
基于多级连续编码与解码的图像超分辨率重建算法
2023-10-08 02:28宋昭漾赵小强惠永永蒋红梅
浙江大学学报(工学版) 2023年9期
宋昭漾,赵小强,惠永永,蒋红梅
(1.兰州理工大学 电气工程与信息工程学院,甘肃 兰州 730050;2.甘肃省工业过程先进控制重点实验室,甘肃 兰州730050;3.兰州理工大学 国家级电气与控制工程实验教学中心,甘肃 兰州 730050)
图像超分辨率重建旨在从低分辨率(lowresolution, LR)图像中重建出一副对应的高分辨率(high-resolution, HR)图像, 是计算机视觉的重要分支[1-2], 在生活中具有广泛的应用场景[3-5].许多深度学习[6-8]的算法致力于通过构建更深或更宽的神经网络模型来学习LR图像和HR图像之间复杂的映射关系[9-12].
基于卷积神经网络的图像超分辨率重建算法(super-resolution convolutional neural network,SRCNN)[13]率先通过建立卷积神经网络来学习LR图像到HR图像的映射关系.虽然该算法较传统算法的性能有较大提升, 但是算法建立的神经网络模型结构比较简单(仅有3个卷积层), 导致该网络模型的学习性能有限.有研究者在卷积神经网络的基础上提出一系列基于神经网络的图像超分辨率重建算法, 如基于快速的卷积神经网络图像超分辨率重建算法(fast super-resolution convolutional neural network, FSRCNN)[14]和基于高效的亚像素卷积网络图像超分辨率重建算法(Efficient sub-pixel convolutional neural network,ESPCN)[15].虽然这些算法拥有较强的学习复杂映射关系的能力, 但是在训练过程中容易造成梯度爆炸.基于深度卷积网络的图像超分辨率重建算法(very deep convolution network super-resolution,VDSR)[16]在加深网络深度和扩大网络感受野的同时引入残差学习.基于递归神经网络的图像超分辨率重建算法(deeply-recursive convolutional network, DRCN)[17]在残差学习的基础上引入全局残差网络.基于增强的深度残差网络图像超分辨率重建算法(enhanced deep residual network for single image super-resolution, EDSR)[18]引入局部残差并去除了残差块中的批归一化层,能够构建更深的神经网络来学习复杂映射关系.基于密集跳线连接的图像超分辨率重建算法(super-resolution using dense network, SRDenseNet)[19]将密集连接网络应用于图像超分辨率重建, 有效抑制了梯度消失问题.基于残差密集网络的图像超分辨率重建算法(residual dense network, RDN)[20]在密集块的开头和结尾增加残差连接和卷积运算进行特征降维, 使模型具有更强的学习能力.这些算法同等对待图像的低、高频特征, 耗费了大量的计算量却未获得图像的深层特征.受深度神经网络蓬勃发展的影响, 有研究者提出用各种网络结构和学习机制来实现更好的图像重建性能.如1)基于深度残差通道注意力网络的图像超分辨率重建算法(residual channel attention network, RCAN)[21]引入通道注意机制来重点关注图像的高频特征并获得更好的性能, 2)基于注意力网络的注意力图像超分辨率图像算法(attention in attention network,A2N)[22]引入注意力丢失机制来动态调整注意力的权重.这些算法难以获取LR内部的多层次信息.
1 多级连续编码与解码网络
1.1 模型框架
如图1所示为多级连续编码与解码的图像超分辨率重建算法模型框架示意图.该模型框架主要由3个部分组成, 分别为初始特征提取操作、深度特征提取操作、上采样和重建操作.当LR图像输入该算法模型时, 1)由卷积核为3×3的卷积层进行初始特征提取:
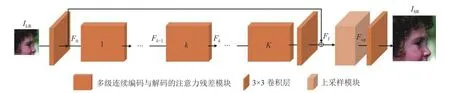
图1 多级连续编码与解码的图像超分辨率重建算法的模型框架Fig.1 Model framework of image super-resolution reconstruction algorithm based on multi-level continuous encoding and decoding
式中:ILR为低分辨率图像,F0为获得的LR图像初始特征,C3为卷积核为3×3的卷积层运算.该卷积层的输入通道数为3, 输出通道为64.2)浅层特征由K个端对端连接的多级连续编码与解码的注意力残差模块进行深度特征提取, 提取的深度特征由卷积核为3×3的中间卷积层进行融合:
式中:H1、HK分别为第1个和第K个多级连续编码与解码的注意力残差模块运算,Ff为提取到的深度特征.中间卷积层的输入通道和输出通道都为64.3)LR图像的初始特征和深度特征通过全局残差连接结合在一起, 由上采样模块和重建卷积层组合模块进行上采样和重建:
式中:Hup为上采样模块的运算,ISR为重建的SR图像,Fup为上采样的特征.重建卷积层的输入通道数为64, 输出通道数为3.本研究使用的上采样模块为亚像素卷积层.
1.2 连续编码与解码
图像内部特征信息比较复杂且有连续相关性, 为此在编码与解码模型的基础上构建连续编码与解码模型, 对比示意图如图2所示.

图2 2种编码与解码模型的对比示意图Fig.2 Comparison diagram of two encoding and decoding models
假设基于编码与解码模型的输入为x, 输出为y, 运算式为
式中:HEn为编码器的运算,HDe为解码器的运算.式(5)表示大小为H×W×C的输入特征x经过编码器的运算变成大小为H×W×C/r的特征, 该特征经过解码器的运算恢复成大小为H×W×C的图像特征,其中r为压缩系数.
原题:The 2011 MW9.0Tohoku earthquake:Comparison of GPS and strong-motion data
连续编码与解码模型不仅通过多个编码器对大小为H×W×C/r的特征进行连续编码和解码,还在相邻的编码器之间增加残差块来避免在连续编码过程中信息丢失;同样地, 该模型在相邻的解码器之间增加残差块来避免在连续解码过程中信息恢复不充分.连续编码与解码模型的运算式为
式中:HE1n、HEnn分别为连续编码器中第1个编码器和第n个编码器的运算,HD1e、HDne表示连续解码器中第1个解码器和第n个解码器的运算,HRes为残差块的运算.式(6)表示大小为H×W×C的输入特征x经过多个连续的编码器和残差块的组合模块运算得到大小为H×W×C/rk的特征, 该特征经过多个连续的编码器和残差块的组合模块运算得到大小为H×W×C/r的最终的编码特征;对称地,得到的编码特征经过多个解码器和残差块的组合模块运算恢复成大小为H×W×C/rk的特征, 该特征经过多个连续的解码器和残差块的组合运算恢复成大小为H×W×C的图像特征.
1.3 多级连续编码与解码
图像的像素级信息分为多个层次, 有容易重建的特征信息(如图像轮廓), 有难以重建的特征信息(如图像内部纹理和边缘),为此在连续编码与解码模型的基础上设计如图3所示的多级连续编码与解码模型.该模型由3个不同层级的编码与解码块组成, 能够分别获取不同层级的图像特征信息, 该模型中第1层级的编码与解码块进行图像浅层的、容易提取的特征提取, 第2层级的连续编码与解码块进行复杂的图像特征提取, 第3层级的连续编码与解码块进行深层的、难以提取的图像特征提取.具体来说, 第1层级的编码与解码块通过编码器先对特征进行编码, 再用解码器对编码的特征进行解码来获得特征:

图3 多级连续编码与解码模型示意图Fig.3 Schematic diagram of multi-level continuous encoding and decoding model
1.4 多级连续编码与解码的注意力残差模块
多级连续编码与解码模型的输出包括图像内部的浅层特征、复杂特征和深层特征, 其中浅层特征容易提取且需要的计算量较小, 深层特征难以提取并需要的计算量较大.如果在提取图像内部的特征时平等地对待这些特征, 则会消耗很大的计算量.在有限的计算量情况下, 为了合理分配计算量并尽可能地提取到图像内部的丰富特征, 设计如图4所示的多级连续编码与解码的注意力残差模块.该模块在多级连续编码与解码模型的基础上, 对3个层级的解码特征进行注意力运算.具体来说, 该模块1)对3个层级的解码特征进行级联运算, 并用1×1卷积层进行融合:
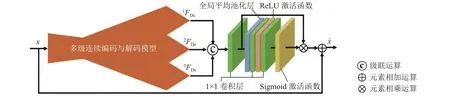
图4 多级连续编码与解码的注意力残差模块结构示意图Fig.4 Schematic diagram of attention residual module structure of multi-level continuous encoding and decoding
式中:Concat(·)为级联运算,C1为卷积核为1×1的卷积层运算,FDe为融合后的解码特征.2)对融合后的解码特征进行注意力运算,包括挤压、激励和重新校准操作3个过程.挤压操作是通过全局平均池化层将融合后的解码特征压缩到通道描述符zc中 :
式中:W11、W12分别为2个1×1卷积层的不同权重,δ为ReLU激活函数的运算,σ为Sigmoid激活函数的运算.重新校准操作是通过乘法重新校准解码特征中包含的浅层特征、复杂特征和深层特征的权重:
式中:为校准后的解码特征.3)通过局部残差连接将输入的图像特征与校准后的解码特征结合, 更新后的图像特征为
2 实验结果与分析
2.1 实验设备
深度学习框架为Pytorch0.4, 编程语言为Python3.6, 训练和测试使用的平台为Ubuntu18.04,CPU为Inter i9-9900 K, 内存为64 G, 使用的GPU为RTX 2080 Ti, 显存为11 G.
2.2 实验数据集
训练集为DIV2K[23]数据集, 该数据集包含800张高清的HR图像, 100张验证图像和100张测试图像.使用Bicubic算法处理HR图像, 生成对应的放大倍数分别为2、3、4的LR图像.为了扩展数据集, 先对HR图像和不同放大倍数下的LR图像按照旋转角度分别为90°、180°、270°进行旋转, 再按照比例系数分别为0.6、0.7、0.8、0.9进行缩放, 最后对这些图像进行裁剪.
测试集为Set5[24]、Set14[25]、BSD100[26]和Urban100[27]数据集, 分别包含5、14、100、100张不同风格的图像(如人像、动物、风景、建筑物等).使用Bicubic算法生成和HR图像对应的放大倍数分别为2、3、4的LR图像.
2.3 训练和测试细节
所提算法在深度特征提取中使用64个多级连续编码与解码的注意力残差模块.本研究使用的损失函数为L1损失函数,使用Adam[28]优化算法对损失函数进行优化.网络训练过程中设置的批次大小为16, 迭代轮次epoch=1 000, 学习率初始为0.000 1;epoch每隔200,学习率降为原来的一半.所提算法在测试过程中使用的性能评价指标为峰值信噪比(peak signal to noise ratio, PSNR)和结构相似度[29](structural similarity index, SSIM), 在YCbCr通道中的Y通道进行测试图像性能测试.
2.4 实验结果与分析
将主流的7种算法(Bicubic、SRCNN[13]、FSRCNN[14]、VDSR[16]、DBPN[30]、RFDN[31]和A2N[22])与所提算法进行算法性能的对比测试.分别在放大倍数为2、3和4的情况下,使用不同算法测试Set5、Set14、BSD100和Urban100数据集, 测试结果如表1~3所示.相比主流算法, 在放大倍数为2、3的情况下,所提算法测试4个数据集的性能评价指标均为最优, 实现了PSNR、SSIM的较大提升.相比主流算法, 在放大倍数为4的情况下,所提算法测试Urban100数据集的性能评价指标最优.具体来说, 对于测试集Set5、Set14、BSD100、Urban100,当放大倍数为2时, 所提算法获得的PSNR比DBPN算法获得的次优PSNR分别提升0.08、0.09、0.01、0.19 dB;当放大倍数为3时, 所提算法获得的PSNR比A2N算法获得的次优PSNR分别提升0.11、0.07、0.06、0.25 dB.当放大倍数为4时,对于Urban100测试集, 所提算法获得的PSNR比DBPN算法获得的次优PSNR值提升0.03 dB;当放大倍数为2、4时, 所提算法获得的SSIM比DBPN算法获得的次优SSIM分别提升0.001 8、0.002 8;当放大倍数为3时, 所提算法获得的SSIM比A2N算法获得的次优SSIM提升0.006 4.所提算法在特征提取过程中通过多级连续编码与解码的注意力残差块,获取不同层级的图像特征信息, 为不同层级的图像特征信息分配不同计算量的权重, 能够尽可能多地获得图像内部丰富的细节特征, 因此相比7种主流算法, 所提算法具有较好的超分辨率重建性能, 能够实现PSNR、SSIM的较大提升.
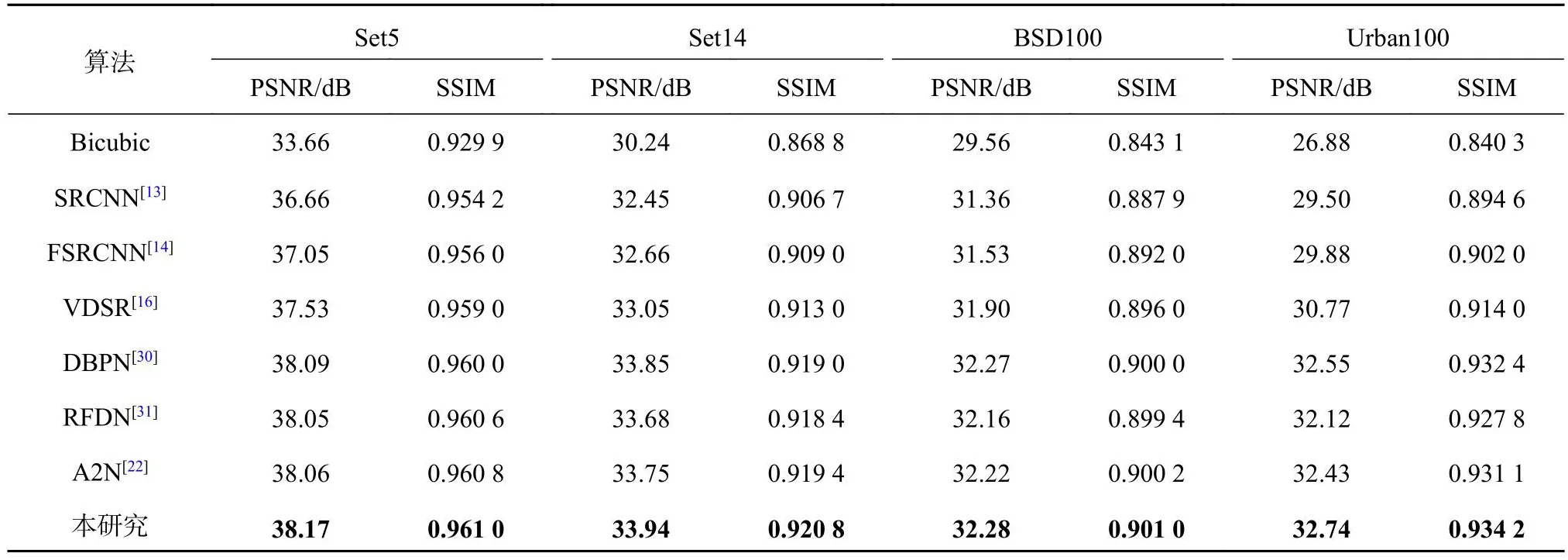
表1 不同图像重建算法在4个测试集上的性能评价指标(放大倍数为2)Tab.1 Performance evaluation indicators of different image resolution algorithms on four test sets (magnification is 2)
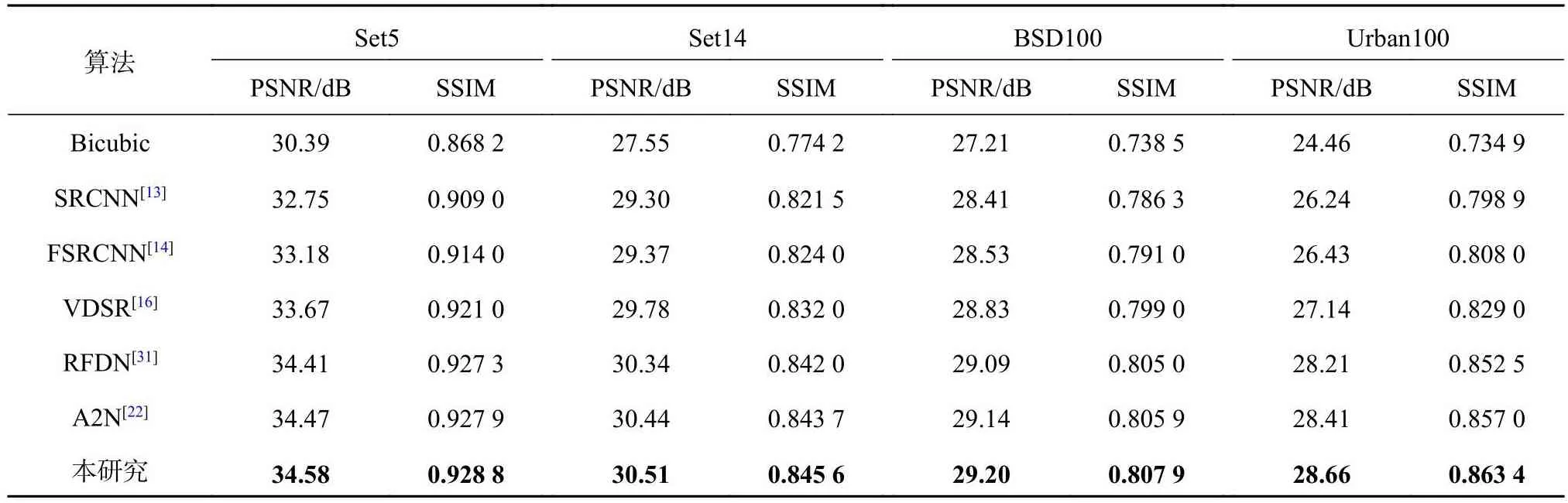
表2 不同图像重建算法在4个测试集上的性能评价指标(放大倍数为3)Tab.2 Performance evaluation indicators of different image resolution algorithms on four test sets (magnification is 3)

表3 不同图像重建算法在4个测试集上的性能评价指标(放大倍数为4)Tab.3 Performance evaluation indicators of different image resolution algorithms on four test sets (magnification is 4)
为了测试所提算法的重建图像的视觉效果,在放大倍数为4的情况下对Urban100测试集中的3张图像(img004、img061和img096)进行不同算法的对比测试, 对比测试的视觉效果图如图5~7所示.图5中, Bicubic、SRCNN、FSRCNN和VDSR算法图像重建的小孔存在模糊问题, DBPN、RFDN和A2N算法图像重建的小孔存在严重的变形问题(如DBPN算法图像重建的小孔存在变小和变圆问题, RFDN、A2N算法图像重建的小孔存在变弯问题), 所提算法图像重建的小孔基本保持了原形状.图6中, Bicubic、SRCNN、和FSRCNN算法图像重建的楼层存在严重的模糊问题,VDSR算法图像重建的高楼层存在严重的变形问题, DBPN、RFDN和A2N算法图像重建的楼层存在严重的锐化问题, 所提算法图像重建的楼层存在轻微的锐化问题, 不存在变形问题.图7中,Bicubic、SRCNN、FSRCNN和VDSR算法图像重建的大楼外侧竖条出现严重的模糊不清问题,DBPN、RFDN和A2N算法图像重建的大楼外右侧竖条存在较严重的模糊问题, 重建的大楼外左侧竖条存在轻微的扭曲问题, 所提算法图像重建的大楼外侧基本没有模糊问题和扭曲问题.综上所述, 所提算法相比主流算法不仅在性能测试指标方面实现较大提升, 而且在重建图像的细节方面也具体较好的视觉效果.

图5 不同图像重建算法重建的img004对比图像(放大倍数为4)Fig.5 Comparison images of img004 reconstructed by different image resolution algorithms (magnification is 4)

图6 不同图像重建算法重建的img061对比图像(放大倍数为4)Fig.6 Comparison images of img061 reconstructed by different image resolution algorithms (magnification is 4)

图7 不同图像重建算法重建的img096对比图像(放大倍数为4)Fig.7 Comparison images of img096 reconstructed by different image resolution algorithms (magnification is 4)
2.5 多级连续编码与解码的注意力残差模块分析
假设ED1、ED2、ED3分别为第1、2、3层级的连续编码与解码块,Attention为注意力残差块.在放大倍数为4的情况下,使用DIV2K数据集分别训练由上述4个模块排列组合成的网络, 并在Set5测试集上进行测试, PSNR 如表4所示.可以看出, 多级连续编码与解码的注意力残差模块能够获得最高的PSNR.原因是只使用ED1、ED2、ED3模块的网络模型只能够获取到图像局部单一的特征, 组合使用3个模块的网络模型能够获得多层级的浅层特征、复杂特征和深层特征.在此基础上, 结合Attention模块, 为获得图像内部多层级的浅层特征、复杂特征和深层特征分配不同的计算量权重, 能够尽可能地提取到图像内部丰富的细节特征.

表4 多级连续编码与解码的注意力残差模块消融研究结果(放大倍数为4)Tab.4 Ablation study results of attention residual module based on multi-level continuous encoding and decoding(magnification is 4)
2.6 模型分析
使用所提算法与SRCNN、FSRCNN、VDSR、DBPN、RFDN和A2N算法在放大倍数为4的Urban100测试集中分别进行参数量n与运行时间t对比, 结果如图8所示.相比DBPN算法,所提算法不仅参数量少, 还实现了PSNR的提升;相比A2N、RFDN、VDSR、FSRCNN和SRCNN算法, 所提算法虽然参数量较多, 但是实现了PSNR的大提升.所提算法的运行时间比DBPN算法的运行时间少, 且近似于A2N算法的运行时间.综上所述, 所提算法的网络模型在实现PSNR提升的同时参数量和运行时间均较少.
3 结 语
本研究提出多级连续编码与解码的图像超分辨率重建算法.所提算法通过多级连续编码与解码的注意力残差模块从低分辨率图像中提取不同层级的特征信息, 并对这些不同层级的特征信息生成不同的权重(给浅层特征分布较小的权重,给深度特征分布较大的权重), 尽可能地提取到图像内部的丰富特征.实验结果表明, 在放大倍数为2、3、4的测试集(Set5、Set14、BSD100和Urban100)上, 相比主流算法, 所提算法能够实现峰值信噪比值和结构相似度值的较大提升, 同时使用所提算法重建的高分辨率图像更清晰且包含更多的细节信息.实际应用中往往需要进行任意倍数的图像超分辨率重建,因此,在未来的研究工作中,计划在所提算法的基础上进行任意倍数的图像超分辨率重建算法研究.
猜你喜欢
小学生学习指导(低年级)(2023年4期)2023-05-09
小学生学习指导(中年级)(2022年9期)2022-09-30
中国石油石化(2022年12期)2022-07-16
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
中国外汇(2019年19期)2019-11-26
自动化学报(2019年6期)2019-07-23
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
新高考·英语进阶(高二高三)(2016年4期)2016-09-19
