
基于ASBC 模型的藏文自动分词方法研究*
2023-09-29 05:51尹宗鹤尼玛次仁
计算机与数字工程 2023年6期
尹宗鹤 尼玛次仁 于 韬 拥 措
(1.西藏大学信息科学技术学院 拉萨 850000)(2.西藏大学藏文信息技术教育部工程研究中心 拉萨 850000)(3.西藏自治区藏文信息技术人工智能重点实验室 拉萨 850000)
1 引言
1999 年,扎西次仁设计一个人机互助的藏文分词和词登录系统,可以看作藏文分词研究开始的标志[2];2003 年,陈玉忠等提出符合藏文特性的最佳分词方案,旨在消除歧义切分和未登录词识别问题[3];2009 年,才智杰提出基于规则的“还原法”一定程度上解决了藏文分词中的黏着词问题[4];2011年,史晓东等移植汉语分词系统SegTag 至藏文上,开发了基于HMM(隐马尔科夫模型)的央金藏文分词标注系统[5];同年,刘汇丹等实现了基于序列标注的藏文分词[6];2015 年,李亚超等基于CRF,开发一个名为TIP-LAS 藏文分词和词性标注系统[7];2018 年,李博涵等分析和实验各类RNN(循环神经网络)在藏文分词上的表现,开始了深度学习在藏文分词中的运用[8];同年6 月,国标版《信息处理用藏文分词规范》正式发布;2020 年,王莉莉等提出一种基于BiLSTM_CRF 的藏文分词方法,提高了藏文分词的准确率[9]。
现代藏文分词主要有基于词表、统计和神经网络的三种方法。其中,基于词表的方法依赖于建立固定大小的词表,不能处理未登录词是最大的局限;基于统计的分词方法是伴随SIGHAN 国际中文分词评测比赛Bakeoff 的开展兴起的,2003 年由Xue N W。使用最大熵算法实现由字构词模型,将分词问题转化为序列标注问题,用4-tags 标注法,给中文每个组成词的汉字标记上不同的标签,利用不同的词位标签对汉字进行词边界确定,从而达到分词目的[10]。后来研究者将该方法运用到藏文分词上,也得到不错的效果。随着深度学习的兴起,许多神经网络模型随之涌现,神经网络在藏文自然语言处理领域蓬勃发展。
基于传统神经网络模型的藏文分词算法不能够有效地获取藏文语句中的上下文信息,基于此问题,提出两种改进方法:其一是使用以ALBERT 预训练语言模型获取音节向量,使得模型能关注到藏文文本序列上下文的信息,增强模型的性能;其二是在藏文分词模型中引入音节特征融合,相邻音节之间进行拼接作为当前音节的输入。本文提出的ASBC(ALBERT-Syllable-BiLSTM-CRF)藏文分词模型,在保留BiLSTM-CRF 自身优势的同时,联系更多的语义特征,使模型在藏文分词中具有更好的表现。
2 模型结构
2.1 ASBC藏文分词模型
本文提出的ASBC 藏文分词模型总体流程如图1所示。

图1 ASBC藏文分词模型图
对于一个输入序列,其经过ALBERT Embedding 层先通过一个全连接层把token 映射到一个较小维度的向量空间,再通过一个全连接层把token映射到目标维度的向量空间,可以得到表示该序列的音节向量;进入到Syllable Fusion 层,对相邻音节进行向量的拼接,通过音节拼接之后的每个向量输入到模型中。
本文的Encoding 层用的是双向长短时记忆模型,Decoding 层使用条件随机场模型。对于每个输入序列,首先经过编码后输入到双向长短时记忆中,BiLSTM Layer 有一个向前和一个向后的LSTM并行将对应位置的输出向量进行拼接,得到的输出包含过去时刻和未来时刻的上下文信息,然后将其输入到条件随机场中,解码发生在模型的预测阶段,CRF Layer 统计每个音节在文本中对应标签的概率,通过给定的观察序列预测音节对应的状态序列,最终有效地保存句子前后的标签信息。
在气温比较低的情况下,输液液体的温度时常会影响输液效果或输液的舒适度,而通过输液加热模块,把输液液体进入病人体内之前加热,以达到正常的输液效果。
2.2 ALBERT预训练语言模型
藏文结构复杂且语料稀少,传统词向量模型很难获取高质量的藏文音节向量,针对此问题,本文选用模型结构更为复杂的ALBERT 预训练语言模型,该预训练语言模型由西藏自治区藏文信息技术人工智能重点实验室提供,具体训练参数如表1所示。

表1 藏文ALBERT预训练语言模型训练参数
2.3 音节特征融合
音节特征融合是指将相邻的两个音节特征融合成一个音节特征的过程。在一句话中,通常被认为距离越近的两个音节,其语义关联性也越强,通过将音节特征融合可使神经网络提取到更多的输入特征。音节特征融合具体步骤如下:
1)在藏文语句X=[x1,x2,…xi,…xn]的句尾添加符号
2)将每个音节和相邻后一音节拼接成的双音节作为当前音节的输入。
3)使用unigram 和bigram 相结合,作为当前音节的输入。
例如对于ང་ལྷ་ས་ལ་དགའ་五个音节来说,其unigram表示为ང་、ལྷ་、ས་、ལ་、དགའ་;bigram 表示为ང་ལྷ、ལྷ་ས་、ས་ལ་、ལ་དགའ་、དགའ་
3 实验
3.1 评价指标
在序列标注任务中,模型评估往往采用准确率(P)、召回率(R)、F1 值(F)作为评价指标。准确率表示检索出来的文本与总文本的比值,用于反映系统的查找精准程度;召回率表示搜索到的相关文本和所有相关文本的比值,用于衡量模型的查全率;而综合指标即综合考虑二者的评估对模型的表现进行一个更全面的评估。具体定义如下:
3.2 实验数据
本实验基于Python 语言和pytorch 深度学习库进行实现,实验数据主要包括第二届少数民族语言分词评测大赛(MLWS2021)提供的藏文语料和实验室自建藏文语料,涉及新闻、小说、诗歌等多个主题,对数据的处理分别经过编码的调整、病句的处理、语句的去重,最终以现有分词工具分词,以《信息处理用藏文分词规范》为标准,经过人工校对,得到本实验数据集共8.5万句,将数据顺序随机打乱,取其中6.5 万句作为训练集,测试集和验证集分别为1万句。
3.3 实验设计与分析
预训练语言模型的应用,使得原本无法针对各种语境变化的静态音节向量表征,向着真正基于语境的语义特征表示演进。为验证ALBERT 预训练语言模型对整个分词模型的有效性,分别在不同基线模型中加入ALBERT,表2 展示了LSTM-CRF 和BiLSTM-CRF 网络在加入ALBERT 前后的实验效果对比。

表2 加入ALBERT效果对比
由表2 可看出,加入Albert 预训练语言模型后的分词效果得到了提升,其中基于LSTM-CRF的方法精确率、召回率和F 值分别提升了1.3%、1.8%和1.5%,基于BiLSTM-CRF 的方法精确率、召回率和F值分别提高了1.3%、1.1%和1.2%。
音节特征融合通过音节拼接使神经网络提取到更多的输入特征,为验证音节特征融合方法的有效性,仍以LSTM-CRF 和BiLSTM-CRF 网络模型作为对比,实验效果如表3所示。

表3 使用音节特征融合效果对比
由表3 可看出,使用音节特征融合后的分词效果得到了提升,其中基于LSTM-CRF 的方法精确率、召回率和F 值分别提升了0.9%、1.3%和1.1%,基于BiLSTM-CRF 的方法精确率、召回率和F 值分别提高了1.1%、0.8%和1.0%。
以上实验表明不论是ALBERT 预训练语言模型还是音节特征融合,都促使了藏文分词效果的提升,为进一步提升分词效果,将不同的方法进行融合,具体实验结果如表4。
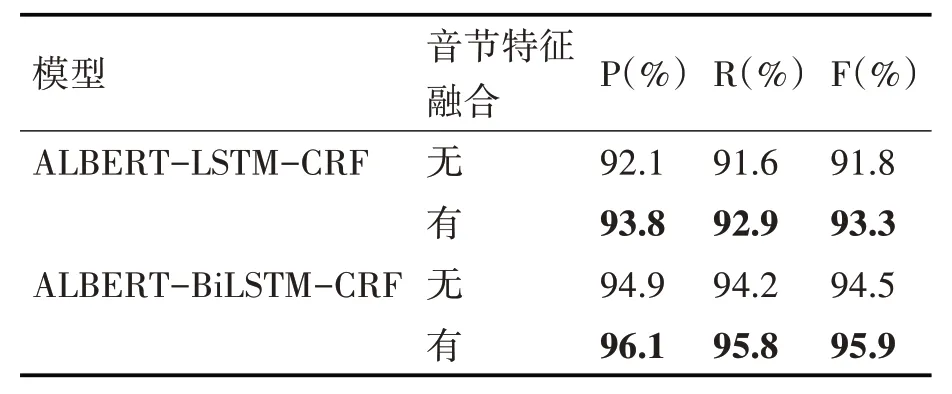
表4 使用ALBERT与音节特征融合效果对比
对比实验结果发现,当同时融入ALBERT预训练语言模型和音节特征融合时,分词达到SOTA 效果。至此,足以证明本文提出的ASBC 模型在藏文分词方面的优秀表现。
在得到完整的ASBC 藏文分词模型之后,为进一步保证分词粒度的准确性,提升分词的效果,在预处理部分加入了词典,该词典包含常见的藏文人名和地名总共20611 个,运用双向最大匹配算法保证测试语料中专有名词的完整性,实验效果如表5所示。

表5 加入词典效果对比
由表5 可看出,加入名词词典的分词效果得到了提升,但提升效果不明显,可能存在以下两个原因:1)测试语料中包含的词典中的人名地名较少;2)词典的加入导致语料中专有名词的粒度发生改变,对前后词语标签信息产生一定的影响。
3.4 实验效果对比
1)BiLSTM-CRF:
༡༩༣༦/ལོར་/ཁོང་/བླ་བྲང་/བཀྲ་ཤིས་/འཁྱིལ་/གྱི་/ཆོས་གྲྭར་ཞུགས/།
2)BiLSTM-CRF(ALBERT):
༡༩༣༦/ལོར་/ཁོང་/བླ་བྲང་བཀྲ་ཤིས་འཁྱིལ་/གྱི་/ཆོས་གྲྭར་ཞུགས/།
3)BiLSTM-CRF(音节特征融合):
༡༩༣༦/ལོར་/ཁོང་/བླ་བྲང་/བཀྲ་ཤིས་འཁྱིལ་/གྱི་/ཆོས་གྲྭར་/ཞུགས/།
4)ASBC:
༡༩༣༦/ལོར་/ཁོང་/བླ་བྲང་བཀྲ་ཤིས་འཁྱིལ་/གྱི་/ཆོས་གྲྭར་/ཞུགས/།/
比较句子(༡༩༣༦ལོར་ཁོང་བླ་བྲང་བཀྲ་ཤིས་འཁྱིལ་གྱི་ཆོས་གྲྭར་ཞུགས།)的不同分词效果,发现BiLSTM-CRF模型将句子粒度分得太细,ALBERT 或音节特征融合具有联系上下文信息的特性,有助于词粒度的准确判断,二者结合使之效果达到最佳。
4 结语
ALBERT的Embedding层通过字典将每个音节映射成音节向量,通过预训练捕捉语法和语义层面的信息,藏文预训练语言模型可帮助模型获取藏文语句中的上下文信息及在目标中建立上下文相关的隐含特征联系,辅助模型更好地锁定目标音节的标签;音节特征融合连接相邻音节的语义特征,进一步提升模型获取到更多特征信息的能力。实验验证了ALBERT 预训练语言模型和音节特征融合对于藏文分词的有效性,将两种方法同时融入BiLSTM-CRF模型中,提出表现能力较好的ASBC藏文分词模型,最后将ASBC 模型加入人名地名词典,藏文分词效果得到进一步提升。
虽然本文提出的ASBC 模型在藏文分词上具有较好表现,但仅依赖神经网络大量训练语料来提升分词效果性价比不高,分词与词性有着极强的关联性,接下来将结合藏文词性标注对藏文分词展开进一步的研究。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
布达拉(2020年3期)2020-04-13
快乐作文(1.2年级)(2019年9期)2019-09-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
西夏学(2019年1期)2019-02-10
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
中国音乐教育(2014年11期)2014-05-18
外语学刊(2011年3期)2011-01-22
