
大数据存储技术在张衡一号卫星数据服务中的应用
2023-09-27 09:02杨旭明王志李忠黄建平杨百一陈朝阳
科学技术与工程 2023年25期
杨旭明, 王志,2, 李忠,2*, 黄建平, 杨百一, 陈朝阳,2
(1.防灾科技学院应急管理学院, 廊坊 065201; 2.防灾科技学院智能应急信息处理研究所, 廊坊 065201; 3.应急管理部国家自然灾害防治研究院, 北京 100085)
“张衡一号”地震电磁卫星(以下简称ZH-1)的成功发射标志着中国已经成为世界上少数拥有在轨运行高精度地球物理场探测卫星的国家之一。ZH-1是中国地震立体观测体系天基观测平台的首颗卫星,主要科学研究目标是通过获取全球电磁场、电离层等离子体、高能粒子观测数据,对中国及其周边区域开展电离层动态实时监测和地震前兆跟踪,弥补地面观测的不足,探索开展全球7级、中国6级以上地震电磁信息研究,总结电离层扰动特征,开展试验性质的地震短临监测,进一步推进中国立体地震观测体系建设,为国际合作研究提供电磁数据服务,为探索地震监测预测提供了新的技术手段[1]。
ZH-1自发射成功至今已在轨工作4年多,ZH-1卫星搭载8种科学载荷,包括感应式磁力仪、电场探测仪(electric field detector,EFD)、高精度磁强计、GNSS掩星接收机、等离子体分析仪、朗缪尔探针、高能粒子探测器和三频信标发射机[1]。其中EFD载荷可采集全球范围的电场数据,是产出数据量最多的载荷之一,每天记录的数据量可达几十千兆字节[2],目前累积数据量已经达到几百太字节,其中不同频段的波形数据和功率谱数据都是以HDF5文件格式存储的,主要包括卫星轨道信息数据和载荷物理量数据。卫星轨道信息数据包括载荷名称、数据类型编码、轨道号、升降轨标识、采样频率、采样时间、频率范围、起始/结束采样时间;载荷物理量数据包括绝对时间、相对时间、地磁经纬度、地理经纬度、工作模式、功率谱频率值、卫星轨道高度、功率谱频率值、功率谱XYZ三分量、电场波形XYZ三分量等。由于EFD每个文件的数据量很大,文件存储方式的数据查询访问效率很低,严重制约着后续针对卫星数据的应用和研究工作。为此,高鹏等[3]针对当前ZH-1卫星数据的文件储存方式访问效率极低的缺陷,提出了一种利用关系型数据库存储卫星数据的存储方法,显著提高了卫星数据的查询访问时间。然而,面对日益增长的海量卫星数据,基于关系型数据库的存储方法具有扩展性差、并发性能偏低、读写速度慢、成本高等缺点[4],依然制约着科研人员对数据的检索访问效率和实际研究进展。因此,如何解决关系型数据库存储面临的瓶颈问题,并对卫星数据进行高效的存读取是迫切需要解决的问题。
当前,大数据存储技术作为处理海量数据的全新数据存储与计算模式,已经被应用在了很多领域[5]。Jiang等[6]为解决大规模煤矿安全监控数据存储在关系数据库中时存储效率低、查询速度慢的问题,设计了一种基于HBase的存储和检索方法,使用该方法对实际煤矿数据的实验结果表明,数据存储和检索效率显著提高;张家伟[7]利用HBase数据库的列存储特性,从优化数据计算流程、HBase表设计、选取数据分类压缩算法、搭建Hadoop和HBase环境、压缩存储电力数据等几个步骤设计实现了基于电力数据的高压缩率和快速存读取的压缩存储系统;刘凯铭等[8]将基于Hadoop框架的大数据技术应用到油气水井生产大数据的存储和分析中,解决了海量数据在传统关系数据库上查询效率低的问题,实现了多维数据的在线分析功能;单维锋等[9]通过深入分析地震前兆时间序列数据的特点以及数据处理的业务需求,首次提出了基于OpenTSDB和HBase结合的优化存储方案,通过测试分析了该方案在海量时空数据存储中高效的读写和并发性能。
现根据ZH-1卫星空间电场数据科研工作的需求,分析现有存储方法扩展性差、并发性能偏低、读写速度慢、成本高等不足,结合大数据存储技术的高可扩展性、高并发读写性、高可用性等优势,提出将ElasticSearch搜索引擎和HBase相结合的卫星大数据存储方案,并以ZH-1卫星记录的空间电场超低频(ultra-low frequency,ULF)频段数据为例,进行存储实验和对比测试,以验证该方案在张衡一号卫星空间电场数据存储中的高效性和适用性。
1 大数据存储方案设计
HBase作为分布式存储数据库,优势明显,主要体现在其容量巨大、列存储方式的低I/O吞吐量、多副本存储的高可靠性、快写入等性能方面[10]。但是HBase仅支持对RowKey的毫秒级高速检索,而RowKey具有唯一性以及字符长度受限的缺陷,使得HBase对于多字段的组合查询显得力不从心。
ElasticSearch作为一个分布式可扩展的实时搜索引擎,能同时支持全文检索和时序检索场景,可以支持丰富的查询需求[11]。但是,ElasticSearch的搜索引擎严重依赖于底层的 Filesystem Cache,每当数据查询时,操作系统都会将磁盘文件里的数据自动缓存到 Filesystem Cache。因此在单独面对海量数据时,如果把所有查询字段和非查询字段都写入ElasticSearch中,不仅会大大增加ElasticSearch的内存管理成本,还会严重影响查询效率。
因此,通过分析HBase和ElasticSearch的优势和劣势,提出将ElasticSearch搜索引擎与HBase各自优势相结合的存储方案(以下简称ES+HBase存储方案),通过把海量数据存储到HBase中,同时在ElasticSearch中建立查询字段的索引字段,以进一步提升HBase检索能力,实现对ZH-1卫星海量数据的多条件组合快速查询。
1.1 基于ElasticSearch和HBase的存储方案
基于ES+HBase的卫星大数据存储方案的原理是将HBase表中涉及条件过滤的字段和RowKey作为索引字段在ElasticSearch中建立索引,通过在ElasticSearch中进行多条件组合查询快速获得符合过滤条件的RowKey值,最后在HBase中通过从ElasticSearch中获取到的RowKey进行高速检索,其原理如图1所示。
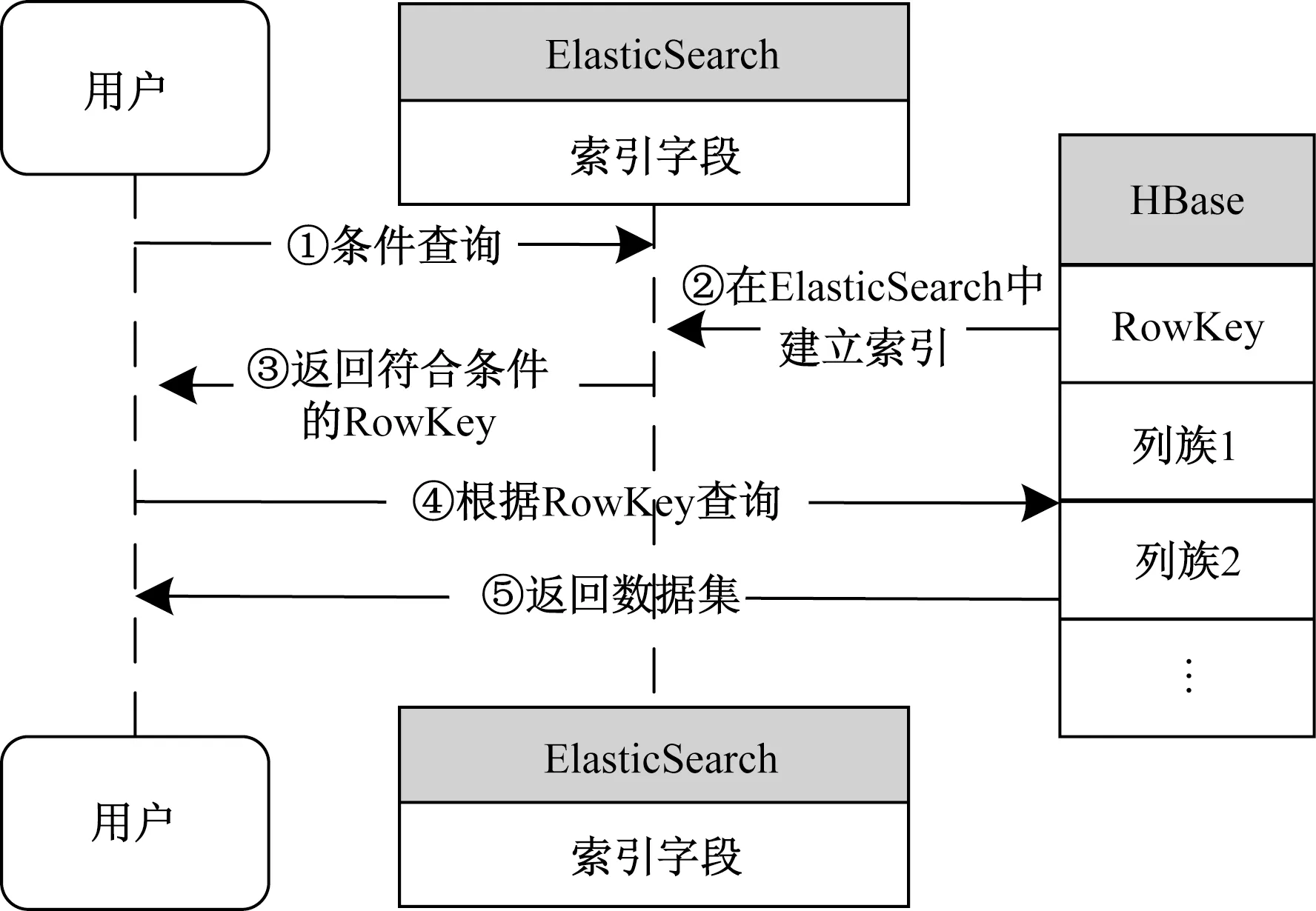
图1 基于ElasticSearch和HBase结合的存储方案原理图Fig.1 Schematic diagram of storage solutions based on ElasticSearch and HBase
由图1可知,当用户发起条件查询请求时,先将请求信息发送给ElasticSearch主机,该主机根据查询条件从索引字段中获取相应RowKey值,并将RowKey值返回给用户,用户使用获得的RowKey值去HBase中获取相应数据集,即可完成整个查询流程。
1.2 存储模型设计
基于ES+HBase的卫星大数据存储方案的存储模型设计主要包括列族设计、RowKey设计、索引字段设计。RowKey是HBase中最重要的概念,是HBase数据表的唯一主键,它按照一定的字典顺序存储的字符串类型数据,并且其字段具有大小限制。另外,它还可以用来进行全表扫描或范围扫描,这也是HBase访问数据的方式之一[12]。RowKey设计的总原则是避免热点现象,提高读写性能。
以2020年6月的ZH-1卫星空间电场探测仪的ULF频段数据为例加以说明。
步骤1根据RowKey设计的长度原则、散列原则和唯一性原则,使用反转HDF5文件中的时间(UTC_TIME)字段数据作为RowKey前缀,通过读取HDF5文件名称和内容中的卫星编号、载荷编码、载荷序号、数据分级编码、观测对象编码、接收站编码、版本号组成RowKey,让数据均衡分布在每个Region-Server,实现负载均衡,提高查询效率,如图2所示。
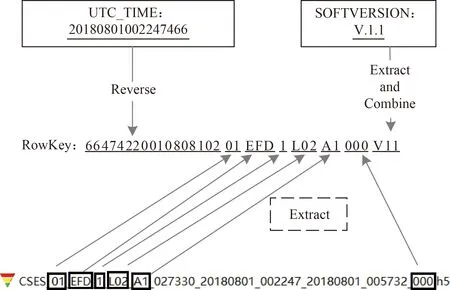
图2 RowKey设计组成图Fig.2 Design composition drawing of RowKey
在图2中,以一个H5文件为例,通过编写程序代码,获取文件中UTC_TIME字段值,进行反转操作后作为RowKey前缀字段,软件版本号(SOFTVERSION)属性值作为RowKey后缀字段,同时提取文件名称中的卫星编号01、载荷编号EFD、载荷序号1、数据分级编码L02、观测对象编码A1以及接收站编码000进行组合作为RowKey的中间字段。
步骤2创建包含时间、卫星编码(SNUM)、探头编码、轨道号、轨道高度、升降轨标识、经度、纬度等列字段的列族CF1,包含电场波形XYZ3个分量数据的列族WAVE,以及包含功率谱XYZ3分量数据和频点值的列族PSD。
步骤3把列族CF1中作为组合查询条件的列字段和RowKey作为索引字段在ElasticSearch中建立索引。数据存储模型如图3所示。

图3 数据存储模型Fig.3 Data storage model
图3中HBase的表名为ZH01_EFD_ULF,ElasticSearch的索引表名为zh01_efd_ulf,其中wave000表示列族WAVE中第一列的列名,psd000表示列族PSD中第一列的列名,WX0_WY0_WZ0表示将波形数据的XYZ三分量的第一个数据进行拼接,PX0_PY0_PZ0表示将功率谱数据的XYZ三分量的第一个数据进行拼接;HBase表中RowKey字段同步到ElasticSearch索引表中作为id字段,HBase表CF1列族中UTC_TIME、SNUM等字段分别在ElasticSearch索引表中创建对应的ES_CF1.UTC_TIME、ES_CF1.SNUM等字段。
2 实验对比分析
由于文献[3]通过关系型数据库方法显著提高了卫星数据的查询访问时间,因此在其基础上,利用2020年6月的ZH-1空间电场探测仪的ULF频段数据,通过搭建基于ES+HBase的大数据存储方案的实验平台,与基于Mysql数据库的关系型数据方法的查询访问效率进行对比分析。
2.1 实验环境配置
搭建了由6台主机组成的基于Hadoop架构的高可用集群、1台ElasticSearch主机和1台Mysql对比测试主机,所有主机的配置为:1个Intel(R) Xeon(R) E5-1620 V2 CPU(3.6 GHz,双核),8 G内存,1块4TSATA硬盘,Centos7操作系统和JDK1.8环境。在Hadoop集群相应节点上分别安装Hadoop3.2.2、ZooKeeper3.6.2、HBase2.2.7软件,在ElasticSearch主机上安装ElasticSearch6.8.15软件,同时在Mysql主机上安装Mysql5.7数据库系统。以上每个主机的角色分配情况如表1所示。
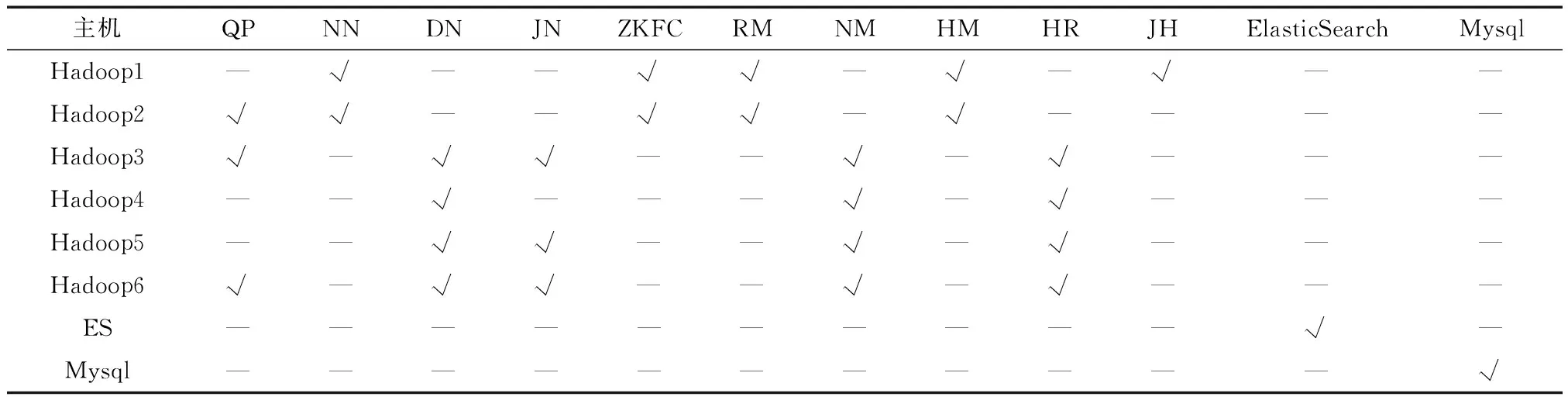
表1 ElasticSearch和HBase角色配置Table 1 ElasticSearch and HBase role configuration
2.2 实验结果分析
实验通过两个角度对基于ES+HBase的大数据存储方法、HBase RowKey查询方法和Mysql数据
库方法的查询访问效率进行比较。一个是不同存储数据量基数下查询相同数据量的效率对比测试;另一个是在相同存储数据量基数下查询不同数据量的效率对比测试。
2.2.1 不同存储量的相同数据查询效率比较
分别测试在700万、1 500万、3 000万、6 000万、1亿条数据量基数下查询200万条数据时不同存储方案的所用时间,实验结果如图4所示。

图4 不同存储基数下查询200万条数据耗时Fig.4 The time used to query 2 million pieces of data in different storage bases
由图4可以看出,随着数据库中所存储的数据总量的不断增大,查询相同数据时,Mysql数据库方法的查询时间持续增加,查询效率明显降低;而利用HBase的RowKey查询的方法与基于ES+HBase存储方案的查询效率仍都维持在较高水平、变化很小,且两者效率相近。
2.2.2 相同存储量的不同数据查询效率比较
在1亿条数据量基数下分别查询1万、10万、100万、200万、300万5种不同数据量时不同存储方案的所用时间,其结果如图5所示。

图5 1亿条数据基数下查询不同数据量耗时Fig.5 The time used to query different amounts of data in a data base of 100 million
由图5可以看出,在相同存储数据量基数下,随着查询数据量的不断增大,Mysql数据库方法查询耗时增加明显;而利用HBase的RowKey查询的方法与基于ES+HBase存储方案的查询耗时增加较为缓慢、变化较小,且两者效率相近。
通过对以上两种方式的对比实验进行分析可知,随着卫星数据量的不断增大,传统Mysql关系型数据库方法在查询大数据量时的效率越来越低,而HBase通过RowKey查询的效率仍维持在较好的状态,优势愈发明显。同时,基于ES+HBase的卫星大数据存储方案中虽然增加了ElasticSearch索引字段的查询阶段,但是该阶段对整体查询效率的影响是微乎其微的,其效率也非常好。因此,基于ES+HBase相结合的卫星大数据存储方法不仅增强了HBase的多条件组合查询的能力,满足了科研人员对卫星数据的精准查询需求,还继承了HBase RowKey查询方法的高效性,实现了对海量卫星数据的高效查询访问。
3 应用效果测试与分析
以ZH-1空间电场探测仪的ULF频段数据为例,利用3.1节的实验环境,测试基于ES+HBase相结合的卫星大数据存储方法的查询响应效果和在不同条件下检索数据的应用效果。
3.1 响应时间测试
由于文献[3]通过关系型数据库方法显著提高了卫星数据的查询访问时间,因此本实验在其基础上,将2019年11月—2020年12月共计14个月的ULF频段数据存入数据库中进行查询响应时间测试,分别测试ES+HBase大数据存储方法、关系型数据库和文件存储方法的响应时间,测试结果如表2所示。

表2 3种存储方法查询响应时间对比Table 2 Comparison of query response time of three storage methods
虽然本实验的硬件环境比文献[3]的实验条件差,数据库存储量比文献[3]测试数据量多,但是由表2测试结果可以看出,ES+HBase存储方法的响应时间都要优于关系型数据库和文件查询,该方法的性能几乎能达到关系型数据库的1.5倍,是现有文件存储方式的几十倍,这种效率的提升增加了进行大规模电场数据应用的可行性,同时也说明了所构建的数据访问平台是高效的,基于ES和HBase的大数据存储方法是可行的。
3.2 根据卫星轨道号绘制波形图和功率谱图
以轨道号13225为例。将轨道号13225和升降轨标识1作为查询条件,检索13225轨道夜侧半轨电场波形数据和功率谱数据,约17 s即可绘制出如图6所示的半轨电场波形图,约23 s即可绘制出如图7所示的功率谱图。由此可知,存储方法不仅具有在线数据分析功能,还大大提高了数据访问效率,是文献[3]关系型存储方法的3倍以上。
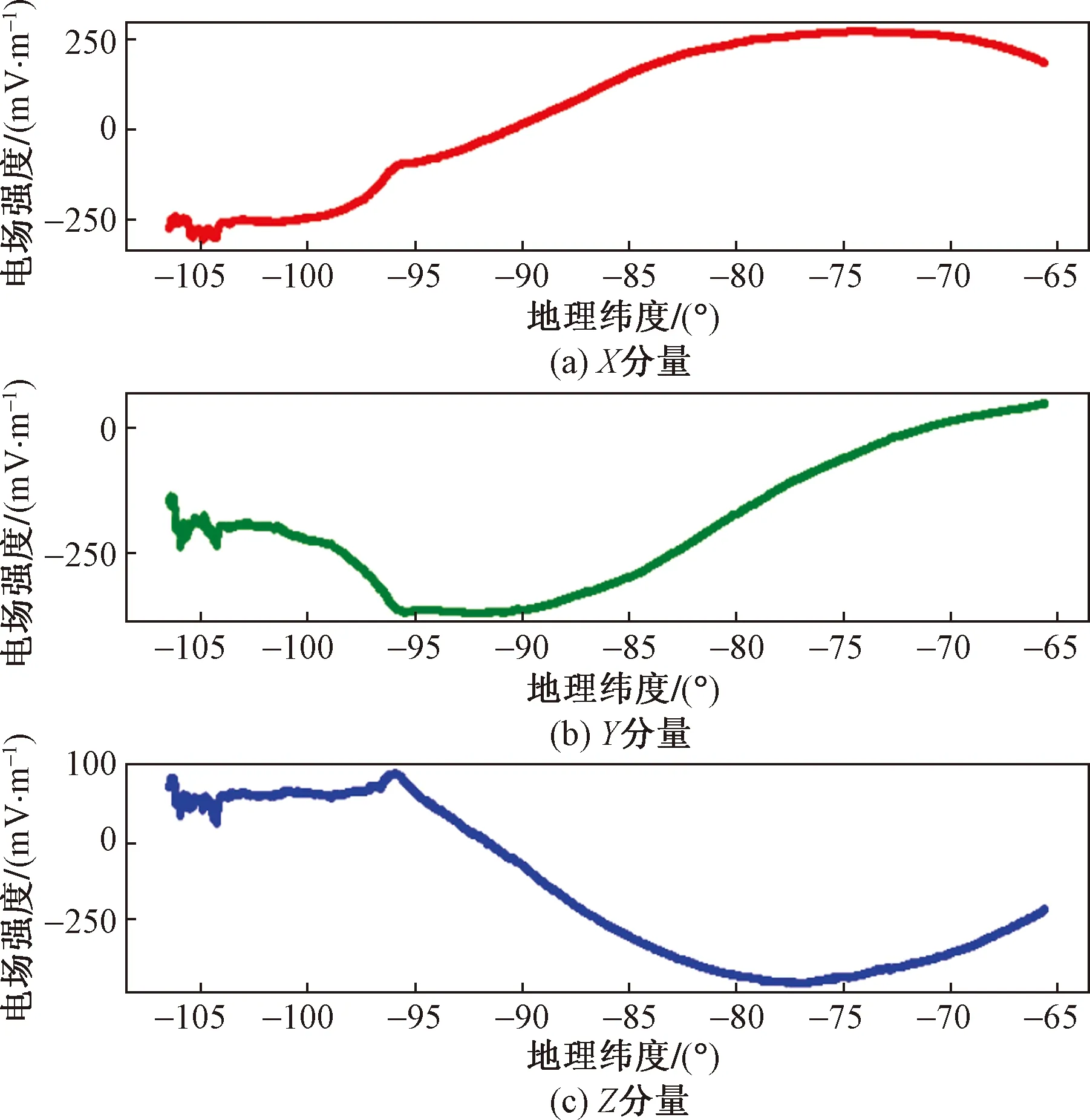
图6 13225_1电场波形图Fig.6 13225_1 electric field waveform
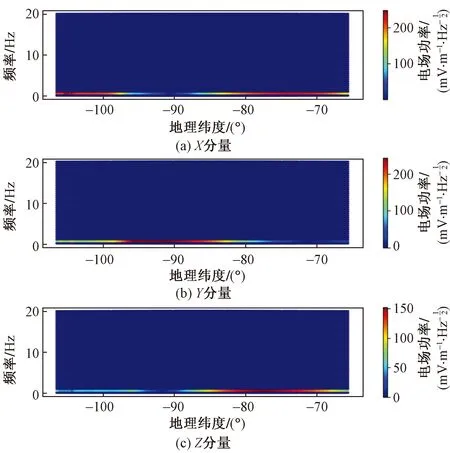
图7 13225_1电场功率谱图Fig.7 13225_1 electric field power spectrum
图6展示的是13225轨道夜侧半轨电场波形三分量数据随着时间、经纬度的变化。图7展示的是13225轨道夜侧半轨中不同经纬度、不同频率下的电场功率谱三分量数据情况。
3.3 根据时间段和经纬度绘制卫星轨道分布图
选择2020年6月23日墨西哥瓦哈卡海岸近海7.8级地震(地理经度为-96.75°,地理纬度为16.15°)的震前15 d电场ULF频段3分量波形数据进行研究。由于ZH-1的所有仪器设计为在纬度±65°的范围内开机工作,重返周期为5 d[3],因此将15 d研究数据划分为3个周期。同时考虑到卫星监测电场数据在白天易受到太阳和人类活动等因素干扰[13],将对ULF数据的搜索条件设置如下。
(1)将该震中区域地理经度加减15°,得到-111.75°~-81.75°区域范围。
(2)地理纬度-65°~65°区域范围。
(3)震前第三个周期即2020年6月19—23日。
(4)选择夜侧升轨。
在存储中查询该条件下的波形X分量数据,约120 s即可绘制出该条件下波形轨道数据的空间分布图,该效率是文献[3]存储方法的3倍,如图8所示。

图8 震中附近X分量波形轨道数据空间分布图Fig.8 Spatial distribution of X component waveform orbit data near the epicenter
图8中显示了2020年6月23日墨西哥瓦哈卡海岸近海7.8级地震震前5 d所有经过其震中附近矩形区域内卫星轨道波形数据空间分布情况。
4 结论
通过分析当前ZH-1卫星数据的现有存储方案在扩展性、存读取效率等方面的不足以及科研工作的需求,充分结合大数据存储技术在海量数据高效存储与读取等方面的优势,提出了基于ES+HBase的卫星大数据存储方案。通过搭建基于所研究方案的大数据存储实验平台,进行对比实验和应用分析,得到以下结论。
(1)通过在ElasticSearch中建立索引字段的方法,基于ES+HBase的卫星大数据存储方案继承了HBase 本身RowKey查询的高效性,实现了对海量卫星数据的高效查询访问;增强了HBase的多条件组合查询的能力,满足了科研人员对卫星数据的多条件组合查询需求,为后续针对海量卫星数据进行的一系列科学研究工作提供高效的技术支撑。另外,该存储方案具有横向扩展性、高可用性和高并发性等特点,不仅解决了传统关系型数据库存储方案的一系列瓶颈问题,还可以通过HBase的预分区、数据压缩等高级功能进一步提高该方案的性能。
(2)实验结果和实际应用效果分析表明,面对不断增加的数据存储需求时,基于ES+HBase的卫星大数据存储方案的高效查询访问的优势越来越明显,查询速度可以比关系型数据库方案高出几倍、几十倍;同时该方案实现了对卫星空间电场ULF频段数据的多条件组合的快速查询。
由于涉及的实验可能会由于环境配置比较低、数据量不足够大等原因没能更好地体现基于ES+HBase存储方案的优势,因此后续将会在该方案的基础上,通过提高服务器配置、调优ES+HBase的性能参数等,对10 TB及以上的数据量存储进行更深层次的实验和实际应用分析,进一步证明基于ES+HBase大数据存储方案在ZH-1卫星数据服务中的适用性。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
中学生数理化(高中版.高考理化)(2021年11期)2022-01-18
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
新高考·高一物理(2016年7期)2017-01-23
中学生数理化·高二版(2016年9期)2016-05-14
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
