
数据同步机制自适应优化的HTAP 数据库原型系统
2023-09-22 01:09:10杨攀飞王清帅
华东师范大学学报(自然科学版) 2023年5期
俞 融, 杨攀飞, 王清帅, 张 蓉
(1. 华东师范大学 数据科学与工程学院, 上海 200062;2. 工业和信息化部电子第五研究所, 广州 511300)
0 引 言
近年来, 随着数据量的快速增长和实际数据应用对实时处理需求的增加, 学术界和工业界对兼具高效事务处理和实时分析处理数据库系统产品的期望越来越迫切. HTAP (hybrid transactional and analytical processing)数据库系统是指在同一个系统中同时执行事务处理和分析处理的数据库系统[1-2], 由于处理的高效性、数据迁移的低代价与运维管理的低成本使其获得了广泛关注. 在HTAP 数据库系统中, 事务处理负载OLTP (online transaction processing, 简写为TP)具有短时延、高并发、小规模的特点, 分析处理负载OLAP (online analytical processing, 简写为AP)具有长时延、操作复杂、大规模的特点, 它们在数据访问上的交叠使得资源使用产生竞争, 用户期望两类负载间的干扰尽可能少, 从而最大化各自的性能. 因此, 为了最大限度发挥HTAP 数据库系统的能力和数据处理的实时性优势, 关键的难点在于如何处理数据共享和资源隔离, 从而在实现负载相互干扰最小化的同时,让AP 读取的数据版本与TP 生成的大量数据版本保持一致(即高新鲜度), 以完成实时分析决策.
资源隔离与HTAP 数据库系统架构密切相关: 资源隔离程度越高, TP 和AP 之间数据共享的难度就越大[2]. 不同的数据库厂商提供了不同的解决方案[3-10], 大致可分为一体式架构的逻辑隔离、分离式架构的缓存隔离和存储隔离三大类[2,11-12], 通过在存储层、缓存层、事务层等不同层次的资源隔离,缓解资源竞争, 提升系统性能. 这3 种架构的数据库隔离处理方案, 虽然能够减少TP 和AP 之间的性能干扰, 但是影响了TP 向AP 同步数据、共享数据的方式. TP 和AP 之间存在的数据版本差距, 从本质上看, 是由于它们选择了不同一致性数据共享模型. 在HTAP 数据库系统中, 根据AP 读版本与TP 写版本差异可以分为3 种一致性同步模型. 线性一致性是TP 有更新就发送, AP 客户端在同一时刻所读取到的数据都是最新一致的; 顺序一致性是TP 更新按批发送, 各 AP 节点在同一时刻读到的数据一致, 但不保证最新; 会话一致性是不同 AP 端在同一时刻所读取到的数据既非最新, 也非完全一致, 但会话内的新查询确保能访问当前写入更新版本的数据[2-3]. 因此, 一致性模型的选择决定了HTAP 数据库读写版本的差距, 较强的一致性往往以牺牲整体性能的下降来换取数据同步对资源利用的提升, 从而提供给AP 任务更新鲜的数据版本.
现有的HTAP 数据库对于整体架构和一致性模型的选择往往采用固定模式, 即为了节约成本, 只选择一种一致性模型进行应用. 然而, 在实际场景中, 用户的不同应用可能有不同的一致性需求[13]. 例如在旅游应用软件的购票场景中, 用户下单购买火车票时需要实时确认最新的余票数量以避免出现超卖, 此时需要TP 与AP 之间保持线性一致性; 对于后台工作人员分析一小时或是一天购票量的统计, 则仅需要按批同步TP 修改更新, 适合使用顺序一致性同步模型; 对于用户行程、差旅酒店推荐等则只需要符合当前用户的会话逻辑, 使用会话一致性同步模型即可. 故而用户多样的一致性需求与架构采用固定一致性模型的矛盾, 使得数据库架构人员只能向上兼容, 为负载选择满足其最高新鲜度需求的同步模型.
通常情况下, 架构师会选择保守策略, 使用线性一致性来防止出现用户需求不满足的情况, 但是数据版本新鲜的高一致性模型通常以性能为代价换取, 使得HTAP 数据库系统的整体性能无法实现最大化. 因此, 为了提升HTAP 数据库系统的性价比, 根据应用自适应选择一致性同步模型是有必要的. 也就是说, 为了权衡性能与新鲜度, 可以通过调整系统一致性强度, 按需保证数据的同步机制, 提升整体性能.
本文期望实现一个能够根据负载动态自适应调整一致性级别的HTAP 数据库原型系统, 由于会话一致性利用缓存提升资源的利用率, 在系统中只能作为提升线性一致性和顺序一致性系统性能的辅助, 因此首先需要进行两种一致性同步方式的实现, 以线性一致性为基础, 向系统输入用户指定的负载一致性类型 (新鲜度需求) , 在达到统计指标阈值后向顺序一致性切换, 从而提升系统吞吐. 在实现过程中存在以下两个难点:
(1)切换过程中如何保证数据正确、在高效访问的同时实现同步粒度的动态调整问题, 将涉及对中间状态、信息收集维护代价的权衡;
(2)如何根据负载一致性分布构建切换决策代价模型, 实现同步模式的有效切换, 涉及负载一致性要求分布与切换频率之间的权衡.
本文主要有以下贡献:
(1)基于数据分片进行了分片顺序一致性同步和线性一致性同步自适应切换的设计;
(2)基于用户指定的查询一致性需求, 提出了一致性切换算法, 并提供切换前后同步数据的处理策略;
(3)实验验证了满足新鲜度要求的情况下, 采用一致性模型切换的方法能有效提升系统整体性能.
1 相关工作
关于一致性及其切换的研究已经有许多相关工作, 但大多集中在对分布式数据库复制服务和云服务的探索上, 如表1 所示. 分布式数据库中的一致性模型要求各物理(或多数)副本内容相同[14], 不关心读写版本的差异[2], 大多通过中间件来实现两种一致性之间连续变化的一致性要求. Lu 等[15]和Yu 等[16]提出了一种在分布式系统的复制服务中能够根据交互自适应地调整不同对象一致性级别的中间件, 以读写操作为粒度发现不一致并进行解决. 对于云服务而言, 数据的一致性是指可伸缩机器之间数据的一致. Gao 等[17]提出了适当放松系统一致性, 改变不同类型对象在服务器之间的复制同步策略换取性能的提升. Kraska 等[13]探索了如何在云存储上获得高可伸缩和低成本解决方案, 提出了根据云上应用对一致性需求的强弱分类调整各个节点数据的一致性, 能够有效实现系统整体吞吐的提升, 并提出根据冲突出现的可能性、系统运行时间长短、数据项的绝对值大小和更新频率等统计信息决定是否进行系统整体一致性的切换. 而HTAP 数据库系统中的一致是TP 和AP 数据版本间的一致, 当TP 写版本和AP 读版本出现差距时, 需进行有方向的数据同步.
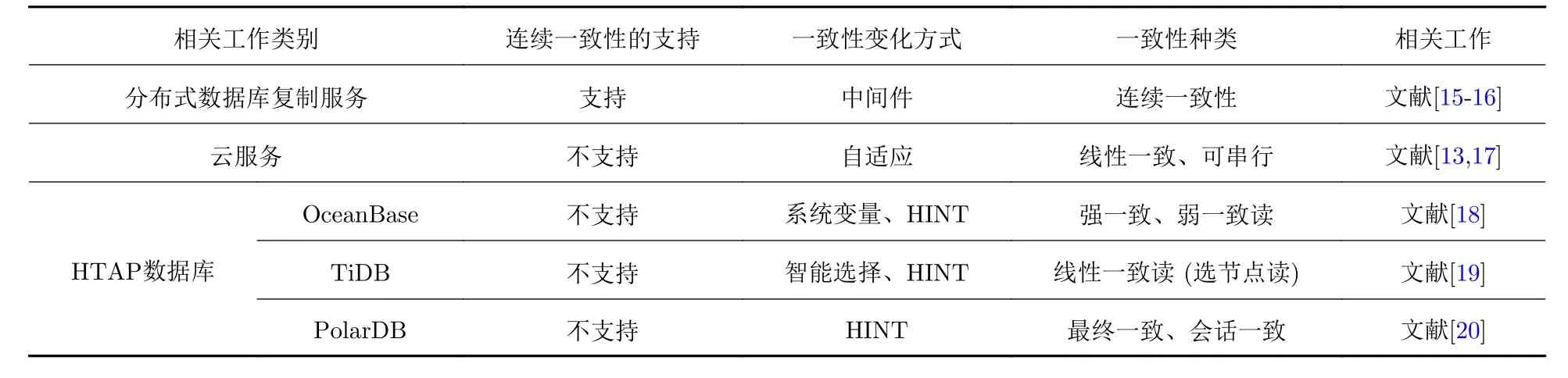
表1 一致性控制的实现对比Tab. 1 Comparison of related work implementation to consistency control
部分现有的开源HTAP 数据库系统也支持多种一致性. OceanBase[18]在全局线性一致性的同时提供对弱一致性读的支持, 也支持在提供全局使用最终一致性的基础上, 给予AP 查询路由到TP 上进行更新数据读取的可能, 但不建议使用查询请求路由到主副本执行的方案, 而是建议在备副本上重试多次失败后回滚, 避免写流量高峰和读流量高峰同时被引流到主节点上, 造成更大的问题. TiDB[19]根据查询指定到不同的副本上进行读操作, PolarDB[20]利用其自身物理复制速度快的优点, 将查询发给已经更新了数据的只读节点, 减少达成全局最终一致性的长时间等待. 虽然现有的数据库能够部分支持根据AP 端不同版本差进行一致性级别的调整, 但还未实现根据动态负载的自适应调整.
2 系统设计
2.1 整体架构
在满足用户新鲜度需求的情况下, 控制数据分片对时间戳的控制粒度, 改变底层存储分片中事务日志的同步方式, 从而改善全系统同时仅支持使用一种一致性带来的性能局限. 由此, 本文设计了一个能够自适应调节分片同步方式的HTAP 数据库原型系统.
2.1.1 系统架构介绍
系统整体架构如图1 所示, 数据在HTAP 数据库系统中由TP 端事务并发执行产生, 相关日志由分片对应的日志应用控制器获取并在AP 端进行回放, 用户将指定一致性(新鲜度)要求的查询负载,在对应分片上完成执行. 自适应一致性通过数据分片标签表存储并标记数据分片的同步方式. 然后,由事务日志发送控制器、分片同步方式监控器、分片同步方式自适应决策器以及分片查询执行监控器四大组件协同完成一致性的自适应转换.
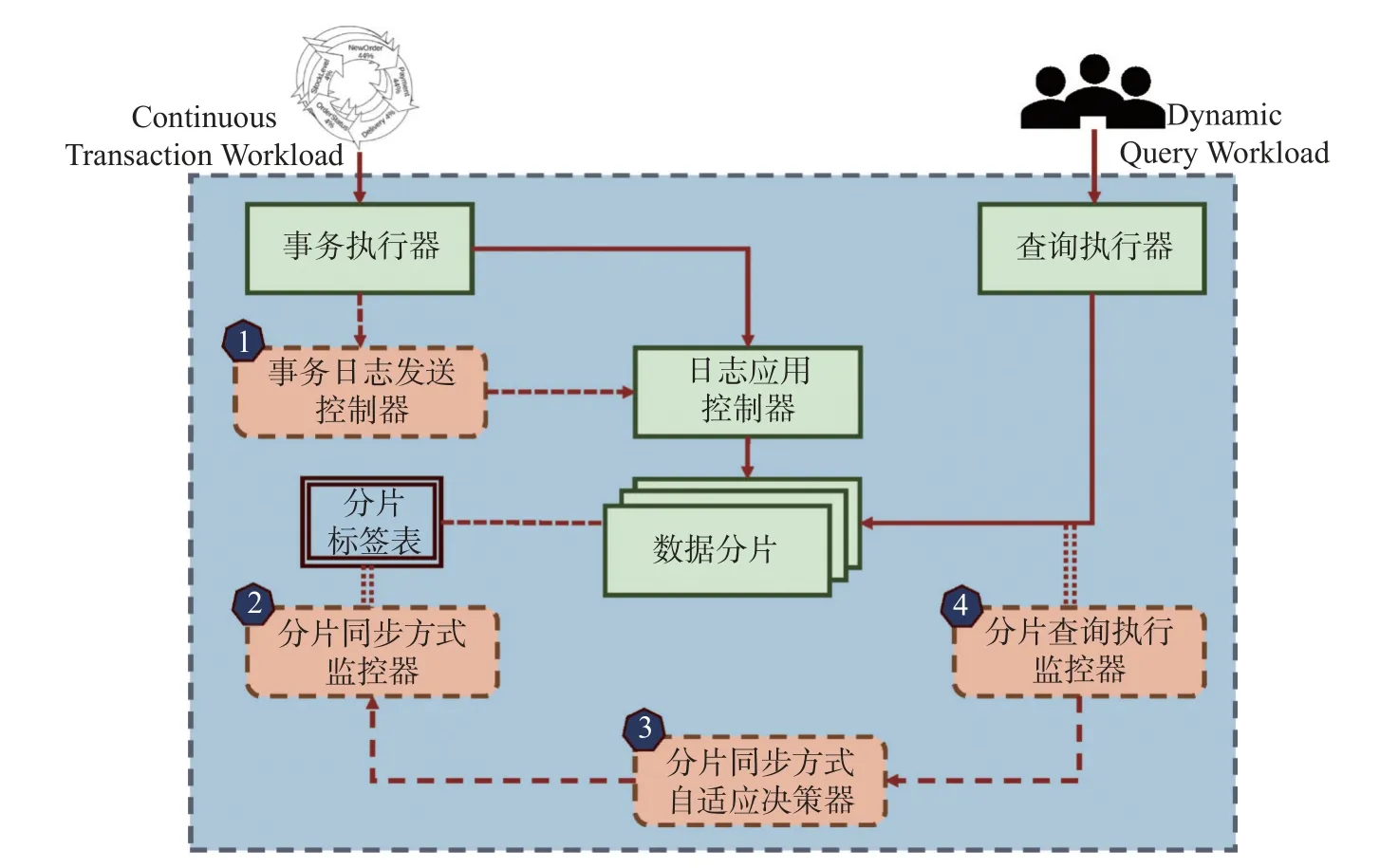
图1 系统整体架构Fig. 1 System operation process architecture diagram
事务日志发送控制器: 该组件控制事务日志向AP 端同步的频率, 控制器向分片标签表发起询问,查看所在分片的数据同步模型, 若是按照线性一致性的方式, 则每隔最小的时间间隔发送日志到对应AP 副本的缓冲区后, 再继续进行下一个单位的同步; 若是以顺序一致性的方式, 则同一时间间隔内的日志以批为单位进行同步和应用.
分片同步方式监控器: 该组件监控数据分片同步标签表内容是否发生变化, 在同一分片标签频繁发生变化时, 及时获知并进行示警.
自适应决策器: 该组件完成代价评估与决策判定, 通过综合判断各个分片上查询的一致性压力与分片本身同步压力的情况, 决策出各个分片是否需要进行TP 端数据同步方式的修改, 若需要变动,则由该组件对分片标签表对应内容进行修改, 支持分片同步方式的自适应调整.
分片查询执行监控器: 在AP 端, 用户查询以带有新鲜度要求的一致性标签方式, 将查询分发到其对应的分片上, 该组件的功能是对各分片上不同一致性需求查询执行的监控和统计.
2.1.2 分片设计
为了更好地应对大规模数据和高并发负载, 避免集中式架构可能面临的性能瓶颈和可扩展性限制, HTAP 数据库系统多采用分布式架构, 将数据分布式地存储到不同的节点, 使得不同类型的负载请求能够互不干扰地进行并行处理. 现有HTAP 数据库系统同步模式的管理是以日志或数据为单位进行的, 对整个数据库实行全局统一管理. 数据的分片存储和管理能够使得系统在同步时, 提升同步的效率. 本文基于采用分片策略的HTAP 数据库系统, 设计一致性同步和变换.
如图2 所示, 情况1 表示当大量顺序一致性需求的查询执行在基于线性一致性同步的分片上时,为了降低同步代价和提升响应速度, 将该分片的同步模式从线性同步转变为顺序同步模式; 情况2 表示当负载需要满足线性一致性需求同时访问分片B 和C 的数据时, 分片C 根据同步代价做出是否进行同步模式切换的决策.

图2 基于数据分片的一致性切换示意Fig. 2 Synchronization switching on data sharding
2.1.3 查询格式
输入的查询需要确定其与用户需求新鲜度之间的关联关系, 用户对负载的一致性需求决定了查询返回的数据新鲜度, 即查询读取版本和事务最新写版本之间的差距. 本文通过设定特定结构体实现对输入查询的一致性需求进行指定, 图3 展示了查询请求格式样例. 在实现中, 通过使用向量的方式完成对输入查询一致性的指定, 同时, 由于使用分片的方式管理数据, 每个机器上可能保存部分数据和备份. 给定一个分片, 查询以哪种一致性协议进行分片访问体现在向量的取值中. 假设qi表示第i个查询的执行向量, 数据库系统具有k个分片(即向量维度), 其中每个维度的取值ci ∈{-1,0,1}, 其中, –1 表示查询需要线性一致性, 1 表示查询需要顺序一致性, 0 表示查询不扫描该分片的数据.

图3 查询请求格式Fig. 3 Query request format
qi的执行向量:
负载集W的执行向量可以表示为
当用户对查询的一致性需求发生变化时, 负载向量的取值可能会变化, 权衡切换分片带来的数据同步压力与系统整体性能的提升情况最终产生执行向量.
2.2 切换策略
在HTAP 数据库系统中, 实现对分片数据同步方式的自适应切换, 关键在于寻找系统中性能和一致性模型切换代价的权衡点, 并做出合适的决策判断, 即根据模型切换代价的估算, 确定数据分片的同步方式. 通过对切换后分片上查询负载性能提升量和分片进行转换时查询等待时间的估计, 根据所获得的正向收益数值大小决定是否进行分片同步方式的转变.
2.2.1 代价建模
在HTAP 数据库系统运行过程中, 同一分片上可能运行着多个不同一致性需求(新鲜度)的查询,分片同步方式的切换会引起分片上不同类型查询在新鲜度和查询响应代价上的变化.
HTAP 数据库系统中TP 端事务的写入较快, 版本号通常快于AP 端. 在线性一致的同步方式中,AP 选择全局最大的时间戳号进行读取, 需要保持最强的一致性和最高的新鲜度, 因此在AP 端, 查询会等待应读版本前发生的所有TP 写日志同步到AP 端并完成回放之后才开始执行, 这部分的同步时间开销对查询的响应时间产生了较大的影响, 但保证了查询的一致性(新鲜度)需求. 在顺序一致的同步方式中, TP 端的更新按批实现同步, AP 端的查询选择AP 当前可读且最小(已完整同步)的epoch 号版本进行读取, 因此AP 端查询无需进行数据版本同步的延迟等待, 虽然读取的数据版本与当时TP 端的写入版本相比有一定的落后, 但是查询响应时间较快.
因此, HTAP 数据库系统需要根据代价情况进行建模, 并制定合理的分片切换策略, 从而实现新鲜度与性能之间的权衡. 查询响应代价是指从查询发起到查询结果返回所耗费的时间, 新鲜度代价是指查询真实执行版本与查询发起时TP 端最新写版本之间的版本差距. 为了使得新鲜度和查询响应在同一维度具有可比较性, 需要将它们统一成可比较的时间延迟或者版本差距. 在AP 端保持恒定日志应用速度的前提下, 新鲜度的版本差距使用版本同步所耗费的等待时间来表征.
由于查询负载是用户指定的, 每个查询的一致性(新鲜度)要求以及执行查询的分片是由负载指定的, 很容易出现分片同步方式和分片查询一致性需求不一致的情况, 数据库存储通过感知负载的一致性自适应调整同步方式, 分片的同步方式是否转换由两部分代价之间的大小关系决定, 即性能或新鲜度的延迟提升量和分片切换等待时间. 分片的同步方式决定了分片上查询执行的读写版本差距, 顺序一致同步下的查询返回给AP 端当前已完整的最小可读版本, 线性一致同步下的查询则是等待最大应读版本同步完成后返回给AP 端, 它们和查询本身的一致性要求是存在差异的, 只需在用户可容忍的新鲜度阈值范围内则是可接受的. 因此, 在保证新鲜度满足阈值的情况下, 可以通过代价模型判定是否切换分片的同步方式, 即是否在可行范围内降低某些查询的新鲜度换取分片上所有查询响应时间的缩短, 图4 展示了查询延迟与分片一致性切换等待权衡示意图.
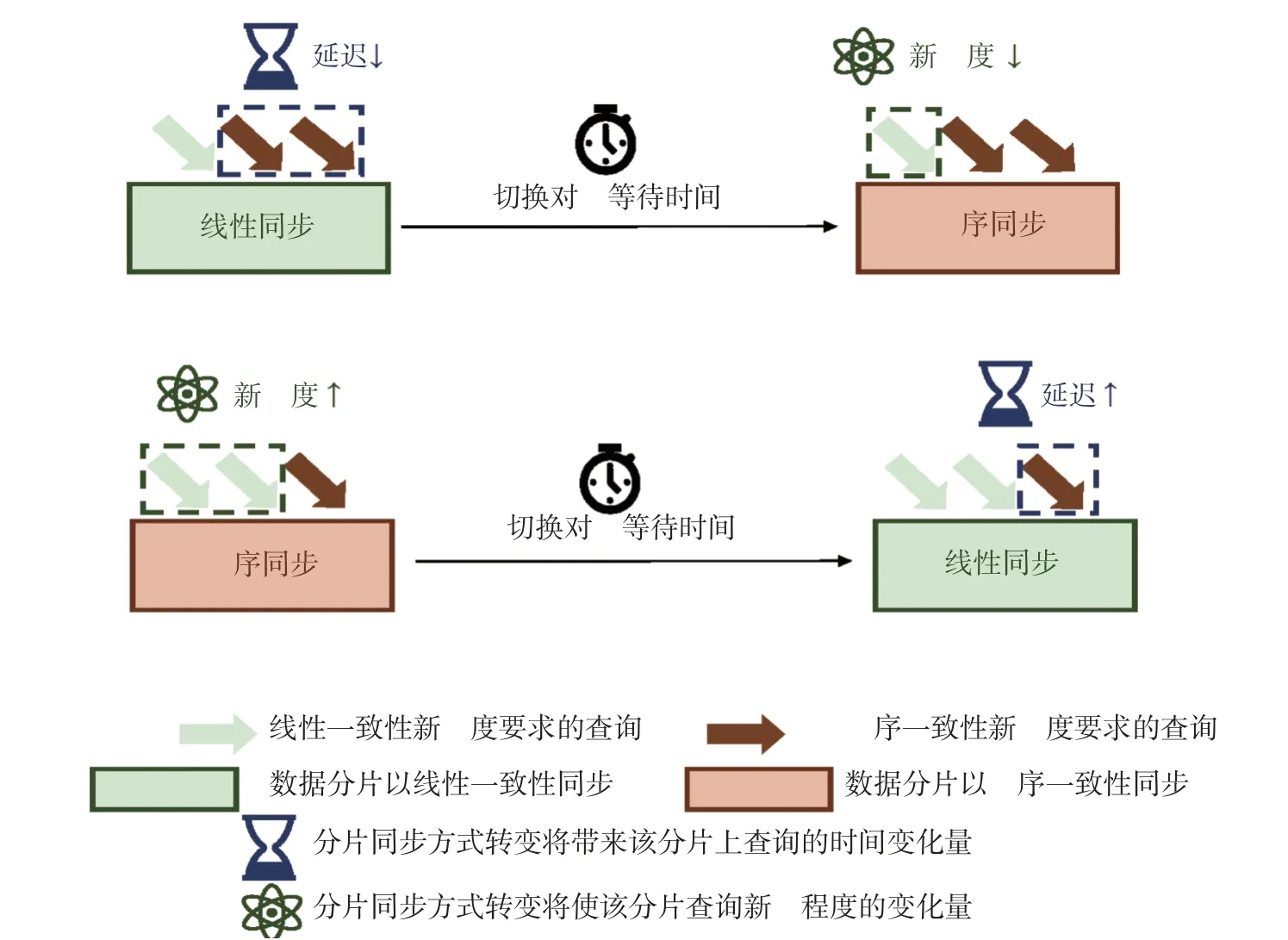
图4 查询延迟与分片一致性切换等待权衡示意Fig. 4 Query latency changing vs. slice consistency switching latency
以单个分片为例, 查询的一致性需求与分片同步方式不一致的情况共有两种. 一种是存在部分顺序一致性需求的查询在线性同步分片上执行, 它们执行在线性一致新鲜度的数据版本上, 高于顺序一致性的需求, 存在新鲜度过剩的现象, 而且由于这种同步方式需要等待分片完成所需版本的同步之后才能继续读取, 延长了顺序查询的响应时间. 因此, 若分片同步方式从线性转变成顺序, 那么在满足一定新鲜度牺牲范围内, 顺序一致性要求的查询响应延迟将显著降低, 当分片切换对齐等待的代价小于查询响应时长提升的收益时, 推荐进行分片同步方式的切换. 另一种是部分线性查询在顺序同步分片上执行时, 它们的执行返回版本是顺序一致批同步已完成的最小版本, 虽然查询响应的时间非常短,但是降低了线性查询的一部分新鲜度. 若分片同步方式从顺序变成线性, 那么线性查询执行的版本新鲜程度将显著提高, 少量顺序一致性需求的查询在线性同步分片的执行延迟会有一定上升, 当分片切换等待所付出的延迟代价小于分片上所有查询引起的延迟提升收益时, 推荐切换.
由于分片同步方式切换引起分片上所有查询整体时延的变化, 定义查询时延变化量=新鲜度变化量 + 同步等待延迟变化量, 查询一致性转变性能提升代价与当前分片的同步类型以及分片上不同类型查询的数量有关; 分片同步模型切换时面临时间戳号 (或epoch 号) 对齐的问题, 由此产生了分片切换等待代价.
当AP 负载中查询的一致性需求发生变化或是分片上存在部分查询与存储分片同步方式不一致时, 需要判定分片的同步方式是否需要发生变化, 而判定的关键在于估计分片上查询在底层同步方式变化后可以获得的查询整体时延提升量.Qi表示查询i从线性同步切换成顺序同步时的读版本的等待时间,Q′i表示查询i从顺序同步切换成线性同步时的查询等待时间, 因此, 式(1)和式(2)分别表示22 个查询线性同步和顺序同步切换的向量.
由于每个查询在不同分片上并行执行, 负载集执行向量W的每一项ci,k决定了查询i是否在第k个分片上执行, m ax{Qi×ci,k}表示查询i在k个分片中最长的同步切换耗时, 从线性到顺序切换时该值为正, 而从顺序到线性切换时该值为负,⊗表示向量运算, 可得到各个查询的同步耗时结果C.
由于在线性向顺序切换的过程中, 线性一致性需求的查询以满足新鲜度为前提, 其新鲜度变化量不计入, 查询延迟变化量以同步等待延迟为主; 而顺序向线性切换的过程中, 顺序一致性需求的查询同步等待代价与新鲜度提升量相比, 数量级很小, 可忽略不计. 因此, 分片上所有查询整体延迟变化量Tlatency为式(3)向量C中各维不为零的同步延迟量之和.
分片切换等待的时间Twait与本地时间戳完成对齐所需的等待时间有关, 即等待递增的本地时间戳计数器Elocal按照原方式(线性间隔或顺序epoch 间隔)增加至Eseq(或Elinear)的整数倍,E′表示对齐完成的时间戳计数器.
式中:t(E′-Elocal) 表示一个t() 函数.
2.2.2 跨分片读
当某类一致性需求的查询涉及多个不同同步类型分片时, 同步策略需要进行基于查询负载的协商, 如图5 所示, 上下两张图分别表示顺序一致性查询和线性一致性查询运行在不同同步方式分片时可能的两种协商方式, 具体需要根据2.2.1 节中提及的代价模型计算分片上查询的切换前后获得的正负收益情况后得出.
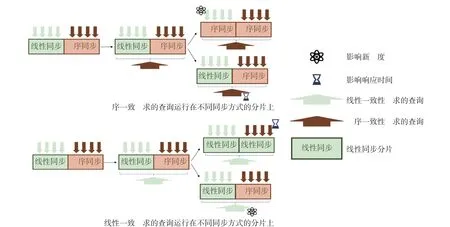
图5 跨分片查询协商示意Fig. 5 Cross-shard query negotiation diagram
2.2.3 切换等待对齐策略
在底层存储分片的同步方式发生转变时, 由于线性一致同步的时间戳粒度远小于顺序一致同步的时间戳粒度, 因此, 在切换时, 需要进行时间戳号的对齐, 算法示意图见图6, 具体细节见算法1.

图6 切换等待对齐算法示意Fig. 6 Schematic diagram of switching wait alignment algorithm
epoch 通常是指时间戳粒度, TP 端以epoch 大小的时间间隔发送日志给AP 端. 算法1, 首先获取开始时间(行1), 对分片同步方式监听的程序持续运行(行2), 算法根据分片标签值确定不同分片采用多大的时间戳间隔进行信号的发送, 由于每到达一次同步时间间隔, 程序将仅为指定一致性同步方式的序号增加一次计数 (线性一致性同步版本由线性同步时间戳计数器E0指示, 线性同步间隔为Ilinear,顺序一致性同步版本由顺序同步时间戳计数器E1指示, 顺序同步间隔为Iseq) . 如果当前分片为顺序一致性同步方式(行3), 首先需要判定本地Elocal号与顺序同步E1号是否一致(行4), 若一致, 则以顺序一致的时间间隔向对应AP 副本所在机器发送日志(行16—21); 若不一致, 说明当前分片上一次epoch 号的发送是通过线性一致性同步发送的, 需要以线性一致性的间隔完成未到达下一个顺序epoch 号的剩余线性一致时间戳日志的发送来实现对齐, 直到本地时间戳计数器Elocal到达顺序一致性的间隔号整数倍位置(行12), 避免出现正确性问题(行6—11).
反之, 当前分片则是以线性一致性同步的方式进行时(行22), 同理首先需要判定本地Elocal号与线性同步E0号是否一致(行23), 若一致, 则以线性一致性的时间间隔向AP 副本所在机器发送日志(行27—32); 若不一致, 则说明分片同步方式刚从顺序一致同步方式中切换过来. 在这种方式下, 由于线性一致时间戳的粒度为1, 仅需使本地时间戳计数增加一次计数即可实现对齐(行23—26).

算法1 分片切换后时间戳连续性保证的一致性间隔对齐算法输入: 线性同步时间间隔Ilinear顺序同步时间间隔Iseq分片本地epoch 号计数器Elocal线性同步时间戳计数器E0
3 实 验
3.1 实验设置
实验基于Vegito[21]代码进行扩展和改造, 在3 台96 核双路Intel Xeon 处理器, 374 GB 内存、x86_64 架构的计算机上进行, 每台计算机配置有MLNX_OFED_LINUX-5.8-1.0.1.1 版本驱动的ConnectX722 10GbE 的IB 网卡, 操作系统为CentOS 7.9, 每组实验使用8 个TP 线程和6 个AP 线程运行60 s 得到, 所使用的HTAP 负载由5 个TPC-C 事务和22 个改装的TPC-H 负载组成.
3.2 实验结果及分析
3.2.1 不同一致性同步的差异对比
实验部分, 首先验证了适配TPC-C 表模式后的22 个查询在不同同步模式下的计算和同步的时间, 如图7 所示, 堆叠图中黄色柱状部分表示查询的计算时间, 蓝色部分表示该查询经历的同步时间,全柱高表示查询的响应时间. 从图7 中, 可以发现线性一致的同步延迟明显高于顺序一致的同步延迟,顺序一致同步时长的数量级为10–3, 几乎可忽略不计.
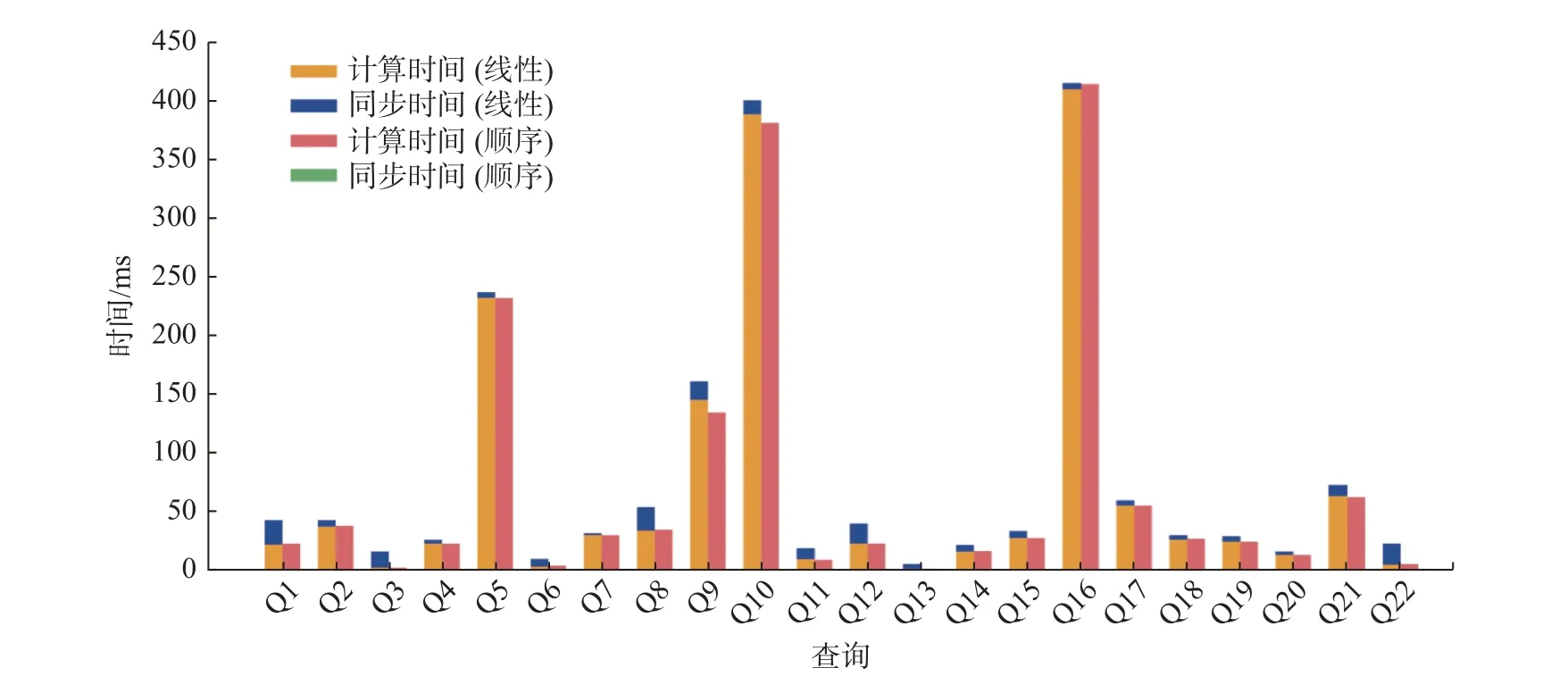
图7 分片使用不同一致性同步时查询的计算延迟与同步延迟对比Fig. 7 Computational latency versus synchronization latency of queries when sharding uses different consistency synchronization
通过对各查询的多次运行, 统计发现不论使用何种同步模式, 查询的计算执行延迟数值均相近.同时结合图7 分析, 在AP 负载运行20 s 后进行分片同步模式从线性到顺序的切换, 并统计了平均值的统计, 结果如表2 所示, 将该表的值作为每个查询预估的同步模式转变的性能提升值, 同理, 分片同步模式从顺序到线性切换的平均延迟结果如表3 所示.

表2 查询负载一致性需求从线性到顺序切换的平均代价表Tab. 2 Average cost table for query load consistency demand switching from linear to sequential

表3 查询负载一致性需求从顺序到线性切换的平均代价表Tab. 3 Average cost table for query load consistency demand switching from sequential to linear
3.2.2 自适应策略的有效性
对于分片同步方式从线性到顺序自适应策略的有效性, 设计了表4 所示3 组变化的负载进行验证, 实验得到的查询延迟结果和同步时间情况对比如图8 所示.

图8 分片同步方式从线性到顺序自适应的3 个实验结果Fig. 8 Three experimental results of adaptive shard synchronization from linear to sequential

表4 查询负载从线性到顺序自适应切换的结果Tab. 4 Results of query workload consistency adaptive switching from linear to sequential
根据负载设计, 仅第3 组实验的负载不会引起分片同步模式的改变, 从图8(a)的结果中发现该组查询的响应时间均比前两组长, 但确实是其对性能和一致性进行权衡后的选择. 在对其同步延迟更细致的分析中, 实验组3 延用线性一致的同步方式, 相对前两组实验的同步延迟略高, 符合预期. 更进一步, 从图8(b)中可见, 实验组3 由于未进行分片同步方式的切换, 有着比其他两组明显更高的同步延迟.
同理, 通过对分片同步方式从顺序到线性的自适应策略有效性设计了表5 所示的负载进行验证,第一组为不开启自适应策略的对照组, 实验结果如图9 所示.

图9 分片同步方式从顺序到线性自适应的4 个实验结果Fig. 9 Four experimental results of adaptive shard synchronization from sequential to linear

表5 查询负载从顺序到线性自适应切换的结果Tab. 5 Results of query workload consistency adaptive switching from sequential to linear
根据表5 中第2、3、4 组切换的预期结果与实际结果可知, 系统的自适应策略是正确且符合预期的, 从图9(a)的结果中可见, 与对照组相比, 大部分查询实现查询延迟比不使用自适应策略小或者绝对数值变化小, Q16 查询延迟的提升相对较为明显, 图9(b)中每个查询均有4 个图柱, 其中实验组1 和实验组4 的同步实验数值很小, 而在同步延迟结果对比中可见, 同步方式从顺序向线性切换时的对齐代价明显小于从线性向顺序切换, 但与不切换相比, 分片切换等待的延迟是不可小视的.
4 结束语
本文通过构建权衡性能与新鲜度的代价模型, 实现了在顺序一致性同步与线性一致性同步上, 自适应调整数据分片的一致性同步方式, 提升了整体性能, 实现自适应调整一致性级别的HTAP 原型系统, 提出了一致性切换算法和切换前后同步数据的处理策略, 最后通过实验进行了自适应切换的有效性验证.
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
火控雷达技术(2018年4期)2019-01-15 05:07:22
电子测试(2018年14期)2018-09-26 06:04:24
制造技术与机床(2017年4期)2017-06-22 11:18:07
电信科学(2016年10期)2016-11-23 05:12:00
核科学与工程(2016年3期)2016-01-03 07:22:33
食品工业科技(2014年13期)2014-03-11 18:16:43
食品工业科技(2014年13期)2014-03-11 18:16:40
