
非全局池化的通道注意力及其在语义分割中的应用
2023-09-25 08:08郑伯川杨文意
西华师范大学学报(自然科学版) 2023年5期
郑伯川,周 兰,陈 雯,杨文意
(西华师范大学 a.计算机学院,b.数学与信息学院,四川 南充 637009)
语义分割是计算机视觉的基础任务,可以理解为像素级别的分类,即逐像素预测所属类别。语义分割提供了全面的场景描述,能提供目标对象的类别、形状、大小等信息,有助于计算机理解图像。传统的图像分割方法多为根据目标区域的局部特征进行分割,主要包括基于阈值[1]、基于边缘[2]、基于局部特征[3]、基于聚类[4]、基于图论[5]以及其他图像分割方法[6]等。传统的图像分割方法无法学习目标的语义特征,不能进行语义分割,并且易受噪声影响,因此只能应用于特定图像的分割,对自然图像分割效果不好,难以提供有效的语义理解信息。
深度卷积神经网络(Deep Convolutional Neural Networks,DCNNs)具有优秀的特征提取性能,被广泛用于图像分类、目标检测、语义分割等任务。全卷积网络(Fully Convolutional Network,FCN)[7]是深度学习技术用于语义分割的开山之作,该网络使用卷积层替换全连接层,将经过多次卷积、池化后得到的特征图进行转置卷积将缩小后的特征图还原为原始图大小,最后通过像素分类实现图像分割。FCN由于能提取图像全局特征,从而可以实现图像语义分割。FCN有优秀的语义分割性能,特别对于自然图像的分割,能很好的将语义目标对象分割出来,从而能提供有效的图像语义信息。FCN被提出之后,研究人员将图像分割方法的研究转向了深度学习技术,主要在FCN的网络框架下进行了大量的改进[8-15],将深度网络的许多新的技术引入到FCN网络模型中提高图像分割性能,如将注意力机制引入特征提取网络提高特征提取性能。特征图中不同的通道所包含的信息重要性不一样,为了使网络更关注包含更重要信息的通道,Hu等[16]提出了SENet,该网络采用的挤压-激励模块(Squeeze-Excitation Block)通过捕获全局信息给通道分配不同的权重以提高模型表征能力。挤压-激励模块中的挤压部分采用全局平均池化,将输入特征图中的每个通道挤压成一个值,忽略了每个通道的局部信息。在挤压模块采用全局平均池化仅得到次优级特征信息,为了提取更精细的通道特征,Woo等[17]提出CBAM(Convolutional Block Attention Module),该模块在挤压模块结合全局平均池化和最大值池化,并以串联的方式融合通道注意力和空间注意力。全局上下文信息对语义分割至关重要,Zhang等[18]提出CEM(Context Encoding Module),将挤压模块中的全局平均池化替换为编码块(Encode),捕获场景上下文语义,并结合语义编码损失进行分割。单独使用全局平均池化会限制模型捕获高阶信息的能力,为解决该问题,Gao等[19]引入GSoP(Global Second-Order Pooling),在挤压模块计算不同通道的协方差矩阵以获得其相关性,再对协方差矩阵进行行方向归一化以获取通道间的关联性。Qin等[20]证明了全局平均池化是离散余弦变换(Discrete Cosine Transform ,DCT)的一种特殊情况,由此提出一种新的多光谱通道注意。Lee等[21]提出SRM(Style-based Recalibration Module),在挤压模块通过计算输入特征的均值和标准差捕获更精细的全局特征,激励模块使用通道级全连接替代原有全连接,减少计算量。在激励模块中加入全连接操作,将不可避免增加参数数量以及消耗额外的计算资源,为了解决这一问题,Yang等[22]提出GCT(Gated Channel Transformation),通过计算各通道L2范数收集全局信息,特征缩放后采用信道归一化进行信道交互。Wang等[23]提出ECA(Efficient Channel Attention)块,在激励模块使用一维卷积确定各通道之间的交互。
为了提取包含更多局部信息的挤压信息,本文对挤压-激励模块进行改进,提出一种基于非全局池化的通道注意力网络结构,并将该网络模块应用于语义分割中。本文主要贡献如下:(1)对SENet通道注意力模块进行改进,提出一种基于非全局池化的通道注意力模块,将原来的全局池化变成非全局池化,获得更丰富的局部特征,有利于后续激励模块学习更好的通道权重。(2)将提出的非全局池化注意力模块应用到语义分割中,并在PASCAL VOC2012增强版分割数据集上验证语义分割方法的有效性。
1 Attention-FCN模型
FCN[7]网络是经典的语义分割网络模型,本文提出的Attention-FCN模型是在FCN网络模型的基础上进行改进,在FCN模型的特征提取网络模块中加入改进后的挤压-激励模块。
1.1 Attention-FCN结构
Attention-FCN网络模型,可以分为两个部分。第一部分为特征提取部分,利用深度卷积神经网络,堆叠卷积层、池化层和注意力模块提取特征信息,通过池化层不断缩小特征图大小。该部分可采用VGG-16[24]和ResNet-34[25]作为特征提取网络。第二部分为特征融合部分,采用转置卷积将特征图恢复到输入图像大小,同时利用跳跃连接,融合多个大小的特征图信息。如图1所示,输入大小为H×W×C的图像,特征提取网络有3个不同的stage块,每个stage块后连接本文提出的改进通道注意力模块(Modified Channel Attention Block,MCAM)。
1.2 全局池化的通道注意力模块
SENet采用的通道注意力模块如图2所示,包括挤压(Squeeze)和激励(Excitation)两个模块。

设X=[x1,x2,…,xC′]为输入特征,其大小为H′×W′×C′。 给定卷积变换Ftr,设V=[v1,v2,…,vC]为一组卷积核,vc表示第c个卷积核,(c=1,2,…,C),Ftr将输入特征X映射到特征U=[u1,u2,…,uC],其中U的大小为H×W×C,则第c个通道的特征信息uc可用公式(1)表示:
(1)
挤压模块通过通道全局平均池化将U各通道全局空间信息uc压缩成一个通道描述符zc。 则第c(c=1,2,…,C)个通道的特征描述符zc可用公式(2)表示:
(2)
激励模块将通过挤压模块得到的特征描述符映射到一组通道权值。该模块采用两个全连接(Fully Connected,FC)层先降维再升维,两个全连接层之间采用ReLU函数作为激活函数,最后一个全连接层的输出经Sigmoid函数激活后得到通道注意力权重s,则s可用公式(3)表示:
s=Fex(z,W)=σ(W2δ(W1z)) ,
(3)
其中,σ表示Sigmoid函数,δ表示ReLU函数。通道注意力权重作用在原特征U上进行特征重标定,即通道加权,如公式(4)所示:
(4)
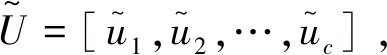
1.3 非全局池化的通道注意力模块
输出特征U各通道特征uc的统计量可以表达整个图像的信息。SENet采用最简单的全局平均池化来聚合特征,即对同一个通道不同区域的信息赋予相同的权值,这种处理方式难以体现同一个通道内不同区域特征的重要性。为了体现同一个通道内不同区域信息的重要性,在挤压模块使用非全局平均池化替换全局平均池化,从而获得通道更多的局部信息。非全局池化的通道注意力模块如图3所示。
将原空间维度为H×W×C的特征图通过窗格池化(非全局池化)压缩成维度为k×k×C的特征图,再通过C个核大小为k×k×C的卷积核卷积得到1×1×C的特征,最后经过Sigmoid函数激活得到每个通道的权重,将该权重与输入特征图对应通道相乘,实现通道级加权,从而实现通道注意力机制。

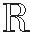
(5)
(6)
非全局平均池化模块中,当窗格大小k=1时,得到zc为一个标量,与SENet中挤压模块得到的输出一致。
为了将一个通道内k×k个窗格的池化值融合成一个特征描述符,同时计算通道间的依赖关系,采用C个核大小为k×k×C的卷积核对Z=[z1,z2,…,zc]进行卷积,得到通道注意力建模的输出,最后经Sigmoid函数激活后得到通道注意力权重s。s可用公式(7)表示:
s=Fex′(z,W)=σ(Fconv(z)),
(7)
其中,σ表示Sigmoid函数。通道注意力权重作用在原特征上,对原特征进行通道级注意力加权,如公式(4)所示。
2 实验与分析
实验硬件环境:单CPU,型号为 Inter Xeon 4114,2.20 GHz;2张GPU卡,分别为NVIDIA Quadro RTX 4000和NVIDIA Quadro P5000。软件环境:Unbuntu18.0、PyCharm、Python 3.7、Pytorch框架。训练时设置batchsize为10,优化器为Adam,初始学习率为0.000 001,训练100轮。
2.1 数据集
使用PASCAL VOC2012增强版图像分割数据集,包含来自PASCAL VOC2012数据的11 355张图像的分割标注,共20个对象类别,加背景21类,每张图像大小为320×320像素。将数据集拆分为训练集8 498张、验证集1 427张、测试集1 430张。
2.2 评价指标
为了评价算法的分割性能,采用像素准确率(Pixel Accuracy,PA)、类别平均交并比(Mean Intersection over Union,MIoU)两个评价指标进行定量评价。PA是语义分割中最常用的像素级评价指标,其计算图像中正确分类的像素占图像中总像素数比值。MIoU是分割结果真值的交集与其并集的比值(Intersection over Union,IoU)按类计算后取平均值。像素准确率和平均交并比定义分别如公式(8)和(9)所示,公式(10)表示某一类别的交并比。
(8)
(9)
(10)
其中,TP(True Positive)为真正,FP为假正(False Positive),TN为真负(True Negative),FN为假负(False Negative)。pii表示第i类被预测为第i类的像素个数,pij表示第i类被预测为第j类的像素数量,pji表示第j类被预测为第i类的像素数量,n是类别数。PA和MIoU的取值范围都是[0,1],他们的值越大说明分割效果越好,反之则表明分割效果变差。
2.3 不同大小窗格对比
非全局平均池化模块窗格大小k对最终的分割效果有一定的影响。为了得到最佳窗格大小,设计6种不同的窗格池化大小进行对比实验,实验模型是基于ResNet-34的FCN,在两种评价指标下的分割性能如表1所示。从表1中可以看出,当k=7时的PA最高,k=9时Miou最高,由于k=7时的计算量比k=9低,因此综合考虑,本文选择k=7。

表1 不同窗格大小下的性能指标对比
2.4 不同组合结构对比
为了验证本文提出的非全局池化通道注意力的有效性,对比了不同模块组合下模型的分割性能。实验模型是基于ResNet-34的FCN,窗格大小设置为k=7,分割性能如表2所示。从表2中可以看出,Pool+Conv组合结构分割性能最好。需要指出的是,前面不同窗格大小对比实验时采用的是Pool+Conv组合结构得到的结果。

表2 不同模块组合下的性能指标对比
2.5 不同通道注意力模块对比
为了进一步验证非全局池化通道注意力模块对分割性能的提升情况,将本文提出的注意力模块与SE、CBAM分别在基于VGG-16和ResNet-34特征提取网络的FCN网络模型上进行对比实验。在两种评价指标下的分割性能对比如表3、表4所示。由表3、表4可以看出,本文提出的窗格池化方法的两个指标都优于基线网络和其他两种通道注意力方法,其中,基于ResNet-34的Attention-FCN,PA比最好的高了1.24个百分点,MIoU比最好的高了4.64个百分点;基于VGG-16的Attention-FCN,MIoU比最好的高了3.9个百分点。

表3 本文方法与其他通道注意力性能指标对比(基于ResNet-34)

表4 本文方法与其他通道注意力性能指标对比(基于VGG-16)
2.6 分割结果展示
图4展示了部分基于ResNet-34特征提取网络的Attention-FCN分割效果图,其中第1列是原始图像,第2列是真实掩模图,第3列是未使用任何通道注意力模块的FCN得到的分割图像,第4列是在FCN中加入SE模块得到的分割图像,第5列是在FCN中加入CBAM模块得到的分割图像,第6列是在FCN中加入本文的MCAM模块得到的分割图像。从图4可以看出,第3—5列均存在错分类现象,而使用本文方法得到的分割图像(第6列图像)更接近真实掩模图(第2列图像),比其他3种结构(第3—5列)的分割效果更好。

3 结 语
本文提出一种非全局池化的通道注意力网络模块,并将它用于Attention-FCN语义分割模型中。非全局池化更能捕获通道的局部特征,获得更准确的通道权重,建立更好的通道依赖。在PASCAL VOC2012增强版数据集上的语义分割实验表明,提出的改进通道注意力网络模块能有效提升语义分割性能,优于其他对比通道注意力网络模块。但是,该算法也存在一定的局限性,如窗格大小需人工设定。后续将进一步将此注意力模块应用到其他网络模型以及其他任务中,进一步验证其性能。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
软件导刊(2022年3期)2022-03-25
少儿美术(2019年4期)2019-12-14
计算机技术与发展(2019年1期)2019-01-21
电脑爱好者(2018年19期)2018-11-05
金桥(2018年4期)2018-09-26
中国卫生(2014年5期)2014-11-10
