性映射损失函数:要完成声学与发音特征转换任务,仅依靠式(1)、(2)、(6)和(7)不能保证映射特征的精度,将真实特征与映射特征的正则化引入Bi-MGAN,通过减少模型在训练时生成误差较大的映射特征,约束映射特征的生成范围.正向与反向束缚性映射损失函数分别为
式中:L1(y,GX→Y(x))为真实声学特征y与映射声学特征GX→Y(x)的L1差值.
3.2 ResTCN-FDA
情感诱发下的不同特征以及不同维度通道携带的情感信息具有一定的差异性[9].在模型训练时,不同特征的不同维度通道分配的权重相同,将导致情感信息的不充分利用.本研究将ResTCN与注意力机制相结合,提出融合FDA注意力机制的ResTCN情感识别网络,通过对ResTCN输出的特征进行加权调整,更好地利用声学与发音特征中与情感显著相关的特征和维度通道.
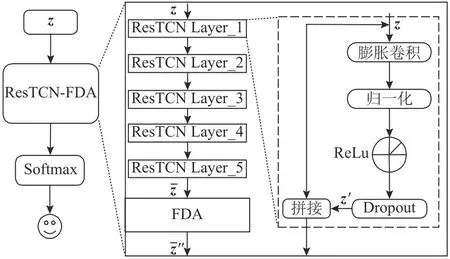
图5 ResTCN-FDA的整体结构图Fig.5 Overall structure of ResTCN-FDA
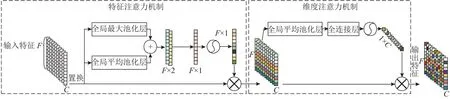
图6 特征-维度注意力机制的整体结构框图Fig.6 Overall structural framework of feature-dimensional attention mechanism
3.2.1 特征注意力机制 在情感识别中,多特征融合比单一特征的识别效果好[9].不同的特征对情感识别的反应能力不同,为了更好地提取多类特征中的情感信息,计算中各类特征的情感信息权重.如图6所示,将转置后的特征向量分别通过全局最大池化层和全局平均池化层,再将两者的输出进行拼接,并通过卷积层和Sigmoid层,最终得到特征注意力权重.
3.2.2 维度注意力机制 针对卷积层在处理序列特征时,维度通道分配相同权重系数导致情感信息的不充分利用问题[12],本研究提出维度通道注意力机制.如图6所示,对进行全局平均池化,得到每个维度通道下的特征均值,再用全连接层和Sigmoid层实现维度注意力,最后将维度注意力的权重系数作用于, 为各个维度通道分配不同的权重系数:
式中:ω为全连接层映射;Fave,c为第c维度通道下的特征均值,其中维度通道下的的特征.
4 实验结果分析
4.1 实验设置和评价指标
实验所用服务器显卡为NVIDIA GeForce RTX 2080,CPU为Intel Core i9-11950H.算法基于Python下的Tensorflow框架完成.网络模型皆以五折交叉验证的方法随机划分数据集.为了验证转换网络的有效性,采用平均绝对误差和均方根误差作为评价指标,
式中:MAE为真实特征和映射特征绝对误差的平均值,RMSE为真实特征和映射特征之间的样本标准差,Nt为测试样本的数,ei、ti分别代表第i测试样本的映射值和真实值.为了验证识别网络的有效性,采用准确率、F1指标、曲线下面积(area under the curve)和混淆矩阵作为评价指标,
式中:ACC为总样本中被正确分类的样本比例,TP为真正例,TN 为真反例,FP 为假正例,FN为假反例,FI为模型的稳健程度AUC为任意正类样本大于负类样本的概率,pos为正例类别,O为正样本个数,N为负样本个数,ri为第i样本的序号.
4.2 不同转换模型的性能对比
为了验证生成器损失函数和束缚性映射损失函数的有效性,进行转换模型的消融实验,对比模型分别设置为CycleGAN[21]、生成对抗网络(generative adversarial network, GAN)[22]、加入生成器损失函数的Bi-MGAN(G)、加入束缚性映射性损失函数的Bi-MGAN(M)和包含以上2种损失函数的Bi-MGAN(GM).如表2所示,Bi-MGAN(G)较CycleGAN的MAE和RMSE分别提升0.010~0.093 mm和0.011~0.087 mm,Bi-MGAN(M)较CycleGAN的MAE和RMSE分别提升0.169~0.248 mm和0.038~0.294 mm,表明生成器损失函数与束缚性映射损失函数在正向和反向映射中皆有利于转换模型生成高精度的映射特征.此外,Bi-MGAN(GM)较Bi-MGAN(M)的MAE和RMSE分别提升0.141~0.176 mm和0.198~0.214 mm,表明生成器损失函数与判别器损失函数的结合会增强模型映射能力,使得映射特征更加趋近于真实特征.
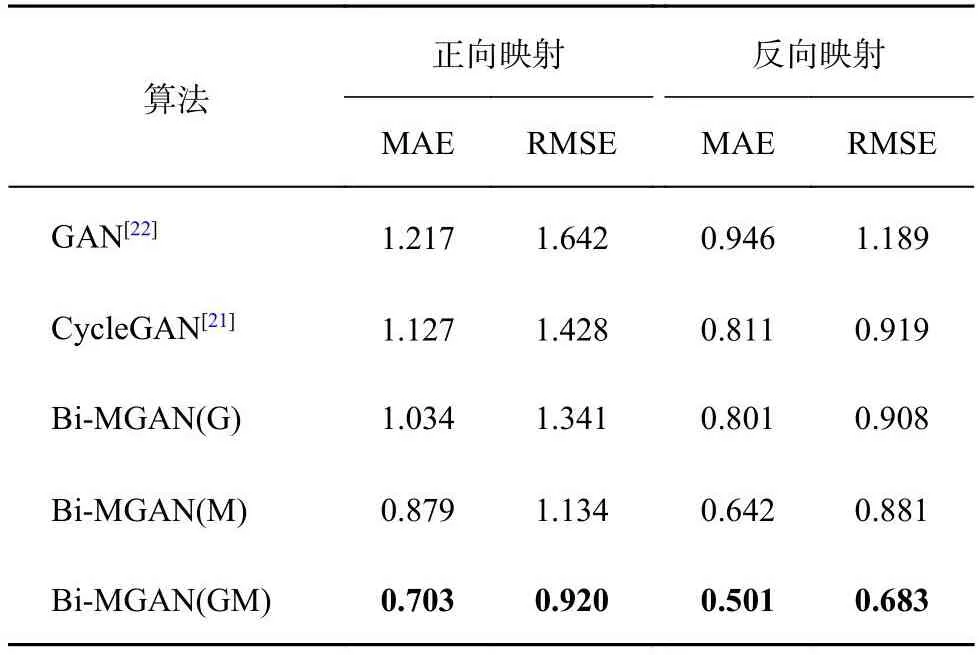
表2 转换网络算法的消融实验Tab.2 Ablation experiment of conversion network algorithmmm
为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14]和BiLSTM[11]以及深度递归混合密度网路(deep recurrent mixture density network,DRMDN)[23]和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6]进行对比.如表3所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm.对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性.

表3 转换网络算法的映射性能对比Tab.3 Comparison of mapping performance for conversion networks algorithmmm
4.3 情感识别网络的性能对比
为了探究FDA在情感识别中的作用,分别提取STEM-E2VA、CASIA、RADVESS和EMO-DB数据库的60维MFCC作为识别网络的输入,进行ResTCN-FDA的消融实验.其中CASIA为6分类数据库,STEM-E2VA和EMO-DB为7分类数据库,RADVESS为8分类数据库.如表4所示,将ResTCN-FA、ResTCN-DA与ResTCN对比可以发现,特征注意力机制对准确率提升量为1.52%~5.32%,维度注意力机制对准确率提升量为1.50%~4.54%,证明给不同特征和不同通道维度分配不同的权重参数有利于提升情感识别准确率.将ResTCN-FDA对比TCN、ResTCN、ResTCN-FA和ResTCN-DA,准确率分别提升量为7.48%~10.92%、4.14%~8.16%、2.00%~4.16%和2.48%~6.66%.另外,ResTCN-FDA的F1和AUC也比其他算法的有一定程度的提升,这说明ResTCN-FDA可以更好的处理情感信息.
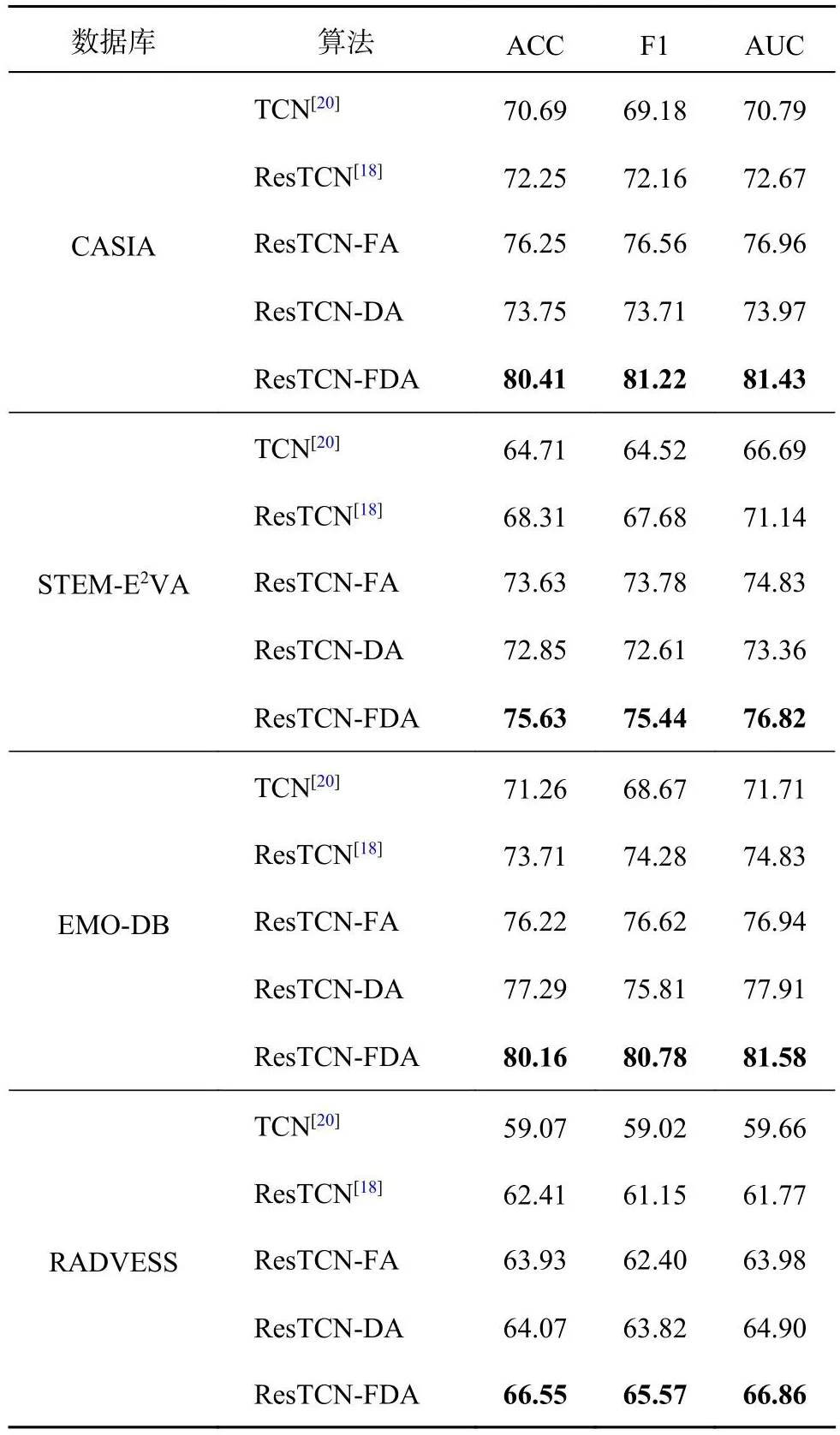
表4 情感识别网络算法的消融实验Tab.4 Ablation experiment of emotion recognition networks algorithm%
为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24]和DRN[25]进行比较.如表5所示,ResTCN-FDA在CASIA、STEM-E2VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HSTCN和DRN相比性能有明显提升.此外,ResTCNFDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性.
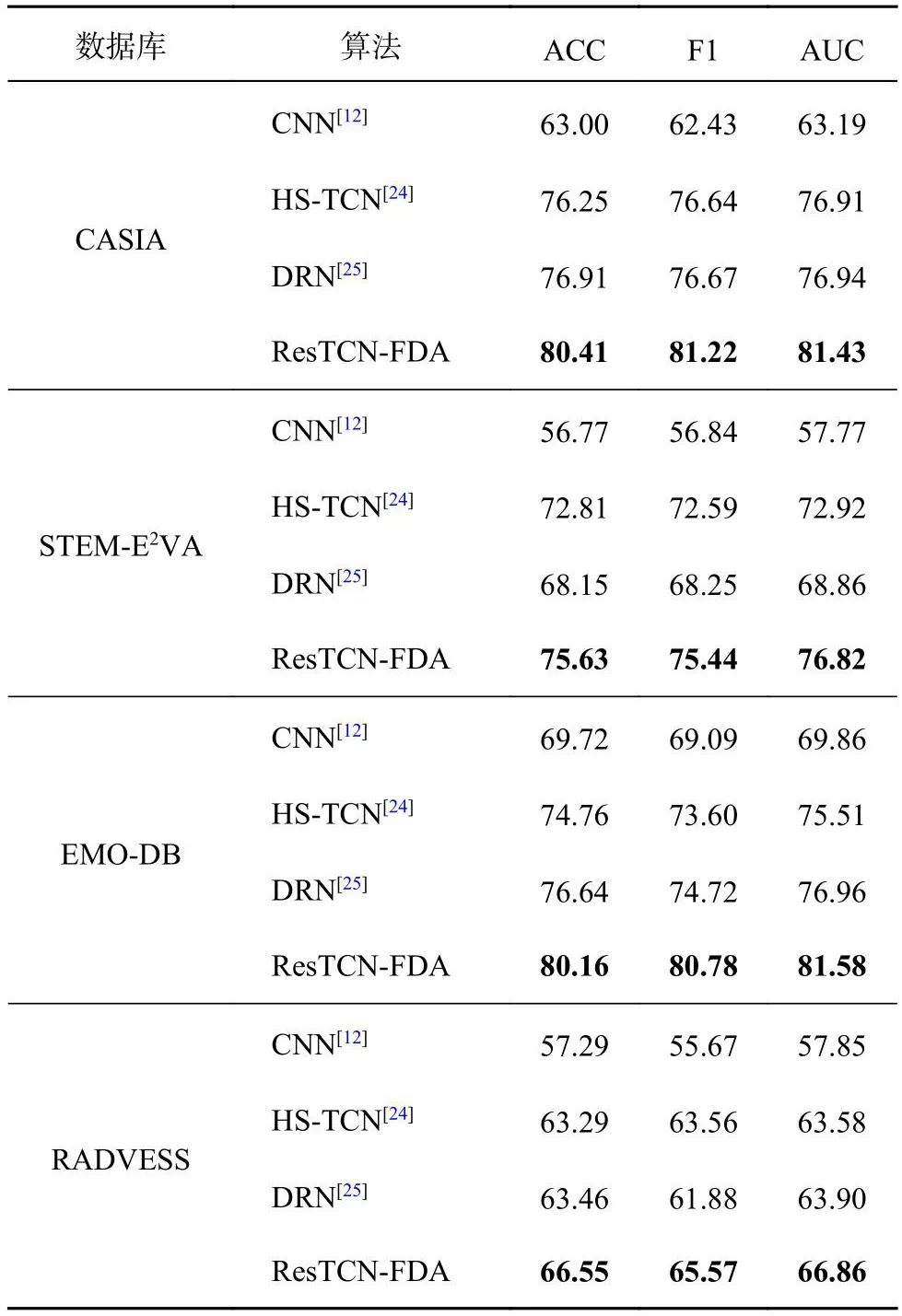
表5 情感识别网络算法的情绪评价指标对比Tab.5 Comparison of emotion evaluation metrics for emotion recognition networks algorithm%
4.4 声学与发音特征转换对情感识别的影响
为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCNFDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响.另外,提取预训练特征[26-27]来对比声学与发音特征的情感识别性能.
如表6所示,在单模态特征中,真实声学特征集的识别率最高为75.63%,映射声学特征集的准确率和映射发音特征集的准确率均低于对应真实特征集的准确率,说明映射特征所包含的情感信息低于真实特征,即正向映射与反向映射会降低识别准确率.在双模态特征中,真实的声学与发音特征的识别率最高为83.77%,真实特征在与映射特征融合后,真实的声学和发音特征集的识别率均有提升,说明映射特征会对真实特征起到情绪补充作用.对比所提特征与预训练特征不难发现,由48层转换提取的HuBERT特征的准确率达到89.66%,相较于真实的声学与发音特征提高5.89个百分点,这说明HuBERT特征在情感识别任务中可以取得比Wav2vec2.0特征和声学与发音特征更好的识别结果.为了保证同一维度下不同特征的对比,对预训练特征使用主成分分析算法降维,通过线性投影将预训练特征分别投影到60维与88维的空间.由表6中可知,60维的HuBERT的准确率最高为78.54%,分别比Acoustic(C)和Acoustic(R)特征识别率高19.31个百分点和2.91个百分点;88维的HuBERT的准确率为80.16%,高于真实声学与映射发音特征,但低于真实声学和真实发音特征,证明在低特征维度的时,HuBERT特征识别率会高于声学特征,但是低于声学与发音学的融合特征.
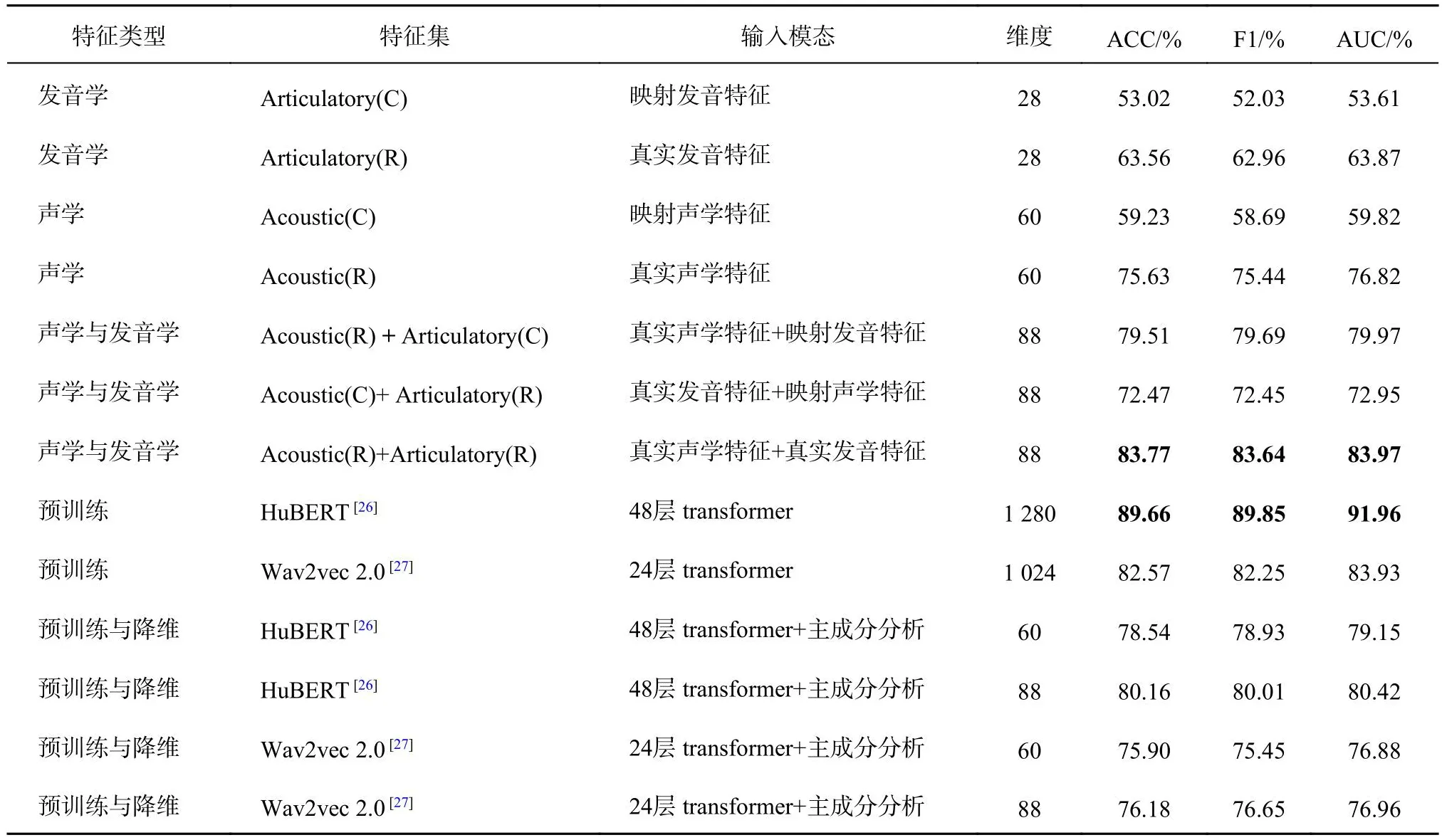
表6 不同声学特征与发音特征的情感评价指标对比Tab.6 Comparison of emotion evaluation indexes for different acoustic and articulatory features
如图7所示为不同特征的混淆矩阵.从图7(a)~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响.对比图7(a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异.对比图7(c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用.对比图7(a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升.

图7 不同特征集的混淆矩阵Fig.7 Confusion matrix for different feature sets
5 结 语
根据声学信号与发音学信号的特性,提出融合声学与发音特征转换的情感识别系统.该系统能够利用Bi-MGAN生成高精度的映射声学特征和映射发音特征,融合FDA机制的ResTCN网络,实现了对特征的权重系数再分配,做到了对特征信息的最大化利用.在探究真实特征和映射特征对情感识别的影响中,映射特征包含的情感信息对真实特征起情绪补充作用,且对不同情绪的补充效果不同.本研究设计并录制的STEME2VA数据库填补了该领域研究中数据的不足.未来计划引入预训练模型和对比学习,让计算机具有理解多模态情感信息的能力.
猜你喜欢
阅读(快乐英语中年级)(2023年11期)2023-04-29 00:00:00
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
家庭影院技术(2020年6期)2020-07-27 01:37:54
家庭影院技术(2019年1期)2019-01-21 02:25:04
家庭影院技术(2018年11期)2019-01-21 02:20:50
今日农业(2019年15期)2019-01-03 12:11:33
家庭影院技术(2018年10期)2018-11-02 05:35:26
小学生时代·大嘴英语(2015年12期)2016-01-07 16:10:00
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
