
基于深度学习的图像色彩一致性算法设计
2023-09-26 01:18:42陈芳
自动化仪表 2023年9期
陈 芳
(苏州信息职业技术学院计算机科学与技术系,江苏 苏州 215000)
0 引言
许多计算机视觉问题都采用颜色一致性处理作为预处理步骤,以确保在不同光照条件下记录的场景中物体的颜色不会发生变化[1]。贝叶斯法[2]以反射率和光源的变异性建模为随机变量,根据图像强度的后验分布估计光源。文献[3]训练1个图像分类器对室内和室外图像进行分类,并提出了不同的试验框架来选择各类别的最佳算法。文献[4]使用图像的内在与低级别属性为给定图像选择最佳算法。文献[5]利用威布尔参数化训练了1种基于混合高斯的最大似然分类器,从而为特定图像选择出性能最好的颜色一致性方法。文献[6]采用高水平视觉信息从1组可能的光源中选择最佳光源。文献[7]研究如何自动检测出具有固有颜色的物体。文献[8]采用图像中的表面信息,通过无监督学习的方法解决了训练图像中每个训练表面的合适模型的颜色一致性问题。
本文采用卷积神经网络(convolutional neural network,CNN)对图像进行自动白平衡调整,使得场景光源的学习和预测在局部区域块上进行。以前的方法通常是在整个图像上积累特征,以估计整体光源的统计数据,只有少数几种方法显示了估计空间变化的光源的能力。相比之下,本文方法可以估计小块的光源。试验结果表明,本文方法在标准的RAW图像数据集上取得了较好的效果。
1 图像一致性算法设计
本文提出的使用深度学习进行光源估计的框架为:首先,对每张彩色图像进行非重叠采样,以得到一些图像块;然后,通过直方图拉伸对每个图像块进行对比度归一化。本文使用CNN估计每个图像块的光源,并结合图像块的“整体打分”获得整张图像的光源估计。
1.1 网络架构
为了实行camera图像的色彩一致性算法,本文提出了1个5层网络的浅层架构。它是1个32×32×3、32×32×240、4×4×240、40、3结构。网络输入为经过对比度归一化的32×32图像块。第一层是卷积层,使用240个卷积核对输入进行滤波。每个核的空间大小为1×1×3。步长为1个像素。此卷积层首先生成240个大小为32×32的特征图,然后使用8×8 大小滤波器和步长为8个像素的下采样层进行最大池化操作,得到的结果是将每个特征图削减为4×4 大小的特征图。随后,卷积层被重塑为3 840×1(4×4×240)的向量。此后,卷积层全连接1个40×1大小的向量。最后的输出层是1个简单的线性回归,输出三维光源照度估计值。
1.2 对比度归一化
为了在不同的光照条件下具有鲁棒性,本文对所有提取到的图像块皆进行了对比度归一化。在不同的对比度增强技术中,本文选择了全局直方图拉伸。这是因为全局直方图拉伸不会改变3个颜色通道的相对贡献权重。此外,由于色彩一致性是基于全局开展的,神经网络有更加明确的优化方向。这有利于算法的收敛。
1.3 下采样
卷积层将对比度归一化后的图像块与240个滤波器进行卷积。每个滤波器对应生成1个特征图。本文在每个特征图上应用最大池化来减少滤波器的响应,使其下降到1个更低的维数。与目标识别场景中的下采样层通常倾向于在较小的邻域上执行不同,即使在场景光源是空间变化的情况下,其也是局部同质的,即1个32×32大小的图像块中所有位置都倾向于拥有相同的光源。这也启发了本文使用更大的池化核。
1.4 ReLU
与双曲正切函数和Sigmoid函数相比,修正线性单元(rectified linear unit,ReLU)在获得几乎相同性能的同时能使网络的训练速度快几倍。因此,本文在全连接层中使用ReLU。此外,ReLU增加了神经网络的非线性映射与拟合的能力,使得模型可以更好地学习到适合色彩一致性的参数。更重要的是,相比于前2个激活函数,ReLU避免了网络可能存在的、因梯度消失而导致的神经元灭活现象。
1.5 AlexNet+SVR
除了设计并学习1个专门针对颜色一致性问题的CNN,本文还研究了经过预训练的CNN是如何处理这些问题的。为此,本文使用文献[9]所描述的AlexNet网络输入227×227 RGB图像,通过5个卷积层和2个全连接层前向传播来得到1个4 096维的特征向量。本文通过提取最后1层隐含层的激活值来获得特征,将提取的特征作为支持向量回归 (support vector regression,SVR)[10]的输入来估计每张图像的光源颜色。在试验结果中,本文将这种方法称为AlexNet+SVR。
2 试验设置
2.1 所用数据集
为了测试算法的性能,本文使用带有明确颜色标准的RAW图像数据集[2]。该数据集是以sRGB格式提供的,但是文献[3]对其进行了重新处理,以获得具有更高动态范围(14 bits)的线性图像数据。该数据集是用高质量的数码单反相机以RAW格式拍摄的,因此不需要任何颜色校正。该数据集是使用佳能5D和佳能1D单反相机采集的,共包含568幅图像。每个场景下皆包含色彩检验色卡(macheth color checker,MCC)。这样能准确估计每张图像的实际光源强度。
2.2 评价指标
一般而言,评价图像增强的性能主要有2种度量指标,分别为结构相似性(structural similarity,SSIM)与峰值信噪比(peak signal-to-noise ratio,PSNR)。为了与其他方法进行对比,本文选取了反余弦误差函数:
(1)
式中:α1×3为真实的光源RGB强度向量分布;β1×3为估计得到的光源RGB分布。
2.3 对比算法
为了证明算法的有效性,本文与一些其他的算法进行了关于白平衡的对比。由于数据集的每幅图像只包含1个MCC,因此只能基于均匀光照的假设来比较相互之间全局颜色的一致性性能。对基于假设的场景光源纠正法而言,在估计光源光照时,唯一已知的信息是传感器对输入图像的响应(即RAW图)。因此,图像白平衡从这种角度来看属于1个欠定问题[1]。此时需要进行进一步的假设。常见的是假设场景中始终有1个均匀光源,即p(w,h)=C。其中,C为常数。基于这项假设,后续许多方法都能以实例化式开展:
(2)
式中:n为导数的阶数;m为闵可夫斯基范数;Iδ(w,h)=I(w,h)⊗Gδ(w,h)为图像经过参数为δ的高斯滤波之后的结果;k通常为了归一化而取值2。
(n,m,δ)的不同取值对应于不同的自动白平衡算法。其中,每种算法的提出又基于不同的假设。例如,(n,m,δ)=(0,1,0)对应于灰度世界算法。此算法假设图像中平均下来的所有点的RGB分量相等,即R=G=B。因此,光源的颜色可根据图像颜色通道中的平均颜色与灰度之间的偏移量来估计。(n,m,δ)=(0,∞,0)对应于白块算法。此算法假设场景中总是有1个白块,并且每个颜色分量通道的最大值是由光源在该白块上的反射引起的,以此来估计光源颜色。(n,m,δ)=(1,0,0)对应于灰边算法。此算法假设边缘的平均色度为灰色,而光源颜色可以通过估计图像颜色通道中边缘的平均颜色与灰色的偏移量来求得。色域映射方法假设对于给定的光源,人们只能观察到有限的色域。该方法具有1个初始阶段。在此阶段可选择1个标准光源,并在该标准光源下可以观察到尽可能多的图像表面时计算标准色域。该方法给定1幅光源未知的输入图像,计算其色域,并且当映射可以被应用于输入图像的色域时光照可以被估计,从而得到一个完全在标准色域内的色域,并产生最终的场景。此外,在已知相机的光谱灵敏度函数的情况下,利用相关方法也可得到相应的颜色。本文有7个对比算法是通过改变式(2)中的(n,m,δ)变量得到的,并且它们皆为广泛使用的颜色一致性算法。不同算法的参数如表1所示。
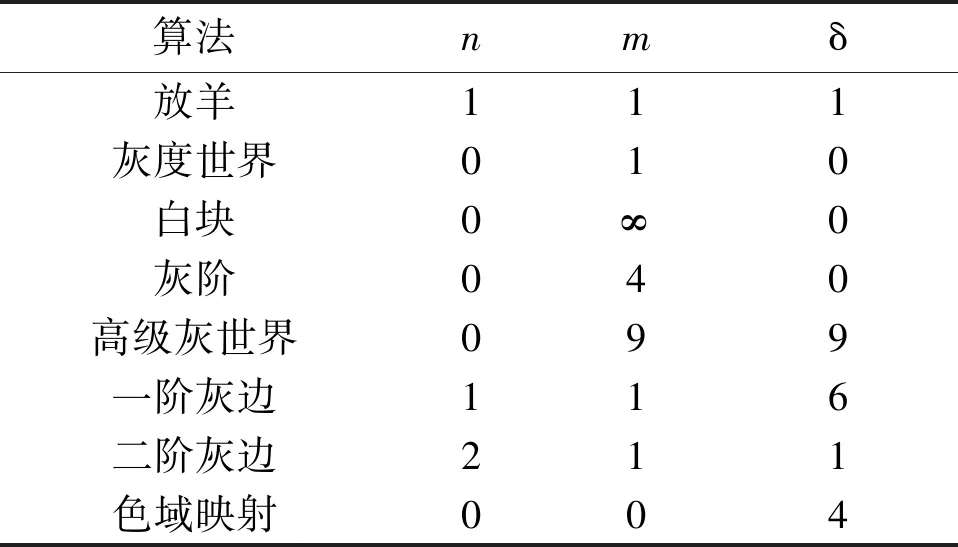
表1 不同算法的参数
表1中的放羊算法,对每幅图像的光源颜色皆给出相同的估计[(n,m,δ)=(1,1,1)],从而假设图像已经达到了白平衡。此算法从某种角度看也属于基于假设的场景光源纠正法。
2.4 试验设置
试验环境为Python+Pytorch+Cuda+Cudnn+Linux,显卡为Nvidia Titan RTX,总推理时间为54 ms/帧。本文使用迁移学习的方法。为了快速收敛,本文在参考Alexnet先验信息的情况下通过消融试验进行了网络参数的设置。试验设置层数为5、学习率为1×10-3、Batch(数据轮次)为32、Epoch(数据批次)为30、Dropout率为0.5。
试验在RAW格式的图像中提取的32×32随机色块上训练CNN。相机图像的大小已调整为max(w,h)=1 200。本文使用3折交叉验证方法训练网络,即数据集中三等分,分别用于训练、验证和测试。为了进行训练,本文为每个图像块皆分配了与其所属图像对应的光源真实标签。在测试时,通过合并预测得到的每个图像块的光源强度,为每个图像生成单个光源估计。与在给定数据集上使用整个图像相比,使用图像块作为输入使得试验拥有大量的训练样本,能更好地进行学习,同时也避免了过拟合。使用的损失函数为欧几里得损失函数。而一旦估计到了场景光源颜色p,则图像中的每个像素可以通过文献[11]中的模型进行矫正。
3 试验结果与分析
不同算法的性能比较如表2所示。
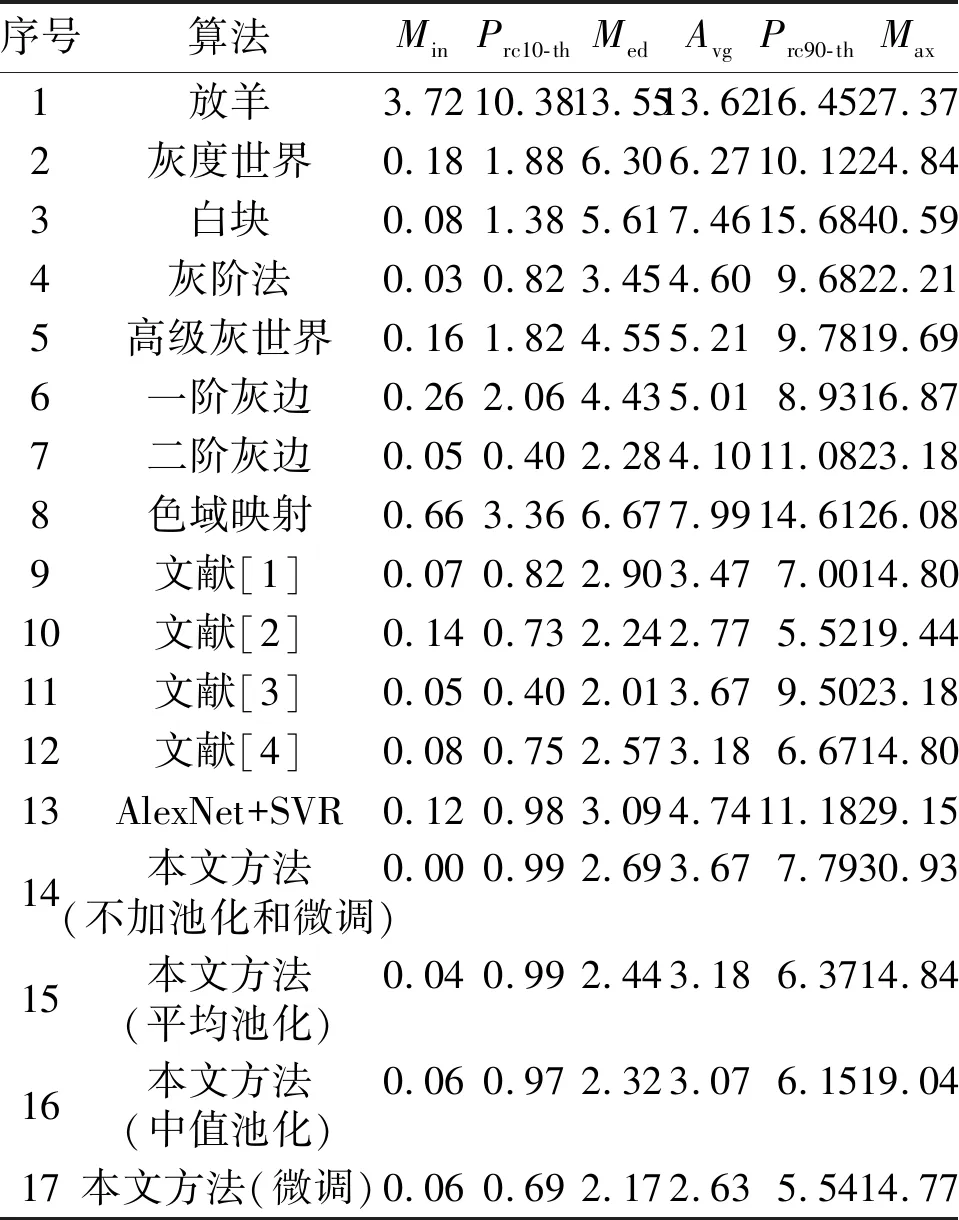
表2 不同算法的性能比较
由表2可知不同算法在RAW图像集上得到的反余弦误差的最小值(Min)、第10百分位数(Prc10-th)、中值(Med)、平均值(Avg)、第90百分位数(Prc90-th)和最大值(Max)。表2中,序号1~8为基于假设的场景光源纠正法,序号9~12为基于统计学习的算法,序号14~17为所提方法的不同变体。在数据集[9]上预先训练的深度CNN加上SVR(即序号13的AlexNet+SVR)已经能够超过大多数基于假设的场景光源纠正法和一些基于统计学习的算法。就中值误差而言,所提方法优于一半以上的其他算法。本文方法(平均池化)和本文方法(中值池化)是通过在整个图像上对基于图像块的光源估计的方法进行池化而获得的结果。本文考虑了2种非常简单的池化策略,即平均池化和中值池化。就中值误差而言,这2种算法的表现都优于大多数先进的算法,平均池化的最大误差仅比基于统计学习的最佳算法差0.3%。表2中的最后一行是采用中值池化和反余弦误差损失并经过微调的CNN。可以看到,它在中值误差、平均值误差和最大值误差均达到了在对比方法中的最佳性能。值得注意的是,这些最佳结果都是在本文算法上同时达到的,而之前算法的最优解分布于不同的算法当中。这进一步佐证了本文算法的有效性。试验结果对比如图1所示。

图1 试验结果对比
为了比较本文算法在不同网络层数和不同Batch大小下对性能的影响,不同网络层数和Batch大小对中值误差的影响如表3所示。
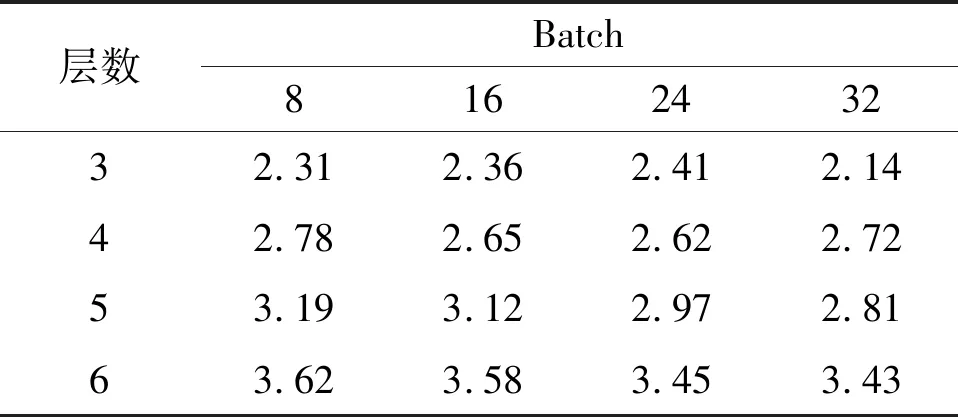
表3 不同网络层数和Batch大小对中值误差的影响
由表3可知,5层网络和Batch大小为32时误差最低。这也是本文网络选择参数的缘由。网络收敛情况如图2所示。
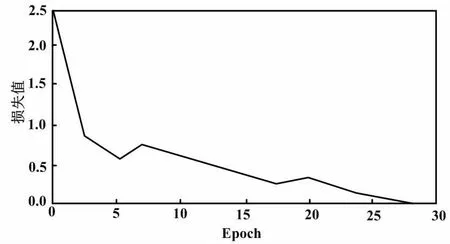
图2 网络收敛情况
训练结果显示,随着Epoch的不断增加,损失值迅速减少,经过30个Epoch后,基本可以实现网络的收敛。此时,训练完成。
4 结论
在不同色温光源下的传感器成像不具有类似于人眼的白平衡特性,使得图像颜色跟随环境光而改变。因此,本文提出了基于CNN的camera图像色彩一致性算法,以准确预测环境光源。所使用的深度主干网络由2个卷积层、1个池化层和2个全连接层组成,以图像块为输入,而非之前常用的手工特征。在提出的网络架构中,本文将特征学习和回归集成到1个端到端的优化过程中,并使得场景光源的学习和预测在局部块区域上进行,可得到1个更有效的场景光照估计模型。在不同光源场景下的图像集上进行的初步试验证明了提出的camera图像色彩一致性算法的有效性。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
公民与法治(2022年5期)2022-07-29 00:47:28
软件导刊(2022年3期)2022-03-25 04:45:04
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
光源与照明(2019年3期)2019-06-15 09:21:04
计算机技术与发展(2019年1期)2019-01-21 00:56:38
数学小灵通·3-4年级(2017年3期)2017-04-16 04:41:11
燕山大学学报(2015年4期)2015-12-25 02:19:49
