
基于GPU的子图匹配优化技术
2023-10-08 02:28李安腾崔鹏杰袁野王国仁
浙江大学学报(工学版) 2023年9期
李安腾,崔鹏杰,袁野,王国仁
(1.北京理工大学 计算机学院,北京 100081;2.东北大学 计算机科学与工程学院,辽宁 沈阳 110169)
图作为重要的数据结构,能清晰地表示系统内各部分之间的复杂联系.子图匹配是基础的图数据挖掘算法,目的是在数据图中找到与查询图结构相同的子图,在社交网络分析[1-2]、知识图谱检索[3-5],化合物发现[6]、生物事件提取[7]等领域都有重要应用.子图匹配被证明是NP-hard问题[8],传统的解决方法通常基于树的搜索和回溯实现[9].随着信息时代的发展,图数据规模急剧增大,上百万条边的图已十分常见[10],传统的串行子图匹配算法难以应对.以图形处理器(graphic processing unit, GPU)为中心的中央处理器(center processing unit, CPU)-GPU异构图处理系统不断涌现[11-12],英伟达推出的计算机统一设备架构(computer unified device architecture,CUDA)编程模型进一步方便了GPU的使用.相比于以CPU为主的图计算系统,GPU有更高的带宽和并发度,为子图匹配问题的解决带来了新的思路.
根据算法的执行环境,对子图匹配算法的研究可以分为2个类别:基于CPU和基于GPU.基于CPU的串行算法由Ullmann[13]提出,使用基于深度优先搜索的策略,VF2[14]在此基础上利用结点间的连接性进行剪枝,VF3[15]改进VF2,由此出现更多的剪枝策略,如启发式确定匹配顺序、结点分类.为了降低候选集的规模,减少冗余的匹配,TurboISO[16]提出邻居等价类的概念.还有许多算法预先建立关于图的结构索引,以减少搜索空间和优化匹配顺序,如QuickSI[17]、GraphQL[18]、GADDI[19]等,这些算法的优化细节[20-21]各有不同,但基本思路都是通过增强候选集的过滤能力来提升算法的执行效率[22].
随着GPU相关技术的发展,研究者开始尝试寻求子图匹配在GPU上的并行解决方案.Tran等[23]提出GpSM,采用基于边的连接策略,利用生成树和非树结构2次过滤候选集以提升匹配效率.同样是以候选边为连接单元,GunrockSM[24]基于Gunrock[25]图计算平台, 采用广度优先的并行处理方式.不同于基于边的连接实现,Zeng等[26]提出的GPU友好子图匹配算法(GPU-friendly subgraph isomorphism algorithm,GSI)采用基于点的连接策略,并针对图的边标签设计数据结构以提升访存效率.Bonnici等[27]提出GRASS算法,采用混合广度优先和深度优先的方式,通过 GPU并行过滤候选集.汪洋等[28]提出多编码树结构,使生成的搜索空间树的尺寸减小.当前子图匹配算法在GPU上的实现主要由过滤和连接2个阶段组成.在过滤阶段,为每个查询图中的结点确定在数据图中可供匹配的候选集,GpSM利用生成树且分2步过滤候选集,并行性不高;GSI将邻边和邻接点的标签数量编码为签名以方便并行验证,但忽略了结点的所处局部的结构特征,过滤能力不强.在连接阶段,GpSM由候选点生成候选边,再基于候选边进行连接运算,但这样不能确定中间结果表的大小和写入地址,需要进行重复连接[23,26],占用大量线程资源且在时间上带来额外开销.
针对以上挑战和已有算法的不足,本研究提出基于GPU的子图匹配算法GpSI,对过滤和连接的2阶段模型进行优化.过滤阶段,综合考虑结点局部的数量特征和结构特征,将这些特征编码生成结点签名,利用GPU并行验证,高效过滤候选集;连接阶段,采用基于候选点的连接策略[26],预分配空间并设计高效的集合运算以避免边连接策略因重复连接带来的额外时空开销.通过在真实数据集与合成数据集上的多个算法对比实验来证明GpSI的优越性.
1 预备知识
1.1 子图匹配
定义:子图匹配.给定查询图Q={Vq,Eq,Lq},数据图G={Vg,Eg,Lg},其中Vq、Vg为图的结点集合,Eq、Eg为边集合,Lq、Lg为结点到标签的映射函数.在Q、G间存在单射函数f:Vq→Vg,使得
子图匹配算法要求枚举所有映射f.如图1所示,在查询图和数据图之间可以找到2个符合定义的匹配,分别为m0={(u0,v0),(u1,v2),(u2,v5)}、m1={(u0,v0),(u1,v3),(u2,v5)} ,其中A、B、C均为结点标签,ui、vi均为结点.
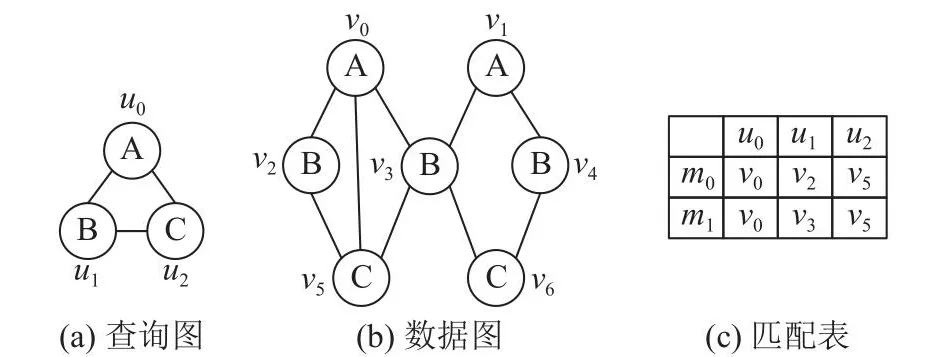
图1 子图匹配示例Fig.1 Example of subgraph matching
1.2 CUDA模型和GPU架构
CUDA由NVIDIA在2007年推出[29].在CUDA模型下,GPU的线程按组织粒度由大到小分为线程格(grid)、线程块(block)以及线程(thread),同一个线程块内每32个线程组织成线程束(warp),工作在单指令多线程(single instruction multiple threads, SIMT)模式下,是GPU最小的调度单元.GPU内部包含一组固定的流式多处理器(streaming multiprocessor, SM),线程块按一定策略被调度到处理器上执行.GPU内存被划分为多个层次和类型,各部分容量和访问延迟均有较大差异.其中最外层为全局内存(global memory),可供所有的线程访问,大小通常为GB级别,访问延迟在400~600个时间片;其次为每个线程块内的共享内存(shared memory),只能由块内线程访问,大小通常为48 KB,访问延迟为32个时间片;线程块内还设有L1缓存,特性与共享内存类似.GPU上内存总线读写全局内存和L1缓存每次都传输连续的128 B[30],因此对同一个线程束内的线程而言,访问一段连续的内存可以进行合并访存优化,显著降低访存频率从而降低访存延迟.
2 算法处理框架
如图2所示为GpSI的整体处理框架.GpSI按执行顺序可以大致分为过滤和连接2个阶段.过滤阶段,利用签名确定每个查询点的候选集;连接阶段,基于这些候选集迭代完成查询点的匹配,最后得出匹配结果.

图2 GpSI的框架Fig.2 Framework of GpSI
GpSI先进行过滤阶段的处理: 1)为输入的数据图和查询图中的每个结点生成签名,即一串编码结点局部特征的比特序列.2)利用签名进行候选集过滤,对每个查询点并行与所有数据点按一定规则进行签名验证.对某个查询点而言,在这一步可以剔除不可能匹配的数据点.过滤阶段完成即可确定每个查询点的候选集,以图1 (a)中u1为例,在经过过滤阶段的处理后,得到它在数据图中的候选集C(u1)={v2,v3}.在连接阶段,按一定顺序连接获得的候选集.采用基于候选点的连接策略,预分配空间,再在这些临时空间上进行集合运算,完成连接过程.连接阶段会产生一系列形如图1 (c)所示的匹配表,由于每次增量匹配1个查询点,新匹配表每次扩充1列,行数与集合运算后产生的结果数有关.当连接阶段完成,最后输出的匹配表即为结果,算法执行完毕.
3 过滤阶段
3.1 复合签名
假设在某个正确匹配中,数据点v是查询点u的匹配点,则除了结点标签一致外,u的局部特征也一定复现于v的局部特征中,这些特征包括局部的数量特征(如邻居数量)和结构特征.GpSI提出结点的复合签名对这些特征进行描述.结点的复合签名由数量签名和结构签名2个部分组成.先对结点的邻居按标签进行分类计数以生成数量签名.为了方便验证,采用哈希算法将邻居标签映射到不同的桶(buckets)进行统计:数量签名表现为比特序列,它被均分成若干个桶,邻居标签将被分别映射到这些桶内并编码计数.如图3所示为图1(b)中v0的数量签名.若桶大小为4,对于某个桶,无标签映射编码为0000,有1个映射编码为0001,2个映射编码为0011,3个映射编码为0111,4个及以上映射编码为1111.在具体实现中,桶的长度可依据输入的图数据信息进行调整.

图3 数量签名Fig.3 Quantity signature
仅利用数量签名不能反映结点的局部特征以及有效过滤候选集.结点和它不超过2跳区域的邻近点可能构成多种结构,如路径和三角形,使用结构签名记录这些结构,可以显著增强候选集的过滤能力.以图1(b)中的v0为例,图4中从v0出发,不超过2跳可以找到由标签组成的1条(A,B,A)路径,2条(A,C,B)路径,3条(A,B,C)路径以及2个标签三角形(A,B,C).如图5所示,结构签名包含若干个桶,被均分为路径签名和三角签名2个部分,对获得的标签序列进行与生成数量签名类似的操作,即对这些序列进行哈希,使之映射到相应的桶中进行编码计数.在结构签名中,各个桶内的编码方式和数量签名一致,如从v0出发的路径序列(A,B,C)出现3次,则对应桶内编码为0111.观察到序列的首位都是出发点的标签,这部分将单独验证,因此实现中可将首位省略,只对序列的后2位组合进行哈希计数即可.在标签三角形序列中,为了避免重复计数,同一个三角形序列严格按标签的次序只计数一次,例如图4中已记录三角形序列(A,B,C)则不再记录序列(A,C,B).算法1为某个结点u的复合签名生成过程.行2~3遍历结点u的邻居,生成数量签名;行4~8从点u出发进行1次不超过2跳的广度优先遍历,得到三角形和路径序列,生成对应的结构签名.

图4 结点的局部路径Fig.4 Local paths of vertex

图5 结构签名Fig.5 Structure signature
算法1生成复合签名
输入:结点u∈G输出:结点签名S(u)
1init(S(u));
2 for eachvinN(u):
3GenQuantitySig(v,S(u));
4 for eachvinN(u):
5 for eachwinN(v):
6 ifw∈N(u):
7GenTriangleSig(v,w,S(u));
8GenPathSig(v,w,S(u));
9 returnS(u);
如图6所示,复合签名由数量签名和结构签名2部分拼接而成.签名的空间占用小不仅能节省GPU的内存,使GPU处理更大规模的图,也能减少后续验证签名的用时.通常情况下,查询图中的结点标签均来自数据图,有|Lg|>|Lq|.为了保证统计的准确性,数量签名的桶数量应为|Lg|;结构签名中的路径和三角形序列都可由2个标签组成,考虑可能构成的组合数,桶数量应该分别为|Lg|2.当|Lg|>>|Lq|时,由于|Lq|一般不超过10,增加桶的个数带来的过滤能力增益有限,此时可以牺牲一定的准确性,基于|Lq|分配桶数量.一般来讲,数量签名的桶所占比特序列较长,偏向于记录数量;结构签名中桶的长度较短,偏向于记录种类.为了节省空间,以上所有类型的桶大小均支持依据图数据的统计信息进行动态调整.
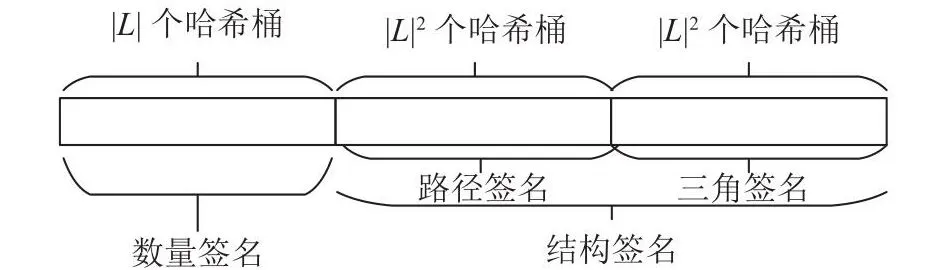
图6 复合签名Fig.6 Composite signature
3.2 候选集过滤
数据图和查询图的每个点的签名生成后,便可以利用这些签名进行候选集过滤.虽然复合签名分为若干部分,但过滤候选集采用统一的验证方法:比较各个桶内编码的数值大小,若v∈C(u),则S(u)的各个桶内数值应不大于S(v).为了方便GPU并行处理,采用按位与运算完成验证.可以推出,∀u∈Vq,v∈Vg;若v∈C(u),则
换言之,作为必要条件,若式(3)不成立,则v∉C(u),以此剔除无关的数据点,使得候选集的规模缩小.相较只考虑数量特征[26],综合利用结点局部的结构和数量特征的复合签名具有更强的过滤能力.以图1(a)中的u1为例,若只采用数量签名,则过滤阶段后C(u1)={v2,v3,v4},只有继续进行连接才能发现v4∉C(u1);若采用复合签名,则过滤阶段后即可确定C(u1)={v2,v3},后续连接阶段的任务量可以认为是各候选集大小的乘积.复合签名能有效地降低候选集规模,减少连接阶段任务量、提升整体性能,在面对大规模的图时优势明显.利用签名验证进行候选集过滤适于GPU并行处理,使用并行前缀和算法[30],时间复杂度为O(|Vq|lb|Vg|),其中|Vq|通常不超过10,时间开销较为理想.
4 连接阶段
按一定顺序连接查询点的候选集,便可得到最终的匹配结果,算法2为连接阶段的总流程.优先选取候选集规模|C(u)|最小的查询点加入部分匹配集Qp,M初始设为起始查询点的候选集;每轮选择与Qp相连且|C(u)|最小的未匹配点u′,调用join函数对M、C(u)进行连接以生成新匹配表M′;每次连接结束,更新M、Qp;当查询图结点全部匹配完成,返回M为结果,连接过程结束.
算法2基于候选点的连接
输入:查询图Q,数据图G
输出:匹配结果表M
1 partial matching query graphQp=Ø;
2 fori=1 to |Vq|:
3 ifi==1:
4u′=argminu|C(u)|;
5M=C(u′),Qp.add(u′);
6 else:
7u′=argminu{|C(u)||u∉Qp∧N(u)∩Qp!=Ø};
8 new matching tableM′=join(M,C(u′));
9M=M′,Qp.add(u′);
10 returnM;
如图7所示,新匹配表的生成是连接阶段的关键步骤.假定Qp={u0,u1}且部分匹配表为M1,须进行u2匹配,已知C(u2)={v5}.1)获得Qm=N(u2)∩Qp,即与u2相邻且已匹配的查询点集,为M1的每一行分配1个线程束(warp),在warpi中查询Qm在该行对应匹配的数据点,求得这些数据点邻居数量的最小值并记录下来,即sizei=min{|N(vj)||vj=mi[u′],u′∈Qm}.2)以sizei为粒度给warpi在全局预分配空间bufi.例如m0中符合条件的匹配点有m˜0={v0,v2},邻居集合中N(v2)规模最小,故以|N(v2)|预分配空间并将N(v2)载入buf0.在这些临时空间bufi上,warpi并行地进行集合运算.以warp0为例,进行N(v2)-m0(排除本行中已匹配数据点)、N(v2)∩C(u2)和N(v2)∩N(v0)等运算.3)将bufi中的结果和M1对应拼接,写入新匹配表M2,完成u2的匹配.重复上述过程直到所有查询点都完成匹配.
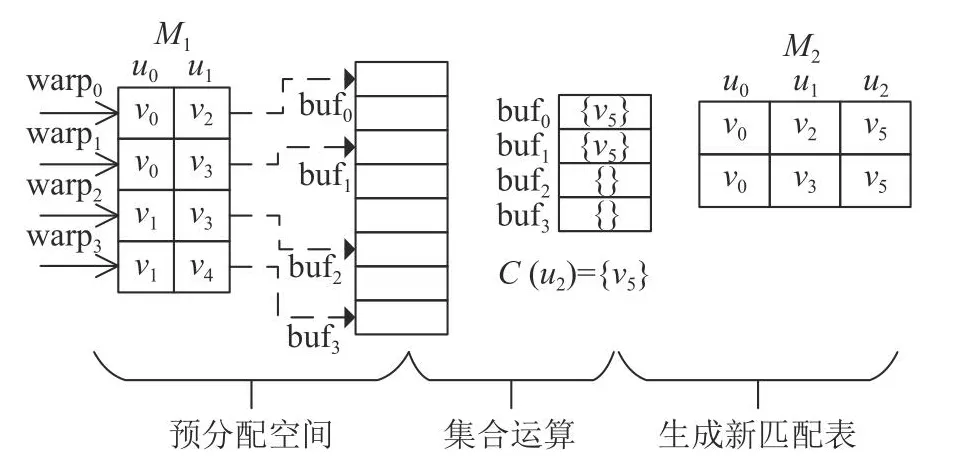
图7 生成新匹配表Fig.7 Generating new matching table
算法3为join 函数的执行过程,由于涉及的集合运算多,优化这些运算将加速整个算法的执行.行7中,由于mi的规模一般不超过10,可以考虑将其缓存至共享内存,直接遍历bufi去除mi中结点即可.行8中,由于C(u)一般规模较大且对所有线程共享,可以将其转换成位图,存于GPU的全局内存或常量内存中,这样不仅空间开销低,且O(1)时间即可判断某个结点是否属于C(u).行9~10是对m˜i中每个数据点的邻居求交集,该部分执行次数多且运算中涉及的集合规模通常比较大,暴力算法时间开销大,有必要进行优化.考虑到图在GPU上的存储结构.采用CSR(compressed sparse row)格式[31]进行存储.不同于传统的邻接表和邻接矩阵的图数据表现形式,CSR具有节省空间、存储结构对GPU友好的优点.使用CSR,O(1)时间即可定位到结点的邻接表,且邻接表都连续存储在一块区域,方便了线程的合并访存.
算法3join(M,C(u))
输入:匹配表M,候选集C(u)
输出:新匹配表M′
1Qm=N(u)∩Qp;
2 parallel allocate memory:
3m˜i={mi[u′]|u′∈Qm};
4vs=minargv{|N(v)||v∈m˜i};
5bufi=N(vs);
6 parallel set operation:
7bufi=bufi-mi;
8bufi=bufi∩C(u);
9 for eachvjinm˜iexceptvs:
10bufi=bufi∩N(vj);
11 allocate memory for new matching tableM′;
12 parallel link process:
13 linkmiwith bufi,write toM′;
14 returnM′;
为了优化交集运算,生成CSR时对邻接表进行预处理,将每个邻接表内结点按编号从小到大的顺序进行排列,以便二分查找使交集运算时间复杂度显著降低.如图8所示,N(vs)被初始加载到bufi中,在所有交集运算的邻居集合中,N(vs)的规模最小.在线程束并行处理下,即匹配表中的每一行各分配1个warp处理时,和1个邻居集合N(vj)求交集,迭代|N(vs)|/|warp|轮,其中|warp|=32.在每轮迭代中,同个warp内线程ti在N(vj)中进行二分查找,验证N(vs)中的结点是否在N(vj)出现.由于所有邻居集合的结点都是按编号有序存放的,当warp中相邻线程在进行二分查找时,访问过的结点在物理内存上有一定程度的邻近性,避免了随机访存,提升了访存效率.
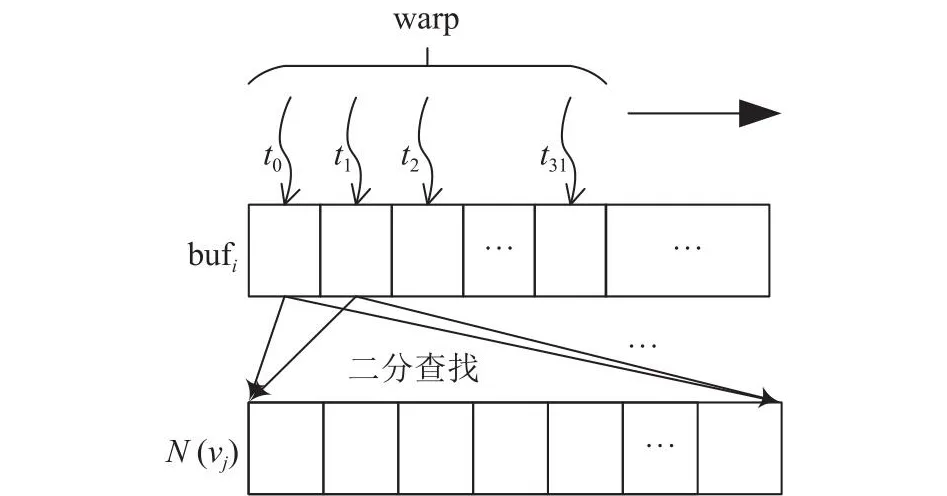
图8 交集运算Fig.8 Intersection operation
引理:给定整数序列3≤N1≤N2,N3,···,Nk(k≥2),给出整数序列1~k的排列π,那么∀π,仅当π[1]=1时取得最小值且最小值与无关.
证明:序列N1,N2,···,Nk已给定,则定值,对原式进行转化:Nπ[1]lb(F/Nπ[1]),其中N1≤Nπ[1]≤F/3.当Nπ[1]=N1即π[1]=1时,Nπ[1]lb(F/Nπ[1])取得最小值,且该最小值与π[2~k]无关,证毕.
时间复杂度的相关推导和证明过程中假定的是临时结果bufi不变,在具体实现中,算法3的行6~10每完成一次集合运算都会即时把不符合要求的数据点从bufi剔除,以降低临时结果规模,因此实际的时空复杂度都会更低.
负载不均衡不但会导致线程资源的浪费,而且会影响整体执行耗时.为此,结合GPU的线程模型,采用线程的三级调度策略[32],即在并行场景下,当任务量较大时,优先采用线程块执行;任务量中等时,使用线程束;若仍有剩余则使用线程并行处理.如算法3的行6~10,若32≤|N(vs)|<1024;优先采用线程束并行处理;1024≤|N(vs)|,优先采用线程块并行处理.行12~13也可以采用类似调度策略并行将结果写入新匹配表.
5 实验结果
对本研究提出的算法GpSI进行实验,并对比GPU上先进的算法GSI、基于边连接的算法GpSM和CPU上广泛使用的串行算法VF3.实验采用真实数据集和合成数据集进行测试.真实数据集来自斯坦福大规模网络数据集SNAP[33],包括脸书社交圈网络(facebook)、联邦能源委员会邮件通信网络(enron)、地理位置社交网络(gowalla)、DBLP协作网络(dblp)以及美国得州道路网(road),各数据集详细信息如表1所示.表中,MD为最大结点度数,NV为结点数,NE为边数.设置相关研究中普遍使用的3个查询图[34]进行实验,如图9所示.稳定性测试中,采用模型生成或随机游走的方式生成数据图、查询图以验证算法的鲁棒性.真实数据集上结点一般不带标签,因此预处理阶段进行随机设置,下文若不作特殊说明,数据图中结点标签种类均设定为5.算法代码均采用C++编写,使用CUDA Toolkit 10.9,操作系统为Ubuntu20.04.CPU为Intel i5-9400,GPU为NVIDIA GTX1650,显存4 GB,拥有896个流处理器,内存为DDR4 16 GB,SSD大小为512 GB.所有实验均重复10次,以平均值作为实验结果.算法输出经过Boost-VF2lib[35]提供的子图匹配算法程序的正确性验证.

表1 子图匹配实验的数据集信息Tab.1 Data set information of subgraph matching

图9 查询图Fig.9 Query graph
5.1 过滤能力测试
在GPU算法中只有GSI基于候选点进行连接,将GpSI与GSI进行候选集过滤能力的对比测试.连接阶段总是从候选集最小的查询点开始,因此以最小候选集的规模衡量过滤能力.使用查询图Q0作为输入,结果如表2所示.可以看出,复合签名过滤能力显著优于GSI,候选集规模更小.在过滤用时上GpSI也略占优势,主要原因是签名经过精心设计,空间占用比GSI少,减少了每个线程验证过程的循环次数.
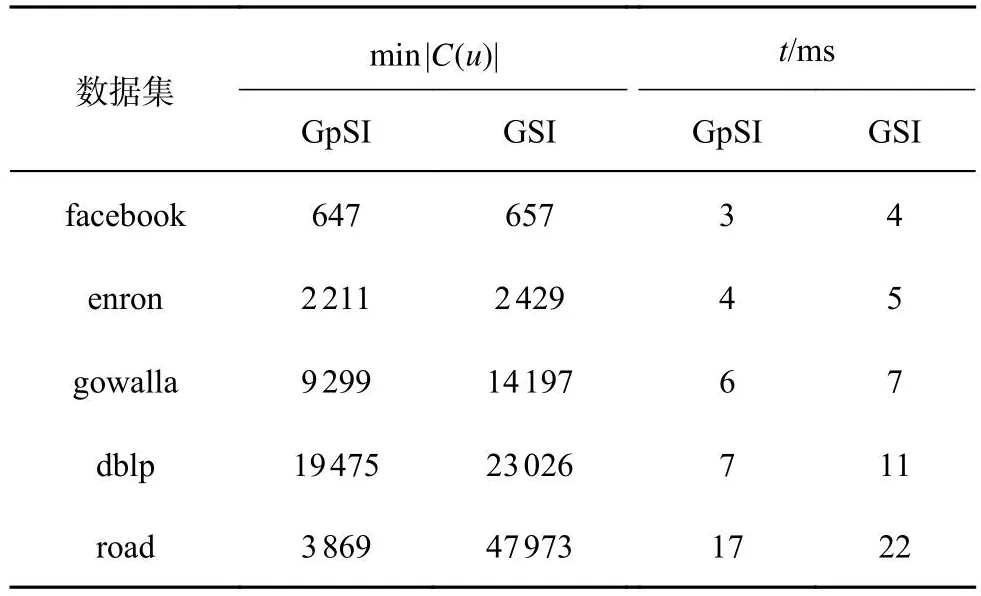
表2 2种算法在不同数据集上的过滤能力测试结果Tab.2 Filtering ability test results of two algorithms on different datasets
5.2 执行用时测试
如图10所示为GpSI与GSI、GpSM和VF3在各数据集和查询图下的总执行用时比较.VF3在查询图Q1、Q2下用时已远超GPU版本算法,故不再记录;Q2在数据图road中找不到匹配,也不作用时统计.实验结果表明,在总执行用时上,GpSI在所有测试数据集上均优于同类算法,其中比GSI加速了2~10倍,比GpSM加速了最高100倍.在查询图为Q0、Q1时,查询图的边数比较稀疏,复合签名充分挖掘查询点局部的数量和结构特征,使得GpSI相比GSI和GpSM加速明显.查询图Q2中的边比较稠密,基于候选边连接的GpSM性能有所提升,由于结点局部数量信息的增加,GSI的过滤能力也得到增强,但GpSI在执行用时上依然优势明显.得益于高效集合运算和三级调度策略,GpSI在真实世界的幂律图下表现出色.图10(a)中,当面对稀疏网格图(road)时,结点局部特征缺乏导致GpSM和GSI候选集过滤能力下降,总用时表现不如VF3,但GpSI的复合签名过滤策略使得候选集规模远小于同类算法,在总执行用时上仍然保持巨大优势.

图10 算法的执行用时对比Fig.10 Comparison of execution time for algorithms
5.3 GPU内存占用测试
为了测试算法的内存开销,进行GPU内存占用MGPU测试.以Q2作为查询图,记录各算法运行时的最大GPU内存占用,结果如图11所示.可以看出,GpSI的整体内存占用优于GSI、GpSM.得益于复合签名的高效过滤能力,GpSI的候选集与匹配表的规模比GSI和GpSM的小;复合签名经过精心设计,自身空间占用优于GSI;GpSI连接阶段以最小邻居数预分配空间的策略,使得生成新匹配表时产生的额外空间占用小于GSI.
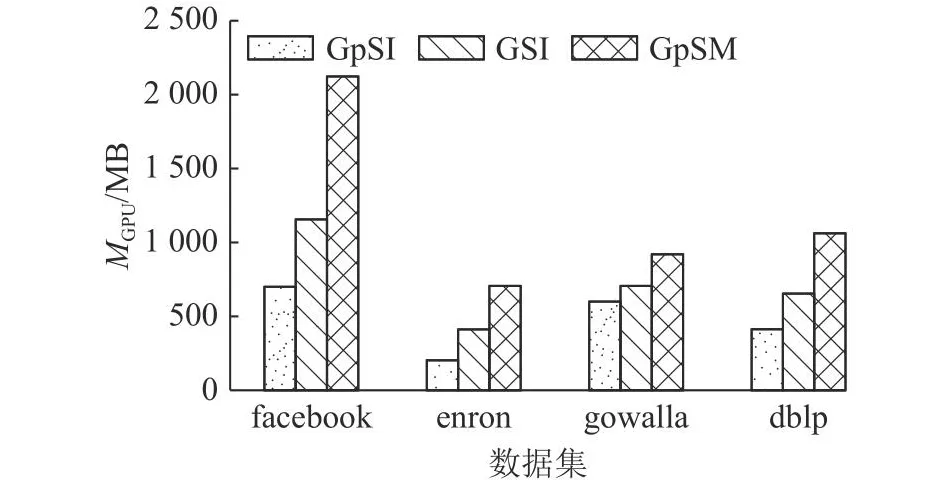
图11 算法的图形处理器内存占用对比Fig.11 Comparison of graphic processing unit memory consumption for algorithms
5.4 稳定性测试
为了测试GpSI的稳定性,记录算法随数据图和查询图规模增长时的总执行用时.数据图规模增长测试中,采用Erdős-Rényi模型[36]生成随机的数据图进行实验,初始时NV=5.0×104、NE=2.0×105,之后数据图规模线性递增直到NV=2.5×105、NE=1.0×106,查询图为Q0.在查询图规模增长测试中,使用Erdős-Rényi模型生成NV=1.0×105、NE=4.0×105的数据图,另随机生成若干查询图,限定查询图结点的平均度数为3,结点数由6递增到10,实验结果如图12所示,图中,NV,D为数据图结点数,NV,Q为查询图结点数.由于候选集和匹配表规模庞大,随着数据图规模的增长,GpSM耗时急剧增加,GpSI和GSI的执行用时都维持着线性增长.GpSI有高强的候选集过滤能力和高效的连接策略,在执行用时上始终优于GpSM和GSI,且对图数据规模的增长不敏感,稳定性最好.
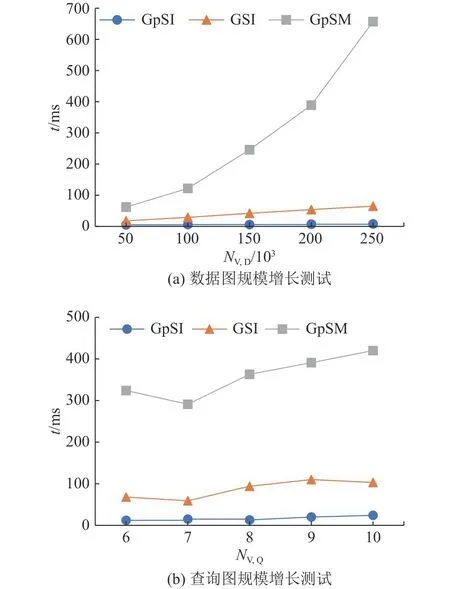
图12 3种算法的稳定性测试Fig.12 Scalability test of three algorithms
6 结 语
本研究提出GPU上的子图匹配算法GpSI,该算法采用过滤和连接的2阶段处理模型.在过滤阶段,充分利用结点的局部数量特征和结构特征设计复合签名,增强了候选集过滤能力.在连接阶段,采用基于候选点的连接策略,提出以最小邻居数为粒度的空间预分配方法,设计高效的集合运算,避免了传统方法带来的额外开销,提升了连接效率.针对图数据的不规则性,在实现上使用多种方式降低访存延迟和均衡线程负载.在未来研究中,计划面对更大规模的图开展基于多GPU的子图匹配算法的相关研究.
猜你喜欢
同济大学学报(自然科学版)(2019年2期)2019-04-02
数学物理学报(2018年1期)2018-03-26
环球市场(2017年36期)2017-03-09
电子科技大学学报(2016年2期)2016-08-31
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
电子设计工程(2014年12期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
吉林建筑大学学报(2012年3期)2012-08-15
采矿技术(2011年5期)2011-11-15
苏州市职业大学学报(2010年1期)2010-01-29
