
基于CLIP 生成多事件表示的视频文本检索方法
2023-09-22 06:22涂荣成毛先领孔伟杰蔡成飞赵文哲王红法黄河燕
计算机研究与发展 2023年9期
涂荣成 毛先领 孔伟杰 蔡成飞 赵文哲 王红法 黄河燕
1(北京理工大学计算机学院 北京 100081)
2(北京大学信息工程学院 广东深圳 518055)
3(浙江大学电子信息学院 杭州 310058)
4(华南理工大学软件学院 广州 510006)
5(中国科学院自动化所 北京 100190)
(tu_rc@bit.edu.cn)
随着互联网上视频文本数据的日益增多,如何检索视频、文本[1-6]以及如何对视频、文本中的信息进行挖掘[7-11]等任务成为了人们日常生活中的新需求.视频文本间的检索作为多模态视觉和语义理解的一项基础研究任务,近年来受到了越来越多的研究者关注.现有的视频文本检索方法依据视频模态输入数据类型的不同主要可以分为基于原视频像素以及基于视频特征的检索方法.
基于原视频像素的这类方法[12-19]在训练模型时直接将原始视频作为输入,通过利用视频文本对匹配信息,将视频特征提取以及视频文本间相似性计算联合起来训练.早期的大部分视频文本检索方法主要是属于这类方式.近年来,在大规模视频-文本数据集(如Howto100M[20])上预训练好的模型表现出了强大的视频特征提取能力,因而基于视频特征的视频文本检索方法[1-6]应运而生.该类方法通过将预训练模型作为视频特征提取器来为每个视频提取好特征,并将提取到的特征作为视频模态的输入以训练视频文本匹配模块.由于预训练模型已在大规模数据集上训练至收敛,这些模型已能较好地将视觉中的语义概念以及文本中的语义概念进行对齐,因此用它们作为特征提取器能使所提取的数据特征更好地连接视觉和语言模态并包含丰富的语义信息,更利于训练检索模型.所以基于预训练模型的视频文本检索方法往往具有较快的训练速度以及出色的检索效果.但由于在训练视频文本检索模型时预训练好的视频特征提取器将不会参与训练,即其参数在训练时不会被更新,因而该类方法往往受限于预训练好的视频特征提取器的能力.
为了进一步提升视频文本检索的效果,如何将预训练模型与原始视频相结合作为输入是一个重要的研究方向.近年来,有些工作开始使用原始视频作为输入预训练视频文本检索模型.这些方法的主要难点在于如何解决稠密视频输入所带来的高计算量问题.为解决该问题,Lei 等人[12]提出ClipBERT 通过采用稀疏采样策略,使端到端预训练模型成为可能.具体来说,该方法在每个训练批次中仅从视频中稀疏地采样1 个或几个短片段作为视频输入以训练模型,最终实验结果表明,这种端到端训练方式有利于低层特征提取,并且少量稀疏采样的视频片段足以解决视频文本检索任务.虽然这些方法的效果相比于以前的工作取得了不错的提升,但受限于预训练模型的文本视频数据集的规模或其标注质量,这些方法的效果仍然难以满足用户对检索精度的需求.
近年来,在大规模数据集上预训练的图文匹配模型—对比图文预训练(contrastive language-image pretraining,CLIP)[21]受到很多研究者的关注.该模型提出的CLIP 方法在从网络中收集到的4 亿条图文对中进行预训练.因其训练数据规模巨大,该模型相比于同时期的预训练模型具有更强的视觉、文本语义概念对齐能力,在多个视觉-语言跨模态任务上表现出了更强的泛化能力,例如在zero-shot 图片文本检索任务上相比其他预训练模型能取得更好的检索效果.因此,目前有些工作开始研究如何将图文预训练模型CLIP[21]所学到的知识转换到视频文本检索模型中以提升视频文本检索效果.这些方法一般是基于全局特征的哈希方法,如图1 所示,它们将视频和文本分别映射成全局特征表示,进而利用全局特征表示计算视频、文本间的相似性关系.例如,由Luo 等人[17]提出的CLIP4Clip 通过在检索数据集上微调预训练模型CLIP 来将视频文本映射到同一个特征空间,然后在检索时每个视频以及文本都被映射成1个全局特征向量,只需计算视频特征与文本特征之间的点积得到视频文本之间的相似度,进而找出匹配的数据点.然而,这些方法忽略了视频、文本数据都是由一个个事件组合而成,如图1 所示,这一视频文本对可以概括成“倒水入锅中”“倒番茄酱”“搅拌食物”3 个事件.因此,若我们将视频和文本中的事件表示出来,进而计算视频事件与文本事件间的细粒度关系,然后以此更为精准地计算出文本数据与视频数据之间的语义相似性关系,进而提升文本视频间跨模态检索效果.

Fig.1 Difference between our proposed CLIPMERG and existing methods图1 本文所提的CLIPMERG 与现有方法的区别
因此针对上述问题,本文提出了一种基于CLIP 生成多事件表示的视频文本检索方法(CLIP based multievent representation generation for video-text retrieval,CLIPMERG),模型框架图如图2 所示.该模型首先通过利用大规模图文预训练模型CLIP 的视觉编码器(ViT[22])以及文本编码器(Tansformer[23])分别将视频、文本数据转换成视频帧token 序列以及文本的单词token 序列,而后通过视频事件生成器(文本事件生成器)将视频帧token 序列(单词token 序列)转换成k个视频事件表示(k个文本事件表示).最后,通过挖掘视频事件表示与文本事件表示之间的细粒度关系以定义视频、文本间的相似性关系.通过在3 个常用的公开视频文本检索数据集MSR-VTT[24],DiDeMo[25],LSMDC[26]上的大量实验结果表明,本文所提的CLIPMERG 优于现有的视频文本检索方法.
1 相关工作
视频文本检索是一项被广泛应用于现实生活中的多模态检索技术,其旨在对于给定的输入文本(视频)在视频(文本)数据库中查找与其相似的视频(文本)数据.现有的视频文本检索方法依据视频模态数据输入形式可以被分成基于视频特征的视频文本检索方法以及基于原视频像素的视频文本检索方法.
基于视频特征的视频文本检索方法[1-6]通过将预训练模型作为视频特征提取器来为每个视频提取好特征,并将提取到的特征作为视频模态的输入以训练视频文本匹配模块.这些预训练模型在大规模视频-文本数据集(如Howto100M[20])上预训练好,具有强大的视频特征提取能力,因而这类方法往往能取得不错的检索效果.例如Gabeur 等人[4]提出MMT(multi-modal transformer),该方法通过利用在大规模数据集Howto100M[20]上训练了多个模态的特征提取器,如视频模态、文本模态以及音频模态等.而后用这些预训练好的提取器提取视频、文本数据的特征以进行视频文本间的检索,此外,Patrick 等人[5]提出SSB(support-set bottlenecks),该方法通过为每个数据文本对选择支持集并根据支持集中的数据加权组合以重构文本来提升预训练模型的表征能力,进而提升模型在视频文本检索任务上的检索效果.然而,由于这类方法在训练视频文本检索模型时,预训练好的视频特征提取器将不会参与训练,即特征提取器的参数在训练时不会被更新,因而该类方法往往受限于预训练好的特征提取器的表征能力.
基于原视频像素的这类方法[8-15]在训练模型时直接将原始视频作为输入,通过利用视频文本对匹配信息,将视频特征提取以及视频文本间相似性计算联合起来训练.该类别中,早期的工作如Yu 等人[15]所提的h-RNN(hierarchical recurrent neural networks)在训练时使用原视频作为输入导致计算复杂度极高,因而使其训练速度十分缓慢,难以在较大规模的数据集中训练,最终使其检索效果往往不如基于视频特征的视频文本检索方法.另外,Bain 等人[16]提出Frozen 模型,该方法将1 张图片视为单帧视频,并设计了课程学习计划使得模型能在图像和视频数据集上进行训练.此外,最近由Radford 等人[21]提出的在大规模的图片文本数据集上预训练的图文匹配模型CLIP 在多个视觉-语言跨模态任务上取得了令人印象深刻的效果,展现了强大的视觉、语言特征提取能力,因此,目前有些工作开始研究如何将图文预训练模型CLIP 所学到的知识转换到视频文本检索模型中以提升视频文本检索效果.例如,由Luo 等人[17]提出的CLIP4Clip,这个方法通过在检索数据集上微调预训练模型CLIP 以将视频文本映射到同一个特征空间,然后在检索时每个视频以及文本都被映射成1 个全局特征向量,只需计算视频特征与文本特征之间的点积得到视频文本之间的相似度,进而找出匹配的数据点.之后,Cheng 等人[18]又提出CAMoE,该方法通过从数据点的实体、动作以及全局3 个视角计算视频文本之间的相似性关系以提升模型的检索效果.
然而,文献[8-18]所提的方法忽略了视频、文本数据都是由一个个事件组合而成.倘若我们能捕捉视频事件与文本事件之间的细粒度关系,这将能帮助模型更好地计算文本数据与视频数据之间的相似性关系,进而提升文本视频间跨模态检索效果.因此,为解决这一问题,本文提出基于CLIP 生成多事件表示的视频文本检索方法.
2 基于CLIP 生成多事件表示的视频文本检索方法
虽然目前已有基于图文匹配预训练模型CLIP的视频文本检索工作被提出,但这些工作忽略了捕捉视频事件与文本事件之间的细粒度关系以辅助计算出更为准确的文本与视频间的语义相似性关系.因此,本文提出一种基于CLIP 生成多事件表示的视频文本检索方法CLIPMERG,其框架如图2 所示.
2.1 基本定义
2.2 视频的多事件表征学习
2.3 文本的多事件表征学习
2.4 基于事件特征的跨模态相似度计算
2.5 目标函数
本文使用对称交叉熵损失作为CLIPMERG 的目标函数L以优化模型参数,对称交叉熵损失定义为:
式(10)~(12)中L的下标V2T 表示视频检索文本,T2V 表示文本检索视频.式(12)是由2 个标准对比损失构成,其中对比损失LV2T的目标是使得视频vi与来自同一个视频文本对中的文本ti的相似性s(vi,ti)大于vi与来自其他视频文本对中的文本tj的相似性s(vi,tj);类似地,LT2V的目标是使得文本ti与来自同一个视频文本对中的视频vi的相似性s(vi,ti)大于ti与来自其他视频文本对中的视频vj的相似性s(vj,ti).因此,通过最小化式(12),将会使得匹配的视频文本对中的视频文本相似性s(vi,ti)大于来自不同视频文本对中的数据之间的相似性.
3 实验分析
3.1 实验数据及评价指标
我们在3 个公开视频文本数据集上进行实验,包括MSR-VTT[22],DiDeMo[23],LSMDC[24].这3 个数据集的详细划分如表1 所示.
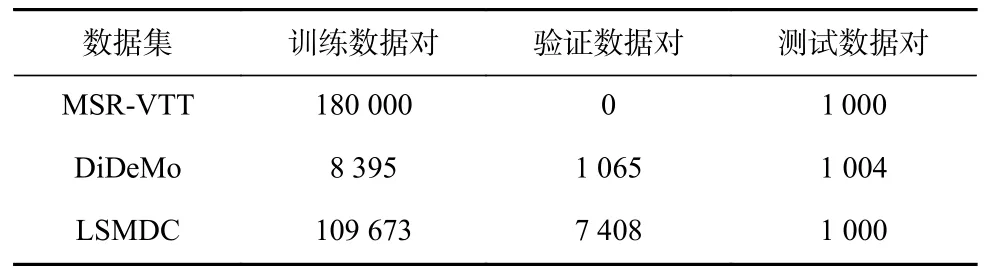
Table 1 Datasets Division表1 数据集划分
MSR-VTT 数据集包含了10 000 个视频,每个视频的时长在10~32 s 之间,且每个视频对应了20 个文本描述.对于该实验数据集的划分,我们采用与CLIP4Clip[13]一样的划分方式.具体地,我们使用其中的9 000 个视频及其对应的文本描述作为训练集,其中每个视频有20 个与其相对应的文本,因此训练集总共有18 万个视频文本对;测试集则用剩余的1 000 个视频以及其对应的文本构成1 000 个视频文本对.
DiDeMo 数据集包含10 464 个视频,每个视频有3~5 个句子描述.按照CLIP4Clip[13]的实验设置,我们将每个视频的所有句子描述,拼接起来作为整个视频的最终描述,并且我们用其中的8 395 对视频文本对作为训练集、1 065 对视频文本对作为验证集以及剩余的1 004 对图片文本对作为测试集.
LSMDC 数据集包含了118 081 对视频文本对,这些视频是从202 部电影中抽取出来的,并且每个视频的时长在2~30 s 之间.对于该数据集,我们用其中的109 673 对视频文本对作为训练集、7 408 对视频文本对作为验证集以及剩余的1 000 对视频文本对作为测试集.
本文使用标准的视频文本检索的评价指标R@K,MdR,MnR.其中,R@K表示返回前K个检索结果中包含与查询样本相关结果的查询点占总查询点数的比例,该值越高表示检索效果越好.在本文中主要考察R@1,R@5,R@10;MdR 表示返回结果中与查询点相关结果排名的中位数,该值越低表示结果越好;MnR 表示返回结果中与查询点相关结果排名的均值,该值越低表示检索效果越好.
3.2 基准模型及实验细节
我们将所提方法CLIPMERG 与MMT[4],SSB[5],ClipBERT[12],Frozen[16],CLIP4Clip[17],CAMoE[18],MDMMT[19],CLIP[21],HiT[28],TT-CE+[29],CE[30]进行了比较.其中:ClipBERT 提出了一个通用的端到端的视频文本学习框架,通过稀疏采样用部分视频片段来表示整个视频以训练模型;SSB 通过将跨实例间的视频描述生成任务作为辅助任务以拉近相似的视频、文本表示间的距离;HiT 通过考虑视频、文本间的层次信息来提升模型检索效果;CE 通过聚合不同模态预训练模型中的信息来辅助视频文本检索;MMT 通过利用原视频、音频等不同模态特征来对齐视频文本的表征;Frozen 将一张图片视为单帧视频,并设计了课程学习计划使得模型能在图像和视频数据集上进行训练;MDMMT 通过着重关注文本中有关动作的单词来提升模型检索效果;CLIP4Clip 通过在检索数据集上微调预训练模型CLIP 来将视频文本映射到同一个特征空间;CAMoE 通过从数据点的实体、动作以及全局3 个视角计算视频文本之间的相似性关系以提升模型的检索效果.
在实验过程中,本文方法对实验数据集的划分与CLIP4Clip 和CAMoE 方法的划分一致,故所有对比方法的实验结果均来源于文献[17-18].本文所提方法CLIPMERG 的视频编码器以及文本编码器的参数用预训练好的CLIP 模型中相应编码器的参数初始化,CLIPMERG 中的其他参数则随机初始化.设置视频、文本的事件数k=4.通过使用Adam[31]优化器优化模型,每次采样的批次大小为128,CLIPMERG 模型参数中,由CLIP 模型参数初始化部分的学习率为1E-7,其余部分的学习率为5E-5.
3.3 视频文本检索实验结果
为了评估本文所提出的基于CLIP 生成多事件表示的视频文本检索方法CLIPMERG 的有效性,我们分别在数据集MSR-VTT 上进行了文本检索视频任务以及视频检索文本任务实验,实验结果如表2所示.在数据集DiDeMo 以及数据集LSMDC 上进行了文本检索视频任务实验,实验结果分别展示在表3和表4 中.另外,在表2~4 中,除CLIPMERG 的实验结果均来源于CLIP4Clip.
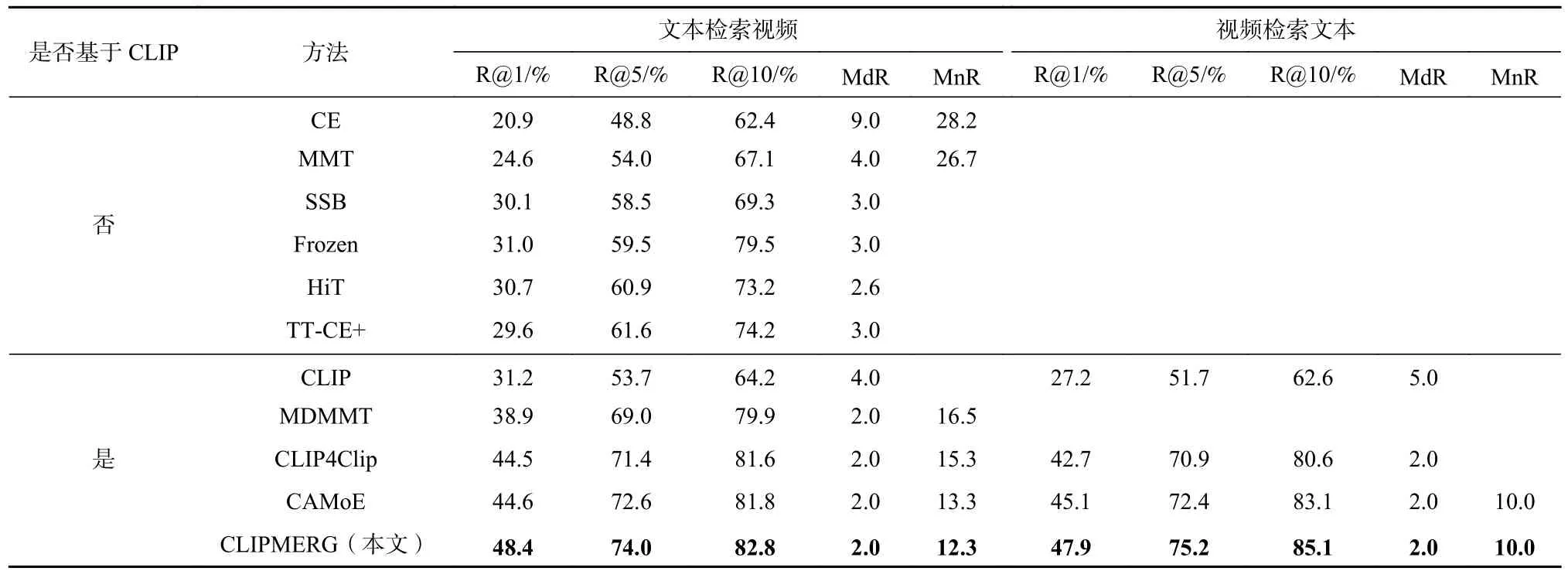
Table 2 Results of CLIPMERG and All the Baselines on MSR-VTT Dataset表2 CLIPMERG 与基准方法在数据集MSR-VTT 上的结果

Table 3 Results of CLIPMERG and All the Baselines on DiDeMo Dataset表3 CLIPMERG 与基准方法在数据集DiDeMo 上的结果
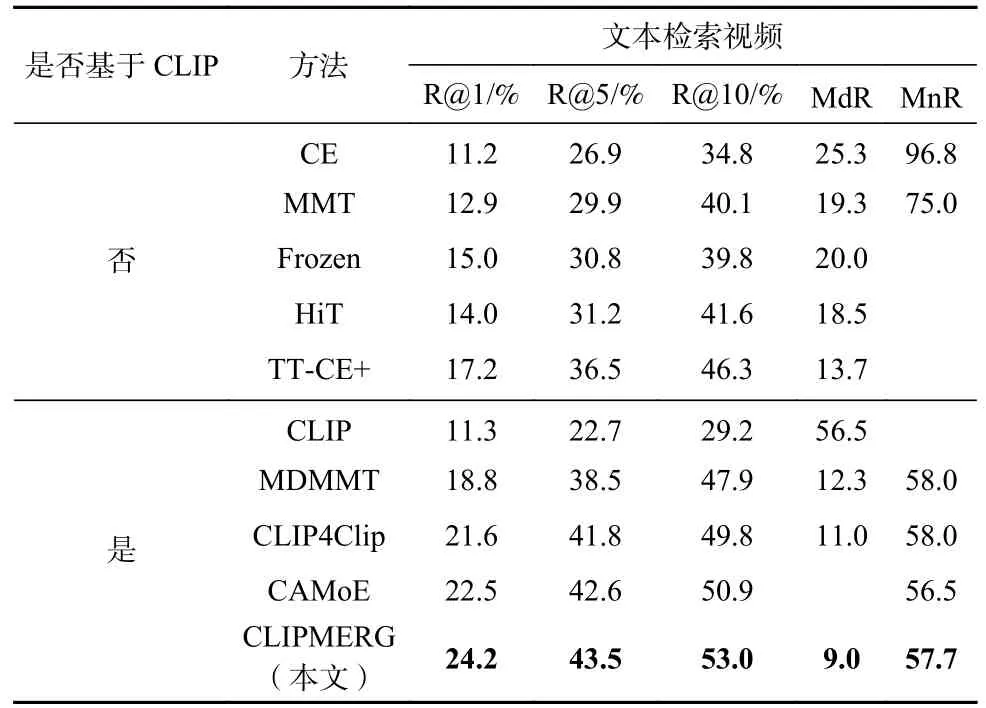
Table 4 Results of CLIPMERG and All the Baselines on LSMDC Dataset表4 CLIPMERG 与基准方法在数据集LSMDC 上的结果
由表2~4 的实验结果可知,CLIPMERG 视频文本检索方法能取得比现有方法更好的检索效果.如表2所示,在MSR-VTT 数据集上,本文所提方法CLIPMERG相比于实验效果最好的基准方法CAMoE,在文本检索视频任务的 R@1,R@5,R@10等指标上取得了3.8%,1.4%,1.0%的提升;在视频检索文本任务的R @1,R@5,R@10等指标上取得了2.8%,2.8%,2.0%的提升.如表3 所示,在DiDeMo 数据集上,本文所提方法CLIPMERG 相比于方法CLIP4Clip,在文本检索视频任务的 R@1,R @5,R@10,MnR 等指标上取得了0.9%,2.6%,1.3%,2.8 的提升.如表4 所示,在LSMDC 数据集上,本文所提方法CLIPMERG 相比于方法CAMoE,在文本检索视频任务的 R@1,R @5,R @10等指标上取得了1.7%,0.9%,2.1%的提升.表2~4 充分表明,本文所提方法CLIPMERG 通过利用预训练模型CLIP 为视频文本分别生成事件表示来定义视频文本间相似性的方式比现有的视频文本检索方法取得更好的实验效果.
3.4 消融实验
为了验证本文提出的为视频、文本数据分别生成多个事件表示,并通过这些事件间的细粒度的相似性关系更好地刻画岀视频与文本间的语义相似性关系这一想法的有效性,我们提出了1 个CLIPMERG的变种CLIPMERG_1,即在计算视频与文本相似性关系时直接用视频的视频帧token 序列的平均池化后的全局特征与文本的EOS 特征直接进行点积表示,并在数据集MSR-VTT,DiDeMo,LSMDC 上做实验,实验结果如表5 所示.
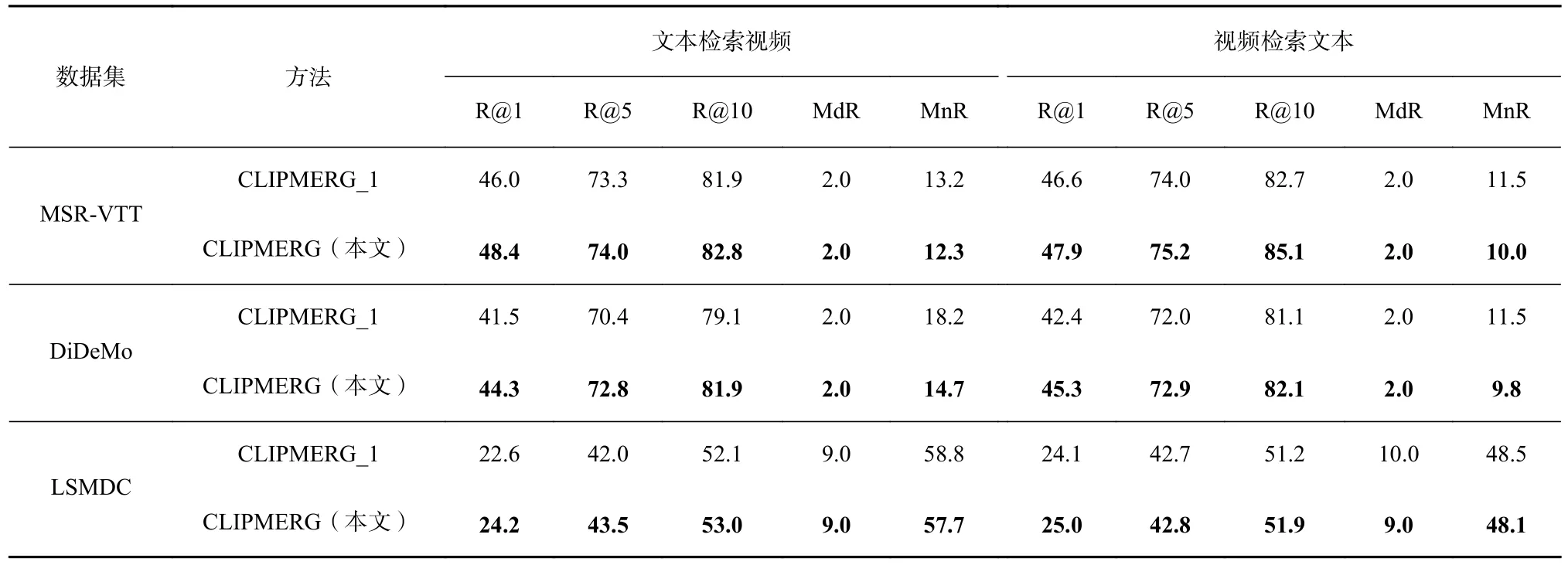
Table 5 Experimental Results of CLIPMERG and Its Variants on Three Datasets表5 CLIPMERG 与其变种在3 个数据集上的实验结果
由表5 可以发现,CLIPMERG 相比于CLIPMERG_1在3 个数据集上均能取得更好的实验效果.如在数据集DiDeMo 上,在文本检索视频的任务中CLIPMERG在R@1,R@5,R@10,MnR 等指标上分别取得了2.8%,2.4%,2.8%,3.5 的提升.表5 表明,通过挖掘视频与文本中事件间的细粒度相似性关系将能更好地刻画出视频与文本间的语义相似性关系,进而提升视频、文本间的检索效果.
3.5 参数敏感性分析
为了充分探讨视频、文本数据生成不同的事件个数k对模型最终的检索效果的影响,本文展示了随k值变化,CLIPMERG 模型在 R@1指标上的检索效果变化趋势,在数据集MSR-VTT,DiDeMo,LSMDC 上的实验结果分别如图3 所示.

Fig.3 Influence of the number of video and text events on R@1图3 视频、文本的事件数k 对R@1 的影响
由图3 可以发现,在这3 个数据集中,当事件数k=4 时,本文所提的CLIPMERG 在文本检索视频(T2V)任务以及视频检索文本(V2T)任务上均能取得不错的实验结果,因此在本文的其他实验中,我们将为每个视频(文本)数据分别生成4 个视频(文本)事件表示,然后通过挖掘数据的事件间的细粒度相似性关系以定义数据点间的语义相似性.
3.6 示例展示
图4 展示了 CLIP4Clip 方法以及CLIPMERG 方法在用视频检索文本时的一个示例,其中正确返回的文本为框中的文本.CLIP4Clip 方法返回最相似的3 个文本,且相似性从左往右依次降低;CLIPMERG方法返回最相似的3 个文本,且相似性从左往右依次降低.可以发现,CLIPMERG 的检索效果更好,这表明通过挖掘视频事件与文本事件间细粒度关系能更好地定义视频文本间的语义关系,进而提升模型的检索效果.

Fig.4 The case of video retrieval text on MSR-VTT dataset图4 MSR-VTT 数据集上视频检索文本示例
4 结论
本文提出了一个基于CLIP 生成多事件表示的视频文本检索方法CLIPMERG.该方法通过捕捉视频中事件与文本中事件之间的细粒度相似性关系来更好地计算文本与视频间的相似性关系,进而提升文本视频间跨模态检索效果.具体地,该方法首先通过利用大规模图文预训练模型CLIP 的视频编码器(ViT)以及文本编码器(Tansformer)分别将视频、文本数据转换成视频帧token 序列以及文本的单词token 序列,而后通过视频事件生成器(文本事件生成器)将视频帧token 序列(单词token 序列)转换成k个视频事件表示(k个文本事件表示).最后,通过挖掘视频事件表示与文本事件表示之间的细粒度关系以定义视频、文本间的相似性关系.在3 个常用的公开视频文本检索数据集MSR-VTT,DiDeMo,LSMDC 上的实验结果表明本文所提的CLIPMERG优于现有的视频文本检索方法.
作者贡献声明:涂荣成提出了算法思路、实验方案以及撰写论文;毛先领负责指导实验、撰写论文以及论文润色;孔伟杰、蔡成飞以及赵文哲负责实验部分;王红法以及黄河燕提出指导意见并修改论文.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
制造技术与机床(2019年10期)2019-10-26
意林图解作文(小学版)(2019年6期)2019-07-16
电子制作(2018年18期)2018-11-14
浙江大学学报(工学版)(2016年2期)2016-06-05
专利代理(2016年1期)2016-05-17
小学教学参考(2015年20期)2016-01-15
语文知识(2014年1期)2014-02-28
俄罗斯问题研究(2013年1期)2013-03-11
