
一种基于VMD-PSO-LSTM 的血糖预测方法*
2023-09-29 05:52丁国荣王文波
计算机与数字工程 2023年6期
童 梦 丁国荣 余 楠 王文波
(武汉科技大学理学院 武汉 430065)
1 引言
随着生活条件和水平提高,糖尿病患者的年龄越来越小,尤其在发展中国家影响越来越广泛,糖尿病也是引发死亡的主要原因[1]。从国际糖尿病联盟(IDF)发布的消息来看,2017 年我国糖尿病患者人数已达1.14 亿,居世界首位。到2019 年,国内糖尿病患者出现局部年轻化,人数增至4 亿。目前主要通过血糖浓度来判断是否患糖尿病,根据预测的血糖可以提前改变胰岛素注射量或者通过改变运动量以及饮食等尽量避免异常血糖值的出现,使血糖浓度处于正常。
国内外学者提出各种方法来预测血糖浓度。Daskalaki等[2]运用机器学习的血糖预测方法,使用递归神经网络(RNN)的血糖和胰岛素信息,其模型优于自回归(AR)模型和使用外部胰岛素输入的AR模型(ARX);Orieke等[3]提出了一种神经模糊模型,利用胰岛素和膳食效应联合预测Ⅰ型糖尿病患者的血糖水平。Orieke对模型的误差网格分析显示87.5%的预测落在了A 区域,而剩下的12.5%的预测落在了4h 预测窗口内的B 区域。Yang Jun 等[4]提出了自回归综合移动平均模型(ARIMA),该模型采用了模型阶数的自适应识别算法。该辨识算法采用Akaike信息准则和最小二乘估计,自适应地确定模型的阶数,同时估计出相应的参数。结果表明,该模型优于自适应单变量模型和ARIMA 模型。血糖预测时间的延长,可以为医生和患者提供充足时间进行血糖浓度控制,提高糖尿病治疗的效果。目前长短时记忆网络在时间序列预测方面的效果较为良好,现已应用于预测股票价格、电力负荷预测、海洋表面温度或者学习的生理模型血糖行为等。LSTM可以比其他网络学习的更迅速和解决过去没有用前反馈网络算法解决的困难问题。成骁彬[5]提出了经验模态分解与层叠式长短期记忆算法相结的模型,并运用该模型对短时风速进行预测。
由于血糖数据通常是非线性、非平稳的数据,通常需要对血糖数据进行预处理来降低其非平稳性。血糖预测方法有基于数据驱动的、生理模型的和结合数据和生理的预测方法,运用不同方法各有其优点和缺点。现阶段已有许多预测方法出现在血糖浓度序列预测比如灰度预测[6]、径向基函数预测[7]、ARIMA预测、神经网络预测、支持向量机预测等,同时运用群体智能优化算法对预测模型参数进行优化,主要有粒子群算法、遗传算法、蚁群算法、人工蜂群算法[8]、花朵授粉算法[9]和烟花算法[10]等。本文选取的是粒子群算法对LSTM 进行结构参数的优化。
本文结合上述文献,针对血糖信号的特点,对血糖信号进行多尺度分解降低其非线性以及非平稳性的特点,提出一种基于变分模态分解和经粒子群优化长短时记忆网络的血糖浓度序列预测模型(VMD-PSO-LSTM)。
2 基本原理
2.1 变分模态分解
变分模态分解(Variational Mode Decomposition,VMD)是由Dragomiretskiy 等在2014 年提出,VMD 是一种将信号分解转化成为变分分解的模式,其分解的核心思想是构建和求解变分问题,对非平稳、非线性的信号有较好的效果[11~12]。
假设原始信号f是由K个固有模态分量(IMF)uk(t)组成。
式(1)中,相位φk(t)是不减函数;Ak(t)表示包络函数。
设各IMF 的中心频率是ωk,以各IMF 的和等于原始信号作为约束条件时,变分模态分解的分解过程步骤如下。
首先对各个IMF进行希尔伯特变换,并且得出uk(t)的解析信号,通过单边谱将uk(t)的中心频带调制到相应的基频带上,可以通过乘以实现:
然后估计出各模态函数的带宽,通过计算解调信号梯度的L2范数实现,最终将原问题变成求解有约束的变分问题,如式(3)。
其中K是将原信号分解成为K个IMF,δ(t)为狄拉克函数,*为卷积运算符。
通过引入Lagrange 乘法算子λ(t)和二次惩罚因子α的方法来求解上述有约束的变分问题的最优解,将原问题转化为无约束变分问题。
最后,将上述问题运用乘子交替方向算法进行求解,通过求解得到的无约束模型的解,而原问题与它的无约束模型问题同解,由式(5)得到所有的IMF。
(ω)是通过当前剩余量进行Wiener 滤波器处理得到,中心频率通过算法各分量功率谱的重心进行重新估计,并通过式(6)更新。
2.2 粒子群算法
粒子群算法(Particle Swarm Optimization,PSO)是一种模拟鸟群觅食的进化算法,是由J.Kennedy和R. C. Eberhart 等开发的。PSO 是从初始的随机解开始,通过不断迭代寻找最优解,运用适应度函数来评价解的好坏。不断更新局部最优和全局最优,最终到达停止条件的出求得的最优解。PSO 首先初始化得到一组随机解,然后迭代不断搜索当前空间最优的粒子,最终获取最优解的过程。
在多维搜索空间中,如果一个群体是以m个粒子组成,在第t次迭代中,第i个粒子的位置和速度分别为Xi,t和Vi,t,粒子通过监督个体最优和全局最优这两个最优解来更新自己的位置和速度。在找寻这两个最优解的过程中。
粒子通过式(7)来更新下一时刻速度,通过式(8)来更新t+1时刻位置:
式(7)中:w为速度惯性因子;c1和c2为学习因子;rand 为[0,1]之间的随机数;式(8)中λ为速度系数,本文取0.5。Vi,t被最大速度Vmax和最小速度Vmin限制。
2.3 长短期记忆网络
由于循环神经网络(RNN)容易出现梯度消失或者梯度爆炸的现象,存在着长期依赖关系,因此提出一种特殊的RNN,长短期记忆网络(Long Short-Term Memory Networks,LSTM)。与RNN 相同,长短期记忆网路也是一种重复神经网络模块的链式形式[13]。在RNN 的基础上,长短期记忆网络的核心思想就是增加了一个单元状态C(Cell state),并且通过输入们和遗忘门这两个门来控制单元状态C。LSTM的结构如图1所示。单个LSTM主要包括以下几个步骤。
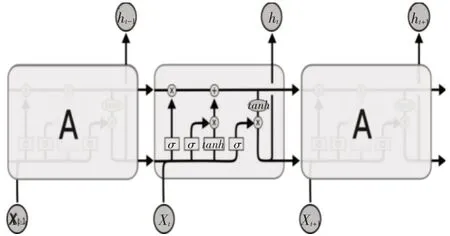
图1 LSTM的结构图
首先遗忘门计算公式如式(9)所示。
其次对输入门来说,确定的是更新的信息,计算式(10)、(11)所示。
更新从t-1 时刻到t时刻的细胞的状态的计算公式为式(12)。
最后一步是这一层网络的输出信息,LSTM 最终预测结果的输出ht,是由输出门和单元状态共同确定。计算公式如式(13)以及式(14)。
2.4 性能评价指标
为了更好的评价和比较各个模型预测的结果,本文选取平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squared Error,RMSE)和克拉克误差网格分析法(Clarke Error Grid Analysis,CEGA)作为性能评价指标,各个评价指标的计算方法如下:
克拉克误差网格分析法利用笛卡尔图来评价血糖预测方法的准确度。CEGA中横纵坐标轴都是[0,400],分为如图2所示的A、B、C、D、E五个区域。
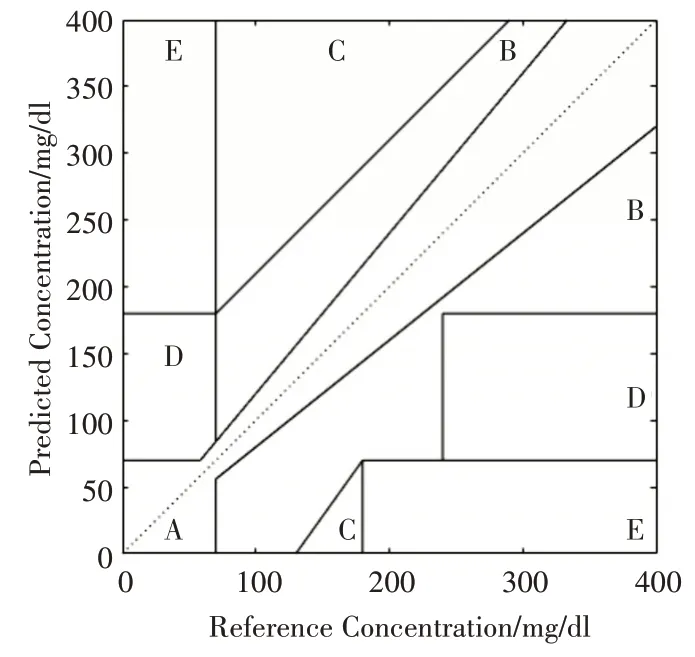
图2 克拉克网格分析
在克拉克网格分析中,预测效果较好的点位于A区域,其次落在B区域,在临床上落在区域A和区域B 是可以接受的预测值,预测效果最差的点落在E区域。
3 本文模型
由于血糖信号的特点,一般的预测方法难以提高血糖浓度的预测精度以及模型的准确性[14~15]。根据前文提出的方法,本节在此基础上进行改进,基于变分模态分解方法对非平稳血糖时间序列信号进行处理以及PSO 算法对LSTM 结构参数的优化,本文提出一种基于VMD 和PSO-LSTM 的血糖浓度预测模型。
基于VMD-PSO-LSTM的血糖浓度预测流程如下:
1)获取血糖浓度序列。利用CGM 连续采集糖尿病患者的血糖序列。
2)基于VMD 方法将血糖序列分解成5 个相对平稳的IMF分量{IMF1,…,IMF5} 。
3)分别对各固有模态分量分别建立PSO-LSTM预测模型。对患者血糖值序列的第i个固有模态函数IMFi,通过粒子群算法对LSTM 参数寻优,利用优化后的LSTM 对IMFi进行预测,获得各分量的预测结果。
4)患者血糖最终预测值等于PSO-LSTM 模型预测得到各分量预测值的和。
5)将VMD-PSO-LSTM预测值分别与实际值和其他预测模型进行对比,通过本文提出的性能评价指标分析验证所提方法的精确性。
VMD-PSO-LSTM 预测血糖浓度的流程图如图3所示。
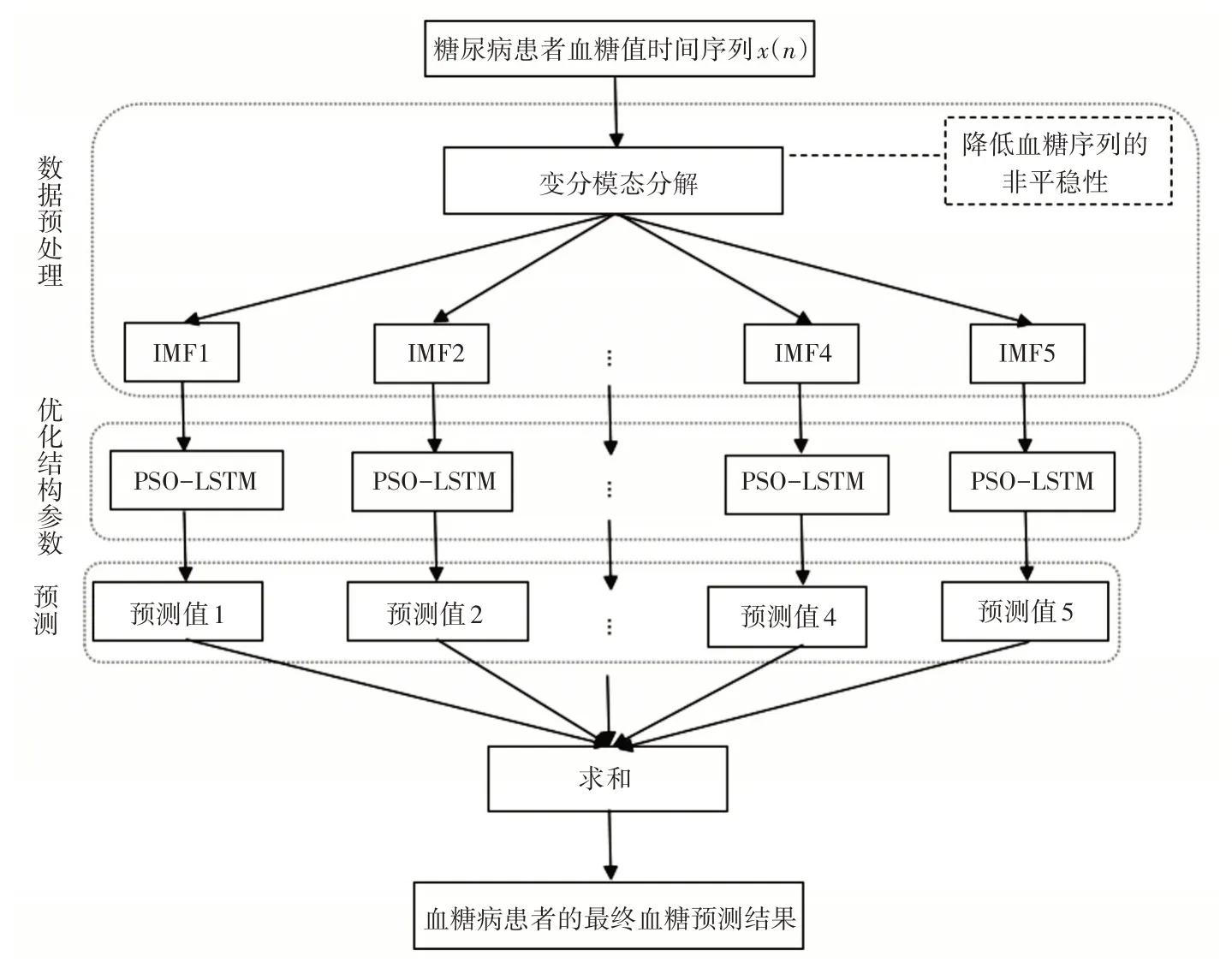
图3 VMD-PSO-LSTM流程图
4 实证分析
在实验中,利用VMD 对血糖序列进行5 层分解。PSO-LSTM 模型结构由输入层、隐藏层和输出层组成,本文选取的损失函数为预测的均方误差。LSTM 的内部参数采用Adam 算法进行训练,训练次数设置为200 次,训练目标取0.0001,该模型将隐藏层神经元数,LSTM 的时间窗口大小设置为LSTM网络模型超参数运用粒子群算法进行优化。
为了减少人为因素对模型的影响,根据血糖序列的具体情况,对超参数的取值范围设置如下:指定隐藏层单元个数取值范围[1,300],时间窗口大小取值范围[1,30]。同时设置粒子群粒子个数为30,最大迭代次数取值为30,学习因子c1=c2=2。速度惯性因子w=0.8,速度系数λ=1。适应度函数选取的是LSTM网络的均方误差。
为了更好地验证本文所提方法的有效性,本文将PSO-LSTM 和VMD-LSTM 预测模型对同样的血糖浓度时间序列数据进行预测,各个模型的预测对比图结果如图4,预测误差对比图如图5所示。

图4 各个模型的预测结果对比图

图5 各个模型的预测误差对比图
在克拉克网格误差分析中,对各个模型运用相对误差大小进行校验相对误差大小,其计算需要用到测量真实值和预测值,该方法是一种通过直观的比较每个点来实现的检验方法。根据本文的研究,它通过比较的就是各个时刻患者血糖的预测值和它的真实值之间的误差。 血糖预测VMD-PSO-LSTM 模型的相对误差为ε(i),计算方法如式(17)。
则平均相对误差计算公式如式(18):
模型的预测精度为p,且p=(1-)×100%
各个预测模型的评价指标对比如表1。

表1 各个预测模型的评价指标
实验结果显示,本文所提方法的MAE和RMSE的均小于PSO-LSTM 和VMD-LSTM 模型的误差,预测精度高于PSO-LSTM 和VMD-LSTM 模型的预测精度,证明了本文方法能够很好地预测血糖浓度时间序列,是一种比较好的预测模型。
5 结语
本文针对血糖浓度序列的特点,提出一种VMD 与PSO 优化LSTM 相结合的短期血糖浓度预测模型。首先利用VMD 方法将通过CGMS 获取的患者的血糖浓度时间序列分解成5 个固有模态函数,从而降低血糖时间序列的非线性和非平稳性;然后对各个IMF分量分别用经PSO优化的LSTM模型来预测,最后将预测后的各子序列叠加得到最终预测结果。
通过实验对比PSO-LSTM 和VMD-LSTM 方法,结果表明:VMD-PSO-LSTM 的平均绝对误差和均方误差都最小,并且所有的点都落在克拉克网格的A 区域,预测精度最高,证明了本文所提出的方法是一种比较好的预测模型。
猜你喜欢
数学杂志(2020年3期)2020-07-25
数学物理学报(2019年6期)2020-01-13
测控技术(2018年10期)2018-11-25
数学物理学报(2017年6期)2018-01-22
浙江工业大学学报(2017年5期)2018-01-22
数学物理学报(2016年3期)2016-12-01
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
物理与工程(2014年4期)2014-02-27
