
基于改进随机森林算法的防火墙日志异常检测并行化方法
2023-09-25 17:13王佳斌洪继炜
现代计算机 2023年14期
刘 成,王佳斌,洪继炜
(华侨大学工学院,泉州 362021)
0 引言
在现今的大数据时代,网络在人们生活中不可或缺。随着互联网的用户量和规模不断增长,网络流量也呈现出井喷式的增长,网络安全问题也变得越值得重视,如何保障网民的合法利益也变得越来越重要。因此,如何对大规模的网络流量进行异常检测并分类,是非常值得研究的课题。
近年来,许多国内外学者开始使用机器学习的方法来解决网络入侵流量异常检测和分类情景中所面临的问题[1]。Erman 等[2]提出使用K-means 算法对单向流信息进行分类。Moore 等[3]改进了用于网络流分类的传统朴素贝叶斯算法,但该算法需要稳定的数据集,不适用于高速和不稳定的网络。雍凯[4]提出了决策树属性的权重评估,生成决策树时,通过优先选取权重较高的属性来提升单个决策树的分类性能。徐鹏等[5]提出利用训练数据的信息熵构建决策树分类方法,但该算法难以应用于高维样本。目前,国内外对网络流量异常检测与分类大多是在单机环境下进行研究,有限的资源难以胜任大数据时代下的大规模流量异常检测任务。
针对以上不足,本文提出了一种基于Spark平台的改进随机森林算法,对生成决策树的Bootstrap 抽样方法添加约束条件,降低非平衡数据对生成决策树的影响;同时,利用不平衡度和袋外数据对决策树进行加权,提高随机森林算法整体的分类准确率。
1 相关技术及方法
1.1 随机森林及Bootstrap抽样介绍
随机森林是一种由Breiman[6]提出的集成学习分类算法,该算法利用若干个决策树来对样本进行学习和预测,随机森林算法的分类原理为:
步骤1:在样本集中用Bootstrap 采样并有放回地抽取m个样本,产生一个新生成的子集,并在新生成的子集中选取所有特征中的s个特征,作为决策树的分离节点;
步骤2: 重复步骤1,直到得到n个决策树组成随机森林;
步骤3:将预测数据交给上一步骤中产生的随机森林中的每棵决策树进行预测,统计各个决策树的预测结果,最多决策树预测出的类别就是随机森林的分类结果。
1.2 抽样子集的不平衡度划分
随机森林算法使用的Bootstrap 重抽样方法每次抽取总体的三分之二作为一个训练样本,不断地重复这一个抽取动作,以期望用一系列大小为原训练样本三分之二的训练样本搭建出一个空间,通过这个空间来无限接近总体。
对于抽样子集的不平衡度定义如下:①假设数据集中的样本数为 |D|=M。S={(xi,yi) },i= 1,2,…,m,公式中xi满足xi∈X,X是维度为n的空间,X={f1,f2,…,fn},且yi∈Y,Y是样本的特征值,Y={1,…,C}。②定义数据集的不平衡系数为B:
其中:Smax和Smin分别为数据集的多数类样本和少数类样本,满足Smax∪Smin={S}且Smax∩Smin={∅}。
从这个角度可以把抽样得到的子集分为以下三种:①子集不平衡系数B′小于原数据集不平衡系数B。②子集不平衡系数B′大于原数据集不平衡系数B。③抽样子集中无少数类样本,即Smin不存在,子集不平衡系数B′无法计算。
以上三种情况在随机森林随机抽样中都会出现,其中②和③情况所得的抽样子集只会加重样本的不平衡性,通过这些抽样子集训练得到的决策树会干扰最终的投票效果。
2 基于Spark的改进随机森林算法及其并行化
2.1 基于约束条件的Bootstrap重抽样
针对以上的决策树子集不平衡问题,设计了一种基于约束条件的重抽样Bootstrap 算法。改进后的Bootstrap 抽样会过滤掉不平衡系数B′较大的子集,进而使不平衡数据集对生成的决策树产生的影响降低。基于约束条件改进后的Bootstrap重抽样流程如下:
步骤1:利用Bootstrap 抽样从数据集D 中抽取三分之二的数据样本;
步骤2:计算所抽取的数据子集的数据非平衡度B,并添加约束条件为数据子集的非平衡度小于或等于原数据集的非平衡度:
其中:D′max为抽样得到的数据子集中的多数类数据,D′min为抽样得到的数据子集中的少数类数据;
步骤3:若Bootstrap 抽样得出的数据子集满足约束条件,则可利用该数据子集来构造决策树。
2.2 改进随机森林算法的并行化建模
但在训练不平衡数据时,随机森林的精度和性能下降一直是该算法的应用局限性,本文提出了一种基于袋外数据和非平衡系数的加权随机森林算法。文献[7]研究了贝叶斯公式,得出了评估各个分类器性能的公式,将其中的con(i)用袋外数据的F1值代替,得出的加权公式为
其中:N为决策树分类器的数;F1(i)为第i个决策树分类器的袋外数据的F1 值;WOOB(i)表示根据袋外数据所求得的第i个决策树分类器的权值。
同时,将得出的各个数据子集的非平衡度B(i)作为权值的另一个要素:
综上所述,改进随机森林算法主要分为以下步骤:
(1)随机Bootstrap 抽样获取样本特征,计算不平衡度是否满足构建决策树的条件;
(2)利用Bagging抽样构建决策树;
(3)通过每棵决策树的袋外数据预测该决策树的F1值;
(4)利用分类器性能评价公式对各个决策树进行加权,并耦合成完整的并行化加权随机森林模型。
3 实验
3.1 实验环境及数据集
本文的实验环境由Windows11 平台上Vmware Workstation 安装的三台虚拟机组成,其中一台作为Master,两台作为Worker,系统为CentOS,Spark 版本为2.4.4,Hadoop 版本为2.7.1,使用的开发语言为Scala 2.13。
本文采用的数据集是加拿大通信安全机构和加拿大网络安全研究所发布的CIC-IDS-2018网络入侵检测数据集,数据集提供的流量模拟真实网络流量。CIC-IDS-2018 数据集中包括多种不同的攻击场景,攻击包含Brute Force FTP,Brute Force SSH,DoS,Heartbleed(OpenSSL 缺陷),Web Attack,Infiltration(渗透),Botnet(僵尸网络)和DDos。
3.2 评价标准
在分类任务中,一般使用精确率、召回率以及F1作为评价指标。为了便于介绍,用混淆矩阵来表示:TP表示实际与判定都为正类的样本;FP表示实际为负类,但被错误判定为正类的样本;FN表示实际为正类,但被预测为负类的样本;TN表示实际与判定结果都为负类的样本。

表1 混淆矩阵
精确率的数学公式为
召回率的数学公式为
F1综合考虑了召回率和精确率,公式为
3.3 实验结果
由表2可以看出,文中改进的随机森林算法在对CIC-IDS-2018 的分类上要优于传统RF 算法。综合来看,本文提出的改进随机森林算法利用了决策树的袋外数据和子数据集的不平衡系数,并通过加权来代替随机森林中相同权重的决策树投票,有效减少了随机森林中劣质树的干扰。

表2 文中算法与传统随机森林算法以及AUC值直接作为权重加权的随机森林算法比较
此外,得益于Spark 分布式平台的特性,算法的运行时间大幅度缩短,这是因为Spark 将文件读取进了内存,减少了对硬盘的频繁I/O 操作。以下为算法在Spark 分布式平台上与单机平台上的运行时间对比。
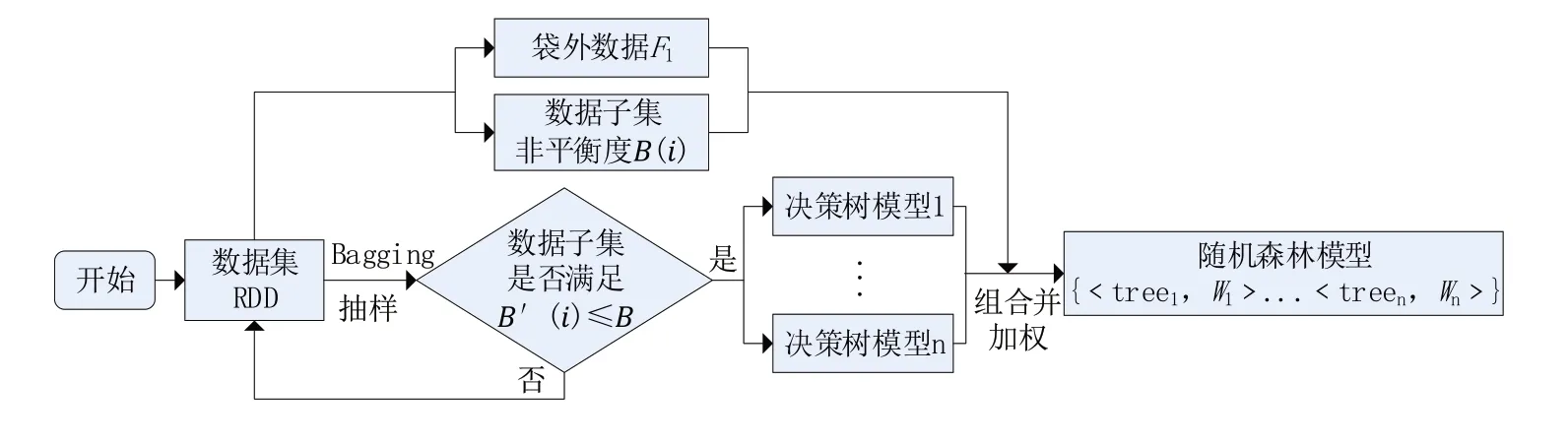
图1 改进的随机森林算法建模
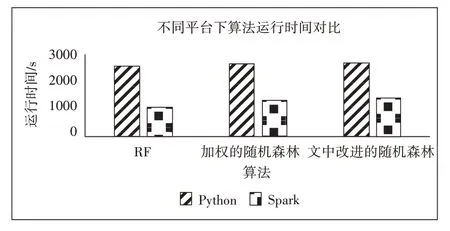
图2 不同平台下各算法运行时间对比
4 结语
本文提出一种基于Spark 的改进随机森林算法,先根据数据子集的不平衡度对决策树的生成过程施加约束,来改善随机森林分类算法对不平衡数据集条件下的适用性。接着采用加权投票的方式减少了随机森林中劣质树的干扰,提高随机森林算法的分类精度。实验结果表明,文中的改进随机森林算法在CIC-IDS-2018 数据集上的分类精度比传统随机森林算法更胜一筹。在以后的研究中,考虑将文中算法与分层抽样相结合,来进一步改善数据子集与原数据集样本类别的一致性。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
都市丽人(2015年4期)2015-03-20
